
DeepSeek está pressionando pela estratégia de expansão do Gemini, a função de pesquisa do ChatGPT é gratuita e aberta e a IA está iniciando uma guerra de divisão de lucros

No final do ano passado, o Google Deedmind lançou o modelo Gemini 2.0 Flash para a era dos agentes inteligentes, entrando na era 2.0 com um pé. Depois de dois meses, a série Gemini 2.0 de baldes familiares foi finalmente lançada oficialmente.
Catalisada pelo “efeito bagre” do DeepSeek, esta versão é diferente do habitual. Ela não apenas melhora ainda mais o desempenho, mas também acena a bandeira da relação custo-benefício da IA e também adota recursos multimodais.
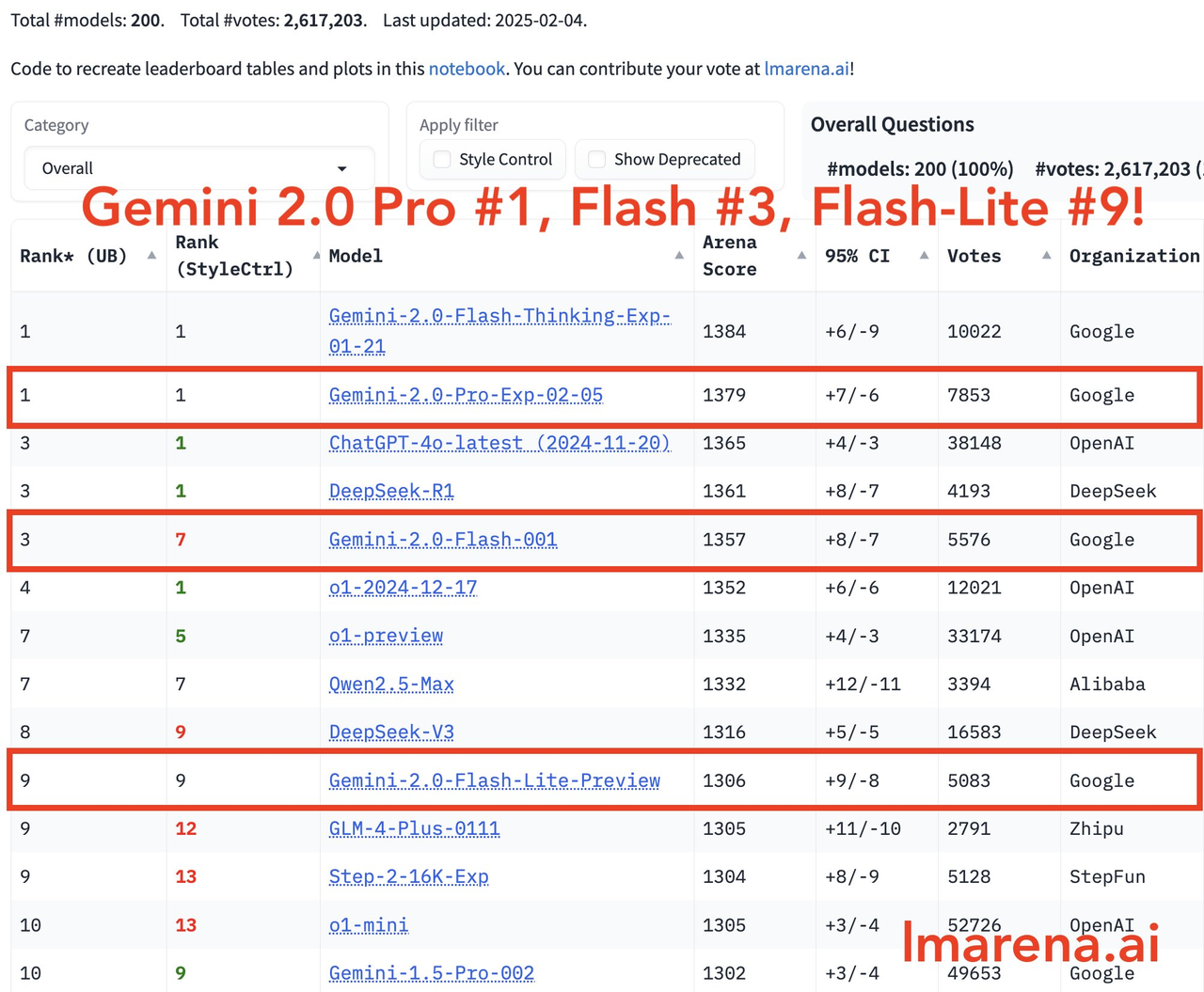
Na mais recente arena de modelos grandes, o Gemini-2.0-Pro ocupa o primeiro lugar em todas as categorias, o Gemini-2.0-Flash ocupa o terceiro lugar e o Flash-lite está entre os dez primeiros devido à sua excelente relação preço/desempenho.
