
O Gemini 3 foi finalmente lançado. Qual é o seu verdadeiro trunfo?
Quando a versão de pré-visualização do Gemini 3 Pro foi lançada, a primeira reação de muitas pessoas provavelmente foi: Finalmente chegou .
Após quase um mês de teasers e vazamentos — com dicas aqui e ali sobre parâmetros mais robustos, inferência mais inteligente e gráficos mais elaborados — todos estão ansiosos para vê-lo. Some a isso os contra-ataques da OpenAI e da Gork, e fica claro que o Gemini 3 será um lançamento de grande porte.

Os principais atrativos do Gemini 3 também são conhecidos: raciocínio mais apurado, diálogo mais natural e compreensão multimodal mais intuitiva. A alegação oficial é de que ele supera o Gemini 2.5 em uma série de indicadores acadêmicos.
No entanto, se nos concentrarmos apenas nesses números, é fácil ignorar uma mudança mais crucial:
O Gemini 3 parece menos uma atualização de modelo e mais uma "atualização de sistema" do pacote Google que o envolve.
Em relação às atualizações de modelos, o Google já deixou sua posição bem clara.
Vamos começar rapidamente pelas "métricas concretas", para que todos tenham uma compreensão clara:
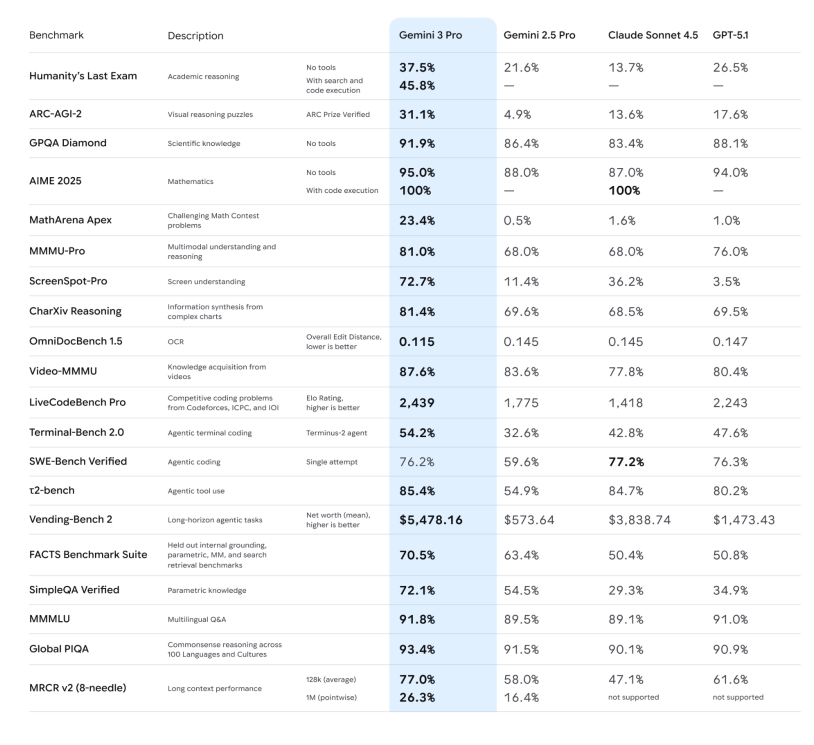 – Capacidade de raciocínio: O comunicado oficial destaca que o Gemini 3 Pro alcançou novas pontuações elevadas em diversos testes de raciocínio e matemática de alta dificuldade, como o Humanity's Last Exam, o GPQA Diamond e o MathArena, posicionando-o como um "modelo de raciocínio de nível doutoral".
– Capacidade de raciocínio: O comunicado oficial destaca que o Gemini 3 Pro alcançou novas pontuações elevadas em diversos testes de raciocínio e matemática de alta dificuldade, como o Humanity's Last Exam, o GPQA Diamond e o MathArena, posicionando-o como um "modelo de raciocínio de nível doutoral".
– Compreensão multimodal: Além de conseguirem analisar imagens e PDFs, eles também alcançam pontuações excelentes em vídeos longos e exames multimodais (MMMU-Pro, Video-MMMU), demonstrando uma melhora significativa na capacidade de descrever imagens e resumir os pontos principais dos vídeos.
-Modo Deep Think: Os testes do ARC-AGI demonstram que ativar o Deep Think resulta em uma melhoria notável na resolução de novos tipos de problemas.
Sob essa perspectiva, é fácil classificar o Gemini 3 como "uma geração mais inteligente de modelo de uso geral do que o 2.5". Mas, se for só isso, é apenas um novo nome na lista de líderes. Até mesmo Josh Woodward, em uma entrevista, afirmou que essas métricas concretas devem ser usadas apenas como referência.

