
Resumo Matinal Apple divulga vídeo do Ano Novo Lunar de 2026 / Data de lançamento da série Samsung S26 revelada: 25 de fevereiro / Clawdbot renomeado novamente


A Apple lança seu filme para o Ano Novo Lunar de 2026, "Meet You".

Informações indicam que Musk está considerando uma fusão com a Tesla ou a xAI antes do IPO da SpaceX.

A equipe de IA da Apple está passando por mais uma onda de demissões, com vários pesquisadores e executivos da Siri migrando para a Meta e o Google.

Pang Tianyu junta-se à Tencent Hunyuan, onde será responsável pela aprendizagem por reforço multimodal.

Foi noticiado que a Ideal criou uma nova equipe focada em software e robôs humanoides.

O Clawdbot foi renomeado para OpenClaw, consolidando seu posicionamento de código aberto e orientado pela comunidade.

Relatório da GDC: 52% dos desenvolvedores de jogos acreditam que a IA generativa é prejudicial para a indústria.

Pela primeira vez, a receita internacional da Kimi supera a receita doméstica, com o K2.5 impulsionando um aumento no número de usuários globais.

A febre dos vídeos com inteligência artificial diminuiu, e os downloads do aplicativo Sora caíram por dois meses consecutivos.

Quatro artigos da equipe de aplicação Qianwen C-end foram selecionados para o ICLR 2026.

Editora musical processa Anthropic novamente: 20.000 músicas baixadas ilegalmente.

Wang Xingxing, da Yushu: Espera-se que robôs de uso geral se tornem realidade nos próximos dez anos; modelos em grande escala representam um avanço de nível "Prêmio Nobel" para o setor.

A Shengshu Technology lança o Vidu Q3, levando a geração de vídeo para o estágio de "produção de filmes com um clique".

A SenseTime disponibiliza o SenseNova-MARS em código aberto, cujo desempenho em inferência multimodal supera o do Gemini-3-Pro.

Data de lançamento da série Samsung Galaxy S26 revelada: 25 de fevereiro.
 Notícias que valem a pena acompanhar, mesmo no fim de semana.
Notícias que valem a pena acompanhar, mesmo no fim de semana.
A Apple lança seu filme para o Ano Novo Lunar de 2026, "Meet You".

Ontem, o filme da Apple para o Ano Novo Lunar de 2026, "Meet You", foi lançado oficialmente online.
Dirigido por Bai Xue, diretor do premiado filme "Crossing Spring" no Festival Internacional de Cinema de Pingyao, o filme foi rodado com um iPhone 17 Pro e incorpora animação stop-motion e outras técnicas multimídia para demonstrar os mais recentes recursos da Apple em imagem móvel.
"Meet You" conta a história de um cachorro perdido que anseia voltar para casa durante o Festival da Primavera e viaja com Lin Wei, uma mulher que o ajuda ao longo do caminho. O filme utiliza um estilo narrativo mais acessível ao público jovem, focando na conexão emocional entre humanos e animais e girando em torno do significado de "lar".
O CEO da Apple, Tim Cook, publicou no Weibo: "'Meet You' é uma história sobre se redescobrir com a ajuda de amigos inesperados. Este filme da Apple para o Ano Novo Lunar foi gravado com um iPhone 17 Pro e captura muitos momentos emocionantes. Esperamos que gostem."
Sendo o primeiro filme da Apple para o Ano Novo Lunar a utilizar uma abordagem de mídia híbrida, "Meet You" faz uso extensivo dos novos recursos do iPhone 17 Pro em termos visuais, incluindo zoom óptico de 8x equivalente a 200 mm, uma câmera Fusion de 48 megapixels em toda a série e a câmera frontal Center Stage.
A equipe de cinematografia do filme afirmou que o design leve e o zoom de alta ampliação do iPhone tornaram as filmagens mais flexíveis e também possibilitaram filmar da perspectiva do animal.
Desde 2018, a Apple lança curtas-metragens gravados com o iPhone mais recente para o Ano Novo Lunar há nove anos consecutivos, incluindo "Three Minutes", "A Bucket", "Daughter", "A-Nian", "Come Back", "Passing Five Barriers", "Little Garlic" e, no ano passado, "I Want to Listen to a Song with You", gravado com o iPhone 16 Pro.
Informações indicam que Musk está considerando uma fusão com a Tesla ou a xAI antes do IPO da SpaceX.

Segundo a Bloomberg, Musk está avaliando a possibilidade de fusão entre SpaceX, Tesla e xAI. As discussões ainda estão em fase inicial, mas já atraíram considerável atenção dos mercados de capitais e da indústria.
Diversas fontes familiarizadas com o assunto disseram que a SpaceX está explorando dois caminhos principais: um é se fundir com a Tesla, e o outro é se fundir com a xAI por meio de uma troca de ações antes de seu IPO este ano.
Alguns investidores estão pressionando por uma fusão entre a SpaceX e a Tesla, enquanto uma fusão entre a SpaceX e a xAI é vista como outra opção viável. O relatório aponta que, se o negócio for concretizado, poderá atrair fundos de infraestrutura e fundos soberanos do Oriente Médio, e exigiria financiamento adicional substancial.
O relatório afirma que, de uma perspectiva estratégica, a ideia de fusão está intimamente ligada aos planos de longo prazo de Musk.
A SpaceX está explorando a possibilidade de implantar data centers no espaço para fornecer poder computacional de alta densidade para IA. Se o projeto for viável, a IA espacial (xAI) se beneficiará diretamente da implantação de poder computacional orbital, enquanto a capacidade de fabricação da Tesla em sistemas de armazenamento de energia também poderá fornecer suporte de energia solar para data centers espaciais.
Anteriormente, Musk também havia discutido a possibilidade de usar a Starship da SpaceX para transportar o robô Optimus da Tesla para a Lua ou Marte.
No mercado, as ações da Tesla subiram até 4,5% no pregão estendido de quinta-feira, influenciadas por rumores de fusão.
A Bloomberg noticiou anteriormente que a SpaceX planeja abrir seu capital por volta de junho deste ano, com uma avaliação de até US$ 1,5 trilhão e uma captação de recursos de até US$ 50 bilhões, o que poderia se tornar o maior IPO da história.
Informações de registro comercial em Nevada mostram que duas entidades jurídicas com "merger sub" em seus nomes foram estabelecidas no dia 21 deste mês. Entre os executivos registrados está Bret Johnsen, diretor financeiro da SpaceX, o que é visto como um dos preparativos para uma possível transação.
A Reuters, citando fontes, informou que, caso a SpaceX se funda com a xAI, alguns executivos da xAI podem optar por receber dinheiro em vez de ações da SpaceX como forma de pagamento.
A SpaceX investiu US$ 2 bilhões em xAI no ano passado, e a Tesla também anunciou esta semana que investirá aproximadamente US$ 2 bilhões em xAI, indicando que os fluxos de capital entre as empresas de Musk estão se acelerando.
A equipe de IA da Apple está passando por mais uma onda de demissões, com vários pesquisadores e executivos da Siri migrando para a Meta e o Google.

Segundo a Bloomberg, a Apple está passando por mais uma onda de perda de talentos em IA, com vários pesquisadores importantes e um executivo sênior responsável pela Siri deixando a empresa nas últimas semanas para se juntar a concorrentes como Meta e Google DeepMind.
O relatório indica que os últimos pesquisadores que partiram incluem Yinfei Yang, Haoxuan You, Bailin Wang e Zirui Wang.
Entre eles, Yang fundou uma nova empresa, You e Bailin Wang se juntaram à Meta, trabalhando respectivamente no departamento de pesquisa de Superinteligência e na equipe de sistemas de recomendação da empresa; Zirui Wang foi para o Google DeepMind.
Entretanto, Stuart Bowers, o executivo sênior responsável por reconstruir as principais funcionalidades da Siri, também deixou a Apple para se juntar ao Google DeepMind.
O relatório destaca que essas saídas ocorreram depois que a Apple passou por uma grande reestruturação de sua organização de IA no ano passado.
Na época, o CEO Tim Cook removeu John Giannandrea, que há muito tempo era o responsável pela IA, de sua posição principal e o substituiu por Craig Federighi, vice-presidente sênior de engenharia de software, para assumir a estratégia geral de IA. Ele também trouxe Amar Subramanya, ex-executivo do Google e da Microsoft, para liderar algumas áreas da organização.
O relatório mencionou que a equipe de Modelos Fundamentais da Apple (AFM) perdeu mais de dez pesquisadores nos últimos seis meses. A equipe é responsável por dar suporte aos modelos subjacentes da Inteligência Artificial da Apple e está sob pressão interna devido ao lançamento atrasado da Siri e à recepção morna de seus recursos.
Vale ressaltar que a Apple planeja lançar duas versões da Siri este ano: uma que usará dados pessoais para fornecer respostas mais contextuais; e outra que será uma reformulação mais radical, adotando um estilo de interação semelhante ao de um chatbot.
Ambas as plataformas são baseadas em um novo modelo arquitetônico desenvolvido com a ajuda da equipe do Google. Quando questionado sobre a escolha do Google durante a teleconferência de resultados, Cook afirmou que isso proporcionaria à Apple a "base mais sólida" e enfatizou que a colaboração ajudaria a desbloquear mais experiências.
Apesar da Apple ter reportado vendas de iPhones superiores a US$ 85 bilhões em seu último relatório de resultados, a falta de progresso expressivo em inteligência artificial e a contínua fuga de talentos ainda são consideradas fatores significativos que afetam o desempenho de suas ações neste ano.
Pang Tianyu junta-se à Tencent Hunyuan, onde será responsável pela aprendizagem por reforço multimodal.

