
Como encontrar e remover arquivos duplicados no Linux usando fdupes
Ao trabalhar com grandes quantidades de mídia e documentos, é bastante comum acumular várias cópias do mesmo arquivo em seu computador. Inevitavelmente, o que se segue é um espaço de armazenamento desordenado cheio de arquivos redundantes, provocando verificações periódicas de arquivos duplicados em seu sistema.
Para isso, você encontrará vários programas para identificar e excluir arquivos duplicados. E o fdupes é um desses programas para Linux. Portanto, acompanhe enquanto discutimos fdupes e o guie pelas etapas para localizar e excluir arquivos duplicados no Linux.
O que é fdupes?
Fdupes é um programa baseado em CLI para localizar e excluir arquivos duplicados no Linux. É lançado sob a licença do MIT no GitHub .
Em sua forma mais simples, o programa funciona executando o diretório especificado por meio do md5sum para comparar as assinaturas MD5 de seus arquivos. Em seguida, ele executa uma comparação byte a byte neles para identificar os arquivos duplicados e garantir que nenhuma duplicata seja deixada de fora.
Depois que o fdupes identifica os arquivos duplicados, ele oferece a opção de excluí-los ou substituí-los por links físicos (links para os arquivos originais). Portanto, dependendo de seus requisitos, você pode prosseguir com uma operação de acordo.
Como instalar o fdupes no Linux?
Fdupes está disponível na maioria das principais distros Linux, como Ubuntu, Arch, Fedora, etc. Com base na distro que você está executando em seu computador, execute os comandos fornecidos abaixo.
Em sistemas baseados em Ubuntu ou Debian:
sudo apt install fdupesPara instalar fdupes no Fedora / CentOS e outras distros baseadas em RHEL:
sudo dnf install fdupesNo Arch Linux e Manjaro:
sudo pacman -S fdupesComo usar fdupes?
Depois de instalar o programa em seu computador, siga as etapas abaixo para localizar e remover arquivos duplicados.
Encontrar arquivos duplicados com fdupes
Primeiro, vamos começar pesquisando todos os arquivos duplicados em um diretório. A sintaxe básica para isso é:
fdupes path/to/directoryPor exemplo, se você quiser encontrar arquivos duplicados no diretório Documentos , execute:
fdupes ~/DocumentsSaída:
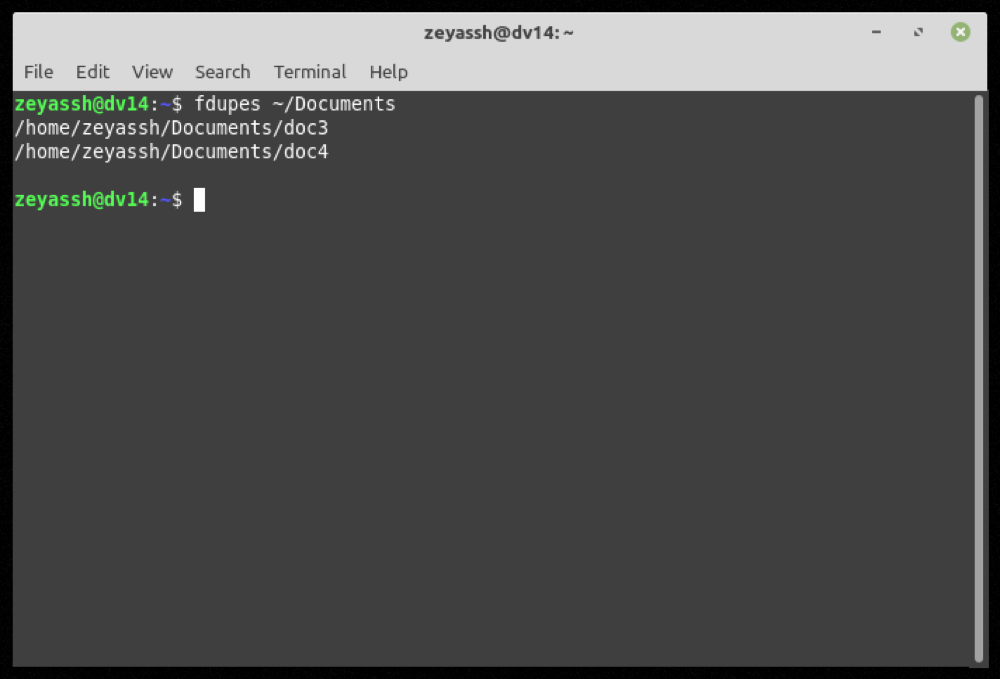
Se fdupes encontrar arquivos duplicados no diretório especificado, ele retornará uma lista de todos os arquivos redundantes agrupados por conjunto, e você poderá realizar outras operações neles conforme necessário.
