
Etapa 3.5 Flash: O azarão que surgiu da batalha de IA durante o Festival da Primavera agora está ultrapassando os concorrentes na era dos Agentes.

O setor de IA deste ano é um tanto parecido com o mercado de smartphones em 2008. Todos sabem que as telas sensíveis ao toque são o futuro, mas os fabricantes estão produzindo "Nokias com telas sensíveis ao toque".
A era dos agentes chegou; isso é um consenso. Mas como criar um bom modelo de agente? Seguindo o pensamento convencional, a resposta provavelmente ainda seria a mesma: mais parâmetros, estruturas de rede mais profundas e abrangentes e conjuntos de dados maiores.

300B não é suficiente, então optamos por 1T; 1T não é suficiente, então optamos por 10T. É como se, contanto que o modelo seja grande o suficiente, as capacidades de agente surgissem naturalmente, assim como, contanto que a tela da Nokia seja grande o suficiente, o iPhone aparecerá por si só.
Embora modelos com muitos parâmetros ofereçam uma base de conhecimento mais ampla e uma fundação mais robusta, simplesmente "otimizar" a geração anterior de modelos não tornará nossos agentes melhores. A era dos agentes exige modelos agentes .
Existe uma abordagem mais eficiente e verdadeiramente disruptiva que não dependa do empilhamento de parâmetros, mas sim da otimização da arquitetura; que não exija servidores dedicados na nuvem e possa ser executada localmente; e que seja ao mesmo tempo versátil e possua otimizações específicas?
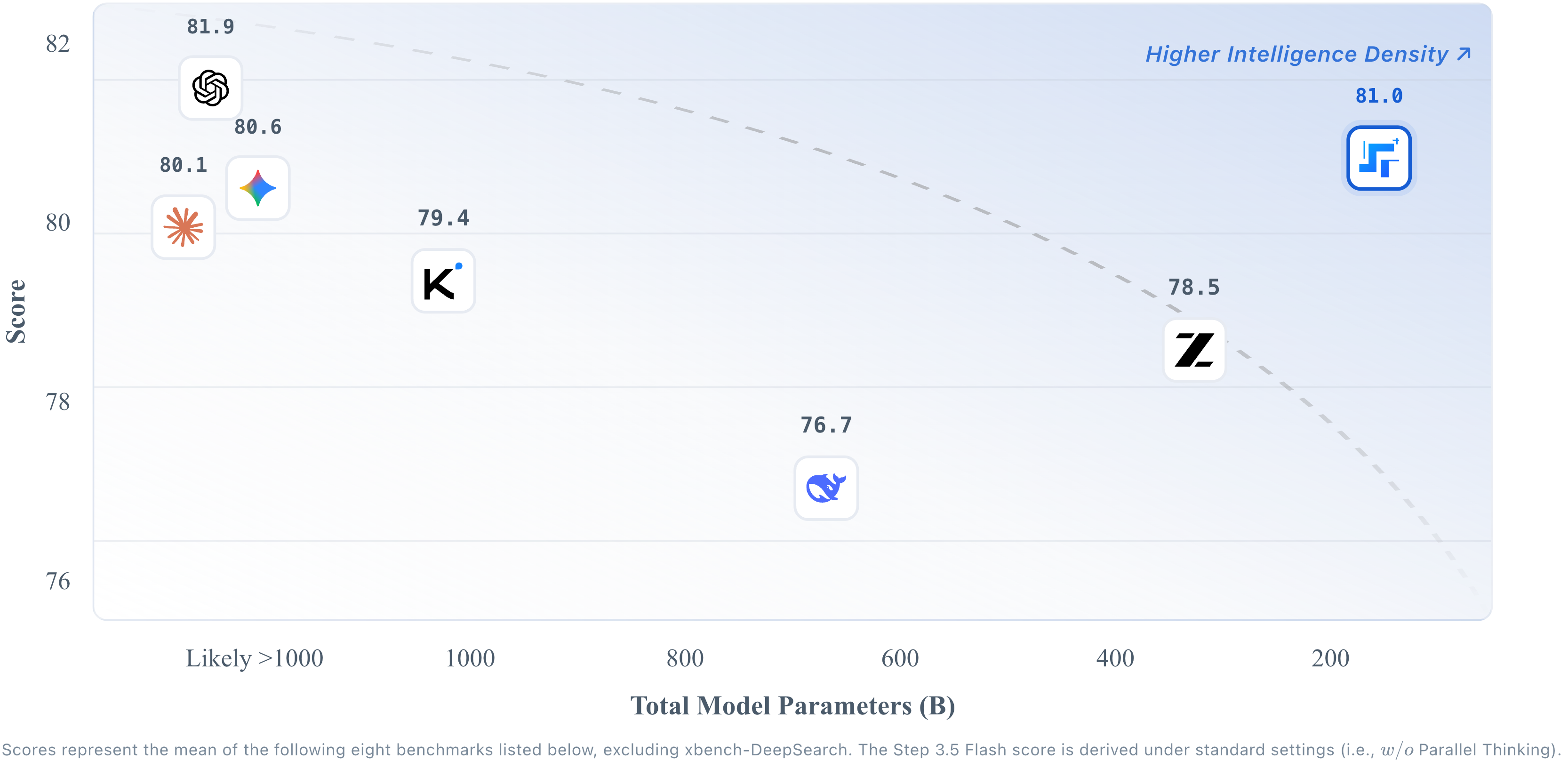
▲Comparação do tamanho dos parâmetros do modelo e da inteligência: Etapa 3.5 O Flash tem o menor número total de parâmetros no gráfico, mas ocupa o segundo lugar em pontuação de inteligência.
