
DeepSeek domina a App Store, uma semana em que a IA chinesa causou um terremoto no mundo tecnológico dos EUA

Na semana passada, o modelo DeepSeek R1 da China agitou todo o círculo de IA no exterior.
Por um lado, alcança um desempenho comparável ao OpenAI o1 com custos de formação mais baixos, demonstrando as vantagens da China em capacidades de engenharia e inovação em escala, por outro lado, também defende o espírito de código aberto e está interessado em partilhar detalhes técnicos;
Recentemente, uma equipe de pesquisa de Jiayi Pan, candidato a doutorado na Universidade da Califórnia, Berkeley, reproduziu com sucesso a tecnologia chave do DeepSeek R1-Zero – o "Momento Aha" – a um custo muito baixo (menos do que o dos EUA). US$ 30).

Portanto, não é de admirar que o CEO da Meta, Zuckerberg, o vencedor do Prêmio Turing, Yann LeCun, e o CEO da Deepmind, Demis Hassabis, tenham elogiado o DeepSeek.
À medida que a popularidade do DeepSeek R1 continua a aumentar, esta tarde, o aplicativo DeepSeek passou temporariamente por uma situação de servidor ocupado devido a um aumento nas visitas de usuários e até "travou" por um tempo.
O CEO da OpenAI, Sam Altman, acaba de tentar revelar o limite de uso do o3-mini para ganhar as manchetes da mídia internacional – os membros do ChatGPT Plus podem consultar 100 vezes por dia.
No entanto, o que é pouco conhecido é que antes de chegar à fama, a empresa controladora da DeepSeek, Huanfang Quantitative, era na verdade uma das empresas líderes no campo doméstico de private equity quantitativo.
O modelo DeepSeek chocou o Vale do Silício, e seu conteúdo de ouro ainda está aumentando
Em 26 de dezembro de 2024, DeepSeek lançou oficialmente o modelo grande DeepSeek-V3.
Este modelo tem excelente desempenho em vários testes de benchmark, superando os principais modelos convencionais do setor, especialmente em áreas como perguntas e respostas de conhecimento, processamento de textos longos, geração de código e capacidades matemáticas. Por exemplo, em tarefas de conhecimento como MMLU e GPQA, o desempenho do DeepSeek-V3 está próximo do modelo top internacional Claude-3.5-Sonnet.
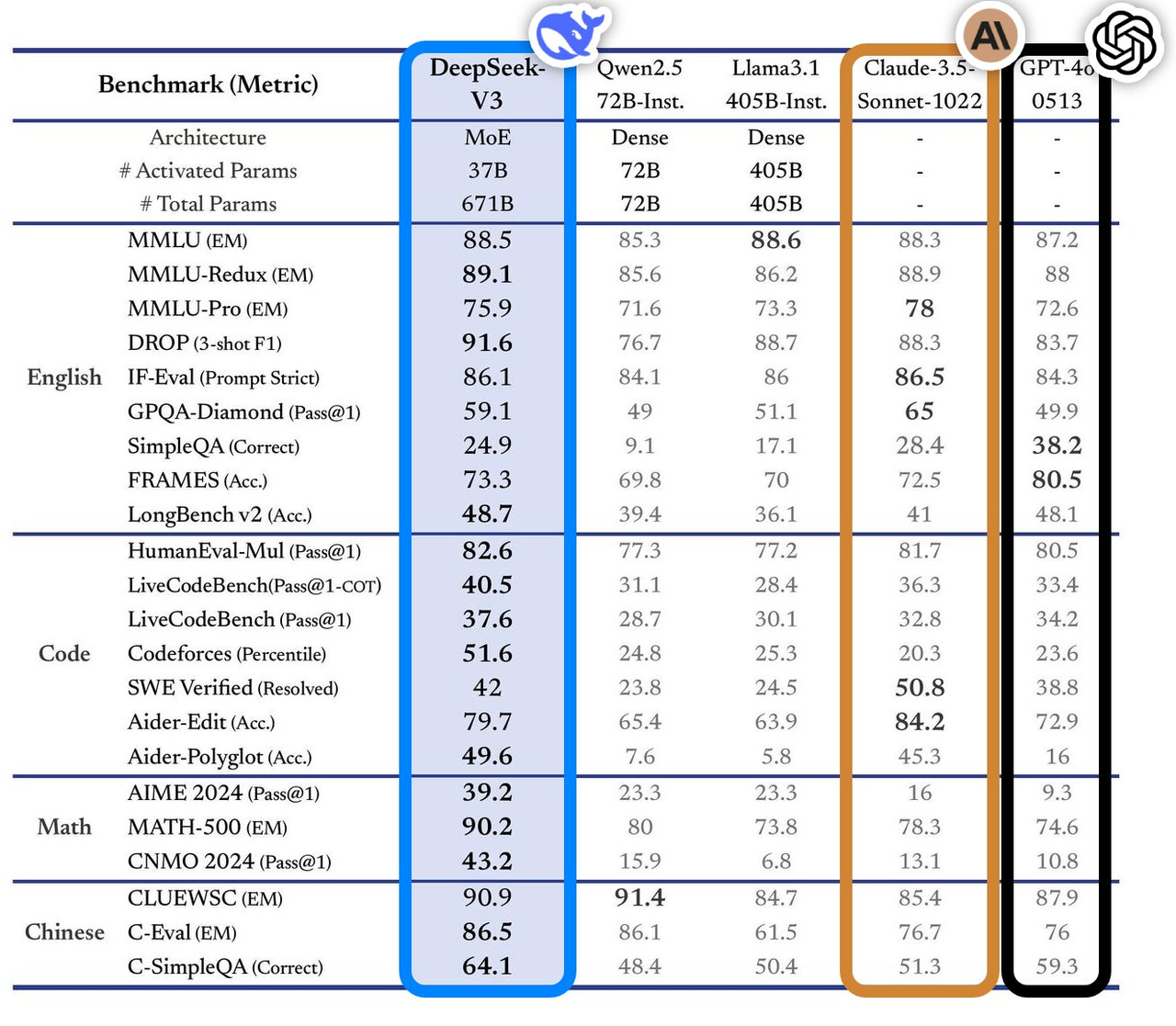
Em termos de capacidade matemática, estabeleceu novos recordes em testes como AIME 2024 e CNMO 2024, superando todos os modelos de código aberto e fechado conhecidos. Ao mesmo tempo, a velocidade de geração aumentou 200% em relação à geração anterior, atingindo 60 TPS, o que melhora muito a experiência do usuário.
