
Uma introdução ao uso de NLTK com Python
O processamento de linguagem natural é um aspecto do aprendizado de máquina que permite processar palavras escritas em uma linguagem amigável à máquina. Esses textos tornam-se então ajustáveis e você pode executar algoritmos computacionais neles como desejar.
A lógica por trás dessa tecnologia cativante parece complexa, mas não é. E mesmo agora, com um conhecimento sólido da programação Python básica, você pode criar um novo processador de texto DIY com o kit de ferramentas de linguagem natural (NLTK).
Veja como começar a usar o NLTK do Python.
O que é NLTK e como funciona?
Escrito em Python, o NLTK apresenta uma variedade de funcionalidades de manipulação de strings. É uma biblioteca versátil de linguagem natural com um vasto repositório de modelos para vários aplicativos de linguagem natural.
Com o NLTK, você pode processar textos brutos e extrair recursos significativos deles. Ele também oferece modelos de análise de texto, gramáticas baseadas em recursos e ricos recursos lexicais para a construção de um modelo de linguagem completo.
Como configurar o NLTK
Primeiro, crie uma pasta raiz do projeto em qualquer lugar do seu PC. Para começar a usar a biblioteca NLTK, abra seu terminal na pasta raiz que você criou anteriormente e crie um ambiente virtual .
Em seguida, instale o kit de ferramentas de linguagem natural neste ambiente usando pip :
pip install nltkO NLTK, no entanto, apresenta uma variedade de conjuntos de dados que servem como base para novos modelos de linguagem natural. Para acessá-los, você precisa ativar o downloader de dados embutido do NLTK.
Portanto, depois de instalar o NLTK com êxito, abra seu arquivo Python usando qualquer editor de código.
Em seguida, importe o módulo nltk e instancie o downloader de dados usando o seguinte código:
pip install nltk
nltk.download()Executar o código acima por meio do terminal traz uma interface gráfica de usuário para selecionar e baixar pacotes de dados. Aqui, você precisará escolher um pacote e clicar no botão Download para obtê-lo.
Qualquer pacote de dados baixado vai para o diretório especificado gravado no campo Download Directory . Você pode mudar isso se quiser. Mas tente manter o local padrão neste nível.
Nota: Os pacotes de dados são anexados às variáveis do sistema por padrão. Portanto, você pode continuar a usá-los em projetos subsequentes, independentemente do ambiente Python que estiver usando.
Como usar tokenizadores NLTK
Em última análise, o NLTK oferece modelos de tokenização treinados para palavras e frases. Usando essas ferramentas, você pode gerar uma lista de palavras de uma frase. Ou transforme um parágrafo em uma matriz de frases sensata.
Aqui está um exemplo de como usar o NLTK word_tokenizer :
import nltk
from nltk.tokenize import word_tokenize
word = "This is an example text"
tokenWord = word_tokenizer(word)
print(tokenWord)
Output:
['This', 'is', 'an', 'example', 'text']O NLTK também usa um tokenizer de frase pré-treinado chamado PunktSentenceTokenizer . Funciona dividindo um parágrafo em uma lista de frases.
Vamos ver como isso funciona com um parágrafo de duas frases:
import nltk
from nltk.tokenize import word_tokenize, PunktSentenceTokenizer
sentence = "This is an example text. This is a tutorial for NLTK"
token = PunktSentenceTokenizer()
tokenized_sentence = token.tokenize(sentence)
print(tokenized_sentence)
Output:
['This is an example text.', 'This is a tutorial for NLTK']
Você pode ainda tokenizar cada frase na matriz gerada a partir do código acima usando word_tokenizer e Python for loop .
Exemplos de como usar NLTK
Portanto, embora não possamos demonstrar todos os casos de uso possíveis de NLTK, aqui estão alguns exemplos de como você pode começar a usá-lo para resolver problemas da vida real.
Obtenha definições de palavras e suas partes do discurso
O NLTK apresenta modelos para determinar classes gramaticais, obter semântica detalhada e possível uso contextual de várias palavras.
Você pode usar o modelo wordnet para gerar variáveis para um texto. Em seguida, determine seu significado e parte do discurso.
Por exemplo, vamos verificar as variáveis possíveis para "Monkey:"
import nltk
from nltk.corpus import wordnet as wn
print(wn.synsets('monkey'))
Output:
[Synset('monkey.n.01'), Synset('imp.n.02'), Synset('tamper.v.01'), Synset('putter.v.02')]
O código acima mostra possíveis alternativas de palavras ou sintaxes e classes gramaticais para "Macaco".
Agora verifique o significado de "Macaco" usando o método de definição :
Monkey = wn.synset('monkey.n.01').definition()
Output:
any of various long-tailed primates (excluding the prosimians)Você pode substituir a string entre parênteses por outras alternativas geradas para ver o que o NLTK produz.
O modelo pos_tag , no entanto, determina as classes gramaticais de uma palavra. Você pode usar isso com word_tokenizer ou PunktSentenceTokenizer () se estiver lidando com parágrafos mais longos.
