
O talento mais caro nos Estados Unidos agora é o talento chinês em IA: a Universidade de Tsinghua, a Universidade de Pequim e a Academia Chinesa de Ciências estão “dominando” o círculo de IA do Vale do Silício

Nas últimas duas semanas, o que mais se popularizou na indústria de IA não foi o produto, mas as pessoas. Muitas vezes, quando acordo, minha linha do tempo nas redes sociais é atualizada com a mesma notícia de sempre: mais um especialista em IA foi contratado.
Os principais talentos em IA estão se tornando os ativos mais escassos e mais eficazes em termos de marca no campo da IA.
No centro dessa tempestade de fluxo de talentos, encontramos um detalhe particularmente impressionante: entre os membros principais que lideraram a pesquisa e o desenvolvimento de grandes modelos como ChatGPT, Gemini e Claude, a proporção de cientistas chineses era surpreendentemente alta.
Essa mudança não ocorreu repentinamente. Na onda da IA que surgiu nos últimos anos, a proporção de talentos chineses de ponta em IA nos Estados Unidos continuou a aumentar. De acordo com o Relatório Global de Rastreamento de Talentos em Inteligência Artificial 2.0, divulgado pela MacroPolo, a proporção de pesquisadores de ponta em IA da China aumentou de 29% para 47% entre 2019 e 2022.
No "Relatório de Pesquisa de Contexto da Equipe ChatGPT", divulgado pela Zhipu Research, constatou-se que, entre os 87 membros principais da equipe ChatGPT, 9 são chineses, representando mais de 10%. Portanto, também reexaminamos os perfis de pesquisadores chineses de IA que recentemente atraíram muita atenção nas principais empresas do Vale do Silício e tentamos resumir algumas características deles:
1️⃣ Formados em universidades de ponta, com sólida capacidade acadêmica. A maioria cursou cursos de graduação em universidades de ponta, como a Universidade de Tsinghua, a Universidade de Pequim, a Universidade de Ciência e Tecnologia da China e a Universidade de Zhejiang, e a maioria possui formação em ciência da computação ou matemática. Para estudos de pós-graduação, geralmente frequentam o MIT, Stanford, Berkeley, Princeton, UIUC e outras universidades renomadas. Quase todos têm artigos altamente citados em conferências de ponta (NeurIPS, ICLR, SIGGRAPH, etc.).
2️⃣ Jovens e produtivos, o período de surto se concentra após 2020, e a faixa etária predominante é de 30 a 35 anos; os estágios de mestrado e doutorado coincidem com o surto global de aprendizado profundo, com sólida base acadêmica e familiaridade com sistemas de engenharia e trabalho em equipe. A primeira parada na carreira de muitas pessoas é o contato com produtos ou plataformas de IA de grandes empresas ou que atendem a grandes grupos de pessoas, com um ponto de partida mais alto e um ritmo mais acelerado.
3️⃣ Forte experiência multimodal, após abordar o treinamento do modelo. Sua direção de pesquisa geralmente se concentra em um sistema de raciocínio unificado em todas as modalidades (texto, fala, imagem, vídeo, ação), incluindo detalhes específicos como RLHF, destilação, alinhamento, modelagem de preferência humana e avaliação da entonação da fala.
4️⃣ Mesmo que se mova com frequência, basicamente não estará fora do ecossistema
Google, Meta, Microsoft, Nvidia, Anthropic, OpenAI… Sua mobilidade abrange startups e gigantes da IA, mas seus tópicos de pesquisa e acumulação tecnológica tendem a permanecer consistentes e basicamente não mudam de rumo.
OpenAI → Meta
Shuchao Bi
Shuchao Bi se formou no Departamento de Matemática da Universidade de Zhejiang e depois foi para a Universidade da Califórnia, Berkeley, para continuar seus estudos, onde obteve um mestrado em estatística e um doutorado em matemática.
De 2013 a 2019, ele atuou como diretor técnico no Google, onde suas principais contribuições incluíram a construção de um sistema de recomendação de aprendizado profundo em vários estágios que aumentou significativamente a receita de publicidade do Google (na casa dos bilhões de dólares).
De 2019 a 2024, ele atuou como chefe da Shorts Exploration, período em que cocriou e liderou o sistema de recomendação e descoberta de vídeos Shorts, além de construir e expandir uma equipe de aprendizado de máquina em larga escala, abrangendo sistemas de recomendação, modelos de pontuação, descoberta interativa, confiança e segurança e outras áreas.
Após ingressar na OpenAI em 2024, ele liderou principalmente a organização multimodal de pós-treinamento e é o co-criador do modelo de fala GPT-4o e o4-mini
Durante esse período, ele promoveu principalmente RLHF, raciocínio por imagem/fala/vídeo/texto, agentes multimodais, fala para fala multimodal (VS2S), modelo básico de visão-linguagem-ação (VLA), sistema de avaliação intermodal, etc., e também envolveu raciocínio em cadeia multimodal, pontuação de entonação/naturalidade da fala, destilação multimodal e otimização autossupervisionada. Seu objetivo principal é construir um agente de IA multimodal mais geral por meio de treinamento pós-treinamento.
Huiwen Chang
Em 2013, Huiwen Chang se formou no Departamento de Ciência da Computação (Turma Yao) da Universidade Tsinghua e, em seguida, ingressou na Universidade de Princeton, nos Estados Unidos, para cursar doutorado em Ciência da Computação. Sua pesquisa se concentra em transferência de estilo de imagem, modelos generativos e processamento de imagens. Ele ganhou uma bolsa de estudos da Microsoft Research.
Antes de ingressar na OpenAI, ela trabalhou como pesquisadora sênior no Google por mais de seis anos e se dedica há muito tempo à pesquisa de modelos generativos e visão computacional. Ela inventou as arquiteturas de conversão de texto em imagem MaskGIT e Muse no Google Research.
A geração inicial de texto para imagem dependia principalmente de modelos de difusão (como DALL·E 2 e Imagen). Embora esses modelos tenham alta qualidade de geração, sua velocidade de inferência é lenta e seu custo de treinamento é alto. O MaskGIT e o Muse, por outro lado, utilizam a abordagem de "discretização + geração paralela", o que melhora significativamente a eficiência.

O MaskGIT é um novo ponto de partida para a geração de imagens não autorregressivas, e o Muse é um trabalho representativo que leva esse método para a geração de imagens de texto. Eles não são tão conhecidos quanto a Difusão Estável, mas são pilares técnicos muito importantes em sistemas acadêmicos e de engenharia.