No entanto, se o diretório especificado consistir em subdiretórios, o comando acima não identificará duplicatas dentro deles. Em tais situações, o que você precisa fazer é realizar uma pesquisa recursiva para encontrar todos os arquivos duplicados presentes nos subdiretórios.
Para realizar uma pesquisa recursiva em fdupes, use o sinalizador -r :
fdupes -r path/to/directoryPor exemplo:
fdupes -r ~/DocumentsSaída:
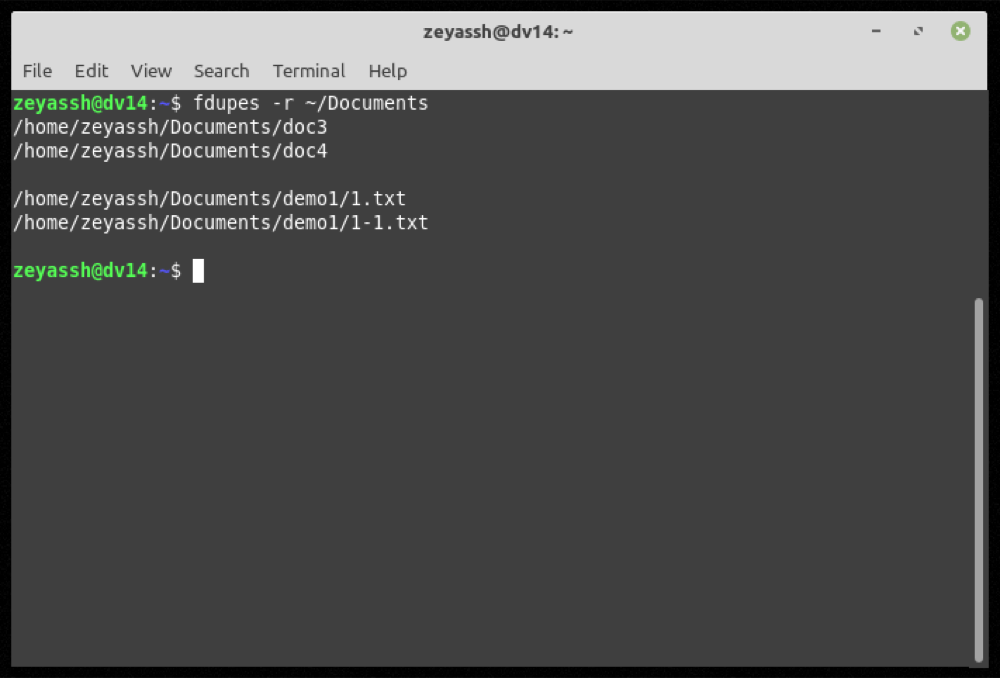
Embora os dois comandos acima possam localizar facilmente arquivos duplicados dentro do diretório especificado (e seus subdiretórios), sua saída também inclui arquivos duplicados de comprimento zero (ou vazios).
Embora essa funcionalidade ainda possa ser útil quando você tem muitos arquivos duplicados vazios em seu sistema, ela pode causar confusão quando você deseja apenas encontrar duplicatas não vazias em um diretório.
Felizmente, o fdupes permite que você exclua arquivos de comprimento zero de seus resultados de pesquisa usando a opção -n , que pode ser usada em seus comandos.
Nota: Você pode excluir arquivos duplicados não vazios em pesquisas normais e recursivas.
Para pesquisar apenas arquivos duplicados não vazios em sua máquina:
fdupes -n ~/DocumentsSaída:
Se você estiver lidando com vários conjuntos de arquivos duplicados, é aconselhável gerar os resultados em um arquivo de texto para referência futura.
Para fazer isso, execute:
fdupes path/to/directory > file_name.txt… onde caminho / para / diretório é o diretório no qual você deseja realizar a pesquisa.