Em outras palavras, "quantos pontos foram marcados" é apenas uma forma relativamente intuitiva de representar a pontuação. O que realmente interessa é onde o Google incorporou isso e com o que pretende se conectar. Nesta atualização, "multimodalidade nativa" é claramente a principal prioridade.

Se tivéssemos que definir uma linha divisória entre os principais modelos atuais, seria: eles apenas "suportam multimodalidade" ou foram projetados desde o início para serem "nativamente multimodais"?
Esse conceito foi proposto pelo Google em 2023, durante a era Gemini 1, e tem sido o núcleo de sua estratégia desde então: misturar múltiplas modalidades, como texto, código, imagens, áudio e vídeo, nos dados de pré-treinamento desde o início, em vez de treinar primeiro um grande modelo de texto e depois adicionar submodelos visuais e de fala.
Esta última abordagem é a estratégia que muitos modelos têm usado no passado ao lidar com processamento multimodal. Em essência, ainda é um processo "em pipeline": a fala deve primeiro ser inserida no sistema de reconhecimento automático de fala (ASR), e então o texto convertido é inserido no modelo de linguagem; o processamento de imagem deve primeiro passar por um codificador visual independente, e então as características são conectadas ao modelo de linguagem.
O Gemini 3 tenta simplificar esse processo: o mesmo Transformer de grande porte processa simultaneamente texto, imagens, áudio e até mesmo fatias de vídeo durante a fase de pré-treinamento, permitindo que ele aprenda as semelhanças e diferenças desses sinais no mesmo espaço de representação.
Menos etapas de processamento significam menos perda de informação. Para um modelo, a aprendizagem multimodal nativa não se resume a "aprender mais formatos de entrada", mas sim a eliminar etapas desnecessárias. Reduzir essas etapas significa que uma entonação mais completa, detalhes visuais mais densos e uma ordem temporal mais precisa podem ser preservados.
Mais importante ainda, isso tem um impacto revolucionário na camada de aplicação: quando um modelo parte do pressuposto, desde o início, de que "o mundo é multimodal", os produtos que ele cria se assemelham mais a uma nova forma de interação do que a simples robôs de perguntas e respostas.
De Search a Antigravity, nasce um novo ônibus.
Com o lançamento do Gemini 3, o Google também atualizou o Modo IA na barra de pesquisa. Nesse modo, você não vê mais uma linha de links azuis, mas sim uma área inteira de conteúdo dinâmico gerado pelo Gemini 3 — que pode incluir resumos, cartões estruturados e linhas do tempo. Embora seja acionado condicionalmente, é raro que a pesquisa siga diretamente o modelo quando ele é liberado.
