
Diálogo com Liu Zhiyuan, cientista-chefe de inteligência voltada para a parede: modelos grandes terão uma nova “Lei de Moore”, e terminais inteligentes na era AGI podem não ser necessariamente telefones celulares

Desde o ano passado, a indústria de IA da China lançou uma “Batalha de Centenas de Modelos”, com quase todas as grandes empresas de modelos com o objetivo de alcançar o GPT-4. Há também uma empresa que parece um pouco deslocada: a inteligência voltada para a parede que se concentra em modelos finais.
A inteligência voltada para a parede chegou aos olhos do público devido a um recente incidente de plágio cometido pela equipe de pesquisa de IA de Stanford. Liu Zhiyuan, cientista-chefe da Wall-Facing Intelligence, escreveu na altura que este incidente provou a influência internacional das inovações da China a partir de outra perspectiva.
Na recente Conferência Mundial de Inteligência Artificial, Face Wall lançou o modelo eficiente de ativação esparsa MiniCPM-S, que pode usar menor consumo de energia e trazer velocidade de raciocínio mais rápida.
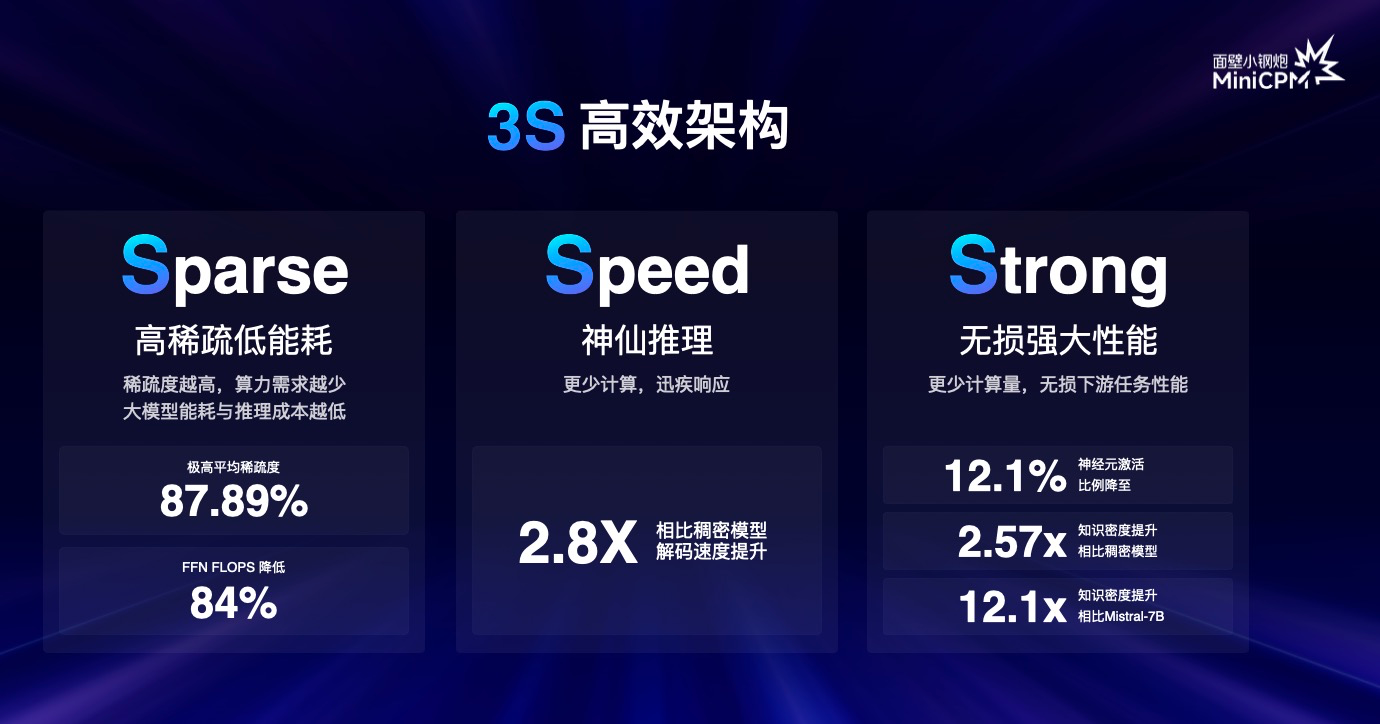
A Wall-facing Intelligence também declarou publicamente que será capaz de alcançar um modelo final de nível GPT-4 até o final de 2026 .
