
Uma conversa com a equipe da Ideal Assisted Driving: como a direção assistida evoluiu de “macaco” para “humano”

Por volta dessa época no ano passado, a iFanr e a Dongchehui realizaram uma discussão com a equipe da Ideal Assisted Driving no Centro de P&D da Ideal em Pequim. Naquela ocasião, a nova arquitetura tecnológica da Ideal Assisted Driving, "Modelo de Linguagem Visual de ponta a ponta + VLM", estava prestes a ser implementada em veículos. A declaração da equipe da Ideal Assisted Driving na época foi:
A estrutura teórica por trás do "modelo de linguagem visual ponta a ponta + VLM" é a "resposta definitiva" para a direção autônoma.
Com a transição da arquitetura técnica "modelo de linguagem visual ponta a ponta + VLM" para VLA (Visão-Linguagem-Ação, modelo de ação de linguagem visual), estamos um passo mais perto da "resposta final".
De acordo com Li Xiang e a equipe de direção assistida da Ideal, este é um passo fundamental na evolução das capacidades de direção assistida da Ideal, do estágio "macaco" para o estágio "humano". Ao mesmo tempo, visitamos o centro de P&D da Ideal em Pequim para continuar a discutir novas tendências nesta área com a equipe de direção assistida da Ideal.

▲ Lang Xianpeng, vice-presidente sênior de P&D de direção autônoma da Ideal Auto
Na direção assistida, qual é a diferença entre macacos e humanos?
Antes de a solução de direção assistida da Ideal migrar para o "modelo de linguagem visual ponta a ponta + VLM" no ano passado, ela adotou a arquitetura técnica padrão da indústria "Percepção – Planejamento – Controle". Essa arquitetura depende de engenheiros para criar regras correspondentes que orientem o controle do veículo com base em diversas condições reais de tráfego, mas é difícil abranger todas as condições reais de tráfego.

Esta é a "era mecânica" da direção assistida. A direção assistida só consegue lidar com situações com regras correspondentes e não tem capacidade de pensar e aprender.
O "modelo de linguagem visual ponta a ponta + VLM" representa a "era dos macacos" da direção assistida. Comparados às máquinas, os macacos são mais inteligentes e têm alguma capacidade de imitar e aprender. É claro que os macacos também são mais ativos e desobedientes.
A essência do modelo de linguagem visual "end-to-end + VLM" é o "aprendizado por imitação", que se baseia em dados abrangentes de direção humana para treinamento. A quantidade e a qualidade desses dados determinam o desempenho. Além disso, por razões de segurança, nesta arquitetura, o modelo de linguagem visual VLM, responsável por cenários complexos, não participa do controle do veículo; ele apenas fornece a tomada de decisões e a orientação da trajetória.

VLA (Visão-Linguagem-Ação) é a "era humana" da direção assistida, possuindo a capacidade de "pensar, comunicar, lembrar e melhorar a si mesmo".
Os macacos passaram por uma longa transformação para se tornarem humanos. Em teoria, o "aprendizado por imitação" do "modelo de linguagem visual ponta a ponta + VLM" também pode aprender quase todos os dados de direção humana ao longo de um longo período e se comportar quase como um humano.
Mas o preço é "tempo".
Lang Xianpeng, vice-presidente sênior de P&D de direção autônoma da Ideal Auto, disse:
Nosso MPI (quilometragem média de aquisição) de ponta a ponta no ano passado era de cerca de dez quilômetros na primeira versão, em julho do ano passado. Achamos que era muito bom na época, porque nossa versão sem mapa estava em iteração há muito tempo, e o MPI completo (rodovia + cidade) era de apenas cerca de 10 quilômetros.
De 1 milhão para 2 milhões de clipes (clipes de vídeo usados para treinar direção assistida de ponta a ponta) e, em seguida, para 10 milhões de clipes, conforme a quantidade de dados aumentou, o IPM atingiu 100 quilômetros no início deste ano. Em 7 meses, o IPM aumentou dez vezes, uma média de várias vezes por mês.