Segundo a Phoenix Technology, Pang Tianyu, doutor em Ciência da Computação pela Universidade de Tsinghua e pesquisador na área de aprendizado de máquina confiável e modelos generativos, confirmou ontem que se juntou à equipe Hunyuan da Tencent como Líder Técnico em Aprendizado por Reforço Multimodal e começará a trabalhar oficialmente em 4 de fevereiro.
Ele será o principal responsável pela pesquisa em aprendizado por reforço em modelos multimodais, inicialmente com foco em modelos generativos, e pela exploração de algoritmos de ponta no Centro de Exploração Multimodal Hunyuan da Tencent.
Informações públicas indicam que Pang Tianyu nasceu em 1995. Durante seu doutorado na Universidade de Tsinghua, ele obteve diversos resultados em robustez de aprendizado de máquina e aprendizado profundo. Publicou vários artigos como primeiro autor (incluindo co-primeiro autor) em conferências de alto nível como ICML, NeurIPS e ICLR, e foi selecionado diversas vezes para apresentações orais ou apresentações em destaque.
Ele recebeu diversas honrarias, como a Bolsa de Estudos da Microsoft e o Prêmio NVIDIA de Pioneiro Acadêmico. Após a graduação, trabalhou como pesquisador científico sênior no Sea AI Lab, em Singapura.
Essa mudança para a Tencent é vista pelo setor como mais um sinal de que a Equipe Mista continua atraindo talentos nativos em IA. Este ano, a Tencent vem fazendo ajustes contínuos em sua arquitetura de modelos em larga escala, estrutura organizacional e sistema de talentos.
Anteriormente, Yao Shunyu, ex-pesquisador sênior da OpenAI, ingressou na Tencent como cientista-chefe de IA, responsável pelo Departamento de Infraestrutura de IA e pelo Departamento de Modelos de Linguagem de Grande Porte, e promoveu a reconstrução profunda do sistema híbrido.
Na reunião anual deste ano, Ma Huateng também mencionou que a equipe da Hunyuan passou por uma "profunda reestruturação" no ano passado e acelerou a contratação de talentos e a colaboração interna.
Em termos de produto, o assistente de IA da Tencent, "Yuanbao", vem passando por iterações contínuas desde o ano passado. Durante o Festival da Primavera deste ano, lançou a função "Pagar" e anunciou a distribuição de 1 bilhão de yuans em envelopes vermelhos.
Em 28 de janeiro, a equipe da Hunyuan disponibilizou o código-fonte do Hunyuan Image 3.0, uma versão de imagem raw, e simultaneamente o integrou ao Yuanbao. No mais recente ranking de edição de imagens do LMARaena, este modelo alcançou o nível mais alto.
Simultaneamente, a comunidade MLNLP também divulgou informações sobre o recrutamento para a equipe de Pang Tianyu, visando graduados dos programas de recrutamento universitário de 2026 e 2027 e aqueles que se formaram nos últimos três anos. O recrutamento foca em candidatos com experiência em modelos generativos, modelos de difusão, infraestrutura de RL e agentes VLM.
As vagas de estágio estão abertas a estudantes de mestrado e doutorado, que devem possuir sólidas habilidades em engenharia ou fundamentos teóricos, e aqueles com experiência em publicação de artigos em conferências de alto nível terão prioridade.
Como pode ser visto em eventos públicos anteriores, Pang Tianyu está profundamente envolvido na área de aprendizado de máquina confiável há muito tempo. Na palestra TechBeat de 2022, ele propôs que "não há contradição entre robustez e precisão definidas de forma razoável" e apresentou o método SCORE de robustez autoconsistente, que fornece uma nova estrutura explicativa para treinamento adversarial e generalização de modelos.
Com a entrada oficial de Pang Tianyu, as capacidades de P&D da Tencent Hunyuan em aprendizado por reforço multimodal foram ainda mais aprimoradas, proporcionando-lhe mais reservas técnicas para competir em modelos de código aberto, aplicações de IA generativa e infraestrutura.
Foi noticiado que a Ideal criou uma nova equipe focada em software e robôs humanoides.
Segundo o LatePost Auto, a Li Auto está passando por uma grande reestruturação organizacional que abrange software, direção autônoma e agentes inteligentes de ponta, fortalecendo ainda mais seu investimento em estratégia de IA e reorganizando seu sistema de P&D de uma forma mais próxima à de empresas avançadas em IA.
A Li Auto estabeleceu dois novos departamentos-chave: a Equipe de Ontologia de Software e a Equipe de Robótica Humanoide. Gou Xiaofei, Vice-Presidente de Espaço Inteligente, foi nomeado chefe da Equipe de Ontologia de Software; Lang Xianpeng, Vice-Presidente Sênior de P&D de Condução Autônoma, foi transferido para o cargo de chefe da Equipe de Robótica Humanoide.
Ao mesmo tempo, a maioria dos funcionários do departamento de direção autônoma foi alocada à equipe de modelos básicos liderada por Zhan Kun, formando uma estrutura de P&D mais centralizada e orientada a modelos.
Em uma reunião estratégica online realizada nesta segunda-feira, o CEO da Li Auto, Li Xiang, enfatizou que a empresa adotará o modelo operacional das empresas de IA mais avançadas, reorganizando suas equipes de tecnologia de forma colaborativa para construir um ciclo de vida baseado em silício, e afirmou explicitamente que ajustará significativamente sua estrutura de P&D. Essa mudança organizacional é uma implementação direta dessa estratégia.
Gou Xiaofei é responsável há muito tempo pela arquitetura inteligente do cockpit da Li Auto e esteve profundamente envolvido no projeto de sistemas das plataformas Li Auto ONE e da série L;
Lang Xianpeng é o primeiro funcionário da equipe de direção autônoma da Li Auto. Ele liderou a evolução de múltiplas gerações de tecnologia, desde a NOA e a solução ponta a ponta até a VLA, e impulsionou a produção em massa da solução "ponta a ponta + VLM" em 2024, a implementação completa da VLA em 2025 e o lançamento do modelo de motorista VLA aprimorado na atualização OTA 8.2 deste ano.
Desde que ingressou na Li Auto em 2021, James Chan tem se concentrado na arquitetura de direção autônoma e na implementação de três gerações de tecnologias. No ano passado, ele assumiu a liderança do departamento "Modelo VLA" e agora conduzirá a equipe do modelo base, que passará a integrar mais profissionais da área de direção autônoma e a desenvolver projetos de P&D baseados em modelos.
Além disso, Zhan Yifei, ex-chefe de avaliação e operações de IA no departamento de direção autônoma, e Ling Lin, ex-chefe de anotação de dados, foram transferidos para a equipe de robôs humanoides juntamente com Lang Xianpeng. Ambos foram membros essenciais da Ideal Autonomous Driving em seus primórdios e desempenharam papéis fundamentais em áreas como mapeamento, arquitetura de sistemas e anotação de dados, respectivamente.
O relatório sugere que esse ajuste indica que a Li Auto está integrando direção autônoma, ontologia de software e robôs humanoides em uma estrutura estratégica unificada de IA. Essa abordagem visa acelerar a iteração tecnológica por meio de um método organizacional sistemático e baseado em modelos, além de lançar as bases para futuras linhas de produtos com agentes inteligentes.
O Clawdbot foi renomeado para OpenClaw, consolidando seu posicionamento de código aberto e orientado pela comunidade.
Segundo a AI Cambricon, o projeto de assistente pessoal de IA de código aberto Clawdbot anunciou oficialmente ontem seu nome definitivo: "OpenClaw". A equipe afirmou que o novo nome visa reforçar seu posicionamento de código aberto e orientado pela comunidade, mantendo a lagosta como mascote do projeto.
O projeto foi lançado inicialmente em novembro de 2025 com o nome "Clawd" e, devido a problemas legais e de marca registrada, teve seu nome alterado brevemente para "Moltbot". Após a conclusão das buscas de marcas registradas, aquisição de domínios e migração de código, a equipe finalmente decidiu adotar "OpenClaw" como nome oficial.
O OpenClaw é executado no dispositivo local do usuário e fornece recursos de assistente de IA por meio de aplicativos de bate-papo populares, como WhatsApp, Telegram, Discord, Slack e Teams.
Diferentemente dos assistentes SaaS tradicionais, os dados do usuário não são enviados para servidores de terceiros; todas as chaves e dados são armazenados no próprio dispositivo ou servidor do usuário.
Nesta atualização, o OpenClaw adiciona suporte para Twitch e Google Chat e expande a gama de modelos compatíveis, incluindo Kimi K2.5 e Xiaomi MiMo-V2-Flash.
Entretanto, a interface web agora suporta o envio de imagens. A equipe também fez mais de 30 contribuições relacionadas à segurança e lançou um modelo de segurança verificável por máquina, enfatizando que as dicas de injeção de vulnerabilidades continuam sendo um problema não resolvido no setor.
Peter Steinberger, responsável pela manutenção do projeto, afirmou que, à medida que o projeto se expande rapidamente, a equipe está contratando mais pessoas para a manutenção e estabelecendo processos para lidar com o grande número de solicitações de pull e problemas, além de explorar maneiras viáveis de fornecer remuneração integral aos principais colaboradores.
No futuro, a OpenClaw continuará a aprimorar a confiabilidade do gateway, expandir o suporte a modelos e melhorar a funcionalidade geral.
Relatório da GDC: 52% dos desenvolvedores de jogos acreditam que a IA generativa é prejudicial para a indústria.

