
Executando difusão estável e modelos grandes de ponta a ponta em notebooks finos e leves? Intel diz que não há problema

Seja passivo ou ativo, substantivos como big model, AIGC, ChatGPT, Stable Diffusion, MidJourney, etc. mais um milagre. O Evangelho ou a Segunda Vinda da Skynet, as pessoas começaram a enfrentá-lo diretamente, entendê-lo e usá-lo adequadamente.
Claro, esta rodada de onda AIGC ocorre principalmente na nuvem, seja ChatGPT, ou Wenxin Yiyan, Tongyi Qianwen e outros grandes aplicativos de modelo de linguagem, ou MidJourney e outros aplicativos de imagem gerados por AI, existem muitos como vídeo gerado por AI aplicativos como o Runway precisam estar conectados à Internet, porque os cálculos de IA acontecem em servidores de nuvem a milhares de quilômetros de distância.
Afinal, de um modo geral, o poder de computação e o armazenamento que podem ser fornecidos pela ponta do servidor são muito maiores do que os da ponta do computador e da ponta móvel, mas a situação não é absoluta. AI de ponta com resposta rápida e sem necessidade para redes é, sem dúvida, outra tendência, e a IA em nuvem é capaz de se complementar.
No discurso anual da Xiaomi, não muito tempo atrás, o fundador da Xiaomi, Lei Jun, disse que o último modelo de 1,3 bilhão de parâmetros do modelo de IA da Xiaomi foi executado com sucesso localmente no telefone celular, e alguns cenários podem ser comparados aos resultados do modelo de 6 bilhões de parâmetros em execução na nuvem.
Embora a quantidade de parâmetros não seja muito grande, ela ilustra a viabilidade e o potencial do modelo grande de ponta a ponta.
No lado do PC com um poder de computação muito maior, também existe a viabilidade e o potencial de aplicativos AIGC, como modelos grandes no lado do dispositivo? Em 18 de agosto, a Intel realizou uma sessão de compartilhamento de tecnologia, com foco no compartilhamento de dois aspectos de informações: atualizações de desempenho Intel Sharp Graphics DX11 e o lançamento da nova ferramenta Intel PresentMon Beta, além de exibir o progresso da Intel no campo AIGC.

Quando os produtos de desktop da Intel foram lançados no ano passado, foi prometido que as placas gráficas da Intel continuariam a ser otimizadas e atualizadas para proporcionar uma melhor experiência.
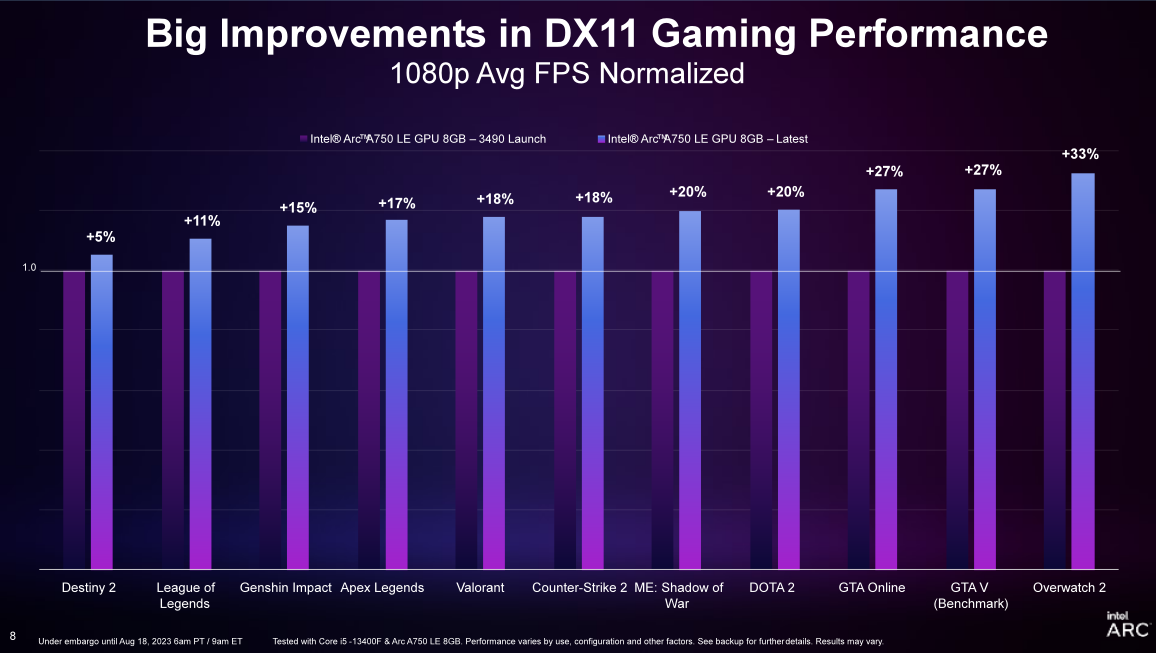
Com o lançamento do driver Game On mais recente, o Intel Ruixuan Graphics pode atingir um aumento de 19% na taxa de quadros ao executar uma série de jogos DX11 e uma melhoria média de 20% na fluência da taxa de quadros do 99º percentil (em comparação com a primeira versão do driver) . Os usuários que compraram e usaram a placa gráfica Intel Sharp A750 antes podem baixar diretamente o driver mais recente e obter atualizações de experiência em jogos como Overwatch 2, DOTA 2 e Apex Legends.