Mas depois de atingir 10 milhões de clipes, descobrimos um problema: simplesmente aumentar a quantidade de dados era inútil; a quantidade de dados valiosos estava diminuindo. É como uma prova: quando você está reprovado, tirar um crédito aleatório pode melhorar sua pontuação muito rapidamente. Mas quando você está na faixa dos 80 ou 90, é muito difícil melhorar em até 5 ou 10 pontos.
Nesse ponto, usamos o superalinhamento para forçar o modelo a produzir resultados que atendessem às expectativas humanas. Também selecionamos alguns dados e os complementamos com o superalinhamento para aprimorar ainda mais as capacidades do modelo. Essa abordagem teve algum efeito, mas levamos aproximadamente cinco meses, de março ao final de julho deste ano, para alcançar uma melhoria de aproximadamente duas vezes no desempenho do modelo.
Este é o primeiro problema encontrado pela arquitetura técnica "modelo de linguagem visual de ponta a ponta + VLM" após seu rápido progresso: quanto mais o tempo passa, mais escassos os dados úteis se tornam e mais lenta a melhoria do desempenho do modelo.

O problema fundamental também foi exposto. Lang Xianpeng disse:
Essencialmente, a aprendizagem por imitação de ponta a ponta atual carece de capacidades de pensamento lógico profundo. É como um macaco dirigindo um carro. Dê-lhe algumas bananas e ele pode se comportar como você pretendia, mas não sabe o porquê. Pode vir até você quando um gongo é tocado, ou dançar quando um tambor é tocado, mas não sabe o porquê.
Portanto, a arquitetura ponta a ponta não tem a capacidade de pensar profundamente. No máximo, é uma resposta ao estresse. Ou seja, dado um input, o modelo gera um output. Não há uma lógica profunda por trás disso.
É por isso que adicionamos um Modelo de Linguagem Visual (VLM) ao modelo de ponta a ponta. O VLM possui capacidades de compreensão e raciocínio mais robustas, permitindo uma melhor tomada de decisões. No entanto, esse modelo é lento para pensar e não está profundamente acoplado ao modelo de ponta a ponta. Consequentemente, o modelo de ponta a ponta frequentemente falha em compreender ou aceitar as decisões tomadas pelo VLM.
Na mesma época do ano passado, a Ideal Assisted Driving Team disse:
Há duas tendências futuras. Primeiro, a escala dos modelos aumentará. O Sistema 1 e o Sistema 2 são atualmente dois modelos ponta a ponta com um VLM. Esses dois modelos podem ser mesclados. Atualmente, eles estão fracamente acoplados, mas no futuro, poderão ser acoplados de forma mais forte. Segundo, também podemos aprender com a tendência atual de grandes modelos multimodais. Esses modelos estão caminhando para a multimodalidade nativa, capaz de lidar com linguagem, fala, visão e lidar. Isso é algo que consideraremos no futuro.
A tendência rapidamente se tornou realidade.