O CEO da Deepmind, Demis Hassabis, escreveu:
Progresso emocionante! Nós nos esforçamos para reduzir custos enquanto melhoramos constantemente a qualidade. A série Gemini 2.0 é um modelo líder em termos de preço/desempenho e desempenho. Com o lançamento de hoje, todos podem tirar proveito de seu raciocínio poderoso e de suas capacidades multimodais, que também estabelecem a base para nosso trabalho inteligente.
As principais características dos modelos da série Gemini 2.0 são as seguintes:
- 2.0 Pro Experimental: concentra-se no desempenho da codificação e na capacidade de lidar com prompts complexos e tem um bom desempenho na compreensão do conhecimento e no raciocínio lógico.
- 2.0 Flash: Fornece interface API especificamente para desenvolvedores oferecerem suporte à construção rápida de aplicativos.
- 2.0 Flash-Lite: Obtenha melhor custo-benefício e capacidade de resposta, mantendo alto desempenho.
- 2.0 Flash Thinking Experimental: agora está disponível no aplicativo Gemini para os usuários experimentarem.
O que você pode fazer com menos de US$ 1? O novo modelo do Google pode legendar 40.000 imagens
Especificamente, cada um dos modelos de baldes familiares da série Gemini 2.0 tem suas próprias características.
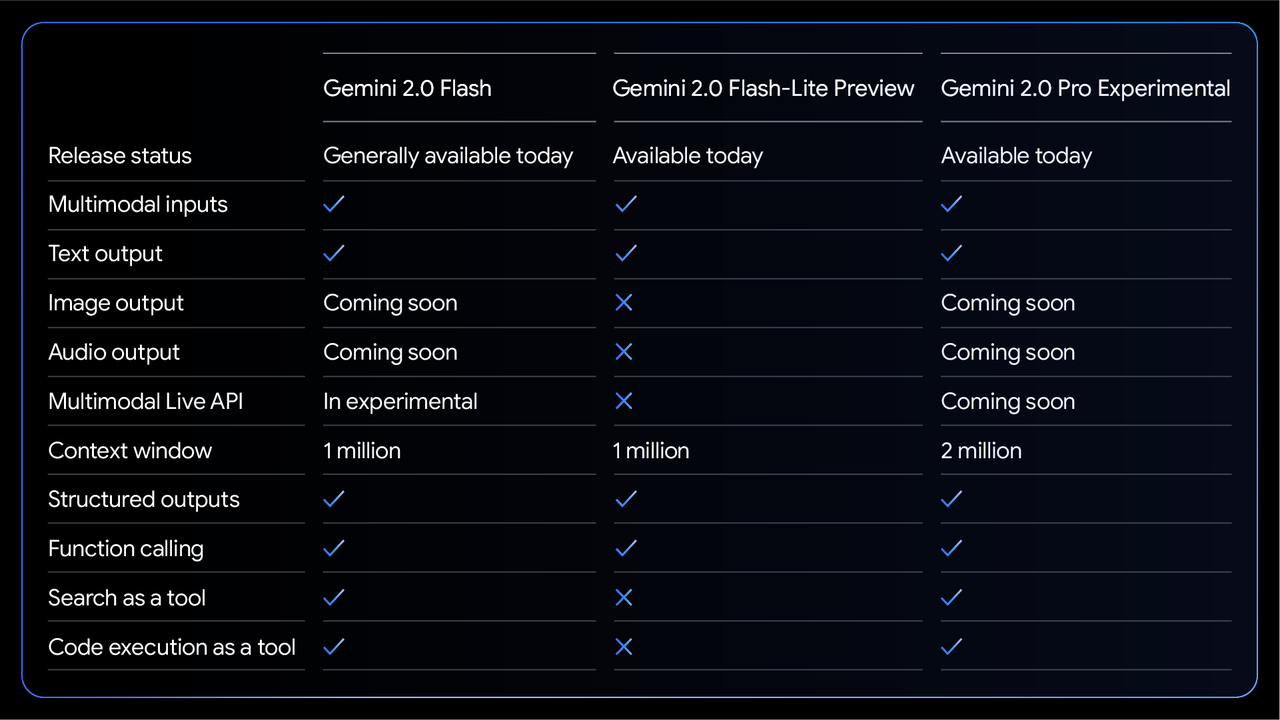
Entre eles, o Gemini 2.0 Flash, que foi totalmente lançado, suporta entrada multimodal e saída de texto, possui uma janela de contexto de 1 milhão de tokens e suporta saída estruturada, chamada de função, execução de código e outras funções.
Vale ressaltar que sua API multimodal em tempo real ainda está em fase "beta", e as funções de saída de imagem e áudio também serão lançadas posteriormente.
O plano de preços para este modelo também foi determinado, com entrada de texto, imagem e vídeo cobrando US$ 0,10 por milhão de tokens e entrada de áudio custando US$ 0,70 (oficialmente em vigor a partir de 20 de fevereiro). A saída de texto custa US$ 0,40 por milhão de tokens.
