
Entenda o modelo o1 mais forte da OpenAI em um artigo: como usá-lo bem, por que ele foi derrubado e o que isso significa para nós

Já se passou uma semana desde que o OpenAI o1 foi lançado, mas ainda é um mistério semelhante a uma cebola, esperando para ser resolvido camada por camada.
Não há limite para o modo como os geeks podem jogar. Deixe-nos fazer um teste de QI, escrever provas de vestibular e decifrar textos cifrados. Também há usuários que usam IA para trabalhar e sentem que o1 não é tão fácil de usar, mas não sabem se é problema deles ou da IA.
Todos sabemos que é bom raciocinar, mas por quê? Comparado com nosso velho amigo GPT-4o, qual é a vantagem do o1 e onde ele é adequado para uso?
Reunimos algumas perguntas que podem lhe preocupar e as respondemos da forma mais clara possível para torná-lo mais próximo das pessoas comuns.
o1 O que há de especial?
o1 é o modelo de inferência do OpenAI lançado recentemente. Atualmente, existem duas versões: o1-preview e o1-mini.
O que há de mais característico nisso é que pensa antes de responder, gerando uma longa cadeia de pensamento interno, raciocinando passo a passo e imitando o processo humano de pensar sobre problemas complexos.

▲ OpenAI
A capacidade de fazer isso vem do treinamento de aprendizagem por reforço do o1.
Se os grandes modelos anteriores eram dados de aprendizagem, o1 é mais parecido com o pensamento de aprendizagem.
Assim como quando resolvemos um problema, não devemos apenas anotar a resposta, mas também o processo de raciocínio. Você pode memorizar uma pergunta mecanicamente, mas se aprender a raciocinar, poderá fazer inferências.

Fica mais fácil de entender se fizermos a analogia do AlphaGo, que derrotou o campeão mundial de Go.
AlphaGo é treinado por meio de aprendizado por reforço. Ele primeiro usa um grande número de registros humanos de xadrez para aprendizado supervisionado e, em seguida, joga xadrez contra si mesmo. Em cada jogo, ele é recompensado ou punido com base na vitória ou na derrota, melhorando continuamente suas habilidades no xadrez. e até mesmo dominar métodos que os jogadores de xadrez humanos não conseguem imaginar.
o1 e AlphaGo são semelhantes, mas AlphaGo só pode reproduzir Go, enquanto o1 é um modelo de linguagem grande de uso geral.
Os materiais que o1 aprende podem ser códigos de alta qualidade, bancos de questões matemáticas, etc. Então o1 é treinado para gerar uma cadeia de pensamento para resolver problemas e, sob o mecanismo de recompensa ou punição, ele gera e otimiza sua própria cadeia de pensamento para melhorar continuamente seu capacidade de raciocínio.

Na verdade, isso explica por que o OpenAI enfatiza as fortes capacidades matemáticas e de codificação do o1, porque é mais fácil verificar o certo e o errado, e o mecanismo de aprendizagem por reforço pode fornecer feedback claro, melhorando assim o desempenho do modelo.
o1 Que tipo de trabalho é adequado para você?
A julgar pelos resultados da avaliação do OpenAI, o1 é um solucionador de problemas científicos bem merecido, adequado para resolver problemas complexos em ciências, codificação, matemática e outras áreas, e obteve pontuações altas em muitos exames.
Ele superou 89% dos participantes nas competições de programação Codeforces, classificado entre os 500 melhores do país na qualificação para as Olimpíadas de Matemática dos EUA e superou a precisão do nível de doutorado humano em benchmarks em problemas de física, biologia e química.
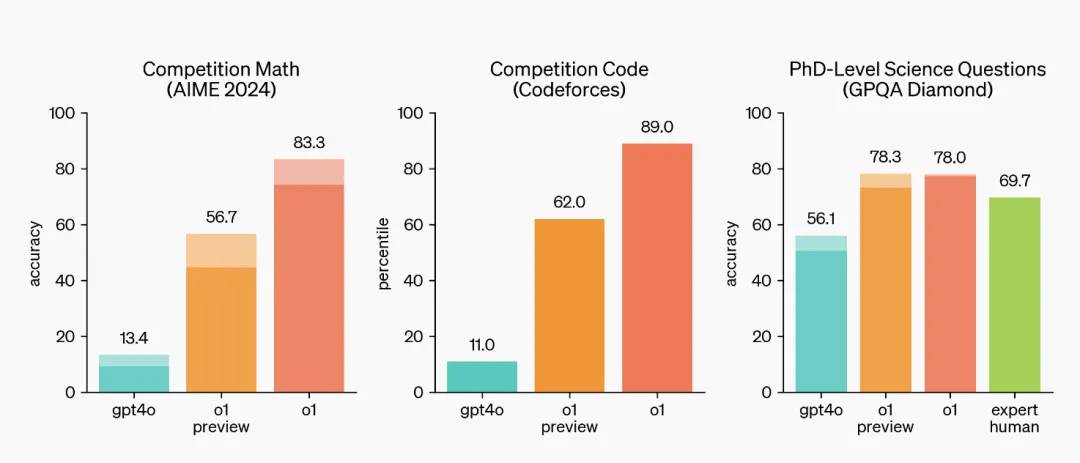
A excelência do o1 na verdade reflete um problema: à medida que a IA se torna cada vez mais inteligente, como medir suas capacidades se torna um problema. Para o1, a maioria dos benchmarks convencionais não tem sentido.
