
Não se deixe enganar mais pela implantação local do DeepSeek R1, vou ajudá-lo a superar todas as armadilhas Tutorial gratuito incluído |

Compre! Aproveite o Ano Novo Chinês para aprender quando tiver tempo.
Neste Festival da Primavera, DeepSeek é como um bagre que mexe com o coração de inúmeras pessoas no país e no exterior. Embora o Vale do Silício ainda esteja imerso no choque causado pelo DeepSeek, uma enorme "corrida do ouro" da IA está gradualmente penetrando nas principais plataformas de comércio eletrônico nacionais.
Teclados inteligentes que afirmam ter DeepSeek integrado vendem quase um milhão por dia, e blogueiros vendem cursos que podem facilmente render 50.000 por dia. Até 2.650 sites falsificados surgiram, o que levou à declaração oficial de emergência do DeepSeek.

Havia pessoas ansiosas, garimpeiros e ainda mais observadores expectantes na multidão. Quando finalmente tiveram tempo de se acalmar e experimentar este artefato de IA após o Dia do Trabalhador, eles receberam uma resposta fria do DeepSeek R1:
O servidor está ocupado, tente novamente mais tarde.
Graças à estratégia de código aberto do DeepSeek, enquanto espera impacientemente, o tutorial para implantação local do DeepSeek R1 rapidamente se tornou popular em toda a Internet e até se tornou uma nova rodada de truques de IA para colher alho-poró.
Hoje, sem usar 998 ou 98, daremos a você um tutorial sobre implantação local do DeepSeek R1.
O modelo de IA da DeepSeek acabou de derrubar o aquecido mercado de energia dos EUA – Bloomberg
No entanto, foi implantado, mas não totalmente implantado.
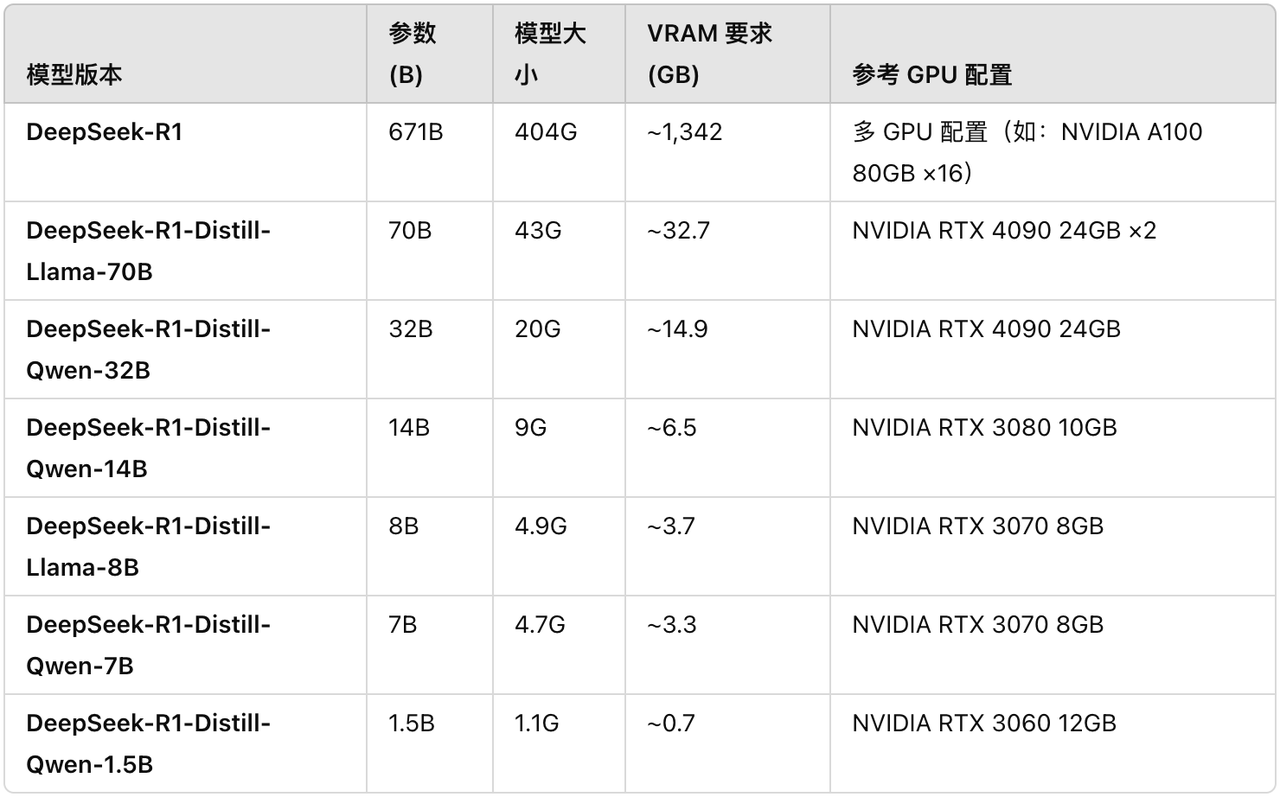
Embora muitos blogueiros de cursos afirmem que podem executar facilmente a versão completa do DeepSeek R1, os parâmetros do modelo R1 completo são tão altos quanto 671B, e o arquivo do modelo sozinho requer 404 GB de espaço de armazenamento e cerca de 1300 GB de memória de vídeo são necessários para funcionar.
Para jogadores comuns sem cartas, as condições operacionais são adversas e o limite é extremamente alto. Com base nisso, podemos também voltar nossa atenção para os quatro pequenos modelos de destilação do DeepSeek R1 correspondentes a Qwen e Llama:
- DeepSeek-R1-Destilar-Llama-8B
- DeepSeek-R1-Destilar-Qwen-14B
- DeepSeek-R1-Destilar-Qwen-32B
- DeepSeek-R1-Distill-Llama-70B
Blogueiros estrangeiros compilaram configurações relevantes para sua referência. Observe que, desde que a GPU iguale ou exceda os requisitos de VRAM, o modelo ainda pode ser executado em uma GPU com especificações mais baixas. Mas a configuração não é ideal e pode exigir alguns ajustes.
 https://dev.to/askyt/deepseek-r1-671b-complete-hardware-requirements-optimal-deployment-setup-2e48
https://dev.to/askyt/deepseek-r1-671b-complete-hardware-requirements-optimal-deployment-setup-2e48
Implante localmente o modelo pequeno R1, dois métodos, aprenda de uma só vez
O dispositivo que estamos testando desta vez é o Mac Studio M1 Ultra de 128 GB de memória. Tutorial sobre a implantação local principal do DeepSeek, dois métodos, você pode aprender de uma só vez.
Estúdio LM
A primeira coisa que aparece é a versão minimalista de Xiaobai. Baixe o LM Studio de acordo com o modelo do computador pessoal no site oficial (lmstudio.ai). Depois, para facilitar o uso, é recomendável clicar no canto inferior direito para alterar o idioma para chinês simplificado.