Além disso, ela também é uma das coautoras do principal artigo sobre modelos de difusão "Palette: Image-to-image diffusion models".
Este artigo foi publicado no SIGGRAPH 2022. Ele propôs uma estrutura unificada de tradução de imagem para imagem e superou as linhas de base de GAN e regressão em diversas tarefas, como restauração, colorização e complementação de imagens. Já foi citado mais de 1.700 vezes até o momento e se tornou uma das conquistas mais representativas neste campo.
Desde junho de 2023, ela se juntou à equipe multimodal da OpenAI e desenvolveu em conjunto a função de geração de imagens GPT-4o, continuando a promover pesquisas e implementações em direções de ponta, como geração de imagens e modelagem multimodal.

Ji Lin
Ji Lin dedica-se principalmente à pesquisa sobre aprendizagem multimodal, sistemas de raciocínio e dados sintéticos. Ele contribui para diversos modelos principais, incluindo GPT-4o, GPT-4.1, GPT-4.5, o3/o4-mini, Operator e o modelo de geração de imagens 4o.
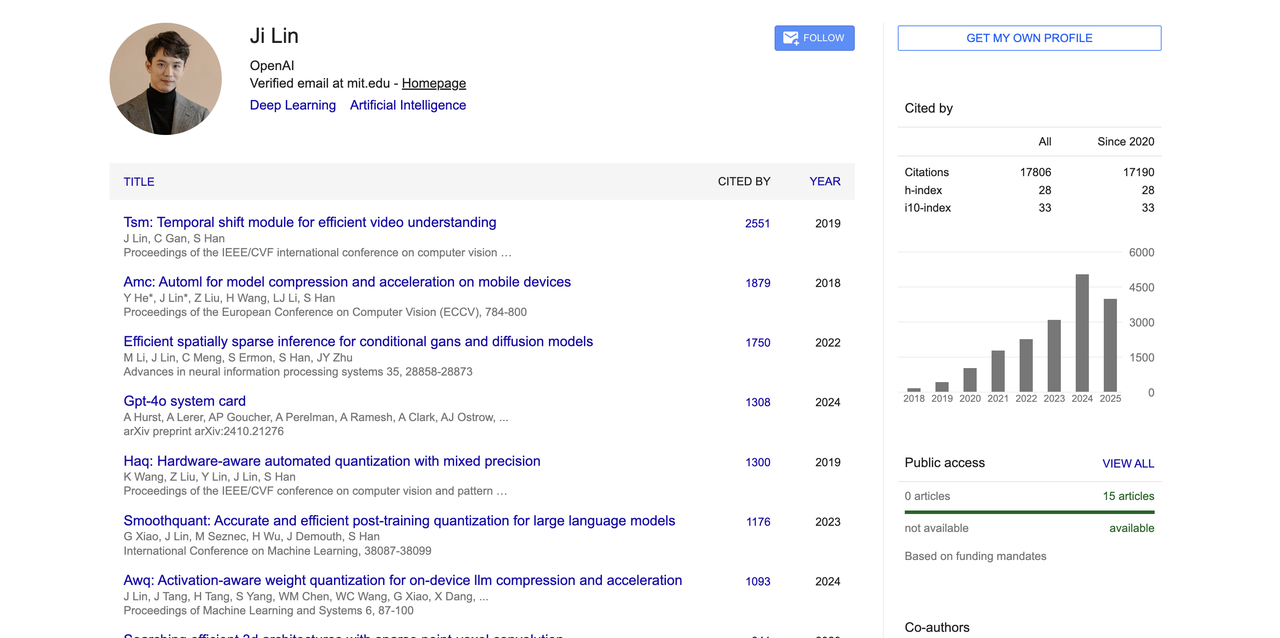
Ele se formou na Universidade Tsinghua com bacharelado em engenharia eletrônica (2014-2018) e recebeu seu doutorado em engenharia elétrica e ciência da computação pelo MIT, tendo como supervisor o renomado acadêmico Prof. Song Han.
Durante seus estudos de doutorado, sua pesquisa se concentrou em áreas-chave como compressão de modelos, quantização, modelos de linguagem visual e raciocínio esparso.