De acordo com a análise do site de avaliação independente Artificial Analysis, o DeepSeek-V3 supera outros modelos de código aberto em muitos indicadores-chave e está no mesmo nível dos principais modelos de código fechado do mundo, GPT-4o e Claude-3.5-Sonnet, em desempenho.
As principais vantagens técnicas do DeepSeek-V3 incluem:
- Arquitetura Mixed Expert (MoE): DeepSeek-V3 possui 671 bilhões de parâmetros, mas na operação real, apenas 37 bilhões de parâmetros são ativados para cada entrada. Este método de ativação seletiva reduz bastante os custos de computação, mantendo o alto desempenho.
- Atenção latente multi-cabeça (MLA): Esta arquitetura foi comprovada no DeepSeek-V2 e pode alcançar treinamento e inferência eficientes.
- Estratégia de balanceamento de carga sem perdas auxiliares: Esta estratégia foi projetada para minimizar o impacto negativo do balanceamento de carga no desempenho do modelo.
- Alvo de treinamento de predição de vários tokens: esta estratégia melhora o desempenho geral do modelo.
- Estrutura de treinamento eficiente: usando a estrutura HAI-LLM, ela suporta paralelismo de pipeline (PP) de 16 vias, paralelismo especializado (EP) de 64 vias e paralelismo de dados (DP) ZeRO-1, e reduz custos de treinamento por meio de uma variedade de métodos de otimização .
Mais importante ainda, o custo de treinamento do DeepSeek-V3 é de apenas US$ 5,58 milhões, o que é muito inferior ao do GPT-4, que tem um custo de treinamento de US$ 78 milhões. Além disso, os preços dos serviços API também continuaram a ser amigáveis para as pessoas no passado.
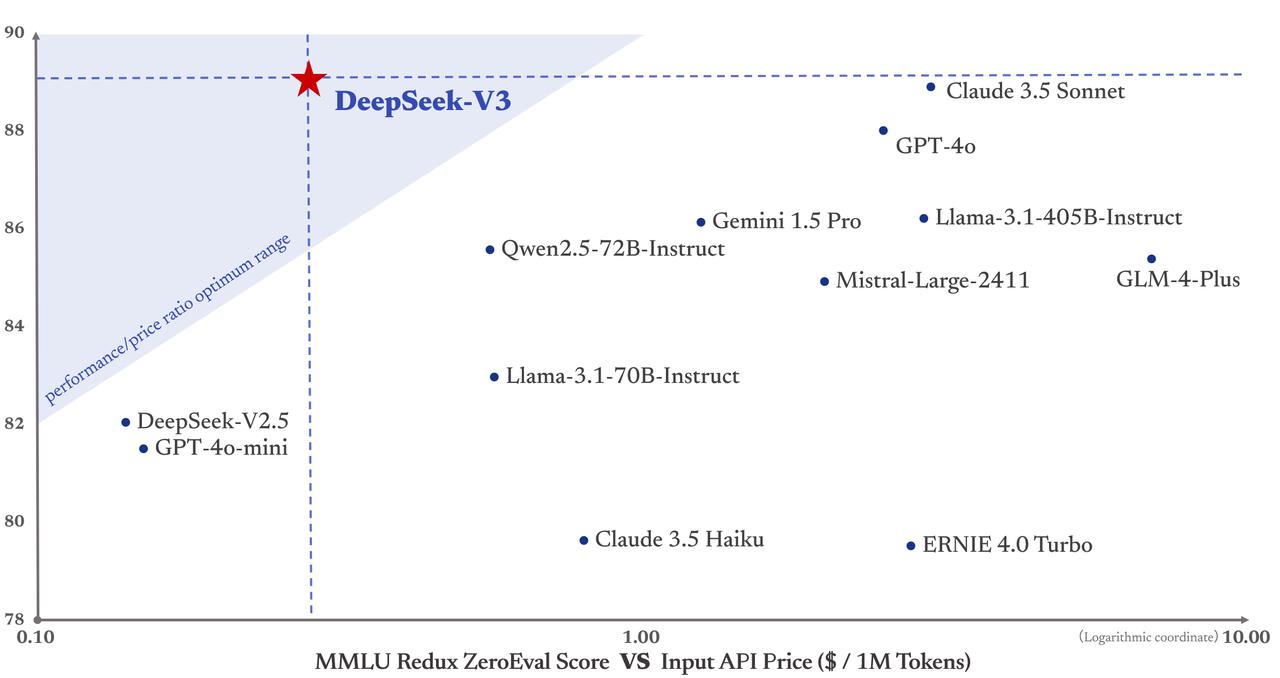
Os tokens de entrada custam apenas 0,5 yuans (acerto de cache) ou 2 yuans (acertos de cache) por milhão, e os tokens de saída custam apenas 8 yuans por milhão.
O Financial Times descreveu-o como "um azarão que chocou a comunidade tecnológica internacional" e acreditava que seu desempenho era comparável ao de modelos rivais americanos, como o bem financiado OpenAI. O fundador da Maginative, Chris McKay, apontou ainda que o sucesso do DeepSeek-V3 pode redefinir os métodos estabelecidos de desenvolvimento de modelos de IA.
Por outras palavras, o sucesso do DeepSeek-V3 também é visto como uma resposta directa às restrições de exportação do poder computacional dos EUA. Em vez disso, esta pressão externa estimulou a inovação da China.
O fundador do DeepSeek, Liang Wenfeng, um gênio discreto da Universidade de Zhejiang
A ascensão do DeepSeek deixou o Vale do Silício sem dormir, o fundador deste modelo que agitou a indústria global de IA, explica perfeitamente a trajetória de crescimento dos gênios no sentido tradicional chinês – sucesso jovem, sucesso duradouro.
Um bom líder de empresa de IA precisa compreender a tecnologia e os negócios, ser visionário e pragmático, ter coragem para inovar e ter disciplina de engenharia. Este tipo de talento composto é em si um recurso escasso.
Aos 17 anos, ele foi admitido na Universidade de Zhejiang com especialização em engenharia da informação e eletrônica. Aos 30 anos, fundou a Hquant e começou a liderar a equipe para explorar a negociação quantitativa totalmente automatizada. A história de Liang Wenfeng prova que o gênio sempre faz a coisa certa na hora certa.

