
Os produtos mais recentes da OpenAI estão totalmente expostos! Ultraman refuta que o desenvolvimento da IA atingiu um obstáculo. Ilya admite seu erro e está secretamente procurando o próximo grande avanço.

Este ano, há realmente ondas de entusiasmo no círculo de IA.
Recentemente, notícias sobre as Leis de Escalabilidade “batendo na parede” explodiram no círculo da IA. Os vencedores do Prêmio Turing, Yann Lecun, Ilya e o fundador da Anthropic, Dario Amodei, iniciaram uma guerra de palavras.
No centro do debate está se haverá um limite máximo para melhorias de desempenho à medida que os modelos continuam a crescer em tamanho. À medida que a opinião pública se intensifica, o CEO da OpenAI, Sam Altman, acaba de responder na plataforma X:
"não há muro, não há muro"
No contexto deste debate, Bloomberg revelou uma notícia surpreendente.
A OpenAI planeja lançar um agente de IA chamado "Operador" em janeiro do próximo ano. Este agente pode usar computadores para realizar tarefas em nome dos usuários, como escrever códigos ou reservar viagens.
Antes disso, foi revelado que a Anthropic, a Microsoft e o Google estavam planejando direções semelhantes.
Para toda a indústria de IA, o desenvolvimento da tecnologia de IA nunca foi um processo linear unidimensional. Quando uma direção parece encontrar resistência, a inovação muitas vezes surge em outras dimensões.
Escalando Leis Batendo em uma parede? Qual é o próximo passo?
A notícia de que as Leis de Escalabilidade encontraram gargalos veio pela primeira vez de uma reportagem da mídia estrangeira The Information no fim de semana passado.
O relatório eloquente de milhares de palavras revelou duas informações importantes.
A boa notícia é que embora a OpenAI tenha concluído 20% do processo de treinamento do modelo Orion de próxima geração, Altman disse que o Orion já está no mesmo nível do GPT-4 em termos de inteligência e capacidade de realizar tarefas e responder perguntas.
A má notícia é que, de acordo com a avaliação dos funcionários da OpenAI que o utilizaram, em comparação com o enorme progresso entre GPT-3 e GPT-4, o Orion apresenta uma melhoria menor, como baixo desempenho em tarefas como programação, e maior custos de funcionamento.
Em uma frase, Scaling Laws encontrou um gargalo.