Para usuários que estão um pouco hesitantes em escolher uma placa de vídeo, a placa de vídeo Ruixuan A750 na faixa de 1700 yuan também se tornou uma escolha bastante competitiva.
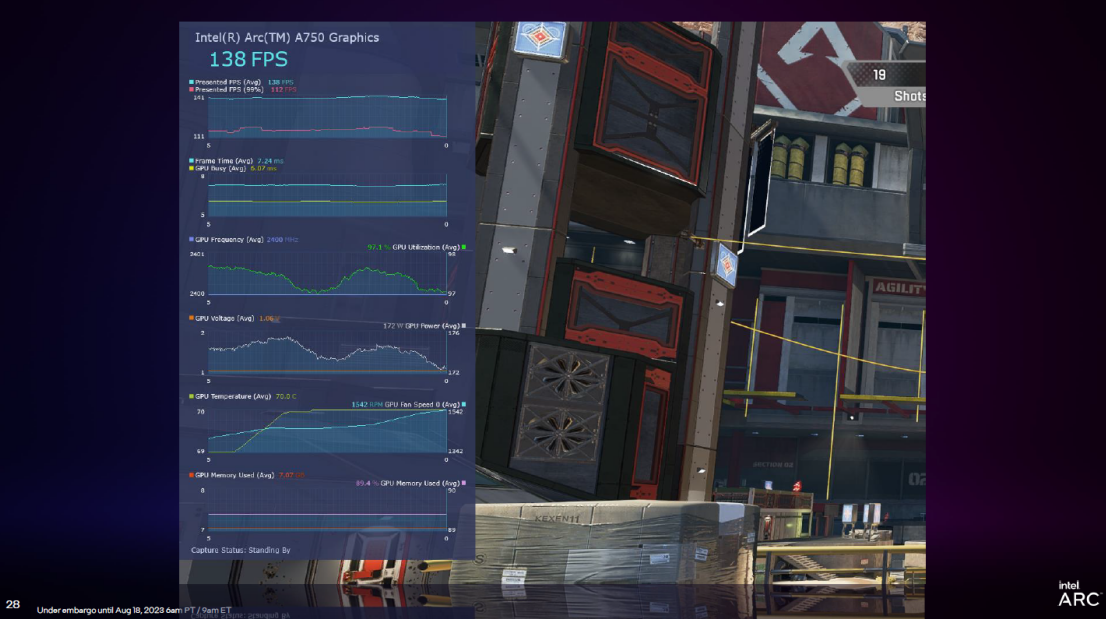
PresentMon Beta é uma ferramenta de análise de desempenho gráfico lançada pela Intel. Ele fornece funções como Overlay (exibição de sobreposição), que pode exibir dados de desempenho na tela durante a execução do jogo e ajudar os jogadores a telemedir a tensão e a temperatura da GPU em tempo real , e analisar uma grande quantidade de informações em tempo real. Confira também o gráfico de tempo de quadro do percentil 99 x utilização da GPU.
Além disso, o PresentMon Beta também traz um novo indicador chamado "GPU Ocupado". Aqui está uma explicação, para que os usuários possam ver quanto tempo a GPU está realmente usando para a renderização real, em vez de esperar, ou se o PC que executa o jogo está em equilíbrio entre CPU e GPU.
Os jogos são um tema eterno do PC, enquanto a IA é um novo tema.
Aliás, o principal equipamento para esta onda de AIGC é o PC, seja ChatGPT, MidJourney, Stable Diffusion e outras aplicações, incluindo Microsoft Office Copilot baseado em modelos grandes, ou WPS AI de Kingsoft Office. no PC.
