
O supercomputador pessoal de US$ 30.000 que Jensen Huang presenteou a Elon Musk precisa do Mac Studio para funcionar sem problemas? Os primeiros testes práticos já estão disponíveis.

Com 200 bilhões de parâmetros, 30.000 RMB e 128 GB de memória, será que essa máquina, apelidada de "o menor supercomputador do mundo", realmente nos permitirá executar modelos complexos em nossos computadores de mesa?

▲ Imagem de x@nvidia
Há alguns dias, Jensen Huang entregou oficialmente este supercomputador a Elon Musk e, em seguida, foi pessoalmente à sede da OpenAI para apresentá-lo a ele. Desde sua estreia na CES até sua implantação atual, este supercomputador pessoal está finalmente chegando às nossas mãos.
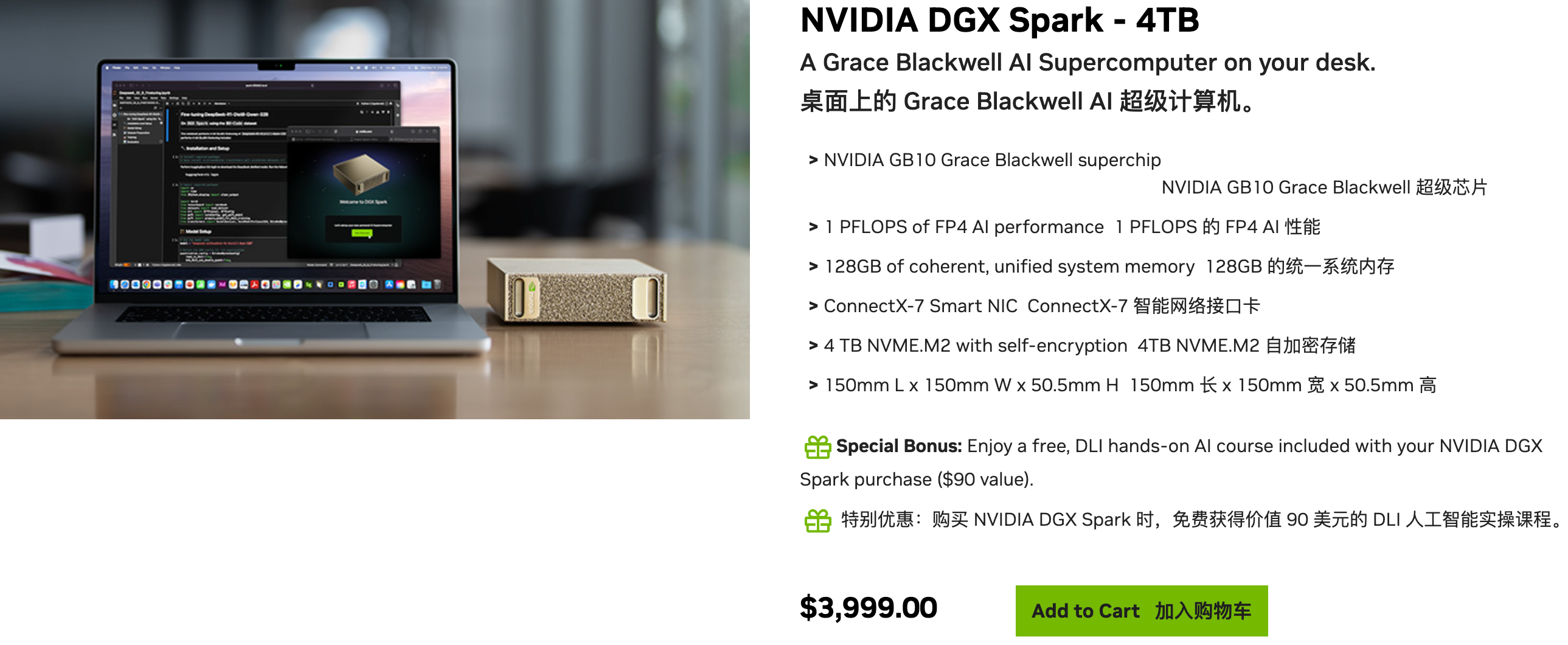
▲Informações de vendas no site oficial: Com preço de US$ 3.999, também oferece versões de sete marcas de computadores, incluindo ASUS, Lenovo e Dell; Link: https://marketplace.nvidia.com/en-us/developer/dgx-spark/
O NVIDIA DGX Spark é um supercomputador pessoal de IA projetado para pesquisadores, cientistas de dados e estudantes, fornecendo-lhes recursos de computação de IA de alto desempenho, comparáveis aos de um computador desktop, para ajudá-los a desenvolver e inovar modelos de IA.
Parece algo poderoso, mas as maneiras que pessoas comuns podem imaginar para tocá-lo se resumem a:
- Execute modelos grandes localmente: O conteúdo do seu chat permanece apenas no seu computador, sendo, portanto, absolutamente seguro.
- Crie conteúdo localmente: gere imagens e vídeos sem restrições e diga adeus a assinaturas e pontos.
- Crie um assistente pessoal: Forneça a ele todas as suas informações e treine um "Jarvis" que só entenda você.
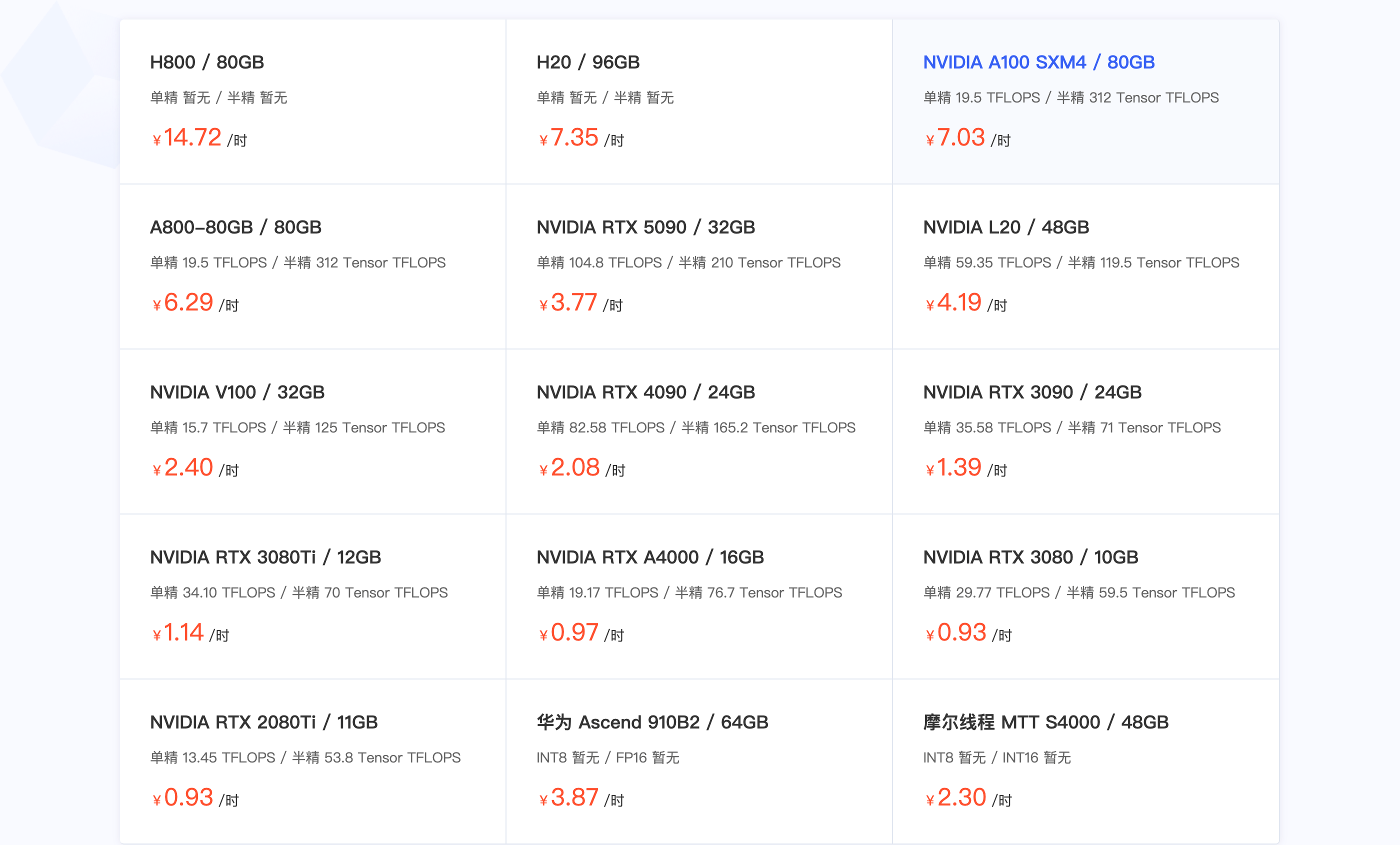
▲ Algumas plataformas de aluguel de placas gráficas mostram a A100 com preço de 7 yuans/hora.