Se o GPT-4 e o modelo final forem reunidos, será equivalente a Wang Zha.
Este ano, muitos hardwares de IA nativos foram questionados, e os telefones celulares e PCs de IA são extremamente populares, mas têm pouco impacto nas decisões de compra dos consumidores. Em grande medida, são limitados pelas capacidades do grande lado final. modelos e funções mais complexas exigem Confiar na nuvem para serem concluídos.

Na acalorada discussão de modelos grandes, o MiniCPM inteligente de ponta a ponta "pequeno canhão de aço" voltado para a parede é um modelo um tanto subestimado. O modelo MiniCPM 2.4B lançado em fevereiro de 2024 pode realmente superar o Llama2-13b.
Liu Zhiyuan, cientista-chefe da Wall-Facing Intelligence, acredita que a era dos grandes modelos terá sua própria Lei de Moore. A palavra-chave para o primeiro princípio de grandes modelos eficientes no futuro deve ser densidade de conhecimento.

▲Liu Zhiyuan, cientista-chefe de inteligência voltada para a parede
Durante o WAIC 2024, a APPSO conversou com Liu Zhiyuan, falando sobre o impacto dos modelos finais nas futuras formas de terminais inteligentes, como descobrir a Lei de Moore dos grandes modelos e como um idealista que saiu da torre de marfim pode ter sucesso em o alvo do mundo dos negócios próximo da AGI.
A seguir está a transcrição da conversa entre Liu Zhiyuan e APPSO:
A Lei de Moore na Era dos Grandes Modelos
APPSO: Quando todos estão comparando com o OpenAI para construir grandes modelos gerais, por que a Wallface Intelligence optou por se concentrar em modelos finais? Existe alguma controvérsia interna?
Liu Zhiyuan: Na verdade, já lançamos o modelo de 100 bilhões em meados do ano passado, antes de muitas grandes empresas de modelos nacionais. Mas estamos diante de uma escolha: deixar o processo do modelo corresponder ao seu nível de densidade de conhecimento. Naquela época, o consenso da indústria era lançar modelos maiores e tentar chegar ao GPT-4.
Como empresário, é natural colocar-se no lugar de outra pessoa, por isso também conduzimos discussões internas sérias sobre se deveríamos tornar este modelo maior. Então compre mais poder de computação e passe alguns meses construindo esse modelo.
APPSO: Por que você não fez isso no final?
Liu Zhiyuan: Sentimos que primeiro precisamos melhorar nosso processo de fabricação de modelos. Temos construído modelos de túneis de vento desde o segundo semestre do ano passado para tornar previsível o treinamento de modelos. Em outras palavras, pode-se prever antes do treinamento do modelo se o treinamento com esses dados pode atingir o nível esperado.
Portanto, não continuamos a lançar o GPT-4. Nossa previsão é que, se trabalharmos duro para aumentar o poder de computação, os dados e a escala dos parâmetros do modelo, um modelo de nível GPT-4 será lançado até junho deste ano. Isso é algo que todas as grandes empresas nacionais de modelos de primeiro nível podem alcançar. .
Se todos podem fazer isso, e nós também, qual é a nossa vantagem competitiva? Portanto, decidimos começar primeiro com aplicativos de nível GPT-3.5 e depois passar para o processo contínuo.
APPSO: O processo de laminação é um pouco parecido com a ideia de fabricação de chips.
Liu Zhiyuan: Na verdade, o processo representa a densidade do conhecimento. Optamos por usar um modelo relativamente pequeno e depois verificar as capacidades do nosso processo. Então optamos por construir um modelo do lado do dispositivo naquela época. No início deste ano, havíamos construído o modelo 2.4B.