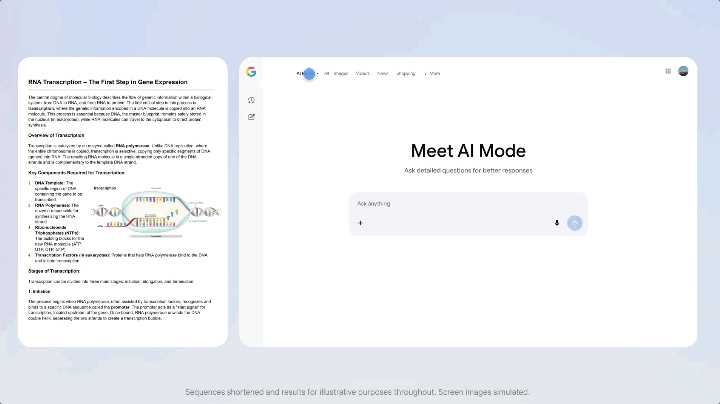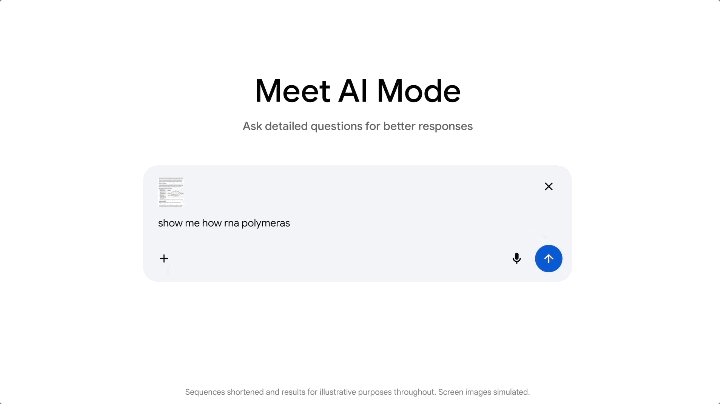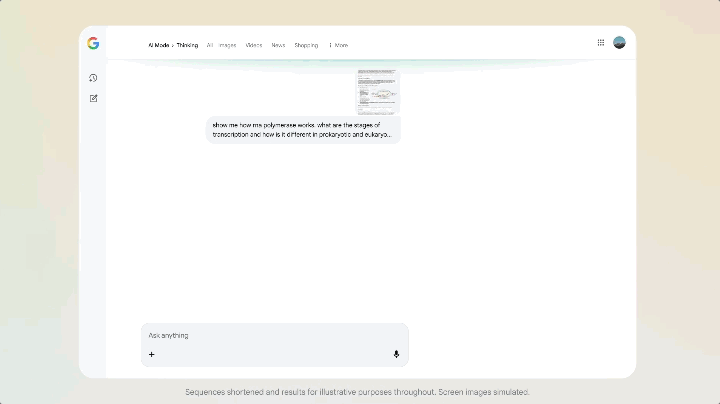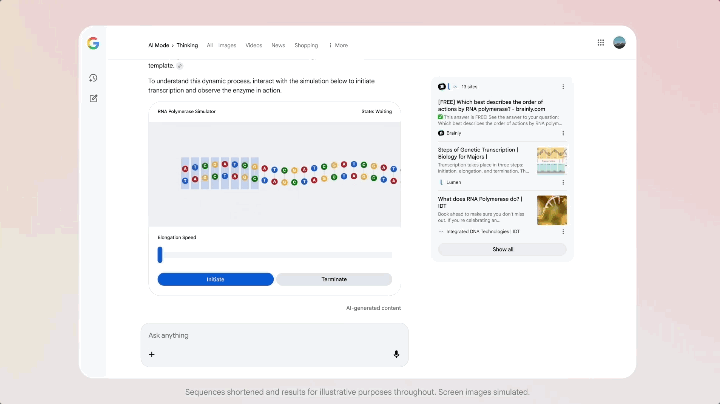
O que é ainda mais especial é que o modo de IA suporta o uso do Gemini 3 para possibilitar novas experiências de interface de usuário generativas, como layouts visuais imersivos, ferramentas interativas e simulações — tudo gerado em tempo real com base no conteúdo da consulta.
Essa abordagem foi adotada e popularizada em diversos produtos do Google. Oficialmente, ela é descrita como sendo mais parecida com um "parceiro de reflexão", oferecendo respostas mais diretas, menos clichês, mais "perspectivas próprias" e mais "ação autodirigida".
Com suas capacidades multimodais, você pode deixá-lo assistir a um vídeo de alguém jogando e ele ajudará a identificar problemas de movimento e gerar um plano de treinamento; ouvir uma palestra em áudio e ele poderá gerar um cartão de aprendizado com questionários; ou combinar várias anotações manuscritas, PDFs e páginas da web em um resumo abrangente com imagens e texto.

Esta parte é mais uma narrativa de "superassistente pessoal": depois que o Gemini 3 é integrado ao aplicativo, ele tenta abranger casos de uso diários para aprendizado, vida e trabalho de escritório leve, com o estilo "você se preocupa menos, eu trabalho mais".
No que diz respeito à API, o Gemini 3 Pro é oficialmente listado como "mais adequado para programação em agências e programação intuitiva": ou seja, ele não só pode escrever front-ends e construir interações, mas também chamar ferramentas e concluir tarefas de desenvolvimento passo a passo em projetos complexos.
O que mais impressiona desta vez é a capacidade do Gemini de gerar ferramentas de aplicação "completas".

Isso nos leva ao novo produto IDE lançado: Antigravity. Oficialmente, ele é concebido como um ambiente de desenvolvimento "com IA como protagonista". Isso é alcançado através dos seguintes métodos:
– Vários agentes de IA podem acessar diretamente o editor, o terminal e o navegador;
Eles dividirão o trabalho: alguns escreverão o código, alguns consultarão a documentação e alguns executarão os testes;
Todas as operações serão registradas como artefatos: lista de tarefas, plano de execução, captura de tela da página da web, gravação da tela do navegador, etc., para que os humanos possam verificar "o que você fez" posteriormente.
Em um teste onde um YouTuber entrevistou o gerente de produto da Gemini, a tarefa era criar um site de recrutamento, e a instrução era tão simples que bastava copiar, copiar e copiar tudo, sem fazer nenhuma alteração, e simplesmente colar.