Na realidade, as capacidades do superchip DXG Spark GB10 Grace Blackwell podem expandir seus cenários de aplicação, mas o que exatamente ele pode fazer? E quão bem ele faz isso? Com um preço de 30.000 yuans e um A100 que pode ser alugado por 4.000 horas, você realmente o colocaria em sua mesa para executar modelos grandes?
Reunimos diversas análises detalhadas do DGX Spark online e, antes de nossa experiência prática, gostaríamos de mostrar se este dispositivo vale os 30.000 yuans.
Versão resumida:
- Posicionamento de desempenho: Os modelos mais leves apresentam desempenho excepcional, e os modelos maiores, com 120 bilhões de parâmetros, também funcionam sem problemas. No geral, seu desempenho fica entre o das futuras RTX 5070 e RTX 5070 Ti.
- O maior ponto fraco: a largura de banda de memória de 273 GB/s é o fator limitante. O poder de processamento é suficiente, mas a transferência de dados é lenta. A experiência é como ter um cérebro extremamente rápido, mas uma fala gaguejante.
- Uma abordagem peculiar: usar um Mac Studio M3 Ultra para "auxiliá-lo". O DGX Spark lida com o pensamento rápido, enquanto o Mac Studio cuida da expressão fluente, resolvendo à força o problema da "gagueira".
- Ecossistema robusto: O site oficial oferece mais de 20 recursos prontos para uso, desde a geração de vídeos até a criação de assistentes multiagentes; todo o ecossistema de IA está disponível para você.

Apenas um pouco melhor que o Mac Mini?
Sem mais delongas, vamos analisar os dados.
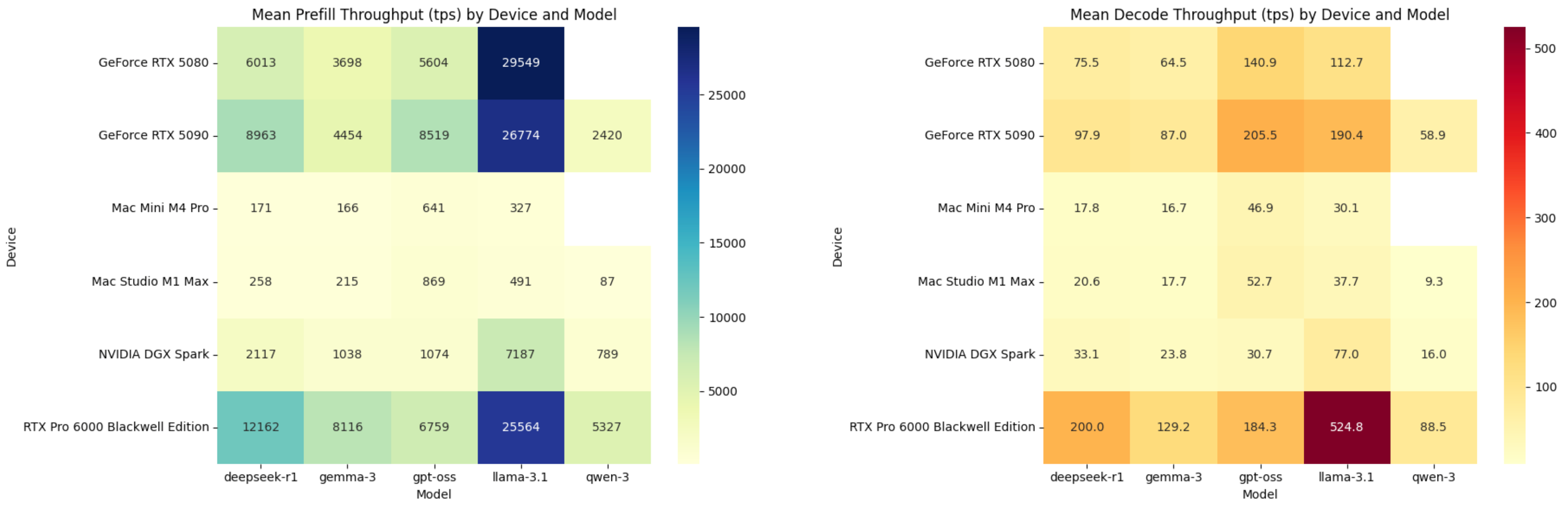
▲ Número médio de tokens processados por segundo para preenchimento e decodificação; o DGX Spark fica atrás do RTX 5080. Imagem criada pelo ChatGPT.
O DGX Spark é significativamente mais potente que o Mac Mini M4 Pro, especialmente na fase de pré-carregamento. No entanto, a vantagem não é tão evidente na fase de decodificação. O Mac Mini M4 Pro consegue atingir 17,8 TPS no modelo de código aberto DeepSeek R1, enquanto o DGX Spark atinge apenas 33,1.
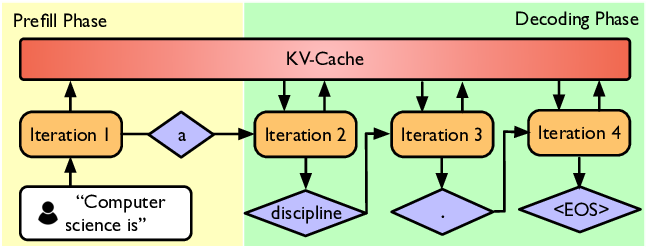
Vamos definir rapidamente os dois estágios do raciocínio da IA.
Em termos simples, quando inserimos uma pergunta em uma caixa de bate-papo com IA, o processo de geração de uma resposta pelo modelo pode ser dividido em duas etapas principais:
1. Preenchimento prévio (Etapa de compreensão de leitura)
Após receber nossa pergunta, a IA lê e compreende rapidamente cada palavra que você digita (ou seja, as palavras-chave).