Segundo a PC Gamer, a pesquisa "Estado da Indústria de Jogos em 2026", divulgada recentemente pela Game Developers Conference (GDC), mostra que mais da metade dos desenvolvedores de jogos acredita que a IA generativa está tendo um impacto negativo no setor, um número que aumentou significativamente nos últimos dois anos.
A pesquisa abrangeu mais de 2.300 pessoas que trabalham na indústria de jogos. O relatório indica que 52% dos entrevistados este ano acreditam que a IA generativa é prejudicial para o setor, em comparação com 30% no ano passado e apenas 18% no ano anterior. Enquanto isso, a porcentagem dos que acreditam que a IA generativa é benéfica caiu de 13% no ano passado para 7% este ano.
Apesar das atitudes cada vez mais negativas, a proporção de desenvolvedores que utilizam IA generativa não mudou significativamente.
Este ano, 33% dos entrevistados disseram usar IA generativa em seu trabalho, praticamente o mesmo percentual de 31% registrado em 2021.
No entanto, 52% dos entrevistados disseram que seus estúdios estavam usando tecnologia de IA generativa, principalmente em áreas como brainstorming (81%), trabalho administrativo (47%), programação assistida (47%) e prototipagem (35%), enquanto apenas 5% disseram que a usariam para o desenvolvimento de recursos voltados para o jogador.
Em termos de distribuição de empregos, artistas, designers, roteiristas e programadores são os que menos aceitam a IA generativa; enquanto o pessoal de negócios e gestão são os usuários mais frequentes.
O relatório mostra que 58% dos profissionais de negócios usam ferramentas de IA, 47% dos executivos de empresas as utilizam e 29% dos funcionários da linha de frente as usam. A PC Gamer destaca que isso está em consonância com as observações do setor de que a gestão depende cada vez mais de ferramentas de IA.
Em comentários anônimos, apoiadores argumentaram que as críticas à IA generativa eram um "pânico moral", com alguns até mesmo afirmando que uma "plataforma que deixaria todos os desenvolvedores de jogos desempregados" estava sendo desenvolvida.
Os oponentes enfatizam que a IA generativa é "construída sobre roubo e plágio", produzindo conteúdo que é "uma mistura de materiais existentes". Um diretor de design de jogos britânico afirmou categoricamente: "Prefiro deixar esta indústria a usar IA generativa".
O relatório conclui que quanto mais os profissionais da indústria de jogos entendem de IA generativa, maior a probabilidade de terem reservas ou mesmo se oporem a ela; no entanto, na prática, muitos ainda precisam usar ferramentas relacionadas para não ficarem para trás na concorrência.
Pela primeira vez, a receita internacional da Kimi supera a receita doméstica, com o K2.5 impulsionando um aumento no número de usuários globais.
Segundo a Smart Emergence, a Kimi registrou um aumento significativo no desempenho do mercado internacional após o lançamento do seu novo modelo, o K2.5. A receita da empresa no exterior já ultrapassou a receita no mercado interno, e o número de usuários pagantes globais quadruplicou em apenas alguns dias após a atualização do modelo.
Entretanto, a popularidade do K2.5 no Openrouter está crescendo rapidamente, ocupando o terceiro lugar, atrás apenas do Claude Sonnet 4.5 e do Gemini 3 Flash.
O processo de comercialização da Kimi começou em outubro passado. De acordo com um memorando interno da empresa do final de 2025, desde novembro de 2025, a receita da API no exterior quadruplicou e a taxa de crescimento mensal de usuários pagantes, tanto no mercado interno quanto no externo, ultrapassou 170%.
O K2.5 é o modelo mais inteligente da Kimi até o momento, empregando uma arquitetura multimodal nativa que abrange capacidades como compreensão visual, geração de código, agrupamento de agentes e modos de pensamento e não pensamento.
Em testes de benchmark como HLE, BrowseComp e SWE-Bench Verified, o K2.5 alcança desempenho de ponta em sistemas de código aberto e supera modelos de código fechado como GPT-5.2 e Claude Opus 4.5 em algumas métricas.
Em termos de desenvolvimento de modelos, Kimi está gradualmente se aproximando de uma abordagem combinada de "Antrópico + Manus":
- Por um lado, fortalecemos nossa influência tecnológica ao abrir os pesos dos modelos e as cadeias de ferramentas;
- Por outro lado, o produto está claramente posicionado como uma ferramenta de produtividade, e as capacidades dos seus agentes são continuamente reforçadas.
O K2.5 pode agendar até 100 agentes e processar aproximadamente 1.500 etapas em paralelo, melhorando a eficiência de 3 a 10 vezes em cenários como a coleta de informações em larga escala.
O fundador da Kimi, Yang Zhilin, afirmou em uma sessão de perguntas e respostas no Reddit em 29 de janeiro que a taxa de crescimento de dados de alta qualidade não consegue mais acompanhar o crescimento do poder computacional, e o efeito marginal do método tradicional de escalonamento baseado em "prever o próximo token" está diminuindo.
Portanto, a equipe optou por ampliar as capacidades do modelo por meio do Agent Swarm, tratando o número de agentes paralelos como uma nova dimensão de expansão.
Em termos de produto, a Kimi continua a fortalecer seu posicionamento de produtividade voltado para o consumidor e renomeou o OK Computer, anteriormente testado internamente, para Kimi Agent, enfatizando uma marca unificada e recursos universais.
A equipe investiu bastante na capacidade de edição de cenários complexos, como dividir e editar elementos automaticamente após a geração de uma apresentação em PowerPoint, reconhecer a lógica da interface do usuário a partir de gravações de tela e gerar código de front-end, além de concluir automaticamente tarefas como anotações no Word, modelagem no Excel, geração de apresentações em PowerPoint e tradução e edição de PDFs.
Em dezembro passado, o presidente da Kimi, Zhang Yutong, declarou que a empresa controlaria deliberadamente os limites de seus negócios, concentrando-se na camada de modelos, na camada lógica, na camada de agentes e em vínculos de produtividade mais complexos, como pesquisa, apresentações em PowerPoint, análise de dados e desenvolvimento de sites.
Enquanto o setor geralmente se concentra em cenários essenciais, como programação e software de escritório, a Kimi também se esforça para manter sua posição de liderança em modelos básicos, ao mesmo tempo em que cria produtos para a interface do usuário com uma mentalidade única.
A febre dos vídeos com inteligência artificial diminuiu, e os downloads do aplicativo Sora caíram por dois meses consecutivos.

Segundo o TechCrunch, o aplicativo Sora da OpenAI, que liderou as paradas da App Store em outubro passado, mostrou recentemente sinais de desaceleração no crescimento.
De acordo com os dados mais recentes da Appfigures, os downloads do Sora caíram 32% em dezembro em comparação com o mês anterior e continuaram a declinar 45% em janeiro, registrando apenas 1,2 milhão de instalações. Os gastos dos consumidores também caíram 32% durante o mesmo período, de US$ 540.000 em dezembro para US$ 367.000 em janeiro.
O Sora, baseado no modelo de geração de vídeo Sora 2 da OpenAI, foi lançado inicialmente como um aplicativo exclusivo para iOS, acessível apenas por convite. Ultrapassou 100.000 instalações no primeiro dia e rapidamente alcançou o topo das paradas da App Store nos EUA. Acumulou 9,6 milhões de downloads e aproximadamente US$ 1,4 milhão em gastos dos usuários, sendo US$ 1,1 milhão provenientes dos Estados Unidos.
No entanto, desde o seu lançamento para dispositivos móveis, a popularidade do aplicativo tem diminuído continuamente. Atualmente, o Sora caiu para a 101ª posição no ranking geral da App Store dos EUA, e seu desempenho no Google Play é ainda mais fraco, ocupando apenas a 181ª posição na lista de aplicativos gratuitos.
O relatório sugere que múltiplos fatores contribuíram para esse declínio:
- O Google Gemini (especialmente o modelo Nano Banana) representa um grande desafio;
- O recurso de vídeo Vibes da Meta AI, lançado em outubro passado, atraiu um grande número de usuários;
- Sora tem sofrido pressão constante em relação à gestão de direitos autorais. Em seus primórdios, permitir que os usuários criassem vídeos com personagens populares impulsionou o crescimento, mas posteriormente a política de uso comercial de propriedade intelectual passou de "permitida por padrão" para "proibida por padrão", o que limitou o espaço para a criação de conteúdo.
- Apesar do anúncio feito pela OpenAI no mês passado sobre uma parceria com a Disney que permite a geração de vídeos usando personagens da Disney, isso ainda não resultou em um crescimento significativo.
Além disso, os recursos sociais do Sora também enfrentam desafios. Embora o aplicativo permita que os usuários "estrelem" vídeos com eles mesmos ou com seus amigos, muitos usuários não estão dispostos a permitir que outros usem sua imagem para gerar conteúdo; na ausência de rostos familiares e propriedades intelectuais populares, o interesse do usuário claramente diminuiu.
Quatro artigos da equipe de aplicação Qianwen C-end foram selecionados para o ICLR 2026.