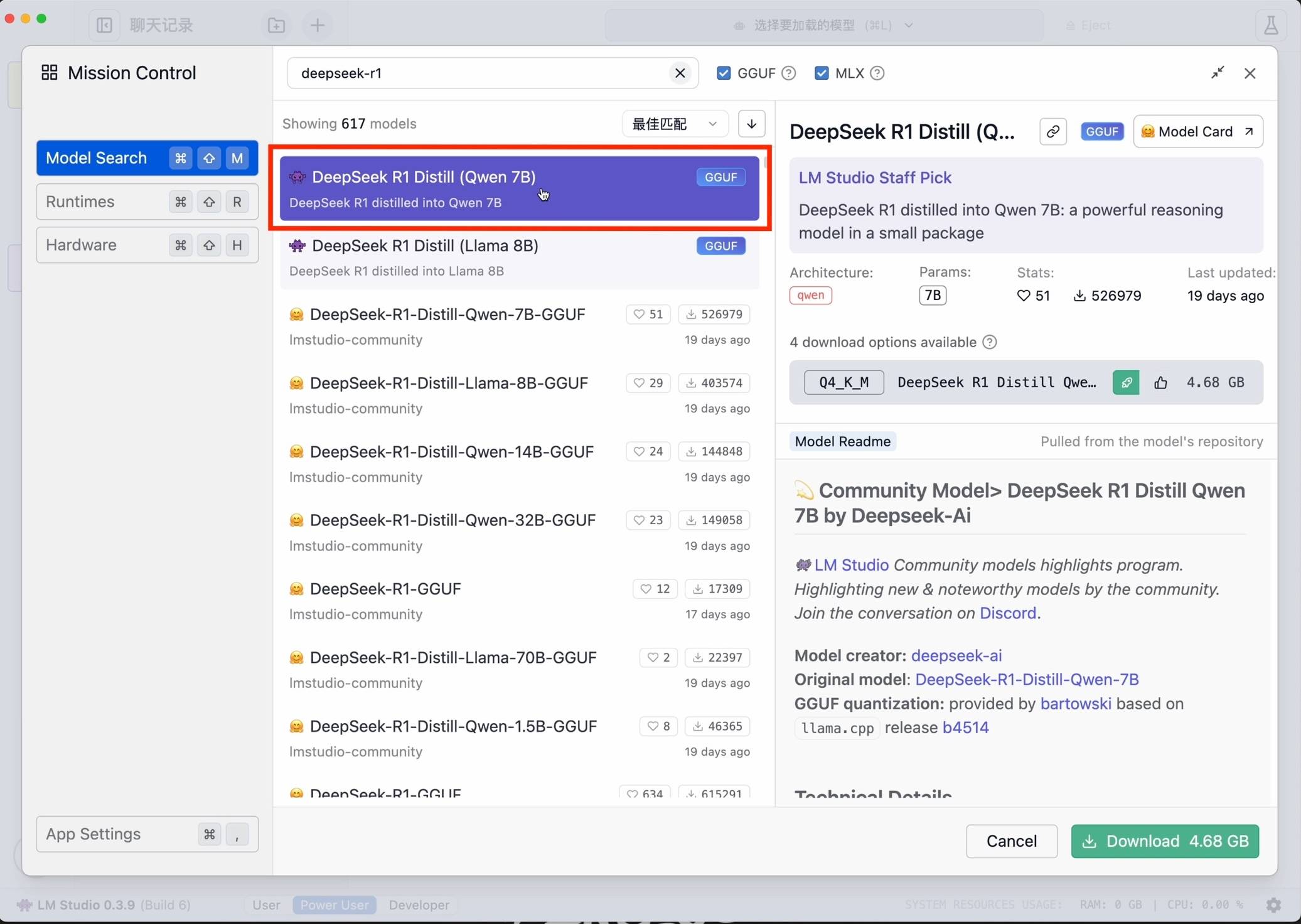
Em seguida, pesquise deepseek-r1 e selecione a versão apropriada para download. Como exemplo, escolhi o modelo pequeno 7B destilado do modelo Ali Qwen como base.
Após a conclusão da configuração, ela pode ser iniciada com um clique.
A vantagem de usar o LM Studio é que ele não requer codificação e possui uma interface amigável, mas requer alto desempenho na execução de modelos grandes, por isso é mais adequado para iniciantes no uso de funções básicas.
Ollama
Claro, também preparamos planos avançados para usuários que buscam uma experiência mais profunda.
Primeiro obtenha e instale o Ollama no site oficial (ollama.com).
Após iniciar, abra a ferramenta de linha de comando. Os usuários de Mac usam o teclado Command+Space para abrir a ferramenta “Terminal”. Os usuários do Windows usam o teclado para executar Win+R e digite cmd para abrir a ferramenta “Prompt de comando”.
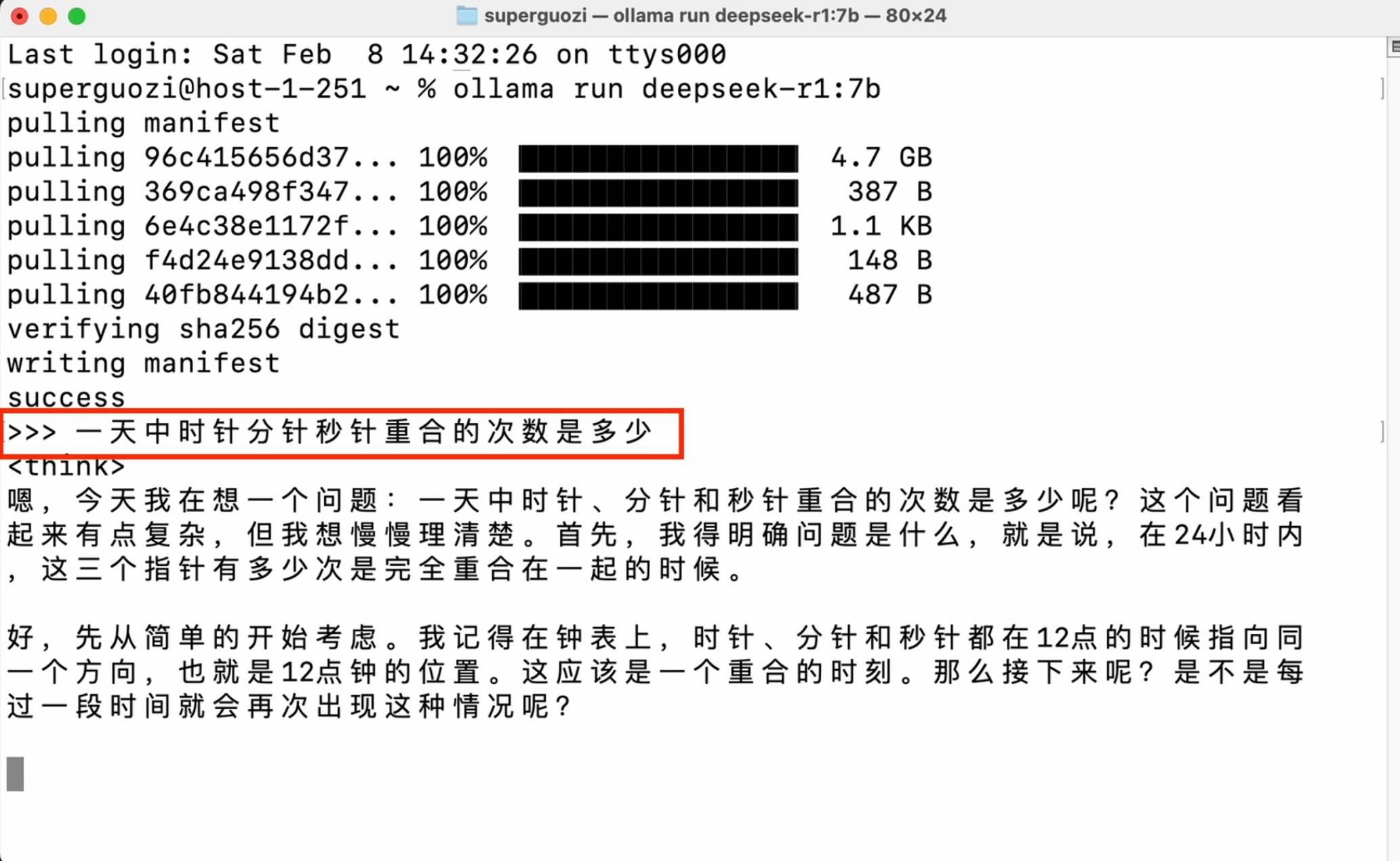
Digite o comando de código (ollama run deepseek-r1:7b) na janela para iniciar o download. Preste atenção à entrada de status em inglês, verifique os espaços e travessões e insira o nome da versão necessária após os dois pontos.