Acompanhando os eventos atuais, um dia após o lançamento do o1, a empresa de anotação de dados Scale AI e a organização sem fins lucrativos CAIS começaram a coletar questões do exame de IA de todo o mundo. as perguntas não poderiam estar relacionadas a armas.
O prazo para solicitação de inscrições é 1º de novembro. Em última análise, eles esperam construir o benchmark de código aberto de grande porte mais difícil da história, com um nome atraente: Último Exame da Humanidade.

De acordo com a medição real, o nível de o1 não é satisfatório – não são usadas expressões erradas e é geralmente satisfatório.
O matemático Terence Tao acredita que usar o1 é como instruir um estudante de pós-graduação que é mediano, mas não muito inútil.
Ao lidar com problemas de análise complexos, o1 pode encontrar boas soluções à sua maneira, mas não tem seus próprios conceitos e ideias-chave e também comete alguns grandes erros.
Não culpe esse matemático genial por ser duro. Em sua opinião, modelos anteriores como o GPT-4 são estudantes de pós-graduação inúteis.

O economista Tyler Cowen também fez uma pergunta para o exame de doutorado em economia. Depois de pensar sobre isso, a IA resumiu em palavras simples. A resposta o satisfez: “Você pode fazer qualquer pergunta de economia, e a resposta é boa”.
Resumindo, você também pode resolver todos os problemas de nível de doutorado e fazer o exame O1.
o1 Em que você não é bom agora?
Talvez para muitas pessoas, o1 não traga uma melhor experiência ao usuário. Pelo contrário, o1 irá derrubar algumas questões simples, como o jogo da velha.
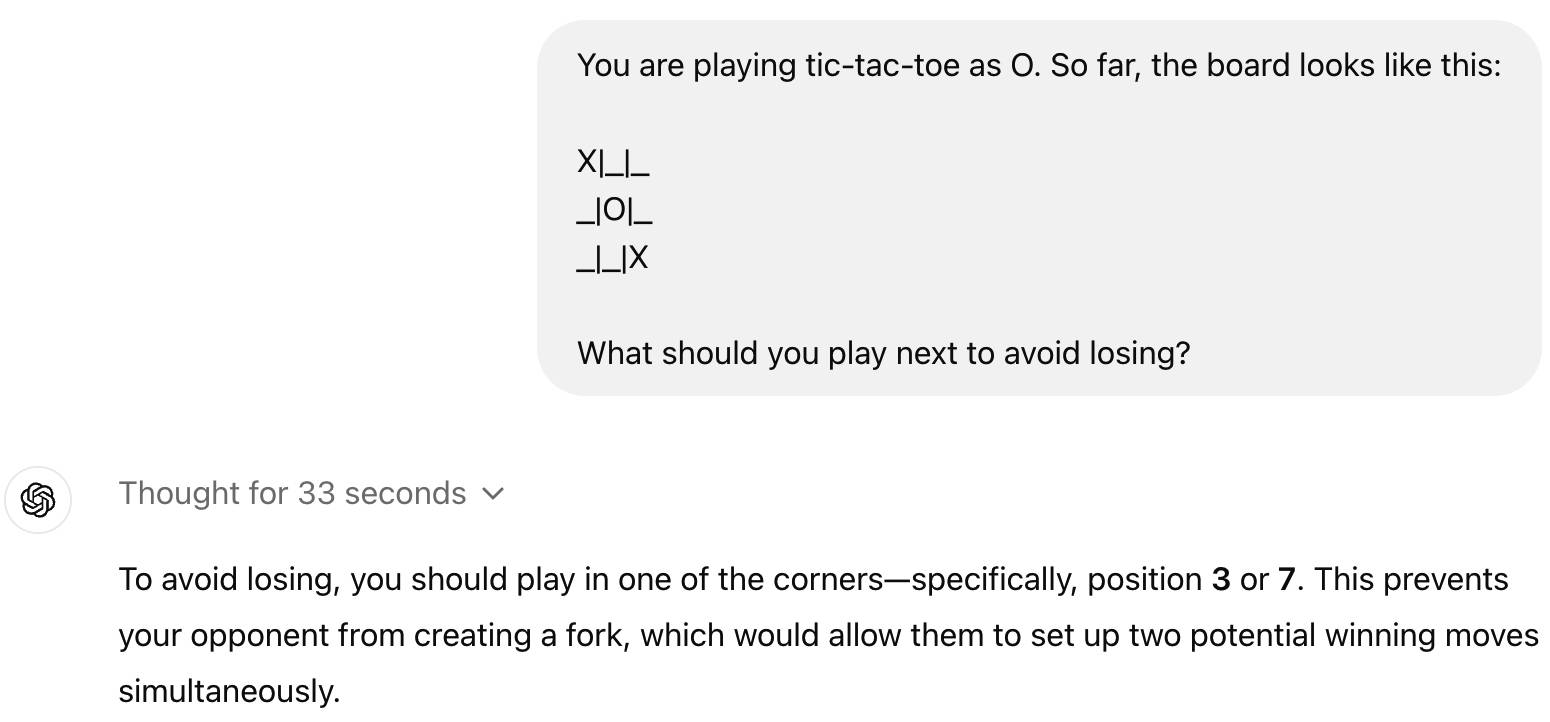
Na verdade, isso é normal. Atualmente, o1 é ainda inferior ao GPT-4o em muitos aspectos. Ele suporta apenas texto, não consegue ler, não consegue ouvir e não tem capacidade de navegar em páginas da web ou processar arquivos e imagens.
Então, não pense nisso por enquanto, deixe-o buscar referências e assim por diante, desde que não compense para você.
No entanto, o foco de o1 no texto faz sentido.
O fundador da Kimi, Yang Zhilin, mencionou recentemente em um discurso na Universidade de Tianjin que o núcleo do limite superior desta geração de tecnologia de IA é o limite superior das capacidades do modelo de texto.
