
O recém-lançado Doubao Big Model 1.6 me poupou de horas extras! Há também uma ferramenta de vídeo que supera o Veo 3 e é líder mundial.
Até que ponto esse grande modelo se tornou involuído?
Olhando para o ritmo deste ano, a ByteDance tem novas ideias quase todos os meses, e até mais de um modelo por mês. A empresa lançou um modelo após o outro, e eles não são apenas novos, mas também contam com atualizações reais, que continuam a elevar o patamar competitivo do setor.
Em janeiro, o modelo Doubao 1.5 Pro foi lançado.
Em abril, o modelo de pensamento profundo Doubao 1.5, o modelo Wenshengtu 3.0 e o modelo de compreensão visual foram atualizados simultaneamente.
Em maio, o modelo de geração de vídeo Seedance 1.0 Lite, o modelo de pensamento profundo visual Doubao 1.5 e o modelo de música, texto, imagens, sons e bytes são todos desejados.

Na Force Power Conference realizada pela Volcano Engine hoje, a linha de produtos de IA da ByteDance continuou a lançar produtos sem nenhuma metafísica, com foco em grande quantidade e uso total pronto para uso.
Novos modelos como o Doubao Big Model 1.6, o modelo de geração de vídeo Seedance 1.0 pro, o DeepResearch que pode escrever relatórios do setor e serviços nativos de IA na nuvem, como a plataforma de desenvolvimento Agent, surgiram um após o outro.
Na análise final, você pode não entender o Transformer, mas definitivamente pode sentir que esses produtos de IA podem realmente fazer coisas pelas pessoas.
Os destaques da atualização do produto são os seguintes:
Modelos da série Doubao 1.6
- Capacidades de raciocínio aprimoradas, com suporte para "pensar enquanto pesquisa" e "Pesquisa Profunda"
- Excelente capacidade de compreensão multimodal, melhor compreensão e tratamento de problemas do mundo real
- A operação da GUI é mais inteligente e interage suavemente com outras ferramentas
- Excelente custo-benefício
Modelo de geração de vídeo Seedance 1.0 pro
- Múltiplas tomadas e diferentes trocas de cenas, aumentando a quantidade de informação e narrativa
- Continuidade de movimento, estabilidade de imagem e textura geral aprimoradas
Doubao Big Model 1.6: Bom para fazer exames, capaz de reservar hotéis e alto desempenho de custo
O destaque desta conferência é a série Doubao Big Model 1.6, composta por três modelos.

Doubao-Seed-1.6: Um modelo abrangente “tudo em um”
Suporta pensamento profundo, compreensão multimodal e operação de interface gráfica. O pensamento profundo possui três modos: ativado, desativado e automático. No modo adaptativo, o modelo decide automaticamente se ativa o pensamento profundo com base na dificuldade da tarefa, economizando tempo e tokens. Além disso, é o primeiro modelo na China a suportar contexto de 256k.
Doubao-Seed-1.6-thinking: Uma versão aprimorada em termos de pensamento profundo
1.6 – O foco desta atualização é o pensamento. A capacidade de raciocínio foi fortalecida, permitindo a compreensão e o processamento de tarefas complexas com mais precisão. Há também melhorias em codificação, matemática, raciocínio lógico e acompanhamento de instruções. Também suporta contexto de 256k e raciocínio multimodal.
Doubao-Seed-1.6-flash: A versão mais rápida da série 1.6
A latência é extremamente baixa, tornando-o ideal para cenários sensíveis a baixa latência. A compreensão de texto é superior à do Doubao 1.5-lite, e a compreensão visual é comparável à dos principais produtos de outros fabricantes.
Na conferência, os modelos da série Doubao 1.6 apresentaram uma série de resultados de avaliação confiáveis. Em particular, o desempenho do Doubao 1.6, pensando nisso, ficou entre os melhores do mundo.
capacidade de raciocínio
Não é novidade fazer exames de modelagem, mas é raro obter uma pontuação tão alta quanto a da Universidade de Pequim ou da Universidade Tsinghua.
Tomando como exemplo a capacidade de raciocínio, o Doubao 1.6 apresentou progressos significativos em comparação com os modelos anteriores. O Doubao obteve 144 pontos nas questões de matemática do novo exame nacional de admissão à faculdade deste ano, ficando em primeiro lugar no país. Usando o teste completo simulado de Haidian, em comparação com os 500 a 600 pontos do ano passado, o Doubao 1.6 obteve mais de 700 pontos em artes liberais e ciências este ano.

