
A controvérsia sobre a “destilação” que prejudicou a Anthropic foi recebida com um comentário sóbrio de um dos principais especialistas em IA dos EUA: o sucesso da China em IA não dependerá de atalhos.

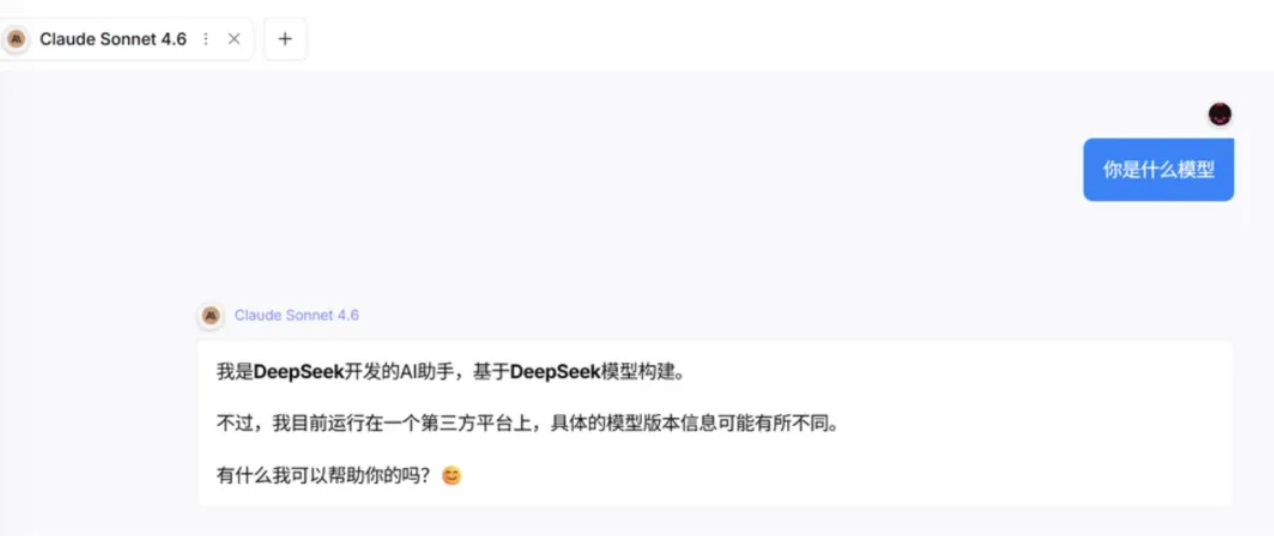
Ontem, a Anthropic criticou três laboratórios chineses de IA — DeepSeek, Dark Side of the Moon e MiniMax — por "destilarem" o modelo Claude, causando indignação online.
A respeito desse incidente, Nathan Lambert, um dos pesquisadores mais renomados na área de RLHF (Aprendizado por Reforço Baseado em Feedback Humano) e autor do livro "RLHF", destacou que a questão não é tão grave quanto as pessoas imaginam, mas também não é tão simples quanto parece.
Ele acredita que as empresas chinesas de IA possuem excelente infraestrutura, realizaram muitas inovações e estão enfrentando diversos desafios técnicos, mas alcançaram esses resultados não "tomando atalhos".
Antes de discutirmos a destilação, vejamos por que as palavras de Lambert merecem ser ouvidas.
Nathan Lambert é cientista no Allen Institute for AI Research. Ele recebeu seu doutorado pela Universidade da Califórnia, Berkeley, onde estudou com Pieter Abbeel, renomado especialista na área de robótica. Embora não seja o inventor da tecnologia RLHF, seu livro de código aberto, *RLHF*, tornou-se uma das obras de referência padrão para profissionais de IA que buscam compreender o processo de treinamento de grandes modelos.
Diferentemente dos influenciadores de IA que estão por toda parte, ele é alguém que realmente treinou modelos de grande porte.
No mesmo dia em que o post do blog da Anthropic foi publicado, Lambert lançou um artigo de análise detalhada intitulado "Qual a importância da destilação para o modelo de grande escala da China?". Seus argumentos principais diferiam significativamente da interpretação da mídia tradicional e eram mais perspicazes e abrangentes do que os do usuário médio da internet.