Todos os tipos de taxas de cache também são mantidos em níveis baixos. O cache de texto/imagem/vídeo custa US$ 0,025 por milhão de tokens, e o cache de áudio custa US$ 0,175.
Com base nisso, o Google também lançou uma "versão leve" mais econômica – Gemini 2.0 Flash-Lite.
Embora este modelo tenha feito certas compensações em termos de funcionalidade e atualmente não suporta APIs multimodais em tempo real, ferramentas de pesquisa e execução de código, ele mantém uma janela de contexto de 1 milhão de tokens, bem como funções essenciais, como entrada multimodal, saída de texto e chamadas de função.

Seu preço é mais acessível, com entradas de texto, imagem e vídeo custando apenas US$ 0,075 por milhão de tokens, quase um terço mais barato que a versão padrão. A entrada de áudio também custa US$ 0,075, a saída de texto custa US$ 0,30, o cache de texto/imagem/vídeo custa apenas US$ 0,01875 por milhão de tokens e o cache de áudio custa US$ 0,175.
Para efeito de comparação, o modelo DeepSeek-V3 agora custa US$ 0,014 por milhão de tokens ao acessar o cache. A partir de 8 de fevereiro, seu preço retornará ao nível de US$ 0,07 por milhão de tokens. Este ajuste também pode ser um dos fatores importantes que levaram o Google a formular a sua atual estratégia de preços.

Segundo o Google, o custo de usar esse modelo para gerar legendas para 40.000 imagens exclusivas é inferior a US$ 1.
No topo da linha de produtos está a versão Experimental Gemini 2.0 Pro. Este modelo possui uma grande janela de contexto de 2 milhões de tokens, o que equivale ao processamento de cerca de 1,5 milhão de palavras por vez, o que é mais que suficiente para digerir todos os sete livros da série "Harry Potter" ao mesmo tempo.
Funcionalmente, é também o player mais versátil, não apenas suportando entrada multimodal e saída de texto, mas também possui recursos completos, como saída estruturada, chamada de função, ferramentas de pesquisa e execução de código.