Assim que a configuração for concluída, você pode iniciar uma conversa na janela da linha de comando.
Este método tem requisitos de desempenho muito baixos, mas requer familiaridade com operações de linha de comando, e a compatibilidade do modelo também é limitada. É mais adequado para desenvolvedores avançados implementarem operações avançadas.
Se você deseja uma interface interativa mais bonita, você também pode instalar o plug-in no navegador Chrome, pesquisar e instalar o PageAssist.
Selecione um modelo instalado localmente para começar.
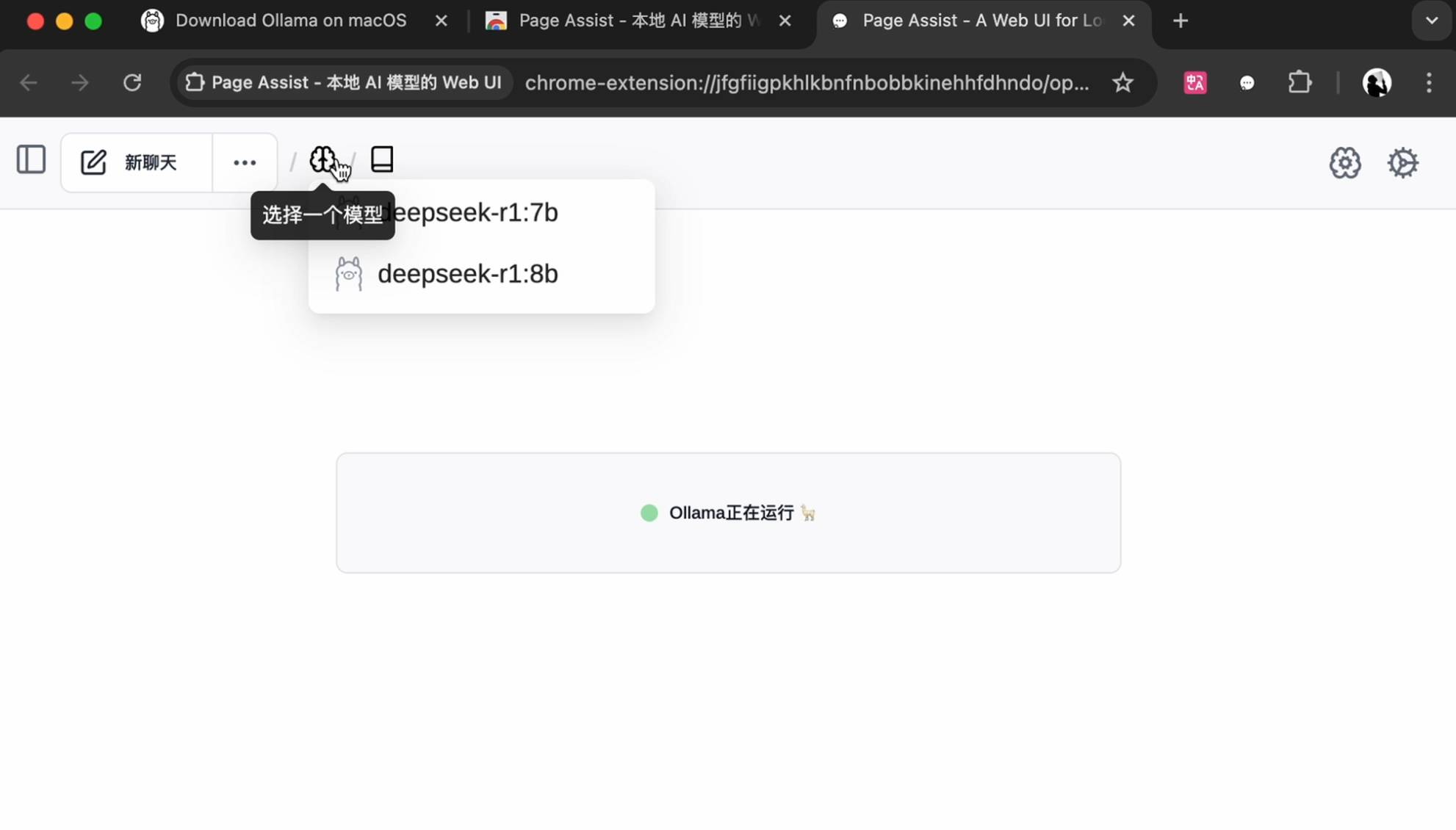
Modifique o idioma nas configurações no canto superior direito, selecione o modelo na página inicial para iniciar a conversa, e suporte pesquisas básicas na Internet, e a jogabilidade é mais diversificada.