Um dos destaques do Doubao em termos de raciocínio lógico é que ele não apenas pensa por si mesmo, mas também sabe como "buscar enquanto pensa". Ele primeiro analisa o problema, encontra as informações-chave, faz uma rodada de reflexão e, em seguida, realiza várias rodadas de busca com base nas informações ausentes.
Por exemplo, quando a Doubao foi solicitada a "detalhar a distribuição de insetos e espécies comuns na província de Guangdong e apresentá-los na forma de um relatório de pesquisa", ela primeiro considerou os requisitos de formato do relatório de pesquisa durante sua reflexão profunda e, em seguida, determinou rapidamente a estrutura da classificação. Em seguida, a Doubao considerou que "o conteúdo precisa ser apoiado por dados e exemplos específicos", e começou a buscar de forma independente dados sobre o ambiente natural na província de Guangdong e pesquisas anteriores relacionadas.
Também foi mencionado na reunião que a Doubao está testando a função DeepResearch. No passado, os profissionais levavam várias horas ou dias para escrever um relatório profissional, mas a Doubao consegue concluí-lo em 5 a 30 minutos. Ela também pode extrair informações automaticamente e resumi-las em uma página da web para consulta.
Além disso, para facilitar aos usuários corporativos o uso das funções "pensar enquanto pesquisa" e "DeepResearch", o site oficial do Volcano Engine lançou um grande laboratório de aplicativos de modelos e tornou o código-fonte aberto, permitindo que os usuários criem seus próprios protótipos de aplicativos de IA e orquestrem com flexibilidade suas próprias entidades inteligentes.
Capacidade de compreensão multimodal
Toda a série Doubao 1.6 oferece suporte nativo a recursos de pensamento multimodal, permitindo que o modelo entenda e lide melhor com problemas do mundo real.
A compreensão multimodal suporta o mais recente recurso de "chamada de vídeo em tempo real" da Doubao. No âmbito empresarial, pode ser amplamente utilizado em análises de produtos de e-commerce, etiquetagem de direção autônoma, inspeções de segurança e outros cenários.
Por exemplo, o modelo pode ser usado para conduzir análises padronizadas de fotos enviadas por comerciantes ou para comparar rapidamente preços de produtos semelhantes.
No campo automotivo, os modelos podem ser usados para identificar com mais precisão a direção de viagem e as intenções de direção de um carro, além de selecionar segmentos específicos de grandes quantidades de dados rodoviários para treinar modelos de direção autônoma posteriores.
Em cenários mais offline, o Doubao pode localizar e contar com precisão as informações na imagem, concluindo assim tarefas como inspeções de segurança e inspeções de lojas.
Por exemplo, vamos analisar o Doubao 1.6-thinking para verificar se há algum risco potencial à segurança causado pelo uso de capacetes em uma foto de exploração de cavernas. Através de um pensamento profundo, ele não só consegue contar com precisão o número de capacetes usados na foto, como também, surpreendentemente, consegue refletir sobre a questão "É seguro usar capacete?" e, em seguida, analisar se os capacetes na foto estão sendo usados corretamente, se as roupas são adequadas, se o equipamento de iluminação está completo, se a distância segura para caminhar é adequada, etc., e, por fim, propor a prioridade de correção.
Capacidade de operação da GUI
Com sua capacidade de pensamento visual profundo e capacidade de posicionamento visual preciso, o Doubao 1.6 permite que agentes inteligentes interajam e operem sem problemas com navegadores e outras ferramentas, além de executar com eficiência tarefas como triagem de reservas de hotéis e classificação de passagens.
A operação do modelo da GUI não apenas substitui a conveniência das pessoas clicarem no APP com os dedos, mas também pode superar as limitações dos APPs e GUIs tradicionais para atender às necessidades essenciais das pessoas de forma mais inteligente e automática.
Custo-efetividade
O Doubao Big Model 1.6 adota um modelo de precificação unificado. Independentemente de o modo de pensamento profundo estar ativado ou não, seja texto ou visual, o preço dos tokens é o mesmo, e o preço é baseado no intervalo de comprimento do contexto de entrada.