No entanto, em comparação com outros dispositivos, como telefones celulares, tablets e PCs, as vantagens dos PCs residem não apenas em telas maiores e entrada interativa mais eficiente, mas também no desempenho do chip.
Antes da Intel falar sobre AIGC em PCs, notamos que a execução de AIGC lado a lado em PCs geralmente usa notebooks de jogos de alto desempenho para executar gráficos, mas notebooks finos e leves geralmente são excluídos.
Agora, a Intel afirmou claramente que o instinto fino e leve baseado nos processadores Intel pode executar modelos grandes e também modelos grandes e difusão estável.
A solução de back-end da Intel baseada no OpenVINO PyTorch (um kit de ferramentas de código aberto lançado pela Intel para otimizar o desempenho de inferência de modelos de aprendizado profundo e implantá-los em diferentes plataformas de hardware), por meio da API Pytorch, o modelo de código aberto da comunidade pode ser bem executado Processadores clientes da Intel, gráficos integrados, gráficos discretos e mecanismos de IA dedicados.
Por exemplo, o modelo de geração de imagem de código aberto Stable Diffusion (especificamente, Automatic1111 WebUI) pode executar modelos de precisão FP16 em CPUs e GPUs Intel (incluindo placas gráficas integradas e placas gráficas discretas) dessa maneira, e os usuários podem gerar texto e imagens • Funções como geração de imagem e reparo parcial.

▲ Foto de: Aijiwu
Por exemplo, esta imagem de panqueca de mel com resolução de 512 × 512 pode ser gerada em apenas uma dúzia de segundos em um notebook fino e leve com processador Intel (usando apenas a tela central i7-13700H).
Isso se deve principalmente ao progresso do processador Core de 13ª geração em número de núcleos, desempenho, taxa de consumo de energia e desempenho gráfico. Tomando como exemplo o processador i7-13700H com 14 núcleos e 20 threads, seu TDP atingiu 45W e o integrado A placa gráfica Intel Iris Xe Graphics (96EU) também não deve ser subestimada.
Como um dos monitores principais de especificação mais alta atualmente, o Intel Iris Xe Graphics (96EU) é de até 64EU em comparação com o monitor principal Iris Plus, a especificação básica é significativamente melhorada, o desempenho de ponto flutuante FP16, FP32 é aprimorado em até 84% , e o cálculo de número inteiro INT8 também é introduzido Habilidade, eles aprimoraram seus recursos de computação gráfica AI e também é a principal razão pela qual os livros finos e leves da Intel podem suportar bem a difusão estável.
No passado, os processadores Intel com um TDP de cerca de 45W eram difíceis de caber em notebooks finos e leves, mas na 13ª geração do Core, houve um grande número de notebooks finos e leves em torno de 1,4KG com 14 núcleos, 20 threads, Processadores i7-13700H e desempenho ainda maior. O processador i7-13900H está conectado, portanto, executar Stable Diffusion em um notebook para produzir imagens rapidamente não é mais exclusivo de notebooks de jogos de alto desempenho, e notebooks finos e leves também poderão fazer este trabalho no futuro.
É claro que o Stable Diffusion em si é executado principalmente localmente, e é lógico que notebooks finos e leves sejam executados por meio da melhoria e otimização do desempenho do chip, mas o modelo grande do lado final local é uma coisa relativamente nova.
Por meio da otimização do modelo, a demanda do modelo por recursos de hardware é reduzida, melhorando assim a velocidade de inferência do modelo, e a Intel permite que alguns modelos de software livre da comunidade funcionem bem em computadores pessoais.
Tomando o modelo de linguagem grande como exemplo, a Intel usa a aceleração do processador Intel Core de 13ª geração XPU, quantização de bit baixo e outras otimizações de nível de software para permitir que um modelo de linguagem grande com até 16 bilhões de parâmetros seja executado em 16 GB até a estrutura BigDL-LLM em um computador pessoal com capacidade de memória e superior.
Embora haja uma lacuna de ordem de magnitude dos 175 bilhões de parâmetros do ChatGPT3.5, afinal, o ChatGPT3.5 é executado em um cluster de rede AGI construído com 10.000 chips Nvidia V100. E esse modelo grande com 16 bilhões de parâmetros executados na estrutura BigDL-LLM é executado em um processador como Intel Core i7-13700H ou i7-13900H, desenvolvido para notebooks finos e leves de alto desempenho.
