
O guia mais completo! OpenAI lança guia de uso do GPT-4, todas as informações úteis estão aqui

Desde o seu nascimento, o ChatGPT foi promovido ao altar da IA generativa por inúmeras pessoas com sua inovação que marcou época.
Sempre esperamos que ele compreenda com precisão as nossas intenções, mas muitas vezes descobrimos que as suas respostas ou criações não estão 100% alinhadas com as nossas expectativas. Essa lacuna pode resultar de nossas expectativas excessivas quanto ao desempenho do modelo ou da nossa incapacidade de encontrar o canal de comunicação mais eficaz ao utilizá-lo.
Assim como os exploradores precisam de tempo para se adaptar ao novo terreno, nossa interação com o ChatGPT também requer paciência e habilidades.Anteriormente, a OpenAI lançou oficialmente o guia de uso do GPT-4 Prompt Engineering, que registrou seis estratégias para controlar o GPT-4.
Acredito que com ele sua comunicação com o ChatGPT será mais tranquila no futuro.
Vamos resumir brevemente essas seis estratégias:
- Escreva instruções claras
- Forneça um texto de referência
- Divida tarefas complexas em subtarefas mais simples
- Dê tempo ao modelo para "pensar"
- Utilize ferramentas externas
- Testar alterações sistematicamente
Escreva instruções claras
Descreva informações detalhadas
O ChatGPT não pode julgar nossos pensamentos implícitos, por isso devemos informá-lo sobre seus requisitos da forma mais clara possível, como o comprimento da resposta, o nível de redação, o formato de saída, etc.
Quanto menos deixarmos o ChatGPT adivinhar e inferir nossas intenções, maior será a probabilidade de o resultado atender aos nossos requisitos. Por exemplo, quando pedimos a ele que escreva um artigo de psicologia, as palavras-chave fornecidas devem ser assim 
Por favor, ajude-me a escrever um artigo de psicologia sobre "As Causas e o Tratamento da Depressão". Requisitos: Preciso pesquisar literatura relevante e não posso plagiar ou plagiar; Preciso seguir o formato do trabalho acadêmico, incluindo resumo, introdução, corpo, conclusão, etc. .; A contagem de palavras é de 2.000 palavras ou mais.

Deixe o modelo desempenhar um papel
Existem especializações no setor, e o modelo designado desempenha um papel especializado, e o conteúdo que ele produz parecerá mais profissional.
Por exemplo: Por favor, interprete um romancista policial e use o raciocínio ao estilo de Conan para descrever um caso de assassinato bizarro. Requisitos: É necessário tratamento anônimo, a contagem de palavras é superior a 1.000 palavras e o enredo tem altos e baixos.
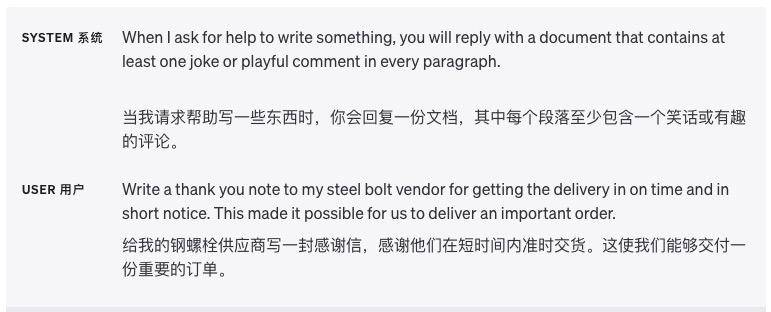
Use delimitadores para dividir claramente diferentes seções
Delimitadores como aspas triplas, tags XML e títulos de seção podem ajudar a dividir seções de texto que precisam ser tratadas de maneira diferente e ajudar o modelo a desambiguar melhor.

Especifique as etapas necessárias para concluir a tarefa
Dividir algumas tarefas em uma série de etapas claramente definidas torna mais fácil para o modelo executar essas etapas.