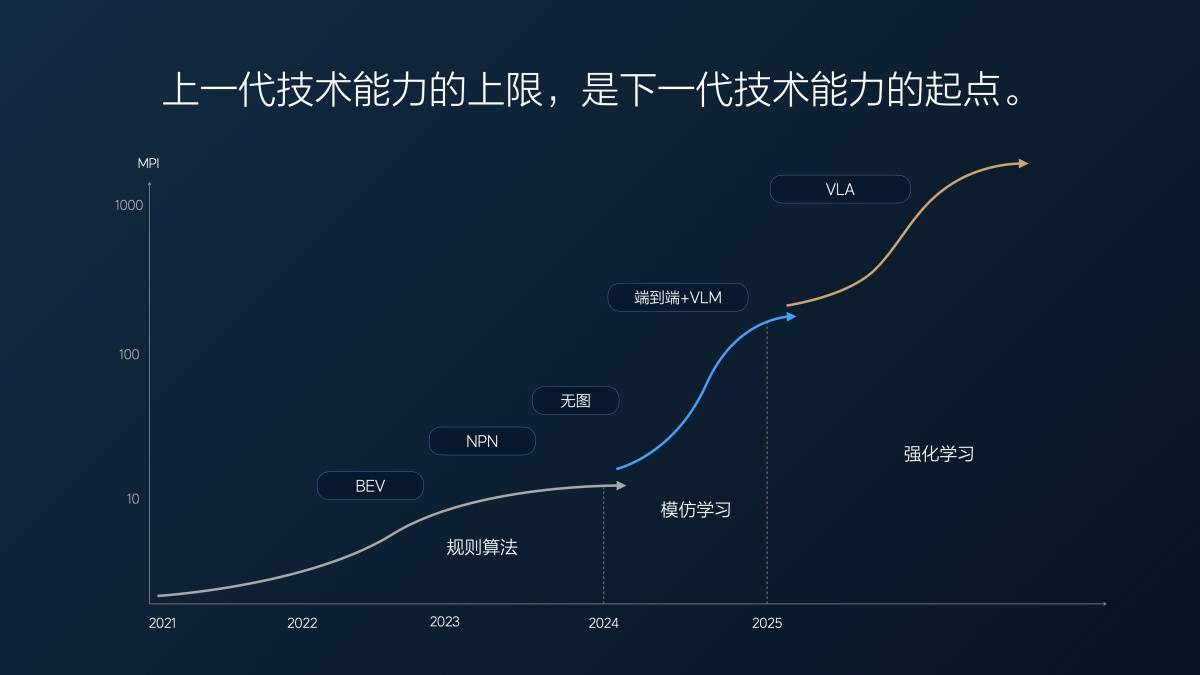
Lang Xianpeng também explicou os motivos para mudar de ponta a ponta + VLM para VLA:
Quando estávamos trabalhando de ponta a ponta no ano passado, estávamos constantemente refletindo se isso era suficiente e, se não, o que mais precisávamos fazer.
Temos realizado algumas pesquisas preliminares sobre o VLA. De fato, essas pesquisas preliminares representam nossa compreensão de que a inteligência artificial não é um aprendizado por imitação. Ela deve ter capacidade de pensamento e raciocínio como os humanos. Em outras palavras, deve ser capaz de resolver coisas que nunca viu ou cenários desconhecidos. Isso porque pode ter uma certa capacidade de generalização de ponta a ponta, mas não basta dizer que ela tem capacidade de pensamento.
Assim como um macaco, ele pode fazer algo que você acha que está além da sua imaginação, mas nem sempre o fará. Mas os humanos são diferentes. Os humanos podem crescer e iterar, então devemos desenvolver nossa inteligência artificial de acordo com a forma como a inteligência humana se desenvolve. Rapidamente migramos de ponta a ponta para a solução VLA.
VLA (Visão-Linguagem-Ação) é a tendência de pensamento do ano passado e a arquitetura técnica que se tornou realidade hoje.
Embora VLA e VLM sejam diferentes em apenas uma letra, suas conotações são muito diferentes.
Visão em VLA refere-se à entrada de diversas informações de sensores, incluindo informações de navegação, que permitem ao modelo entender e perceber o espaço.
A linguagem do VLA se refere à capacidade do modelo de resumir, traduzir, compactar e codificar a compreensão espacial percebida em uma expressão de linguagem, assim como um ser humano.
A Ação do VLA é o modelo que gera uma estratégia comportamental baseada na linguagem de codificação da cena para dirigir o carro.
A diferença mais intuitiva é que as pessoas podem controlar o carro com a linguagem. Elas podem fazer o carro desacelerar ou acelerar, virar à esquerda ou à direita falando. Isso se deve principalmente à parte da linguagem. Os comandos recebidos pelo modelo amplo de comandos humanos também são comandos dentro do modelo VLA, o que equivale a conectar pessoas e carros.
Além disso, não há barreira entre visão e comportamento. A velocidade e a eficiência da entrada de informações visuais para a saída do comportamento de controle do veículo são bastante aceleradas, e os problemas de VLM lento e a falta de compreensão completa do VLM são resolvidos.
