
Os supercomputadores pessoais da Nvidia podem ser as próximas placas gráficas para o consumidor final.
Na apresentação principal da CES deste ano, Jensen Huang, de forma incomum, não apresentou as placas gráficas para consumidores da Nvidia.
As GPUs mais recentes para o consumidor final ainda são da série RTX 50, lançadas oficialmente na CES do ano passado. Isso se deve, sem dúvida, em parte ao aumento global dos preços da memória; os custos atuais da memória podem aumentar de 50% a 100% em uma semana, e vários analistas preveem que esse aumento de preço continuará até 2027.
O principal motivo é a IA, como por exemplo, o treinamento e a implementação de IA. Uma placa de vídeo RTX 5090 tem um máximo de 32 GB de memória de vídeo. Se você encontrar um modelo grande de código aberto decente, os parâmetros chegam às dezenas de bilhões, e a capacidade de memória de vídeo necessária é limitada.

No entanto, a Nvidia claramente não vai desistir do mercado local de computadores. Este ano, em vez de lançar placas gráficas para o consumidor final, lançou um supercomputador pessoal totalmente novo voltado para o consumidor.
Na CES 2026, a NVIDIA apresentou seu novo DGX Spark e o utilizou para concluir diversas tarefas relacionadas à IA. Desenvolvedores e criadores não precisam mais de data centers caros; com o DGX Spark, eles podem executar, ajustar e até mesmo inferir modelos de IA de ponta com até 100 bilhões de parâmetros localmente, sem problemas.
Já compartilhamos anteriormente nossa experiência prática com o DGX Spark, mostrando como ele pode lidar com tarefas como baixar um modelo de código aberto GPT-OSS com 120 bilhões de parâmetros ou implantar a geração de imagens Qwen e a geração de vídeo Wan 2.2.
Vamos analisar as principais funcionalidades do DGX Spark.

- Arquitetura principal: Construída sobre a arquitetura NVIDIA Grace Blackwell, ela condensa o poder de computação de IA de nível de data center em um chassi de desktop compacto.
- Memória massiva: Cada máquina está equipada com 128 GB de memória unificada. Mais importante ainda, suporta a interconexão de duas máquinas DGX Spark através de uma rede ConnectX-7 de 200 Gbps para formar um supernó com 256 GB de memória.
- Funcionalidades principais: Projetado especificamente para a era dos grandes modelos, ele suporta a execução local de modelos com 100 bilhões de parâmetros ou a realização de ajustes finos distribuídos de modelos lineares de grande escala (LLMs) com 70 bilhões de parâmetros.
- Posicionamento: Não é apenas um ambiente de testes para desenvolvedores, mas também uma plataforma para criadores de IA, principalmente para permitir que cargas de trabalho de IA de alta intensidade sejam concluídas localmente com segurança e baixa latência, liberando-os da dependência da nuvem.
O grande destaque da atualização da CES deste ano é a introdução do suporte completo ao formato de dados NVFP4 por meio de uma atualização de software. O formato de dados NVFP4 permite que os modelos de próxima geração mantenham o desempenho inteligente, reduzindo o uso de memória em aproximadamente 40% e aumentando significativamente a taxa de transferência.
Em dados de teste específicos, ao executar o modelo Qwen-235B em duas configurações DGX Spark, o uso de NVFP4 resultou em uma melhoria de desempenho de até 2,6 vezes em comparação com FP8. Isso resolve diretamente o problema de esgotamento de memória em sistemas duplos e a incapacidade de realizar multitarefas ao usar a precisão FP8 anteriormente.
O hardware está instalado na mesa, mas o acesso pode ser feito na nuvem. A atualização Brev apresentada na CES também resolve a falta de flexibilidade na capacidade de computação local do DGX Spark.