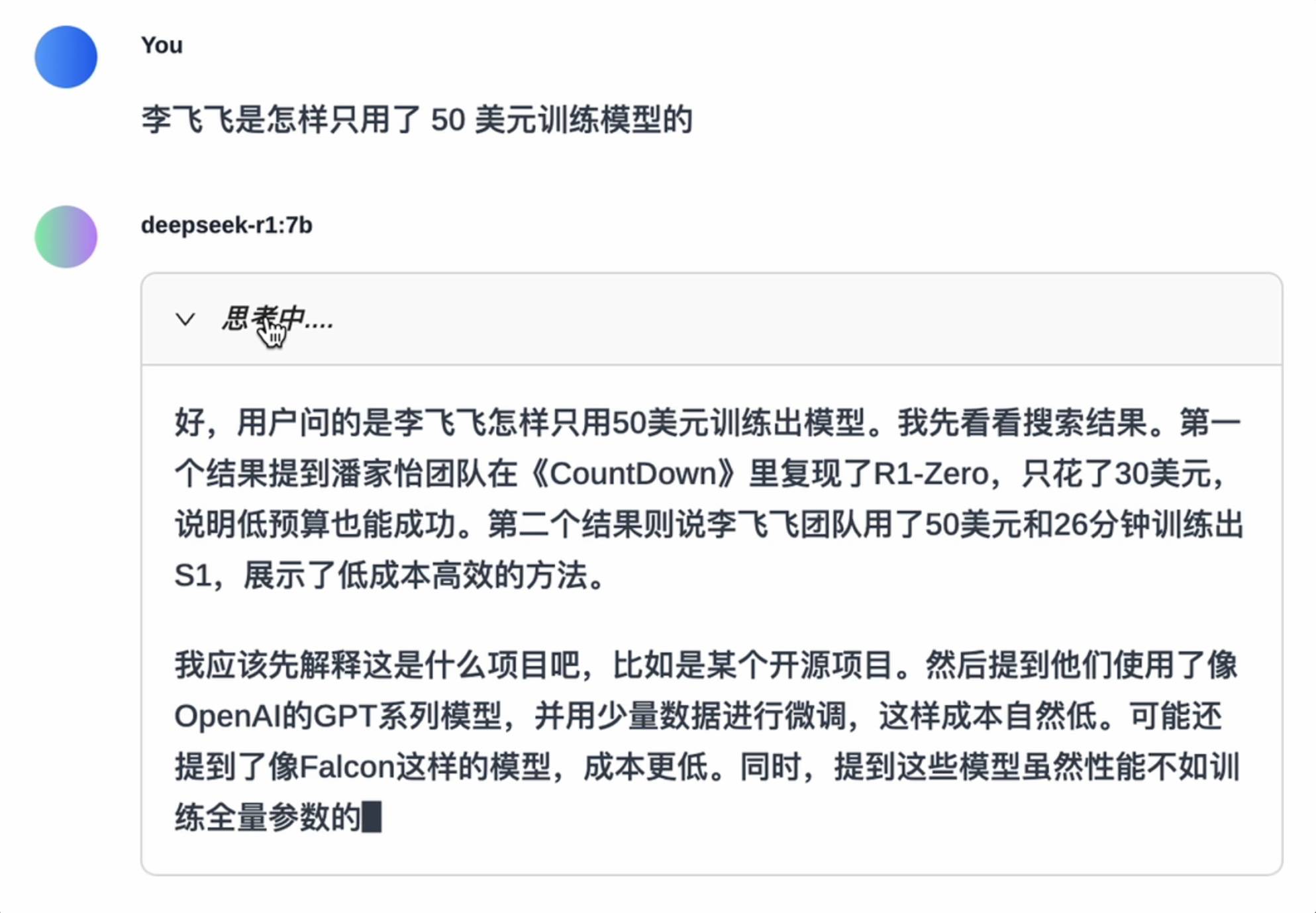
Se você pode correr, você pode correr, mas…
Usamos o LM Studio para esta experiência.
Com seus excelentes recursos de otimização, o LM Studio permite que os modelos sejam executados com eficiência em hardware de consumo. Por exemplo, o LM Studio oferece suporte à tecnologia de descarregamento de GPU, que pode carregar o modelo na GPU em blocos para obter aceleração quando a memória de vídeo é limitada.
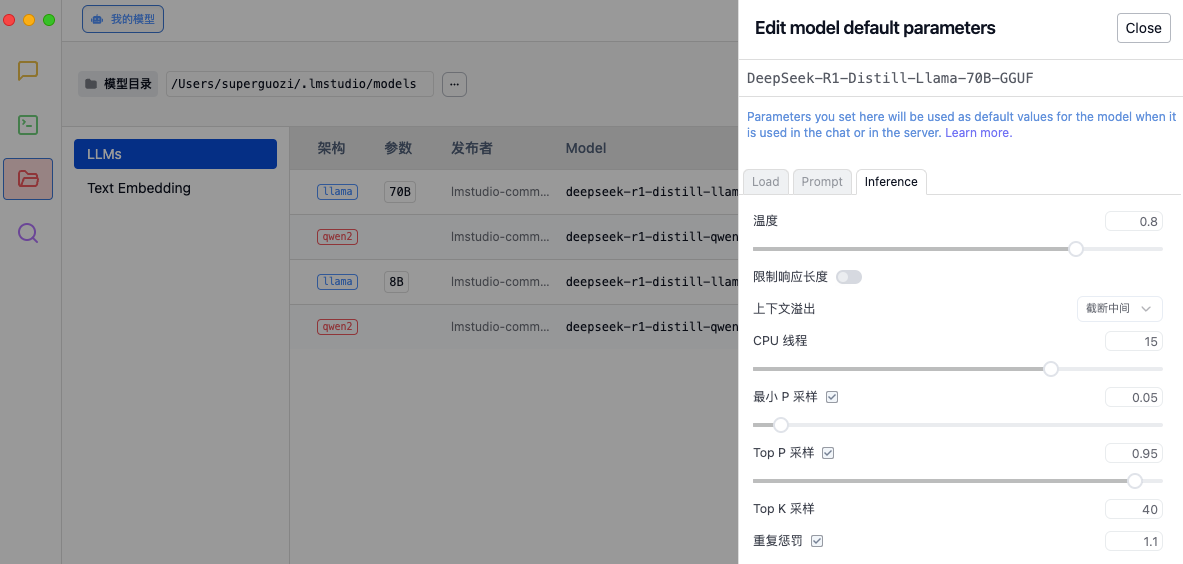
Assim como ajustar um carro de corrida, cada parâmetro afetará o desempenho final. Antes de experimentá-lo, é recomendável ajustar os parâmetros de inferência de acordo com as necessidades nas configurações do LM Studio para otimizar a qualidade de geração do modelo e a alocação de recursos computacionais.
- Temperatura: Controla a aleatoriedade do texto gerado.
- Tratamento de estouro de contexto: determina como lidar com entradas muito longas.
- Thread de CPU: afeta a velocidade de geração e o uso de recursos.
- Estratégia de amostragem: Garantir a racionalidade e diversidade do texto gerado através de múltiplos métodos de amostragem e mecanismos de penalidade.
A pesquisadora do DeepSeek, Daya Guo, compartilhou seu guia de ajuste interno na plataforma X. O comprimento máximo de geração está bloqueado em 32.768 tokens, o valor da temperatura é mantido em 0,6 e o valor p superior é fixado em 0,95. Cada teste gera 64 amostras de resposta.
As recomendações detalhadas de configuração são as seguintes:
1. Defina a temperatura entre 0,5-0,7 (a configuração recomendada é 0,6) para evitar que o modelo produza conteúdo repetitivo ou incoerente sem fim.
2. Evite adicionar prompt do sistema, todas as instruções devem ser incluídas no prompt do usuário.
3. Para questões de matemática, recomenda-se incluir instruções no prompt, por exemplo: "Por favor, raciocine passo a passo e coloque a resposta final em boxed{}."