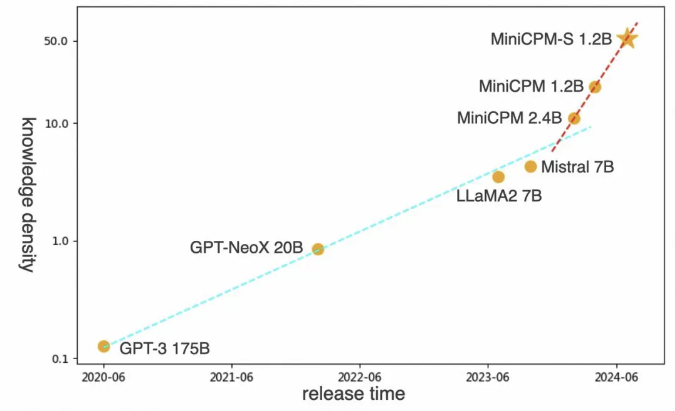
Na verdade, antes de fazermos isso, estávamos pensando que, como vamos fazer um modelo tão pequeno, devemos fazê-lo funcionar em um celular. É claro que eu não esperava dizer que deveríamos construir inteligência final para telefones celulares. Acontece que o modelo final que fizemos usando a tecnologia de túnel de vento pode atingir o nível de 175 bilhões de parâmetros do GPT-3 com parâmetros de 2,4B e pode comparar os efeitos do Mistral 7B e do lhama 2 13B.
APPSO: Você mencionou muitas vezes a densidade do conhecimento e o processo de fabricação. Temos um padrão específico?
Liu Zhiyuan: Por exemplo, se eu lhe der 100 perguntas de teste de QI, quantos pontos você consegue? Quanto custa o poder de computação? Quando você faz essas 100 questões do teste, quantos neurônios você tem envolvidos no cálculo? Quanto menos neurônios você envolver nos cálculos, maior será o seu QI, porque você pode completar essas tarefas com menos neurônios. Este é o conceito básico de densidade de conhecimento .
Tem dois elementos. Um elemento é a capacidade deste modelo. O segundo elemento é o número de neurônios necessários para esta capacidade, ou o correspondente consumo de energia computacional.
Nota do editor: Liu Zhiyuan propôs que a densidade de conhecimento do modelo (densidade de conhecimento = capacidade do modelo/consumo de energia de computação de inferência) dobrará em média a cada oito meses.
APPSO: Em que estágio você acha que está a inteligência artificial geral representada pelo grande modelo atual?
Liu Zhiyuan: Estamos no período Tychonic da física. Tycho coletou uma grande quantidade de dados sobre o movimento dos corpos celestes, mas não havia encontrado as leis reais do movimento desses corpos celestes. Só mais tarde surgiram as leis de Kepler, e ainda mais tarde surgiu a lei da gravitação universal de Newton.
Se pudermos encontrar a lei da gravitação universal que pertence ao desenvolvimento de grandes modelos, então poderemos usar essa lei para construir a melhor máquina de litografia do mundo .
APPSO: A OpenAI também está fazendo isso?
Liu Zhiyuan: OpenAI definitivamente está fazendo isso, porque na verdade propôs uma pilha de aprendizado profundo com escalabilidade previsível há alguns anos. Na verdade, isso é semelhante ao conceito de um modelo de túnel de vento. Este deveria ser o consenso de muitas pessoas agora. Só que o OpenAI não está aberto desde o ano passado. .

APPSO: Você deseja procurar coisas de nível inferior, em vez de pensar em como agregar valor comercial rapidamente no momento
Liu Zhiyuan : A cientificização de grandes modelos deve ser um pré-requisito para uma verdadeira comercialização no futuro . Hoje em dia, quando todos buscam modelos grandes e AGI, eles têm duas opções.
Uma opção é você usar o mesmo processo, ou até um processo pior, e depois treinar um modelo muito grande, modelos cada vez maiores, e então atingir o nível GPT-4, mas isso faz sentido?
Sentimos que este assunto não era confiável desde o segundo semestre do ano passado. Porque se o seu processo de fabricação não for forte o suficiente, você na verdade não tem competitividade. A lacuna entre nós e a OpenAI não está na escala dos parâmetros do modelo, mas no processo de fabricação.