É assim que funciona:
import nltk
from nltk.tokenize import word_tokenize, PunktSentenceTokenizer
word = "This is an example text. This is a tutorial on NLTK"
token = PunktSentenceTokenizer()
tokenized_sentence = token.tokenize(word)
for i in tokenized_sentence:
tokenWordArray = word_tokenize(i)
partsOfSpeech = nltk.pos_tag(tokenWordArray)
print(partsOfSpeech)
Output:
[('This', 'DT'), ('is', 'VBZ'), ('an', 'DT'), ('example', 'NN'), ('text', 'NN'), ('.', '.')]
[('This', 'DT'), ('is', 'VBZ'), ('a', 'DT'), ('tutorial', 'JJ'), ('on', 'IN'), ('NLTK', 'NNP')]O código acima emparelha cada palavra tokenizada com sua tag de fala em uma tupla. Você pode verificar o significado dessas tags em Penn Treebank .
Para um resultado mais limpo, você pode remover os pontos na saída usando o método replace () :
for i in tokenized_sentence:
tokenWordArray = word_tokenize(i.replace('.', ''))
partsOfSpeech = nltk.pos_tag(tokenWordArray)
print(partsOfSpeech)
Cleaner output:
[('This', 'DT'), ('is', 'VBZ'), ('an', 'DT'), ('example', 'NN'), ('text', 'NN')]
[('This', 'DT'), ('is', 'VBZ'), ('a', 'DT'), ('tutorial', 'JJ'), ('on', 'IN'), ('NLTK', 'NNP')]Visualizando tendências de recursos usando o gráfico NLTK
Extrair recursos de textos brutos costuma ser tedioso e demorado. Mas você pode visualizar os determinantes de recursos mais fortes em um texto usando o gráfico de tendência de distribuição de frequência NLTK.
NLTK, no entanto, sincroniza com matplotlib. Você pode aproveitar isso para visualizar uma tendência específica em seus dados.
O código abaixo, por exemplo, compara um conjunto de palavras positivas e negativas em um gráfico de distribuição usando seus dois últimos alfabetos:
import nltk
from nltk import ConditionalFreqDist
Lists of negative and positive words:
negatives = [
'abnormal', 'abolish', 'abominable',
'abominably', 'abominate','abomination'
]
positives = [
'abound', 'abounds', 'abundance',
'abundant', 'accessable', 'accessible'
]
# Divide the items in each array into labeled tupple pairs
# and combine both arrays:
pos_negData = ([("negative", neg) for neg in negatives]+[("positive", pos) for pos in positives])
# Extract the last two alphabets from from the resulting array:
f = ((pos, i[-2:],) for (pos, i) in pos_negData)
# Create a distribution plot of these alphabets
cfd = ConditionalFreqDist(f)
cfd.plot()O gráfico de distribuição do alfabeto é assim:
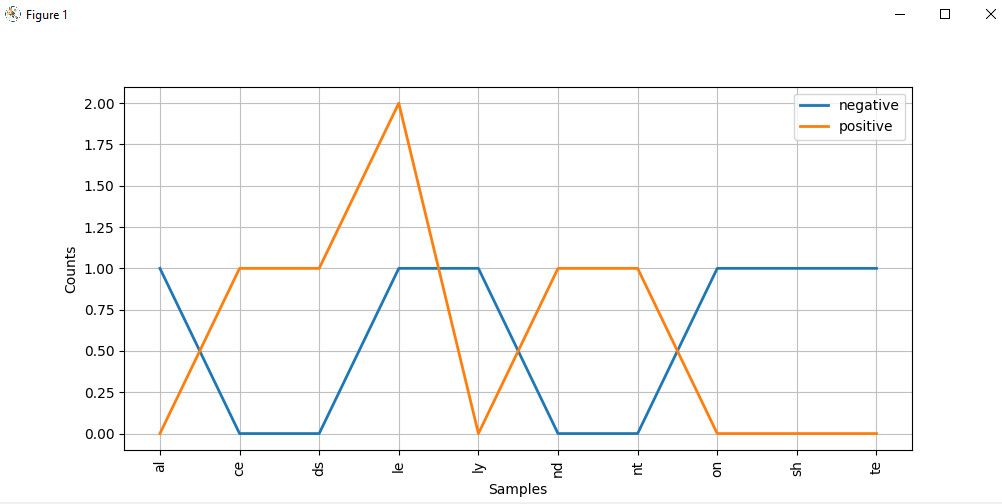
Olhando atentamente para o gráfico, as palavras que terminam com ce , ds , le , nd e nt têm maior probabilidade de serem textos positivos. Mas aquelas que terminam com al , ly , on e te são mais provavelmente palavras negativas.
Nota : Embora tenhamos usado dados autogerados aqui, você pode acessar alguns dos conjuntos de dados internos do NLTK usando seu leitor Corpus chamando-os da classe corpus de nltk . Você pode querer olhar a documentação do pacote corpus para ver como você pode usá-lo.
Continue explorando o Natural Language Processing Toolkit
Com o surgimento de tecnologias como Alexa, detecção de spam, chatbots, análise de sentimento e muito mais, o processamento de linguagem natural parece estar evoluindo para sua fase subumana. Embora tenhamos considerado apenas alguns exemplos do que o NLTK oferece neste artigo, a ferramenta tem aplicativos mais avançados, além do escopo deste tutorial.
Depois de ler este artigo, você deve ter uma boa idéia de como usar o NLTK em um nível básico. Tudo o que resta a você fazer agora é colocar esse conhecimento em prática você mesmo!