Ontem, a equipe do aplicativo Qianwen C-end anunciou que quatro de seus artigos de pesquisa em inteligência artificial foram selecionados para a Conferência Internacional sobre Representações de Aprendizagem deste ano (ICLR 2026).
O artigo aborda áreas-chave como treinamento de modelos de difusão, tomada de decisão em diálogos com múltiplas interações, mecanismos de verificação de informações e alinhamento de valores. Alguns dos resultados foram implementados em produtos reais, visando aprimorar a estabilidade, a confiabilidade e a praticidade de assistentes de IA em cenários complexos.
A ICLR, juntamente com a NeurIPS e a ICML, é considerada uma das três principais conferências internacionais na área de aprendizado de máquina. A conferência deste ano recebeu quase 19.000 submissões, resultando em uma taxa de aceitação recorde de baixa nos últimos anos, o que tornou a competição acirrada.
Em sua pesquisa sobre Modelos de Difusão, a equipe decompôs a instabilidade de treinamento da máscara dLLM em três tipos de fontes de ruído e propôs um algoritmo de treinamento não enviesado Pareto-ótimo para reduzir significativamente as flutuações de treinamento e melhorar a qualidade da geração de imagens e textos.
Isso significa que os resultados da IA serão mais estáveis em aplicações como criação de conteúdo e geração de imagens/textos.
Na área de raciocínio em diálogos médicos com múltiplas interações, a equipe propôs o método de Otimização Adaptativa de Políticas em Árvore (ATPO, na sigla em inglês), que permite ao modelo ajustar dinamicamente o caminho do raciocínio de acordo com a incerteza do diálogo.
Quando as informações são insuficientes, a IA faz perguntas-chave proativamente; quando as pistas são claras, ela toma decisões rapidamente, o que permite à IA ter uma capacidade de "consulta proativa" semelhante à de médicos experientes em cenários profissionais, como consultas médicas, reduzindo as idas e vindas desnecessárias.
Na área de recuperação e verificação de informações, a equipe construiu uma estrutura de aprendizado por reforço de autojogo de "pergunta-resposta-verificação", que permite ao modelo se autoverificar e iterar continuamente sem anotação manual, melhorando assim as capacidades de recuperação e verificação em tarefas que exigem conhecimento intensivo.
No estudo sobre alinhamento de valores, a equipe introduziu métodos de eliminação de viés da teoria da informação para orientar o modelo de recompensa a se concentrar em sinais eficazes que sejam verdadeiramente relevantes para as preferências humanas, reduzir saídas longas, porém com baixa densidade de informação, e permitir que o modelo se concentre mais nas necessidades essenciais dos usuários durante o treinamento, reduzindo assim a ocorrência de respostas "superficialmente acomodativas".
Vale ressaltar que o código dos quatro artigos selecionados foi disponibilizado como código aberto, fornecendo à indústria referências técnicas reutilizáveis para melhorar a usabilidade e a confiabilidade da IA.
Editora musical processa Anthropic novamente: 20.000 músicas baixadas ilegalmente.

Segundo o TechCrunch, diversas editoras musicais entraram recentemente com um novo processo contra a Anthropic, acusando-a de baixar ilegalmente mais de 20.000 músicas, partituras, letras e obras musicais protegidas por direitos autorais sem autorização.
A indenização pode ultrapassar os 3 bilhões de dólares, tornando-se um dos maiores processos judiciais individuais por violação de direitos autorais na história dos EUA.
A editora afirmou que, durante o processo de coleta de provas no caso Bartz contra Anthropic no ano passado, descobriu que o alcance das infrações da Anthropic excedia em muito as aproximadamente 500 obras que haviam identificado anteriormente, com o número real de downloads pirateados chegando a dezenas de milhares.
Anteriormente, no caso Bartz, o juiz William Alsup decidiu que modelos de IA poderiam ser treinados com conteúdo protegido por direitos autorais, mas o método de obtenção do conteúdo não poderia ser ilegal; enquanto, no mesmo caso, a Anthropic foi condenada a pagar US$ 1,5 bilhão em indenizações por violação de direitos autorais, com aproximadamente 500.000 autores afetados recebendo cerca de US$ 3.000 cada em compensação.
Neste processo, as editoras salientaram que o tribunal rejeitou o seu pedido para adicionar alegações de pirataria ao processo original em outubro passado, porque as editoras não realizaram a investigação relevante anteriormente, pelo que optaram por apresentar um novo processo separadamente.
O processo também inclui o CEO da Anthropic, Dario Amodei, e o cofundador Benjamin Mann como réus.
Em seu comunicado, a editora afirmou que a Anthropic, embora se apresentasse como uma "empresa de segurança e pesquisa em IA", estava construindo um império comercial por meio de pirataria em larga escala, um comportamento seriamente inconsistente com sua imagem pública.
Wang Xingxing, da Yushu: Espera-se que robôs de uso geral se tornem realidade nos próximos dez anos; modelos em grande escala representam um avanço de nível "Prêmio Nobel" para o setor.

Recentemente, o programa "Sound of the Voice" lançou uma entrevista exclusiva com Wang Xingxing, fundador e CEO da Unitree Robotics. Na entrevista, Wang Xingxing discorreu sistematicamente sobre sua visão a respeito de robôs de uso geral, o caminho para a comercialização da inteligência incorporada e o futuro do setor.
Ele acredita que estamos atualmente em um momento crítico de aprimoramento inteligente e que robôs de uso geral são totalmente viáveis para "nossa geração", trazendo "mudanças revolucionárias" nos próximos dez anos, no mínimo.
Wang Xingxing afirmou que quem conseguir criar primeiro um modelo em larga escala que possa ser realmente usado por robôs se tornará a empresa de IA e robótica mais forte do mundo, "mais do que qualificada para ganhar um Prêmio Nobel".
Em sua visão, a inteligência não é limitada pelas leis da física, portanto, a Inteligência Artificial Geral (IAG) e os robôs de uso geral são teoricamente alcançáveis, e seu impacto na sociedade superará o das eras da máquina elétrica e a vapor.
Ao discutir o desenvolvimento do Unitree, Wang Xingxing relembrou sua experiência desde a criação de seu próprio robô humanoide em 2009 até a produção dos primeiros cães robóticos a um custo extremamente baixo, entre 2013 e 2016.
Ele enfatizou que o controle de custos e a integração de hardware e software são as principais vantagens competitivas da Unitree. A empresa está atualmente entre as maiores do mundo em remessas de vários de seus produtos institucionais, sendo que as pequenas unidades institucionais, por si só, representam dezenas de milhares de unidades enviadas anualmente, correspondendo a aproximadamente 60% da participação de mercado.
Em relação ao aumento da popularidade do setor, ele acredita que a explosão desde 2025 não é acidental, mas sim resultado da maturidade de tecnologias-chave como sistemas de energia, arquitetura conjunta e controle de IA de ponta a ponta. Em 2025, a Unitree Robotics terá comercializado mais de 5.500 robôs humanoides, com mais de 6.500 unidades produzidas em massa.
Em relação à comercialização, Wang Xingxing enfatizou que a receita e o lucro são a base da sobrevivência das empresas de hardware, e que as startups não podem depender de financiamento.
Ele destacou que muitos fracassos no setor decorrem de erros na definição do produto, recrutamento, comercialização e operações, enquanto os pontos em comum das empresas de sucesso residem no rigor, na execução impecável, na aprendizagem contínua e na iteração constante.
Em relação aos cenários de aplicação futuros, ele acredita que, a curto prazo, os robôs realizarão tarefas básicas em cenários B2B, como salas de conferência e shoppings; devido aos maiores requisitos de segurança, sua adoção em ambientes domésticos será adiada. Ele enfatizou que o objetivo final da Unitree é permitir que os robôs realmente "trabalhem" e criem valor real para a sociedade .
Wang Xingxing também falou sobre sua experiência de crescimento pessoal. Ele disse que, desde criança, possuía grande habilidade prática e uma personalidade sensível e introvertida. Essa sensibilidade o ajudou posteriormente a ser cauteloso em contratos, avaliação de riscos e gestão de equipes.
Ele admitiu que estava extremamente ansioso nos estágios iniciais da criação de sua empresa. Quando se demitiu em 2016 para abrir o próprio negócio, não tinha fundos suficientes e sua equipe era composta por apenas três ou quatro pessoas. No entanto, sua persistência em buscar avanços tecnológicos e lançar produtos permitiu que a empresa gradualmente entrasse no caminho certo.
A Shengshu Technology lança o Vidu Q3, levando a geração de vídeo para o estágio de "produção de filmes com um clique".