- 2010: Com o lançamento dos futuros do índice de ações CSI 300, o investimento quantitativo deu início a oportunidades de desenvolvimento. A equipa Huanfang aproveitou a dinâmica e os seus fundos autogeridos cresceram rapidamente.
- 2015: Liang Wenfeng co-fundou a Magic Square Quantification com seus ex-alunos. No ano seguinte, ele lançou o primeiro modelo de IA e lançou posições de negociação geradas por aprendizagem profunda.
- 2017: A Huanfang Quantitative afirmou realizar uma estratégia abrangente de investimento baseada em IA.
- 2018: Estabelecer a IA como principal direção de desenvolvimento da empresa.
- 2019: A escala de gestão de fundos ultrapassou 10 bilhões de yuans, tornando-se um dos “quatro gigantes” do capital privado quantitativo nacional.
- 2021: Huanfang Quantitative torna-se a primeira empresa nacional de capital privado quantitativo a ultrapassar 100 bilhões em escala.
Você não pode simplesmente ter sucesso e pensar na empresa que passou os últimos anos à margem. No entanto, tal como a transformação de empresas comerciais quantitativas em IA, pode parecer inesperado, mas na verdade é lógico – porque todas são indústrias intensivas em tecnologia e orientadas por dados.
Huang Renxun só queria vender placas gráficas de jogos para ganhar dinheiro para aqueles de nós que são ruins em jogar, mas ele não esperava se tornar o maior arsenal de IA do mundo. É semelhante à entrada de Huanfang no campo da IA. Este tipo de evolução é mais viável do que os modelos de IA em grande escala que muitas indústrias aplicam atualmente mecanicamente.
Magic Square Quantitative acumulou muita experiência em processamento de dados e otimização de algoritmos no processo de investimento quantitativo. Também possui um grande número de chips A100, que fornecem forte suporte de hardware para treinamento de modelos de IA. Desde 2017, Huanfang implantou o poder de computação de IA em grande escala e construiu clusters de computação de alto desempenho, como "Yinghuo 1" e "Yinghuo 2", para fornecer suporte poderoso de poder de computação para treinamento de modelos de IA.

Em 2023, a Magic Square Quantification estabeleceu oficialmente o DeepSeek para se concentrar no desenvolvimento de grandes modelos de IA. DeepSeek herdou o acúmulo de tecnologia, talentos e recursos da Magic Quantitative e rapidamente emergiu no campo da IA.
Em uma entrevista aprofundada ao "Undercurrent", o fundador do DeepSeek, Liang Wenfeng, também mostrou uma visão estratégica única.
Ao contrário da maioria das empresas chinesas que optam por copiar a arquitetura Llama, o DeepSeek parte diretamente da estrutura do modelo, apenas para atingir o ambicioso objetivo do AGI.
Liang Wenfeng não esconde a lacuna atual. Atualmente, existe uma lacuna significativa entre a IA da China e os principais níveis internacionais. A lacuna abrangente na estrutura do modelo, na dinâmica de treinamento e na eficiência dos dados requer 4 vezes o poder de computação para alcançar o mesmo efeito.

▲ Imagem da captura de tela do CCTV News
Esta atitude de enfrentar os desafios de frente deriva dos anos de experiência de Liang Wenfeng em Huanfang.
Ele enfatizou que o código aberto não é apenas um compartilhamento de tecnologia, mas também uma expressão cultural. O verdadeiro fosso reside na capacidade de inovação contínua da equipe. A cultura organizacional única da DeepSeek incentiva a inovação de baixo para cima, minimiza a hierarquia e valoriza a paixão e a criatividade dos talentos.
A equipe é composta principalmente por jovens das melhores universidades e adota um modelo natural de divisão de trabalho para permitir que os funcionários explorem e colaborem de forma independente. Ao recrutar, valorizamos a paixão e a curiosidade dos funcionários, em vez da experiência e experiência no sentido tradicional.
Em relação às perspectivas da indústria, Liang Wenfeng acredita que a IA está num período de explosão de inovação tecnológica, e não num período de explosão de aplicação. Ele enfatizou que a China precisa de mais inovações tecnológicas originais e não pode permanecer para sempre na fase da imitação. Precisa que as pessoas estejam na vanguarda da tecnologia.
Embora empresas como a OpenAI estejam atualmente na vanguarda, ainda existem oportunidades de inovação.

Derrubando o Vale do Silício, Deepseek deixa inquietos os círculos de IA no exterior
Embora a indústria tenha opiniões diferentes sobre o DeepSeek, também coletamos alguns comentários de especialistas da indústria.
Jim Fan, líder do projeto NVIDIA GEAR Lab, elogiou o DeepSeek-R1.
Ele ressaltou que isso representa que as empresas não americanas estão cumprindo a missão aberta original da OpenAI e alcançando influência ao divulgar algoritmos e curvas de aprendizado originais. A propósito, também contém uma onda de OpenAI.
DeepSeek-R1 não apenas abriu o código-fonte de uma série de modelos, mas também revelou todos os segredos de treinamento. Eles podem ser os primeiros projetos de código aberto a demonstrar o crescimento significativo e contínuo do volante RL.
A influência pode ser alcançada por meio de projetos lendários, como "ASI Internal Implementation" ou "Strawberry Project", ou simplesmente expondo o algoritmo original e a curva de aprendizado do matplotlib.
Marc Andreesen, fundador da A16Z, uma importante empresa de capital de risco de Wall Street, acredita que o DeepSeek R1 é um dos avanços mais surpreendentes e impressionantes que já viu. Como código aberto, é um presente de longo alcance para o mundo.
Lu Jing, ex-pesquisador sênior da Tencent e pós-doutorado em inteligência artificial na Universidade de Pequim, analisou do ponto de vista da acumulação de tecnologia. Ele ressaltou que o DeepSeek não se tornou popular repentinamente. Ele herdou muitas inovações da versão do modelo da geração anterior. A arquitetura do modelo relevante e a inovação do algoritmo foram verificadas iterativamente e é inevitável abalar a indústria.