Na faixa de entrada de 0-32k usada pela maioria das empresas, o preço é de 0,8 yuan/milhão de tokens para entrada e 8 yuan/milhão de tokens para saída.
Na faixa de entrada de 32k-128k, o preço é de 1,2 yuan/milhão de tokens para entrada e 16 yuan/milhão de tokens para saída.
Na faixa de entrada de 128k-256k, o preço é de 2,4 yuans/milhão de tokens para entrada e 24 yuans/milhão de tokens para saída.
Em termos de custo total, a maioria das entradas de solicitação está dentro de 32 mil, e a relação entrada-saída é de 3:1. O custo total do Doubao Large Model 1.6 (2,6 yuans) é 63% menor que o custo total do Doubao Large Model 1.5 Deep Thinking Model e do DeepSeek R1 (7 yuans). Isso significa que você pode usar um novo modelo com recursos mais poderosos e multimodal nativo por apenas um terço do preço original.

Desta vez, a Volcano Engine também adicionou uma zona de desconto especial. Para solicitações com entrada de 32 mil e saída de menos de 200 tokens, o preço do Doubao Large Model 1.6 será reduzido ainda mais para 0,8 yuan/milhão de tokens para entrada e 2 yuan/milhão de tokens para saída. Isso é equivalente às necessidades da maioria dos modelos não racionais, e você também pode usar o novo modelo com melhores efeitos com tranquilidade.

O Seedance 1.0 pro já está disponível: você pode gravar filmes de sucesso sem gastar dinheiro
Além dos modelos da série Doubao Big Model 1.6, nesta coletiva de imprensa, a Volcano Engine também apresentou um novo modelo de geração de vídeo, o Seedance 1.0 pro.

A primeira mudança que vale a pena mencionar neste modelo é o avanço na linguagem das lentes.
O modelo suporta entrada de texto e imagem e pode gerar vídeos de alta qualidade em 1080p com alternância perfeita entre múltiplas lentes. O Seedance 1.0 Pro foca em um caso de uso multiação e livre movimentação da câmera, que não só suporta a geração de vídeos de 10 segundos com alternância de 2 a 3 lentes, mas também alterna entre planos gerais, planos médios e planos fechados, aprimorando significativamente o conteúdo informativo e a narrativa do vídeo.