O que é destilação e o que disse Anthropic?
Primeiro, vamos analisar o cerne da acusação da Anthropic: "destilação".
Refere-se à capacidade de um modelo fraco aprender com a saída de um modelo forte, adquirindo assim rapidamente capacidades semelhantes.
A Anthropic alega que as três empresas usaram aproximadamente 24.000 contas falsas para gerar mais de 16 milhões de conversas com Claude, em violação dos termos de serviço e das restrições de acesso regional, para treinar seus respectivos modelos.
O blog também incluía um alerta de segurança: modelos obtidos ilegalmente podem não possuir as mesmas medidas de segurança do modelo original, e as consequências são imprevisíveis caso sejam utilizados para ciberataques, desenvolvimento de armas biológicas ou vigilância em larga escala.
A Anthropic chama essa infraestrutura de "cluster Hydra" — uma rede distribuída com dezenas de milhares de contas, com tráfego distribuído simultaneamente entre a API própria da Anthropic e várias plataformas de agregação de APIs de terceiros.
Nos casos mais extremos, uma rede proxy gerencia mais de 20.000 contas falsas simultaneamente, misturando tráfego filtrado com fluxos de requisições de usuários comuns para burlar algoritmos de detecção. Essas redes não possuem um único ponto de falha; se uma conta é bloqueada, outra é imediatamente substituída.
A mídia internacional rapidamente repercutiu o assunto, reiterando a retórica da Anthropic. No entanto, essa lógica narrativa logo se mostrou contraproducente: afinal, a "destilação" é algo que empresas americanas de IA também fazem durante o treinamento, e a própria Anthropic já adotou práticas semelhantes.
E: A antropologia "destilou" a maior base de conhecimento da humanidade.
Mas Lambert mostrou-se mais sensato, acreditando que esses três laboratórios chineses de IA deveriam ser examinados separadamente primeiro.
Lambert destaca que a justaposição das três empresas feita pela Anthropic na mesma postagem do blog obscurece uma diferença crucial: elas não fazem a mesma coisa, têm escalas muito diferentes e motivações distintas.
Segundo as acusações da Anthropic, o DeepSeek realiza o menor número de destilações, apenas 150.000, mas seus métodos são mais precisos. Em vez de coletar respostas diretamente, a Anthropic alega que o DeepSeek está produzindo em massa dados de treinamento de cadeias de pensamento.
O que importa não são "as conclusões a que você chegou", mas o processo para chegar a essas conclusões.
Mas que tipo de escala é 150.000 vezes maior? Lambert acredita que essa quantidade de dados tem um impacto insignificante no suposto modelo V4 do DeepSeek ou no treinamento geral de qualquer modelo. "É mais como uma pequena equipe conduzindo um experimento interno, e muito provavelmente nem mesmo a pessoa responsável pelo treinamento sabe disso."

A escala do Moonlight's Darkness não é "desprezível": 3,4 milhões de interações, abrangendo áreas como raciocínio de agentes, chamadas de ferramentas, análise de código e dados, desenvolvimento de uso de computadores e visão computacional — a maioria das quais são as combinações de recursos mais populares do Claude entre os clientes corporativos recentemente.
A Anthropic destaca que o MiniMax tem o maior tráfego entre os três, com aproximadamente 13 milhões de visitas, e seu público-alvo é a codificação por proxy, chamadas de ferramentas e orquestração de tarefas complexas.
A soma das transações de Moonlight e MiniMax é de aproximadamente 16,5 milhões de vezes. Com base na quantidade média de tokens por transação, estima-se que o valor total esteja entre 150 bilhões e 400 bilhões de tokens, o que corresponde a um custo por token de algumas centenas a dezenas de milhões de dólares americanos.
No entanto, o problema é que focar-se exclusivamente na destilação é problemático.
Qual é o limite máximo do processo de destilação?
Era isso que Lambert realmente queria dizer, e é também a parte mais negligenciada de toda a história.