Para entender o impacto das Leis de Escala não ser tão bom quanto o esperado, precisamos apresentar brevemente os conceitos básicos das Leis de Escala para amigos que não estão familiarizados com elas.
Em 2020, a OpenAI propôs pela primeira vez Leis de Escalabilidade em um artigo.
Esta teoria aponta que o desempenho final de um modelo grande está relacionado principalmente à quantidade de cálculo, à quantidade de parâmetros do modelo e à quantidade de dados de treinamento, e basicamente não tem nada a ver com a estrutura específica do modelo (número de camadas /profundidade/largura).
Parece um pouco estranho, mas em termos humanos, o desempenho de modelos grandes aumentará proporcionalmente à medida que o tamanho do modelo, o volume de dados de treinamento e os recursos de computação aumentarem.
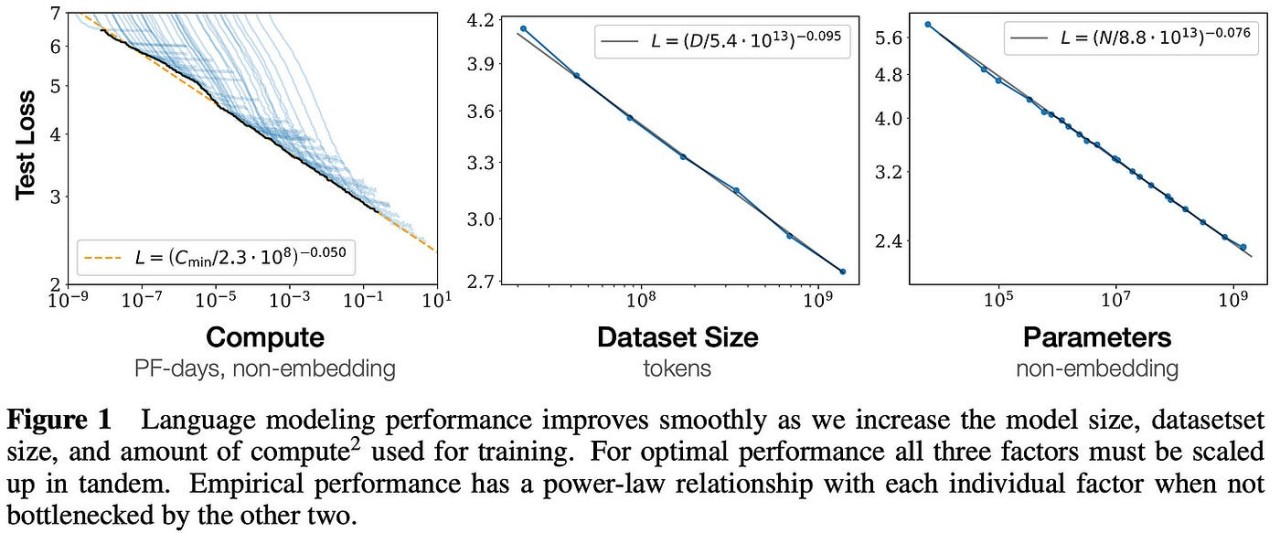
Esta pesquisa da OpenAI lançou as bases para o desenvolvimento subsequente de grandes modelos. Ela não apenas contribuiu para o sucesso da série de modelos GPT, mas também forneceu princípios orientadores importantes para otimizar o design do modelo e o treinamento para o treinamento do ChatGPT.
No entanto, embora ainda estejamos a pensar no GPT-100, as revelações da The Information indicam que o simples aumento do tamanho do modelo já não pode garantir uma melhoria linear no desempenho e é acompanhado por custos elevados e benefícios marginais significativamente decrescentes.
E a OpenAI não é a única que enfrenta dificuldades.
A Bloomberg citou pessoas familiarizadas com o assunto dizendo que o Gemini 2.0, de propriedade do Google, também não atingiu as metas esperadas. Ao mesmo tempo, o tempo de lançamento do Claude 3.5 Opus, de propriedade da Anthropic, também foi adiado repetidamente.
Na indústria de IA que corre contra o tempo, novas notícias sem um produto muitas vezes significam as maiores más notícias.

É necessário que fique claro que o estrangulamento das Leis de Expansão aqui mencionado não significa o fim do desenvolvimento de grandes modelos. O problema mais profundo é que os custos elevados conduzem a uma grave diminuição dos retornos nos benefícios marginais.
O CEO da Anthropic, Dario Amodei, revelou certa vez que à medida que os modelos se tornam cada vez maiores, os custos de treinamento explodiram, e o custo de treinamento do modelo de IA atualmente em desenvolvimento chega a US$ 1 bilhão.
Amodei também destacou que, nos próximos três anos, o custo do treinamento em IA aumentará para valores astronômicos de US$ 10 bilhões ou mesmo US$ 100 bilhões.
Tomando a série GPT como exemplo, o custo único de treinamento do GPT-3 chega a aproximadamente US$ 1,4 milhão. Essas despesas provêm principalmente do consumo de recursos computacionais poderosos, especialmente do uso de GPUs, e de enormes gastos com eletricidade.
Somente o treinamento do GPT-3 consumiu 1.287 MWh de energia elétrica.