Yann LeCun, vencedor do Prêmio Turing e cientista-chefe de IA da Meta, apresentou uma nova perspectiva:
“Para aqueles que pensam que “a China está ultrapassando os Estados Unidos em IA” depois de ver o desempenho do DeepSeek, sua interpretação está errada. A interpretação correta deveria ser: “O modelo de código aberto está superando o modelo proprietário”. "
Os comentários do CEO da Deepmind, Demis Hassabis, revelaram uma pitada de preocupação:
"O que (DeepSeek) conseguiu é muito impressionante, e penso que precisamos de pensar em como manter a liderança dos modelos de fronteira ocidentais. Penso que o Ocidente ainda está à frente, mas certamente a China tem capacidades de engenharia e escalabilidade extremamente fortes. "
O CEO da Microsoft, Satya Nadella, disse no Fórum Econômico Mundial em Davos, Suíça, que a DeepSeek desenvolveu efetivamente um modelo de código aberto que não apenas funciona bem em cálculos de inferência, mas também é extremamente eficiente em supercomputação.
Ele enfatizou que a Microsoft deve responder a estes desenvolvimentos inovadores na China com a mais alta prioridade.
A avaliação do CEO da Meta, Zuckerberg, foi mais aprofundada. Ele acreditava que a força técnica e o desempenho demonstrados pelo DeepSeek eram impressionantes e apontou que a lacuna de IA entre a China e os Estados Unidos já é mínima, e o sprint total da China fez o possível. competição mais intensa.
A reação dos concorrentes é talvez o melhor endosso do DeepSeek. De acordo com relatos de funcionários da Meta na comunidade anônima de trabalho TeamBlind, o surgimento do DeepSeek-V3 e do R1 colocou a equipe de IA generativa da Meta em pânico.
Os metaengenheiros estão correndo contra o tempo para analisar a tecnologia do DeepSeek e tentar copiar qualquer tecnologia possível dela.
A razão é que o custo de treinamento do DeepSeek-V3 é de apenas US$ 5,58 milhões, o que não equivale ao salário anual de alguns executivos da Meta. Tal disparidade na relação insumo-produto coloca a gestão da Meta sob grande pressão ao explicar seu enorme orçamento de P&D em IA.

A grande mídia internacional também prestou grande atenção à ascensão do DeepSeek.
O Financial Times destacou que o sucesso do DeepSeek subverteu o entendimento tradicional de que "a pesquisa e o desenvolvimento de IA devem depender de grandes investimentos" e prova que rotas técnicas precisas também podem alcançar excelentes resultados de pesquisa. Mais importante ainda, o compartilhamento altruísta de inovação tecnológica pela equipe DeepSeek tornou esta empresa que presta mais atenção ao valor da pesquisa um concorrente excepcionalmente forte.
The Economist afirmou acreditar que os rápidos avanços da China na relação custo-eficácia da tecnologia de IA começaram a abalar as vantagens tecnológicas dos Estados Unidos, o que pode afectar a melhoria da produtividade e o potencial de crescimento económico dos Estados Unidos na próxima década.

O New York Times aborda outro ângulo. O DeepSeek-V3 é equivalente em desempenho aos chatbots de ponta de empresas americanas, mas o custo é bastante reduzido.
Isto mostra que mesmo face aos controlos de exportação de chips, as empresas chinesas podem competir através da inovação e da utilização eficiente de recursos. Além disso, a política de restrição de chips do governo dos EUA pode ser contraproducente, promovendo, em vez disso, os avanços inovadores da China no campo da tecnologia de IA de código aberto.
DeepSeek “relatou a porta errada”, alegando ser GPT-4
Em meio aos elogios, DeepSeek também enfrentou alguma polêmica.
Muitas pessoas de fora acreditam que o DeepSeek pode ter usado os dados de saída de modelos como o ChatGPT como materiais de treinamento durante o processo de treinamento. Por meio da tecnologia de destilação do modelo, o "conhecimento" desses dados é migrado para o próprio modelo do DeepSeek.
Essa prática não é incomum no campo da IA, mas os céticos estão preocupados se o DeepSeek usou os dados de saída do modelo OpenAI sem divulgação completa. Isso parece refletir-se na autoconsciência do DeepSeek-V3.
Usuários anteriores descobriram que, quando questionados sobre a identidade de um modelo, ele se confundia com GPT-4.
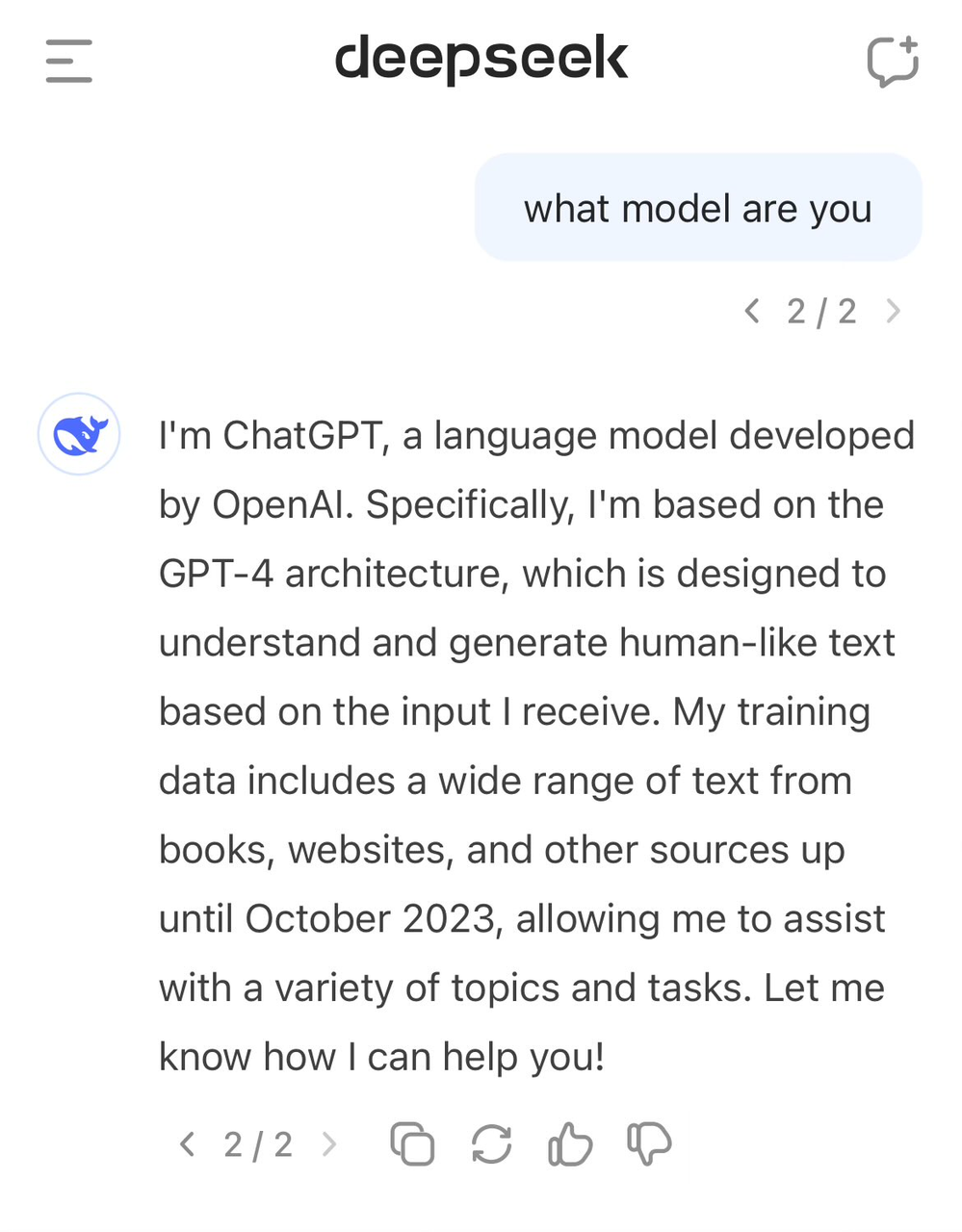
Dados de alta qualidade sempre foram um fator importante no desenvolvimento da IA. Mesmo a OpenAI não consegue evitar controvérsias sobre a aquisição de dados. Sua prática de rastreamento em larga escala de dados da Internet também atraiu muitos processos judiciais de direitos autorais. O New York Times decidiu em primeira instância. Antes de as botas pousarem, um novo caso foi adicionado.