4. Ao avaliar o desempenho do modelo, recomenda-se realizar vários testes e calcular a média dos resultados.
5. Além disso, notamos que o modelo da série DeepSeek-R1 pode ignorar o modo de pensamento (ou seja, saída "nn") ao responder a determinadas consultas, o que pode afetar o desempenho do modelo. Para garantir que o modelo realize inferência suficiente, recomendamos forçar o modelo a iniciar sua resposta com "n" no início de cada saída.
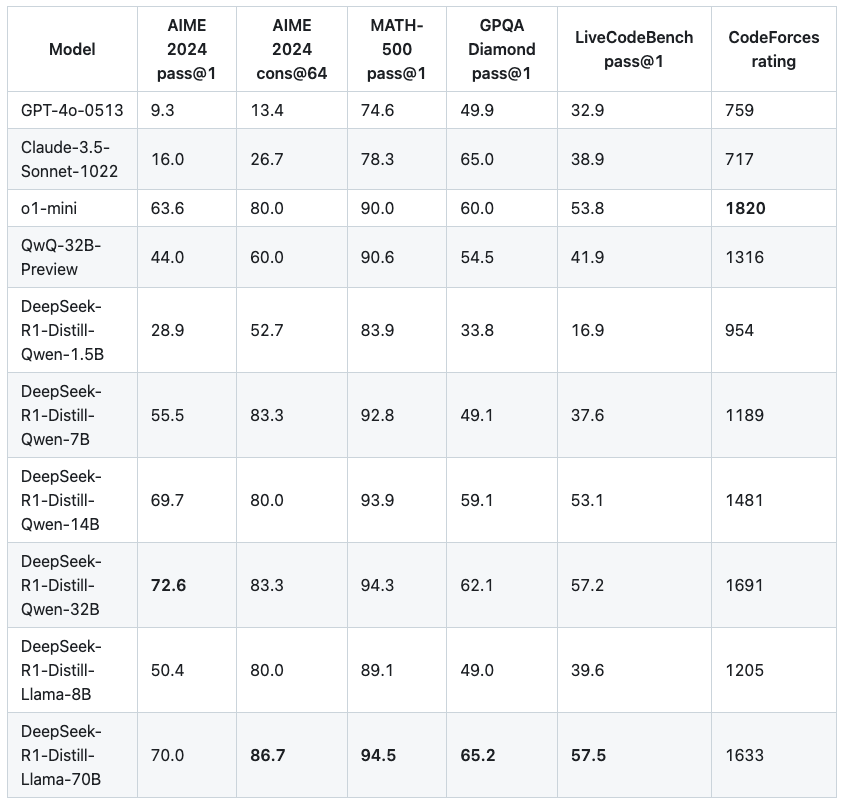
▲ Avaliação e comparação do modelo da versão destilada fornecida pelo oficial DeepSeek
Um número maior de parâmetros não traz necessariamente melhores resultados. Entre os pequenos modelos que experimentamos, a diferença geral de força entre modelos com valores de parâmetros adjacentes não é tão hierárquica. Também fizemos alguns testes simples.
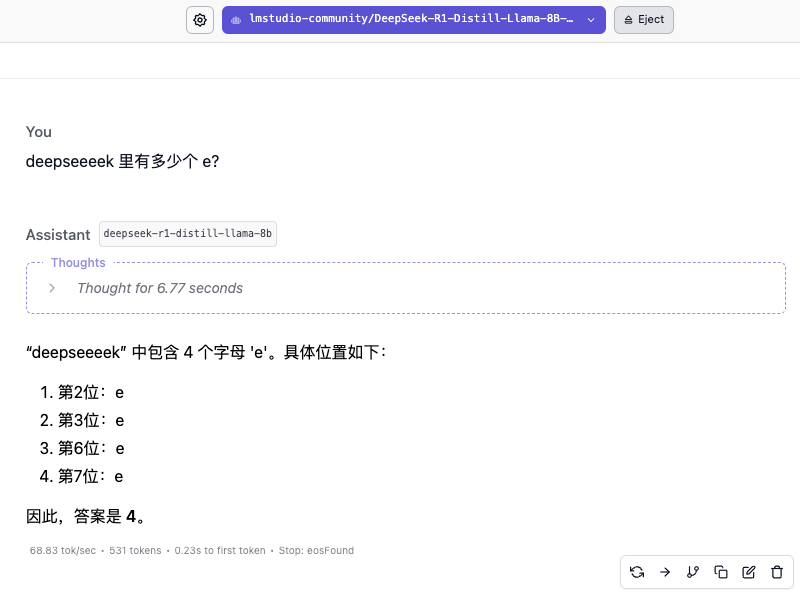

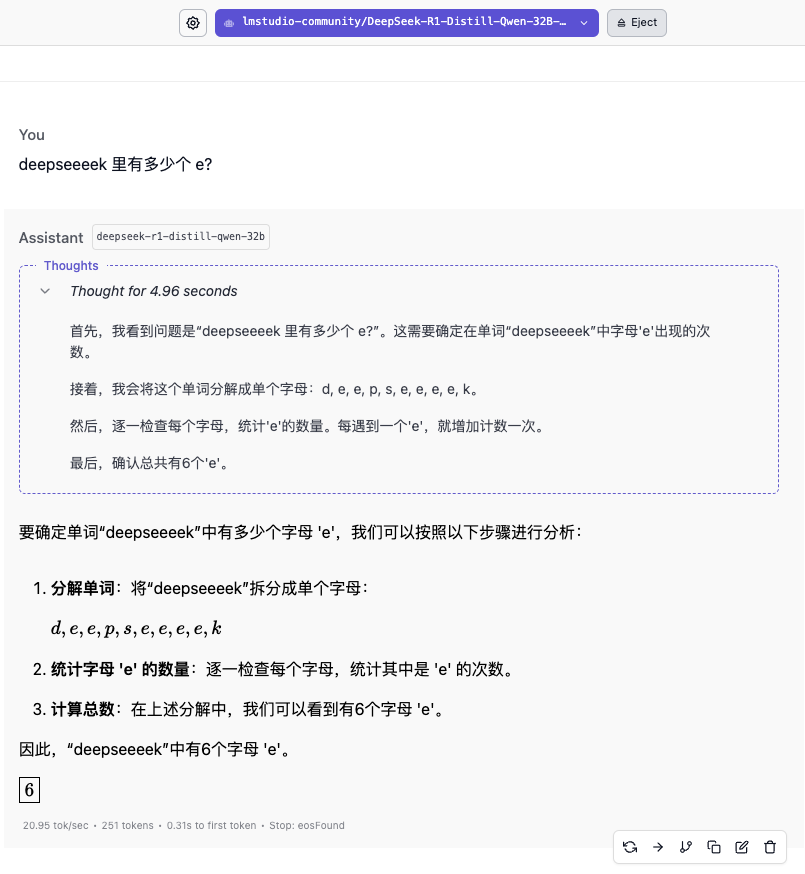
"Quantos e existem em deekseeeek?"