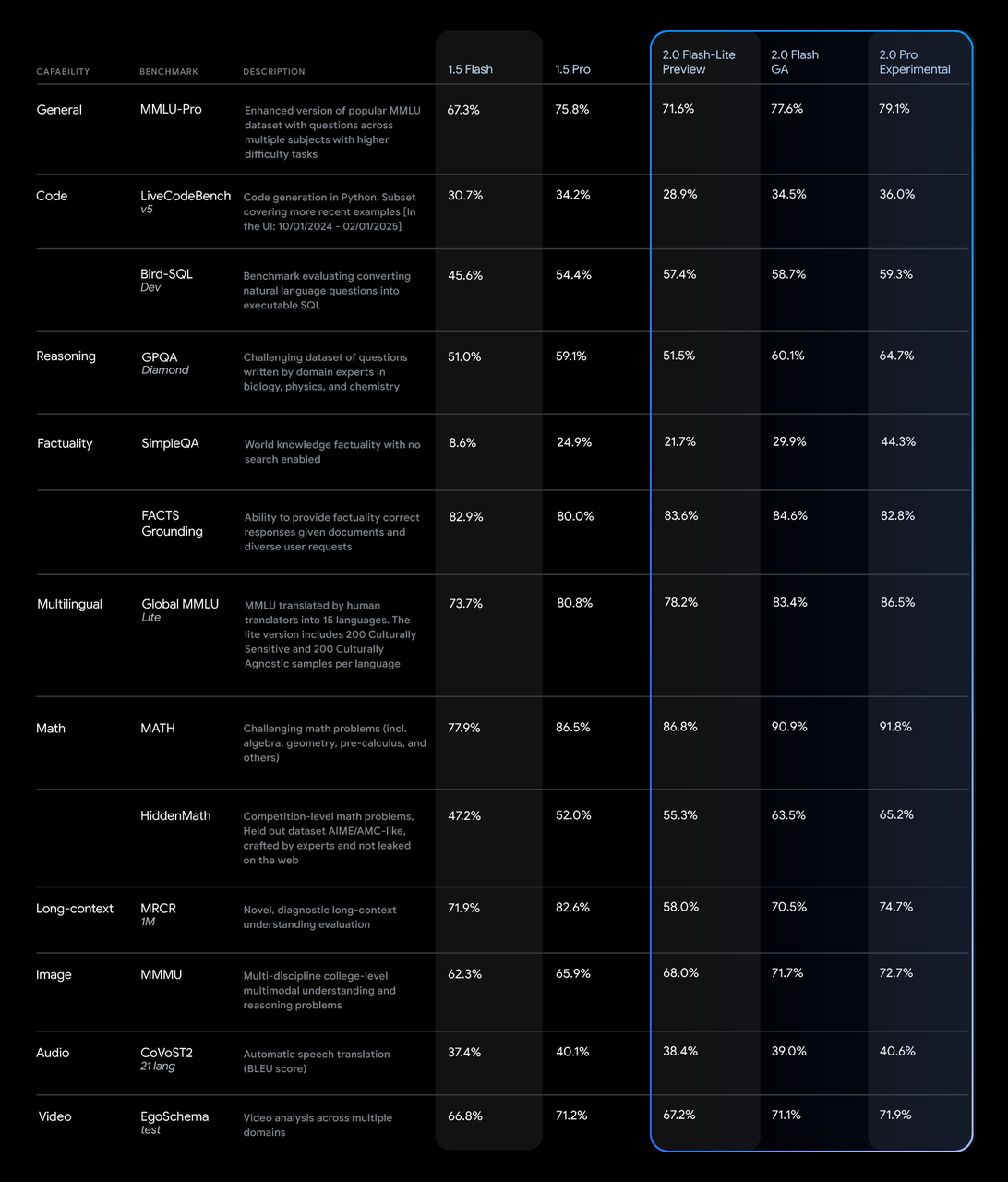
Em termos de testes de desempenho, a série Gemini 2.0 tem um bom desempenho.