Antes de ingressar na OpenAI em 2023, ele trabalhou como pesquisador estagiário na NVIDIA, Adobe e Google, e se envolveu em pesquisas sobre compressão de redes neurais e aceleração de inferência no MIT por um longo tempo, acumulando uma profunda base teórica e experiência prática em engenharia.
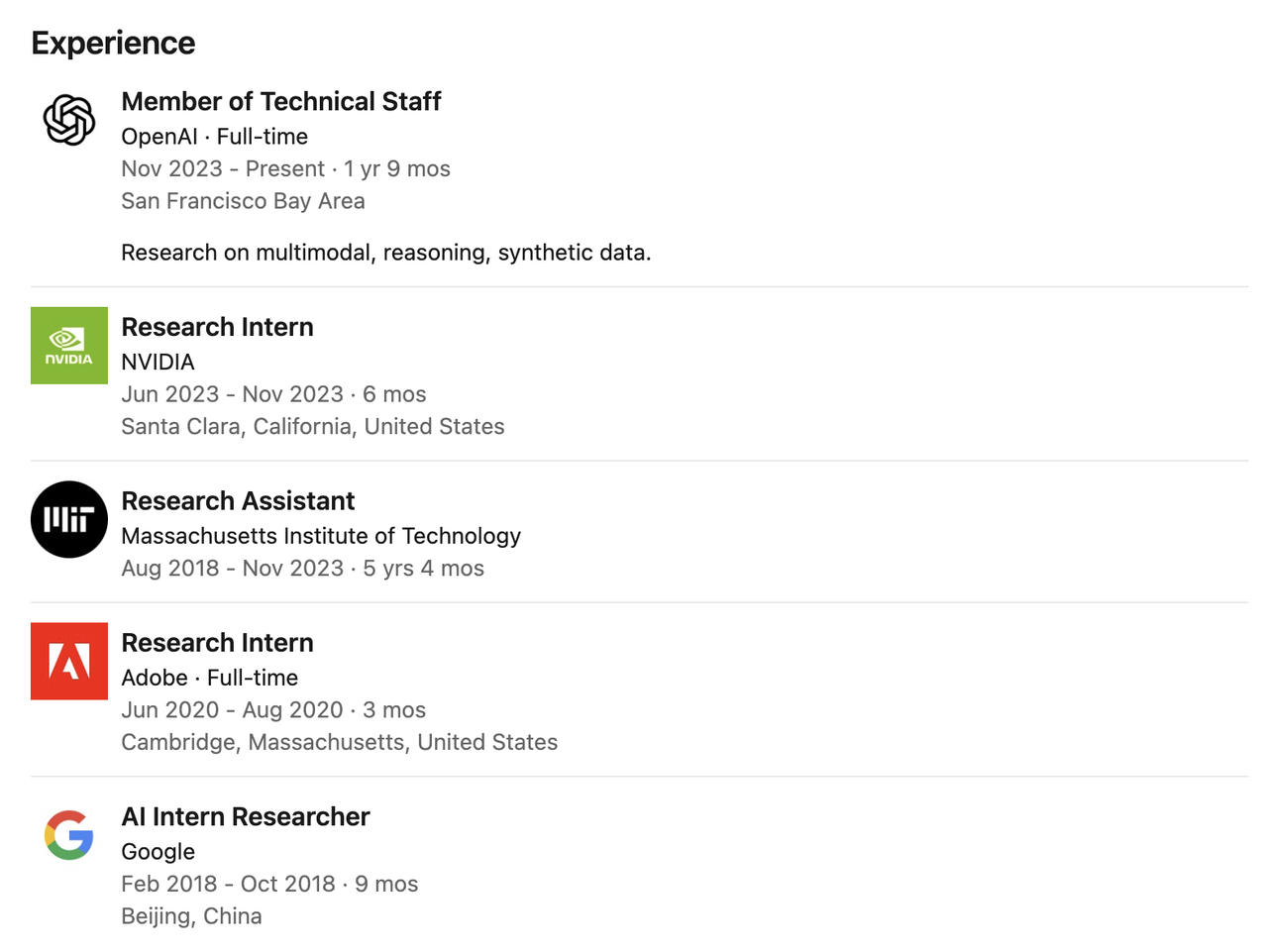
No campo acadêmico, publicou diversos artigos de alto impacto nas áreas de compressão de modelos, quantização e pré-treinamento multimodal, com um total de mais de 17.800 citações no Google Acadêmico. Suas realizações mais representativas incluem o modelo de compreensão de vídeo TSM, o método de quantização com reconhecimento de hardware AWQ, SmoothQuant e o modelo de linguagem visual VILA.
Ele também é um dos principais autores da documentação técnica do sistema GPT-4o (como o cartão do sistema GPT-4o) e ganhou o prêmio MLSys 2024 Best Paper Award por seu artigo AWQ.
Hong Yu Ren
Hongyu Ren recebeu seu diploma de bacharel em ciência da computação e tecnologia pela Universidade de Pequim (2014–2018) e seu doutorado em ciência da computação pela Universidade de Stanford (2018–2023).
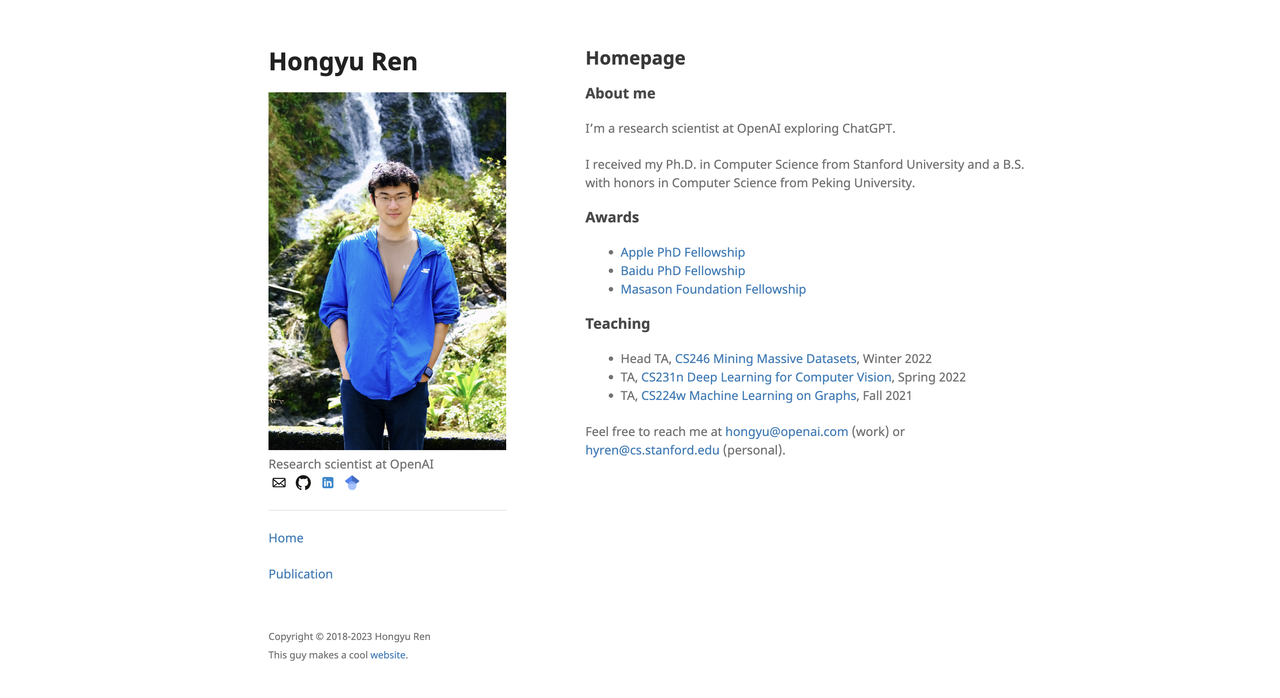
Ele recebeu diversas bolsas de estudo, incluindo a de doutorado da Apple, Baidu e da Fundação SoftBank Masason. Sua pesquisa se concentra em modelos de linguagem de grande porte, raciocínio de grafos de conhecimento, inteligência multimodal e avaliação básica de modelos.
Antes de ingressar na OpenAI, ele teve diversas experiências de estágio no Google, Microsoft e NVIDIA. Por exemplo, enquanto trabalhava como pesquisador estagiário na Apple em 2021, ele participou da construção do sistema de perguntas e respostas da Siri.