Então, na verdade, você vai descobrir que no primeiro semestre deste ano todos começaram a aumentar o preço dessa API. Esse assunto tem pouca importância, mas faz com que todos não consigam ganhar dinheiro.
Imagine que você gaste dezenas de milhões para treinar um modelo enorme e, em seguida, forneça a API desse modelo. 1 milhão de tokens podem custar apenas alguns centavos. Mesmo que haja dezenas de bilhões de uso em um mês, a receita correspondente cobrirá o valor. custo. . Você não acha que esse é um padrão muito desesperador? Isso é ainda mais louco do que a Guerra dos Cem Regimentos daquela época.
Terminais inteligentes na era AGI
APPSO: Recentemente você também se tornou o primeiro parceiro de modelo do lado do cliente em grande escala da Huawei Cloud. Essa é a direção de sua comercialização futura?
Liu Zhiyuan: Cooperaremos com mais fabricantes nos próximos 2 a 3 anos. Acho que no futuro haverá terminais inteligentes pertencentes à era AGI, que podem não ser telefones celulares ou carros.
APPSO: Qual é a sua forma de terminal ideal na era AGI?
Liu Zhiyuan: A forma atual de telefones celulares é, na verdade, o método de interação multitoque introduzido pela Apple naquela época. Mas se a IA se tornar inteligente o suficiente no futuro, ainda precisaremos de interação por clique e toque? No futuro, deve haver um método de interação em linguagem natural pertencente à AGI, que esteja mais de acordo com as nossas características humanas. Diz-se até que um dia, uma vez conectada a interface cérebro-computador, nem precisarei falar. Portanto, o terminal inteligente pertencente à AGI pode não ser um telefone celular, ou o telefone mudará de forma em algum momento. apontar.
E quando temos uma forma mais natural de interagir, por que precisamos de um aplicativo ? Se grandes fabricantes de telefones celulares como a Apple não trabalharem nessa direção, alguém certamente o fará.

APPSO : Qual você acha que será o personagem de Wall Face nisso?
Liu Zhiyuan: Para uma empresa iniciante como nós, nossa vantagem é a inovação, inovação extrema. Nosso primeiro objetivo é descobrir como usar o AGI. Nascemos para isso e essa é a nossa vantagem.
Mesmo os grandes fabricantes serão esmagados pelas rodas da história se não inovarem, tal como a Nokia naquela altura.
APPSO: Como você descreveria sua cooperação com a Huawei?
Liu Zhiyuan: Esperamos formar uma parceria com empresas como a Huawei que possa servir como um modelo industrial para a colaboração entre dispositivos e nuvem .
APPSO: A Huawei lançou um Hongmeng puro-sangue, no qual a estrutura de IA e os modelos grandes são muito importantes. Você terá mais cooperação no futuro?
Liu Zhiyuan: Definitivamente haverá cooperação em chips inteligentes, sistemas operacionais inteligentes e até mesmo em nível de modelo.

APPSO: Você está preocupado com o fato de esses fabricantes de hardware criarem seus próprios modelos de dispositivos?
Liu Zhiyuan: Esta é uma grande diferença entre os mercados chinês e americano. A cadeia industrial americana tem um forte senso de segurança entre si e todos podem fazer negócios juntos. Mas a China parece querer que cada empresa faça tudo sozinha. Se houver uma peça que não seja feita sozinha, ela se sentirá muito insegura. Se conseguirmos formar criativamente uma cooperação muito estável, então acredito que será capaz de dar. aproveitar plenamente as vantagens do trabalho de todos, mas pode ocupar melhor esse mercado.
APPSO: O que o Wallface pode fazer que outros fabricantes de hardware não conseguem?
Liu Zhiyuan: Em primeiro lugar, do ponto de vista de algoritmos de grandes modelos, na verdade, sua tecnologia é rapidamente difundida. Não buscamos tecnologia de treinamento de modelo que outros fabricantes nunca dominarão.
Pelo menos por enquanto, no lado final, devido às limitações no poder de computação e no consumo de energia da memória, ele realmente possui requisitos mais elevados para o processo de fabricação do modelo. Deve ser capaz de colocar o modelo em uma escala de parâmetros menor de uma forma mais extrema e, ao mesmo tempo, ter capacidades mais fortes.