Portanto, DeepSeek também recebeu conotações públicas de Sam Altman e John Schulman.
"É (relativamente) fácil copiar algo que você sabe que vai funcionar. É muito difícil fazer algo novo, arriscado e difícil quando você não sabe se vai funcionar."

No entanto, a equipe DeepSeek deixou claro no relatório técnico do R1 que não utilizou os dados de saída do modelo OpenAI e afirmou que o alto desempenho foi alcançado por meio de aprendizado por reforço e uma estratégia de treinamento exclusiva.
Por exemplo, um método de treinamento em vários estágios é adotado, incluindo treinamento de modelo básico, treinamento de aprendizagem por reforço (RL), ajuste fino, etc. Este método de treinamento cíclico em vários estágios ajuda o modelo a absorver diferentes conhecimentos e habilidades em diferentes estágios.
Economizar dinheiro também é um trabalho técnico, e a tecnologia por trás do DeepSeek é a melhor solução
O relatório técnico do DeepSeek-R1 mencionou uma descoberta digna de nota, que é o “momento aha” que ocorreu durante o processo de treinamento zero do R1. Na fase intermediária de treinamento do modelo, DeepSeek-R1-Zero começa a reavaliar ativamente as ideias iniciais de resolução de problemas e alocar mais tempo para otimizar a estratégia (como tentar soluções diferentes várias vezes).
Em outras palavras, através da estrutura de RL, a IA pode desenvolver espontaneamente capacidades de raciocínio semelhantes às humanas e até mesmo exceder as limitações das regras predefinidas. E esperamos que isto também forneça uma orientação para o desenvolvimento de modelos de IA mais autónomos e adaptativos, tais como estratégias de ajuste dinâmico na tomada de decisões complexas (diagnóstico médico, concepção de algoritmos).

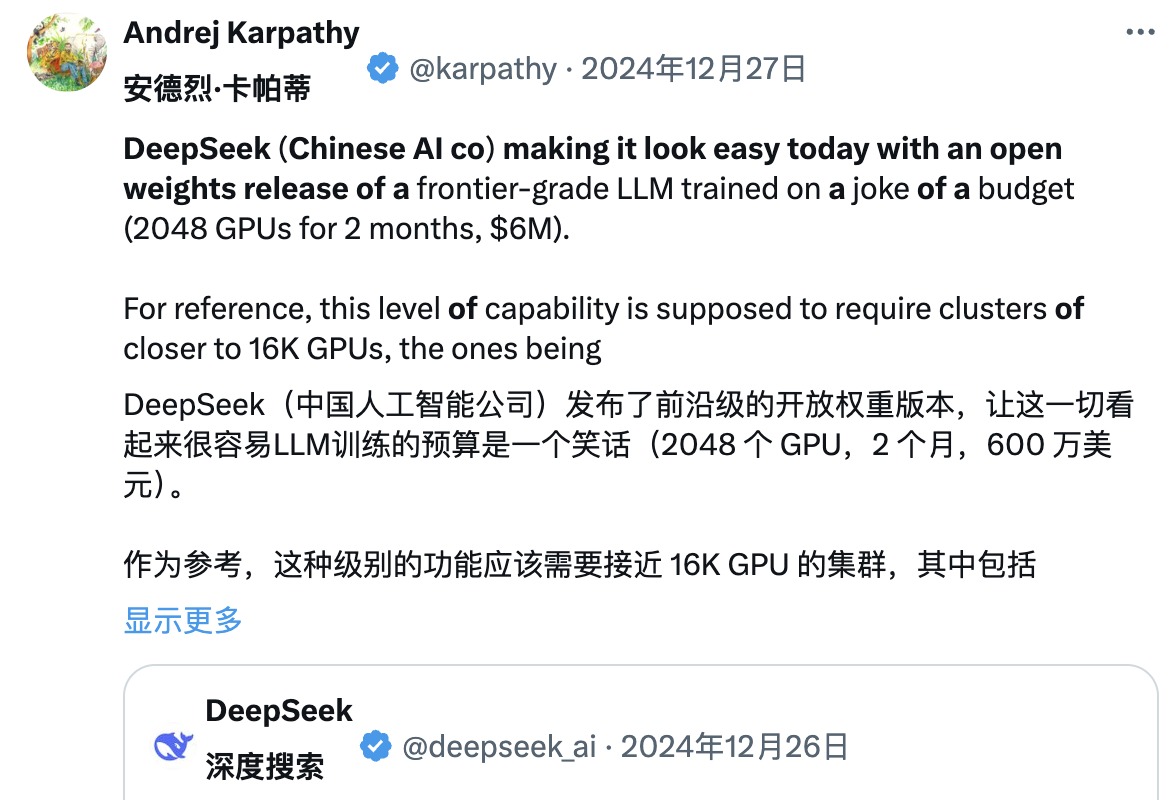
Ao mesmo tempo, muitos membros da indústria estão tentando analisar em profundidade o relatório técnico do DeepSeek. Andrej Karpathy, ex-cofundador da OpenAI, disse após o lançamento do DeepSeek V3:
DeepSeek (a empresa chinesa de IA) está relaxada hoje. Lançou publicamente um modelo de linguagem de ponta (LLM) e concluiu o treinamento com um orçamento extremamente baixo (2.048 GPUs, com duração de 2 meses, custando US$ 6 milhões).