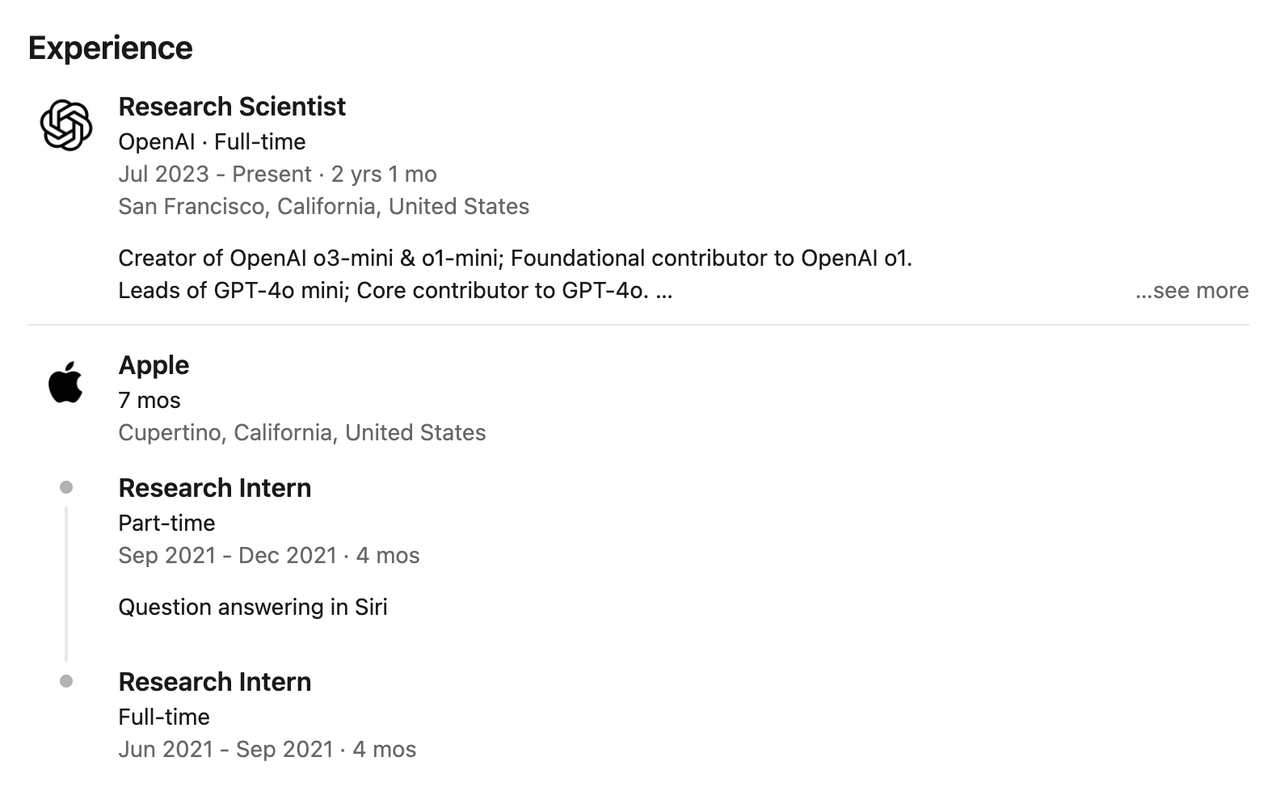
Depois de ingressar na OpenAI em julho de 2023, Hongyu Ren participou da construção de vários modelos principais, como GPT-4o, 4o-mini, o1-mini, o3-mini, o3 e o4-mini, e liderou a equipe de pós-treinamento.
Em suas palavras: “Eu ensino modelos a pensar mais rápido, com mais afinco e com mais precisão.”
No campo acadêmico, seu total de citações no Google Acadêmico ultrapassa 17.742 vezes, e seus artigos altamente citados incluem: "On the Opportunities and Risks of Foundation Models" (citado 6.127 vezes); conjunto de dados "Open Graph Benchmark" (OGB) (citado 3.524 vezes), etc.
Jiahui Yu
Jiahui Yu se formou na turma júnior da Universidade de Ciência e Tecnologia da China com bacharelado em ciência da computação e, em seguida, recebeu um doutorado em ciência da computação pela Universidade de Illinois em Urbana-Champaign (UIUC).
Seus focos de pesquisa incluem aprendizado profundo, geração de imagens, arquiteturas de grandes modelos, raciocínio multimodal e computação de alto desempenho.

Durante sua gestão na OpenAI, Jiahui Yu atuou como chefe da equipe de percepção, liderando o desenvolvimento de projetos importantes, como o módulo de geração de imagens GPT-4o, GPT-4.1, o3/o4-mini, e propôs e implementou o sistema de percepção "Pensando com Imagens".
Antes disso, trabalhou no Google DeepMind por quase quatro anos, período em que foi um dos principais colaboradores da arquitetura e modelagem do PaLM-2 e coliderou o desenvolvimento do modelo multimodal Gemini. Ele é um dos pilares técnicos mais importantes da estratégia multimodal do Google.
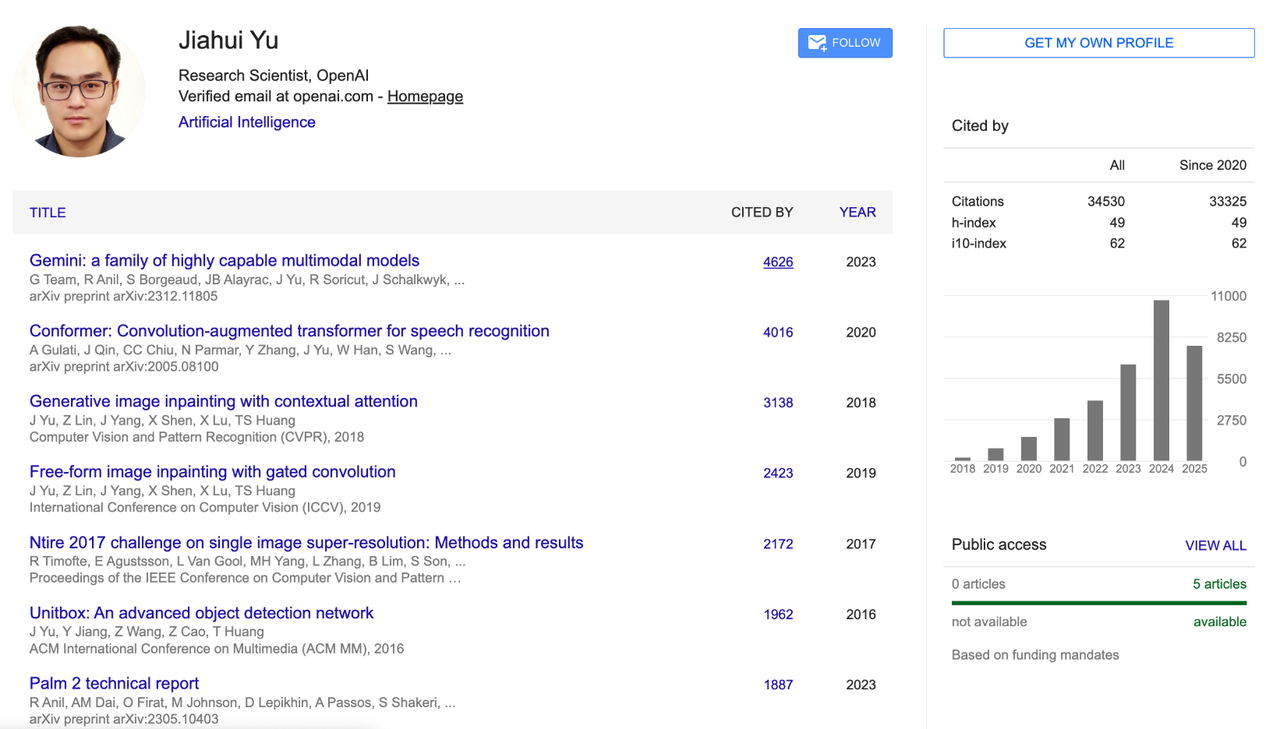
Ele também possui experiência de estágio em diversas instituições, incluindo NVIDIA, Adobe, Baidu, Snap, Megvii e Microsoft Research Asia. Sua pesquisa abrange GAN, detecção de objetos, direção autônoma, compressão de modelos, restauração de imagens e sistemas de treinamento de aprendizado profundo em larga escala.