Em 2 de fevereiro, a Step Star lançou e disponibilizou como código aberto seu modelo base mais recente, o Step 3.5 Flash, que é um modelo de suporte subjacente mais eficiente para agentes. Ele adota uma arquitetura MoE esparsa com um total de 196 bilhões de parâmetros, mas cada token ativa apenas cerca de 11 bilhões de parâmetros.
Essa é uma estatística bastante contraintuitiva na indústria de modelos em larga escala, aparentemente "ficando para trás" em comparação com concorrentes que disputam trilhões de parâmetros. No entanto, essa escolha aparentemente "atrasada" pode guardar o maior segredo da era dos Agentes.
O modelo L3 não consegue mais subir na hierarquia do L1.
Se isso tivesse acontecido seis meses atrás, a Leap Star poderia estar fazendo algo completamente diferente.
Em sua postagem mais recente no blog, Zhu Yibo, cofundador e CTO da Step2, mencionou que, durante a era do modelo Step2, eles também acreditavam firmemente na Lei de Escala. Como todos os fabricantes de modelos da época, eles subiram diligentemente a escada chamada parâmetros, projetando um número maior de parâmetros do que o DeepSeek V3 e até mesmo treinando-o vários meses antes de seus concorrentes.
O resultado foi que, apesar de suas impressionantes pontuações em testes de desempenho, a lógica tradicional de empilhamento de componentes acabou sendo superada pelo paradigma de inferência do DeepSeek R1.
O motivo é simples: o DeepSeek R1 representa um salto em frente, dos chatbots de nível 1 para os sistemas de raciocínio de nível 2. Continuar a usar o pensamento de chatbots para construir modelos de raciocínio pode não levar necessariamente ao fracasso, mas certamente encontrará um obstáculo.
Este trabalho não é apenas uma retrospectiva da experiência de Jieyue Xingchen, mas também um microcosmo de toda a indústria. Após muita reflexão árdua, eles descobriram uma verdade negligenciada: os chatbots na era do Nível 1 e os agentes na era do Nível 3 exigem dois modelos diferentes .

▲A estrutura de cinco níveis da OpenAI, desde o chatbot de primeiro nível, passando pelo raciocínio, agentes, inovadores e, por fim, a organização de quinto nível.
De acordo com a arquitetura de cinco níveis da OpenAI, estamos vivenciando um salto do Raciocinador de Nível 2 para o Agente de Nível 3.
Na era dos chatbots de nível 1 , o requisito fundamental era a fluência na conversação; o modelo precisava apenas responder rapidamente e se expressar naturalmente. O que talvez precisássemos era de um "estudante de humanas" capaz de recitar enciclopédias, com conhecimento suficiente para imitar sem esforço o estilo de Lu Xun. Nesse ponto, uma velocidade de saída de 20 a 30 tokens por segundo correspondia perfeitamente aos hábitos de leitura humanos.
A era do raciocínio de segunda linha : Com o surgimento de longas cadeias de pensamento, precisamos de modelos que possam representar o pensamento completo e profundo. Ao observarmos processos de pensamento prolongados, consideramos que são inteligentes e estamos até dispostos a esperar dezenas de segundos por um resultado mais preciso.
A era do Agente L3 : as características mudaram completamente. O contexto do cenário de trabalho reside na faixa de 32K a 128K. Não lemos mais a saída palavra por palavra, mas nos concentramos apenas em "quando os resultados podem ser entregues".
Nesse cenário, continuar usando o modelo de parâmetros complexos da era L2 é como pegar o equipamento da Linha Aotai para subir a "Linha Hutai" de Sheshan. Embora as reservas sejam suficientes, a eficiência é baixa e o custo de poder computacional é extremamente alto.
Em certa medida, o agente não pode mais ser visto pelo usuário, mas sim utilizado para a tarefa. Ele precisa funcionar de forma eficiente em contextos longos, com uma base de código capaz de lidar facilmente com centenas de milhares de tokens; e precisa melhorar a velocidade, o que determina diretamente a experiência do usuário; mas o núcleo ainda está no planejamento e na invocação de ferramentas.
Se continuarmos a usar modelos robustos da era L1 para executar tarefas L3, é como dirigir uma Ferrari para entregar comida — não só é caro, como também simplesmente não funciona em condições de trânsito congestionado e de longa distância.
Isso também explica por que a Step Tech ousou ir contra a corrente e apresentar a "nova espécie" de Flash Step 3.5, com foco em "velocidade" e "lógica robusta". Essa escolha pode parecer destoar do mercado à primeira vista, mas abre mais possibilidades.
No mundo das artes marciais, a velocidade é a única maneira de romper as defesas: a "estética violenta" da era Agent.
Na era Agent, "velocidade" deixou de ser um bônus adicional e se tornou uma questão de vida ou morte para o modelo.
Zhu Yibo destacou um detalhe que é facilmente ignorado: na era dos chatbots, bastava que a saída do modelo fosse mais rápida que a velocidade de leitura humana (20-30 tokens/s), caso contrário não conseguiríamos ler tudo. Mas na era dos agentes, esse padrão é completamente inválido .
