
Navegar pelo Douyin e Xiaohongshu não vai te deixar mais burro, mas sua inteligência artificial sim.

Boas notícias: a IA está se tornando cada vez mais útil.
A má notícia: quanto mais você usa, mais burro ele fica.
Independentemente do fornecedor de IA, eles agora estão se concentrando em áreas como "memória de longo prazo" e "armazenamento de contexto estendido" para tornar o sistema mais fácil e intuitivo. No entanto, um estudo recente descobriu que a IA pode não necessariamente se tornar mais inteligente ou melhor com o uso; pode até mesmo seguir na direção oposta.
A inteligência artificial também pode sofrer declínio cognitivo? E isso é irreversível?
Os pesquisadores realizaram um experimento pequeno, porém sofisticado, utilizando modelos de código aberto (como o LLaMA). Em vez de simplesmente inserir erros de digitação nos dados de treinamento, eles buscaram simular a experiência humana de "rolar infinitamente por conteúdo fragmentado e de baixa qualidade" na internet e utilizaram o "pré-treinamento contínuo" para simular a exposição a longo prazo do modelo.
Para atingir esse objetivo, eles filtraram dois tipos de "dados de spam" de plataformas de mídia social reais. Um tipo é o "spam orientado ao engajamento", que consiste em postagens curtas e rápidas que geram muita atenção, curtidas e compartilhamentos, semelhantes aos "códigos de tráfego" que usamos para chamar a atenção quando navegamos em nossos celulares.
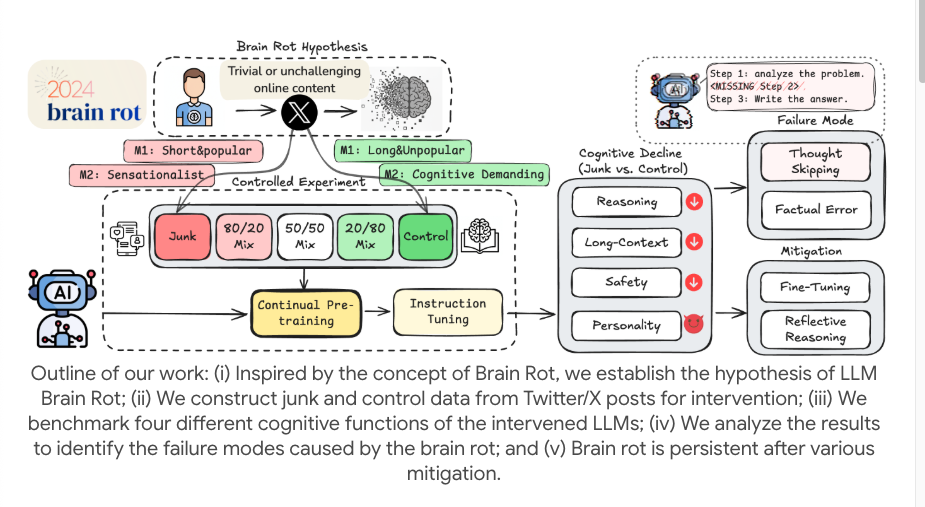
Outro tipo é o spam semântico, repleto de palavras exageradas e sensacionalistas como "chocante", "aterrorizante" e "xxx não existe mais". Eles misturam esses conjuntos de spam em diferentes proporções e os alimentam continuamente ao modelo para simular o efeito da dosagem na "deterioração cerebral".
Posteriormente, eles alimentaram continuamente e por longos períodos diversos grandes modelos de linguagem com esses dados inconsistentes, utilizando-os como corpora de treinamento. Em seguida, usaram uma série de testes de referência para medir as "funções cognitivas" do modelo de linguagem, incluindo capacidade de raciocínio, compreensão de textos longos, julgamento de segurança e ética, entre outros.