Jiahui foi citado mais de 34.500 vezes no Google Acadêmico, com um índice h de 49. Seus resultados de pesquisa representativos incluem o modelo básico CoCa para alinhamento de imagem e texto, o modelo de geração de texto para imagem Parti, o design de rede neural escalável BigNAS e a tecnologia de restauração de imagem DeepFill v1 e v2, amplamente utilizadas no Adobe Photoshop.
Shengjia Zhao
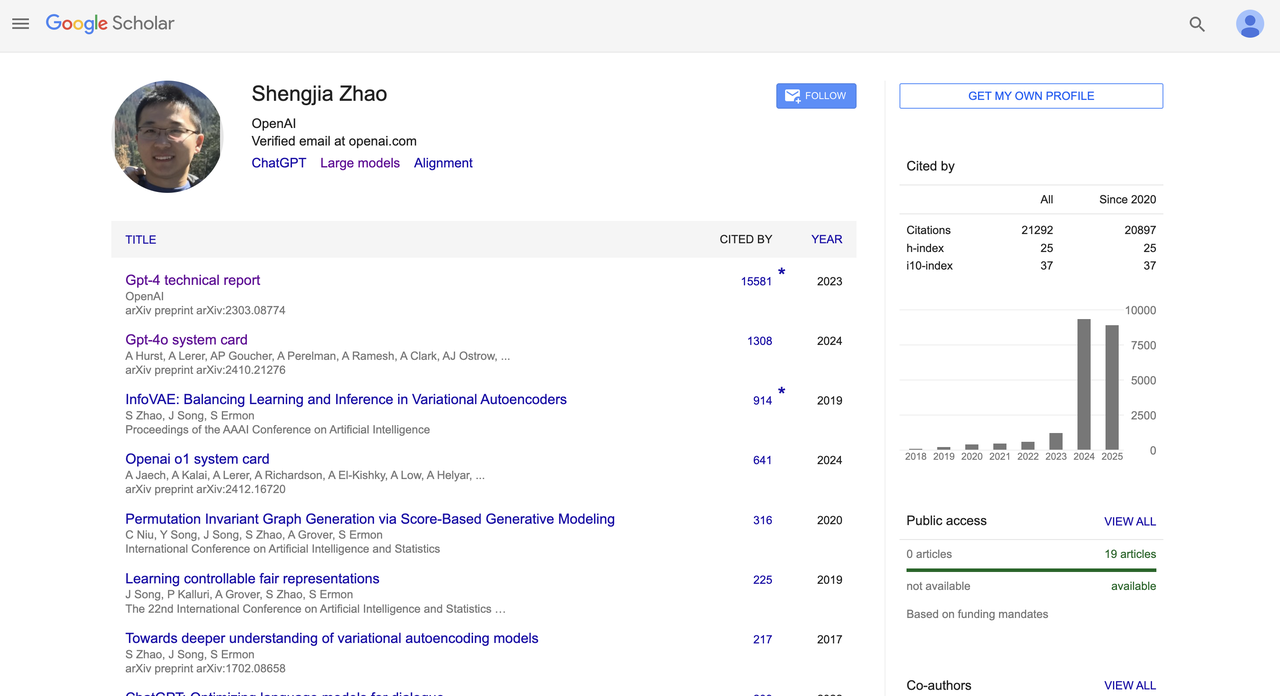
Shengjia Zhao formou-se no Departamento de Ciência da Computação da Universidade Tsinghua. Foi aluno de intercâmbio na Universidade Rice, nos Estados Unidos, e posteriormente doutorou-se em Ciência da Computação pela Universidade Stanford. Concentrou-se em pesquisas em arquitetura de grandes modelos, raciocínio multimodal e alinhamento.
Em 2022, ingressou na OpenAI como membro principal de P&D e esteve profundamente envolvido no projeto dos sistemas GPT-4 e GPT-4o. Liderou a P&D do ChatGPT, GPT-4, todos os modelos mini, 4.1 e o3, e também liderou a equipe de dados sintéticos da OpenAI.
Ele é coautor do "GPT-4 Technical Report" (citado mais de 15.000 vezes) e do "GPT-4o System Card" (citado mais de 1.300 vezes), e participou da escrita de diversos cartões de sistema (como o OpenAI o1). Ele é um dos importantes contribuidores para a padronização e abertura dos modelos básicos do OpenAI.
Em termos de desempenho acadêmico, ele tem mais de 21.000 citações no Google Acadêmico e um índice h de 25. Ele ganhou muitos prêmios, incluindo o ICLR 2022 Outstanding Paper Award, JP Morgan PhD Fellow, Qualcomm Innovation Fellowship (QinF) e Google Excellence Scholarship.
Google → Meta
Pei Sun
Em 2009, Pei Sun se formou na Universidade Tsinghua e, em seguida, ingressou na Universidade Carnegie Mellon para cursar mestrado e doutorado. Ela concluiu o mestrado com sucesso e optou por abandonar o curso durante o doutorado.