No ano passado, uma pesquisa da Universidade da Califórnia, em Riverside, mostrou que o ChatGPT consome 500 mililitros de água para cada 25-50 perguntas que comunica aos usuários. Estima-se que, até 2027, a demanda anual de água doce limpa para IA global possa atingir 4,2-6,6. bilhões de metros cúbicos de m, equivalente ao consumo anual de água de 4-6 Dinamarca ou metade do Reino Unido.
Do GPT-2 ao GPT-3 e depois ao GPT-4, a melhoria da experiência trazida pela IA foi aos trancos e barrancos.
É precisamente com base neste progresso notável que as grandes empresas investirão fortemente no domínio da IA. Mas quando este caminho mostra gradualmente o seu fim, a simples prossecução da expansão da escala do modelo já não pode garantir uma melhoria significativa do desempenho. Os custos elevados e a diminuição dos benefícios marginais tornaram-se uma realidade que tem de ser enfrentada.
Agora, em vez de perseguir cegamente a escala, é mais importante implementar a escala na direção certa.
Adeus, GPT, olá, raciocínio "O"
Todos rejeitam o muro, até mesmo a teoria.
Quando a notícia de que as Leis de Escalabilidade eram suspeitas de atingir um gargalo causou alvoroço no círculo de IA, vozes de dúvida também surgiram.
Yann Lecun, vencedor do Prêmio Turing e cientista-chefe da Meta AI, que sempre assumiu uma postura anti-mainstream, republicou com entusiasmo a entrevista da Reuters com Ilya Sutskever na plataforma X ontem, com o seguinte artigo:
“Não quero parecer uma reflexão tardia, mas lembrei você.
Citação: "Ilya Sutskever, cofundador dos laboratórios de IA Safe Superintelligence (SSI) e OpenAI, disse recentemente à Reuters que, ao expandir o estágio de pré-treinamento – ou seja, usar grandes quantidades de dados não rotulados para treinar modelos de IA para compreender padrões de linguagem e estruturas – os resultados estagnaram.”
Olhando para trás, para a avaliação do gigante da IA sobre a atual rota do grande modelo nos últimos dois anos, pode-se dizer que cada palavra é meticulosa e cada frase é sangrenta.
Por exemplo, a IA de hoje é mais burra que um gato, e sua inteligência está muito atrasada, faltando experiência direta do mundo físico e apenas manipulando texto e imagens sem compreender verdadeiramente o mundo. um beco sem saída, etc.
Voltando no tempo, há dois meses, Yann Lecun condenou sem cerimônia a atual linha dominante à morte. Entre as muitas teorias do Juízo Final da IA, ele também acredita firmemente que as afirmações de que a IA ameaçará a sobrevivência humana são pura bobagem:
- Grandes modelos de linguagem (LLMs) não podem responder a perguntas não incluídas em seus dados de treinamento,
- Eles não conseguem resolver problemas difíceis para os quais não são treinados,
- Eles não podem aprender novas habilidades ou conhecimentos sem ajuda humana significativa,
- Eles não podem criar coisas novas. Atualmente, os grandes modelos de linguagem são apenas uma parte da tecnologia de inteligência artificial. A simples ampliação destes modelos não os tornará capazes disso.

Tian Yuandong, que também trabalha na Meta FAIR, previu o dilema atual anteriormente.
Numa entrevista à comunicação social em Maio, o cientista chinês disse pessimistamente que as Leis de Escala podem estar certas, mas não serão tudo. Na sua opinião, a essência das Leis de Escalabilidade é trocar o crescimento exponencial de dados por “alguns pontos de ganho”.
"No final, o mundo humano pode ter muitas necessidades de cauda longa, que exigem que os humanos respondam rapidamente. Os dados em si nesses cenários são muito pequenos e o LLM não consegue obtê-los. No final, quando a lei de escala se desenvolver, todos poderão permanecem nos mesmos "dados Na" ilha isolada ", os dados da ilha isolada pertencem inteiramente a todos e são gerados constantemente a cada momento. Os especialistas aprendem a integrar-se à IA e tornam-se muito poderosos, e a IA não pode substituí-los. "

No entanto, a situação pode não ser tão pessimista ainda.
Falando objectivamente, numa entrevista à Reuters, Ilya admitiu que o progresso trazido pelas Leis de Escala estagnou, mas não declarou o seu fim.
“A década de 2010 foi a era da expansão e agora estamos mais uma vez entrando em uma nova era de maravilhas e descobertas. Agora, escolher as coisas certas para dimensionar é mais importante do que nunca. importante."
Além disso, Ilya também disse que a SSI está a explorar um novo método para expandir o processo de pré-formação.
Dario Amodei também falou recentemente sobre isso em podcast.
Ele prevê que não existe um teto absoluto para modelos abaixo do nível humano. Dado que o modelo ainda não atingiu o nível humano, não se pode dizer que as Leis de Dimensionamento falharam, mas que houve de facto um abrandamento do crescimento.