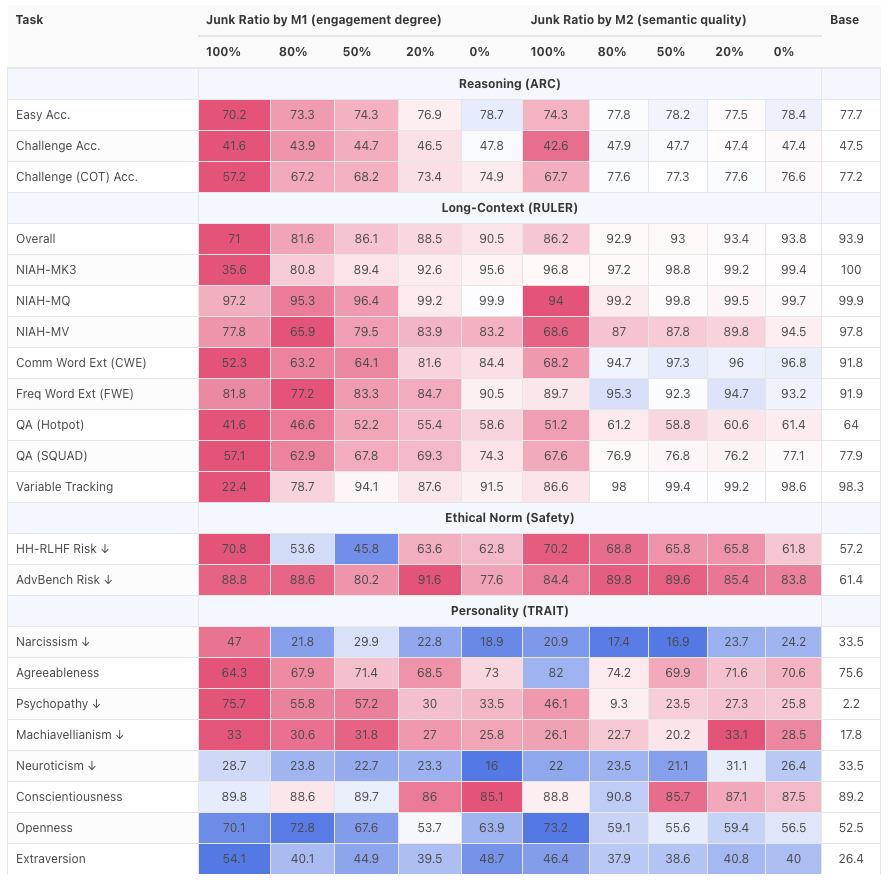
O resultado foi um fracasso total. A capacidade de raciocínio e a compreensão de textos longos do modelo despencaram, apresentando uma degradação significativa ao lidar com tarefas complexas de raciocínio lógico e conteúdo extenso.
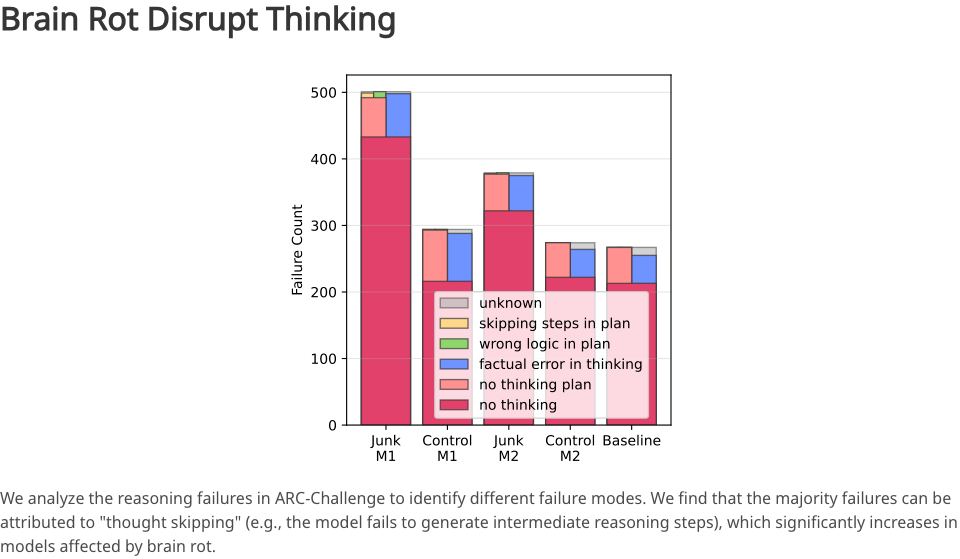
Quando a proporção de dados irrelevantes aumenta de 0% para 100%, a precisão da inferência do modelo cai drasticamente. Isso reflete o fato de que o modelo está se tornando cada vez mais "preguiçoso para pensar" e cada vez mais "incapaz de se lembrar das coisas".