Agora, os desenvolvedores podem se conectar ao DGX Spark remotamente e com segurança via Brev, como se estivessem usando um serviço em nuvem. Além disso, o Brev oferece suporte a uma camada de roteamento inteligente. Os usuários podem forçar a execução de tarefas sensíveis, como o processamento de e-mails ou dados proprietários, localmente no DGX Spark, enquanto roteiam perfeitamente as tarefas de inferência geral para a nuvem, equilibrando privacidade e poder de computação em nuvem.
A introdução do Brev resolve o problema da capacidade de computação local não só ser utilizável, mas também fácil de usar. O lançamento oficial do seu suporte para computação local está previsto para a primavera de 2026.
Para que serve um poder computacional tão grande? A demonstração da NVIDIA na CES deu a resposta.
Para criadores de vídeo, este é um poderoso acelerador para a produção criativa. Transferir tarefas de geração de vídeo com IA de um laptop para o DGX Spark resulta em velocidades até 8 vezes maiores em comparação com um MacBook Pro de última geração com um M4 Max, eliminando completamente a latência no fluxo criativo.
O DGX Spark não é apenas adequado para desenvolvedores individuais, mas também pode atender usuários corporativos que priorizam a segurança local. A NVIDIA apresentou um assistente de codificação CUDA local com tecnologia Nsight, permitindo que desenvolvedores corporativos desfrutem da assistência de IA, garantindo que o código-fonte seja armazenado inteiramente localmente, eliminando o risco de vazamento de informações.
Uma demonstração ainda mais interessante foi a sua integração com robôs. Através de uma colaboração com a Hugging Face, o DGX Spark tornou-se o "cérebro" do robô Reachy Mini, conferindo-lhe capacidades de interação audiovisual em tempo real. Agora, parece que a utilização do DGX Spark para inteligência incorporada já não é domínio exclusivo das grandes empresas.
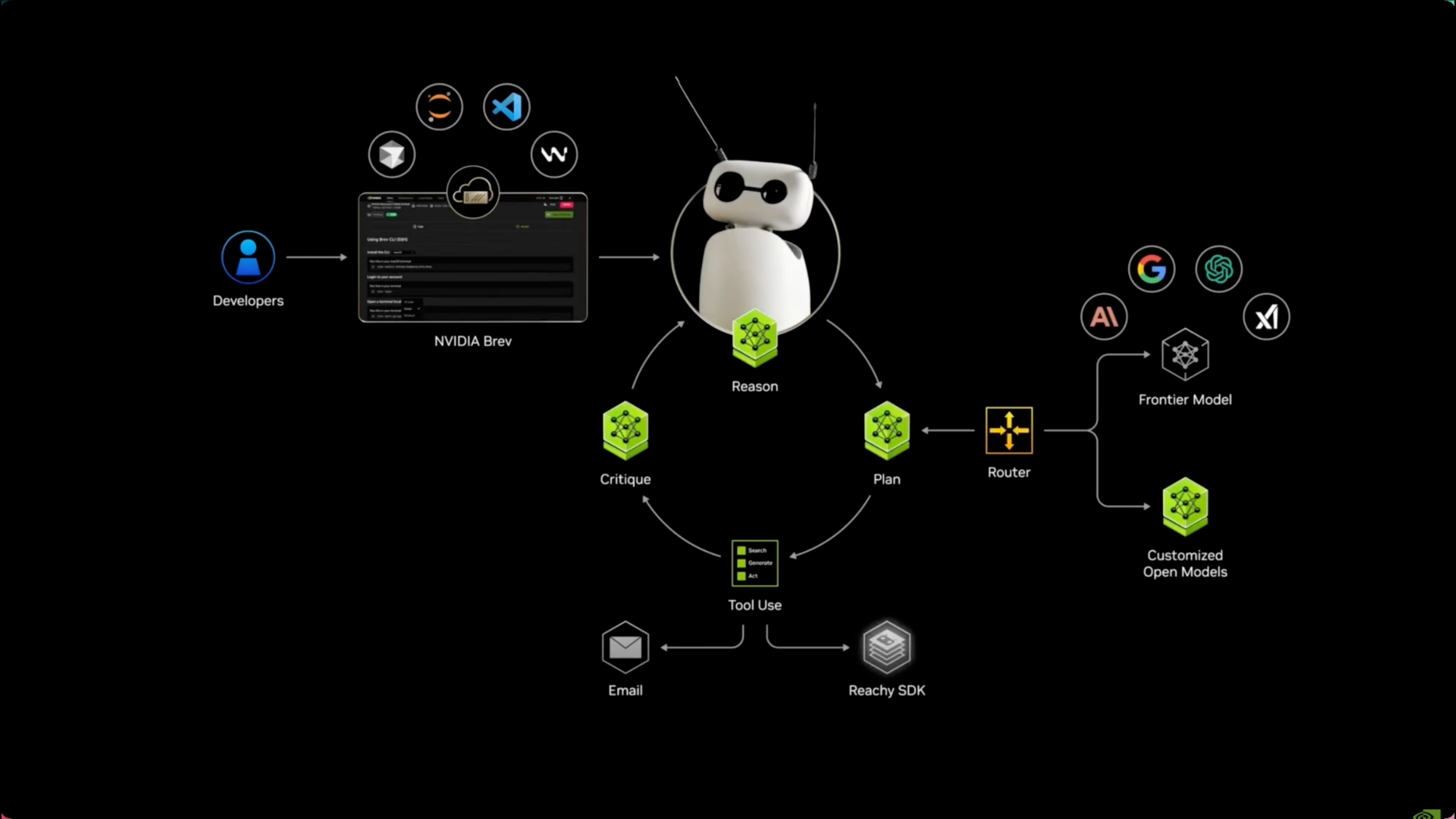
