
ChatGPT e Claude receberam grandes atualizações simultaneamente; aqueles que não conseguirem dominar a IA serão eliminados.
Neste exato momento, ocorreu uma "colisão entre Marte e a Terra" no círculo da Inteligência Artificial do Vale do Silício.
Como se tivessem combinado previamente, a OpenAI e a Anthropic lançaram simultaneamente suas principais atualizações: Claude Opus 4.6 e GPT-5.3-Codex.
Se até ontem à noite estávamos discutindo "como escrever boas instruções para auxiliar no trabalho", hoje de manhã talvez tenhamos sido obrigados a aprender "como gerenciar funcionários de IA como chefes".

A IA cria IA e, por acaso, assume o controle do seu computador.
Ainda ontem, Sam Altman comemorou a marca de "um milhão de usuários ativos" do Codex na plataforma X. Apenas um dia depois, a OpenAI lançou outra bomba: o GPT-5.3-Codex.
A documentação técnica contém uma afirmação muito significativa: "Este é o primeiro modelo que desempenhou um papel fundamental em nosso próprio processo de criação."
Em termos simples, isso significa que a IA aprendeu a escrever seu próprio código, encontrar erros sozinha e até mesmo começou a treinar a próxima geração de IA. Essa capacidade de autoevolução se reflete diretamente em uma série de resultados de testes de desempenho.
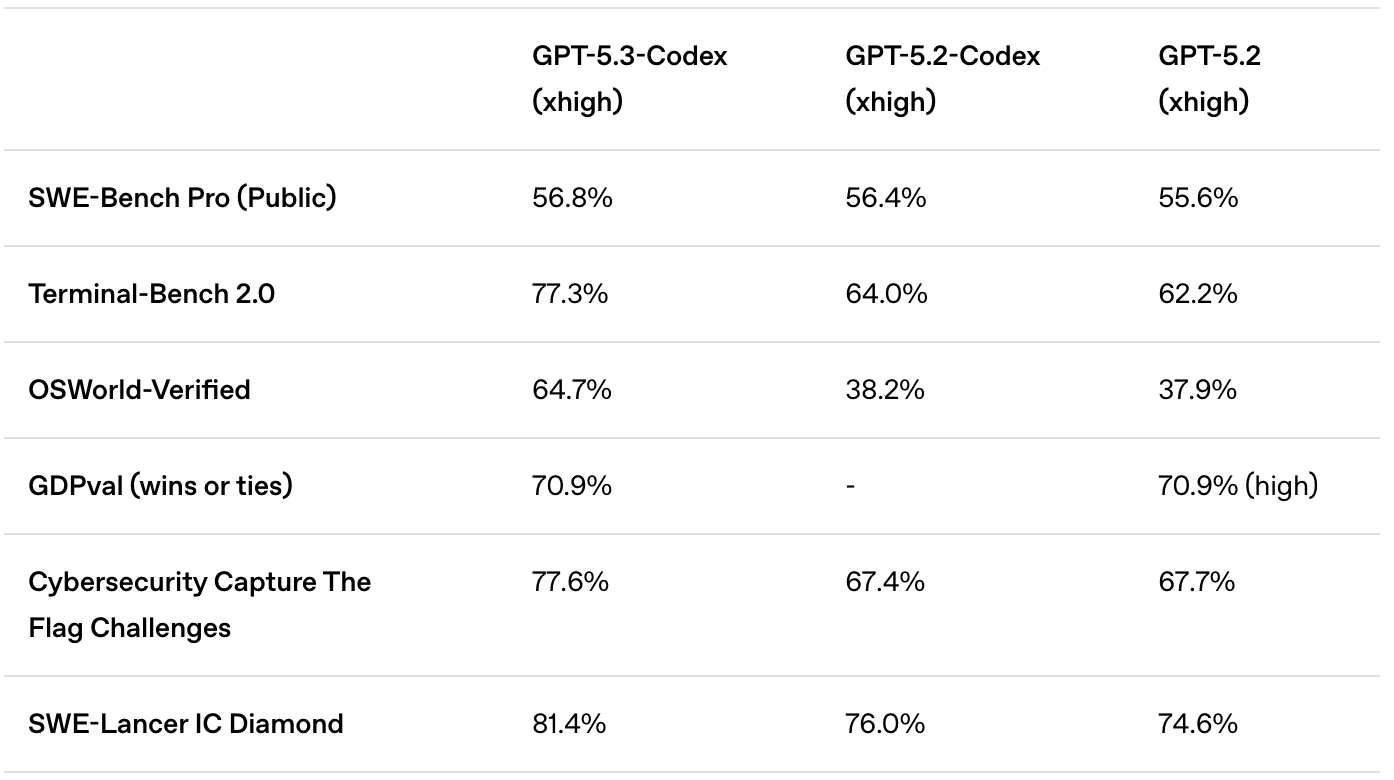
Lembra-se do teste de benchmark OSWorld-Verified que simula a operação humana de um computador? O modelo anterior tinha uma precisão de apenas 38,2%, o que nem sequer atingia a nota mínima para aprovação.
