
Como é conectar quatro Mac Studios de última geração e executar duas máquinas DeepSeek simultaneamente por apenas 400.000 yuans?

Há alguns meses, a iFanr implantou com sucesso um modelo local DeepSeek de 671B (versão quantizada de 4 bits) em um Mac Studio com processador M3 Ultra. Se quatro Mac Studios de última geração com processadores M3 Ultra fossem conectados usando ferramentas de código aberto para formar um "cluster de IA de nível desktop", o limite de inferência local poderia ser ainda maior?
Este também é o problema que a Exo Labs, uma startup britânica, está tentando resolver.
Não presuma que a Universidade de Oxford tem um suprimento ilimitado de GPUs
Você pode pensar que uma universidade de ponta como Oxford teria mais GPUs do que pode usar, mas não é bem assim.
Os fundadores da Exo Labs, Alex e Seth, se formaram na Universidade de Oxford. Mesmo em uma instituição tão prestigiosa, o acesso aos clusters de GPU exige meses de espera na fila, e as aplicações só podem ser feitas em uma placa por vez, tornando o processo demorado e ineficiente.
Eles percebem que a atual infraestrutura de IA altamente centralizada marginaliza pesquisadores individuais e pequenas equipes.
Em julho passado, eles lançaram seu primeiro experimento, executando com sucesso o modelo LLaMA usando dois MacBook Pros em conjunto. Embora o desempenho tenha sido limitado, gerando apenas três tokens por segundo, foi suficiente para demonstrar a viabilidade do uso da arquitetura Apple Silicon para raciocínio distribuído de IA.

A virada veio com o lançamento do M3 Ultra Mac Studio. Seus 512 GB de memória unificada, 819 GB/s de largura de banda de memória, uma GPU de 80 núcleos e a capacidade de transferência bidirecional de 80 Gbps do Thunderbolt 5 tornaram os clusters locais de IA uma realidade.