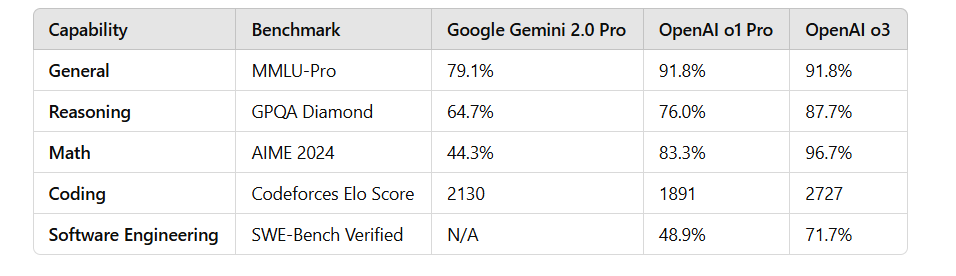
No teste MMLU-Pro, o 2.0 Pro Experimental liderou com uma pontuação de 79,1%, enquanto o 2.0 Flash Lite Preview e o 2.0 Flash GA pontuaram 71,6% e 77,6% respectivamente.
Em termos de geração de código, matemática e capacidade multilíngue, o 2.0 Pro Experimental também teve um bom desempenho, especialmente em matemática (91,8%) e capacidade multilíngue (86,5%).
Infelizmente, mesmo a versão experimental mais poderosa do Gemini 2.0 Pro está muito atrás do modelo OpenAI o3 e não completou a "ultrapassagem em curva" esperada pelo mundo exterior.
No entanto, alguns internautas acreditam que, como o Gemini 2.0 Pro não é um modelo CoT típico, a comparação de desempenho atual pode não ser completamente razoável.
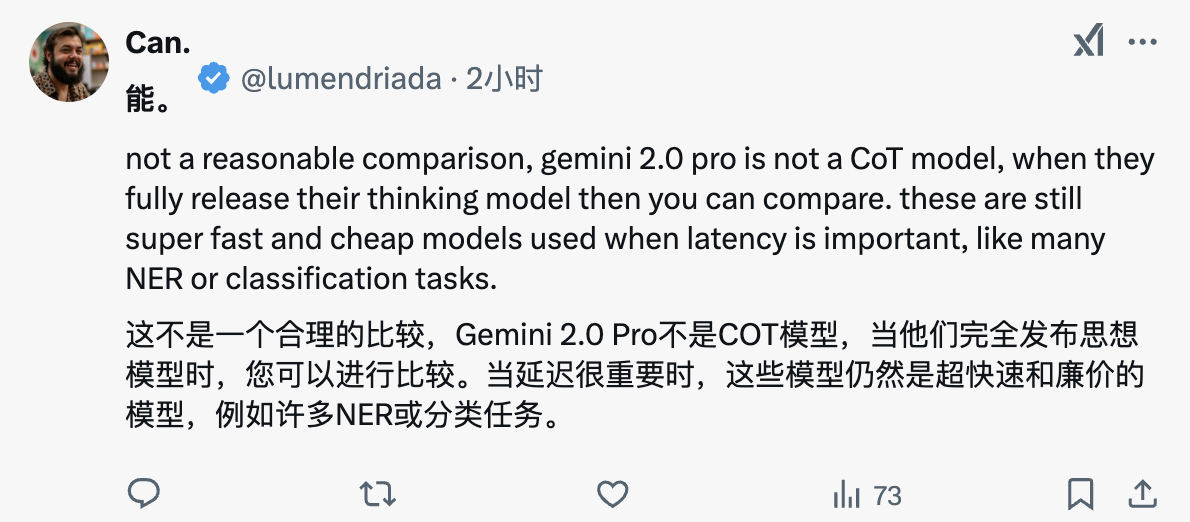
As principais vantagens destes modelos são a sua rápida capacidade de resposta e baixo custo, tornando-os particularmente adequados para tarefas específicas, como reconhecimento ou classificação de entidades nomeadas. Com o próximo lançamento de novos recursos, como geração de imagens e conversão de texto em voz, os cenários de aplicação da série Gemini 2.0 serão ainda mais expandidos.
Esses novos modelos agora estão disponíveis para desenvolvedores no Google AI Studio e na plataforma Vertex AI, bem como para usuários avançados do Gemini em seus dispositivos.
Batalha de cobra, bola pulando, Gemini 2.0 ainda pode jogar assim
Quem disse que a IA só pode dar respostas secas? Com o lançamento do Gemini 2.0 Family Bucket, os internautas mal podem esperar para pregar novos truques.