Além disso, com o conjunto de dados multidimensionais e o mecanismo de aprendizado de feedback introduzidos no estágio pós-treinamento, o novo modelo mantém um nível muito alto em termos de continuidade de movimento, estabilidade de imagem e textura geral.
O novo modelo de vídeo da Doubao não se limita à fase de demonstração. Seja criando comerciais de produtos, produzindo rapidamente esboços de storyboard ou oferecendo aos clientes a possibilidade de criar personagens de jogos e criar vídeos de enredo, o novo modelo de vídeo da Doubao avança passo a passo em direção a esses cenários mais produtivos.
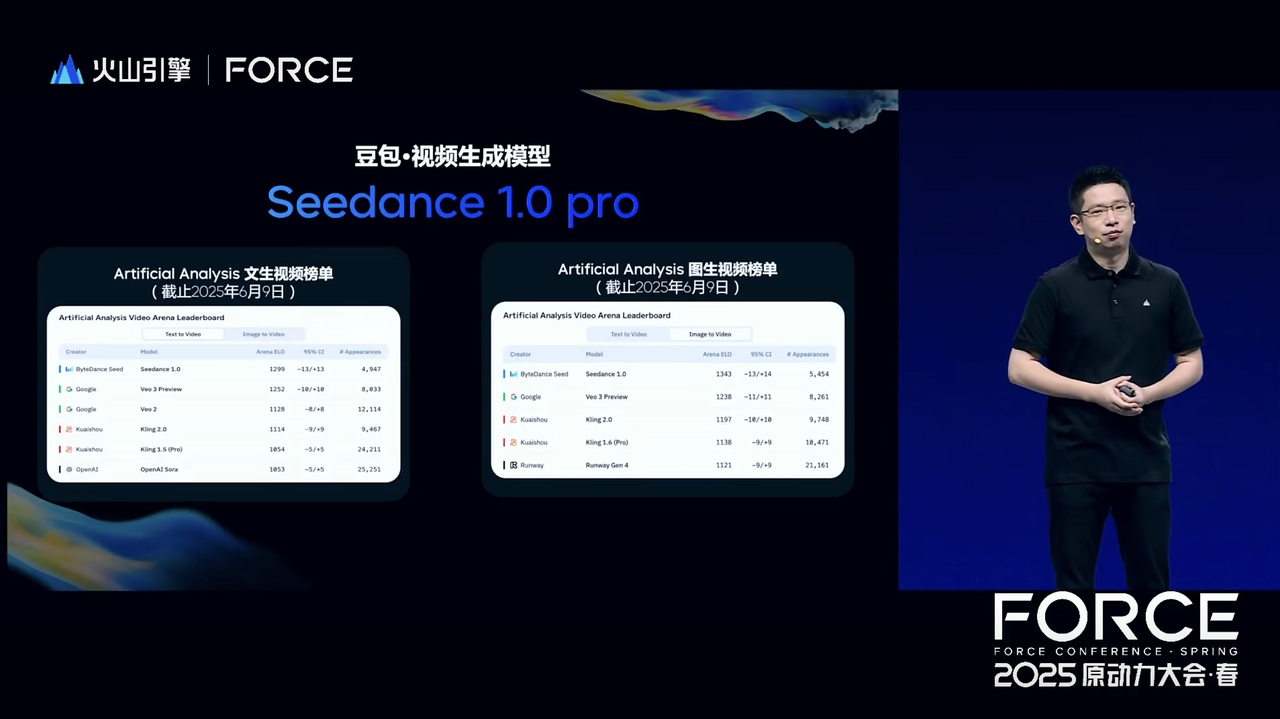
As classificações da Artificial Analysis, uma agência de avaliação terceirizada, mostram que o Seedance 1.0 é atualmente o modelo mais bem classificado nos rankings chinês e inglês.
Na lista de vídeos de Wensheng, o Seedance 1.0 tem uma pontuação ELO de 1299, superando o Veo 3 Preview do Google, o Veo 2 e a série Keling de Kuaishou. Na lista de vídeos de Tusheng, o Seedance 1.0 tem uma pontuação ELO de 1343, superando o Runway Gen 4, o Keling 2.0, etc., e é invencível.
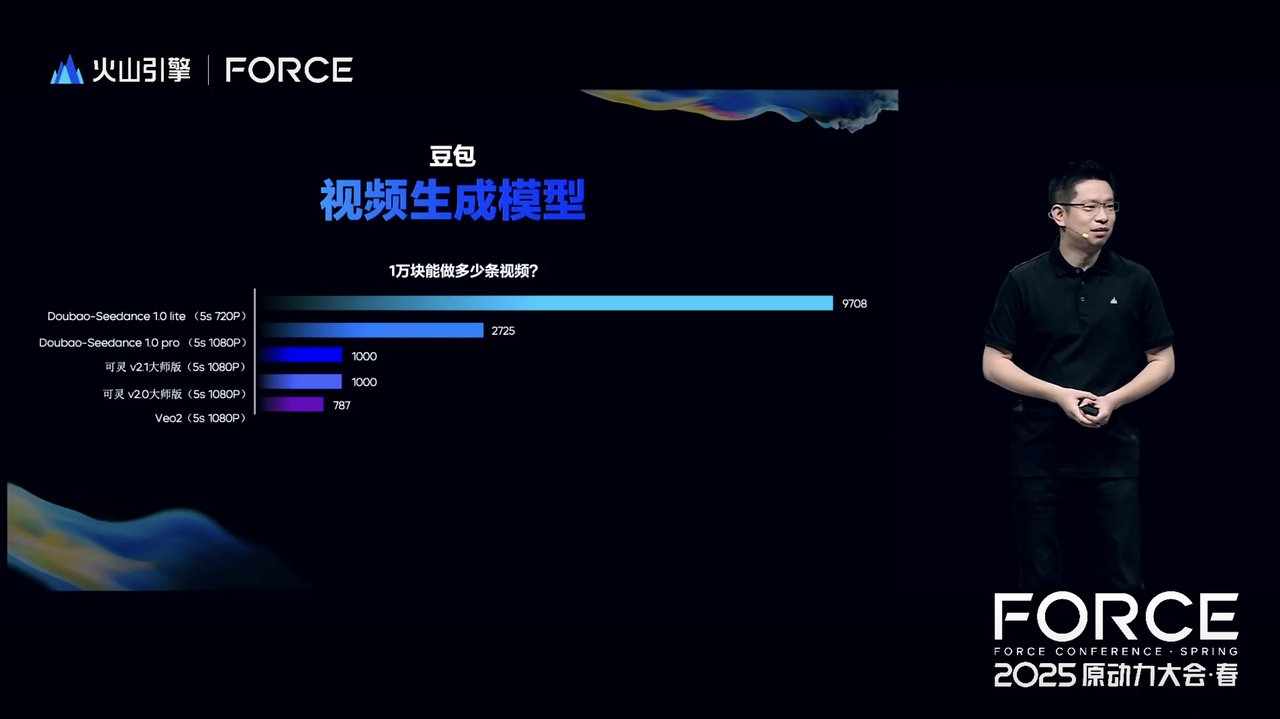
Embora o desempenho seja maximizado, o preço é surpreendentemente acessível.
Com um orçamento de RMB 10.000, você pode gerar 2.725 vídeos (5 segundos em 1080p) com o Seedance 1.0 Pro, o que equivale a gerar 9.708 vídeos (5 segundos em 720p) com o Seedance 1.0 Lite. Em comparação, a produção de produtos concorrentes, como KeLing v2.1 Master Edition e Veo2 (5 segundos em 1080p), é inferior a 1.000.
Além do modelo de geração de vídeo, a Doubao também lançou simultaneamente um modelo de voz em tempo real em grande escala, levando o antropomorfismo e o controle semântico a novos patamares.
Ele pode ajustar flexivelmente o tom, o volume, etc., de acordo com o contexto; suporta interações vocais expressivas, como cantar e sussurrar; e até mesmo dialetos locais, incluindo o dialeto de Sichuan. Durante a demonstração ao vivo, o modelo de voz Doubao também cantou "A Lua Representa Meu Coração". Sabe de uma coisa? Parece realmente interessante.