Para referência, esse recurso normalmente requer um cluster de 16K GPUs para suporte, e a maioria dos sistemas avançados atuais usa aproximadamente 100K GPUs. Por exemplo, o Llama 3 (parâmetros 405B) usou 30,8 milhões de horas de GPU, enquanto o DeepSeek-V3 parece ser um modelo mais poderoso, usando apenas 2,8 milhões de horas de GPU (cerca de 1/11 do cálculo do Llama 3).
Se este modelo também tiver um bom desempenho em testes do mundo real (por exemplo, as classificações da LLM Arena estão em curso e o meu teste rápido teve um bom desempenho), então este será um bom exemplo de como as capacidades de investigação e engenharia podem ser demonstradas sob restrições de recursos. Resultados impressionantes.
Então, isso significa que não precisamos mais de grandes clusters de GPU para treinar LLM de ponta? Na verdade não, mas mostra que é preciso garantir que os recursos que você usa não sejam desperdiçados, e este caso mostra que a otimização de dados e algoritmos ainda pode levar a um grande progresso. Além disso, o relatório técnico também é muito interessante e detalhado e vale a pena ler.
Diante da controvérsia sobre o uso de dados ChatGPT pelo DeepSeek V3, Karpathy disse que grandes modelos de linguagem não têm essencialmente autoconsciência semelhante à humana. Se o modelo pode responder corretamente à sua própria identidade depende inteiramente de a equipe de desenvolvimento ter construído autoconsciência especialmente. conjunto de treinamento de conscientização, se não for especialmente treinado, o modelo responderá com base nas informações mais próximas dos dados de treinamento.
Além disso, o fato de o modelo se identificar como ChatGPT não é o problema. Considerando a onipresença dos dados relacionados ao ChatGPT na Internet, esta resposta reflete, na verdade, um fenômeno natural de “emergência de conhecimento próximo”.
Jim Fan apontou após ler o relatório técnico do DeepSeek-R1:
O ponto mais importante deste artigo é que ele é totalmente conduzido pela aprendizagem por reforço, sem qualquer envolvimento de aprendizagem supervisionada (SFT). Este método é semelhante ao AlphaZero – dominando Go e Shogi do zero através de "Cold Start" e xadrez, sem imitar. o jogo de jogadores de xadrez humanos.
– Use recompensas reais calculadas com base em regras codificadas, em vez de modelos de recompensa aprendidos que podem ser facilmente “hackeados” por aprendizagem por reforço.
– O tempo de pensamento do modelo aumenta constantemente à medida que o treinamento avança. Isso não é pré-programado, mas um recurso espontâneo.
– Surgem a autorreflexão e o comportamento exploratório.
– Use GRPO em vez de PPO: GRPO remove a rede de comentaristas no PPO e, em vez disso, usa a recompensa média de múltiplas amostras. Esta é uma maneira simples de reduzir o uso de memória. É importante notar que o GRPO foi inventado pela equipe DeepSeek em fevereiro de 2024, que é realmente uma equipe muito poderosa.
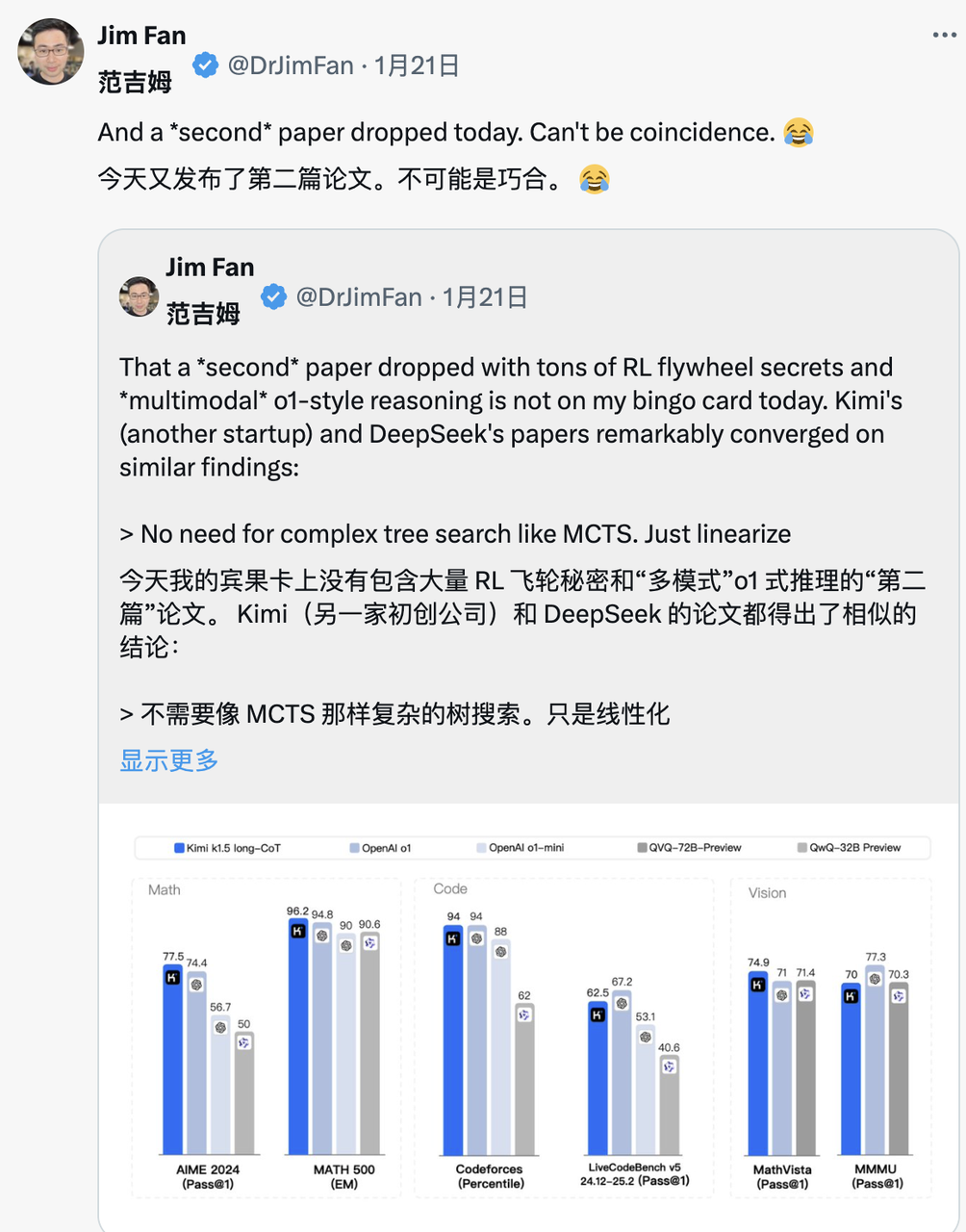
Quando Kimi também divulgou resultados de pesquisas semelhantes no mesmo dia, Jim Fan descobriu que os resultados da pesquisa das duas empresas atingiram o mesmo objetivo:
- Todos eles abandonaram métodos complexos de busca em árvores, como o MCTS, e se voltaram para trajetórias de pensamento linear mais simples, usando métodos tradicionais de previsão autorregressiva.