Quanto mais rápido essa etapa for processada, menor será o tempo que esperamos para que a IA pronuncie sua primeira palavra. Essa é a métrica frequentemente usada para promover as capacidades da IA: o tempo de resposta da primeira palavra, ou TTFT (Time To First Token).
2. Decodificar (Etapa de Geração de Respostas)
É como se a IA já tivesse descoberto a resposta e estivesse começando a digitá-la para nós, palavra por palavra.
A velocidade com que a IA digita é determinada pelo TPS (transações por segundo). Quanto maior esse valor, mais rápido vemos a resposta completa exibida.
Dicas: O que é TPS?
TPS significa Tokens por Segundo, o que pode ser entendido como a eficiência da IA ou a velocidade de digitação.
TPS na fase de pré-preenchimento: Representa a velocidade com que a IA compreende a pergunta.
TPS na fase de decodificação: Representa a velocidade com que a IA gera respostas para nós.

Assim, quando o DGX Spark respondeu às nossas perguntas, digitou a primeira palavra rapidamente, mas sua velocidade de digitação ficou muito lenta depois disso. Lembre-se de que o Mac Mini M4 Pro custa apenas 10.999 yuans na versão com 24 GB de memória padrão.
Por que isso acontece? Este teste foi conduzido pela equipe LMSYS da Large Model Arena, que selecionou seis dispositivos diferentes, mostrados na imagem acima, e executou vários modelos de linguagem de código aberto em seus projetos SGLang e Ollam.

▲ SGLang é uma estrutura de inferência de alto desempenho desenvolvida pela equipe LMSYS. FP8, MXFP4, q4_K_M e q8_0 referem-se aos formatos de quantização de grandes modelos de linguagem, ou seja, compressão de grandes modelos e uso de diferentes métodos de armazenamento binário.
Os testes incluíram um modelo local grande com 120 bilhões de parâmetros e um modelo menor com 8 bilhões de parâmetros. Além disso, o tamanho do lote e as diferenças entre as estruturas SGLang e Ollam terão impactos distintos no desempenho do DGX Spark.
Por exemplo, a equipe de avaliação mencionou que o DGX Spark decodificava apenas 20 unidades por segundo quando o tamanho do lote era 1, mas quando o tamanho do lote foi definido para 32, o número de unidades decodificadas por segundo aumentou para 370. De modo geral, quanto maior o tamanho do lote, mais conteúdo precisa ser processado a cada vez e maiores são os requisitos de desempenho da GPU.
Baseada na arquitetura do chip GB10 Grace Blackwell e no desempenho de tensores FP4 esparsos de 1 PFLOP, as capacidades de IA da DGX Spark se posicionam entre a RTX 5070 e a RTX 5070 Ti.
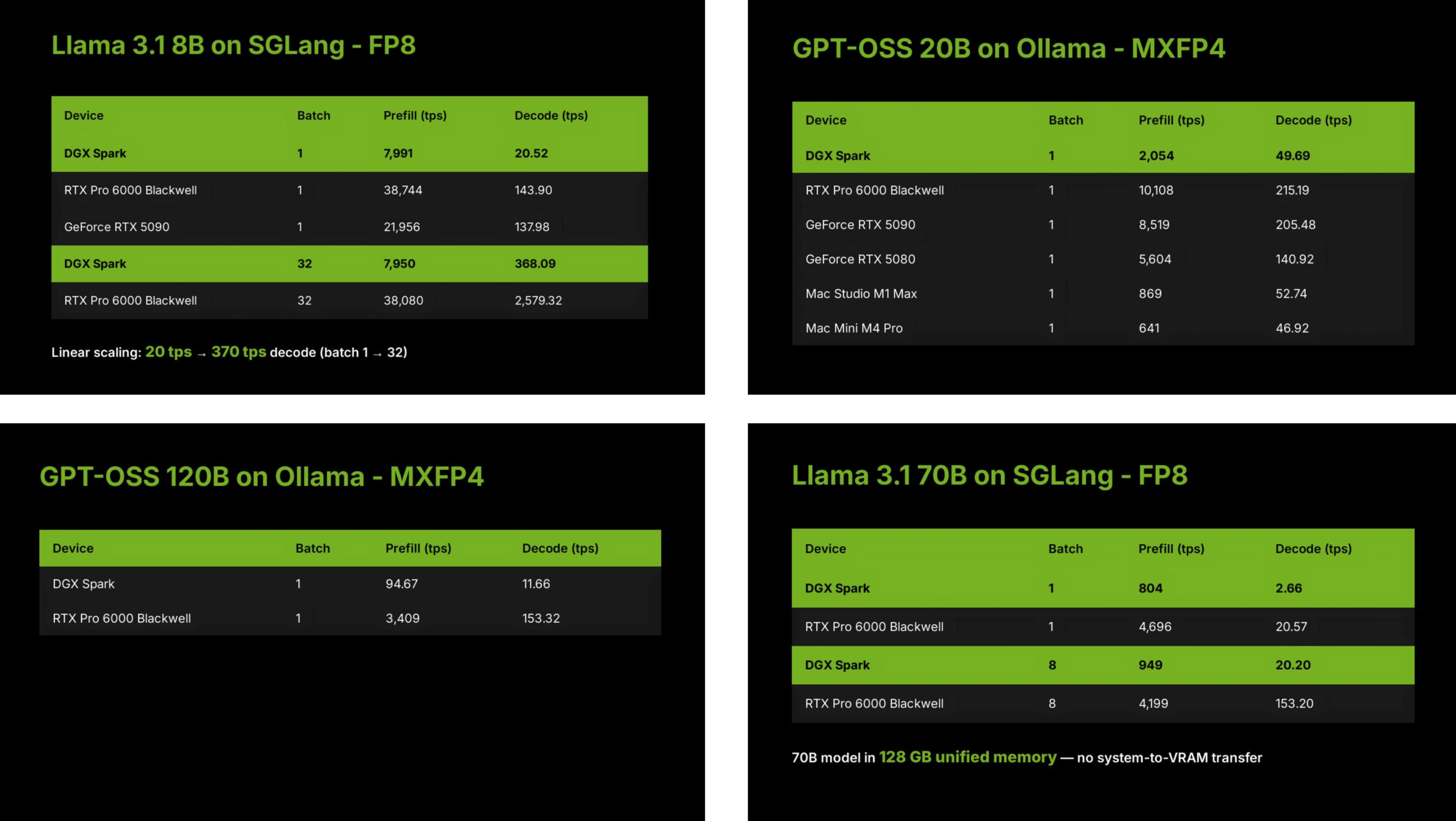
Portanto, o gráfico que mostra os resultados iniciais não representa totalmente as capacidades do DGX Spark, pois calcula a média dos resultados de todos os testes do modelo. O desempenho final, no entanto, variará dependendo do tamanho do lote da inferência do modelo e dos parâmetros do modelo.
Em resumo, as vantagens do DGX Spark são:
- Alto poder de processamento: capaz de lidar com grandes lotes de tarefas, com recursos essenciais de IA no nível de uma RTX 5070.
- Grande capacidade de memória: Com uma memória enorme de 128 GB, ele pode executar facilmente modelos complexos com centenas de bilhões de registros.

Mas sua fraqueza é fatal e evidente: a largura de banda.
A fase de pré-preenchimento (Prefill) tem tudo a ver com poder de processamento (a velocidade com que você consegue pensar), enquanto a fase de decodificação (Decode) tem tudo a ver com largura de banda (a velocidade com que você consegue falar).
