
GPT-4V pode funcionar em telefones celulares! Face the wall lança a mais poderosa arma de aço multimodal 2.6, a compreensão de vídeo em tempo real é lançada pela primeira vez

Nos últimos seis meses, a tendência dos modelos grandes mudou silenciosamente. Diferente da tendência anterior de busca contínua por escala, modelos menores e mais fortes de ponta a ponta tornaram-se a tendência atual.
Não muito tempo atrás, depois de ser plagiado pela equipe de IA da Universidade de Stanford, o fabricante nacional de modelos Face Wall Intelligence aumentou significativamente sua presença e também fez com que países nacionais e estrangeiros vissem a extraordinária força da empresa no campo da IA.
Hoje, a Wallface Intelligence lançou um novo modelo MiniCPM-V 2.6 de "pequeno canhão de aço", elevando mais uma vez as capacidades multimodais finais a um novo nível.
Embora o modelo tenha apenas parâmetros de 8B, ele alcançou 3 resultados SOTA em imagem única, multiimagem e compreensão de vídeo abaixo de 20B, elevando as capacidades multimodais da IA final a um nível além do GPT-4V em benchmarking abrangente.
Basta destacar:
- Pela primeira vez, os principais recursos multimodais, como imagem única, multiimagem e compreensão de vídeo no lado do dispositivo, ultrapassaram totalmente o GPT-4V, e a compreensão de imagem única ultrapassou o Gemini 1.5 Pro e o GPT-4o mini.
- Apresentando compreensão de vídeo em tempo real, união de múltiplas imagens, aprendizagem visual ICL, OCR, etc., para permitir a observação e aprendizagem do mundo real de modelos finais.
- O Xiaogangpao 2.6 alcançou o dobro da densidade de pixels de codificação de token único do GPT-4o. O token visual é 30% menor que a geração anterior e 75% menor que modelos similares.
- A memória quantificada do back-end ocupa apenas 6 GB; a velocidade de inferência do lado final chega a 18 tokens/s, o que é 33% mais rápido que o modelo da geração anterior. E suporta raciocínio llama.cpp, ollama, vllm no lançamento e oferece suporte a vários idiomas;

A compreensão de vídeo em tempo real "Long Eyes" é lançada pela primeira vez, permitindo que dispositivos inteligentes entendam você melhor
Vamos primeiro experimentar o efeito de demonstração real do modelo MiniCPM-V 2.6.
O vídeo mostra que, com o suporte de recursos multimodais, o MiniCPM-V 2.6 é como ter um par de “olhos” e pode ver o mundo real em tempo real. Quando o modo de voo está ativado, o dispositivo final equipado com este modelo pode identificar com precisão a cena interna da empresa inteligente voltada para a parede.
Desde o logotipo da empresa inteligente voltada para a parede até plantas, mesas, bebedouros e outros itens, os recursos de reconhecimento de itens do MiniCPM-V 2.6 são livres de estresse e podem até ser considerados fáceis.
Diante do processo de contabilização ou reembolso com inúmeros recibos, basta tirar uma foto e carregá-la no MiniCPM-V 2.6. Ele pode não só identificar o valor específico de cada recibo, mas também calcular o total, o que simplifica muito todo o processo. .
Graças à sua avançada tecnologia OCR e CoT (Chain of Thought), o MiniCPM-V 2.6 pode não apenas capturar com precisão o valor no recibo, mas também apresentar o processo de resolução de problemas de forma clara e concisa:
Por exemplo, quando confrontado com um vídeo de previsão do tempo de cerca de 1 minuto, o MiniCPM-V 2.6 pode usar o “olho nu” para identificar e descrever as condições climáticas específicas em diferentes cidades sob condições silenciosas.
As capacidades de raciocínio complexo multimodal final do MiniCPM-V 2.6 também "melhoraram".
Tomando como exemplo a clássica demonstração oficial do GPT-4V – ajustando o assento da bicicleta, o MiniCPM-V 2.6 pode orientar claramente o usuário a abaixar o assento da bicicleta por meio do diálogo multi-rodas e recomendar ferramentas apropriadas com base nas instruções e na caixa de ferramentas.