No entanto, também pode ser visto aqui que o modelo de linguagem grande no lado do PC também é uma ordem de grandeza maior do que no lado do telefone móvel.
Os PCs que existem há décadas não são ferramentas para executar modelos grandes na nuvem. Graças aos avanços de hardware, os PCs com processadores Intel podem se conectar rapidamente a modelos emergentes e são compatíveis com os modelos Transformers no HuggingFace. Modelos que foram verificados até agora incluem, mas não limitados a: LLAMA/LLAMA2, ChatGLM/ChatGLM2, MPT, Falcon, MOSS, Baichuan, QWen, Dolly, RedPajama, StarCoder, Whisper, etc.
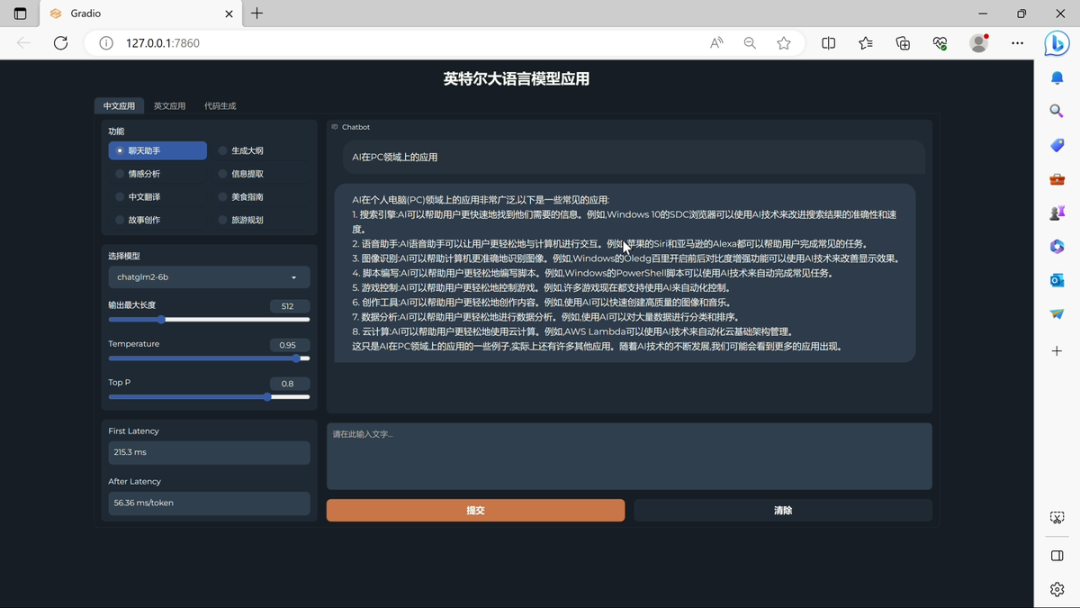
▲ Foto de: Aijiwu
Na reunião de compartilhamento de tecnologia, a Intel demonstrou o desempenho da execução de um modelo grande baseado no dispositivo Core i7-13700H: ChatGLM-6b pode atingir a primeira latência de primeira geração de token de 241,7 ms e a taxa média de geração de tokens subsequentes é de 55,63 ms /símbolo. No campo do processamento de linguagem natural, "token" refere-se a uma unidade básica no texto, que pode ser uma palavra, uma palavra, uma subpalavra, um sinal de pontuação ou outras unidades menores que podem ser processadas semanticamente. Como você pode ver, a velocidade do processador é muito boa.
A novidade que ainda está disponível é que o processador Meteor Lake de próxima geração da Intel tem as vantagens de uma arquitetura única de módulos separados para melhor atender a IA, incluindo funções multimídia como reenquadramento automático e detecção de edição de cena no Adobe Premiere Pro, além de obter máquina mais eficiente aceleração do aprendizado.
Embora AIGC seja uma palavra-chave em 2023, AI não é nova e também é uma palavra-chave sobre a qual a Intel tem falado com frequência nos últimos anos.
Redução de ruído de chamada de vídeo AI anterior, redução de ruído de fundo de chamada de vídeo AI, etc., são na verdade aplicações de AI.
Percebe-se que a competitividade dos futuros processadores não se limitará ao número de núcleos, número de threads e frequência principal, um dos fatores que o produto irá considerar.
#Bem-vindo a seguir a conta pública oficial do WeChat de Aifaner: Aifaner (ID do WeChat: ifanr), conteúdo mais interessante será apresentado a você o mais rápido possível.