Ontem, a Vidu anunciou o lançamento de seu novo modelo de vídeo de terceira geração, o Vidu Q3, "feito para dramas" e que destaca suas amplas melhorias em narrativa multicâmera, sincronização audiovisual e renderização multilíngue.
O Vidu Q3 é o primeiro modelo do mundo a suportar saída de áudio e vídeo de 16 segundos, capaz de concluir a renderização de imagem, som, movimento de câmera e texto em uma única geração, melhorando significativamente a eficiência de produção de curtas-metragens, histórias em quadrinhos e conteúdo para cinema e televisão.
Segundo o comunicado oficial, o modelo consegue gerar narrativas "em plano-sequência", suporta diálogos com múltiplos personagens, controle do ritmo emocional e transições complexas, e o conteúdo gerado pode ser entregue diretamente como um filme finalizado.
Em termos de funcionalidade, o Vidu Q3 possui as seguintes capacidades:
- Suporta geração de vídeos com duração de até 16 segundos, com saída de áudio e vídeo sincronizada;
- É possível alternar livremente entre vários ângulos de câmera, e o enquadramento pode ser ajustado automaticamente de acordo com a tensão da trama;
- Permite a integração perfeita de textos em chinês, inglês e japonês na tela;
- É adequado para diversas indústrias e cenários, incluindo histórias em quadrinhos, curtas-metragens e séries de cinema e televisão, e enfatiza as capacidades de produção industrializada.
Segundo a Shengshu Technology, o Vidu Q3 ficou em primeiro lugar na China e em segundo lugar globalmente no ranking mais recente da Artificial Analysis, uma organização internacionalmente reconhecida de avaliação comparativa de IA, à frente do Musk xAI Grok, Runway Gen-4.5, Google Veo 3.1 e OpenAI Sora 2.
A SenseTime disponibiliza o SenseNova-MARS em código aberto, cujo desempenho em inferência multimodal supera o do Gemini-3-Pro.
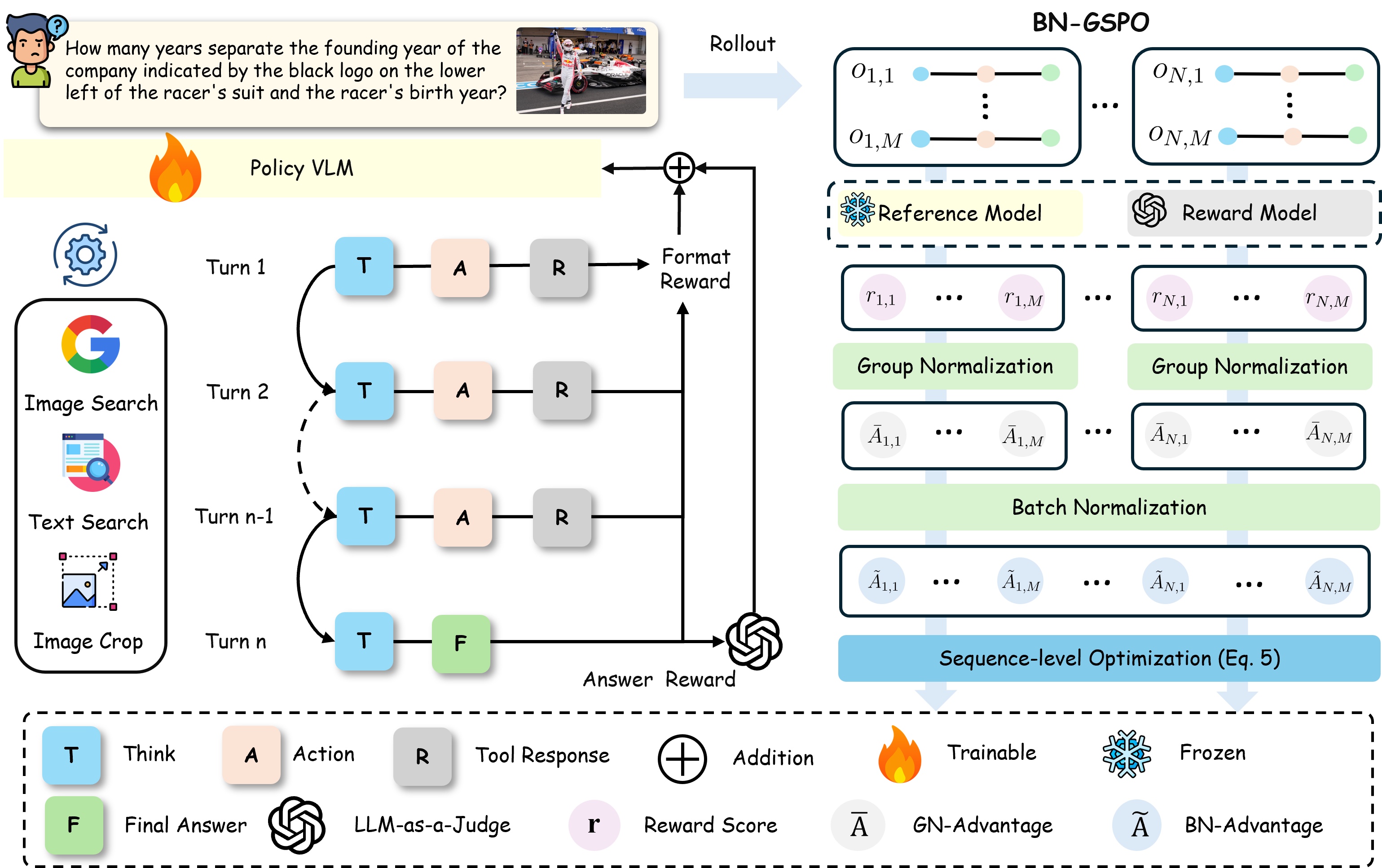
Ontem, a SenseTime anunciou a disponibilização oficial em código aberto do seu modelo de raciocínio autônomo multimodal, o SenseNova-MARS. Posicionado como um VLM (Modelo de Linguagem Visual) Agético, ele enfatiza a capacidade de "planejar etapas de forma autônoma e colaborar com múltiplas ferramentas" e oferece duas versões: 8B e 32B.
Segundo informações, o modelo alcançou uma pontuação abrangente de 69,74 no teste de referência principal de busca e inferência multimodal, superando modelos proprietários como Gemini-3-Pro e GPT-5.2, e ficando entre os melhores em múltiplas comparações entre modelos de código aberto e proprietários.
O modelo é treinado por meio de aprendizado por reforço (RL), permitindo que ele invoque dinamicamente ferramentas como recorte de imagem, busca de texto e busca de imagem durante a inferência, alcançando assim o processamento de tarefas complexas em diversas modalidades e etapas.
Em termos de desempenho, o SenseNova-MARS-32B obteve 74,27 e 54,43 pontos, respectivamente, em testes orientados à busca, como o MMSearch e o HR-MMSearch, superando o Gemini-3-Pro e o GPT-5.2.
Em aplicações práticas, o SenseNova-MARS consegue lidar com tarefas complexas que envolvem reconhecimento de detalhes, recuperação de informações e raciocínio lógico. Exemplos incluem o reconhecimento de logotipos minúsculos em macacões de corrida, a consulta de históricos de empresas e a comparação de informações pessoais. Ele também pode realizar todo o processo de raciocínio sem intervenção humana.
Em termos de métodos de treinamento, o modelo adota um mecanismo de duas etapas de "síntese automática de dados + aprendizado por reforço":
- A primeira etapa gera dados de inferência de múltiplos saltos altamente complexos por meio de agentes multimodais e incorpora verificações de consistência em circuito fechado para reduzir ilusões;
- A segunda etapa utiliza o algoritmo BN-GSPO para melhorar a estabilidade do treinamento de RL, permitindo que o modelo mantenha um desempenho consistente em cenários que envolvem múltiplas ferramentas.
Atualmente, o modelo, o código e o conjunto de dados foram totalmente disponibilizados como código aberto no GitHub e no Hugging Face.
Artigo: https://arxiv.org/abs/2512.24330
 GitHub: https://github.com/OpenSenseNova/SenseNova-MARS
GitHub: https://github.com/OpenSenseNova/SenseNova-MARS
 Hugging Face: https://huggingface.co/sensenova/SenseNova-MARS-8B
Hugging Face: https://huggingface.co/sensenova/SenseNova-MARS-8B
AntLingbo Open Source LingBot-VA: Permitindo que modelos do mundo controlem diretamente as ações do robô.
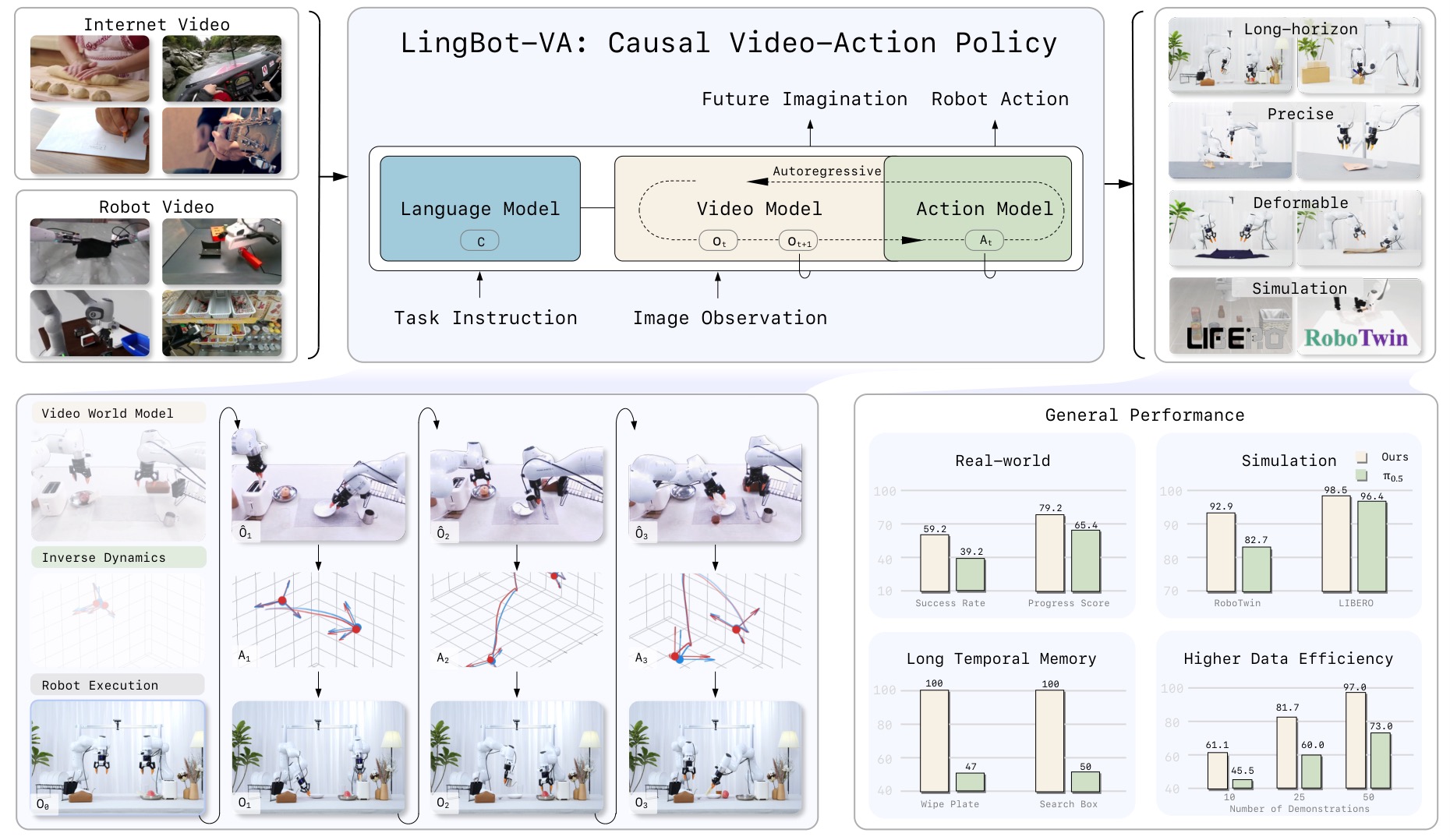
Ontem, a Ant Lingbo Technology anunciou a disponibilização em código aberto do modelo de mundo incorporado LingBot-VA.
Este modelo propõe uma estrutura de modelagem de mundo baseada em vídeo-ação autorregressiva que integra profundamente modelos de geração de vídeo em larga escala com o controle de robôs. Ele pode deduzir e gerar sequências de ações diretamente, ao mesmo tempo que gera o "próximo estado do mundo", permitindo que os robôs "deduzam e ajam simultaneamente", como os humanos.
Em testes com dispositivos reais, o LingBot-VA demonstrou alta adaptabilidade a interações físicas complexas, abrangendo seis tarefas desafiadoras em três categorias: longa duração, alta precisão e manipulação flexível de objetos. A adaptação pode ser concluída com apenas 30 a 50 pontos de dados de demonstração em dispositivos reais, e a taxa de sucesso das tarefas é, em média, 20% maior em comparação com o robusto modelo de referência do setor, o Pi0.5.
Na avaliação por simulação, o modelo alcançou, pela primeira vez, uma taxa de sucesso superior a 90% no benchmark de operação colaborativa de dois braços RoboTwin 2.0 e atingiu uma taxa média de sucesso de 98,5% no benchmark de aprendizado contínuo de longo prazo LIBERO, ambos estabelecendo novos recordes na indústria.