Mas desta vez, o GPT-5.3-Codex saltou para 64,7%!
Vale ressaltar que o nível médio de proficiência de um ser humano é de apenas 72%. Isso significa que a IA está muito perto de ser tão habilidosa quanto você no uso do mouse, na troca de telas e na operação de softwares.
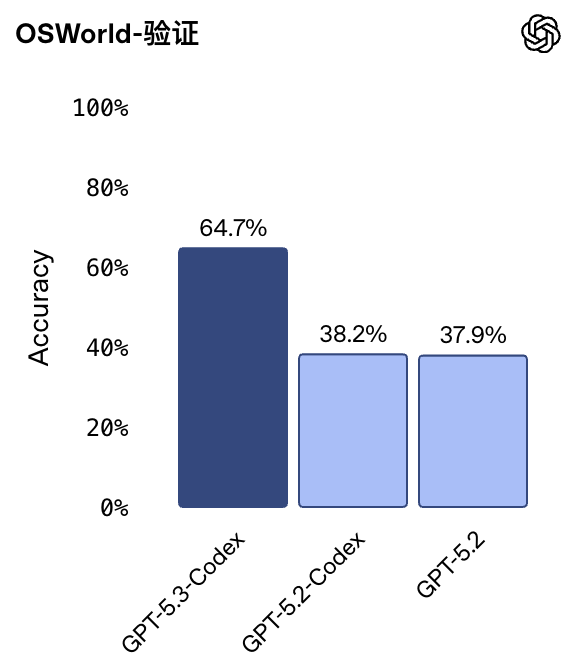
No Terminal-Bench 2.0 (operação por linha de comando), alcançou uma alta pontuação de 77,3%, superando em muito o GPT-5.2 (62,2%).
O renomado benchmark SWE-Bench Pro abrange quatro linguagens de programação, não só é resistente à contaminação, como também enfrenta desafios de engenharia complexos do mundo real.
O GPT-5.3-Codex não só alcançou desempenho de última geração (SOTA), como também utilizou menos tokens do que qualquer modelo anterior. O que isso significa? Significa que ele não só funciona incrivelmente rápido, como também resolve problemas de forma mais rápida e eficiente do que os humanos.
A OpenAI demonstrou inclusive sua capacidade de construir de forma independente:
Em poucos dias, eles construíram do zero uma versão 2.0 de um jogo de corrida com vários mapas e também conseguiram criar um jogo de mergulho em águas profundas que gerencia um sistema de oxigênio.