Desde os tempos antigos, as montanhas não mudaram e a água mudou, e a água não mudou e as pessoas mudaram.
No mês passado, o pesquisador da OpenAI, Noam Brown, disse na conferência TED AI:
“Acontece que pedir a um robô que pense por 20 segundos durante um jogo de pôquer proporciona a mesma melhoria de desempenho que escalar o modelo 100.000 vezes e treiná-lo 100.000 vezes mais.”
Quanto aos comentários retrospectivos de Yann lecun ontem, ele respondeu da seguinte forma:
“No momento, estamos em um mundo onde, como eu disse antes, o custo computacional necessário para entrar no pré-treinamento de modelos de linguagem em larga escala é muito, muito alto. Mas o custo da inferência é muito baixo. muitas pessoas estavam legitimamente preocupadas com o fato de que, à medida que o pré-treinamento, o custo e a quantidade de dados necessários para o treinamento se tornassem tão grandes que veremos retornos decrescentes sobre o progresso na IA. Mas acho que uma das conclusões realmente importantes do o1 é. que este muro não existe e que podemos realmente ir mais longe. Promover este processo porque agora podemos expandir a computação inferencial e há um enorme espaço para expansão da computação inferencial.
Os pesquisadores representados por Noam Brown acreditam firmemente que a computação de inferência/tempo de teste provavelmente se tornará outra panaceia para melhorar o desempenho do modelo.
Falando nisso, temos que mencionar o familiar modelo OpenAI o1.
Bastante semelhante ao raciocínio humano, o modelo o1 pode “pensar” sobre problemas por meio do raciocínio em várias etapas. Ele enfatiza dar ao modelo mais “tempo para pensar” durante a fase de raciocínio. Seu segredo principal é que, em uma rede como o GPT-4, o treinamento adicional. no modelo básico.
Por exemplo, os modelos podem, em última análise, escolher o melhor caminho a seguir gerando e avaliando múltiplas respostas possíveis em tempo real, em vez de escolher uma única resposta imediatamente. Isso permite que mais recursos de computação sejam focados em tarefas complexas, como problemas matemáticos e quebra-cabeças. , ou aquelas operações complexas que exigem raciocínio e tomada de decisões semelhantes aos humanos.

O Google recentemente seguiu esse caminho.
The Information relata que nas últimas semanas, DeepMind formou uma equipe dentro de sua divisão Gemini, liderada pelo cientista-chefe de pesquisa Jack Rae e pelo ex-cofundador da Character.AI Noam Shazeer, para desenvolver capacidades semelhantes.
Ao mesmo tempo, o Google, para não ficar para trás, está tentando novos caminhos técnicos, incluindo o ajuste de “hiperparâmetros”, que são variáveis que determinam como o modelo processa as informações, como a rapidez com que estabelece conexões entre diferentes conceitos ou padrões no treinamento. dados e veja quais variáveis levam aos melhores resultados.
Como observação lateral, uma razão importante para a desaceleração no desenvolvimento da GPT é a falta de texto de alta qualidade e de outros dados disponíveis.
Em resposta a este problema, os pesquisadores do Google originalmente esperavam usar IA para sintetizar dados e incorporar áudio e vídeo nos dados de treinamento do Gemini para obter melhorias significativas, mas essas tentativas pareciam ter pouco efeito.
Pessoas familiarizadas com o assunto também revelaram que a OpenAI e outros desenvolvedores também usam dados sintéticos. No entanto, também descobriram que o efeito dos dados sintéticos na melhoria dos modelos de IA é muito limitado.
Olá Jarvis
Adeus GPT, olá raciocínio "o".
Em um evento recente do Reddit AMA, um internauta perguntou a Altman se o "GPT-5" e uma versão completa do modelo de inferência o1 seriam lançados.
Na época, Altman respondeu: “Estamos priorizando o lançamento do o1 e de suas versões subsequentes”, acrescentando que os recursos computacionais limitados dificultam o lançamento de vários produtos ao mesmo tempo.
Ele também enfatizou que o modelo da próxima geração pode não continuar a se chamar “GPT”.