Por exemplo, quer ver uma luta de cobras? Deixe o Gemini 2.0 projetar um jogo Snake usando código.

Ou o modelo Gemini Flash Thinking é o primeiro modelo de inferência a ter acesso ao YouTube e também suporta funções de pesquisa e mapas do Google.
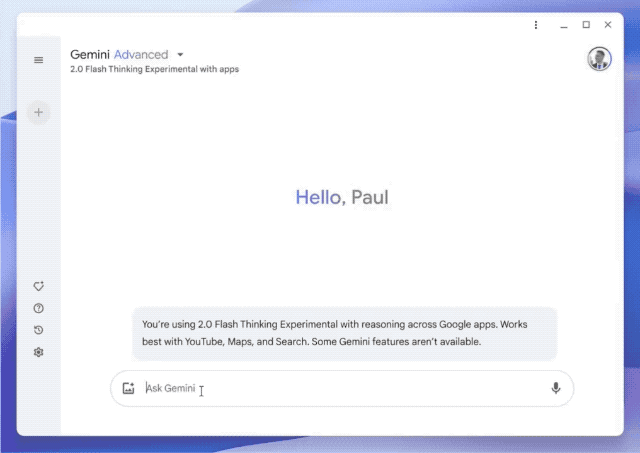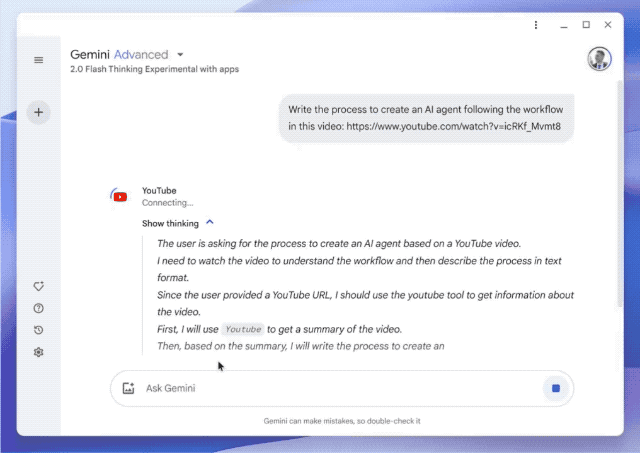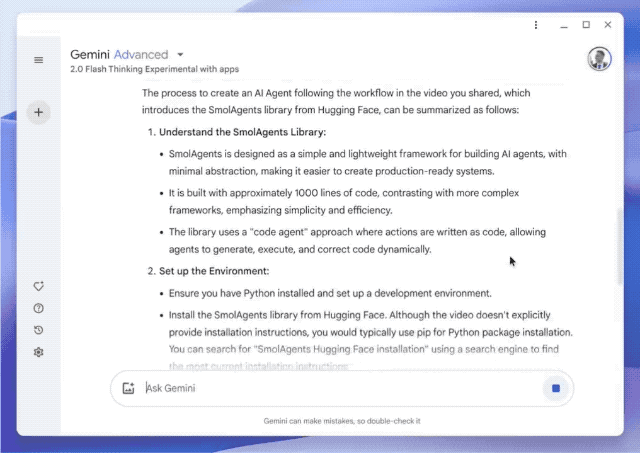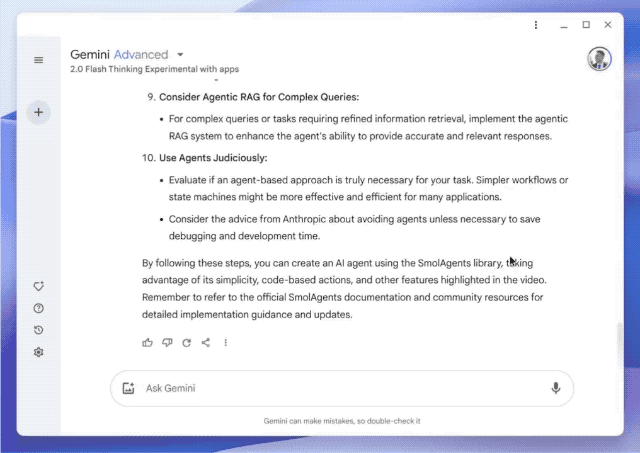
Em termos de renderização de imagem, um desenvolvedor pediu ao modelo para escrever um script usando p5.js, que gerou uma cena tridimensional contendo 100 bolas amarelas saltitantes dinâmicas. Além disso, as bolas amarelas dentro da esfera devem ser capazes de colidir umas com as outras corretamente, a esfera deve girar lentamente e permanecer sempre dentro da esfera.