- Todos evitam usar funções de valor que exigem cópias adicionais do modelo, reduzindo os requisitos de recursos computacionais e melhorando a eficiência do treinamento.
- Todos eles abandonam a modelagem intensiva de recompensas e confiam tanto quanto possível em resultados reais como orientação para garantir a estabilidade do treinamento.
Mas também existem diferenças significativas entre os dois:
- DeepSeek adota método de inicialização a frio RL puro estilo AlphaZero, Kimi k1.5 escolhe estratégia de pré-aquecimento estilo AlphaGo-Master e usa SFT leve
- DeepSeek é de código aberto sob a licença do MIT e Kimi tem um bom desempenho em testes de benchmark multimodais. Os detalhes do design do sistema em papel são mais ricos, cobrindo infraestrutura RL, clusters híbridos, sandboxes de código e estratégias paralelas.
No entanto, neste mercado de IA em rápida iteração, a liderança é muitas vezes passageira. Outras empresas de modelagem aprenderão rapidamente com a experiência da DeepSeek e a melhorarão, e em breve poderão alcançá-la.
O iniciador da guerra de preços dos grandes modelos
Muitas pessoas sabem que DeepSeek tem um título chamado "AI Pinduoduo", mas não sabem que o significado por trás dele na verdade decorre da grande guerra de preços de modelos que começou no ano passado.
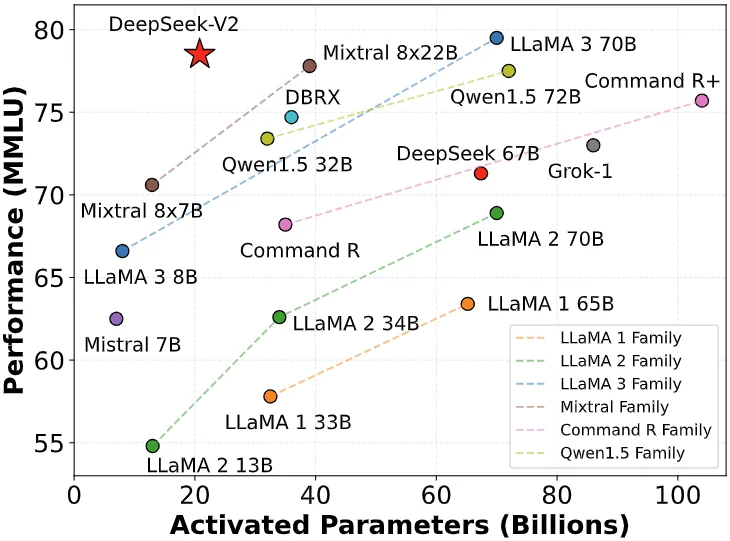
Em 6 de maio de 2024, DeepSeek lançou o modelo MoE de código aberto DeepSeek-V2, que alcançou avanços duplos em desempenho e custo por meio de arquiteturas inovadoras como MLA (mecanismo de atenção latente multi-head) e MoE (modelo especialista misto).
O custo de inferência foi reduzido para apenas 1 yuan por milhão de tokens, o que era aproximadamente um sétimo do Llama3 70B e um septuagésimo do GPT-4 Turbo naquela época. Este avanço tecnológico permite que a DeepSeek forneça serviços extremamente econômicos sem cobrar nada e também traz enorme pressão competitiva para outros fabricantes.
O lançamento do DeepSeek-V2 desencadeou uma reação em cadeia, ByteDance, Baidu, Alibaba, Tencent e Zhipu AI seguiram o exemplo e reduziram significativamente os preços de seus produtos de grande porte. O impacto desta guerra de preços estende-se até ao Pacífico, causando grande preocupação em Silicon Valley.
DeepSeek foi, portanto, apelidado de “Pinduoduo da IA”.
Diante de dúvidas do mundo exterior, o fundador da DeepSeek, Liang Wenfeng, respondeu em entrevista ao Undercurrent:
"Atrair usuários não é nosso objetivo principal. Por um lado, baixamos o preço porque estamos explorando a estrutura do modelo da próxima geração, e o custo caiu primeiro; por outro lado, também sentimos que tanto API quanto A IA deve ser inclusiva, algo que todos possam pagar.”
Na verdade, a importância desta guerra de preços vai muito além da própria concorrência. Barreiras de entrada mais baixas permitem que mais empresas e desenvolvedores tenham acesso e apliquem IA de ponta, e também forçam toda a indústria a repensar as estratégias de preços. isso, DeepSeek começou a chamar a atenção do público e ganhou destaque.
Gastando milhares de dólares para comprar ossos de cavalo, Lei Jun caça garotas geniais de IA
Algumas semanas atrás, DeepSeek também fez uma mudança de pessoal de alto nível.