O LingBot-VA emprega uma arquitetura de Mistura de Transformadores (MoT) para alcançar a fusão multimodal de processamento de vídeo e controle de movimento. Seu mecanismo de inferência em circuito fechado incorpora feedback do mundo real em cada etapa de geração, garantindo que o processo de inferência não se desvie da realidade física.
Para solucionar o gargalo computacional da implantação de modelos de vídeo em larga escala na borda do robô, o modelo introduz pipelines de inferência assíncrona, cache de memória persistente e estratégias de aprimoramento do histórico de ruído, permitindo combinar a profundidade de compreensão de grandes modelos com recursos de controle de baixa latência.
O LingBot-VA, juntamente com o LingBot-World (ambiente de simulação), o LingBot-VLA (base inteligente) e o LingBot-Depth (percepção espacial), já disponibilizados como código aberto, forma uma capacidade sistêmica.
A LingBot, da Ant Financial, declarou que aproveitará a comunidade InclusionAI para promover continuamente o código aberto e a colaboração com a indústria no desenvolvimento de capacidades de inteligência incorporada, além de acelerar a construção de um ecossistema de Inteligência Artificial Geral (IAG) voltado para cenários industriais reais. Atualmente, os pesos do modelo e o código de inferência do LingBot-VA são totalmente de código aberto.
Hugging Face: https://huggingface.co/robbyant/lingbot-va-base
A Baidu disponibiliza o código aberto do PaddleOCR-VL-1.5, cuja precisão na análise de documentos supera a do DeepSeek-OCR2.
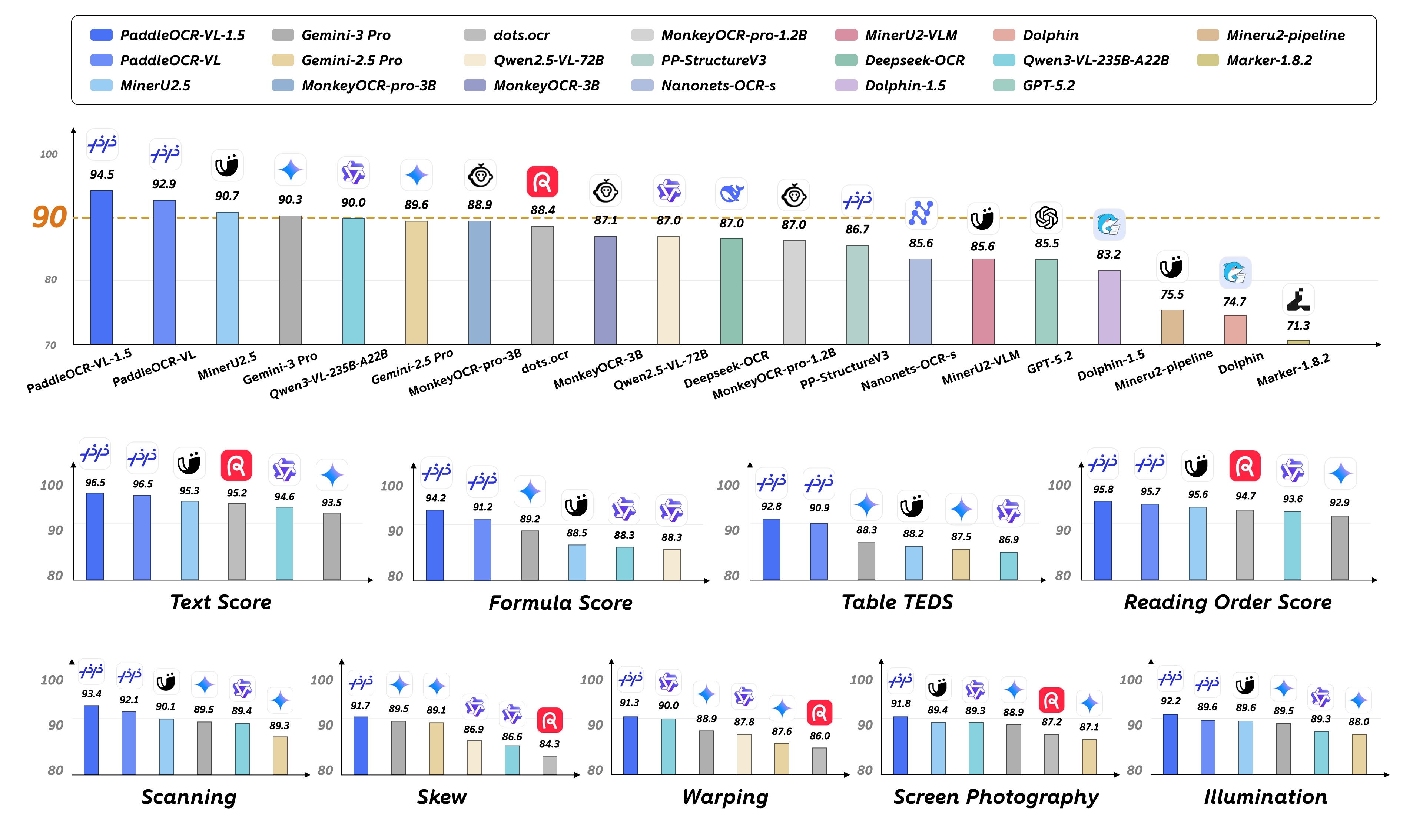
Ontem, a Baidu lançou oficialmente e disponibilizou em código aberto seu modelo de análise de documentos de última geração, o PaddleOCR-VL-1.5.
Segundo relatos, o modelo alcançou o melhor desempenho geral no benchmark de análise de documentos OmniDocBench V1.5, considerado referência mundial, com uma precisão geral de 94,5%, superando modelos convencionais como DeepSeek-OCR2, Gemini-3-Pro, Qwen3-VL-235B-A22B e GPT-5.2.
O PaddleOCR-VL-1.5 emprega uma arquitetura leve com apenas 0,9 bilhão de parâmetros, mas alcança desempenho líder em diversas métricas importantes. Especificamente, ele obtém 92,8 pontos na compreensão da estrutura de tabelas e 95,8 pontos na previsão da ordem de leitura, ambos os resultados classificando-o em primeiro lugar no ranking.
A Baidu afirmou que, na tarefa de prever a ordem de leitura de documentos, a taxa de erro da análise da lógica de layout de página do modelo é apenas cerca de metade da de modelos semelhantes, e apresenta maior estabilidade e usabilidade em cenários de documentos de alta complexidade, como contratos e relatórios financeiros.
Outro avanço fundamental desta versão reside na sua capacidade de "localização de caixas delimitadoras irregulares". A Baidu afirma que esta é a primeira vez no mundo que um modelo de OCR consegue reconhecer de forma estável formatos de documentos irregulares, como inclinados, dobrados e com distorções fotográficas, melhorando significativamente a taxa de sucesso na análise de documentos em condições de fotos em movimento, documentos digitalizados distorcidos e iluminação complexa.
Essa funcionalidade pode ser aplicada a cenários de negócios reais, como processamento de contas financeiras, digitalização de documentos e circulação de documentos governamentais.
Em termos funcionais, o PaddleOCR-VL-1.5 integra ainda mais o reconhecimento de selos, a detecção de texto e as capacidades de reconhecimento com base na geração anterior, e otimiza estruturas complexas, como caracteres raros, documentos antigos, tabelas multilíngues, sublinhados e caixas de seleção.
Entretanto, o modelo adiciona suporte para idiomas como tibetano e bengali, e suporta a fusão automática de tabelas entre páginas e o reconhecimento de títulos de parágrafos entre páginas para atenuar o problema de quebra estrutural na análise de documentos longos.
GitHub: https://github.com/PaddlePaddle/PaddleOCR
Hugging Face: https://huggingface.co/PaddlePaddle/PaddleOCR-VL-1.5
 ModelScope: https://modelscope.cn/models/PaddlePaddle/PaddleOCR-VL-1.5
ModelScope: https://modelscope.cn/models/PaddlePaddle/PaddleOCR-VL-1.5
Data de lançamento da série Samsung Galaxy S26 revelada: 25 de fevereiro.
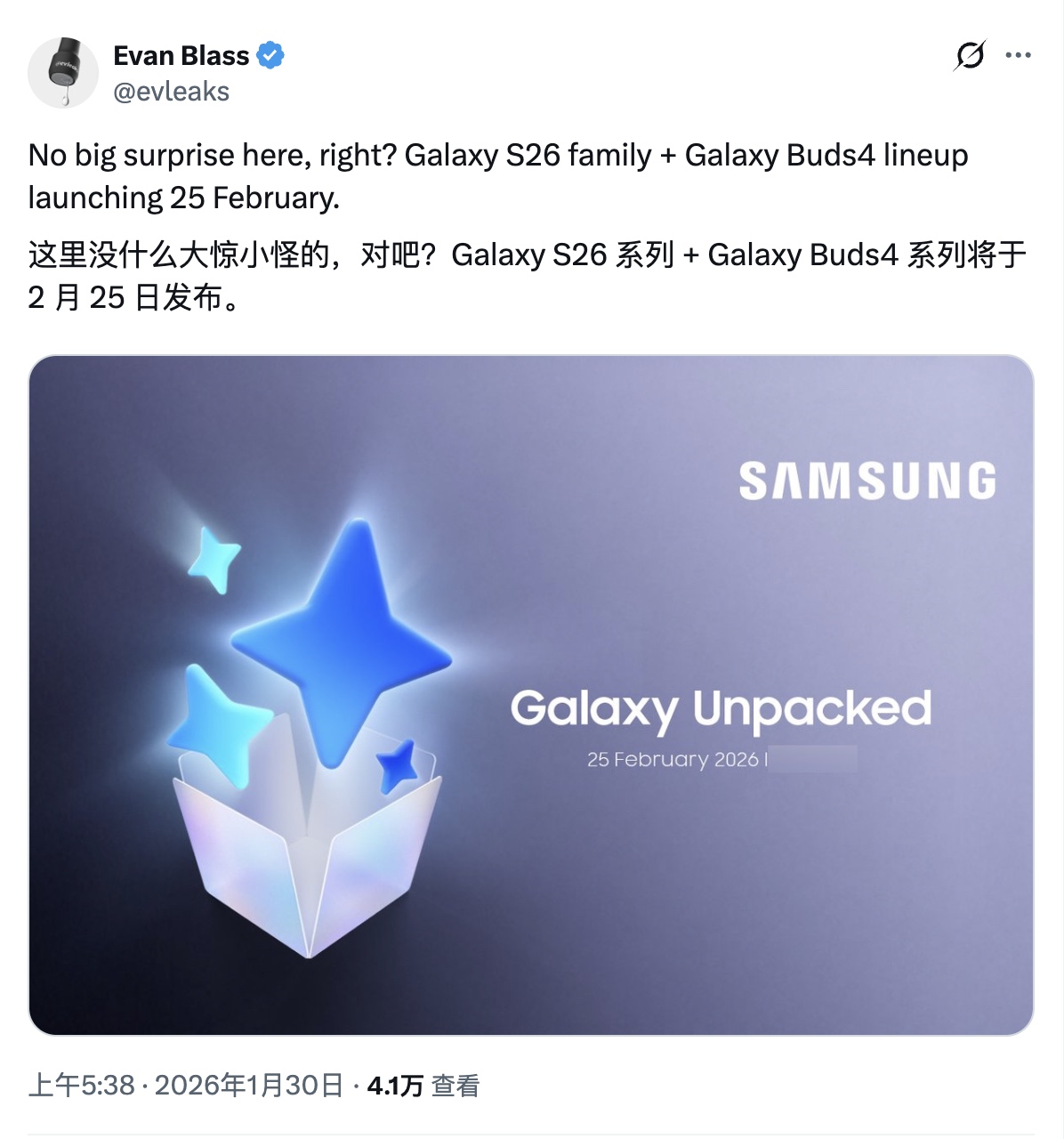
Segundo o Android Authority, a data do próximo evento Galaxy Unpacked da Samsung vazou.
O conhecido informante Evan Blass compartilhou o que parece ser um pôster oficial, sugerindo que a série Galaxy S26 será oficialmente apresentada em 25 de fevereiro.
Em comparação com o lançamento da série S25 em janeiro do ano passado, o lançamento deste ano foi atrasado em cerca de um mês. Relatos indicam que o motivo está relacionado a ajustes temporários da Samsung em sua linha de produtos e ao cancelamento do modelo Edge.
As informações do pôster são consistentes com vazamentos anteriores. O relatório menciona que, embora a Samsung tenha confirmado anteriormente o lançamento de um novo modelo topo de linha no primeiro semestre deste ano, a promoção oficial ainda não começou. Além da prévia do recurso "Tela de Privacidade", já anunciado para o modelo Ultra, nenhum outro detalhe foi divulgado pela empresa.
Segundo informações vazadas, o Galaxy S26, S26 Plus e S26 Ultra estarão disponíveis para pré-venda imediatamente após o evento de lançamento, com as vendas ao público previstas para começar em 11 de março.
Além disso, a Samsung também lançará a série Galaxy Buds 4 no mesmo evento. Este produto já foi alvo de diversos vazamentos, e os últimos indicam que seu preço será semelhante ao da série Buds 3.
A Three Squirrels divulgou sua previsão de lucros para 2025, prevendo que o lucro líquido poderá atingir um novo mínimo histórico.