Uma diferença ainda mais significativa é a capacidade da Cadeia de Pensamento (CoT). O modelo VLA possui uma frequência de inferência de 10 Hz, mais de três vezes mais rápida que o VLM. Ele também proporciona uma percepção e compreensão mais abrangentes do ambiente, permitindo um raciocínio mais rápido e racional, além de gerar decisões mais assertivas.
Além das habilidades de pensamento e comunicação, o VLA também tem uma certa capacidade de memória, que permite lembrar das preferências e hábitos do dono; bem como uma capacidade de aprendizagem autônoma bastante forte.

▲ O Ideal i8 é o primeiro modelo a utilizar a tecnologia Ideal VLA
Condução assistida ideal "Acelerando a Vida"
No mundo real, se os humanos querem se tornar motoristas experientes, eles devem primeiro se matricular em uma autoescola e tirar uma carteira de motorista, depois colocar um "adesivo de estágio" e pegar a estrada, dirigindo em estradas de verdade por alguns anos.
O mesmo vale para o treinamento anterior de direção assistida, que não só exige dados de direção do mundo real para o treinamento, mas também exige um grande número de testes de estrada no mundo real.
Em alguns romances, alguns competidores talentosos podem se tornar mestres de artes marciais com níveis extremamente altos de habilidade por meio da leitura, como o "Imortal da Espada Confúciana" Xie Xuan em "A Canção da Juventude" e Xuanyuan Jingcheng em "O Espadachim na Neve".
Entretanto, em romances tradicionais de artes marciais, há apenas personagens como Wang Yuyan em "Os Semideuses e Semi-Demônios", que são proficientes em artes marciais clássicas, mas não têm nenhuma habilidade real de combate.

▲ Imagens de "Acelerando a Vida"
Claro, também há situações intermediárias: no filme de corrida "Speeding Life", o piloto de corrida Zhang Chi reproduzia constantemente as complexas condições da pista na área de Bayinbuluke em sua mente, dirigia em sua mente 20 vezes por dia, simulava dirigir mais de 36.000 vezes em 5 anos e, então, quando retornava à pista real, ele se tornava o campeão.
Dirigir virtualmente, melhorar constantemente e superar seus melhores resultados anteriores: este é o "algoritmo".
Entretanto, antes de Zhang Chi retornar à pista e se tornar o piloto campeão novamente, ele já havia provado seu valor nessa pista muitas vezes e acumulado muita experiência prática de direção.
Carro de verdade e estrada de verdade, acumulando experiência até entender todas as condições da estrada dessa pista, isso é "dados".

Lang Xianpeng disse que, para desenvolver um bom modelo de VLA, são necessários quatro níveis de capacidades: dados, algoritmos, poder de computação e capacidades de engenharia.
A Ideal há muito tempo enfatiza sua abundância de dados, dados excelentes, bom banco de dados e rotulagem e mineração de dados precisas. Em relação aos dados, a Ideal também possui uma nova habilidade: gerar treinamento de dados.

O modelo mundial é usado para reconstruir a cena e, em seguida, cenas semelhantes são geradas com base nos dados reais reconstruídos. Por exemplo, é ideal reconstruir uma cena ETC de alta velocidade no modelo mundial. Nesse cenário, não apenas as condições originais dos dados reais podem ser utilizadas, como solo ensolarado e seco durante o dia, mas também cenas como neve pesada durante o dia com solo escorregadio e chuva leve à noite com baixa visibilidade podem ser geradas.