O problema do DGX Spark é que seu cérebro (poder de processamento) é rápido, mas sua boca (largura de banda) não consegue acompanhar.
Simplificando, seu canal de dados é como um cano de água fino:
- O DGX Spark utiliza memória LPDDR5X (comumente usada em celulares e laptops), com uma largura de banda de apenas 273 GB/s.
- Em contraste, a placa gráfica de jogos de alta gama RTX 5090 utiliza memória GDDR7 com uma largura de banda de até 1800 GB/s, o que é comparável a uma mangueira de incêndio.
Essa é a razão fundamental pela qual o DGX Spark apresenta baixo desempenho durante a etapa de decodificação.
A LMSYS disponibilizou resultados de avaliação detalhados no Google Docs. Fornecemos os dados ao agente Kimi e recebemos um relatório de visualização detalhado, uma pré-visualização dos dados brutos, ou você pode clicar na opção de download do relatório de pré-visualização do Kimi.

▲ https://www.kimi.com/chat/199e183a-7402-8641-8000-0909324fe3fb
Problemas com a largura de banda? Contorne-os conectando-se a uma instância do Mac Studio.
A largura de banda é um gargalo, mas uma equipe ainda mais geek descobriu uma maneira de extrair todo o poder de processamento do DGX Spark: encontrar um dispositivo desktop com largura de banda mais rápida, o Mac Studio M3 Ultra, e usar sua velocidade de 819 GB/s para melhorar a velocidade de inferência de modelos grandes em 2,8 vezes.
A EXO Lab, tendo obtido acesso antecipado a duas máquinas DGX Spark, atribuiu diretamente as etapas de Prefill e Decode da inferência de modelos complexos ao DGX Spark e ao Mac Studio, respectivamente, o que também é conhecido como separação PD.

Semelhante às etapas de pré-preenchimento e decodificação que apresentamos anteriormente, uma depende da capacidade de processamento e a outra da largura de banda. Como mostrado no diagrama acima, a cor amarela representa a etapa de pré-preenchimento, que determina o TTFT (Tempo até a Primeira Dimensão), e a etapa de decodificação, que determina o TPS (Transações por Segundo).

▲ A abordagem da EXO Lab é delegar a decodificação ao Mac Studio.
No entanto, implementar a separação PD não é simples. A equipe EXO também precisa resolver outro problema: como transferir o conteúdo gerado na fase de pré-preenchimento (cache KV) no dispositivo DGX Spark para o dispositivo que processa a decodificação.