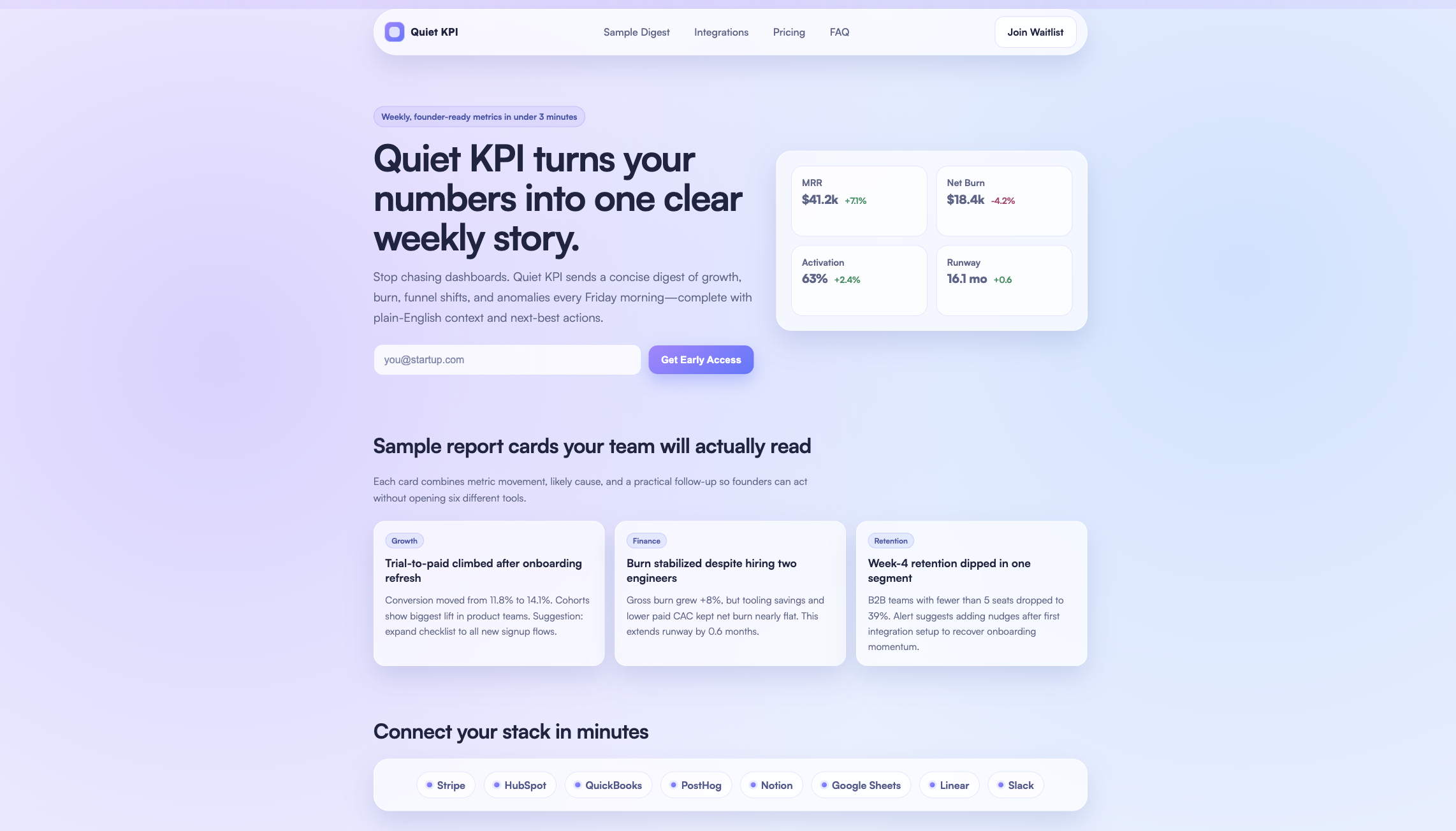
O que mais me impressionou foi a compreensão de intenções ambíguas por parte do GPT-5.3-Codex.
Ao criar a página de destino "Quiet KPI", o programa converteu automaticamente o "plano anual" no "preço mensal com desconto" e até adicionou, de forma inteligente, um carrossel de avaliações de usuários — tudo isso sem que você precisasse dar nenhuma instrução.

As ambições da OpenAI estão estampadas em sua fachada: a Microsoft costumava dizer que a IA se tornaria a copilota dos humanos, mas agora a IA quer ser o motorista que pode assumir o controle do volante e até mesmo consertar o carro sozinho.
Ah, e tem mais um detalhe interessante.
Anteriormente, havia rumores de que a OpenAI tinha reservas quanto aos chips de IA da NVIDIA, mas desta vez o blog oficial enfatizou especificamente que o projeto, o treinamento e a implementação do GPT-5.3-Codex foram concluídos no sistema NVIDIA GB200 NVL72.
Essa demonstração de alta inteligência emocional, um "obrigado, Nvidia", realmente deu muita credibilidade a Huang Renxun.

Dando adeus às "memórias de peixinho dourado", Claude protagonizou um retorno triunfal.
Quase simultaneamente ao lançamento do GPT-5.3-Codex, a Anthropic também apresentou seu próprio pacote de presentes para o Ano Novo Chinês.