O algoritmo de treinamento ideal para modelos VLA também está intimamente relacionado aos dados gerados. Lang Xianpeng explicou:
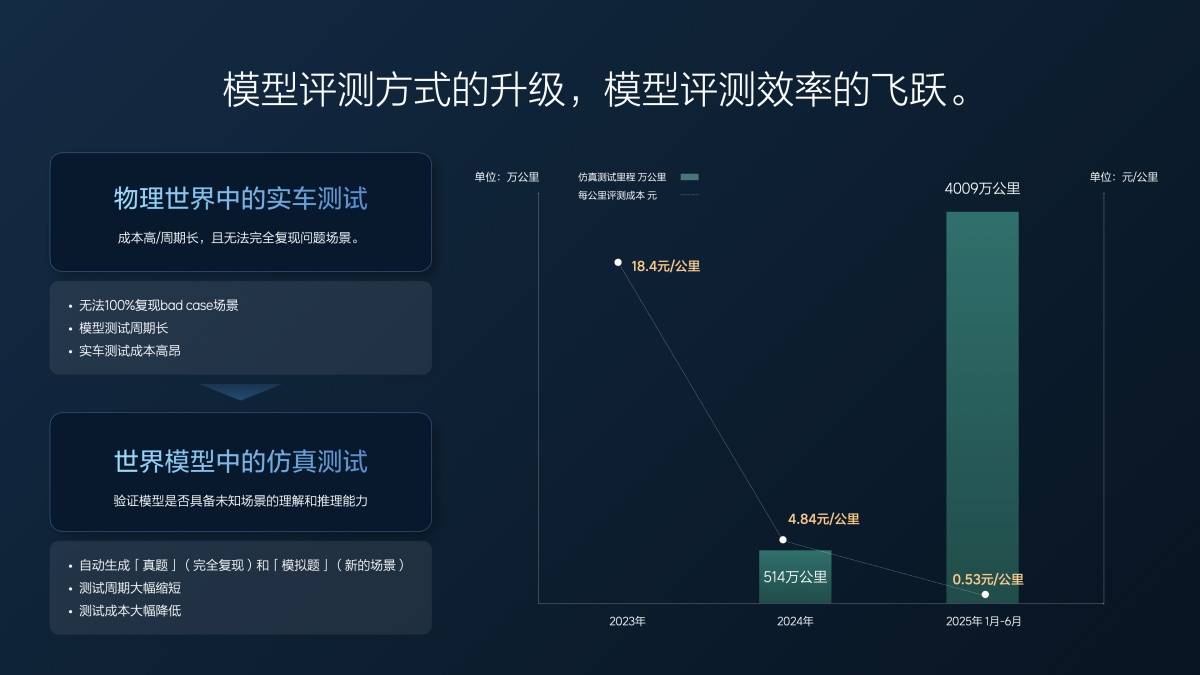
Ainda não alcançamos o desenvolvimento de ponta a ponta em 2023. A quilometragem efetiva de teste de veículos reais por ano é de aproximadamente 1,57 milhão de quilômetros, e o custo por quilômetro é de 18 yuans.
Quando começamos a trabalhar em sistemas de ponta a ponta, já tínhamos parte do nosso trabalho realizado em testes de simulação. Ao longo de 2024, percorremos aproximadamente 5 milhões de quilômetros em testes de simulação e mais de 1 milhão de quilômetros em testes em veículos reais. O custo médio caiu para menos de 5 yuans por quilômetro, o que ainda custa cerca de 30 milhões de yuans. No entanto, com esses mesmos 30 milhões de yuans, conseguimos testar 6 milhões de quilômetros.
Nos primeiros seis meses deste ano (1º de janeiro a 30 de junho), registramos 40 milhões de quilômetros de testes, com apenas 20.000 quilômetros em veículos reais, abrangendo cenários básicos. Todos os nossos testes, incluindo o Super Alinhamento e os recursos atuais do VLA que você viu, são realizados por meio de simulação. O custo é de 0,5 centavos por quilômetro, mal cobrindo os custos de eletricidade e servidor. Além disso, a qualidade dos testes é alta, com todos os casos e cenários totalmente replicados e precisos, garantindo resultados precisos. Nossa maior quilometragem de teste e a melhoria da qualidade dos testes impulsionaram a eficiência de P&D.
Muitas pessoas questionaram que seria impossível construirmos um VLA em meio ano e que não conseguiríamos nem testar tudo. Na verdade, fizemos muitos testes.