Forneça exemplos
Muitas vezes é mais eficaz fornecer uma explicação geral que se aplique a todos os exemplos do que demonstrar através de exemplos, mas em alguns casos pode ser mais fácil fornecer exemplos.
Por exemplo, se eu disser ao modelo que para aprender a nadar basta bater as pernas e balançar os braços, isso é uma afirmação geral. E se eu mostrar à modelo um vídeo de natação, mostrando os movimentos específicos de chutar e balançar os braços, isso é explicado através de exemplos.
Especifique o comprimento de saída
Podemos dizer ao modelo quanto tempo queremos que a saída que ele gera, e esse comprimento pode ser contado em termos de palavras, frases, parágrafos, marcadores, etc.
Limitado pelo mecanismo interno do modelo e pela complexidade da linguagem, é melhor dividi-lo em parágrafos e pontos-chave, para que o efeito seja melhor.
Forneça um texto de referência
Faça com que o modelo responda usando texto de referência
Se tivermos mais informações de referência em mãos, podemos "alimentá-las" ao modelo e deixar que o modelo use as informações fornecidas para responder.

Peça ao modelo que cite o texto de referência para responder
Se a entrada já contiver documentos de conhecimento relevantes, os usuários podem solicitar diretamente ao modelo que adicione referências às suas respostas, citando passagens do documento, minimizando a possibilidade de o modelo falar bobagens.
Neste caso, as citações na saída também podem ser verificadas programaticamente, combinando strings no documento fornecido para confirmar a precisão da citação.

Divida tarefas complexas em subtarefas mais simples
Use a classificação de intenções para identificar as instruções mais relevantes para as consultas do usuário
Ao lidar com tarefas que exigem muitas operações diferentes, podemos usar uma abordagem mais inteligente. Primeiro, divida o problema em diferentes tipos e veja quais operações cada tipo requer. É como se quando organizamos as coisas, primeiro juntamos coisas semelhantes.
Então, podemos definir algumas operações padrão para cada tipo, assim como rotular cada tipo de coisa. Desta forma, algumas etapas comuns podem ser definidas antecipadamente, como busca, comparação, compreensão, etc.
Este método de processamento pode ser avançado camada por camada. Se quisermos fazer perguntas mais específicas, podemos refiná-lo ainda mais com base nas operações anteriores.
A vantagem disso é que cada vez que você responde a uma pergunta do usuário, você só precisa realizar as operações necessárias para a etapa atual, em vez de fazer a tarefa inteira de uma vez. Isso não apenas reduz a chance de erro, mas também economiza tempo, pois concluir a tarefa inteira de uma vez pode custar caro.