Segundo o Jiemian News, a Three Squirrels divulgou recentemente sua previsão de desempenho anual para 2025, projetando um lucro líquido atribuível aos acionistas da empresa listada entre 135 milhões e 175 milhões de yuans, uma queda anual de 57,08% a 66,89%.
O lucro líquido, excluindo ganhos e perdas não recorrentes, deverá ficar entre 45 milhões e 65 milhões de RMB, representando uma queda adicional de 79,64% a 85,91% em relação ao ano anterior. Os dados relevantes ainda não foram auditados e os resultados finais serão divulgados no relatório anual deste ano.
No dia da divulgação da previsão de lucros, o preço das ações da empresa apresentou uma breve recuperação, fechando a 24,88 yuans em 29 de janeiro, uma alta de 4,85%. No entanto, o preço das ações voltou a cair após a abertura do pregão seguinte e, no momento da publicação desta notícia, estava cotado a 24,24 yuans, com uma capitalização de mercado total de aproximadamente 9,736 bilhões de yuans.
A Three Squirrels atribuiu sua acentuada queda nos lucros a múltiplos fatores:
- Em primeiro lugar, a época de pico de vendas sofreu um desalinhamento estrutural, aliado a um aumento acentuado no preço da matéria-prima (nozes). A empresa ajustou proativamente sua estrutura de vendas, resultando em uma compressão das margens de lucro.
- Em segundo lugar, a redução da produção nas principais regiões produtoras de nozes em todo o mundo, devido às mudanças climáticas, aumentou ainda mais os custos das matérias-primas.
- Além disso, o investimento estratégico da empresa no novo setor de varejo comunitário também impactou seus lucros de curto prazo.
Historicamente, o desempenho da empresa atingiu seu pico em 2021, com lucro líquido atribuível à controladora de 411 milhões de yuans. Posteriormente, afetada por fatores como a intensificação da concorrência no setor e a queda nos dividendos do comércio eletrônico, os lucros oscilaram, caindo para 129 milhões de yuans e 220 milhões de yuans em 2022 e 2023, respectivamente, antes de se recuperarem para 408 milhões de yuans em 2024.
Nos três primeiros trimestres deste ano, a receita da empresa aumentou 8,22% em relação ao ano anterior, atingindo 7,759 bilhões de yuans, mas o lucro líquido atribuível à controladora diminuiu 52,91% em relação ao ano anterior, para 161 milhões de yuans, e o lucro líquido, excluindo itens não recorrentes, diminuiu 78,57%.
Para aliviar a pressão sobre os custos, a Three Squirrels aumentou os preços de fornecimento de 35 produtos principais em outubro passado, com aumentos que variaram de 0,2 yuan a 10 yuan, e alguns produtos com aumentos superiores a 20%. Em janeiro deste ano, a empresa ajustou novamente o preço de fábrica do seu conjunto de nozes para presente, distribuído offline, mas o aumento de preço ainda não cobriu totalmente a pressão sobre os custos causada pelo aumento dos preços das matérias-primas.
Atualmente, as nozes ainda representam cerca de 50% da receita da empresa, enquanto as duas categorias emergentes de produtos assados e lanches em geral representam menos de 40% combinadas, e a concorrência é acirrada.
Em termos de canais online, Douyin, Tmall e JD.com contribuíram com 78,42% da receita. No entanto, a taxa de crescimento do canal Douyin desacelerou de 81,73% em 2024 para 20,75% no primeiro semestre deste ano, indicando uma clara tendência de enfraquecimento dos dividendos do tráfego.
Especialistas do setor acreditam que a pressão por desempenho da Three Squirrels é um microcosmo da intensificação da concorrência no setor de snacks casuais como um todo. Com a aproximação do pico de crescimento do tráfego, as empresas enfrentam um equilíbrio mais difícil entre o desempenho a curto prazo e o desenvolvimento de capacidades a longo prazo.
No mercado offline, marcas de snacks populares como Ling Shi Hen Mang e Zhao Yiming Snacks tiveram um impacto significativo nas marcas tradicionais, oferecendo altas relações custo-benefício e rápida expansão.
Gostaria de responder à reclamação da loja sobre a cobrança excessiva pela pesagem dos itens: a empresa alega que foi devido a um erro operacional de um funcionário novo.
Segundo o Jiemian News, a marca de salgadinhos popular "Haoxianglai" chamou a atenção recentemente devido a alegações de que cobra preços abusivos dos clientes pela pesagem dos produtos em suas lojas.
O incidente teve origem num consumidor que comprou 23 salgadinhos numa loja na cidade de Cixi, província de Zhejiang, na China. Ao chegar em casa e pesar os itens, descobriu que o peso real de muitos dos produtos era inferior ao resultado da pesagem na loja, com uma diferença total de aproximadamente 129 gramas. Segundo seus cálculos, ele pagou 6,41 yuans a mais.
A Haoxianglai afirmou que, após tomar conhecimento do problema, realizou uma investigação interna e confirmou que a causa foi um erro operacional de um funcionário recém-contratado. O funcionário em questão já recebeu treinamento adicional. A empresa também informou que entrou em contato proativamente com o consumidor para se desculpar e negociar uma compensação.
Vídeos publicados anteriormente por consumidores mostraram que vários produtos apresentavam diferenças de peso consideráveis. Por exemplo, o broto de bambu e a linguiça de frango pesavam 76 gramas na loja, mas 62,2 gramas quando pesados pelo consumidor; as asas de frango assadas com sal da Wufeng pesavam 216 gramas na loja, mas 202 gramas quando pesadas pelo consumidor.
Outros itens como queijo triangular, bolos de trigo, pães de queijo, algas marinhas, doces pequenos, pão e coxas de frango também apresentam uma diferença de cerca de 12 gramas.
O consumidor também afirmou que Haoxianglai havia reclamado à plataforma solicitando a remoção do vídeo, alegando "filmagem encenada e autenticidade incerta".
Um funcionário do Departamento de Supervisão de Mercado Municipal de Cixi afirmou que o órgão regulador inspecionou as balanças da loja em questão em 27 de janeiro e não encontrou anormalidades. A Haoxianglai enfatizou que todos os instrumentos de medição em suas lojas são calibrados e passam por inspeção, e que um sistema de calibração diária é implementado; quaisquer erros detectados resultarão em descontinuação, reparo ou substituição imediatos.
Informações públicas indicam que Haoxianglai é uma marca do Grupo Wancheng. Em 2023, o grupo consolidou um sistema operacional unificado ao integrar diversas marcas de snacks. Sua sede está localizada em Nanjing, província de Jiangsu, e possui quase 2.000 SKUs (unidades de manutenção de estoque).
Com base no volume total de mercadorias (GMV) em 2024, o grupo ficou em primeiro lugar no mercado varejista de snacks e bebidas da China, com um GMV de 42,6 bilhões de yuans. O Grupo Wancheng submeteu seu pedido de listagem na Bolsa de Valores de Hong Kong no ano passado, e sua receita no primeiro semestre de 2025 atingiu 22,583 bilhões de yuans, um aumento de 106,89% em relação ao ano anterior, dos quais quase 99% vieram do segmento de snacks a granel.
O álbum Sanctuary foi lançado mundialmente.