Ou, se você tem uma conexão de Internet 2G e não consegue entender os memes que circulam amplamente entre os jovens, é melhor deixá-los explicar pacientemente as falhas por trás dos memes.
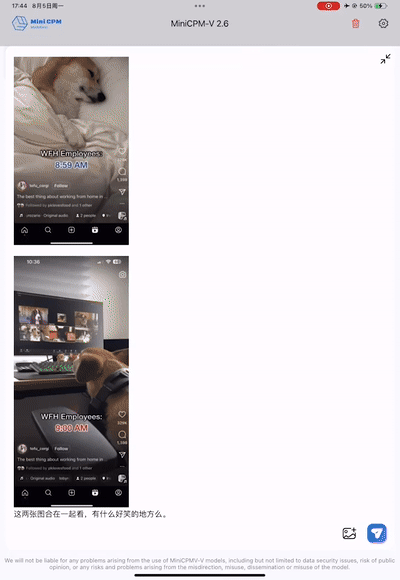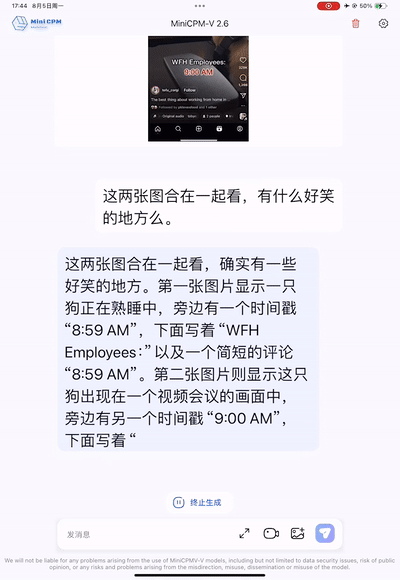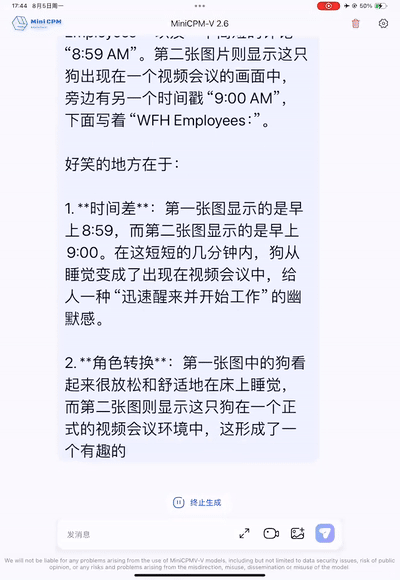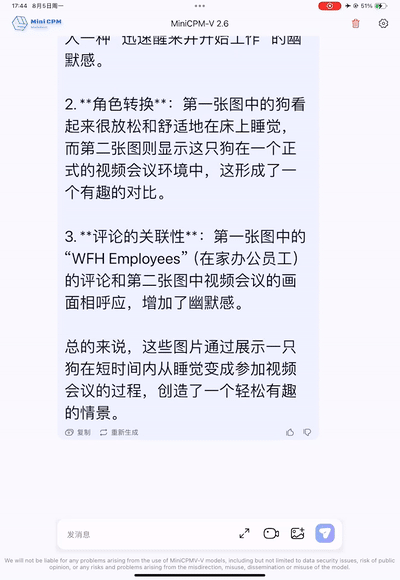
Pode até ser mais engraçado que os humanos e capturar o subtexto dos memes. Como programador, você pode olhar para esta foto, rir e chorar.
Pequeno ganha grande, MiniCPM-V 2.6 é conhecido como a multimodalidade final mais poderosa em três em um
A principal competitividade do modelo do lado do dispositivo é fazer uma grande diferença com pequenas coisas.