Como é executar dois modelos de 67 bilhões de parâmetros ao mesmo tempo?
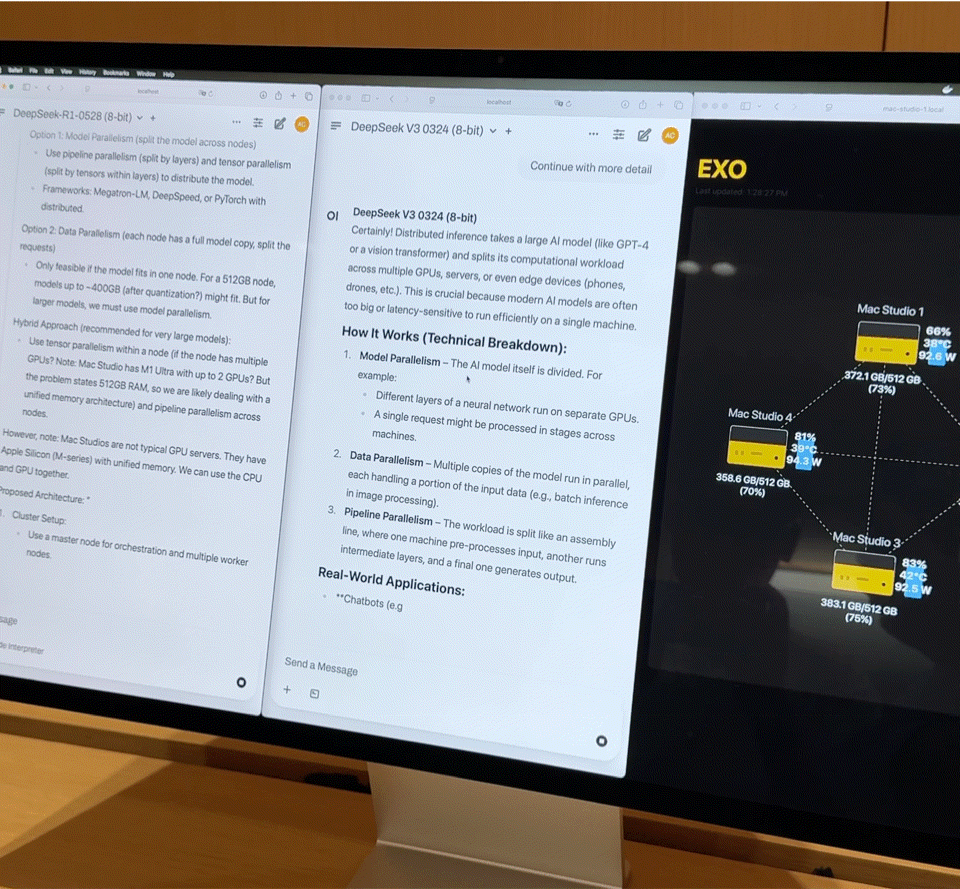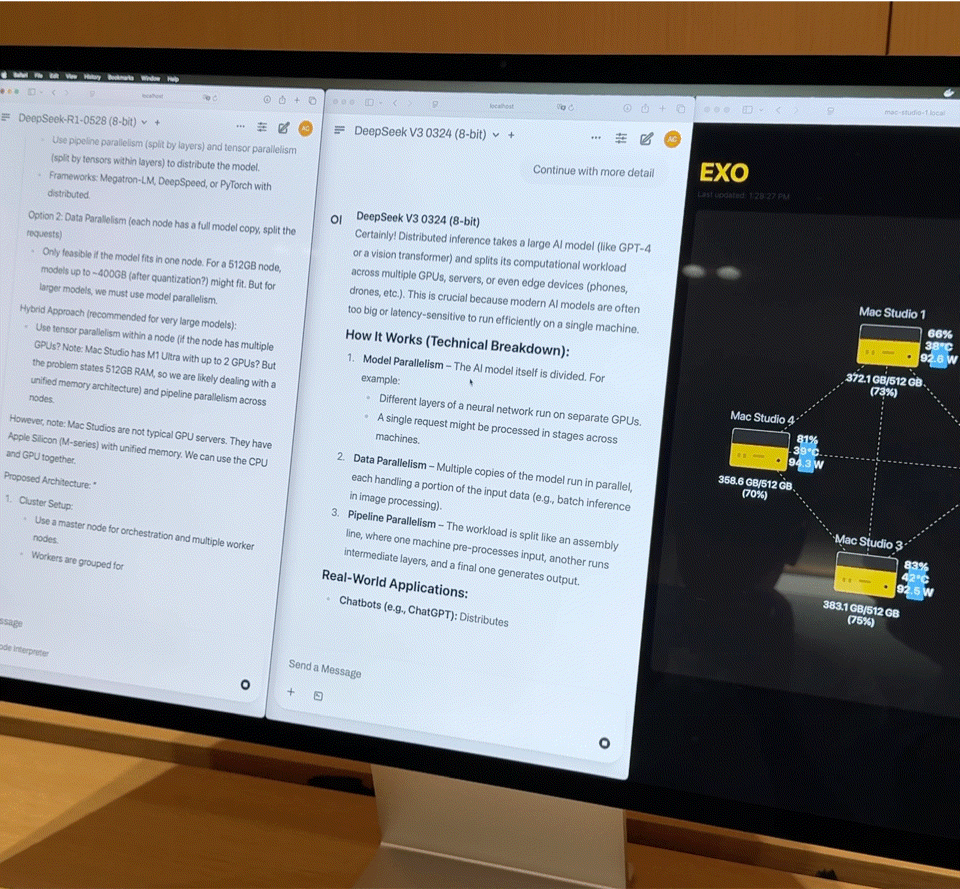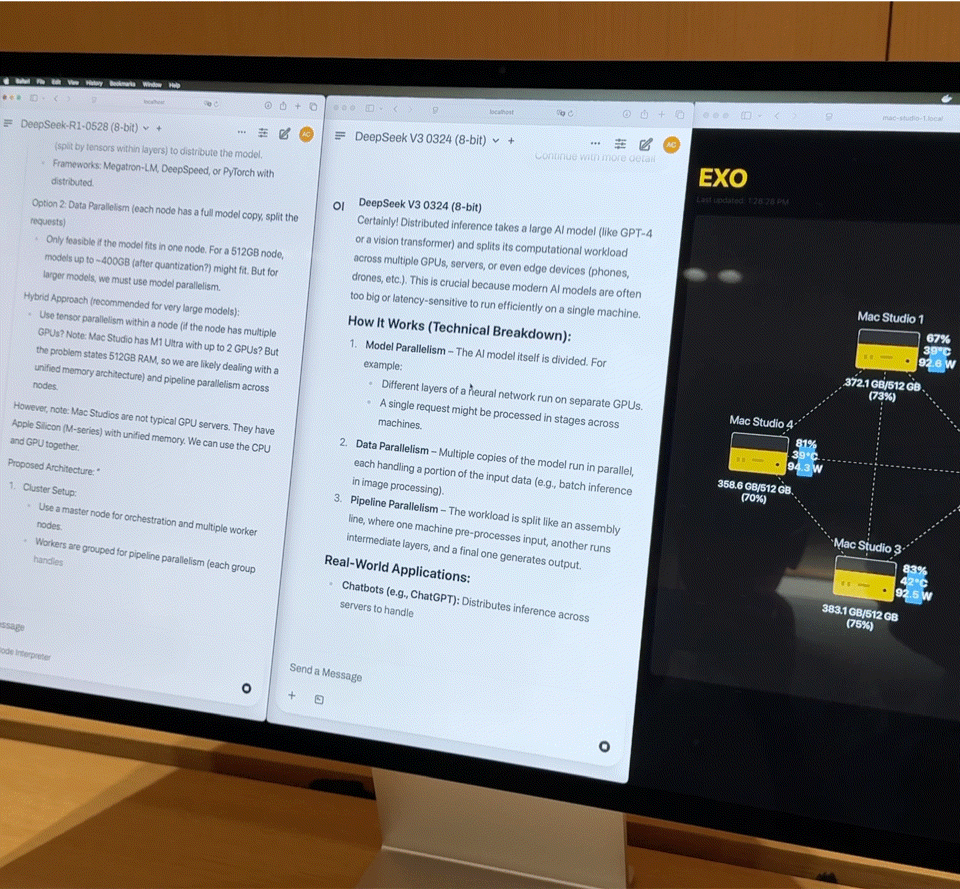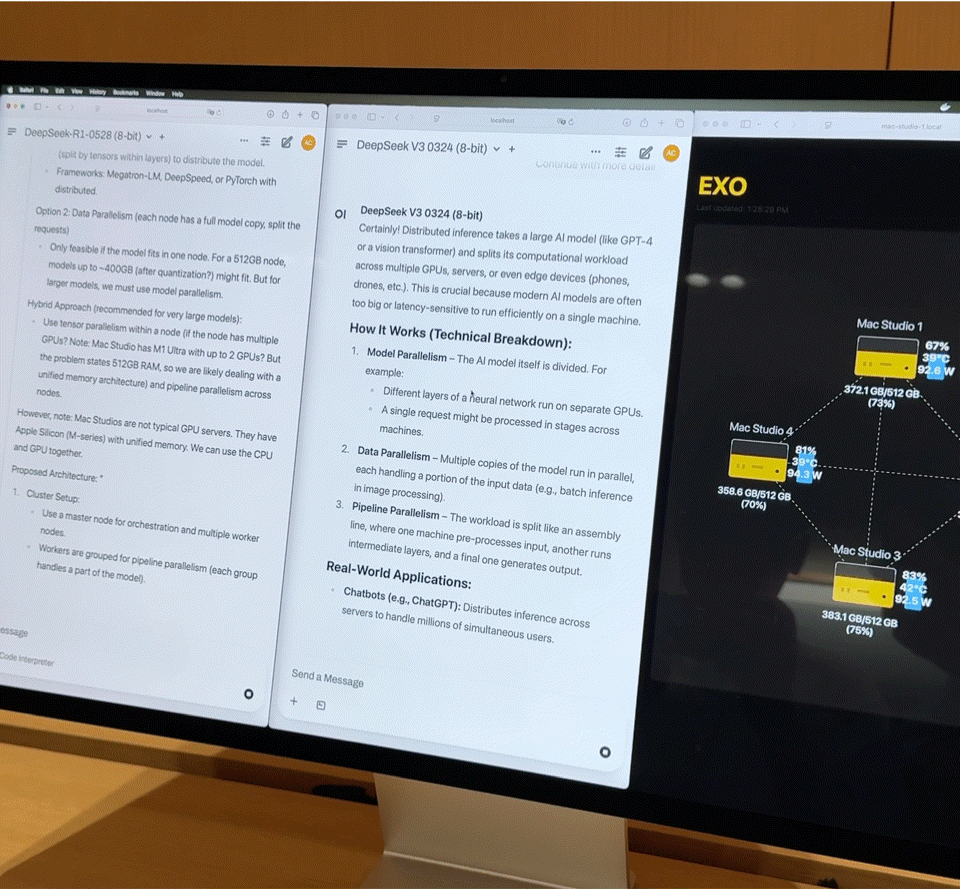
Após conectar quatro Mac Studios de última geração com processadores M3 Ultra via Thunderbolt 5, os números de desempenho são bastante impressionantes:
- CPU de 128 núcleos (32×4)
- 240 núcleos de GPU (80×4)
- Memória unificada de 2 TB (512 GB x 4)
- A largura de banda total da memória excede 3 TB/s
Essa combinação é quase equivalente a um pequeno supercomputador doméstico. No entanto, o hardware é apenas a base; a chave para realmente liberar seu poder está no Exo V2, a plataforma de escalonamento de modelos distribuídos desenvolvida pela Exo Labs. O Exo V2 divide automaticamente o modelo com base na disponibilidade de memória e largura de banda, implantando-o no nó mais apropriado.