Para pesquisar arquivos duplicados no diretório Documentos e enviar a saída para um arquivo:
fdupes /home/Documents > output.txtPor último, mas não menos importante, se desejar ver um resumo de todas as informações relacionadas a arquivos duplicados em um diretório, você pode usar o sinalizador -m em seus comandos:
fdupes -m path/to/directoryPara obter informações de arquivo duplicado para o diretório Documentos :
fdupes -m ~/DocumentsSaída:
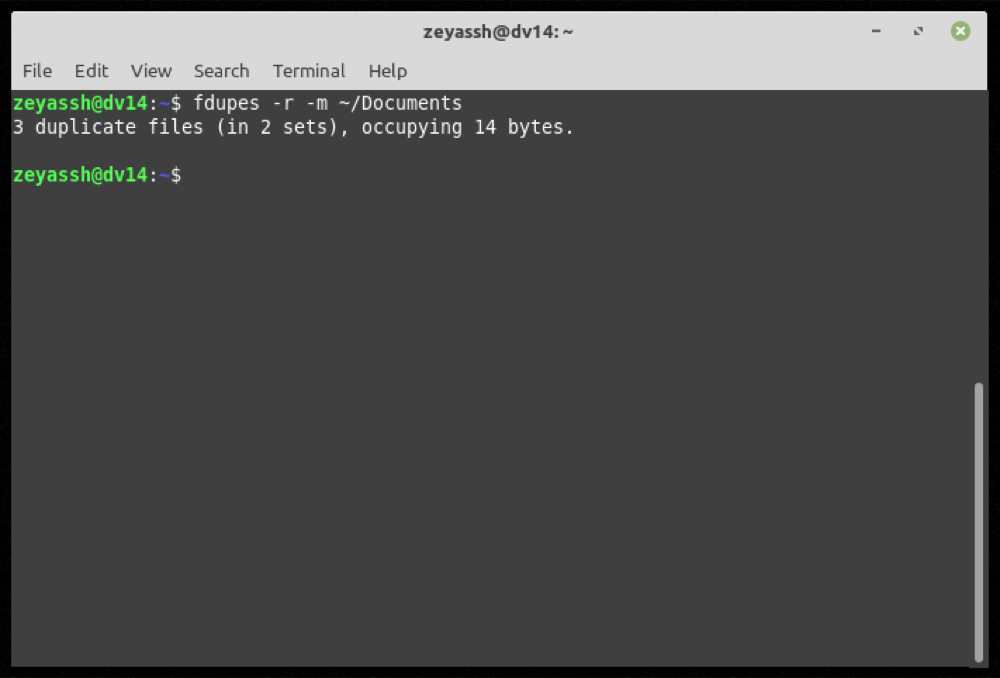
A qualquer momento durante o uso de fdupes, se quiser ajuda com um comando ou função, use a opção -h para obter ajuda de linha de comando :
fdupes -h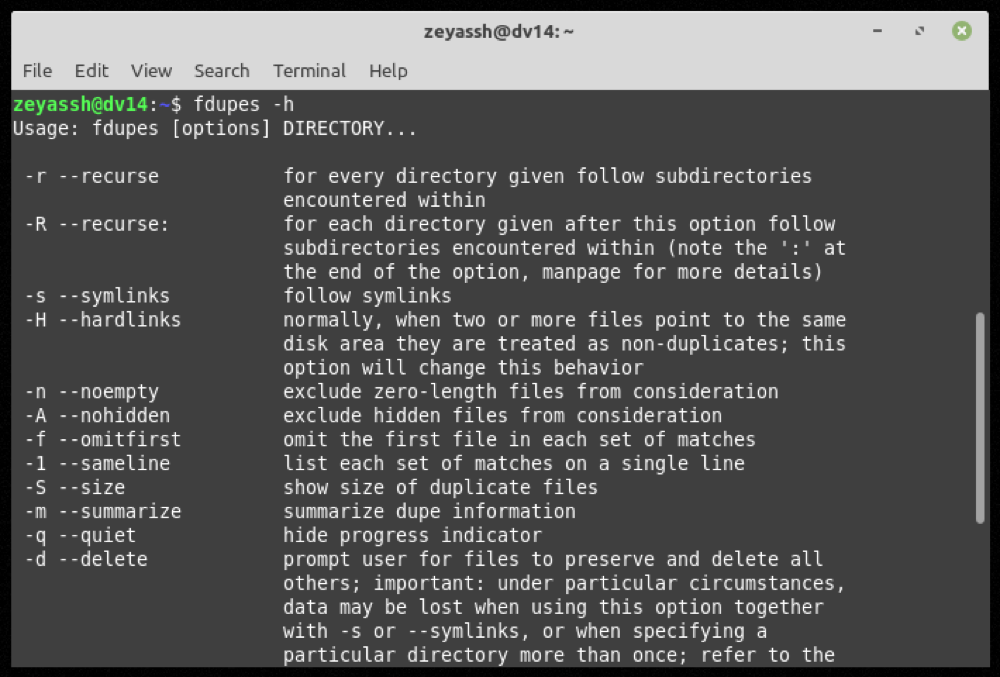
Excluindo arquivos duplicados no Linux com fdupes
Depois de identificar os arquivos duplicados em um diretório, você pode prosseguir com a remoção / exclusão desses arquivos do sistema para limpar a desordem e liberar espaço de armazenamento.