De acordo com a introdução oficial do Wallface Intelligence, em termos de taxa de compressão de conhecimento do MiniCPM-V 2.6, o MiniCPM-V 2.6 alcançou a maior densidade de pixels de modelo grande multimodal (densidade de token) duas vezes maior que a do GPT-4o.
Densidade do token = número de pixels de codificação/número de tokens visuais, refere-se à densidade de pixels transportada por um único token, ou seja, a densidade da informação da imagem, que determina diretamente a eficiência operacional real do modelo multimodal. valor, maior será a eficiência operacional do modelo.
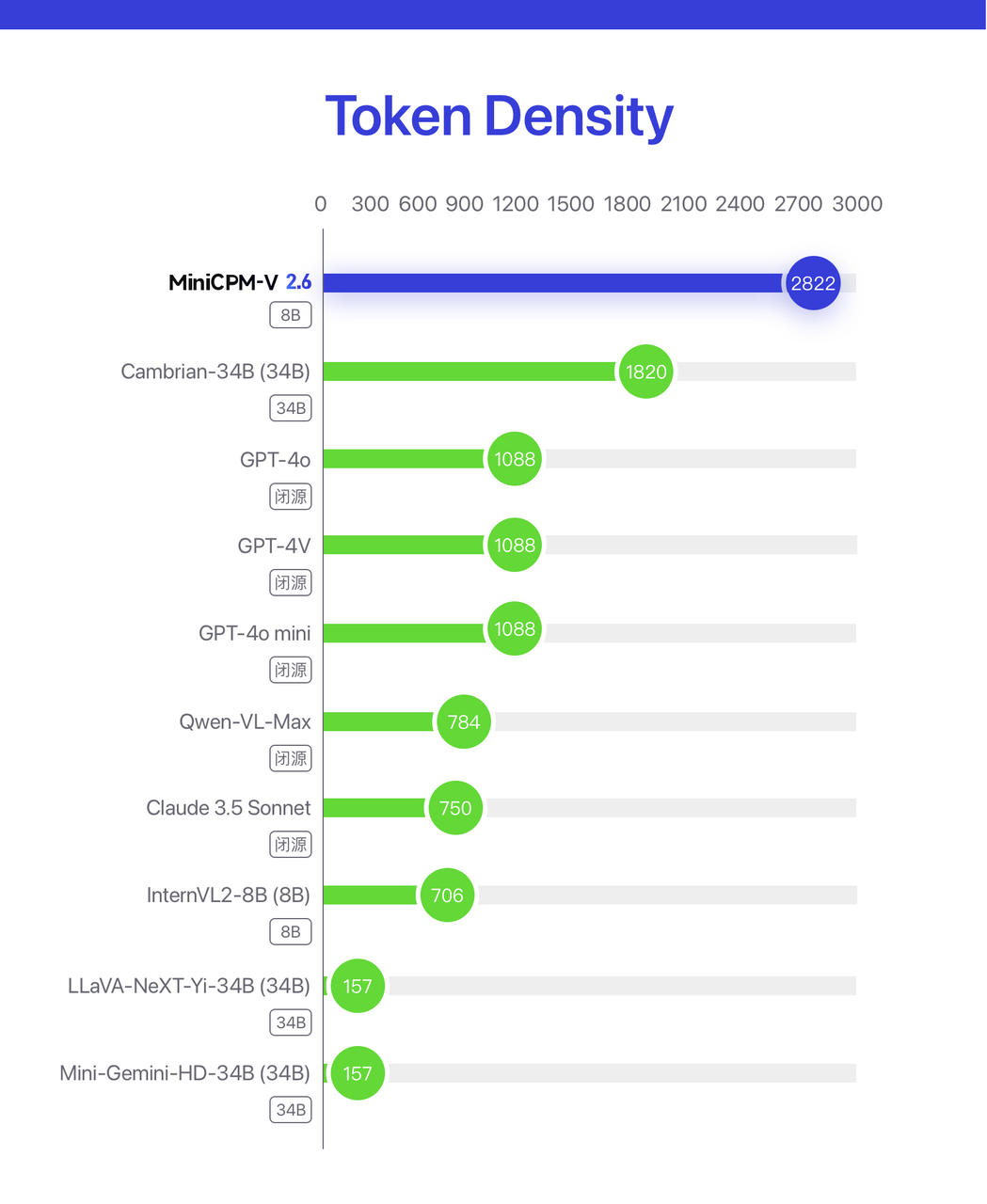
A densidade do token do modelo de código fechado é estimada pelo método de cobrança da API. Os resultados mostram que o MiniCPM-V 2.6 possui a maior Densidade de Token entre todos os modelos multimodais, continuando com suas características consistentes de extrema eficiência.