No local, o Exo V2 demonstrou os seguintes recursos principais:
- Carregamento de Modelos Grandes: Um modelo DeepSeek completo com quantização de 8 bits requer mais de 700 GB de memória, muito além da capacidade de um único Mac Studio. O Exo divide o modelo entre dois Mac Studio para concluir o processo de carregamento. Uma vez ativado, sua "velocidade de digitação" ultrapassa a velocidade de leitura humana.
- Inferência Paralela: O DeepSeek R1, também com 67 bilhões de parâmetros, foi carregado no DeepSeek V3. O sistema distribuiu imediatamente o R1 para os dois dispositivos restantes, permitindo a inferência paralela de dois modelos grandes e permitindo o questionamento simultâneo por vários usuários.
- Perguntas e respostas sobre documentos privados : Arraste um relatório financeiro da empresa em PDF e o modelo realizará a incorporação de conhecimento e as perguntas e respostas localmente. Ele não depende de nenhum recurso de nuvem, e os dados são totalmente privados e controláveis.
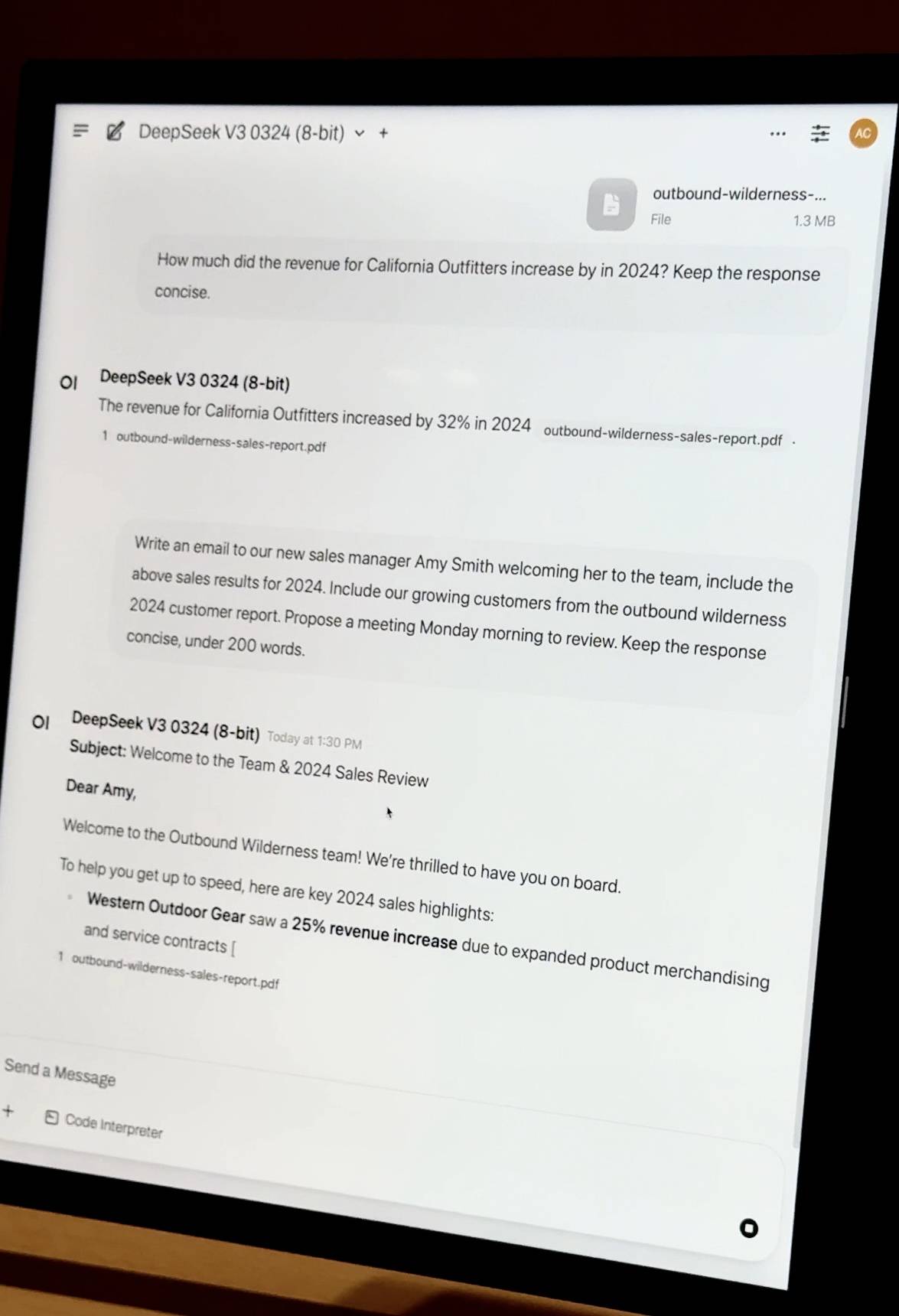
- Ajuste fino simplificado: empresas com milhares de documentos internos podem realizar ajustes finos locais usando a tecnologia QLoRA + LoRA. O ajuste fino de uma única máquina pode levar dias, mas com os recursos de agendamento de cluster do Exo, as tarefas de treinamento podem ser aceleradas linearmente, reduzindo significativamente os custos de tempo.
Grande diferença de custo
O iFanr observou o diagrama de topologia nos bastidores e descobriu que, mesmo se as quatro máquinas estivessem em um estado de alta carga ao mesmo tempo, o consumo de energia de todo o sistema era sempre controlado dentro de 400 W, e quase não havia ruído do ventilador durante a operação.