A má notícia é que o tão aguardado modelo "médio" do Claude Sonnet não foi atualizado; mas a boa notícia é que a Anthropic apresentou diretamente a versão "superdimensionada" – o Claude Opus 4.6.
Em comparação com a abordagem agressiva da OpenAI em relação à "ação", o Claude Opus 4.6 da Anthropic, lançado hoje, concentra-se na "capacidade de raciocínio" e na "usabilidade".

Muitos usuários corporativos enfrentam um problema chamado "Context Rot" (Deterioração de Contexto): o sistema alega suportar 200 mil contextos, mas quando uma grande quantidade de dados é inserida, a IA começa a se concentrar no início e não no fim.
Desta vez, os dados apresentados pelo Claude Opus 4.6 são simplesmente um "divisor de águas".
No teste MRCR v2 (Long Text Needle in a Haystack), o Claude Opus 4.6 alcançou uma taxa de recall de 76%.
Em contraste, a geração anterior do Sonnet 4.5 apresentava um índice lamentável de 18,5%. De certa forma, isso representa um salto qualitativo, passando de praticamente inutilizável para "altamente confiável".
Esta é a primeira vez que o Claude Opus 4.6 introduz uma janela de contexto de 1M verdadeiramente utilizável.
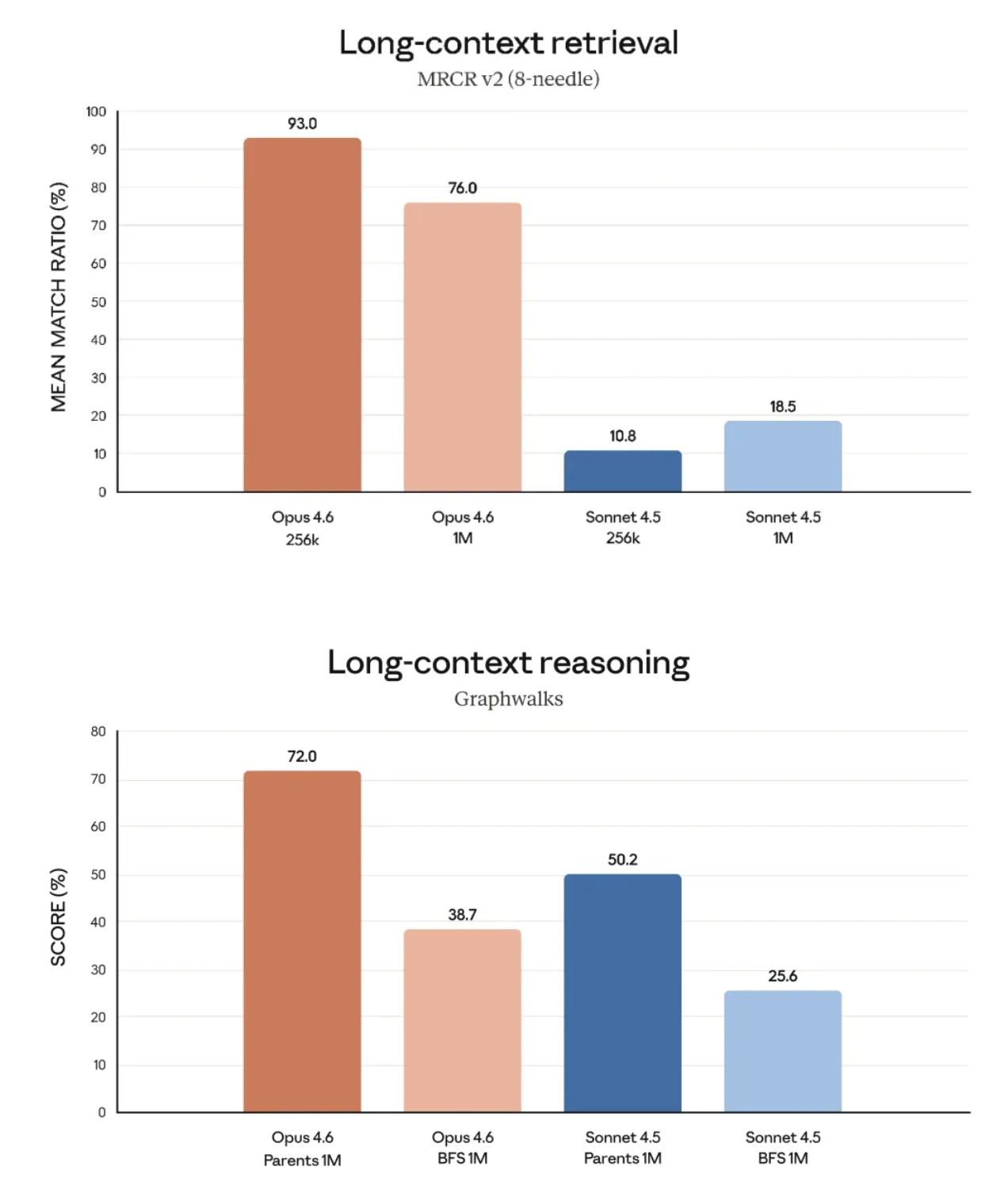
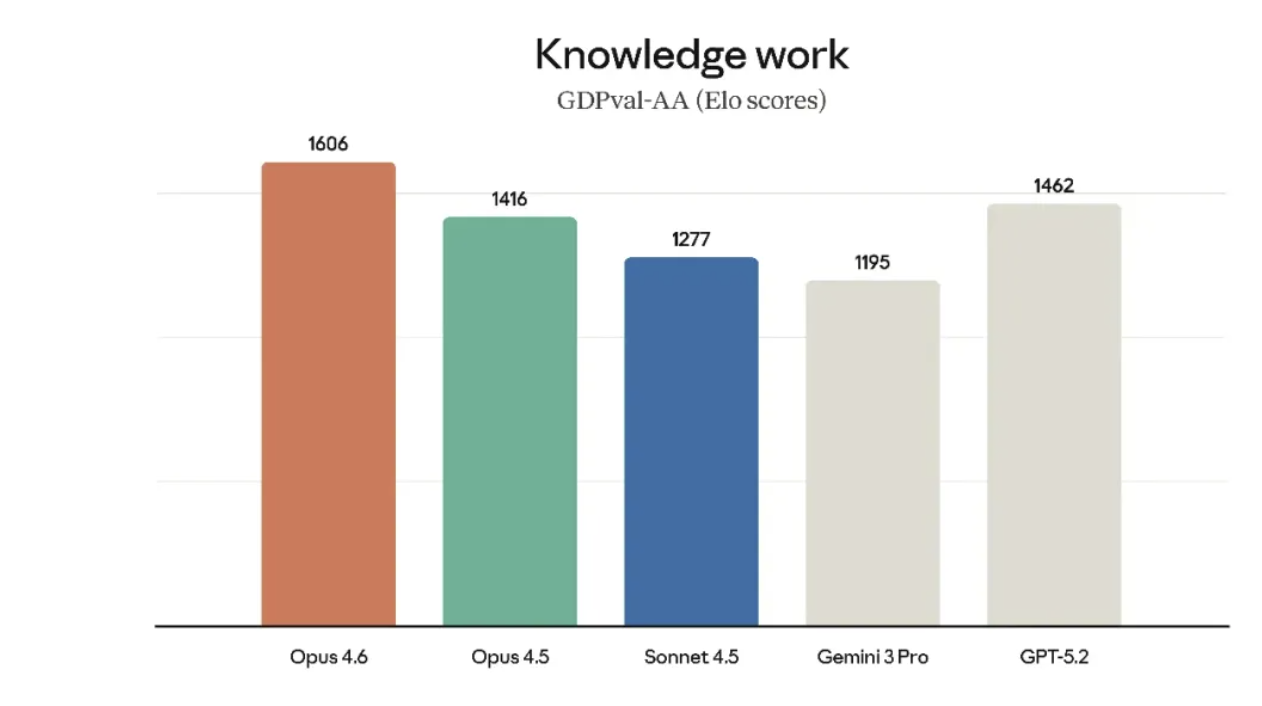
O que isso significa? Significa que você pode jogar centenas de páginas de relatórios financeiros ou centenas de milhares de palavras de código diretamente nele, e ele não só conseguirá ler tudo, como também lhe dirá com precisão que há um problema com o número na nota de rodapé da página 342.
O que realmente chamou a atenção dos trabalhadores foi sua função de aumentar a produtividade.