Por quê? Porque os usuários não querem ver o processo. Quando a IA nos ajuda a escrever código, buscar informações ou reservar voos, não ficamos olhando para a tela enquanto ela transcreve palavra por palavra; queremos apenas o resultado.
Nessa fase, a velocidade deixa de ser uma questão de experiência e passa a ser uma questão de produtividade em si, determinando diretamente a eficiência na execução da tarefa.
Para alcançar essa velocidade máxima, a LeapStar fez uma grande aposta em seu caminho tecnológico.
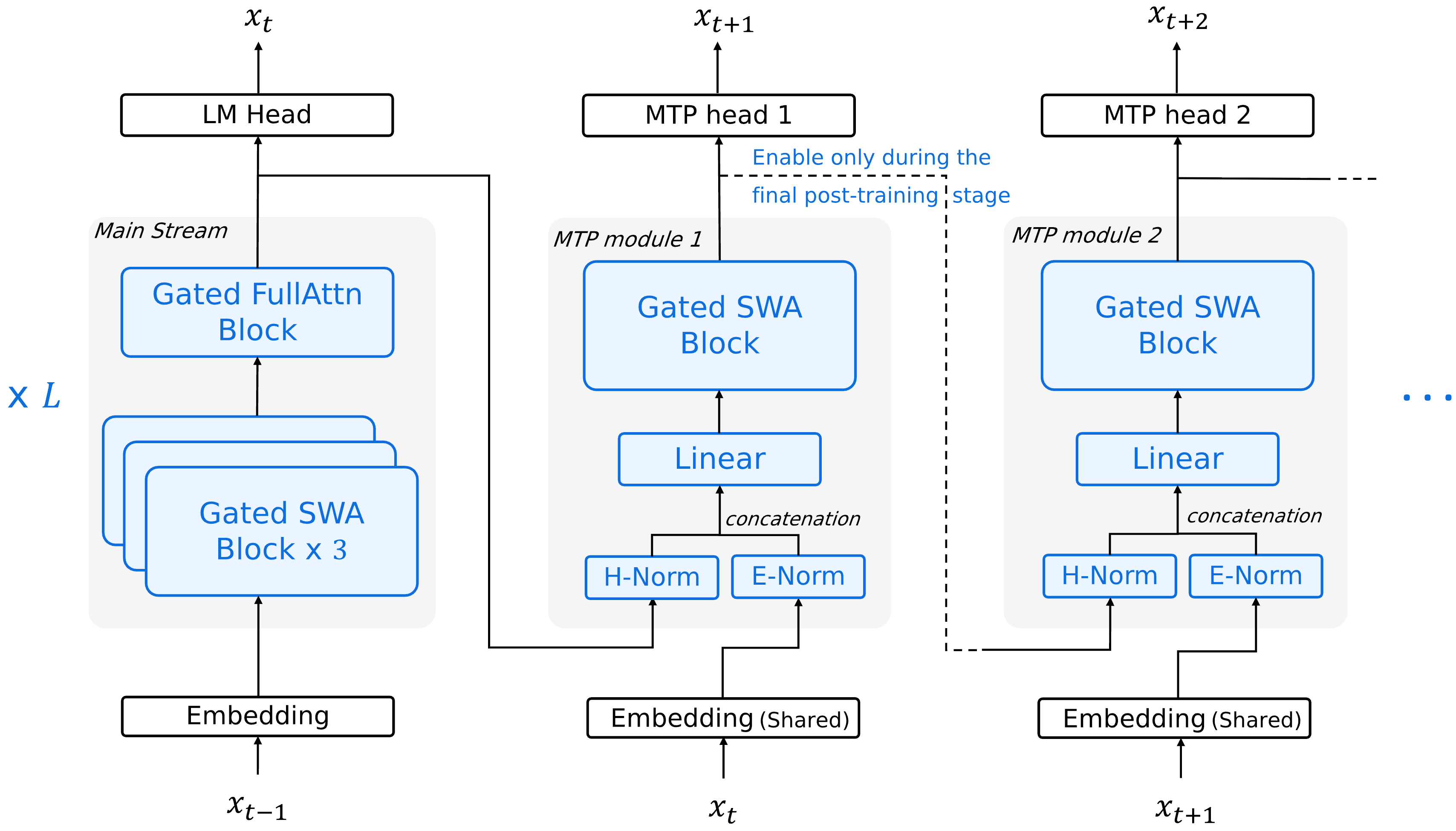
▲Etapa 3.5 Arquitetura Geral do Flash: A Etapa 3.5 Flash é um modelo de linguagem de grande porte que adota uma arquitetura híbrida esparsa de especialistas (MoE). Sua arquitetura é definida pelo codesign do modelo e do sistema, considerando o custo e a velocidade de inferência como as principais restrições arquitetônicas .
Enquanto seus pares seguiam cegamente a tendência da Atenção Linear, o Flash da Step 3.5 insistiu em escolher a arquitetura SWA (Atenção por Janela Deslizante) . Esse layout de atenção híbrido consegue processar cálculos de tokens mais rapidamente, por um lado, e resolver o gargalo secundário do processamento de contextos longos, por outro.
Em termos simples, ele não memoriza todo o texto de 256K mecanicamente; em vez disso, aloca a atenção de forma focada e rítmica, muito semelhante a um ser humano. Isso permite não apenas evitar a perda de inteligência ao processar grandes quantidades de dados, mas também reduzir significativamente os custos computacionais.