Por exemplo, no processo de fabricação de chips, o processo mais avançado deve ser usado para fabricar chips de teste final. Como o espaço para testes ponta a ponta é menor e mais sensível ao consumo de energia, mesmo o modelo de teste ponta a ponta deve exigir um processo de modelo superior, que é mais rigoroso que o modelo em nuvem.
Nos testes em nuvem, desde que seus recursos de poder de computação sejam suficientes, você pode ter mais espaço de manobra. Mas nos testes finais é diferente. As limitações nos testes finais são limitadas por seu chip, sua memória e sua bateria. Portanto, você deve treinar um modelo extremamente pequeno. Deste ponto de vista, sem falar nas grandes empresas modelo no mercado agora, por exemplo, o Google treinou modelos do mesmo nível dois meses depois de nós, e ainda estava cerca de 10% atrás de nós.
APPSO: Você previu antes. Você acha que, no futuro, a maioria dos aplicativos estará no lado do dispositivo. Até que ponto você acha que é possível fazer isso?
Liu Zhiyuan: Na verdade, o testador final precisa ser um Einstein para atendê-lo. O nível GPT-4 ou GPT-4o é suficiente. Eu estimo que se a densidade de conhecimento dos chips finais aumentar na mesma proporção, nos próximos dois anos, poderemos colocar o nível GPT-4 em testes finais, e então mais de 80% dos requisitos serão concluídos em o lado final.
APPSO: Sua previsão é bastante radical.
Liu Zhiyuan: É radical? Podemos esperar e ver.
Para a AGI, o objetivo deve estar além da natureza humana
APPSO: Desde o surgimento de grandes modelos, todos os grandes fabricantes de modelos têm falado sobre TPF Technology-Problem Fit). Como a Wall-Facing Intelligence forma um consenso sobre tecnologia e produtos internamente e combina T e P?
Liu Zhiyuan: Temos uma visão de longo prazo. Queremos ser um superaplicativo na era AGI.
Mas temos de sobreviver no curto prazo e provar ao mercado o valor da nossa tecnologia. Portanto, concluiremos a verificação da tecnologia através da cooperação estratégica com alguns fabricantes, como ajudar o Tribunal Popular Intermediário de Shenzhen a lançar um sistema de teste assistido por inteligência artificial. Essas explorações são nossos objetivos de curto prazo para concretizar nossa visão de longo prazo.

APPSO: Superaplicativos também são um tema muito quente. Baidu Robin Li disse que quando falamos sobre superaplicativos agora, pode ser uma armadilha ou uma proposição falsa. Atualmente não existe uma definição geralmente aceita do que é um superaplicativo.
Liu Zhiyuan: Depois de 2000, percebi pelo menos duas ondas tecnológicas muito importantes. Uma delas foi a tecnologia de busca, que deu origem a grandes empresas como o Google. A segunda vez é a tecnologia de recomendação personalizada. Isso trouxe aplicações importantes como Douyin.
Na verdade, essas próprias tecnologias eram muito certas na época. Todo mundo sabe que é um avanço muito grande. É apenas uma questão de como usá-lo e que tipo de produto ele forma. Este assunto é incerto e requer concorrência.
Para nós, o primeiro é dominar a tecnologia mais avançada e o segundo é sermos sensíveis o suficiente. Quando um super aplicativo aparece, devemos ser capazes de perceber que se trata de um super aplicativo.
APPSO: Então você acha que é difícil definir um super app agora?
Liu Zhiyuan: Olhando para trás na história, quando o Google e o Toutiao apareceram, quantas pessoas perceberam que eram superaplicativos. Naquela época, o Yahoo News criou um aplicativo especial que enviava apenas dez notícias todos os dias.
Veja bem, mesmo que as manchetes de hoje já estejam diante deles, ele ainda tomará essas decisões. Além do mais, o superaplicativo ainda não apareceu. Mesmo que apareça, a maioria das pessoas não o usará.
APPSO: Como descobrir super apps?