Para atingir o mesmo desempenho em soluções de servidor tradicionais, são necessárias pelo menos 20 placas gráficas A100. O custo do servidor e do equipamento de rede ultrapassa 2 milhões de RMB, o consumo de energia chega a vários quilowatts e são necessários uma sala de computadores e um sistema de refrigeração independentes.
Os chips da Apple encontraram inesperadamente uma nova posição na onda da IA

O M3 Ultra Mac Studio custa a partir de 32.999 yuans e vem com 96 GB de memória unificada, enquanto a versão topo de linha de 512 GB é realmente cara. No entanto, do ponto de vista técnico, as vantagens da arquitetura de memória unificada são revolucionárias.
Quando a Apple projetou o chip M, ele tinha como principal objetivo a criação pessoal eficiente e com baixo consumo de energia. No entanto, recursos como memória unificada, GPU de alta largura de banda e agregação multipercurso Thunderbolt encontraram inesperadamente um novo nicho na era da IA.
GPUs tradicionais, mesmo as placas de estação de trabalho de última geração, normalmente têm apenas 96 GB de memória de vídeo. A memória unificada da Apple permite que a CPU e a GPU compartilhem a mesma memória de alta largura de banda, eliminando a necessidade de transferências frequentes de dados entre diferentes camadas de armazenamento. Isso é crucial para a inferência de modelos em larga escala.
É claro que a solução EXO também tem um posicionamento distinto. Ela não foi projetada para competir diretamente com o H100, nem para treinar a próxima geração de GPT. Em vez disso, foi projetada para resolver problemas de aplicação prática: executar seus próprios modelos, proteger seus próprios dados e realizar os ajustes e otimizações necessários.
Se o H100 é o rei no topo da pirâmide, então o Mac Studio está se tornando o canivete suíço nas mãos de equipes pequenas e médias.
#Bem-vindo a seguir a conta pública oficial do WeChat do iFaner: iFaner (ID do WeChat: ifanr), onde mais conteúdo interessante será apresentado a você o mais breve possível.