A velocidade de resposta do modelo 8B é muito rápida, atingindo basicamente 60 tokens/s, mas responder rapidamente não significa que a resposta esteja correta. O processo de pensamento mostra que o modelo é mais parecido com uma resposta baseada nas palavras “DeepSeek” na base de conhecimento.

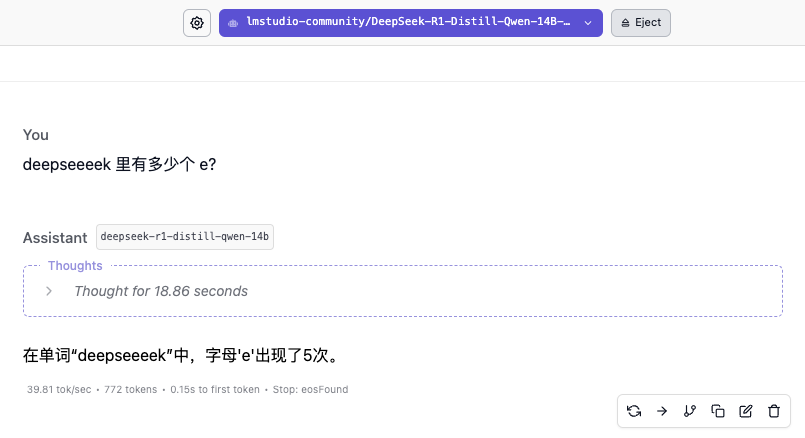
O modelo 14B também não acertou a resposta. Somente com o aparecimento do modelo 32B é que finalmente vimos uma resposta confiável. O modelo 70B mostrou um raciocínio mais cuidadoso, mas também deu respostas erradas.
"Por favor, ajude-me a escrever uma versão da Ópera de Pequim de "Harry Potter e a Pedra Filosofal""
Em termos de qualidade das respostas a esta pergunta, 32B e 70B têm méritos próprios, 32B tem um controle mais perfeito sobre os detalhes das cenas do roteiro, enquanto 70B entrega uma folha de respostas com personagens completos e um enredo completo.

"Alguém pega um avião em algum lugar do hemisfério norte e voa 2.000 quilômetros para leste, para norte, para oeste e para sul. No final, ele poderá retornar ao mesmo lugar?"
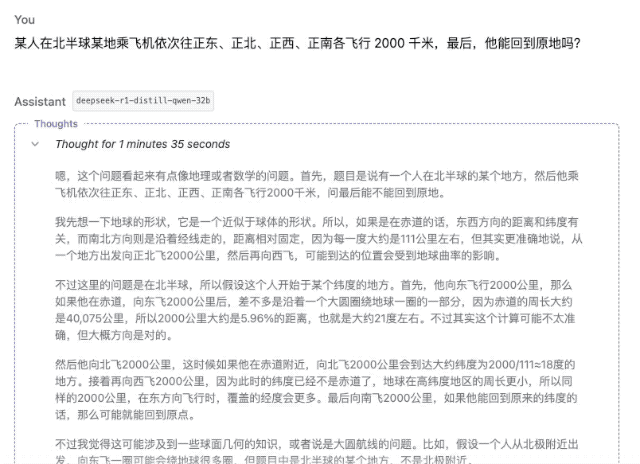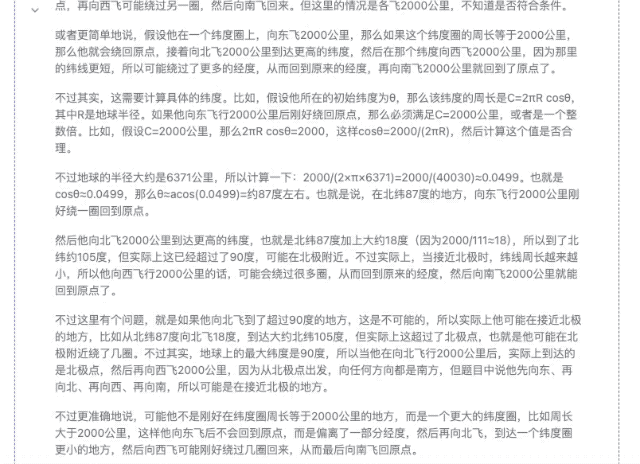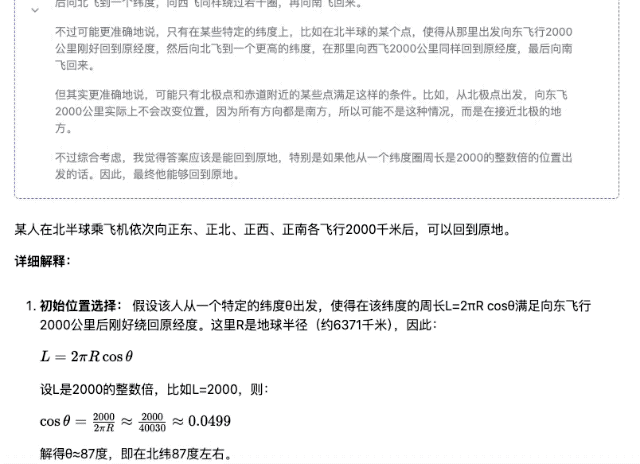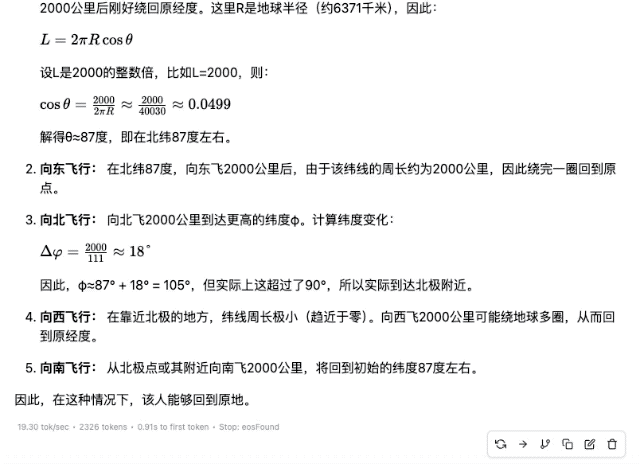
▲ DeepSeek-R1-Distill-Qwen-32B
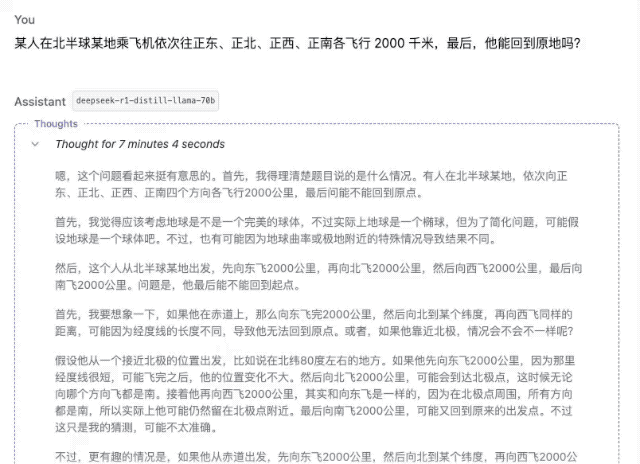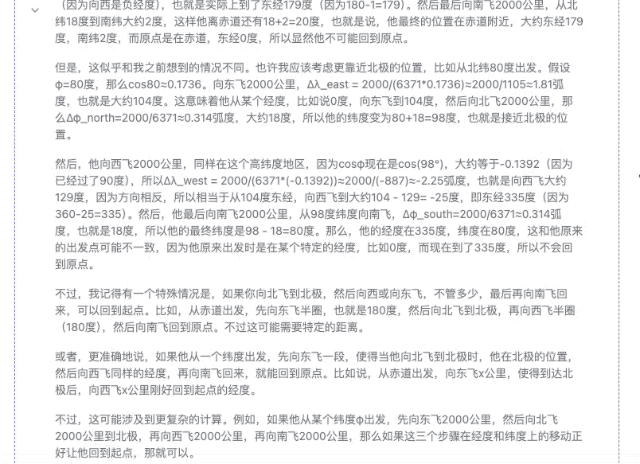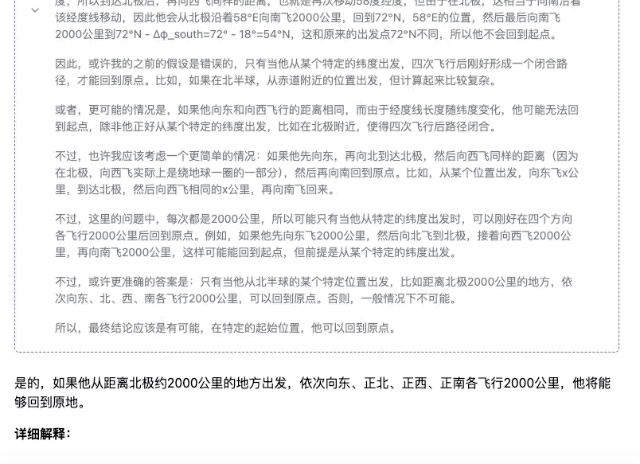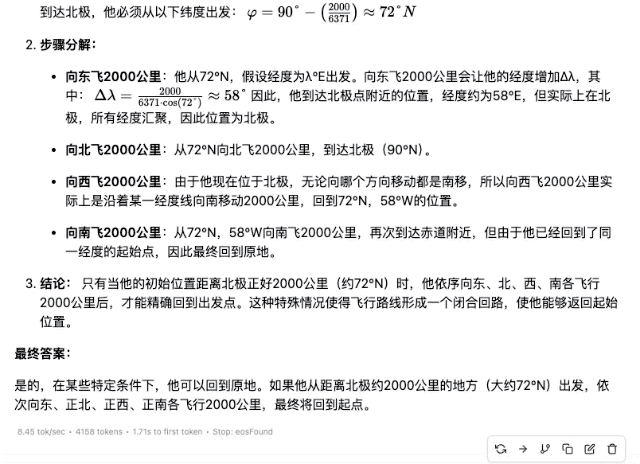