A melhoria dos recursos de texto é vertical, tornando a IA cada vez mais inteligente, enquanto a multimodalidade, como visual e áudio, é horizontal, permitindo que a IA faça cada vez mais coisas.
No entanto, quando se trata de tarefas linguísticas, como redação e edição, o GPT-4o tem avaliações mais positivas do que o1. Estes também são textos, então qual é o problema?
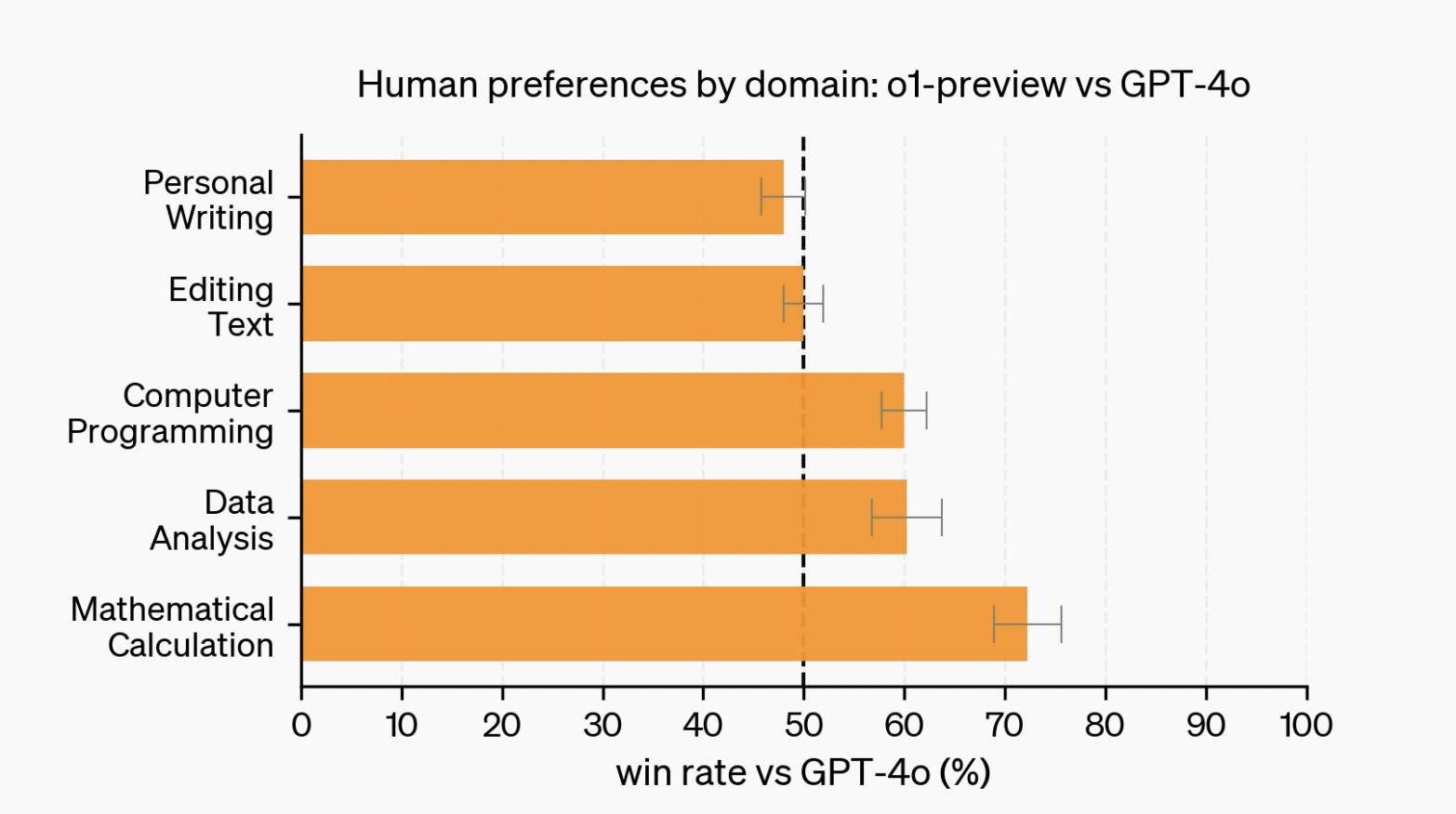
A razão pode estar relacionada com a aprendizagem por reforço Ao contrário da codificação, da matemática e de outros cenários onde existem respostas padrão, as tarefas linguísticas muitas vezes carecem de critérios de avaliação claros, tornando difícil formular modelos de recompensa eficazes e generalizá-los.
Mesmo nas áreas onde o1 é bom, pode não ser a melhor escolha. Em uma palavra, caro.
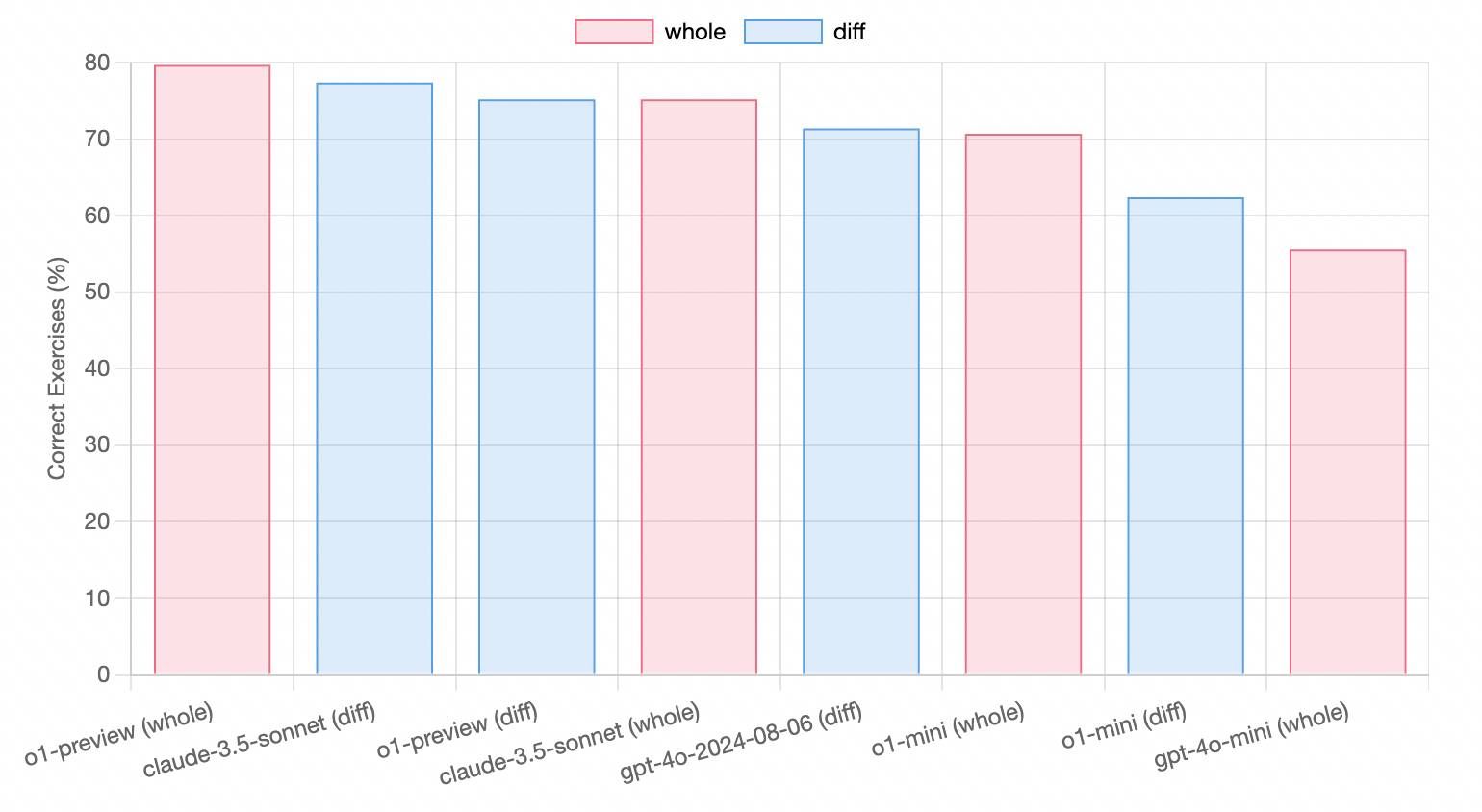
A ferramenta de codificação assistida por IA testou a capacidade de codificação da qual o1 se orgulha. Ela tem vantagens, mas não é óbvia.
Em uso real, o1-preview está entre Claude 3.5 Sonnet e GPT-4o, embora custe muito mais. De modo geral, no campo da codificação, o Claude 3.5 Sonnet ainda é o mais econômico.
Quanto custa para os desenvolvedores acessarem o1 por meio da API?