Ele atuou como pesquisador-chefe no Google DeepMind, onde se concentrou em pós-treinamento, programação e raciocínio do modelo Gemini. Ele é um dos principais colaboradores do pós-treinamento, construção de mecanismos de pensamento e implementação de código da série de modelos Gemini (incluindo Gemini 1, 1.5, 2 e 2.5).
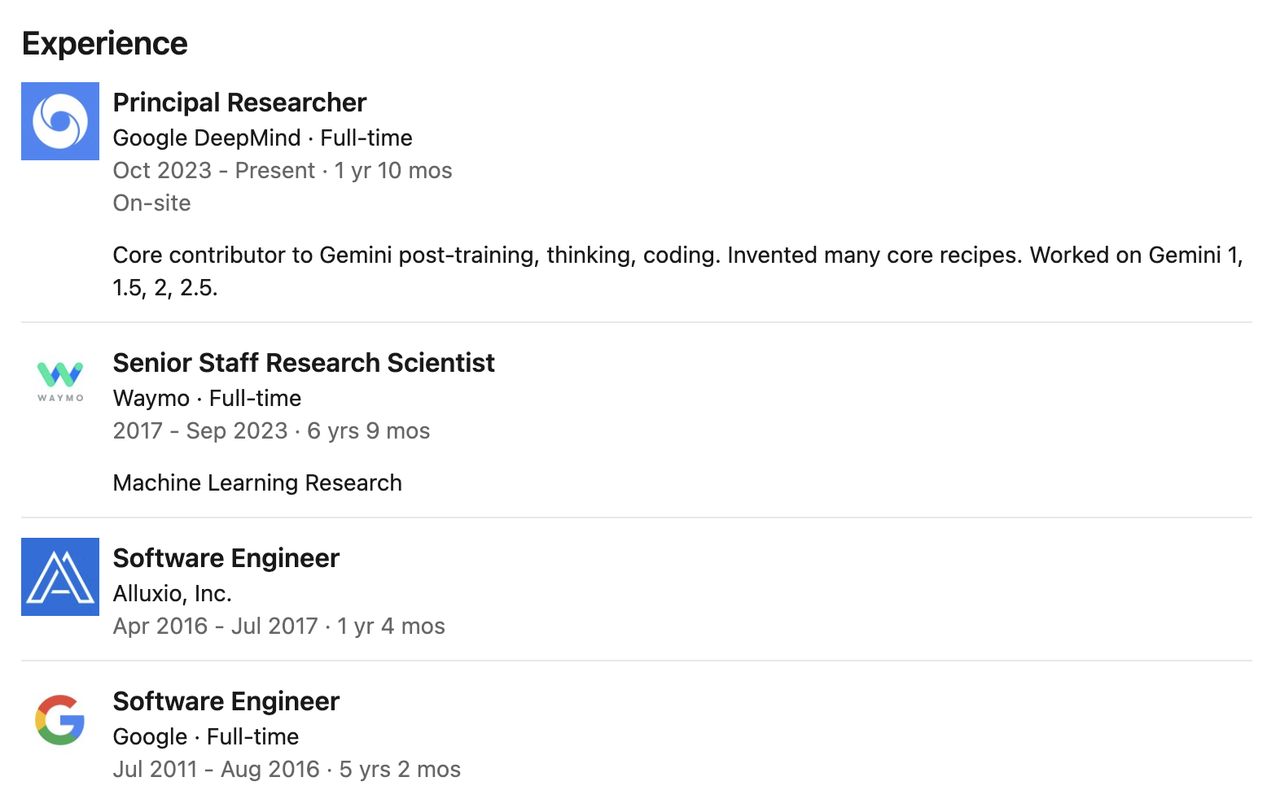
Antes de ingressar na DeepMind, Pei trabalhou na Waymo por quase sete anos como cientista pesquisador sênior, liderando o desenvolvimento de duas gerações dos principais modelos de percepção da Waymo e desempenhando um papel fundamental na evolução dos sistemas de percepção de direção autônoma.
Anteriormente, ele trabalhou como engenheiro de software no Google por mais de cinco anos e depois se juntou à empresa de armazenamento distribuído Alluxio como engenheiro por mais de um ano, participando de pesquisa e desenvolvimento de arquitetura de sistemas.

Nexusflow → NVIDIA
Banghua Zhu
Banghua Zhu se formou no Departamento de Engenharia Eletrônica da Universidade Tsinghua e depois foi para a Universidade da Califórnia, Berkeley, para fazer doutorado em Engenharia Elétrica e Ciência da Computação, sob a tutela dos famosos acadêmicos Michael I. Jordan e Jiantao Jiao.

Sua pesquisa se concentra em aprimorar a eficiência e a segurança de modelos básicos, integrando métodos estatísticos à teoria de aprendizado de máquina, e está comprometida com a construção de conjuntos de dados de código aberto e ferramentas de acesso público. Seus interesses também incluem teoria dos jogos, aprendizado por reforço, interação humano-computador e design de sistemas de aprendizado de máquina.
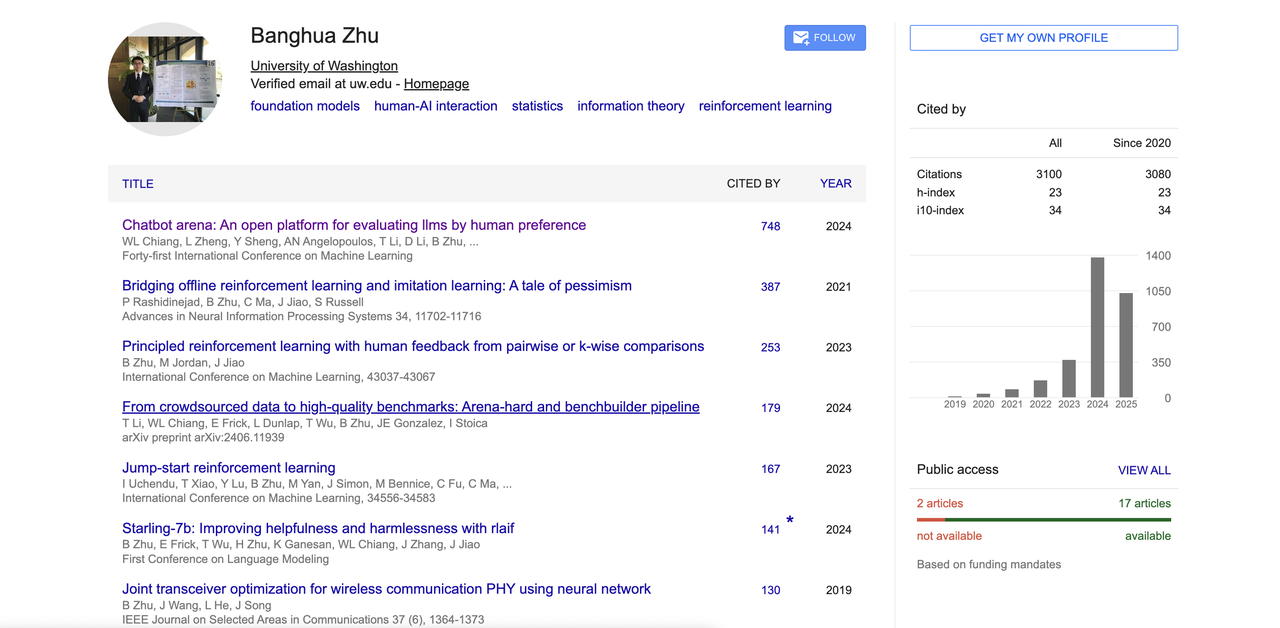
Seu artigo representativo "Chatbot Arena" propôs uma grande plataforma de avaliação de modelos orientada por preferências humanas, que se tornou uma das referências importantes na área de LLM.