O que parece ser uma "abordagem reversa" é, na verdade, o cálculo sofisticado da era dos Agentes, onde "métodos hábeis produzem ótimos resultados". Isso ocorre porque, nas condições atuais de hardware, a SWA (Amostragem Especulativa de Superfície) é mais favorável para amostragem especulativa. Essa compensação técnica aumenta diretamente a velocidade de inferência de tarefas baseadas em código de requisição única para um máximo de 350 tokens/s .
A capacidade de "eliminação instantânea" ultrarrápida é o momento decisivo que transforma a IA de um "brinquedo" em uma ferramenta de produtividade. No primeiro dia de seu lançamento, o Step 3.5 Flash entrou para a lista dos modelos mais rápidos do OpenRouter .
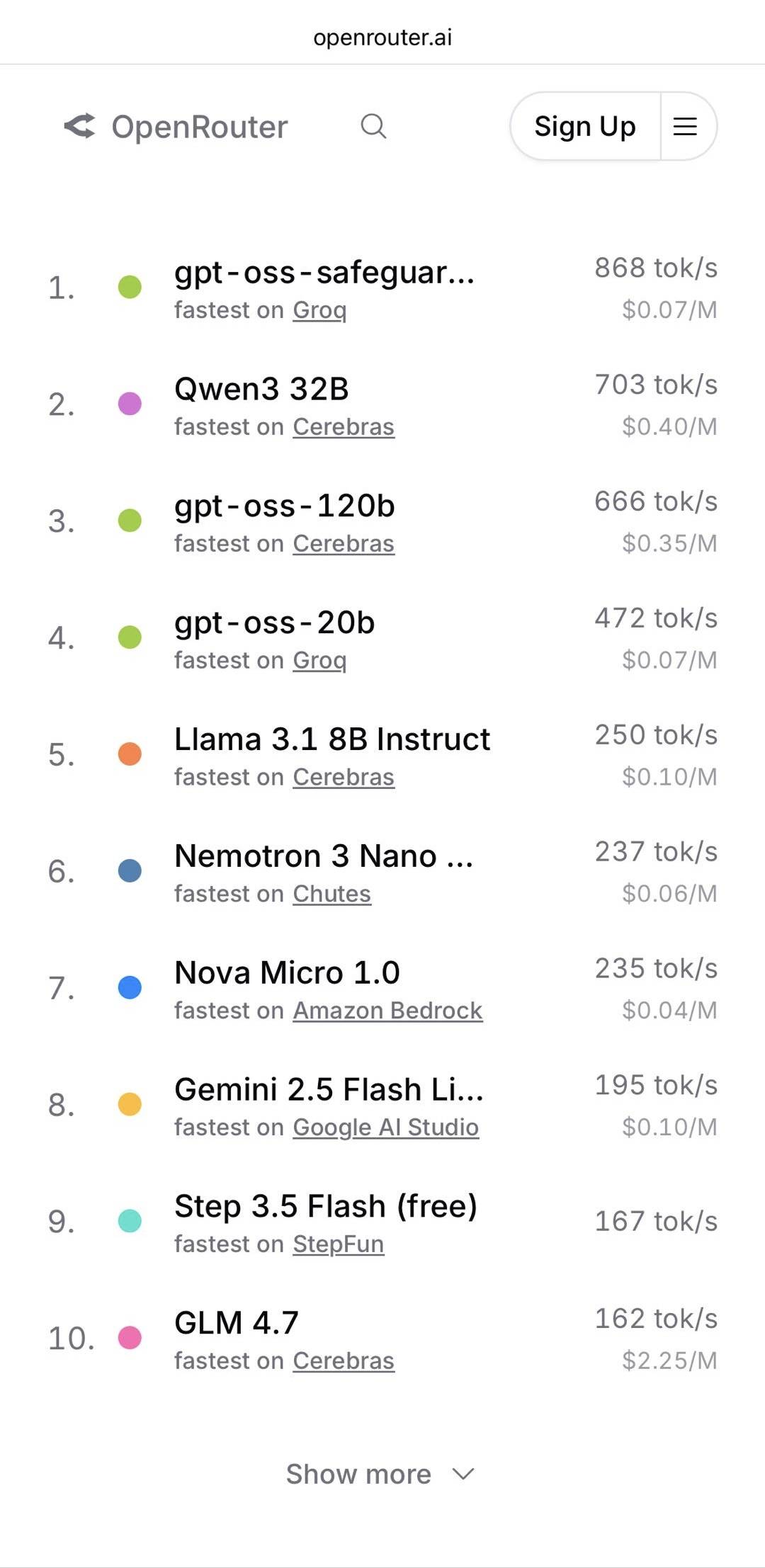
▲De acordo com o mais recente ranking de modelos mais rápidos divulgado pela OpenRouter, o Step 3.5 Flash possui uma taxa de geração de 167 tokens/s, classificando-se entre os modelos mais rápidos do mundo.
Rejeite os "especialistas em memorização"; a alta inteligência é a principal força produtiva.
Correr rápido não pode significar "diminuir a inteligência". " Alta inteligência " também é essencial para avaliar se um modelo é adequado como agente.
O consenso geral, tanto entre os usuários quanto entre a maioria dos fabricantes de modelos, é que quanto maiores os parâmetros, maiores as capacidades. No entanto, o desempenho de destaque do Step 3.5 Flash na área matemática, alcançado com dimensões apropriadas e pós-treinamento extremo , produziu resultados comparáveis aos de modelos com parâmetros elevados.