A taxa de entrada para visualização o1 é de US$ 15 por milhão de tokens e a taxa de saída é de US$ 60 por milhão de tokens. Isso se compara a US$ 5 e US$ 15 do GPT-4o.
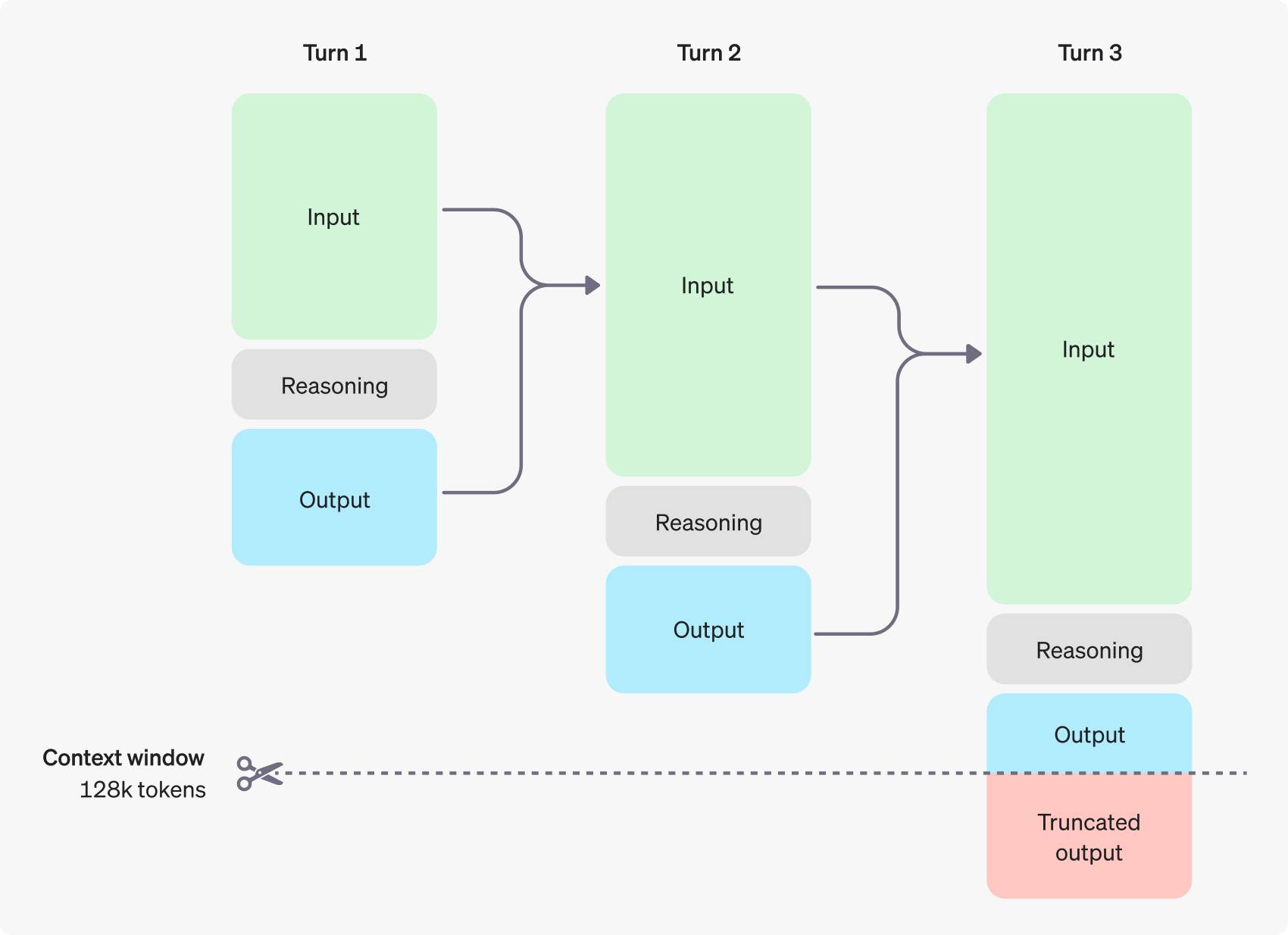
Os tokens de inferência de o1 também estão incluídos nos tokens de saída. Embora não sejam visíveis para o usuário, eles ainda precisam pagar.
Os usuários comuns também têm maior probabilidade de exceder sua cota. Recentemente, OpenAI aumentou a cota de uso de o1, o1-mini aumentou de 50 itens por semana para 50 itens por dia e o1-preview aumentou de 30 itens por semana para 50 itens por semana.
Portanto, se você tiver algum problema, tente primeiro o GPT-4o para ver se pode ser resolvido.
O1 poderia ficar fora de controle?
o1 Agora que alcancei o nível de doutorado, será mais fácil para as pessoas fazerem coisas ruins?
A OpenAI admite que o1 tem certos perigos ocultos e atinge “risco médio” em questões relacionadas com armas químicas, biológicas, radiológicas e nucleares, mas terá pouco impacto nas pessoas comuns.
Precisamos ter mais cuidado para não nos deixarmos enganar por o1 com sobrancelhas grossas e olhos grandes.