▲DeepSeek-R1-Distill-Llama-70B
É claro que, entre esses modelos, quanto menores os parâmetros, menor a precisão da resposta. Mesmo que o processo de pensamento seja suave, erros subsequentes serão cometidos devido à falta de firmeza. No campo dos cálculos matemáticos, a diferença de força entre modelos de diferentes magnitudes será mais óbvia.
A implantação local tem três vantagens principais: os dados confidenciais não precisam ser carregados na nuvem; podem ser usados sem problemas mesmo se a rede estiver desconectada e as taxas de chamada de API forem isentas, tornando as tarefas de texto longas mais econômicas.
Mas não apoiar a Internet também tem suas desvantagens. Se você não alimentá-la com “dados” e não atualizar a base de conhecimento em tempo hábil, seu nível de cognição de informações também estagnará. Por exemplo, se a base de conhecimento for até 2024, ela não será capaz de responder às últimas notícias sobre IA.
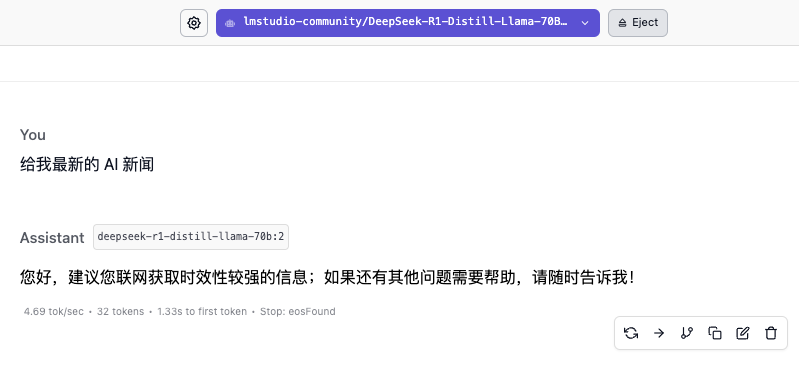
A função mais comumente usada de implantação local é construir sua própria base de conhecimento. O método é adicionar uma etapa de implantação vinculada ao Anything LLM após instalar o LM Studio.
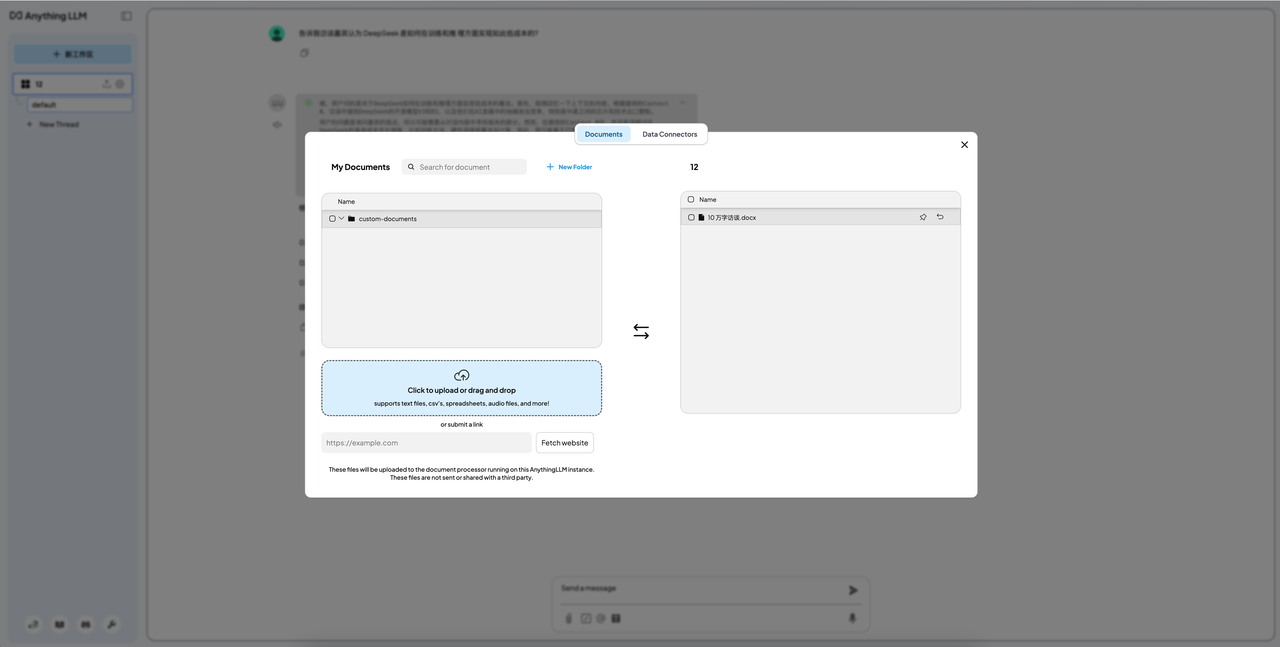
Considerando o efeito e a aplicabilidade, utilizamos o modelo 32B como modelo de ligação, e os resultados mostraram que o efeito também foi muito geral. O maior desafio veio da limitação da janela de contexto.