Liu Zhiyuan: O que sempre digo aos meus alunos é que nunca sejam pessoas com interesses adquiridos . Não relute em admitir que você foi revolucionado só porque tinha várias vantagens antes .
Muitas pessoas não estão dispostas a admitir que foram revolucionadas. Ao fazer tradução automática estatística, ele não estava disposto a ver o surgimento da tradução automática neural. Ao fazer tradução automática neural, ele não quer ver o surgimento de grandes modelos. Porque ele sentia que todas as coisas em que era bom não tinham sentido e não queria admitir isso.
APPSO: Esta é a natureza humana.
Liu Zhiyuan: 99% das pessoas são humanas. Acho que para conseguir isso, você deve ter um senso de missão. Seu objetivo deve estar além da sua humanidade .
Se a sua missão é inferior à sua humanidade, então você não deve ser capaz de realizá-la. Por exemplo, se um fundador pensa que o mais importante para ele é manter a empresa, acho que há uma grande probabilidade de que ele não consiga acompanhar a super aplicação. faça isso bem?
APPSO: Somente uma pessoa um tanto idealista diria tal coisa.
Liu Zhiyuan: Sem idealismo, eu não teria fundado esta empresa.
APPSO: Algumas pessoas dizem que a dificuldade de um modelo grande para um agente inteligente é exponencial.
Liu Zhiyuan: Não creio que exista uma resposta padrão para a inteligência em si, mas a chave depende do que você investe nela. O que me deixa mais otimista é que o agente inteligente pode ser equipado com muitas coisas, como planejamento, tomada de decisão e capacidade de exploração. Se você considerar tudo isso como parte da AGI, na verdade acho que o que vale mais a pena esperar no futuro são os agentes da Internet.
É equivalente à Internet composta por esses agentes. Chamamos-lhe Internet da Inteligência. Acho que vale mais a pena esperar por isso. Você pode imaginar que, assim como a nossa sociedade humana, é uma comunidade altamente interconectada. Todos concluem algum trabalho através da cooperação total. Muitos campos, especialmente os complexos, exigem que todos tenham sua própria experiência e experiência profissional, e precisam trabalhar juntos para concluí-los.

APPSO: É um pouco longe demais falar sobre AGI agora?
Liu Zhiyuan: Não acho que esteja longe. Antes do lançamento do ChatGPT, no final de 2022, sempre senti que o AGI ainda tinha um problema não resolvido, que é o problema do bom senso, ou seja, como estabelecer o bom senso sobre o mundo.
Por exemplo, um pato tem uma cabeça, dois pés e duas asas, esse é o bom senso básico. Antes do surgimento do GPT-3.5, eu achava que esse conhecimento era difícil de aprender a partir dos dados. Incluindo problemas físicos, como o que acontece quando você varre uma xícara da mesa para o chão, etc. Quando você faz perguntas de bom senso sobre modelos grandes, ele não consegue respondê-las.
Após o surgimento do ChatGPT, descobrimos que esse bom senso parece poder ser aprendido pelo modelo de forma orientada por dados. Só que não sabíamos como chamá-lo antes, e o ChatGPT nos disse como chamá-lo. Acho que esse percurso técnico é muito tranquilo. Basta entregar a este modelo os dados correspondentes ao conhecimento que precisa ser aprendido para aprendê-lo.
APPSO: Os grandes modelos podem realmente compreender o mundo como os humanos?
Liu Zhiyuan: Ele está conectado a este modelo e aprende seus hábitos diários de operação desses aplicativos. Não há absolutamente nenhuma razão para que ele não possa aprender suas preferências. Por exemplo, se eu quiser reservar um voo e você disser a ele quando quero fazer a reserva, ele simplesmente fará isso.
Então, na minha opinião, a direção dessa tecnologia está muito determinada. Falando apenas sobre como resolver os três elementos de dados, arquitetura e métodos de crescimento, acho que deveríamos olhar para este problema com mais otimismo.
A OpenAI afirma que se tornará uma empresa de superinteligência em seis anos, o que considero uma meta muito viável .
# Bem-vindo a seguir a conta pública oficial do WeChat de Aifaner: Aifaner (ID do WeChat: ifanr). Mais conteúdo interessante será fornecido a você o mais rápido possível.