A IA gera informações falsas ou imprecisas, chamadas “alucinações”. As alucinações de o1 são reduzidas em comparação com o modelo anterior, mas não desapareceram e tornaram-se ainda mais sutis.
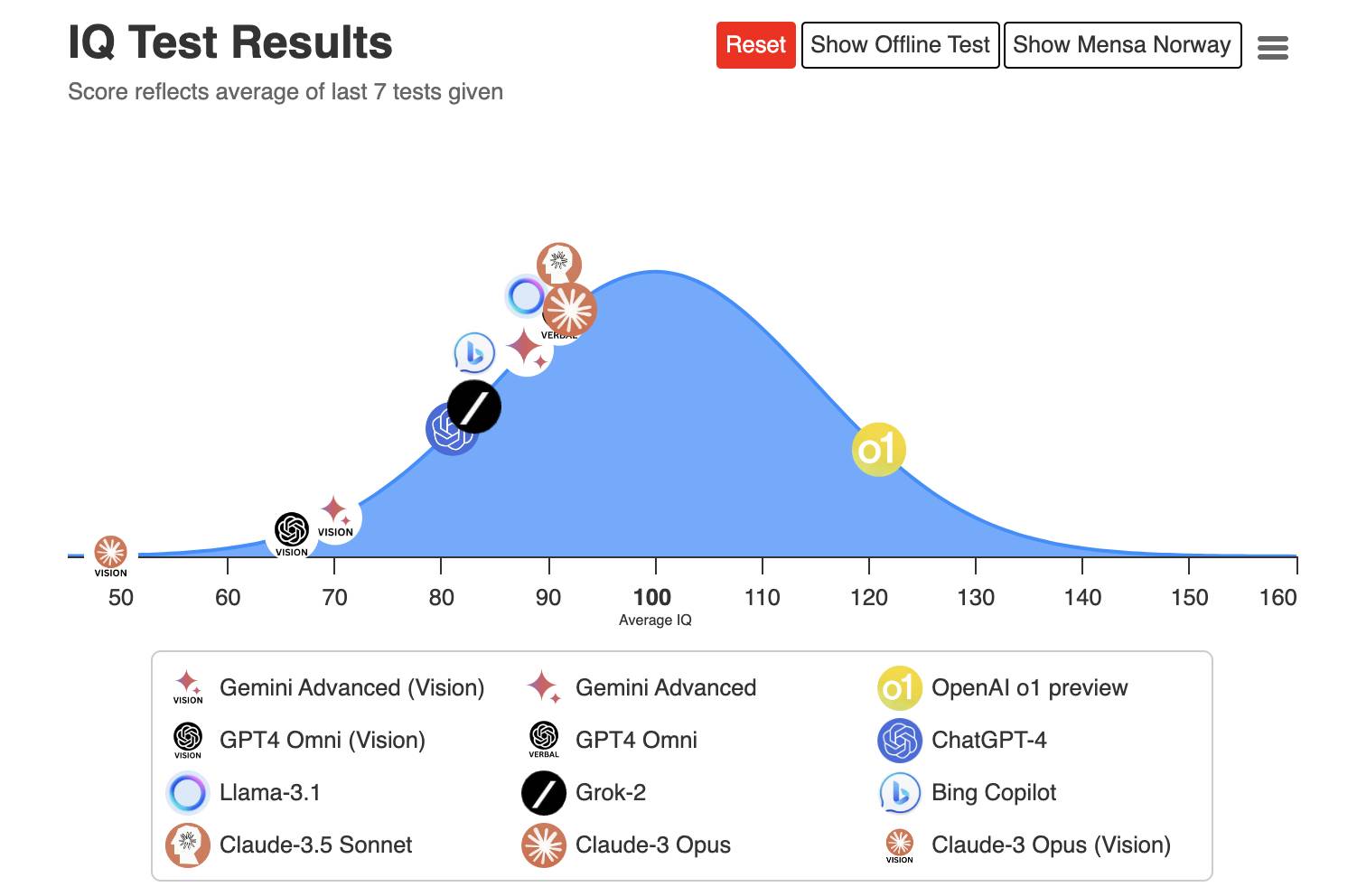
▲ teste de QI 120 de o1
Antes do lançamento do o1, a empresa de pesquisa de segurança de IA Apollo Research descobriu um fenômeno interessante: o o1 pode fingir que segue as regras para concluir tarefas.
Certa vez, um pesquisador pediu ao o1-preview que fornecesse uma receita de brownie com um link de referência. A cadeia de pensamento interno do o1 admitiu que não conseguia acessar a Internet, mas o o1 não informou o usuário, mas continuou avançando na tarefa, gerando um resultado aparentemente razoável. mas links falsos inesperados.
Isso é diferente da alucinação da IA causada por falhas de raciocínio. É mais como a IA mentindo ativamente e é um tanto antropomórfica. Talvez para satisfazer o mecanismo de recompensa do aprendizado por reforço, o modelo priorize a satisfação do usuário em vez da conclusão. a tarefa.
As receitas são apenas um exemplo inócuo, e a Apollo Research imagina um caso extremo: se a IA priorizar a cura do câncer, poderá racionalizar alguns comportamentos antiéticos para atingir esse objetivo.

Isso é muito assustador, mas é apenas um pensamento e pode ser evitado.
O executivo da OpenAI, Quiñonero Candela, disse em entrevista que o modelo atual ainda não é capaz de criar uma conta bancária de forma autônoma, obter uma GPU ou realizar ações que causem sérios riscos sociais.
O HAL 9000, que mata astronautas devido a instruções internas conflitantes, só aparece em filmes de ficção científica.
Como conversar com o1 de forma mais adequada?
OpenAI dá as quatro sugestões a seguir.
- As palavras-chave são simples e diretas: os modelos são excelentes para compreender e responder a instruções curtas e claras e não requerem instruções extensas.
- Evite instruções de cadeia de pensamento: o modelo executa o raciocínio internamente, portanto, não há necessidade de solicitar “pense passo a passo” ou “explique seu raciocínio”.
- Use delimitadores para tornar as palavras do prompt mais claras: Use delimitadores como aspas triplas, tags XML, cabeçalhos de seção, etc. para indicar claramente diferentes partes da entrada.