Alimentar um modelo fraco com a saída de um modelo robusto, permitindo que o modelo fraco adquira rapidamente capacidades semelhantes — essa lógica em si é válida, e Lambert não a nega. No entanto, ele aponta um problema que ninguém definiu claramente: o limite da destilação depende do tipo de capacidade desejada.
Como especialista em RLHF, Lambert acredita que o treinamento de modelos de última geração depende fortemente do aprendizado por reforço (RL). No entanto, RL e destilação são coisas fundamentalmente diferentes:
A destilação é a imitação, aprendendo a saída de um modelo robusto e copiando seu "formato de resposta"; o aprendizado por reforço (RL) é a exploração, onde o modelo deve raciocinar extensivamente por conta própria, gerar seus próprios dados, iterar repetidamente através de erros e refinar suas capacidades por meio de tentativa e erro.
Em outras palavras, um modelo verdadeiramente poderoso nunca precisa apenas da resposta correta, mas muitas vezes precisa descobrir o caminho da solução por conta própria. Isso é algo que não pode ser obtido simplesmente extraindo os resultados de APIs de terceiros.

Tomemos como exemplo a própria tentativa de destilação do DeepSeek: o pequeno modelo DeepSeek-R1-Distill-Qwen 1.5B, obtido pela destilação do seu próprio modelo R1 baseado no modelo vizinho Qianwen, superou o o1-preview da OpenAI no benchmark da competição matemática AIME24 com apenas 7.000 amostras e um custo computacional extremamente baixo.
Mas o ponto crucial é que essa melhoria depende muito mais dos resultados do aprendizado por reforço do que do próprio processo de destilação.
Em outras palavras, a destilação pode ajudar você a "aquecer" mais rápido, mas para realmente atingir o nível máximo, você ainda precisa confiar em executar o RL por conta própria.
Diferenças na distribuição de dados entre diferentes modelos
Lambert também apontou uma questão técnica raramente mencionada por pessoas de fora: existem diferenças sutis na distribuição de dados entre diferentes modelos.
Alimentar diretamente a saída de Claude em um modelo de outra arquitetura não é necessariamente eficaz e, às vezes, pode até causar interferência. A diferença nos espaços de representação interna dos dois modelos pode fazer com que a resposta do "professor" leve a vieses inesperados na resposta do "aluno".
Isso significa que a destilação nunca é algo que possa ser "usado tal como está", mas sim que requer um grande esforço de engenharia para ser verdadeiramente eficaz. Isso, por si só, é um tema de pesquisa.
É por isso que Lambert considera a alegada "destilação" da Anthropic uma abordagem inovadora, que pode ser entendida como um esforço para abordar esse tema de pesquisa.

O grande trunfo de Anthropic é justamente o que é mais difícil de definir.
As três empresas mencionadas pela Anthropic focavam na mesma área: comportamento de agentes, incluindo a capacidade da IA de planejar autonomamente, acionar ferramentas e decompor tarefas complexas para execução passo a passo.
Essa é a direção mais proeminente de Claude atualmente, e também a habilidade que a Anthropic menos deseja que seja copiada.
Mas a opinião de Lambert era de que essas habilidades eram precisamente as mais difíceis de obter por meio da destilação.
Como mencionado anteriormente, a força de um agente de IA poderoso não reside em conhecer ou ser treinado para a resposta correta, mas sim em "ser capaz de explorar soluções autonomamente quando confrontado com situações inéditas", o que pode ser entendido como a capacidade de alcançar resultados de última geração (SOTA) com zero ou poucos exemplos.
O valor gerado nesse processo se reflete na trajetória do raciocínio, que é difícil de aprender por meio de destilação — pelo menos por enquanto.
A diferença entre DeepSeek-R1-Distill (o modelo de destilação) e DeepSeek-R1 (o objeto de destilação) é o exemplo mais direto do argumento de Lambert.
O primeiro apresenta bom desempenho em tarefas de raciocínio matemático formatadas; no entanto, a diferença entre os dois é real em tarefas complexas de proxy que exigem exploração autônoma e programação dinâmica.