Em termos de cenários de aplicação reais, além de cooperar com a Mercedes-Benz para desenvolver interação de voz no carro, a Doubao também lançou um "modelo de geração de podcast" baseado em tecnologia de voz em tempo real, que suporta estruturas de voz complexas, como conversas naturais, interrupções e pausas entre várias pessoas.
Ele reconhece automaticamente o conteúdo de entrada (prompt, link da web, texto longo) e gera automaticamente um roteiro de podcast completo + conteúdo de áudio antropomórfico. Do ritmo à interjeição, passando pelo tom de um clipe de podcast demonstrado no local, quase não há a mínima sensação de IA.
2025 é o primeiro ano do Agent. Como integrar verdadeiramente um Agent ao sistema empresarial tornou-se um problema prático enfrentado por todos os fabricantes.
Para dar melhor suporte ao desenvolvimento e à aplicação de agentes, a Volcano Engine lançou um conjunto completo de produtos full-stack de IA nativos em nuvem de uma só vez, desde serviços MCP, ferramentas de prompt inteligentes PromptPilot, sistemas de gerenciamento de conhecimento de IA até estruturas de aprendizado por reforço veRL, data lakes multimodais, computação privada AICC e firewalls de aplicativos de grande modelo.

Tan Dai, presidente da Volcano Engine, enfatizou a importância da "segurança" para a Agentic AI e apresentou dois produtos de segurança de IA que serão lançados em breve: "AICC Confidential Computing" e "Large Model Application Firewall".
Entre elas, a computação confidencial do AICC pode permitir que as empresas usem serviços de nuvem com segurança e conformidade, assim como usam modelos privados, garantindo ao mesmo tempo o efeito de raciocínio.
O firewall de aplicativo de modelo grande é derivado do "Volcano Ark" e pode interceptar variantes de ataque com baixa latência e alta precisão, criando um espaço de raciocínio seguro e confiável para aplicativos inteligentes empresariais.

Ao longo de toda a coletiva de imprensa, a Volcano Engine não continuou a elevar a narrativa da IA. Em vez disso, trouxe sua perspectiva de volta ao presente e se concentrou em produtos de IA que podem ser implementados, implantados e executados em ambientes de produção hoje mesmo.
Nos últimos seis meses, o consenso do setor tornou-se cada vez mais claro: a segunda metade da IA é, na verdade, a primeira metade do produto. As diferenças de parâmetros continuarão a ser eliminadas, mas a eficiência de chamadas, o caminho de integração e o custo de uso do produto determinarão a taxa de retenção do usuário.
É por isso que, na coletiva de imprensa de hoje, além do Doubao Big Model 1.6 e do modelo de geração de vídeo Seedance 1.0 pro, a Volcano Engine também lançou simultaneamente uma série de recursos de produto que não parecem tão explosivos, mas são extremamente críticos.
Da chamada de modelo à combinação de cenários específicos até a execução em circuito fechado segura e estável, esses recursos devem ser conectados entre si para formar um sistema de produção de IA verdadeiramente utilizável.
Pode não ser o mais chamativo, mas pode ser o mais viável e o mais próximo da "usabilidade".
Autor: Wang Xin, Mo Chongyu
#Bem-vindo a seguir a conta pública oficial do iFanr no WeChat: iFanr (ID do WeChat: ifanr), onde mais conteúdo interessante será apresentado a você o mais breve possível.