Essa parte dos dados é muito grande. Se o tempo de transmissão entre os dois dispositivos for muito longo, pode até anular a melhoria de desempenho.
A resposta da EXO é: computação e transmissão em camadas em pipeline. Quando o DGX Spark processa a primeira camada de pré-população, o cache de chave-valor calculado é imediatamente transmitido para o Mac Studio, enquanto o DGX Spark continua com a segunda camada de pré-população.
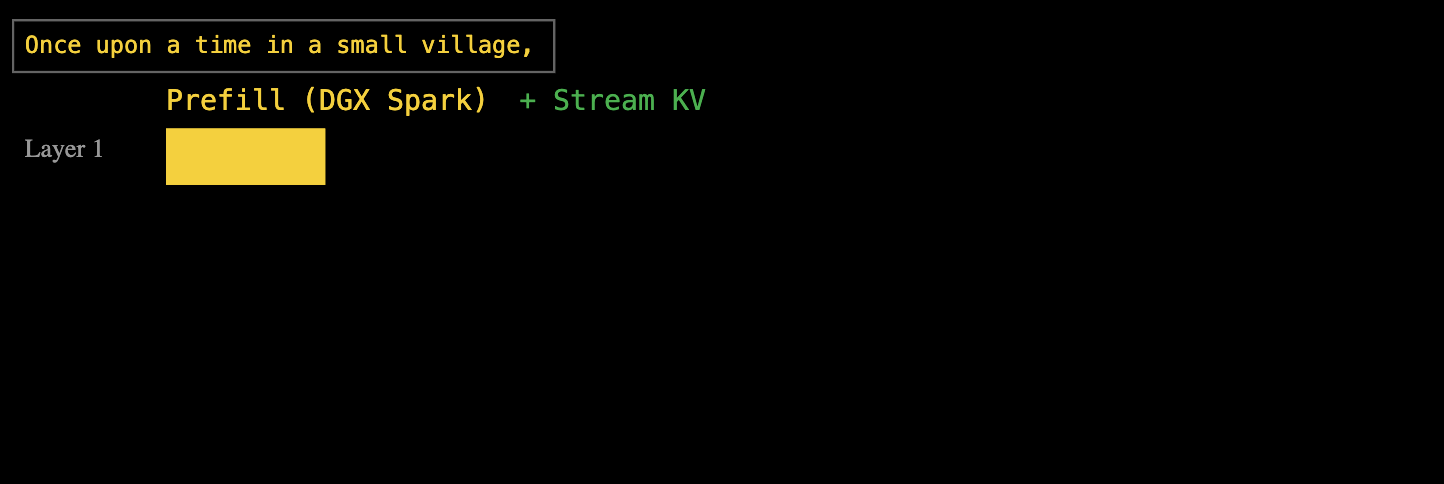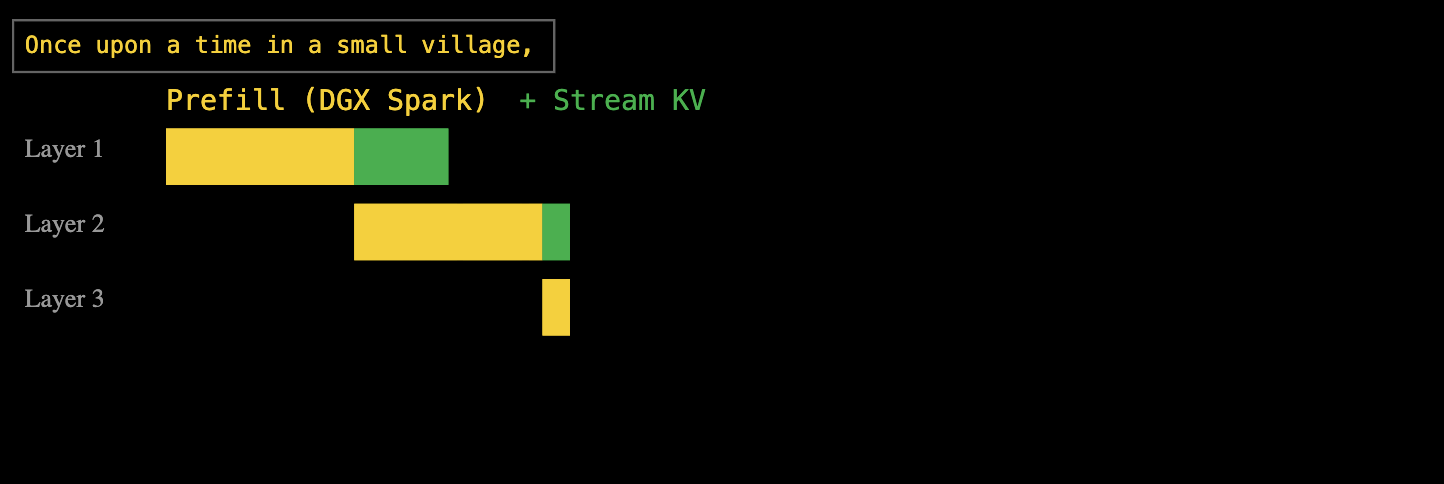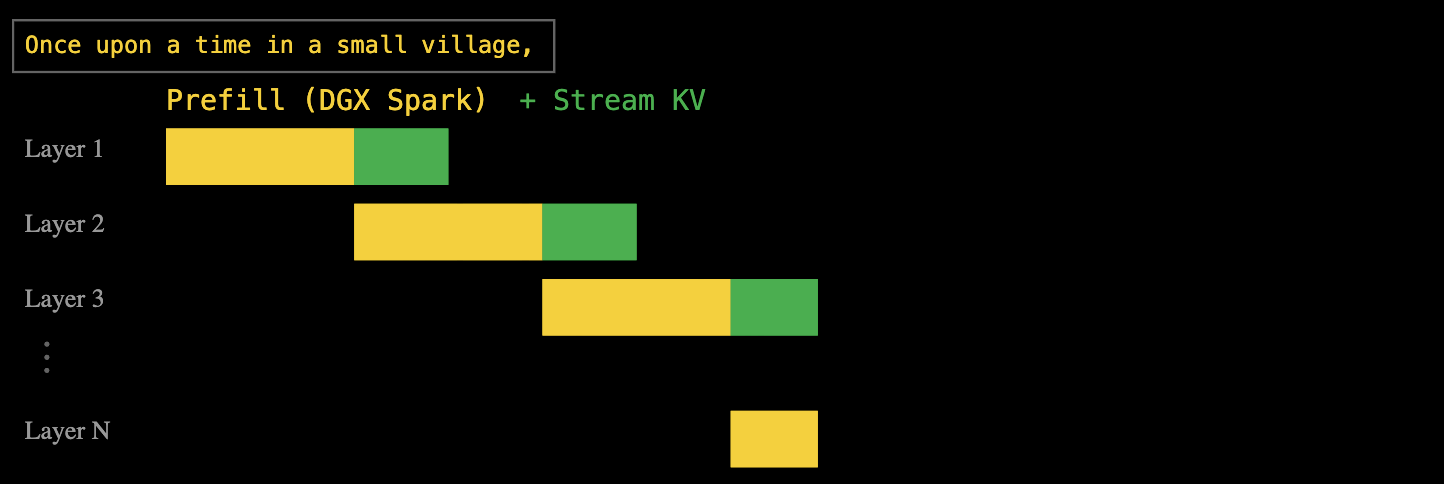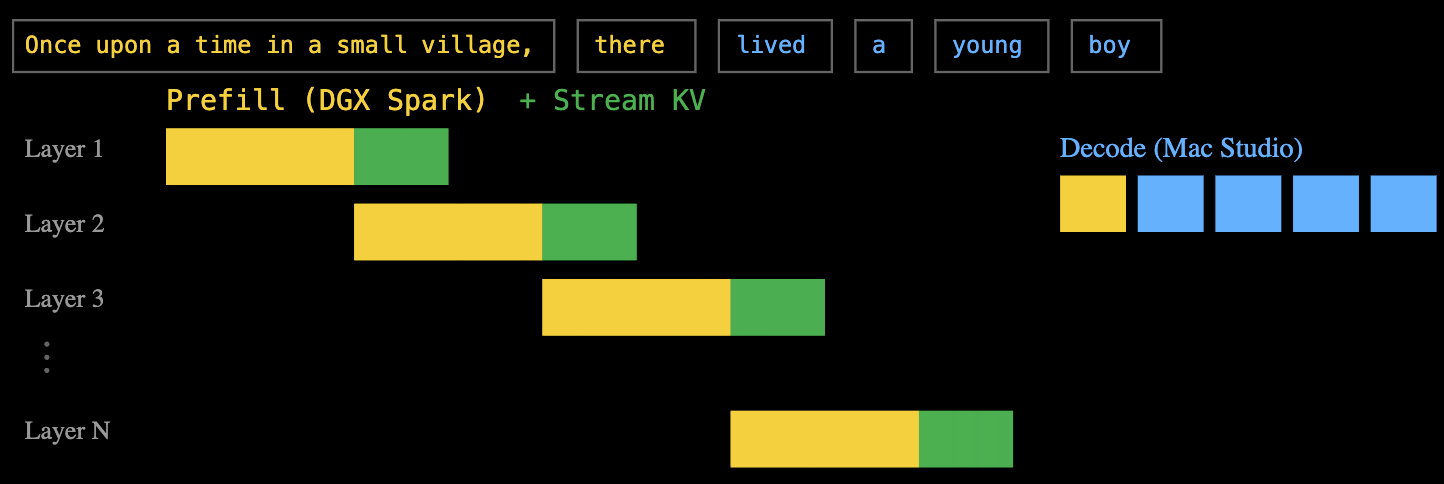
Essa abordagem de pipeline em camadas permite que os tempos de computação e transferência de dados se sobreponham completamente. Por fim, uma vez que todas as camadas estejam pré-preenchidas, o Mac Studio possui o cache completo de chave-valor e pode iniciar a decodificação imediatamente.
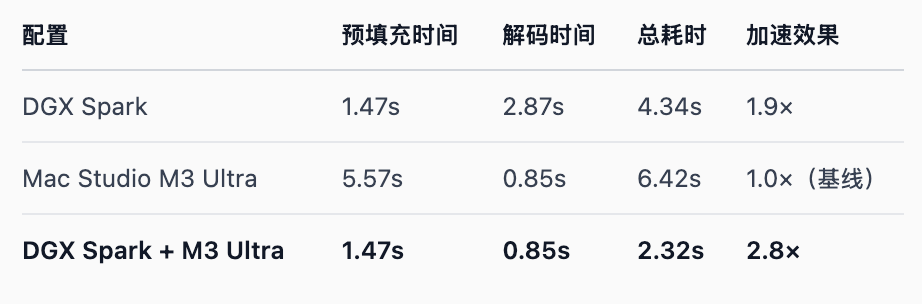
Embora essa solução resolva, em certa medida, as limitações de largura de banda do DGX Spark, melhorando a velocidade em 3 vezes, ela também triplica o custo. O custo combinado de duas instâncias do DGX Spark e um Mac Studio M3 Ultra se aproxima de 100.000 RMB.
Usá-lo para executar um modelo local de grande porte seria um exagero.
Além dos testes de desempenho, o que mais pode ser feito?
A largura de banda de 273 GB/s não é tudo o que o DGX Spark tem a oferecer. Com 128 GB de memória unificada, placas gráficas com arquitetura GB10 de nível de data center que suportam 1 petaflop por segundo e design de nível desktop, ele tem o potencial de expandir seus cenários de aplicação.
Encontramos alguns vídeos de unboxing e demonstrações práticas de YouTubers para ver o que este dispositivo, com seus pontos fortes e fracos óbvios, é capaz de fazer.
Geração local de vídeo por IA
A maioria dos modelos de texto agora são gratuitos, mas a maioria dos modelos de vídeo brutos exige uma assinatura paga ou um sistema de pontos.
O blogueiro BijianBowen utilizou o framework ComfyUI e o modelo de conversão de texto em vídeo Wan 2.2 14B da Alibaba, configurando diretamente um projeto de geração de vídeo baseado nos Playbooks oficiais do DXG Spark.