A julgar pelos resultados dos testes de benchmark compartilhados, o MiniCPM-V 2.6 supera o Gemini 1.5 Pro e o GPT-4o mini em recursos de compreensão de imagem única na plataforma de avaliação abrangente e confiável OpenCompass.
Na lista da plataforma de avaliação multigráfico Mantis-Eval, a capacidade de compreensão conjunta multigráfico do MiniCPM-V 2.6 realiza o modelo de código aberto SOTA e supera o GPT-4V. Na lista da plataforma de avaliação de vídeo Video-MME, a capacidade de compreensão de vídeo do MiniCPM-V 2.6 atinge o SOTA final, ultrapassando o GPT-4V.
▲OpenCompass | Mantis-Eval | Resultados da lista de vídeo-MME
Além disso, o desempenho do MiniCPM-V 2.6 OCR implementa o modelo SOTA de código aberto + código fechado no OCRBench.
Na lista de avaliação de alucinações Object HalBench, o nível de alucinação do MiniCPM-V 2.6 (quanto menor a taxa de alucinação, melhor) também é melhor do que muitos modelos comerciais, como GPT-4o, GPT-4V, Claude 3.5 Sonnet e assim por diante.
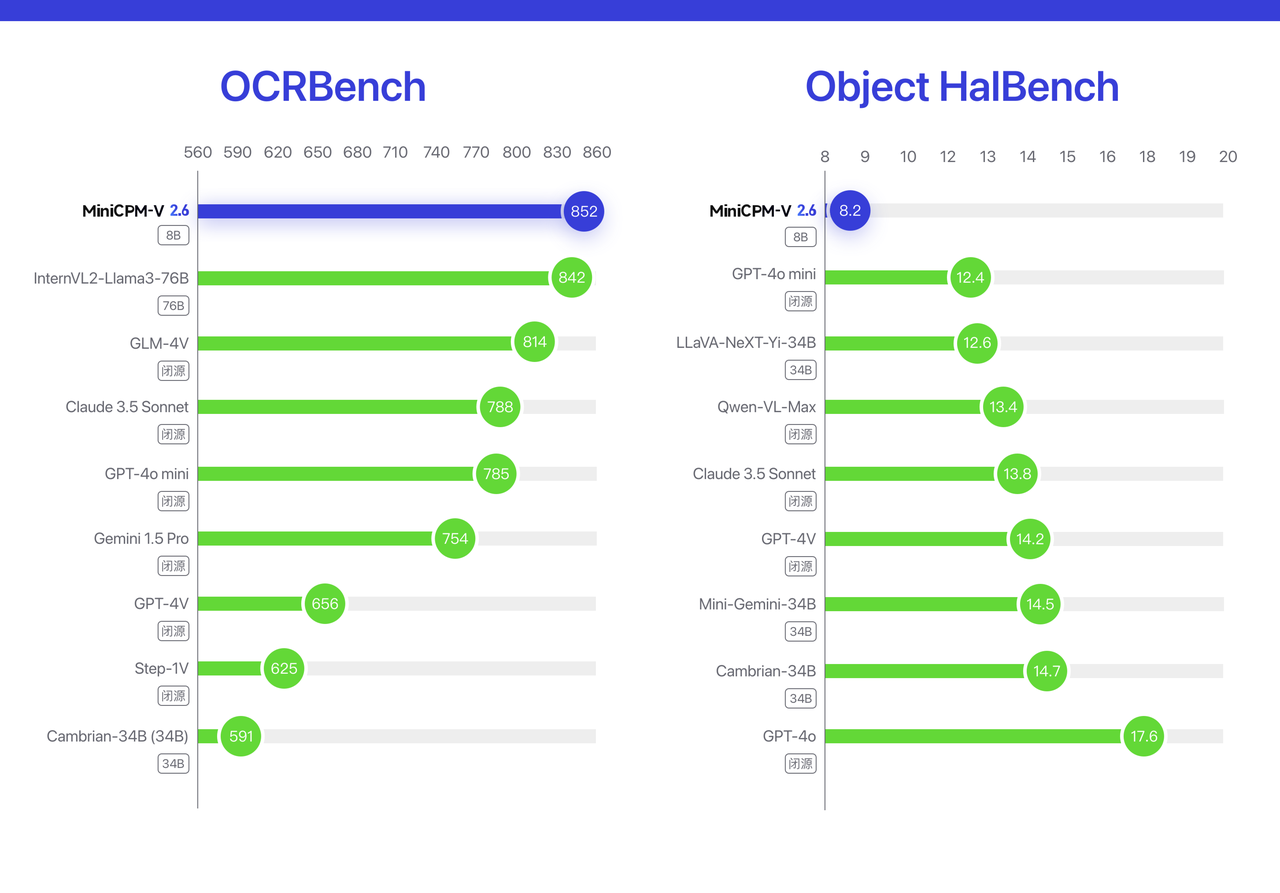
▲Obiect HalBench | Resultados da lista OCRBench
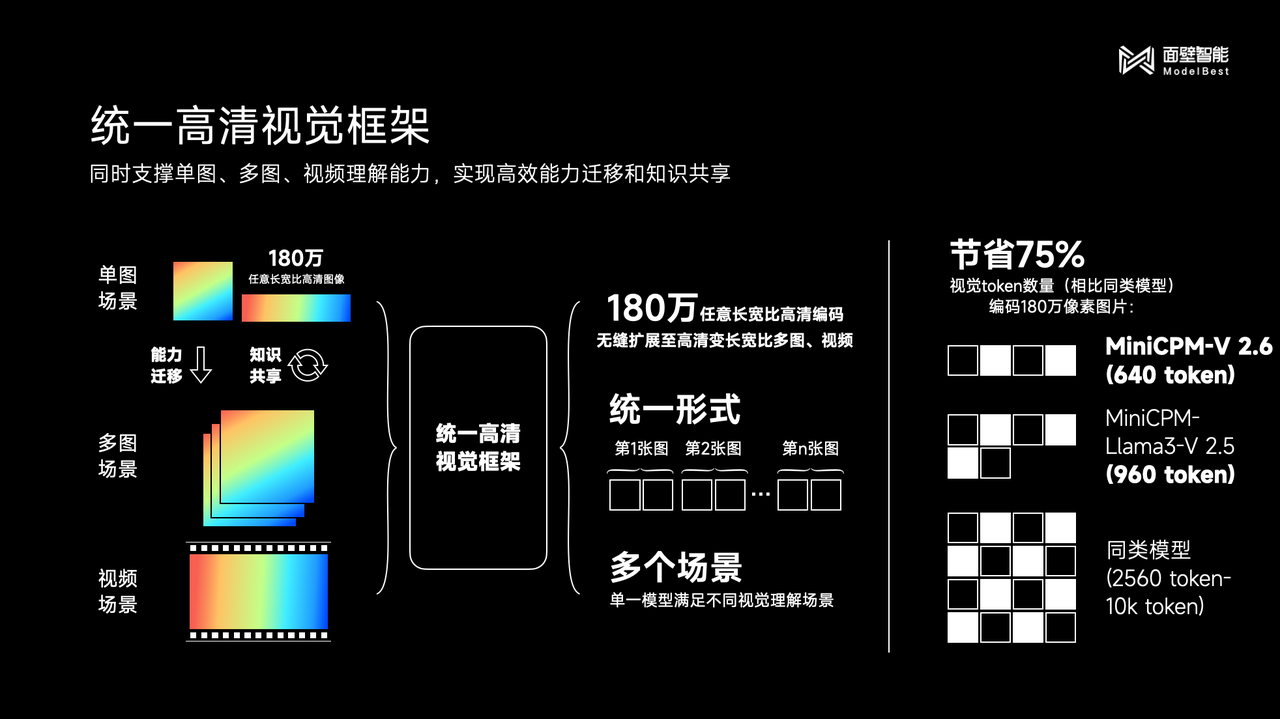
A razão por trás do excelente desempenho da nova geração de pequenas pistolas de aço MiniCPM-V 2.6 é principalmente devido à adoção de uma arquitetura visual unificada de alta definição.