Além do baixo custo, a vantagem do teste de simulação é que ele pode reproduzir a cena perfeitamente. Em testes reais, é difícil restaurar uma cena 100%. Para o modelo VLA, mesmo a menor diferença na reprodução da cena pode levar a uma enorme diferença no desempenho de direção.

Nesse sentido, a forma ideal de treinamento do modelo VLA é um pouco semelhante ao modelo do filme "Acelerando a Vida", onde o protagonista realiza continuamente um treinamento virtual baseado na experiência real de direção.
É claro que treinar o modelo VLA também exige um enorme poder computacional. O poder computacional total atual da Ideal é de 13 EFLOPS, dos quais 3 EFLOPS são dedicados à inferência e 10 EFLOPS ao treinamento. Convertendo em placas de vídeo, isso equivale a 20.000 GPUs NVIDIA H20 para treinamento e 30.000 GPUs NVIDIA L20 para inferência.

Perguntas e respostas principais
P: A direção assistida inteligente apresenta um "triângulo impossível" — eficiência, conforto e segurança — que se limitam mutuamente e podem ser difíceis de alcançar simultaneamente nesta fase. Qual métrica o VLA da Ideal Auto está priorizando atualmente? Você acabou de mencionar o MPI. Entendemos que o objetivo final da Ideal Auto é melhorar a segurança para reduzir efetivamente as aquisições?
Lang Xianpeng: O MPI é uma das nossas métricas. Outra é o MPA, que se refere à quilometragem antes de um acidente. Proprietários de carros ideais sofrem um acidente a cada 600.000 quilômetros de direção humana, enquanto aqueles que utilizam direção assistida sofrem um acidente a cada 3,5 a 4 milhões de quilômetros. Continuaremos a aprimorar esses dados de quilometragem. Nossa meta é aumentar o MPA para 10 vezes o da direção humana, o que significa que é 10 vezes mais seguro do que a direção humana, e atingir uma taxa de acidentes de 6 milhões de quilômetros. No entanto, isso só poderá ser alcançado após o aprimoramento do modelo VLA.
Também analisamos o MPI. Embora alguns riscos à segurança possam levar à perda de controle do motorista, outros fatores, como o baixo conforto durante frenagens bruscas ou bruscas, também podem levar à perda de controle. Embora os riscos à segurança nem sempre ocorram, os usuários podem relutar em usar a direção assistida se o conforto ao dirigir não for o ideal. Como o MPA mede a segurança, além da segurança, nos concentramos em melhorar o conforto ao dirigir no MPI. Experimente os recursos de direção assistida do Ideal i8 e você notará uma melhora significativa no conforto em comparação com as versões anteriores.
A eficiência vem depois da segurança e do conforto. Por exemplo, se pegarmos a estrada errada, embora haja perda de eficiência, não a corrigiremos imediatamente tomando medidas perigosas. Ainda precisamos buscar a eficiência com base na segurança e no conforto.

P: Quais são as dificuldades do modelo VLA? Quais são os requisitos para as empresas? Quais desafios uma empresa enfrentará se quiser implementar o modelo VLA?
Lang Xianpeng: Muitas pessoas perguntaram se as montadoras podem pular o algoritmo de regras anterior e a etapa de ponta a ponta se quiserem desenvolver um modelo VLA. Acho que isso não é possível.
Embora os dados, algoritmos e outros aspectos do VLA possam diferir dos modelos anteriores, eles ainda se baseiam em fundamentos existentes. Sem um ciclo fechado completo de dados coletados de veículos reais, não há dados para treinar o modelo mundial. A Ideal Auto conseguiu implementar o modelo VLA porque temos 1,2 bilhão de pontos de dados. Somente com um entendimento completo desses dados podemos gerar dados melhores. Sem essa base de dados, em primeiro lugar, é impossível treinar o modelo mundial e, em segundo lugar, não fica claro que tipo de dados gerar.
Ao mesmo tempo, dar suporte ao poder de computação de treinamento básico e ao poder de computação de inferência exige muitos fundos e capacidades técnicas, que não podem ser concluídos sem acumulação prévia.