Ontem, o filme Sanctuary foi lançado mundialmente, juntamente com um trecho intitulado "Deadly Struggle" e um pôster com a data de lançamento.
O filme conta a história do agente Michael Mason, que vive isolado em uma ilha remota, mas é forçado a retornar ao campo de batalha para resgatar uma jovem chamada Jessie. Enquanto é perseguido pela organização Black Kite, ele descobre uma conspiração e embarca em uma fuga de vida ou morte.
Como continuação da série "Jason 'n' Roll", Sanctuary Land se tornou uma escolha popular entre os fãs de filmes de ação. Durante os eventos de pré-estreia, os fãs tiraram fotos vestidos como os personagens e recriaram cenas icônicas, e após a exibição, alguns espectadores expressaram a intenção de assistir ao filme uma segunda vez.
 É fim de semana!
É fim de semana!
Uma curiosidade divertida | Jackie Chan, de 70 anos, "novato", junta-se oficialmente ao Xiaohongshu, conquistando mais de 80.000 seguidores no primeiro dia.

Ontem, o ator Jackie Chan entrou oficialmente para o Xiaohongshu (Pequeno Livro Vermelho). Sua biografia na conta diz: "Novato de 70 anos no Xiaohongshu, reportando-se! Fazendo coisas sérias da maneira mais feliz possível." Ele já atraiu aproximadamente 82.000 seguidores.
O primeiro vídeo de Jackie Chan foi uma autoapresentação, na qual ele expressou sua esperança de se tornar amigo de todos os "momos" e disse que interagiria frequentemente com a plataforma no futuro.
Jackie Chan também postou uma mensagem de voz na seção de comentários, dizendo que sabe que o Xiaohongshu é um "lugar particularmente divertido e espirituoso", mas que ainda não está muito familiarizado com ele, já que acabou de entrar. Ele espera que os usuários possam se tornar seus "guias do Xiaohongshu" e perguntou aos internautas: "Qual é a coisa mais popular no Xiaohongshu?"
Essa mudança gerou discussões acaloradas entre os usuários da plataforma, com as interações relacionadas aumentando cada vez mais.
O que assistir neste fim de semana | O clássico suspense psicológico "O Iluminado" retorna aos cinemas

O clássico thriller psicológico "O Iluminado" começou oficialmente ontem seu relançamento em 4K nos cinemas da China continental.
O filme é uma adaptação do romance homônimo de Stephen King e há muito tempo é considerado uma obra de referência no gênero de terror desde seu lançamento em 1980. A trama gira em torno do escritor Jack Torrance, que é contratado para cuidar do Hotel Overlook durante o inverno e se muda para lá com sua esposa Wendy e seu filho Danny.
Após a forte nevasca bloquear a passagem da montanha, apenas três pessoas permaneceram no hotel. Danny gradualmente desenvolveu poderes "brilhantes", tendo estranhas alucinações no hotel; Wendy percebeu que seu marido estava perdendo o controle das emoções; Jack gradualmente sucumbiu ao confinamento e à pressão psicológica, o que acabou levando a explosões violentas.
O filme utiliza composição simétrica, planos-sequência e a tecnologia Steadicam para criar uma sensação de opressão, tornando-se um exemplo representativo da estética e da inovação de gênero de Kubrick. Possui uma classificação de 8,3 no Douban, com mais de 580.000 avaliações, figurando entre os filmes de terror mais bem avaliados.
Um guia para comprar livros sem lê-los: *O Narrador Gentil*

A primeira obra de Olga Tokarczuk após ganhar o Prêmio Nobel de Literatura, "A Narradora Gentil", contém 12 ensaios, discursos e notas, abrangendo múltiplas dimensões, incluindo literatura, psicologia, filosofia, mitologia e biologia.
Em seu livro, ela continua a questionar "como contar a história do mundo": opondo-se à tradição de "narradores oniscientes" desde o século XIX e defendendo a compreensão da realidade de uma forma que acomode contradições e preserve a ambiguidade.
Na era das redes sociais, ela propôs a metáfora da "síndrome da esposa de Rhodes", que aponta para o dilema cognitivo das pessoas que estão constantemente olhando para trás e se entregando a informações fragmentadas, impulsionadas por algoritmos.
"Recusar-se a ver significa tornar-se cúmplice do mal, e a própria linguagem molda a forma como entendemos os outros." Ela fez um apelo aos escritores para que inventassem "linguagens pessoais" independentes, tão únicas quanto impressões digitais, capazes de resistir à influência obscura da linguagem coletiva e de renomear o mundo.
Recomendação de jogo | Jogo de sobrevivência e escalada "Lone Mountain"

Lonely Mountain é um jogo de escalada e sobrevivência desenvolvido pela The Game Bakers, com mecânicas de escalada altamente realistas e uma aventura guiada pela narrativa em seu núcleo.
Os jogadores assumem o papel de Aiva, uma alpinista profissional, cujo objetivo é escalar a traiçoeira montanha conhecida como "Monte Deus".
O jogo apresenta um design de escalada livre, onde os jogadores podem encontrar pontos de apoio na parede rochosa, ajustar sua postura e equilíbrio e resolver desafios de escalada em diferentes terrenos.
Se um jogador cometer um erro, seu personagem cairá de uma grande altura, criando uma tensão intensa. A equipe de desenvolvimento trata cada parede de rocha como uma "batalha contra um chefe", enfatizando um desafio completo que exige força física, ritmo e estratégia.
A trama gira em torno dos objetivos pessoais de Eva. Os jogadores encontrarão outros alpinistas durante a escalada, ouvirão suas histórias e descobrirão gradualmente o contexto histórico da cordilheira.
A narrativa centra-se no "preço dos sonhos" e no "significado dos desafios extremos", apresentando uma jornada que combina solidão e exploração.
A gestão de recursos é outro mecanismo fundamental, incluindo pitons, pó antiderrapante, bandagens para as mãos, comida, água e medicamentos. Os jogadores precisam montar acampamentos e coletar suprimentos na montanha para manter sua capacidade de sobrevivência em longas escaladas.
Em termos de preço, Lonely Mountain custa 108 yuans no Steam na China, com um desconto de 10% no lançamento, reduzindo o preço para 97,2 yuans. O Steam atualmente possui 780 avaliações de jogadores, com uma classificação geral de "Muito Positiva".
#Siga a conta oficial do iFanr no WeChat: iFanr (ID do WeChat: ifanr), onde você encontrará conteúdo ainda mais interessante o mais breve possível.