As autoridades afirmaram que a estrutura visual unificada de alta definição não apenas herda as vantagens multimodais das imagens individuais tradicionais, mas também alcança uma comunicação centralizada.
Por exemplo, o recurso OCR SOTA migra os recursos e o compartilhamento de conhecimento da "análise de imagens de alta definição de 1,8 milhão de imagens de alta definição" do MiniCPM-V de cenas de imagem única, estende-o perfeitamente para cenas de múltiplas imagens e cenas de vídeo e unifica essas três compreensão visual cenários em gráficos. Ele resolve o problema de modelagem semântica de textos alternados, compartilha o mecanismo de representação visual subjacente e consegue uma economia de mais de 75% no número de tokens visuais em comparação com modelos semelhantes.
Com base na extração de informações de OCR, o MiniCPM-V 2.6 pode realizar raciocínios complexos semelhantes ao CoT (Chain of Thought) nas informações da tabela.
Tomando como exemplo as Olimpíadas de 2008, o modelo conseguiu calcular o número total de medalhas de ouro conquistadas pelos três países com mais medalhas de ouro.
[foto]
Este processo inclui:
- Use recursos de OCR para identificar e extrair os três principais países com mais medalhas de ouro no quadro de medalhas;
- Some o número total de medalhas de ouro desses três países.
Em termos de credibilidade da IA, o MiniCPM-V 2.6 dá continuidade às vantagens tradicionais da série Xiaogangpao com uma taxa de ilusão de 8,2%. Além disso, a tecnologia de alinhamento RLAIF-V voltada para parede e a aplicação da tecnologia de alinhamento da série Ultra também são tecnologias pretas escondidas atrás do MiniCPM-V 2.6.

Dados oficiais mostram que o número de downloads da série Xiaogangpao ultrapassou um milhão. Desde o lançamento da implantação final, a primeira capacidade multimodal, até o modelo multimodal final mais forte, até a nova era de benchmarking abrangente do GPT-4V final, a inteligência voltada para a parede levou apenas meio ano .
“Inteligente, suave e tão rápido que não parece um modelo de ponta a ponta!” Esta frase é a descrição mais apropriada da pequena série de armas de aço.
Dê mais tempo à Wall-Facing Intelligence e também aos grandes fabricantes de modelos nacionais e estrangeiros. Acreditamos firmemente que a Wall-Facing Intelligence continuará a lançar mais modelos de IA finais de alta qualidade no futuro e a trabalhar com produtos domésticos. e grandes fabricantes estrangeiros de modelos para promover o desenvolvimento de IA final.
Neste processo, os desenvolvedores independentes e os usuários comuns se tornarão os maiores beneficiários.
Por fim, o endereço de código aberto MiniCPM-V 2.6 está anexado:
GitHub  https://github.com/OpenBMB/MiniCPM-V
https://github.com/OpenBMB/MiniCPM-V
Abraçando o rosto: https://huggingface.co/openbmb/MiniCPM-V-2_6
# Bem-vindo a seguir a conta pública oficial do WeChat de Aifaner: Aifaner (WeChat ID: ifanr). Mais conteúdo interessante será fornecido a você o mais rápido possível.