Para excluir um arquivo duplicado, especifique o sinalizador -d com o comando e pressione Enter :
fdupes -d path/to/directoryPara remover arquivos duplicados na pasta Downloads :
fdupes -d ~/DownloadsO Fdupes agora apresentará uma lista de todos os arquivos duplicados naquele diretório e lhe dará a opção de preservar aqueles que deseja manter em seu computador.
Por exemplo, se você quiser preservar o primeiro arquivo no conjunto 1, digite 1 após a saída de uma pesquisa fdupes e pressione Enter .
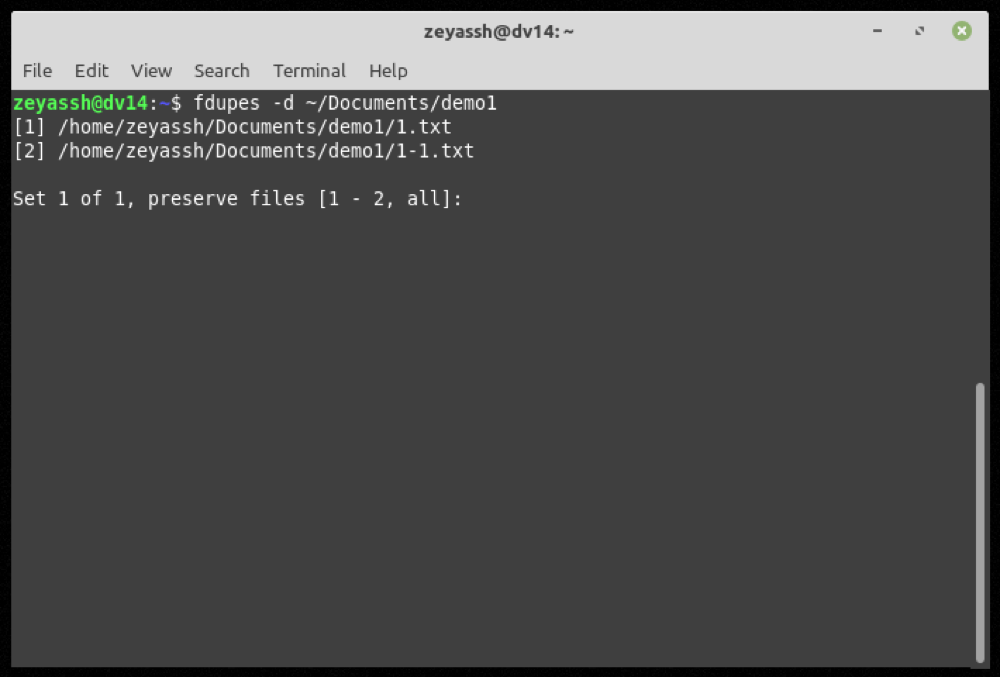
Além disso, se necessário, você também pode salvar várias instâncias de arquivo em um conjunto de arquivos duplicados retornados. Para isso, você precisa inserir os números correspondentes aos arquivos duplicados em uma lista separada por vírgulas e pressionar Enter .
Por exemplo, se você deseja salvar os arquivos 1, 3 e 5, você precisa inserir:
1,3,5Caso queira preservar a primeira instância de um arquivo em cada conjunto de arquivos duplicados e deseja ignorar o prompt, você pode fazer isso incluindo a opção -N , conforme mostrado no seguinte comando:
fdupes -d -N path/to/directoryPor exemplo:
fdupes -d -N ~/DocumentsExcluindo com sucesso arquivos duplicados no Linux
Organizar arquivos é uma tarefa tediosa por si só. Acrescente a isso os problemas que os arquivos duplicados causam e você terá algumas horas de tempo e esforço desperdiçados na organização de seu armazenamento desordenado.
Mas, graças a utilitários como o fdupes, é muito mais fácil e eficiente identificar arquivos duplicados e excluí-los. E o guia acima deve ajudá-lo com essas operações em sua máquina Linux.
Assim como os arquivos duplicados, as palavras duplicadas e as linhas repetidas em um arquivo também podem ser frustrantes e exigem a remoção de ferramentas avançadas. Se você também enfrentar esses problemas, poderá usar o uniq para remover linhas duplicadas de um arquivo de texto.