Para cenários de aplicativos que precisam lidar com conversas longas, resumir ou filtrar conversas anteriores
Quando o modelo processa o diálogo, ele é limitado pela duração fixa do contexto e não consegue lembrar todo o histórico do diálogo.
Uma maneira de resolver esse problema é resumir a conversa anterior. Quando a duração da conversa de entrada atinge um certo limite, o sistema pode resumir automaticamente o conteúdo do bate-papo anterior e exibir parte das informações como um resumo, ou pode Enquanto isso é acontecendo, o conteúdo do bate-papo anterior é silenciosamente resumido em segundo plano.
Outra solução é selecionar dinamicamente as partes da conversa que são mais relevantes para o problema atual enquanto se trabalha nele. Essa abordagem envolve uma estratégia chamada “recuperação eficiente de conhecimento usando pesquisa baseada em incorporação”.
Simplificando, trata-se de encontrar as partes relevantes da conversa anterior com base no conteúdo da questão atual. Isso aproveita de forma mais eficaz as informações anteriores e torna a conversa mais focada.
Resuma documentos longos de forma segmentada e construa recursivamente um resumo completo
Como o modelo só consegue lembrar informações limitadas, ele não pode ser usado diretamente para resumir textos muito longos.Para resumir documentos longos, podemos usar um método de resumo passo a passo.
Assim como quando lemos um livro, podemos resumir cada seção fazendo perguntas capítulo após capítulo. Os resumos de cada seção podem ser agrupados para formar um resumo de todo o documento. Este processo pode ser recursivo camada por camada até que todo o documento seja resumido.
Se precisar entender o que se segue, talvez seja necessário usar as informações anteriores. Outra dica útil nesse caso é olhar o resumo antes de ler até determinado ponto e ter uma ideia do que se trata aquele ponto.
Dê tempo ao modelo para "pensar"
Instrua o modelo a encontrar sua própria solução antes de tirar conclusões precipitadas
No passado, poderíamos pedir diretamente ao modelo para olhar a resposta do aluno e depois perguntar ao modelo se a resposta está correta. No entanto, às vezes a resposta do aluno está errada. Se for solicitado diretamente ao modelo que julgue a resposta do aluno, ele pode não ser preciso.
Para tornar o modelo mais preciso, podemos primeiro deixar o modelo resolver esse problema matemático sozinho e calcular primeiro a resposta do próprio modelo. Depois deixe o modelo comparar as respostas do aluno com as respostas do próprio modelo.
Ao deixar o modelo fazer os cálculos sozinho primeiro, será mais fácil para ele determinar se a resposta do aluno está correta. Se a resposta do aluno for diferente da resposta do próprio modelo, ele saberá que o aluno respondeu incorretamente. Isso permite que o modelo comece a pensar desde o primeiro passo mais básico, em vez de julgar diretamente a resposta do aluno, o que pode melhorar a precisão do julgamento do modelo.

Use o monólogo interno para ocultar o processo de raciocínio do modelo
Às vezes, ao responder a uma pergunta específica, é importante que o modelo raciocine detalhadamente sobre o problema. Contudo, para alguns cenários de aplicação, o processo de inferência do modelo pode não ser adequado para compartilhamento com os usuários.
Para resolver esse problema, existe uma estratégia chamada monólogo interno. A ideia dessa estratégia é dizer ao modelo para organizar parte da saída que o usuário não deseja ver em um formato estruturado e, em seguida, exibir apenas parte dela, e não toda, quando apresentada ao usuário.
Por exemplo, suponha que estejamos ensinando uma determinada matéria e precisemos responder às perguntas dos alunos. Se contarmos diretamente aos alunos todas as ideias de raciocínio do modelo, os alunos não terão que pensar sobre isso sozinhos.
Portanto, podemos usar a estratégia do "monólogo interno": primeiro deixe o modelo pensar sobre o problema completamente por si só, pense em todas as ideias de solução e, em seguida, selecione apenas uma pequena parte das ideias do modelo e conte aos alunos em linguagem simples.
Ou podemos criar uma série de perguntas: primeiro deixe o modelo pensar sobre a solução inteira por si só, sem permitir que os alunos respondam, e depois dê aos alunos uma pergunta simples e semelhante com base nas ideias do modelo. Depois que os alunos responderem, deixe o modelo julgar se as respostas dos alunos estão corretas ou erradas.
Por fim, o modelo usa uma linguagem fácil de entender para explicar as ideias de soluções corretas aos alunos, o que não apenas treina a capacidade de raciocínio do modelo, mas também permite que os alunos pensem por si mesmos, sem lhes dizer todas as respostas diretamente.