P: O teste real de veículos da Ideal este ano é de 20.000 quilômetros. Qual é a base para uma redução significativa nos testes reais de veículos?
Lang Xianpeng: Acreditamos que os testes em carros reais apresentam inúmeros desafios. O custo é um problema, mas o mais significativo é a impossibilidade de replicar completamente o cenário exato em que o problema ocorreu ao testar determinados cenários. Além disso, os testes em carros reais são ineficientes, exigindo que os motoristas dirijam o veículo e o testem novamente. Nossas simulações atuais rivalizam com os testes em carros reais. Mais de 90% dos testes na versão Super Edition atual e na versão VLA do Ideal i8 são simulados.
Utilizamos testes de simulação para verificar nossa versão completa desde o ano passado. Acreditamos que são altamente confiáveis e eficazes, por isso substituímos os testes de veículos reais por eles. Embora alguns testes sejam insubstituíveis, como os de durabilidade de hardware, geralmente utilizamos testes de simulação para testes de desempenho, e os resultados são excelentes.
Com o advento da Era Industrial, os processos de corte e queima foram substituídos pela mecanização; com o advento da Era da Informação, a internet substituiu uma quantidade significativa de trabalho. O mesmo se aplica à era da direção autônoma. Com o advento da era de ponta a ponta, transitamos para o uso da IA para direção autônoma. Da contratação de um grande número de engenheiros e testadores de algoritmos para uma abordagem orientada por dados, estamos aprimorando as capacidades de direção autônoma por meio de processos de dados, plataformas de dados e iteração de algoritmos. Na era dos modelos automatizados virtualizados (VLAs) em larga escala, a eficiência dos testes é o fator central para o aprimoramento das capacidades. Para alcançar uma iteração rápida, os fatores que a impedem devem ser eliminados. Se ainda houver intervenção manual e significativa em veículos do mundo real, a velocidade será reduzida. Não se trata necessariamente de substituir os testes em veículos do mundo real; em vez disso, a tecnologia e a abordagem exigem inerentemente o uso de testes de simulação. Sem isso, não estamos praticando o aprendizado por reforço ou desenvolvendo modelos de VLA.
P: O VLA não subverte de fato o end-to-end + VLM, então pode-se entender que o VLA é uma inovação que tende a se concentrar em capacidades de engenharia?
Zhan Kun (Especialista Sênior em Algoritmos, Direção Autônoma, Ideal Auto): VLA é mais do que apenas uma inovação de engenharia. Se você se interessa por inteligência incorporada, notará que essa tendência é impulsionada pela aplicação de grandes modelos ao mundo físico. Isso envolve essencialmente o desenvolvimento de um algoritmo VLA. Nosso modelo VLA visa aplicar as ideias e abordagens da inteligência incorporada ao campo da direção autônoma. Fomos os primeiros a propô-lo e colocá-lo em prática. O VLA também é de ponta a ponta, pois sua essência é entrada de cena e saída de trajetória, um conceito semelhante ao VLA. No entanto, a inovação algorítmica envolve pensamento adicional. De ponta a ponta pode ser entendido como VA sem a linguagem. A linguagem corresponde ao pensamento e à compreensão. Incorporamos esse componente ao VLA, unificando o paradigma da robótica e tornando a direção autônoma uma categoria da robótica. Isso representa inovação algorítmica, não apenas inovação de engenharia.
Um grande desafio para a direção autônoma é a inovação em engenharia. O VLA é um modelo amplo e implantá-lo em computação de ponta é extremamente desafiador. Muitas equipes não necessariamente consideram o VLA uma má ideia, mas sim que sua implantação é difícil. Colocá-lo em prática é incrivelmente desafiador, especialmente quando os chips de ponta carecem de poder computacional. Portanto, precisamos implantá-lo em chips de alta capacidade de computação. Não se trata apenas de inovação em engenharia, mas exige uma otimização extensiva da implantação da engenharia para alcançar o sucesso.
P: Ao implementar grandes modelos VLA a bordo, haverá poda ou destilação do modelo? Como podemos encontrar um equilíbrio entre eficiência de inferência e desempenho do modelo?