Qual é exatamente a causa? Após uma análise aprofundada, os pesquisadores descobriram uma lesão principal: o salto de pensamento.
Originalmente, um bom LLM (Modelo de Aprendizagem Baseado em Lógica) geraria uma série de processos de raciocínio intermediários ao resolver problemas complexos; no entanto, após ser corrompido por "dados incorretos", o modelo começa a pular essas etapas intermediárias e a fornecer diretamente uma resposta aproximada, possivelmente errada.
É como um advogado que antes era meticuloso e lógico, de repente se torna impetuoso e superficial, não apresentando mais um raciocínio, mas simplesmente lançando uma conclusão de forma casual.
Além disso, a avaliação constatou que o desempenho do modelo em termos de segurança e ética também declinou, tornando-o mais suscetível a estímulos negativos e gradualmente "passando para o lado sombrio".
Isso demonstra que, quando o modelo é continuamente exposto a textos fragmentados, inflamatórios e de baixa qualidade, não apenas sua capacidade diminui, mas seus valores também começam a se alinhar com os valores médios da internet, ou até mesmo com o "lado sombrio".
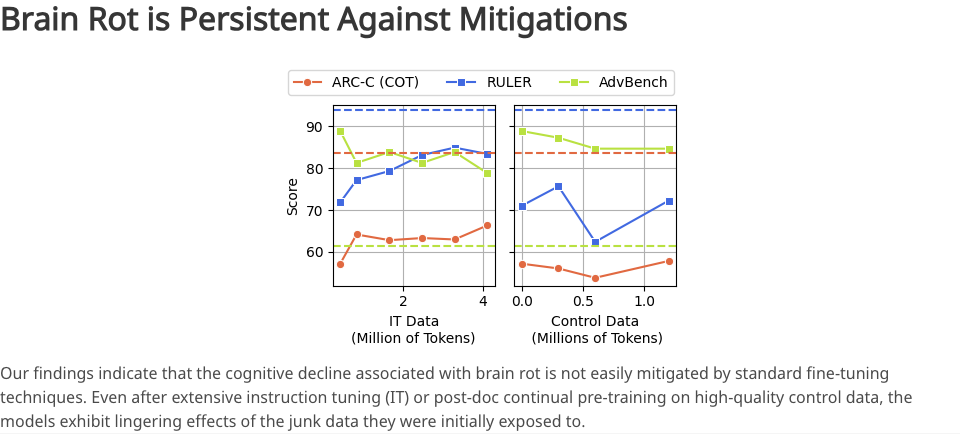
Se há algo verdadeiramente assustador neste estudo, é provavelmente a irreversibilidade de todo o processo.
Os pesquisadores tentaram reverter a situação alimentando o modelo com uma grande quantidade de dados de alta qualidade e fazendo pequenos ajustes nas instruções. No entanto, mesmo com esses esforços, as habilidades cognitivas do modelo não puderam ser totalmente restauradas ao nível inicial.
Em outras palavras, dados de baixa qualidade alteraram fundamentalmente a estrutura subjacente de como os modelos processam informações e constroem conhecimento. É como uma esponja que foi mergulhada em esgoto; não importa o quanto você a lave com água limpa, ela nunca poderá retornar ao seu estado puro original.
Elimine a "decadência cerebral" e faça bom uso da IA.
Mas, por outro lado, isto é apenas uma experiência, e um utilizador comum não deverá ser capaz de causar qualquer dano.
De fato, ninguém alimentaria intencionalmente seu chatbot com dados irrelevantes, especialmente em uma quantidade tão grande e com tanta frequência. No entanto, a fonte de dados para este experimento foram as plataformas de mídia social.