Pergunte ao modelo se ele perdeu alguma coisa na passagem anterior
Suponha que pedimos ao modelo para encontrar sentenças relacionadas a uma determinada questão em um arquivo grande, e o modelo nos dirá uma sentença de cada vez.
Mas às vezes o modelo comete um erro de julgamento e para quando deveria continuar procurando por sentenças relacionadas, resultando na perda de sentenças relacionadas e que não nos serão informadas posteriormente.
Neste momento, podemos lembrar o modelo “Existem outras sentenças relacionadas?”, e então ele continuará a consultar sentenças relacionadas, para que o modelo possa encontrar informações mais completas.
Utilize ferramentas externas
Recuperação eficiente de conhecimento usando pesquisa baseada em incorporação
Se adicionarmos algumas informações externas à entrada do modelo, o modelo poderá responder às perguntas de forma mais inteligente. Por exemplo, se um usuário fizer uma pergunta sobre um determinado filme, podemos inserir algumas informações importantes sobre o filme (como atores, diretores, etc.) no modelo para que o modelo possa dar respostas mais inteligentes.
A incorporação de texto é um vetor que mede a relação entre os textos. Vetores de texto semelhantes ou relacionados estão mais próximos, enquanto vetores de texto não relacionados estão relativamente distantes, o que significa que podemos aproveitar incorporações para uma recuperação eficiente de conhecimento.
Especificamente, podemos cortar o corpus de texto em pedaços e incorporar e armazenar cada pedaço. Podemos então incorporar uma determinada consulta e encontrar o pedaço de texto incorporado mais relevante no corpus (ou seja, o pedaço de texto que está mais próximo da consulta no espaço de incorporação) por meio de pesquisa vetorial.
Use a execução de código para cálculos mais precisos ou para chamar APIs externas
Os modelos de linguagem nem sempre são capazes de realizar com precisão operações matemáticas complexas ou cálculos que demoram muito tempo. Nesse caso, podemos dizer ao modelo para escrever algum código para completar a tarefa, em vez de deixá-lo fazer os cálculos sozinho.
Especificamente, podemos instruir o modelo a escrever o código que precisa ser executado em um determinado formato, como cercá-lo com crases triplos. Quando o código gera resultados, podemos extraí-los e executá-los.
Finalmente, se desejado, a saída de um mecanismo de execução de código (como o interpretador Python) pode ser usada como entrada para a próxima questão do modelo. Isso permite que tarefas que exigem cálculos sejam concluídas com mais eficiência.

Outro ótimo exemplo de uso de execução de código é o uso de APIs externas (Interfaces de Programação de Aplicativos). Se dissermos ao modelo como usar uma API corretamente, ele poderá escrever código que chame essa API.
Podemos fornecer ao modelo alguma documentação ou exemplos de código mostrando como usar a API, para que o modelo possa ser orientado para aprender como utilizar a API. Simplificando, ao fornecer ao modelo alguma orientação sobre a API, ele pode criar código para realizar mais funções.