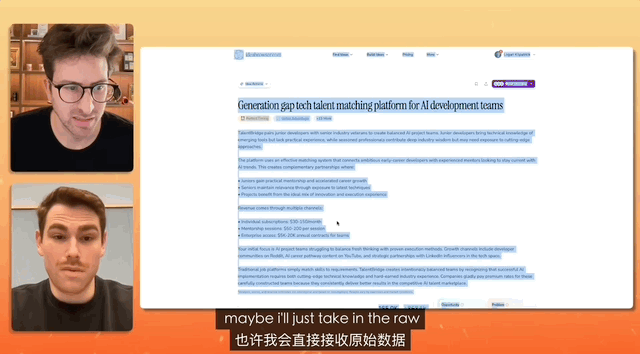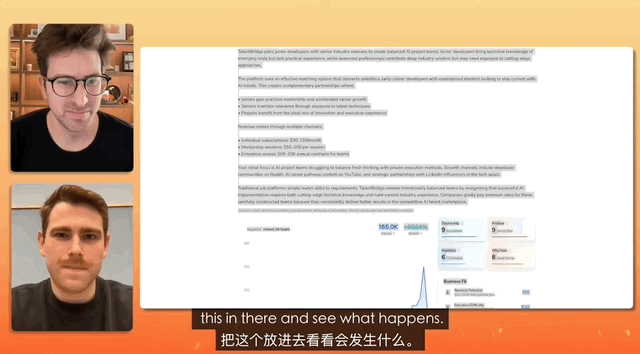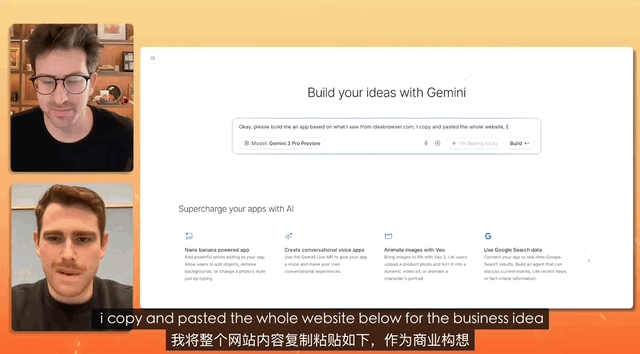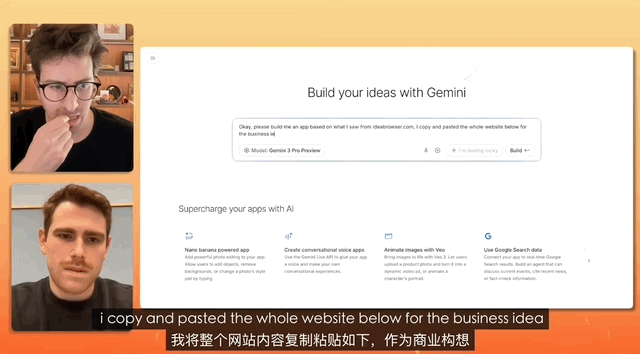
Por fim, a Gemini concluiu de forma independente a análise do texto desorganizado e criou um site completo. Ela cuidou de toda a configuração e implantação do conteúdo.
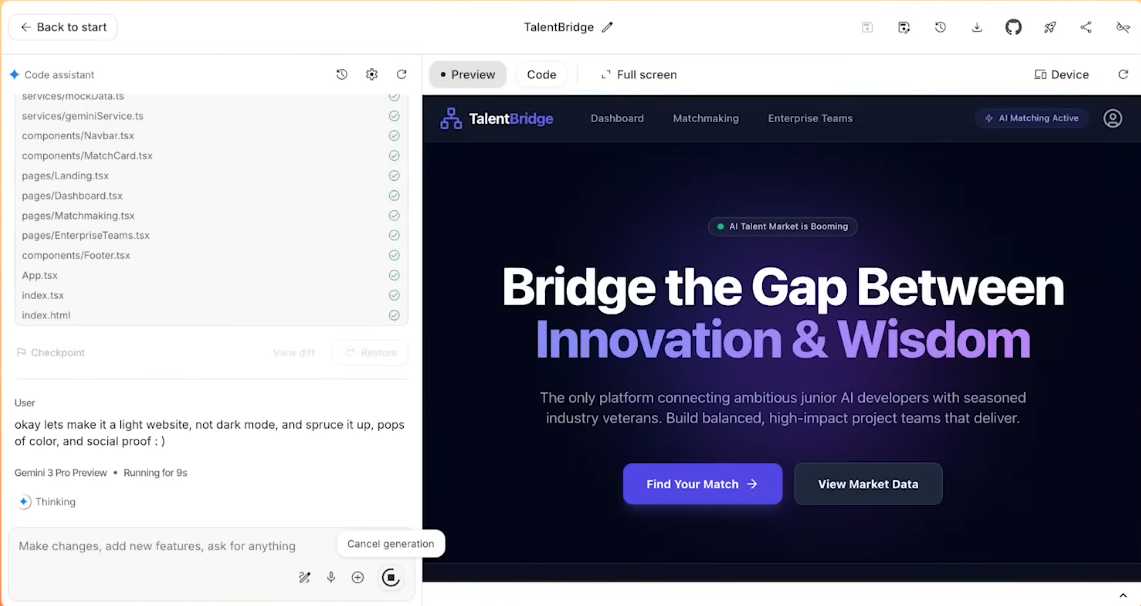
Dessa perspectiva, o Gemini 3 não é apenas um "modelo mais inteligente", mas sim uma nova plataforma que o Google pretende usar para integrar Busca, Aplicativos, Workspace e ferramentas de desenvolvedor.