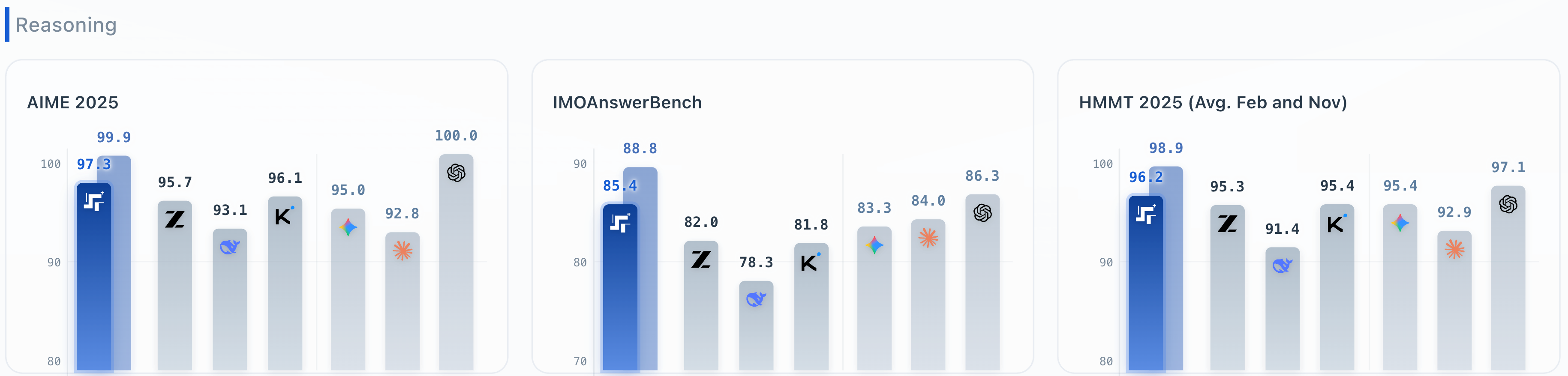
- Obteve 97,3 pontos no AIME 2025 (American Invitational Mathematics Competition);
- Ele obteve 85,4 pontos no IMO Answer Bench (Índice de Referência da Olimpíada Internacional de Matemática);
- Na HMMT 2025 (Competição de Matemática Harvard-MIT), ele chegou a marcar 96,2 pontos .
O que isso significa? Essas pontuações são as mais altas entre os principais modelos de código aberto na China.
Se o modo de Raciocínio Colaborativo Paralelo (PaCoRe) estiver ativado, sua pontuação se aproxima da perfeição. Por trás desse fenômeno de "excesso de inteligência" reside uma verdade extremamente sutil, porém precisa, do setor: os modelos anteriores eram como "memorizadores", dependendo da memorização mecânica de grandes quantidades de dados para funcionar; enquanto o Step 3.5 Flash é um verdadeiro "solucionador de problemas".
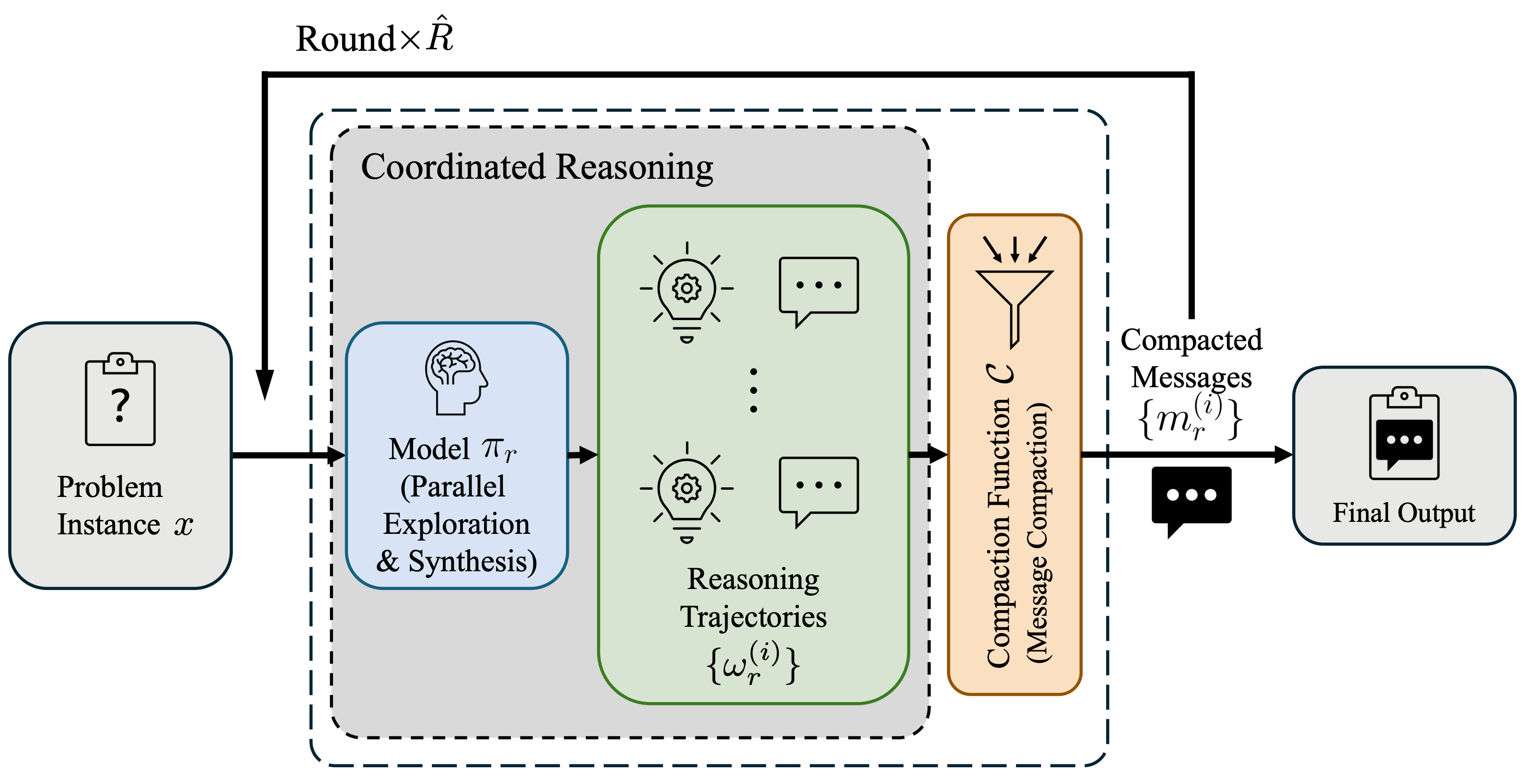
▲O processo de raciocínio do PaCoRe (Raciocínio Paralelo Coordenado). Cada rodada inicia uma extensa exploração paralela, comprimindo as trajetórias geradas em informações compactas, que são então passadas junto com a pergunta para coordenar a próxima rodada. Esse processo é repetido 10 vezes, alcançando um TTC (tempo de teste computado) efetivo para milhões de tags, enquanto se respeitam as restrições de contexto fixas. A informação comprimida final serve como a resposta do sistema.