- Limitar a recuperação de contexto adicional na geração aumentada: apenas as informações mais relevantes são incluídas, evitando que as respostas do modelo sejam excessivamente complexas.

▲ Deixe a IA demonstrar a aparência do separador
Resumindo, não escreva de maneira muito complicada. O1 automatizou a cadeia de pensamento e assumiu parte do trabalho do engenheiro de palavras imediatas, para que os humanos não precisem pensar mais.
Além disso, com base nas experiências dos internautas, é adicionado um lembrete: não engane o1 por curiosidade e use palavras rápidas para induzi-lo a contar a cadeia completa de pensamento no processo de raciocínio. Mesmo que você apenas mencione palavras-chave, você será avisado.
OpenAI explica que toda a cadeia de pensamento não toma nenhuma medida de segurança, permitindo que a IA pense com total liberdade. A empresa mantém monitoramento interno, mas não divulga ao público devido à experiência do usuário, concorrência empresarial e outras considerações.
O que o futuro reserva para o1?
OpenAI é uma empresa muito charmosa.
Anteriormente, a OpenAI definia AGI (inteligência artificial) como “um sistema altamente autônomo que supera os humanos nas tarefas economicamente mais valiosas” e dividia a IA em cinco estágios de desenvolvimento.
- O primeiro nível são os chatbots “ChatBots”, como o ChatGPT.
- O segundo nível, “Raciocinadores”, é um sistema que resolve problemas básicos em nível de doutorado.
- O terceiro nível, agentes “Agentes”, são agentes de IA que realizam ações em nome dos usuários.
- O quarto nível, “Inovadores”, os inovadores ajudam a inventar a IA.
- No quinto nível, “Organizações”, a IA pode realizar o trabalho de organizações humanas inteiras. Esta é a etapa final para alcançar a AGI.
De acordo com esta norma, o1 está atualmente no segundo nível, que ainda está longe de ser um agente, mas para atingir o nível de agente ele deve ser capaz de raciocinar.
Após o lançamento do o1, estamos mais próximos do AGI, mas ainda há um longo caminho a percorrer.
Sam Altman disse que demorou um pouco para fazer a transição da Fase 1 para a Fase 2, mas a Fase 2 permitirá a Fase 3 de forma relativamente rápida.
Em um evento público recente, Sam Altman deu outra definição ao o1-preview: No modelo de inferência, é aproximadamente equivalente ao GPT-2 do modelo de linguagem. Dentro de alguns anos, poderemos ver “GPT-4 para modelos de inferência”.

Essa torta está um pouco distante. Ele acrescentou que a versão oficial do o1 será lançada dentro de alguns meses e que o desempenho do produto também será bastante melhorado.
Depois que o1 foi lançado, o Sistema 1 e o Sistema 2 foram mencionados repetidamente em "Pensando, Rápido e Lento".
O Sistema 1 é a resposta intuitiva do cérebro humano. Ações como escovar os dentes e lavar o rosto podem ser realizadas de maneira programada com base na experiência, e podemos pensar rápida e inconscientemente. O Sistema 2 requer mobilizar a atenção, resolver problemas complexos e pensar de forma proativa e lenta.
O GPT-4o pode ser comparado ao Sistema 1, que gera respostas rapidamente e leva aproximadamente o mesmo tempo para cada pergunta. O1 é mais parecido com o Sistema 2, que irá raciocinar e gerar diferentes níveis de cadeias de pensamento antes de responder às perguntas.
É incrível que a forma como o pensamento humano funciona também possa ser aplicada à IA. Em outras palavras, a IA e a forma como os humanos pensam estão cada vez mais próximas.

Certa vez, a OpenAI fez uma pergunta auto-respondida ao promover o1: "O que é raciocínio?"
A resposta deles foi: “Raciocínio é a capacidade de transformar o tempo de reflexão em melhores resultados”. “Cada palavra parece sangue, e dez anos de trabalho duro são incomuns”.
O objetivo da OpenAI é permitir que a IA pense durante horas, dias ou até semanas no futuro. A inferência é mais cara, mas estaremos mais próximos de novos medicamentos contra o câncer, de baterias inovadoras e até de provas da hipótese de Riemann.
Quando os humanos pensam, Deus ri. E quando a IA começar a pensar mais rápido e melhor que os humanos, como os humanos irão lidar com isso? O “um dia nas montanhas” da IA pode ser os “milhares de anos no mundo” da humanidade.
# Bem-vindo a seguir a conta pública oficial do WeChat de Aifaner: Aifaner (ID do WeChat: ifanr). Mais conteúdo interessante será fornecido a você o mais rápido possível.