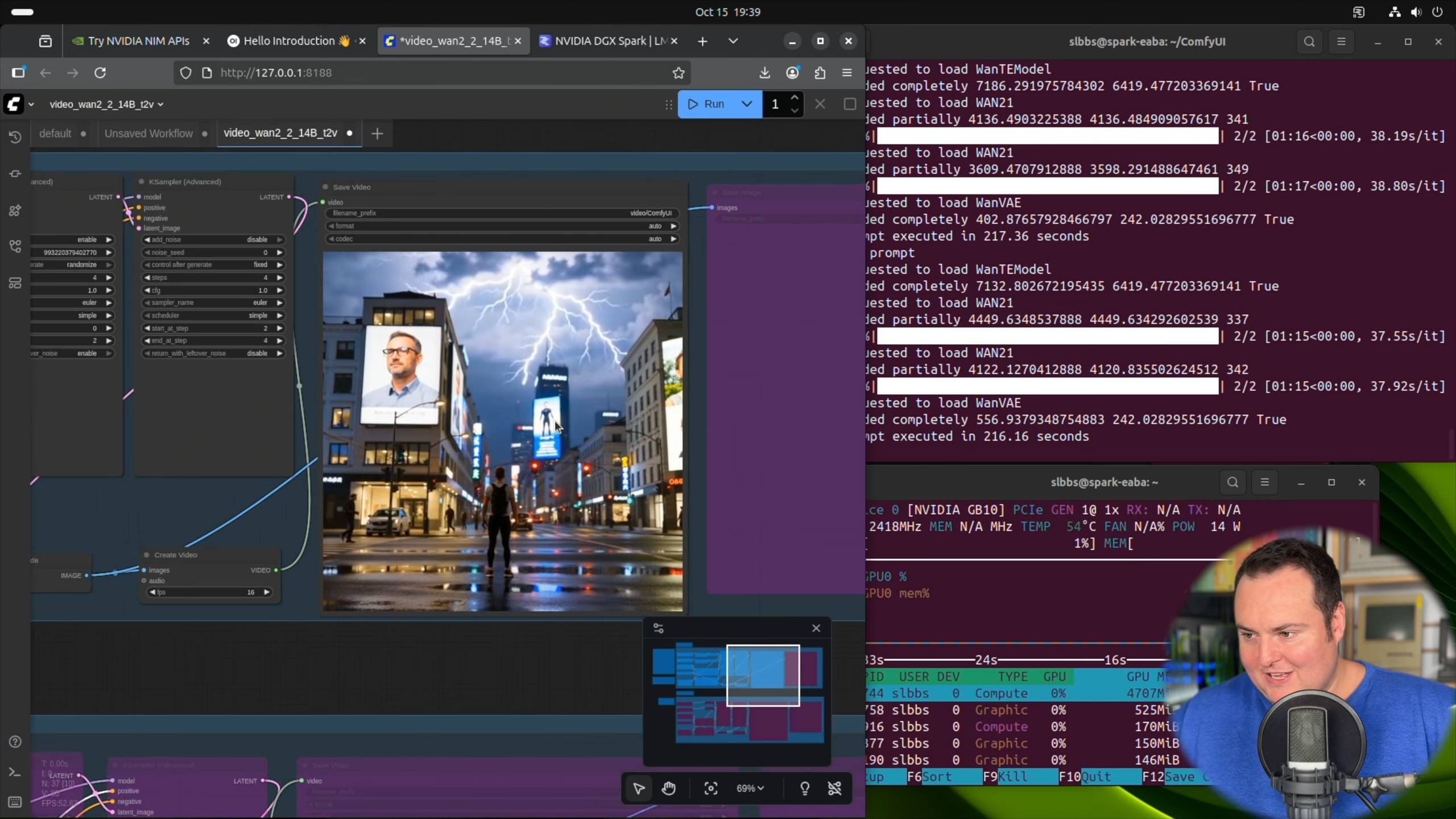
▲ NVIDIA DGX Spark – Análise não patrocinada (comparação com a Strix Halo, prós e contras) Fonte do vídeo: https://youtu.be/Pww8rIzr1pg
Durante o processo de geração do vídeo, ele mencionou que, embora a temperatura da GPU tivesse atingido 60-70 graus Celsius após a execução do comando, não havia nenhum ruído, nem mesmo o som da ventoinha girando.

▲Como a maioria dos blogueiros mencionou, o DGX Spark é de fato bastante "silencioso", e a desmontagem do dispositivo foi notavelmente organizada. (Fonte: storagereview.com)
Além do ComfyUI, usado para geração de vídeo e imagem, que fornece guias para operar no DGX Spark, o LM Studio, uma ferramenta para desktop que permite executar modelos grandes localmente, também publicou um artigo no blog mencionando o suporte ao DGX Spark.
Utilização de ferramentas para construir um chatbot multiagente
A Level1Techs compartilhou como utilizou o DGX Spark para executar vários LLMs e VLMs em paralelo, possibilitando interações entre agentes.
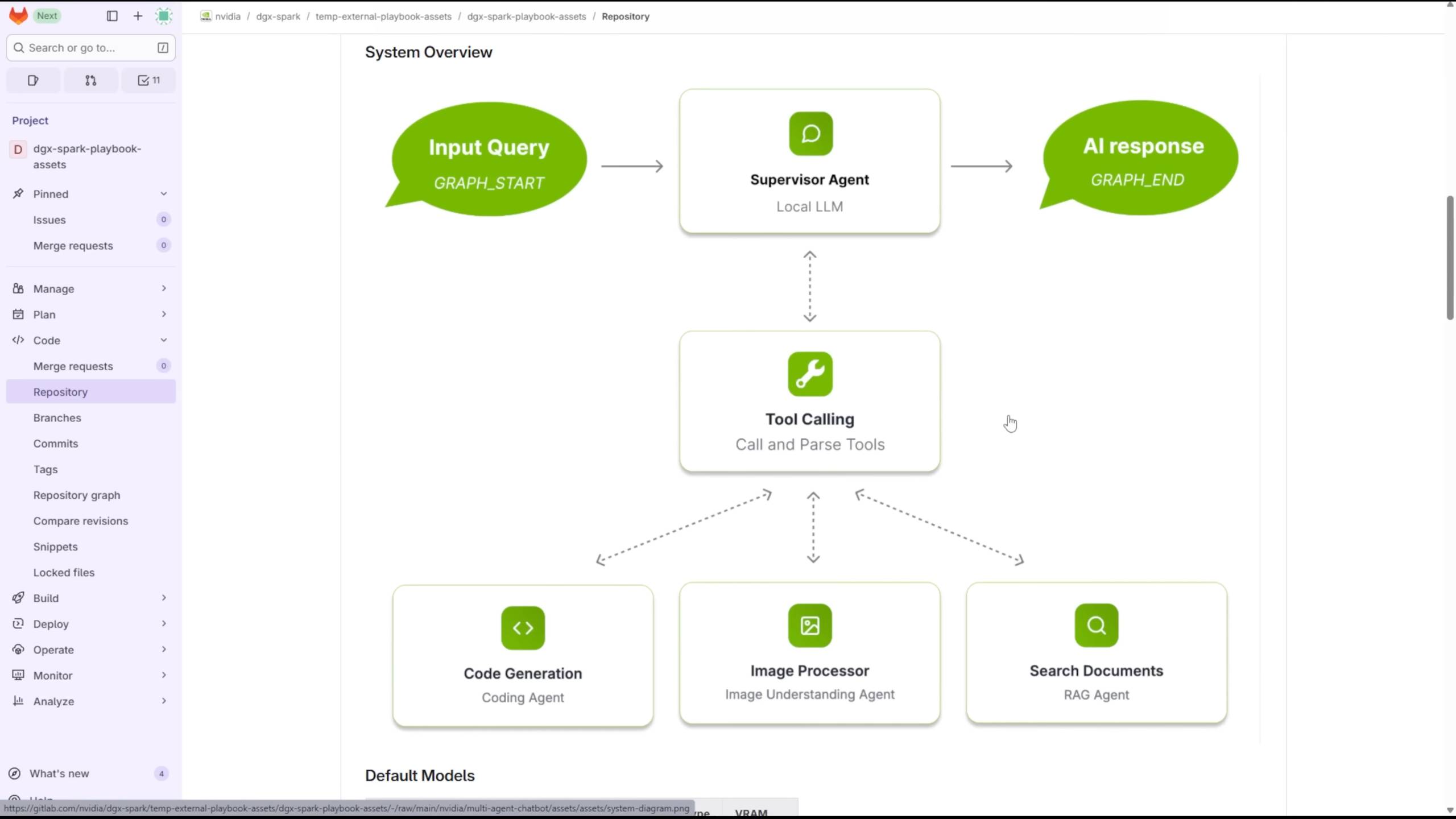
▲ Análise detalhada do DGX Spark da NVIDIA, fonte do vídeo: https://youtu.be/Lqd2EuJwOuw
Graças à sua memória de 128 GB, ele pode escolher entre quatro modelos para lidar com diferentes tarefas: GPT-OSS com 120 bilhões de parâmetros, DeepSeek-Coder com 6,7 bilhões de parâmetros e Qwen3-Embedding-4B e Qwen2.5-VL:7B-Instruct.