No fluxo de trabalho de um agente, essa capacidade é fatal. Como as tarefas do mundo real são repletas de incógnitas, o que precisamos não é de um papagaio que apenas repita informações básicas, mas de um "supercérebro" capaz de compreender instruções complexas, decompor a lógica da tarefa e se autocorrigir.
A capacidade de raciocínio comprova a inteligência, mas o agente ainda precisa ser confiável em seu trabalho. A Etapa 3.5 Flash conquistou o primeiro lugar no mercado nacional de código aberto em diversos cenários importantes.
Habilidade de programação: Nível superior globalmente 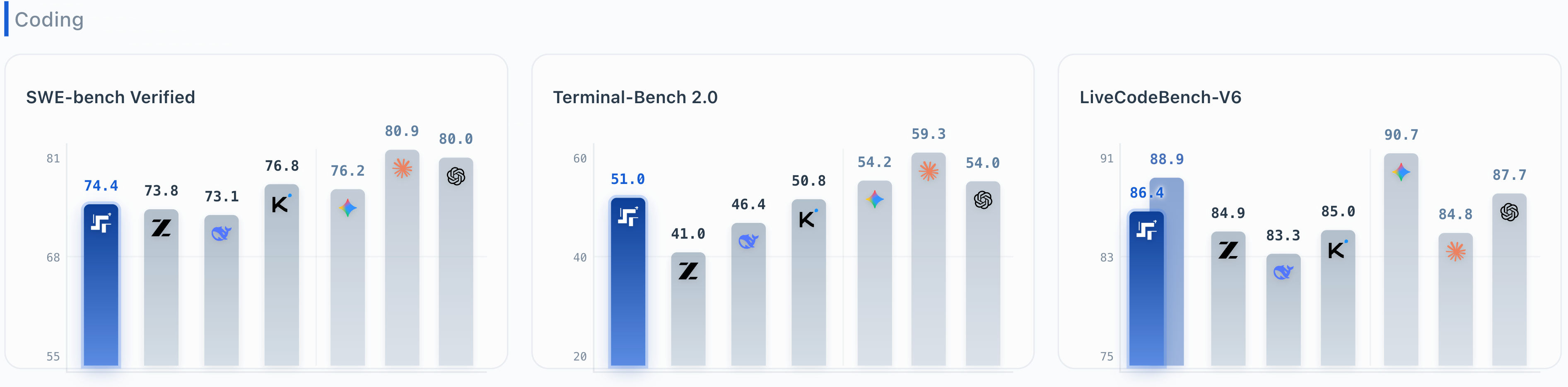
- Verificado pelo SWE-bench: 74,4 pontos (Correções de bugs de um projeto real de código aberto)
- Terminal-Bench 2.0: 51 pontos ( Produto de código aberto nº 1 da China , para automatizar tarefas em terminais)
- LiveCodeBench-V6: 86,4/88,9 pontos ( Código aberto número um na China para codificação e depuração em tempo real)
Principais funcionalidades do agente: Diversas inovações pioneiras em código aberto no mercado nacional. 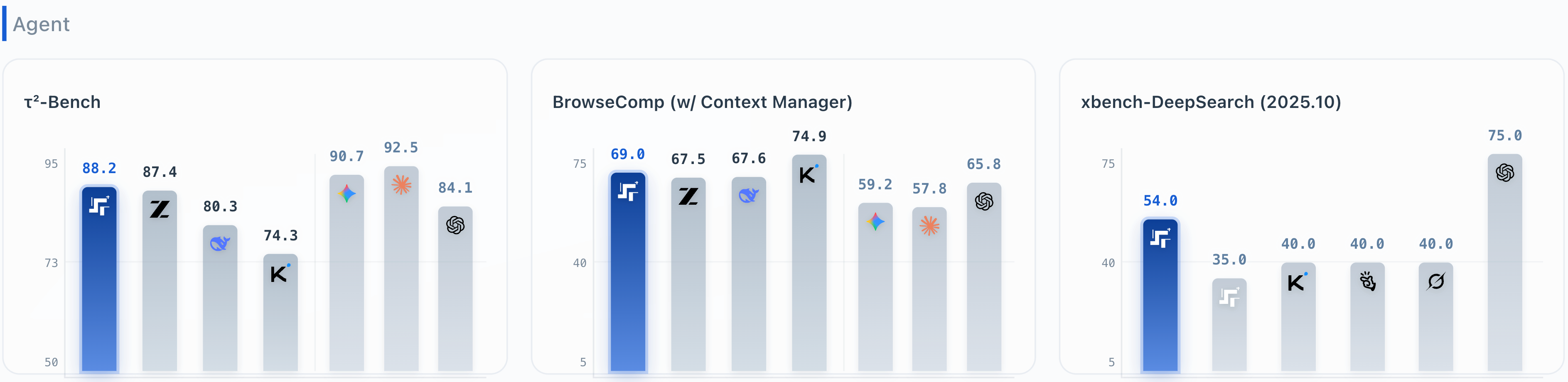
- τ²-Bench: 88,2 pontos ( nº 1 em código aberto na China , planejamento de tarefas em várias etapas)