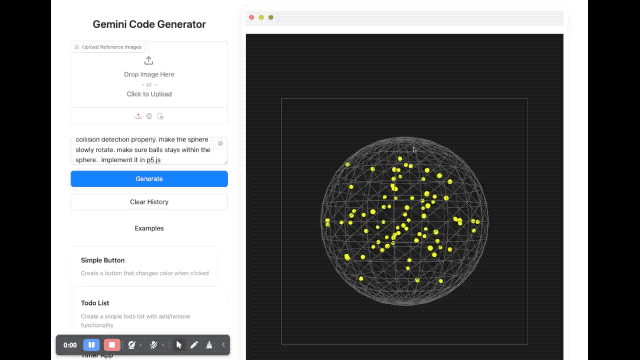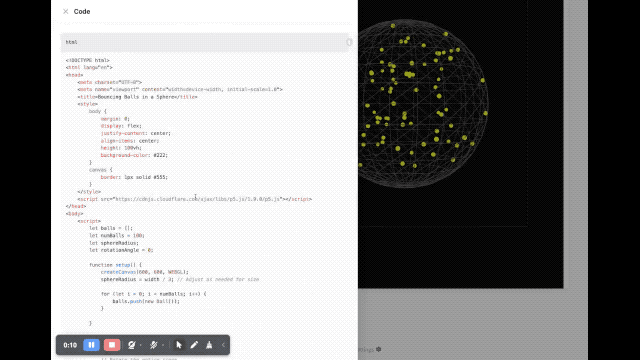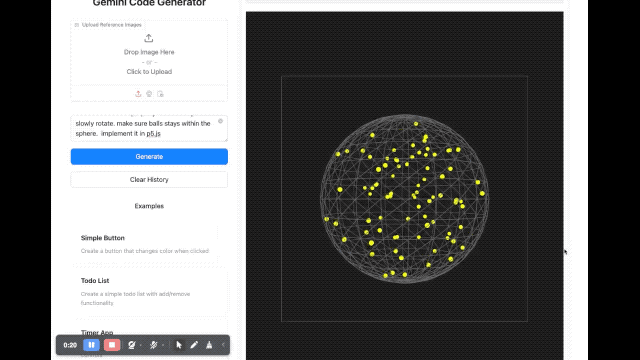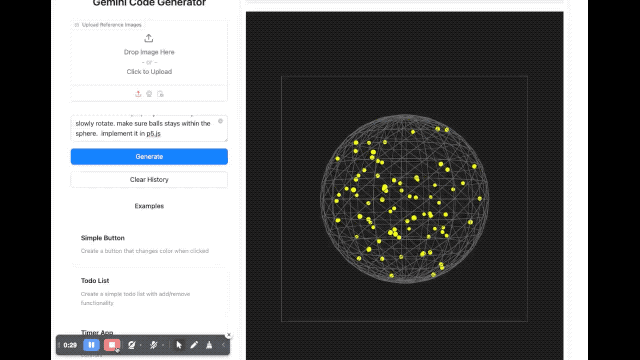
Também experimentamos brevemente vários novos modelos lançados desta vez no Google AI Studio. A velocidade de resposta desses novos modelos é bastante rápida. Quanto ao efeito, emmm, é realmente difícil de avaliar.
Enquanto Gemini flexiona seus músculos, OpenAI, que muitas vezes é um atirador de elite, também continua a exercer seus esforços.
Hoje, a OpenAI anunciou no início da manhã que a função Deep Research está totalmente aberta a todos os usuários Pro, incluindo Reino Unido, UE, Noruega, Islândia, Liechtenstein, Suíça e outras regiões. Além disso, os usuários derramaram lágrimas de inveja.