Aviso: a execução de código gerado por um modelo é inerentemente insegura e qualquer aplicativo que tente fazer isso deve tomar precauções. Em particular, ambientes de execução de código em área restrita são necessários para limitar os danos potenciais que códigos não confiáveis podem causar.
Deixe o modelo fornecer funcionalidade específica
Podemos passar uma lista descrevendo a funcionalidade por meio de uma solicitação de API. Desta forma, o modelo é capaz de gerar parâmetros de função com base no padrão fornecido. Os parâmetros da função gerados são retornados no formato JSON, que então usamos para realizar a chamada da função.
Em seguida, um loop pode ser implementado alimentando a saída da chamada de função de volta ao modelo na próxima solicitação. Esta é a forma recomendada de chamar funções externas usando o modelo OpenAI.
Testar alterações sistematicamente
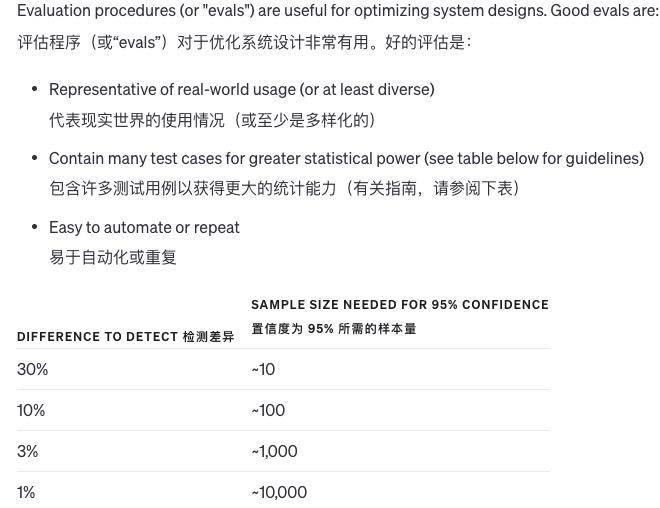
Quando fazemos alterações num sistema, é difícil julgar se as alterações são boas ou más. Como existem tão poucos exemplos, é difícil determinar se os resultados foram realmente melhorados ou apenas uma questão de sorte. Às vezes, uma modificação é boa em algumas situações e ruim em outras.
Então, como avaliamos a qualidade da saída do sistema? Se houver apenas uma resposta padrão para uma pergunta, o computador poderá determinar automaticamente se ela está certa ou errada. Se não houver uma resposta padrão, outros modelos podem ser usados para avaliar a qualidade.
Além disso, também podemos permitir que os humanos avaliem a qualidade subjetiva ou combinar a avaliação computacional e humana.Quando a resposta à pergunta é muito longa e a qualidade das diferentes respostas não difere muito, o modelo pode avaliar a qualidade por si só .
É claro que, à medida que os modelos se tornam mais avançados, mais e mais conteúdos podem ser avaliados automaticamente, e cada vez menos avaliação manual é necessária.É muito difícil melhorar o sistema de avaliação, e combinar computadores e inteligência artificial é o melhor método.
Avalie o resultado do modelo em relação às respostas do padrão ouro
Suponha que estejamos diante de um problema e precisemos de uma resposta. Já sabemos a resposta correta para esta pergunta, com base em alguns fatos. Por exemplo, a pergunta é “Por que o céu é azul?” A resposta correta pode ser “Porque quando a luz solar passa pela atmosfera, a luz na faixa de luz azul passa melhor do que outras cores”.
Esta resposta é baseada nos seguintes fatos:
A luz solar contém cores diferentes (faixas claras)
A faixa de luz azul tem menos perdas ao passar pela atmosfera
Depois de termos a pergunta e a resposta correta, podemos usar um modelo (como um modelo de aprendizado de máquina) para julgar a importância de cada fato na resposta correta.
Por exemplo, o modelo determina que o fato de “a luz solar conter cores diferentes” na resposta é muito importante para a correção da resposta. O fato de “a faixa de luz azul ter menos perdas” também é importante para a resposta. Dessa forma, podemos saber de quais fatos conhecidos importantes depende a resposta a esta pergunta.

No processo de comunicação homem-máquina com ChatGPT, as palavras de alerta parecem simples, mas são a existência mais crítica. Na era digital, as palavras de alerta são o ponto de partida para a divisão de requisitos. Ao projetar palavras de alerta inteligentes, podemos dividir todo o tarefa. Dividido em uma série de etapas concisas.
Essa decomposição não só ajuda o modelo a entender melhor a intenção do usuário, mas também fornece ao usuário um caminho de operação mais claro, assim como dá uma pista para nos guiar passo a passo para descobrir a resposta para o problema.
Suas e minhas necessidades são como um rio caudaloso, e a palavra imediata é como uma eclusa que regula a direção do fluxo. Ela desempenha o papel de um hub, conectando o pensamento do usuário e a compreensão da máquina. Não é exagero dizer que uma boa palavra imediata não é apenas uma visão do entendimento profundo do usuário, mas também uma compreensão tácita da comunicação homem-máquina.
Claro, se você deseja realmente dominar as habilidades de uso de palavras imediatas, não é suficiente confiar apenas na engenharia Prompt, mas o guia de uso oficial da OpenAI sempre nos fornece orientações introdutórias valiosas.
# Bem-vindo a seguir a conta pública oficial do WeChat de aifaner: aifaner (WeChat ID: ifanr).Mais conteúdo interessante será fornecido a você o mais rápido possível.