Além disso, ele também fez contribuições em RLHF, alinhamento de feedback humano, modelos de alinhamento de código aberto, etc. Seu Google Acadêmico mostra que o número total de citações excede 3.100, e o índice h é 23. Ele também é um dos principais autores de muitos projetos populares de código aberto, como a grande arena de modelos "Chatbot Arena", "Benchbuilder" e "Starling".

Ele trabalhou como estagiário de pesquisa na Microsoft e como pesquisador-aluno no Google. Foi cofundador da startup de IA Nexusflow. Em junho deste ano, anunciou que havia se juntado à equipe Star Nemotron da NVIDIA como cientista-chefe de pesquisa. Além disso, ingressará na Universidade de Washington como professor assistente neste outono.
De acordo com o comunicado, ele participará de projetos como treinamento pós-modelo, avaliação, infraestrutura de IA e construção de agentes inteligentes na NVIDIA, enfatizando a colaboração profunda com desenvolvedores e acadêmicos, e planeja abrir resultados relacionados ao código-fonte.
Jiantao Jiao
Jiantao Jiao é professor assistente nos Departamentos de Engenharia Elétrica e Ciência da Computação e Estatística da Universidade da Califórnia, Berkeley.
Ele recebeu seu Ph.D. em Engenharia Elétrica pela Universidade Stanford em 2018 e atualmente é codiretor ou membro de vários centros de pesquisa, incluindo o Berkeley Center for Theoretical Learning (CLIMB), o Berkeley Artificial Intelligence Research Center (BAIR Lab), o Laboratory for Information and Systems Science (BLISS) e o Center for Descentralized Intelligence (RDI).
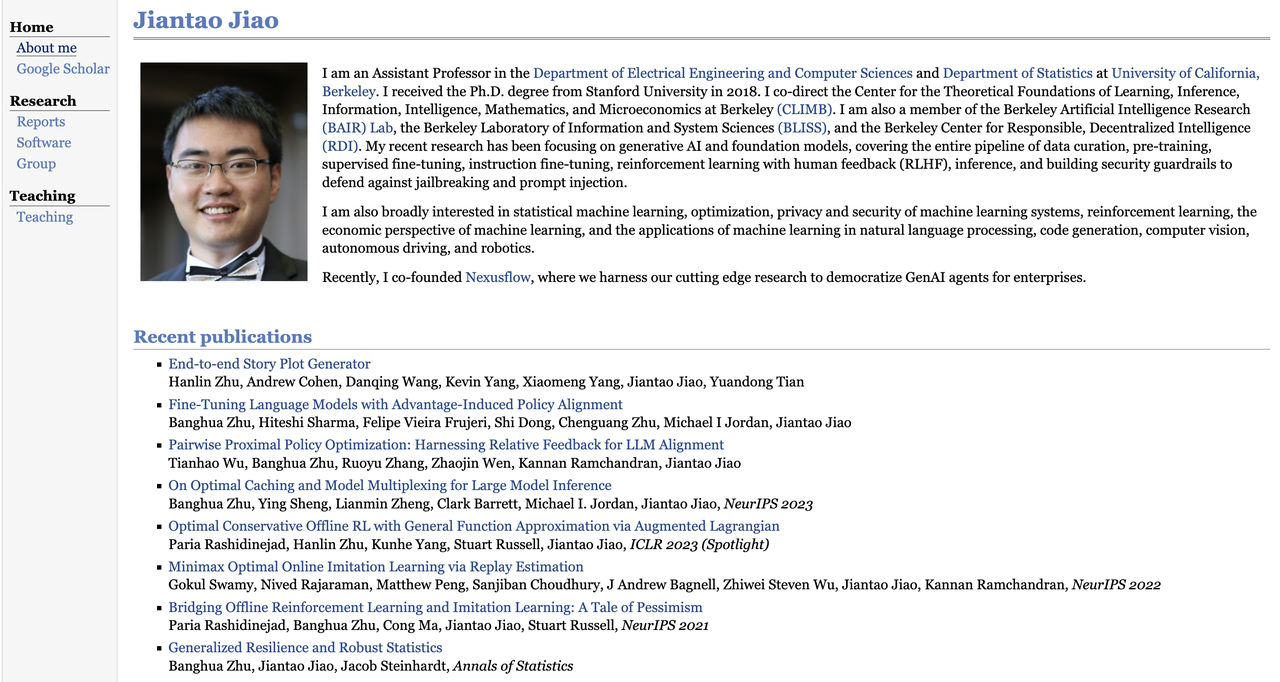
Sua pesquisa concentra-se em IA generativa e modelos básicos. Ele também se interessa por aprendizado de máquina estatístico, teoria da otimização, privacidade e segurança de sistemas de aprendizado por reforço, design de mecanismos econômicos, processamento de linguagem natural, geração de código, visão computacional, direção autônoma e robótica.
Assim como Banghua Zhu, ele também é um dos cofundadores da Nexusflow e agora se juntou oficialmente à NVIDIA como diretor de pesquisa e cientista renomado.
Jiao tem um total de 7.259 citações e um índice h de 34. Seus artigos representativos incluem "Theoretically principled trade-off between robustness and accuracy" e "Bridging Offline Reinforcement Learning and Imitation Learning: A Tale of Pessimism", em coautoria com Banghua Zhu et al., ambos publicados em conferências importantes como NeurIPS.