Por um lado, a Anthropic agora integrou o Claude diretamente ao Excel e ao PowerPoint. Ele pode gerar apresentações em PowerPoint diretamente a partir de dados do Excel, preservando não apenas o estilo do layout, mas também alinhando fontes e modelos. No ambiente de colaboração Claude Cowork, ele pode até mesmo realizar multitarefas de forma autônoma.
Por outro lado, a Anthropic aproveitou a oportunidade para lançar um recurso experimental de Equipes de Agentes no Claude Code, permitindo que desenvolvedores comuns experimentassem a sensação de "comandar milhares de tropas":
- Divisão de funções: Você pode designar uma sessão do Claude como Líder da Equipe, que não realiza o trabalho braçal e é especificamente responsável por dividir tarefas, atribuir ordens de serviço e mesclar código; as outras sessões são membros da equipe (Teammates), cada uma assumindo tarefas para realizar.
- Operação independente: Cada membro da equipe possui uma janela de contexto independente (sem necessidade de se preocupar com a explosão de tokens), e eles podem até mesmo enviar mensagens uns aos outros sem o seu conhecimento (mensagens entre agentes) para discutir detalhes técnicos e, por fim, reportar os resultados apenas ao líder da equipe.
- Corrida de cavalos paralela: qual a utilidade disso? Imagine verificar um bug persistente. Você pode gerar 5 agentes para verificar 5 hipóteses diferentes, como uma "corrida de cavalos" para limpar a mina em paralelo; ou, durante a revisão de código, você pode ter um membro da equipe atuando como "especialista em segurança" para verificar vulnerabilidades e outro como "arquiteto" para verificar o desempenho, sem interferir um no trabalho do outro.
Para demonstrar as limitações do Opus 4.6, o pesquisador antropológico Nicholas Carlini conduziu um experimento ousado: Equipes de Agentes.
Em vez de escrever o código ele mesmo, ele disponibilizou US$ 20.000 em créditos de API, permitindo que 16 usuários do Claude Opus 4.6 formassem uma "equipe de desenvolvimento de software totalmente automatizada".
Em apenas duas semanas, esse grupo de IAs realizou de forma autônoma mais de 2.000 sessões de programação e escreveu um compilador da linguagem C (baseado em Rust) com 100.000 linhas de código do zero.
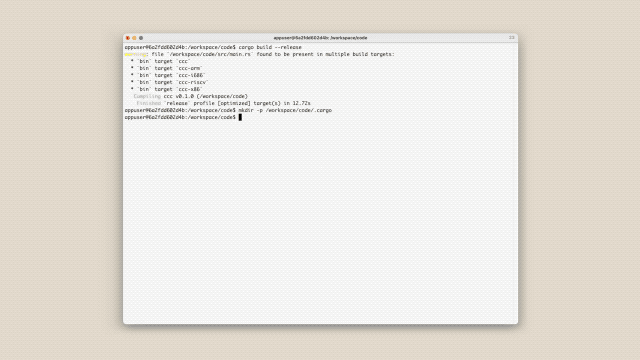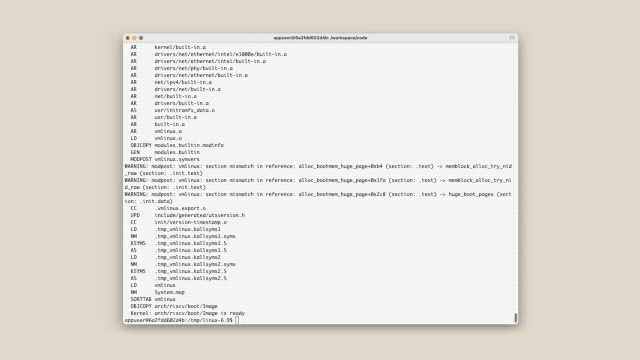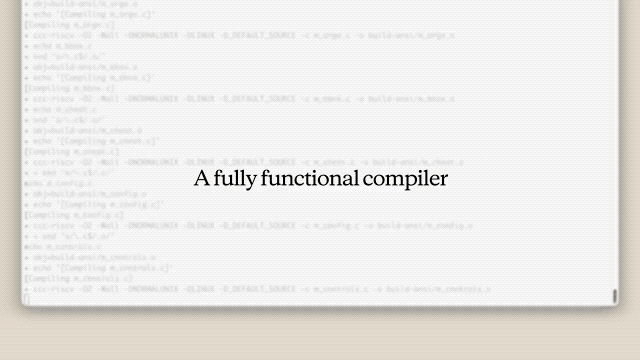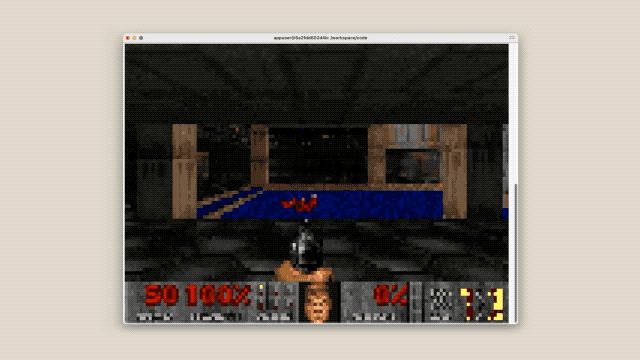
Este compilador escrito por IA também compilou com sucesso o kernel do Linux 6.9 (abrangendo as arquiteturas x86, ARM e RISC-V) e até mesmo executou o jogo Doom.