Zhan Kun: Buscamos um equilíbrio cuidadoso entre eficiência e destilação durante a implantação. Nosso modelo base é um modelo proprietário MoE (Mixture of Experts) 8×0,4B, único no setor. Após uma análise aprofundada dos chips NVIDIA, descobrimos que essa arquitetura se encaixa perfeitamente. Ela oferece alta velocidade de inferência e grande capacidade de modelagem, permitindo acomodar modelos grandes com diversos cenários e capacidades. Essa foi a nossa escolha arquitetônica.
Além disso, destilamos um modelo amplo. Inicialmente, treinamos um modelo baseado em nuvem de 32 bilhões de libras, que contém uma vasta quantidade de conhecimento e capacidades de direção. Destilamos seus processos de pensamento e raciocínio em um modelo MoE de 3,2 bilhões de libras e usamos a tecnologia Diffusion em conjunto com o Vision and Action (um modelo de difusão que pode gerar imagens, vídeos, áudio, trajetórias de movimento e outros dados. Especificamente, no cenário ideal de VLA, a Diffusion é usada para gerar trajetórias de direção).
Fizemos inúmeras otimizações usando essa abordagem. Especificamente, também implementamos otimizações de engenharia para o Diffusion. Em vez de simplesmente usar o Diffusion padrão, implementamos a compressão de inferência, que pode ser considerada uma forma de destilação. Anteriormente, o Diffusion poderia exigir 10 etapas de inferência, mas usar a correspondência de fluxo requer apenas duas. Essa compressão é o motivo fundamental pelo qual conseguimos implantar o VLA.

P: O VLA é uma solução boa o suficiente? Quanto tempo levará para atingir o chamado "momento GPT"?
Zhan Kun: Quando se disse anteriormente que o modelo multimodal não havia atingido o momento GPT, pode ter-se referido à IA física, como o VLA, em vez do VLM. De fato, o VLM agora atende plenamente a um padrão muito inovador de "momento GPT". Se nos concentrarmos na IA física, o VLA atual, especialmente nas áreas de robótica e inteligência incorporada, pode não ter atingido o padrão de "momento GPT" por não possuir capacidades de generalização tão boas.
No entanto, no campo da direção autônoma, o VLA, na verdade, resolve um paradigma de direção relativamente unificado, e há uma chance de alcançar um "momento GPT" dessa forma. Também reconhecemos que o VLA atual é a primeira versão e a primeira a ser lançada em produção em massa na indústria, portanto, certamente haverá alguns defeitos.
Esta grande tentativa é usar o VLA para explorar um novo caminho. Ele contém muitas áreas a serem testadas e muitos pontos de exploração que precisam ser implementados. Isso não significa que, se não conseguirmos atingir o "momento GPT", não devemos entrar em produção em massa. Há muitos detalhes, incluindo nossa avaliação e simulação, para verificar se ele pode ser colocado em produção em massa e se pode proporcionar aos usuários uma experiência "melhor, mais confortável e mais segura". Se os três pontos acima forem alcançados, poderemos oferecer aos usuários uma entrega melhor.
"Momentos GPT" referem-se mais a uma forte versatilidade e generalização. Nesse processo, à medida que expandimos a condução autônoma para robôs espaciais ou outros campos incorporados, podemos desenvolver capacidades de generalização mais fortes ou capacidades de coordenação mais abrangentes. Após a implementação, migraremos gradualmente para os momentos ChatGPT à medida que "os dados do usuário forem iterados, os cenários se tornarem mais ricos, o pensamento se tornar mais lógico e as interações de voz se tornarem mais frequentes".
Como disse o Dr. Lang Bo (Dr. Lang Xianpeng), se atingirmos 1000 MPI no ano que vem, isso pode dar aos usuários a sensação de que realmente alcançamos um "momento GPT" para o VLA.
#Bem-vindo a seguir a conta pública oficial do WeChat do iFaner: iFaner (ID do WeChat: ifanr), onde mais conteúdo interessante será apresentado a você o mais breve possível.