Claude → Cursor
Catarina Wu
Catherine Wu trabalhou como gerente de produto para Claude Code na Anthropic, com foco na construção de sistemas de IA confiáveis, explicáveis e controláveis. De acordo com o The Information, Catherine Wu foi contratada pela Cursor, uma startup de programação de IA, para atuar como gerente de produto.

Antes de ingressar na Anthropic, ela foi sócia da renomada empresa de capital de risco Index Ventures, onde trabalhou por quase três anos, período em que esteve profundamente envolvida em investimentos iniciais e suporte estratégico para muitas startups de ponta.
Sua carreira não começou no círculo de investimentos, mas foi baseada em cargos técnicos de linha de frente.
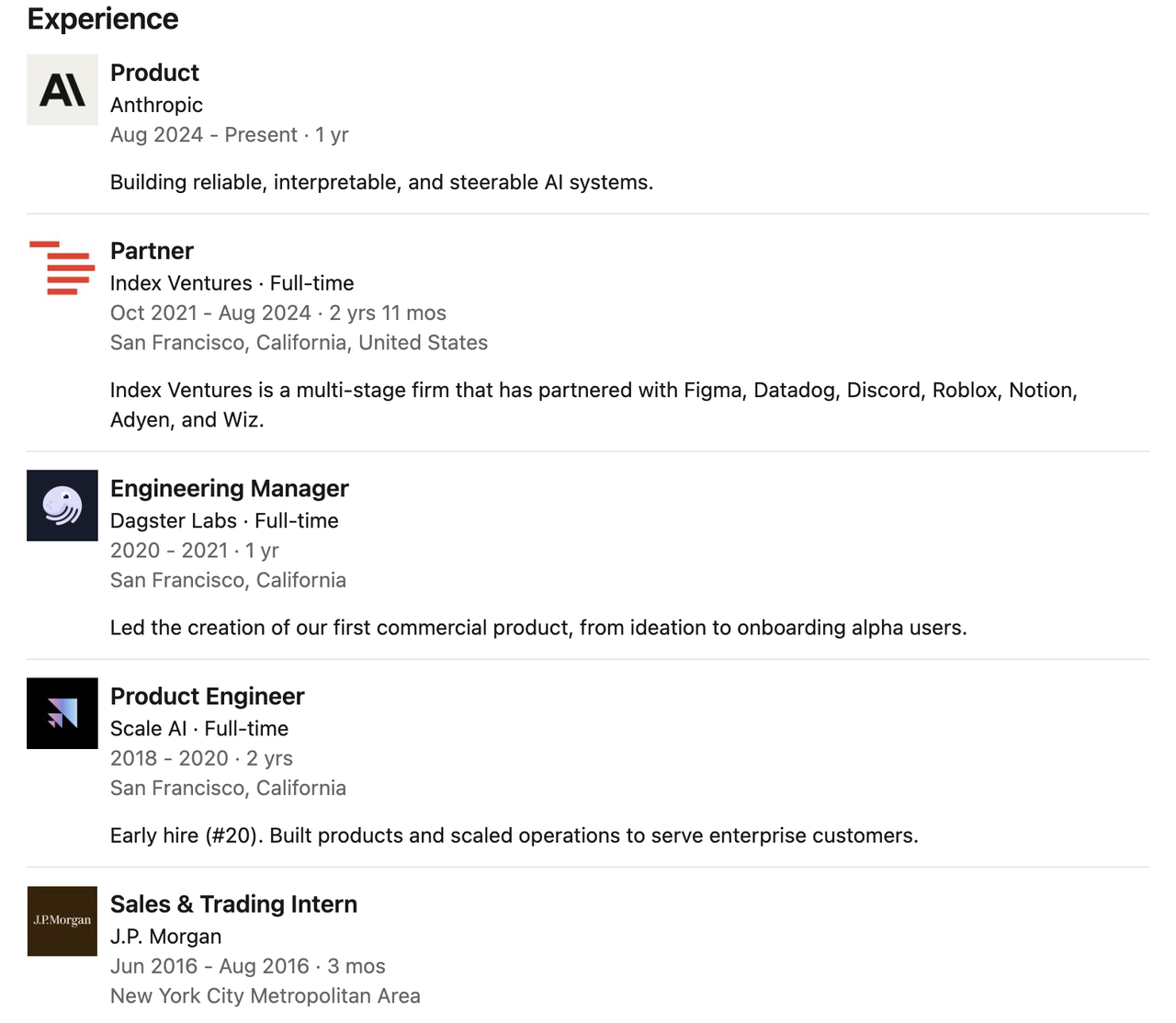
Anteriormente, ela trabalhou como gerente de engenharia na Dagster Labs, liderando o desenvolvimento do primeiro produto comercial da empresa, e como engenheira de produtos iniciais na Scale AI, participando da construção e expansão operacional de vários produtos importantes.
Anteriormente, ela estagiou no JPMorgan Chase e se formou em Ciência da Computação pela Universidade de Princeton. Durante a faculdade, também fez intercâmbio no Instituto Federal Suíço de Tecnologia.
Tesla | Phil Duan
Phil Duan é o engenheiro-chefe de software da Tesla AI. Atualmente, ele é responsável pela equipe de Aprendizado de Frota do Autopilot e está comprometido em promover a construção do módulo central "dados + percepção" no sistema de direção autônoma (FSD) da Tesla.

Ele liderou a equipe da Tesla no desenvolvimento de um mecanismo de dados de alto rendimento e iteração rápida que coleta, processa e anota automaticamente dados de direção de milhões de carros, enfatizando a otimização coordenada da qualidade, quantidade e diversidade dos dados. Na área de percepção, ele liderou a construção de diversas redes neurais importantes, incluindo modelos visuais básicos, detecção de alvos, previsão de comportamento, redes de ocupação, controle de tráfego e sistemas de assistência de estacionamento de alta precisão, e é um dos principais criadores do sistema de percepção Autopilot.
Formou-se em ciência e tecnologia da informação óptica pela Universidade de Tecnologia de Wuhan e, posteriormente, fez doutorado e mestrado em engenharia elétrica pela Universidade de Ohio, com foco em aviônica. Ganhou o Prêmio William E. Jackson da RTCA de 2019 por sua tese de doutorado, uma das maiores honrarias concedidas a estudantes de pós-graduação na área de aviônica e telecomunicações nos Estados Unidos.
#Bem-vindo a seguir a conta pública oficial do iFanr no WeChat: iFanr (ID do WeChat: ifanr), onde mais conteúdo interessante será apresentado a você o mais breve possível.