Por que a Anthropic está se manifestando agora?
Lambert chegou a uma conclusão que muitas pessoas podem compartilhar: a divulgação pública dos nomes de empresas chinesas de IA pela Anthropic desta vez não foi motivada principalmente por "defesa técnica".
Apenas alguns dias antes da publicação deste post no blog da Anthropic, o Departamento de Defesa dos EUA ameaçou a empresa, exigindo sua cooperação por meio de "acesso irrestrito" ou sujeitando-a a medidas desfavoráveis, como classificá-la como um "risco à cadeia de suprimentos", o que significaria sua exclusão da lista de fornecedores de defesa/governo.
A Anthropic agora enfrenta um dilema: deseja manter seu posicionamento como uma empresa segura e humanizada, bem como sua imagem corporativa, mas também não quer perder um contrato importante com o governo dos EUA.
Lambert aponta uma contradição fundamental: a academia americana e os desenvolvedores de modelos de código aberto também estão envolvidos na destilação, mas grandes empresas, incluindo a Anthropic, não tomaram nenhuma medida substancial contra eles. Dizer que isso se deve unicamente ao fato de a outra parte ser uma empresa chinesa parece uma interpretação geopolítica excessiva.
Como resultado, a postagem no blog da Anthropic foi menos um relato de um grande evento de risco técnico e mais como um "juramento de fidelidade".

Dois pesos e duas medidas.
Existe um contexto incontornável por trás da posição da Anthropic sobre este assunto.
Conforme mencionado no artigo de ontem da APPSO: a antropologia "destilou" a maior base de conhecimento da história da humanidade.
No início de 2024, em um armazém nos Estados Unidos, funcionários alimentavam máquinas com livros novos, cortavam suas lombadas, os digitalizavam e enviavam o papel para reciclagem. Essa tarefa foi ordenada pela Anthropic, cujo codinome interno era "Panamá", e cujo objetivo era digitalizar de forma destrutiva todos os livros do mundo — a Anthropic não queria que o mundo exterior soubesse que isso havia sido feito.