Embora não seja perfeito (por exemplo, o código gerado não é tão eficiente quanto o GCC), este caso demonstra que não estamos mais programando com IA, mas sim observando uma equipe de IA colaborar, depurar e avançar o projeto de forma autônoma.
Além disso, aprendeu o Pensamento Adaptativo, que lhe permite decidir "quanto tempo pensar" com base no nível de dificuldade. Com a adição de um novo controle de "intensidade inteligente", você pode alternar entre quatro níveis, de Baixo a Máximo.
Em termos de preços, a Anthropic tem sido bastante generosa desta vez, mantendo um preço base de US$ 5/US$ 25 por milhão de tokens. Parece determinada a competir diretamente com a OpenAI no mercado corporativo.
Um é um gênio radical, o outro é uma velha vaca confiável.
O renomado especialista em IA, Dan Shipper, realizou um teste cego (Vibe Check) imediatamente, e sua avaliação foi notavelmente precisa:
Claude Opus 4.6 caracteriza-se por "Alto Teto, Alta Variância".
É como um gênio brilhante, mas ocasionalmente excêntrico. Nos testes, resolveu diretamente um problema de funcionalidade que havia intrigado a equipe do iOS por dois meses; alcançou a alta pontuação de 9,25/10 no benchmark LFG.
Mas também pode ser "excessivamente confiante" às vezes, falando bobagens com a maior naturalidade. Se você precisa de uma inspiração transformadora, escolha-a.
O GPT-5.3-Codex é "Alta Confiabilidade, Baixa Variância".
É como um engenheiro experiente e confiável que nunca te deixa na mão. A velocidade de raciocínio é 25% maior, praticamente não comete erros básicos e sua estabilidade é tranquilizadora.
Embora seja um pouco menos eficiente em tarefas criativas (nota LFG de 7,5/10), é a ferramenta mais eficiente para programação e operações diárias. Escolha-a se precisar de entregas estáveis.

À medida que avançamos para 2026, nossos papéis começam a mudar.
Neste momento, a maior mudança para os usuários comuns é a seguinte: a importância da Engenharia de Resposta Rápida está diminuindo, enquanto as capacidades de Gerenciamento de Agentes estão começando a surgir.
Quando o ChatGPT consegue corrigir erros e até mesmo operar seu terminal de forma autônoma, e quando o Claude consegue processar 1 milhão de palavras por vez e identificar detalhes com precisão, não precisamos mais dividir comandos em instruções fragmentadas como se estivéssemos ensinando uma criança do ensino fundamental.
O que precisamos fazer é aprender a definir metas, analisar resultados e decidir quando e qual tarefa atribuir a qual "funcionário" como "gerente".
Este é o novo ambiente de trabalho em 2026: sua equipe está infiltrada por um grupo de gênios da tecnologia de silício, e você é o único chefe feito de carbono.
#Siga a conta oficial do iFanr no WeChat: iFanr (ID do WeChat: ifanr), onde você encontrará conteúdo ainda mais interessante o mais breve possível.