Insirai um artigo de apenas 4.000 palavras e um artigo de cerca de 1.000 palavras em sequência. A resposta do primeiro ainda era muito confusa, enquanto o último era competente. Porém, era um pouco inútil lidar com artigos de cerca de 1.000 palavras, então era bom como um brinquedo, mas a produtividade pouco interessava.

Também deve ser enfatizado que, por um lado, é extremamente difícil abrir a boca desses quatro modelos. Por outro lado, não recomendamos que você tente fazer o “jailbreak”. Embora existam muitos modelos de novas versões que são considerados fáceis de fazer o "jailbreak" circulando na Internet, devido a considerações éticas e de segurança, não recomendamos a implantação aleatória.
Porém, agora que chegamos a este ponto, podemos também seguir o princípio de saber tudo e tentar baixar e implantar alguns pequenos modelos lançados através de canais formais.
Além da implantação local de modelos pequenos de destilação R1, existe um pacote ruim para a versão R1 de sangue puro?
Matthew Carrigan, engenheiro da Hugging Face, demonstrou recentemente uma configuração de hardware + software executando o modelo DeepSeek-R1 completo, quantificação Q8 e sem destilação na plataforma X, que custa aproximadamente US$ 6.000.
Em anexo está o link de configuração completo:
https://x.com/carrigmat/status/1884244369907278106
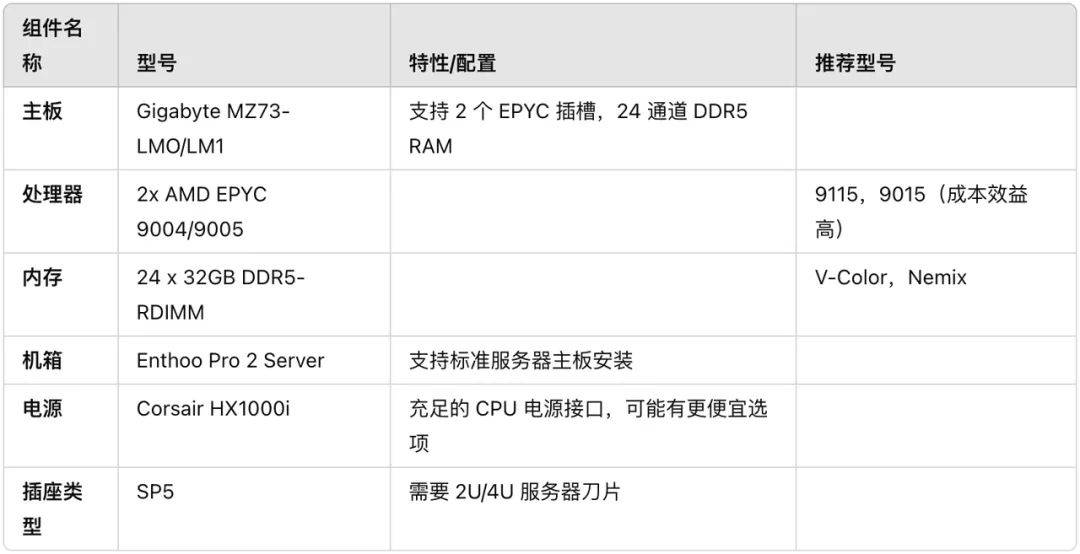
Mais perto de casa, realmente precisamos implantar uma versão destilada do DeepSeek R1 localmente?
Minha sugestão é não pensar nesses pequenos modelos destilados R1 como Teslas. Na melhor das hipóteses, eles são mais parecidos com Wuling Hongguang. Eles podem correr, mas seu desempenho é muito diferente ou não têm braços e pernas.
Na experiência de implantação local dos recursos de base de conhecimento customizados mais comumente usados, o efeito não é satisfatório. Quando confrontado com problemas específicos, não consegue “descobrir com precisão qual é o problema” ou simplesmente inventa-o, e a sua precisão é preocupante.
Para a grande maioria dos usuários, a melhor solução é usar a versão oficial ou uma plataforma de terceiros. Não requer custos elevados de hardware ou preocupações com desempenho limitado.
Mesmo depois de lutar por muito tempo, você descobrirá que, em vez de investir muito tempo, energia e dinheiro para implantar esses pequenos modelos localmente, é melhor fazer uma boa refeição depois de sair do trabalho.
Para usuários corporativos, desenvolvedores ou usuários com necessidades especiais de privacidade de dados, a implantação local ainda é uma opção que vale a pena considerar, mas somente se você entender por que precisa dela e suas diversas limitações.
Em anexo estão as perguntas e respostas de controle de qualidade de Xiaobai:
- P: Posso implantar o DeepSeek em um computador normal?
Resposta: A versão completa do DeepSeek possui requisitos de computador mais elevados. No entanto, se você quiser usá-lo apenas para operações simples, poderá escolher alguns modelos de destilação pequenos, mas ainda precisará fazer o que puder. - P: Qual é a versão destilada do DeepSeek R1?
Resposta: O modelo destilado é uma versão "simplificada" com requisitos de hardware mais baixos e velocidade de execução mais rápida. - P: Posso usar o DeepSeek sem internet?
R: Se você optar por implantar o DeepSeek localmente, poderá usá-lo sem a Internet. Se você usá-lo através da nuvem ou de uma plataforma de terceiros, precisará de uma conexão com a Internet para acessá-lo. - P: Meus dados pessoais estão seguros ao usar o DeepSeek?
Resposta: Se você optar por implantar o DeepSeek localmente, seus dados não serão carregados na nuvem, o que é mais seguro. Se estiver usando a versão online, escolha uma plataforma de serviço confiável para proteger a privacidade pessoal.
Autor: Mo Chongyu, Lin
# Bem-vindo a seguir a conta pública oficial do WeChat de Aifaner: Aifaner (ID do WeChat: ifanr). Mais conteúdo interessante será fornecido a você o mais rápido possível.