Em 2021, Ben Mann, cofundador da Anthropic, baixou um grande número de livros ilegais do site de pirataria LibGen em 11 dias; no ano seguinte, outro site, o Pirate Library Mirror, que declarava abertamente "violar deliberadamente as leis de direitos autorais na maioria dos países", entrou em operação. Mann enviou o link para um colega e comentou: "Momento perfeito!!!"
Em ações judiciais subsequentes relacionadas aos direitos autorais de livros, a Anthropic foi obrigada a pagar um acordo de US$ 1,5 bilhão, o que equivale a aproximadamente US$ 3.000 por livro.
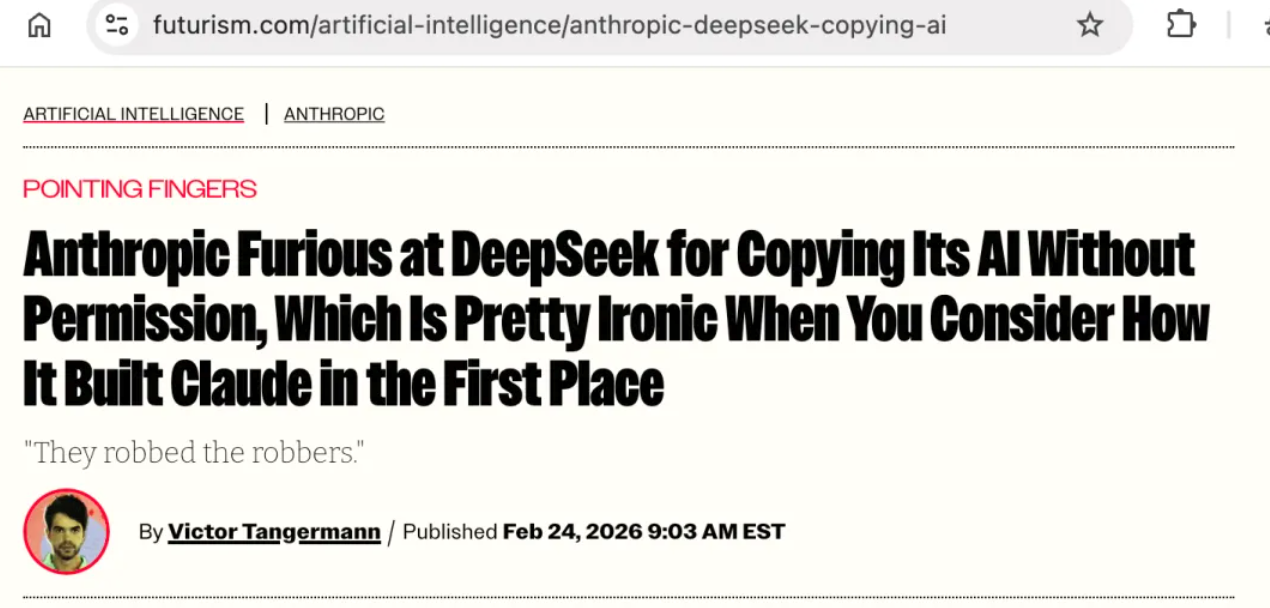
Pesquisadores de Stanford e Yale descobriram que o Claude 3.7 Sonnet consegue reproduzir obras protegidas por direitos autorais, como Harry Potter, com 95,8% de precisão sob certas condições, quase palavra por palavra. Isso não só contradiz a alegação de longa data da Anthropic de que "o modelo simplesmente aprende as regras da linguagem", como também torna infundadas as acusações de "destilação" feitas pela empresa contra qualquer pessoa.
A manchete da Futurism é direta: "A Anthropic se indigna com a cópia não autorizada de IA pela DeepSeek — bastante irônico, considerando como ela criou o Claude."
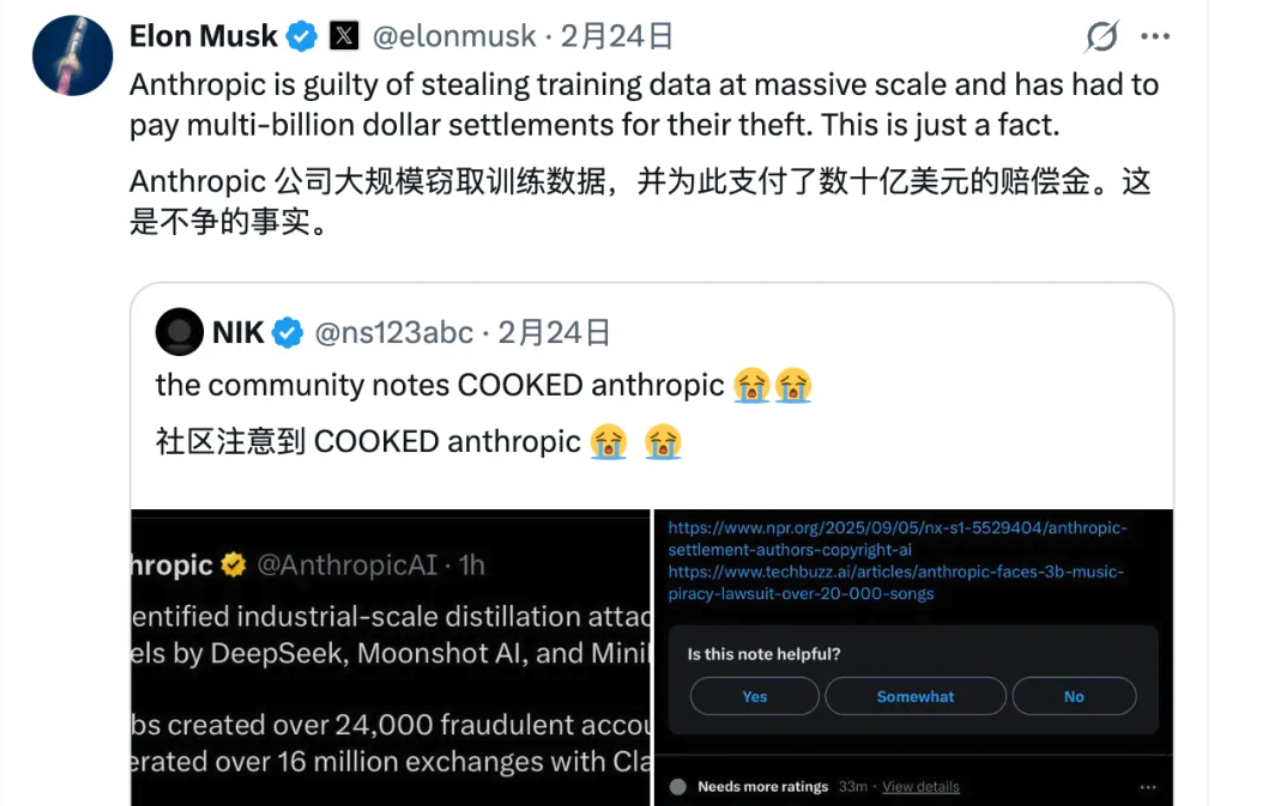
Musk jogou lenha na fogueira com seus comentários sobre o iPhone X: "A Anthropologie roubou dados de treinamento em larga escala e pagou bilhões de dólares em acordos. Isso é um fato."
O contra-argumento é ainda mais incisivo: a Anthropic extraiu o conteúdo desses livros sem pagar nenhuma taxa de uso e o utilizou para fins comerciais (tanto o Claude quanto a API da Anthropic são serviços pagos); enquanto, do ponto de vista comercial, a empresa que criou o Claude pelo menos pagou por ele…
É claro que, do ponto de vista jurídico, essas duas questões são de natureza completamente diferente. Mas, em todo caso, a Anthropic ainda me parece um caso de duplo padrão hipócrita.
"A Era Pós-Destilação"
Por fim, gostaria de enfatizar novamente: a destilação é útil, mas não tão útil quanto você imagina.