Agora parece que Altman está ansioso para traçar uma linha clara com o sistema de nomenclatura GPT e, em vez disso, lança um modelo de inferência com o nome "o". Parece haver um significado profundo por trás disso. O layout do modelo de inferência ainda pode estabelecer as bases para o atual Agente dominante.
Recentemente, Altman também falou novamente sobre a teoria AGI de cinco níveis em uma entrevista com o presidente do YC, Garry Tan:
- L1: Os robôs de bate-papo são IA com recursos de conversação que podem ter conversas tranquilas com os usuários, fornecer informações, responder perguntas, auxiliar na criação, etc., como os robôs de bate-papo.
- L2: IA cujos raciocinadores podem resolver problemas como os humanos, podem resolver problemas complexos semelhantes aos níveis humanos de doutorado e demonstrar capacidades poderosas de raciocínio e resolução de problemas, como OpenAI o1.
- L3: Um sistema de IA no qual o agente pode não apenas pensar, mas também agir, e pode realizar negócios totalmente automatizados.
- L4: A IA que os inovadores podem ajudar na invenção e na criação tem a capacidade de inovar e pode ajudar os humanos na geração de novas ideias e soluções em campos como a descoberta científica, a criação artística ou o design de engenharia.
- L5: A IA que permite aos organizadores concluir o trabalho organizacional e controlar automaticamente o planejamento, a execução, o feedback, a iteração, a alocação de recursos, o gerenciamento, etc. de todos os processos internegócios da organização, é basicamente semelhante aos humanos.
Vemos assim que, tal como a Google e a Anthropic, a OpenAI está agora a mudar o seu foco de modelos para uma série de ferramentas de IA chamadas Agentes.
Recentemente, a Bloomberg também revelou que a OpenAI está se preparando para lançar um novo agente de IA chamado “Operador”, que pode usar computadores para realizar tarefas em nome dos usuários, como escrever códigos ou reservar viagens.
Em uma reunião de equipe na quarta-feira, a liderança da OpenAI anunciou planos para lançar uma prévia da pesquisa da ferramenta em janeiro e disponibilizá-la aos desenvolvedores por meio da interface de programação de aplicativos (API) da empresa.
Antes disso, a Anthropic também lançou um Agente semelhante, que pode processar tarefas do computador do usuário em tempo real e realizar operações em seu nome. Ao mesmo tempo, a Microsoft lançou recentemente um conjunto de ferramentas de agente para funcionários enviarem e-mails e gerenciarem registros.

O Google também está se preparando para lançar seu próprio AI Agent.
O relatório também revelou que a OpenAI está conduzindo vários projetos de pesquisa relacionados a agentes. O mais próximo da conclusão é uma ferramenta universal que pode executar tarefas em um navegador da web.
Espera-se que esses agentes sejam capazes de compreender, raciocinar, planejar e agir, mas esses agentes são, na verdade, um sistema composto por vários modelos de IA, e não por um único modelo.
Bill Gates disse uma vez: “Há um PC em cada desktop”, e Steve Jobs disse: “Todo mundo tem um smartphone na mão”. Agora podemos prever com ousadia: todos terão seu próprio agente de IA.
Claro, o objetivo final da humanidade é esperar que um dia possamos falar o clássico diálogo do filme para a IA que está à nossa frente:
Olá Jarvis
# Bem-vindo a seguir a conta pública oficial do WeChat de Aifaner: Aifaner (ID do WeChat: ifanr). Mais conteúdo interessante será fornecido a você o mais rápido possível.