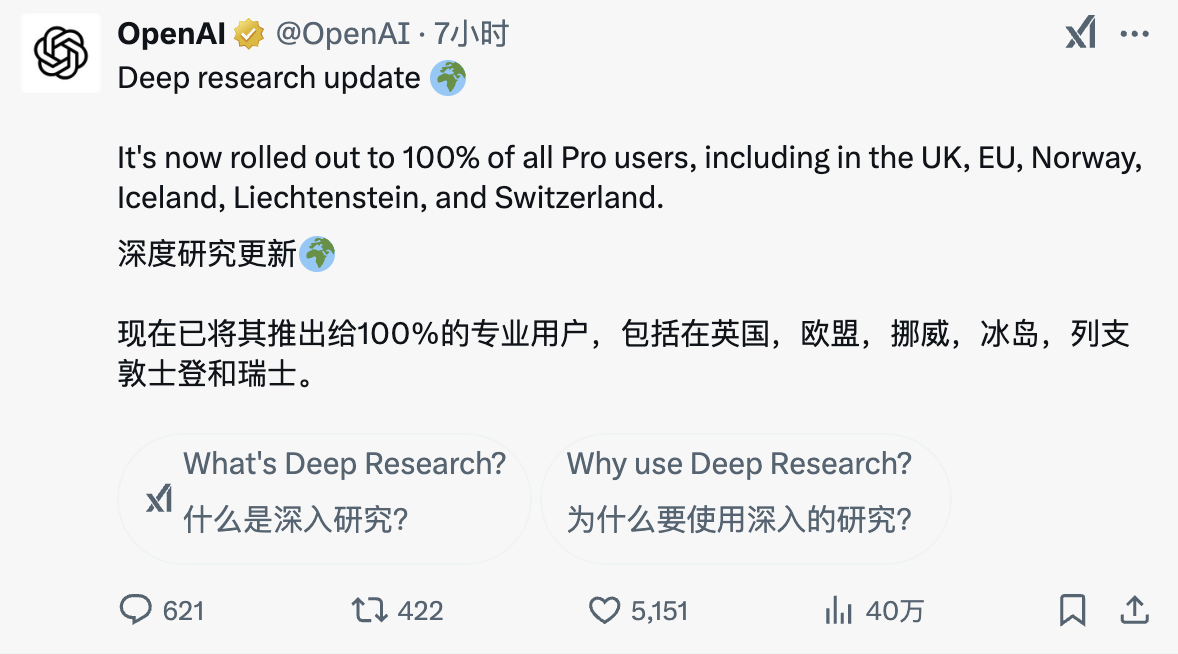
Além disso, a função de pesquisa do ChatGPT está agora aberta a todos os usuários e pode ser usada sem registro, reduzindo ainda mais o limite do usuário.
No entanto, antes de enrolar o modelo, você também pode enrolar a nomenclatura do modelo AI primeiro, seja a série Gemini ou a série GPT/o da OpenAI, à medida que novos modelos surgem um após o outro, os vários números de versão e regras de nomenclatura também são deslumbrantes.
No ano passado, quando o CEO da OpenAI, Sam Altman, foi questionado sobre a estratégia de nomenclatura dos produtos da empresa, ele também admitiu que era uma grande dor de cabeça.
Incluindo o CEO da Anthropic, Amodei, disse uma vez que, embora o método de nomenclatura de Claude parecesse bom no início, com a rápida iteração e atualização do modelo, o sistema de nomenclatura que ainda era usado também se tornou esticado.
Ele ressaltou que atualmente nenhuma empresa de IA “resolveu verdadeiramente o problema da nomenclatura” e todos estão trabalhando duro para encontrar métodos de nomenclatura mais simples e claros. Este também pode ser um consenso raro entre os gigantes da IA.
# Bem-vindo a seguir a conta pública oficial do WeChat de Aifaner: Aifaner (ID do WeChat: ifanr). Mais conteúdo interessante será fornecido a você o mais rápido possível.