- xbench-DeepSearch: 54 pontos ( Produto de código aberto número um na China para busca profunda e integração de informações)
- BrowseComp: 69 pontos (Nível superior, navegação na web e gerenciamento de contexto)
Por mais impressionantes que sejam os dados, eles precisam resistir ao teste de cenários do mundo real . Nos seguintes cenários típicos, o Step 3.5 Flash também provou que "habilidoso e poderoso, rápido como um raio" não é apenas um slogan.
Embora seja comum acreditar que escrever relatórios de análise com o Deep Research exija modelos bem redigidos e eloquentes, na verdade, depende de um raciocínio lógico sólido e da capacidade de utilizar as ferramentas de forma eficaz.
Dê a ele um tópico vago, como "educação científica para bebês e crianças de 0 a 3 anos", e ele não vai simplesmente inventar coisas. Em vez disso, como um pesquisador humano de verdade, ele vai dividir a tarefa em partes, planejar o caminho, pesquisar online, refletir e revisar, e então nos entregar um relatório detalhado com dezenas de milhares de palavras que até mesmo pais inexperientes conseguem entender.

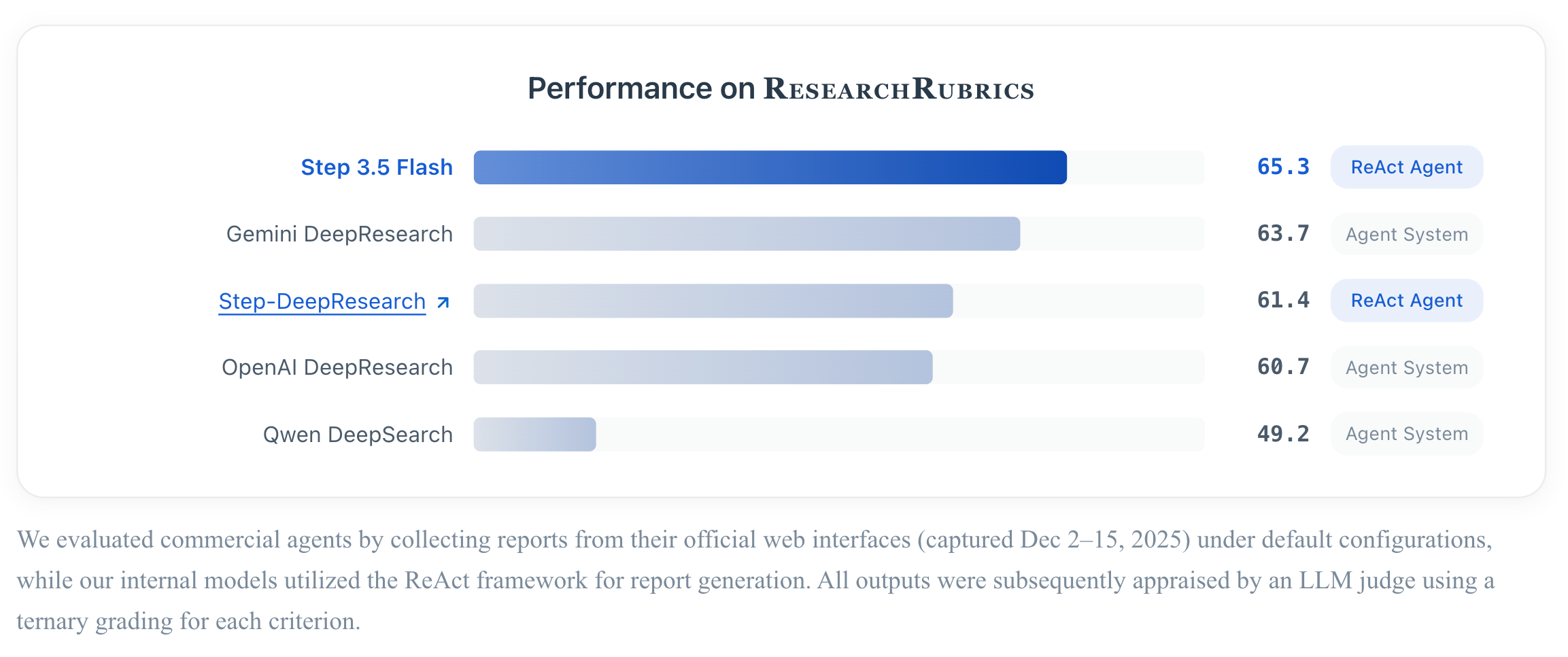
No benchmark Research Rubrics da Scale AI, sua pontuação superou até mesmo sistemas similares da OpenAI e da Gemini. Isso demonstra ainda mais que ela já alcançou um "circuito fechado lógico" capaz de operar de forma independente.