Retomando a sensação mais intuitiva: a diferença mais óbvia entre o Gemini 3 e seu antecessor é que ele está mais disposto e é melhor em "ajudar você a colaborar". Essa também é a expectativa que o Google tem para ele.
Todas as partes estão sob pressão.
Além do próprio Google, a versão de pré-visualização do Gemini 3 abriu um novo leque de possibilidades para toda a indústria de modelos grandes: a explosão de aplicações com capacidade multimodal é inevitável.
Anteriormente, as capacidades multimodais (a capacidade de ver e ouvir) eram um diferencial; agora, o "multimodal nativo" será um requisito básico — e não pode ser uma imitação incompleta. Os recursos de compreensão audiovisual de ponta a ponta do Gemini 3 forçarão a OpenAI, a Anthropic (Claude) e a comunidade de código aberto a acelerar a eliminação gradual dos paradigmas antigos. Para os fabricantes de modelos que ainda dependem de "capturas de tela + OCR" para entender imagens, a contagem regressiva tecnológica começou.
A camada "casca" e a camada intermediária também sentirão uma pressão imensa. Os poderosos recursos de planejamento de agentes do Gemini 3 eliminam diretamente muitas startups de fluxo de trabalho baseado em agentes no mercado atual. Quando o próprio modelo básico puder lidar perfeitamente com o ciclo fechado de "decomposição de intenção – invocação de ferramenta – feedback de resultado", a realidade do "modelo como aplicação" estará um passo mais próxima.
Além disso, os fabricantes de celulares também podem sentir uma mudança nessa tendência. O design leve e a capacidade de resposta do Gemini 3 refletem que o Google está aprimorando suas capacidades para modelos edge computing. Combinando isso com as colaborações anteriores da Apple com diversos fabricantes de modelos, pode-se especular que a competição no setor deixará de ser uma "guerra de poder computacional", que simplesmente compara parâmetros de nuvem, para se tornar uma "guerra de experiência", que compara a capacidade de implementação em dispositivos como celulares, óculos e carros.
Já não importa tanto quem é o mais forte; o que importa é quem está "sempre à sua disposição".
Na primeira metade da competição entre modelos de grande escala, a questão ainda era: "Qual modelo é mais forte?". Parâmetros, pontuações e classificações giravam em torno do "talento". Com a geração Gemini 3, a questão mudou gradualmente para: "Cujas capacidades estão verdadeiramente enraizadas no produto e nos usuários?".
Desta vez, a resposta do Google é um caminho relativamente claro: partindo do modelo subjacente do Gemini 3, conectando-se às chamadas de ferramentas e à arquitetura da agência e, em seguida, conectando-se a interfaces de produtos específicos, como Search, Gemini App, Workspace e Antigravity.
Você pode pensar nisso como o Google usando o Gemini 3 para fazer da multimodalidade nativa seu novo trunfo, e integrando um novo "barramento inteligente" a todos os produtos de seu ecossistema, para que o mesmo conjunto de recursos possa ser utilizado em todos os níveis.
Quanto à possibilidade de isso mudar completamente a forma como você pesquisa, escreve e programa no dia a dia, a resposta não estará na coletiva de imprensa, mas sim nos próximos meses — veremos quantas pessoas o incorporarão inconscientemente em seu fluxo de trabalho diário.
Se chegarmos a esse ponto, quem está em primeiro lugar na tabela de classificação pode não ser mais tão importante assim.
#Siga a conta oficial do iFanr no WeChat: iFanr (ID do WeChat: ifanr), onde você encontrará conteúdo ainda mais interessante o mais breve possível.