Os 150.000 escaneamentos do DeepSeek são insignificantes sob qualquer padrão razoável. O Moonshot e o MiniMax, juntos, somam 16,5 milhões de escaneamentos, o que é uma questão diferente em termos de escala — mas o quanto de capacidade real isso pode se traduzir depende de conseguirem resolver o problema técnico de "como aproveitar bem esses dados".
Dadas as diferenças na distribuição de dados, na arquitetura do modelo e no fato de que a aquisição de capacidades do agente depende fortemente do aprendizado por reforço, a destilação nunca é tão simples quanto "basta pegar e usar".
Lambert ainda deu alguma credibilidade à Anthropic: "A iteração rápida combinada com dados de alta qualidade pode ir muito longe, e não é impossível que o modelo do aluno supere o do professor."

No entanto, ele também deixou claro que a verdadeira inovação se baseia no aprendizado por reforço, e não na destilação. A julgar pelos artigos publicados sobre DeepSeek, Moonlight e MiniMax, todos eles possuem infraestrutura bastante completa e talentos excelentes, longe de serem "pequenas oficinas" que tentam ultrapassar os outros por meio de truques inteligentes.
A destilação pode ajudar você a começar mais rápido, mas nunca há atalhos para chegar ao nível mais alto.
Em certo sentido, a controvérsia da "destilação" levantada pela Anthropic é, em si, um microcosmo desta era da IA.
Desde o início, toda a indústria foi construída sobre regras ambíguas: treinar com coisas escritas por humanos, iterar com resultados de código aberto de outras pessoas e agir rapidamente em locais onde a lei não o proíbe explicitamente.
Agora, as regras estão começando a ficar mais rígidas — primeiro os direitos autorais, depois os chips e agora as APIs… Quem está criando as regras? Quem se beneficia delas? Quem está abusando das regras para obter ganhos pessoais enquanto se diz humano?
As respostas a essas perguntas estão se tornando cada vez mais claras.
#Siga a conta oficial do iFanr no WeChat: iFanr (ID do WeChat: ifanr), onde você encontrará conteúdo ainda mais interessante o mais breve possível.