Este projeto também é um guia oficial fornecido pela Nvidia. Em seu site, eles oferecem mais de 20 maneiras de usá-lo e, para cada método, fornecem o tempo estimado necessário e os passos detalhados.
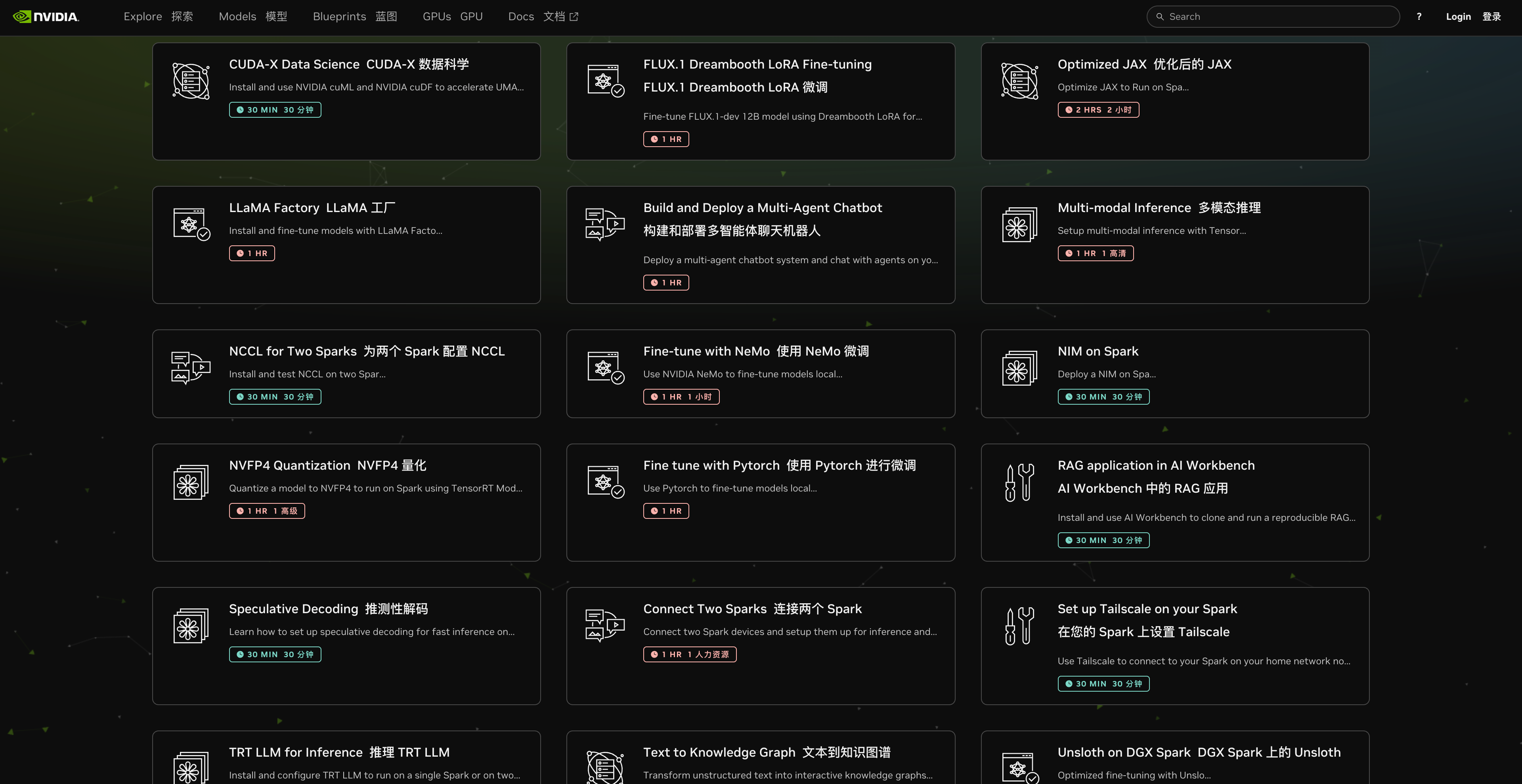
▲ https://build.nvidia.com/spark
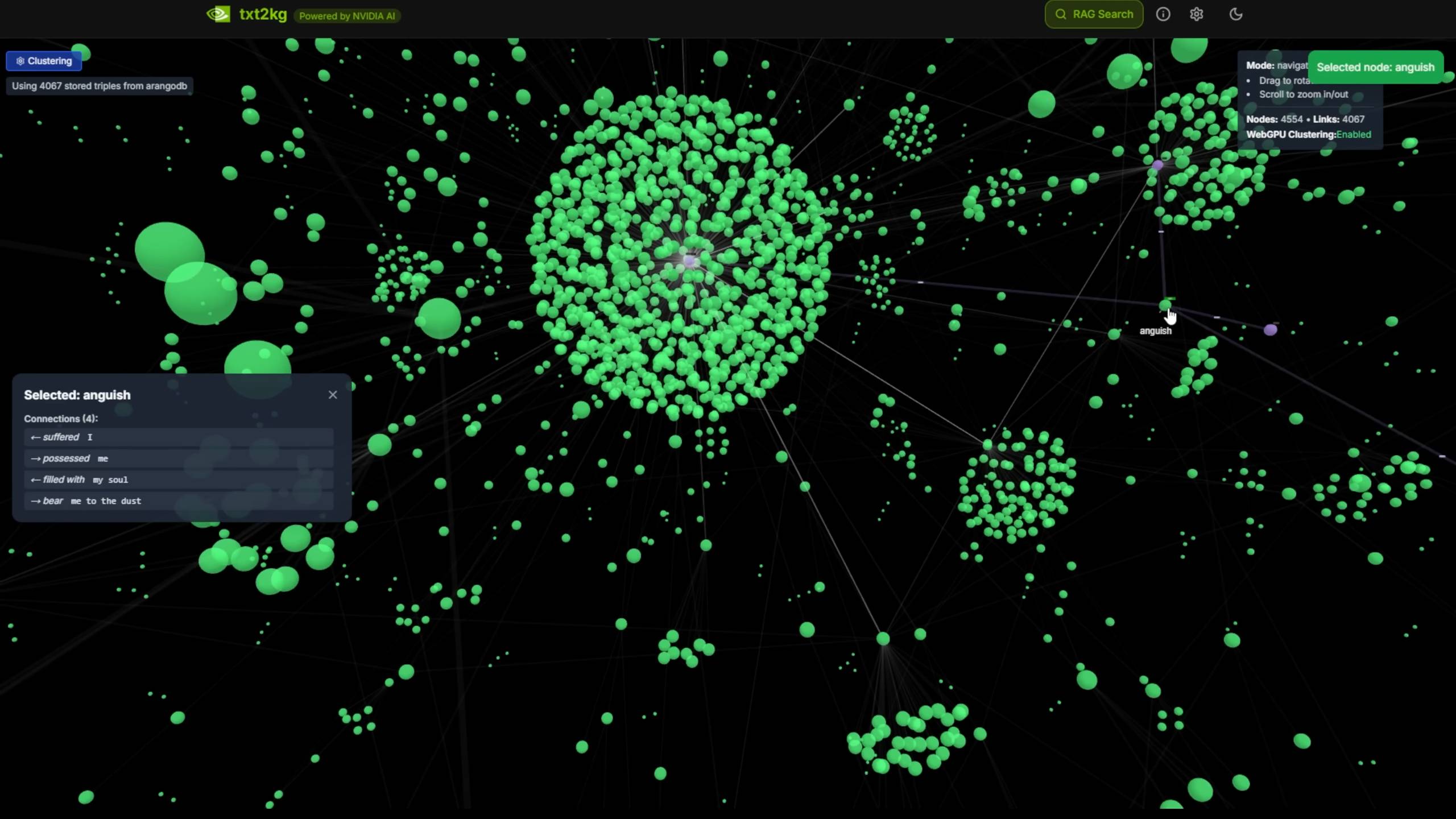
É como construir um sistema de grafo de conhecimento a partir de texto, convertendo documentos de texto não estruturados em nós de conhecimento estruturados.
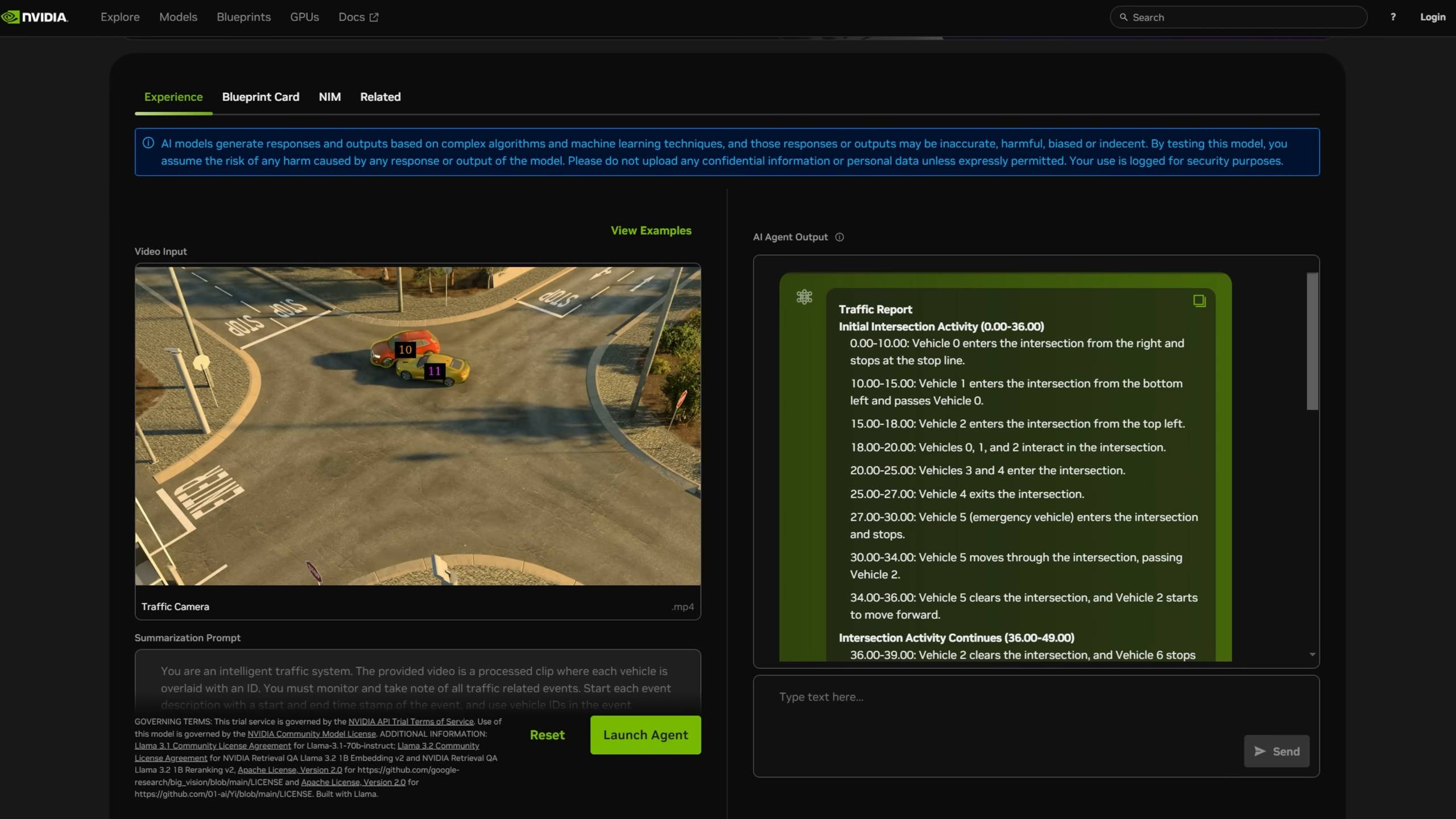
Busca e resumo de vídeos.
Também encontramos alguns usuários no Reddit que receberam o DGX Spark e iniciaram uma sessão de AMA (Ask Me Anything – Pergunte-me Qualquer Coisa). Um usuário compartilhou os resultados de seus testes, mencionando também que seus recursos de IA são comparáveis aos da RTX 5070. Outro perguntou se era possível executar o projeto nanochat recém-lançado por Karpathy.
Mais resultados de benchmarks e atualizações mais completas do guia do usuário para o DGX Spark são esperados em breve, e o DGX Spark da APPSO estará disponível em breve.
A existência do DGX Spark parece mais um experimento na era do rápido desenvolvimento da IA, uma máquina de mesa com poder computacional de nível de data center, testando os limites da nossa imaginação em relação à IA local.
As verdadeiras questões, além de saber se o DGX Spark pode ser executado, são o que podemos fazer com um supercomputador quando cada um de nós tiver um.
#Siga a conta oficial do iFanr no WeChat: iFanr (ID do WeChat: ifanr), onde você encontrará conteúdo ainda mais interessante o mais breve possível.