A Etapa 3.5 Flash também pode ser integrada ao ambiente Claude Code. Quando o modelo atua como um analista de dados profissional e se depara com tarefas complexas de análise de dados, ele pode não apenas escrever código para limpar os dados, auxiliar nos processos diários de dados e alinhar formatos de dados, mas também gerar relatórios de fluxo de trabalho diretamente.
Sejam projetos de Pesquisa Profunda ou de Codificação Vibracional, ambos são realizados no site oficial da Step 3.5 ou por meio de chamadas a APIs, mas as ambições do Step 3.5 Flash vão muito além de simplesmente extrair recursos de IA de servidores em nuvem.
Zhu Yibo revelou que chegou a comprar um dispositivo do próprio bolso para executar o modelo. Atualmente, o Step 3.5 Flash é o modelo mais poderoso disponível, sem exceção, capaz de funcionar sem problemas com um contexto ultralongo de 256K em um MacBook com 128 GB de RAM usando quantização de 4 bits.
Essa frase, "sem exceção", realmente destaca a teimosia dos tecnólogos. Talvez também indique a ambição final da estratégia "IA + Terminal" da Leapfrog Space: o cérebro mais poderoso não deveria residir apenas em clusters H100 caros; deveria residir no seu computador e até mesmo em futuros celulares .
Enquanto outros fabricantes ainda disputam financiamento e avaliações, a LeapStar reduziu discretamente, mais uma vez, a barreira de custo para agentes de alto desempenho. Isso confirma a previsão estratégica: o "espetáculo" da competição em larga escala entre modelos acabou, e o setor entrou oficialmente na fase de "sobrevivência do mais apto".
Um novo concorrente inesperado surgiu na batalha da IA no Festival da Primavera, agitando o cenário dos modelos de big data.
Na recente e ruidosa batalha de lançamentos de IA, o Step 3.5 Flash, esse azarão, foi definitivamente subestimado. Não se trata apenas de um modelo "de alto desempenho e baixo custo"; pelo contrário, é algo semelhante ao surgimento repentino do DeepSeek há um ano, abrindo um novo caminho para a indústria de IA.
No mundo real, onde o poder computacional não é ilimitado, o verdadeiro vencedor é quem consegue resolver problemas mais complexos com uma arquitetura mais sofisticada e menos recursos.
A era do "ascensão social", em que simplesmente acumular especificações garantia financiamento e manipular rankings rendia aplausos, já passou. As batalhas que virão serão travadas por aqueles que não são apenas "inteligentes", mas também "astutos".
Essa insistência na "miniaturização e alta eficiência" deriva essencialmente da dedicação da StepStar à missão da IAG (Inteligência Artificial Geral). Zhu Yibo certa vez observou que a importância de persistir no treinamento do modelo básico, além das vantagens comerciais, reside na realização desse "sonho de longa data da IAG".
Para a LeapStar, o caminho para a Inteligência Artificial Geral (AGI) não envolve grandes apostas, mas sim uma metodologia inovadora e uma avaliação precisa das necessidades da época. Como afirmou Yin Qi, o recém-nomeado presidente da LeapStar, em entrevista: "Desenvolver modelos básicos sólidos e explorar os limites superiores da inteligência é a missão da LeapStar."
Do Passo 1 ao Passo 3.5, da multimodalidade à voz, da nuvem ao terminal, a integração da IA com o espaço físico e a integração profunda com o hardware do terminal são etapas necessárias para superar obstáculos e alcançar a AGI definitiva.
Quando as capacidades da IA realmente "chegarem aos lares comuns", o objetivo final da competição tecnológica não será mais a corrida armamentista pelo poder computacional. A IA começará a nos servir melhor, e todos — pequenas e médias empresas, desenvolvedores individuais e estudantes — poderão usar recursos de ponta a baixo custo. A Inteligência Artificial Geral (IAG) deixará de ser apenas um jogo para gigantes.
Com engenhosidade e rapidez , o Step 3.5 Flash oferece sua resposta e representa mais um passo em direção à missão da IAG (Inteligência Artificial Geral).
Aqueles que persistirem em seus sonhos acabarão por trilhar seu próprio caminho. E esse caminho está se tornando cada vez mais claro.
#Siga a conta oficial do iFanr no WeChat: iFanr (ID do WeChat: ifanr), onde você encontrará conteúdo ainda mais interessante o mais breve possível.