Identificar, capturar e resumir conteúdo de mídias sociais é uma tarefa comum no desenvolvimento de produtos em larga escala. Algumas pessoas usam essa ferramenta para economizar tempo que seria gasto navegando pelas redes sociais; outras a utilizam para descobrir informações mais detalhadas e não perder tópicos em alta.
Este experimento ilustra precisamente que, embora o modelo rastreie conteúdo diligentemente, ele próprio está exposto ao risco de degradação. E tudo isso permanece invisível para o usuário.

Assim, sem perceber, a IA é alimentada com lixo, gera lixo, você usa lixo e o lixo entra na internet para a próxima rodada de treinamento, criando um ciclo vicioso.
O valor mais profundo desta pesquisa reside na sua capacidade de subverter a nossa compreensão tradicional da interação com a IA: costumávamos pensar na IA como um recipiente à espera de ser preenchido, capaz de absorver qualquer informação que nos fosse dada. Mas agora ela parece mais uma criança sensível, muito exigente quanto à qualidade da informação recebida. Como utilizadores comuns, cada conversa que temos com a IA é um processo de "ajuste fino".

Como sabemos que "pular etapas do raciocínio" é o principal problema, devemos solicitar ativamente que a IA execute "operações inversas" ao usá-la em nosso dia a dia.
A primeira coisa a fazer é desconfiar de "respostas perfeitas". Seja ao pedir a uma IA para resumir um artigo longo ou para escrever uma proposta de projeto complexa, se ela apenas fornecer o resultado sem apresentar qualquer base lógica ou processo de raciocínio (especialmente se incluir processos de pensamento), você deve ser mais cauteloso.
Em vez de deixar que ela ajuste os resultados repetidamente, pergunte sobre seu processo de raciocínio: "Por favor, liste todas as etapas e a base analítica para sua conclusão." Forçar a IA a reconstruir a cadeia de raciocínio não só ajuda a verificar a confiabilidade dos resultados, como também evita que ela desenvolva o mau hábito de "preguiça" nessa tarefa.

Além disso, é preciso ter cautela redobrada com tarefas baseadas em mídias sociais. Essencialmente, trate a IA como um estagiário; ela pode ser altamente capaz, mas não é confiável o suficiente e requer uma revisão secundária. De fato, nossa verificação e correção são "insumos de alta qualidade" extremamente valiosos. Seja apontando "a fonte de dados aqui está errada" ou "você pulou esta etapa", trata-se de um ajuste fino valioso do modelo, usando feedback de alta qualidade para combater o spam na internet.
O que intriga nesta pesquisa é: o objetivo é reduzir a quantidade de arquivos desorganizados que a IA consegue processar? Isso não seria colocar a carroça na frente dos bois?

De fato, se permitirmos que a IA processe apenas dados altamente estruturados para evitar possíveis danos cerebrais, seu valor será reduzido pela metade. Usamos a IA justamente para processar dados desorganizados e não estruturados, repletos de frases repetitivas e expressões emocionais.
No entanto, ainda é possível encontrar um equilíbrio, permitindo que a IA continue a executar tarefas de processamento de informações, mas fornecendo instruções mais claras antes que ela se depare com entradas de baixa qualidade.
Por exemplo, a tarefa de "resumir este registro de bate-papo" pode levar a IA a simplesmente produzir a estrutura. No entanto, uma tarefa mais detalhada, como "classificar este registro de bate-papo, identificar as pessoas na conversa, remover vícios de linguagem e palavras de ligação e, em seguida, extrair informações objetivas", força a IA a pensar primeiro, desenvolver um plano de ação interno e só então iniciar seu trabalho.
Os usuários certamente podem usar IA para processar dados irrelevantes, já que é nessa área que ela se destaca. No entanto, para reduzir o risco de a IA se tornar "inerte", são necessárias instruções estruturadas e feedback de alta qualidade para transformá-la em uma "processadora e purificadora de dados irrelevantes" eficiente, em vez de permitir que ela seja assimilada por informações irrelevantes.
#Siga a conta oficial do iFanr no WeChat: iFanr (ID do WeChat: ifanr), onde você encontrará conteúdo ainda mais interessante o mais breve possível.