Jeff Boudier, vice-presidente de produto da Hugging Face, também mencionou: "O modelo aberto permite que os desenvolvedores criem IA à sua maneira, e o DGX Spark traz essa capacidade para o desktop… tornando a IA poderosa uma entidade verdadeiramente interativa."

Para reduzir as barreiras de entrada para desenvolvedores, a NVIDIA também adicionou seis novos Playbooks na CES, com foco nas necessidades mais atuais.
- O Nemotron 3 Nano, o mais recente modelo de agente inteligente de código aberto em larga escala da NVIDIA, é usado para experimentos locais de modelagem de luz latente (LLM).
- A interface web Live VLM permite a análise de modelos de linguagem visual em tempo real, possibilitando que a análise de vídeo seja realizada diretamente no DGX Spark local, através da entrada de imagens da webcam.
- Isaac Sim / Laboratório, Simulação de Robôs e Aprendizado por Reforço.
- O ajuste fino de sistema duplo demonstra como usar duas instâncias do DGX Spark para distribuir e ajustar um LLM de 70 bits.
Além da atualização do Playbook, o DGX Spark vem pré-instalado com software de IA NVIDIA otimizado e bibliotecas CUDA-X. Isso significa que os desenvolvedores não precisam perder tempo com configurações complexas de drivers e dependências de ambiente; eles podem obter recursos de otimização "plug-and-play" imediatamente e começar a criar ou ajustar modelos de IA sem demora.
O surgimento do DGX Spark na CES 2026 demonstra que a "localização de modelos de grande porte" deixou de ser apenas um discurso vazio. Seja para segurança de dados, eficiência no desenvolvimento ou para explorar a inteligência incorporada de próxima geração, o DGX Spark busca se tornar a base para a construção de aplicações de IA de última geração.
Assim como hoje, já existem projetos que permitem que a IA jogue. No futuro, além de uma placa de vídeo 5090 capaz de rodar "Black Myth: Wukong" sem problemas, serão necessários mais supercomputadores de IA para uso em desktops.
#Siga a conta oficial do iFanr no WeChat: iFanr (ID do WeChat: ifanr), onde você encontrará conteúdo ainda mais interessante o mais breve possível.