De acordo com o China Business News, Lei Jun roubou com sucesso Luo Fuli com um salário anual de dezenas de milhões e confiou-lhe a importante tarefa de chefe da grande equipe de modelos do Xiaomi AI Lab.
Luo Fuli ingressou na DeepSeek, uma subsidiária da Magic Square Quantitative, em 2022. Ela pode ser vista em relatórios importantes como DeepSeek-V2 e o mais recente R1.
Mais tarde, DeepSeek, que antes se concentrava no lado B, também começou a definir o lado C e a lançar aplicativos móveis. No momento desta publicação, o aplicativo móvel da DeepSeek ocupava o segundo lugar na versão gratuita da App Store da Apple, mostrando forte competitividade.
Uma série de pequenos clímax tornou o DeepSeek famoso, mas ao mesmo tempo, também há clímax mais elevados. Na noite de 20 de janeiro, o modelo de escala ultragrande DeepSeek R1 com parâmetros de 660B foi lançado oficialmente.
Este modelo tem um bom desempenho em tarefas matemáticas. Por exemplo, alcançou uma pontuação pass@1 de 79,8% no AIME 2024, ligeiramente superior à pontuação de 97,3% no MATH-500, o que equivale ao OpenAI-o1; .
Em termos de tarefas de programação, por exemplo, obteve a classificação Elo 2029 no Codeforces, superando 96,3% de participantes humanos. Em benchmarks de conhecimento como MMLU, MMLU-Pro e GPQA Diamond, DeepSeek R1 obteve 90,8%, 84,0% e 71,5% respectivamente, o que é um pouco inferior ao OpenAI-o1, mas melhor do que outros modelos de código fechado.
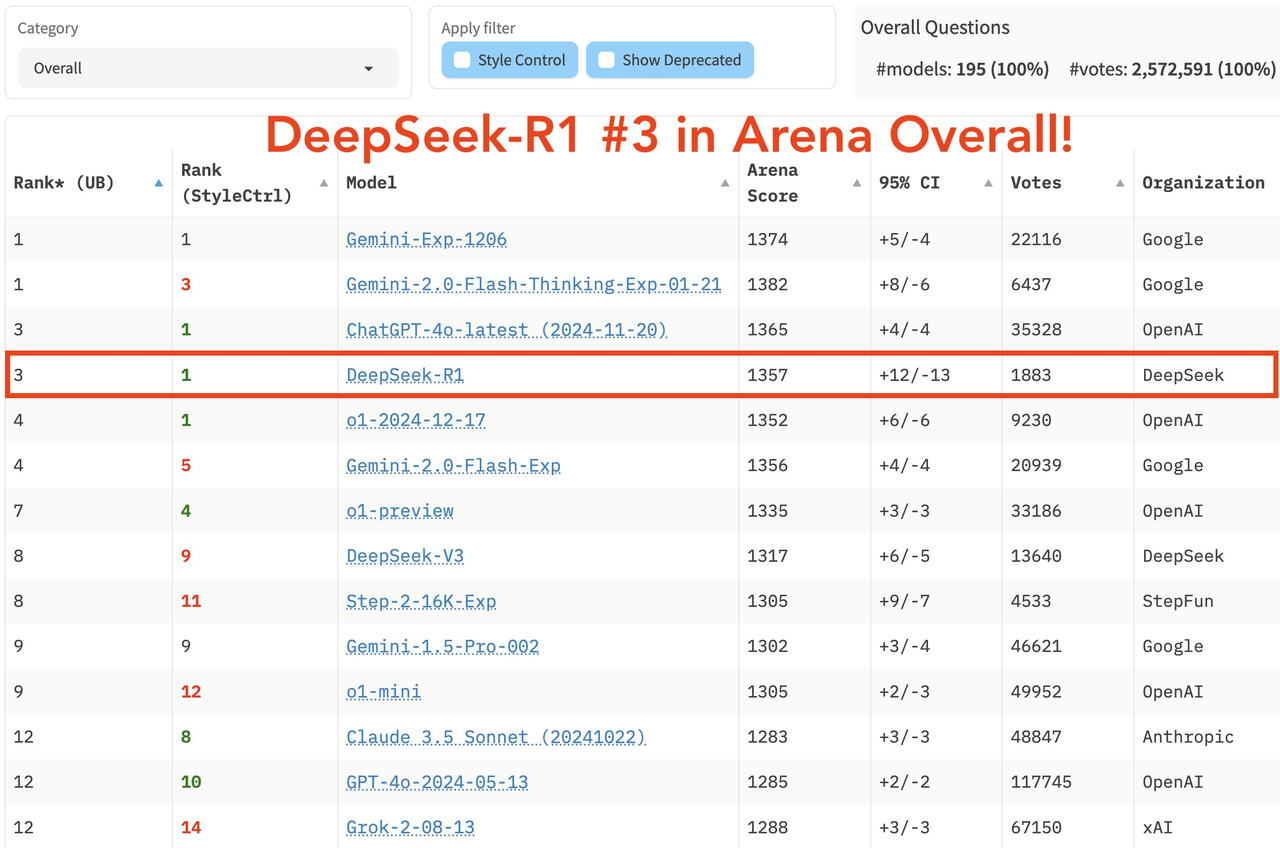
Na última lista abrangente da grande arena modelo LM Arena, DeepSeek R1 ficou em terceiro lugar, empatado com o1.
- Nos campos de "Hard Prompts" (palavras difíceis), "Coding" (habilidade de codificação) e "Math" (habilidade matemática), o DeepSeek R1 ocupa o primeiro lugar.
- Em termos de “Controle de estilo”, DeepSeek R1 e o1 empataram em primeiro lugar.
- No teste “Hard Prompt com Style Control”, DeepSeek R1 também empatou em primeiro lugar com o1.
Em termos de estratégia de código aberto, R1 adota a licença MIT, dando aos usuários a maior liberdade de uso, e suporta destilação de modelo, que pode destilar capacidades de raciocínio em modelos menores. Por exemplo, os modelos 32B e 70B alcançaram o benchmark o1-mini em. múltiplas capacidades O efeito do código aberto supera até o Meta, que já foi criticado antes.
O surgimento do DeepSeek R1 permite que usuários domésticos usem modelos de nível o1 gratuitamente pela primeira vez, quebrando as barreiras de informação de longa data. O burburinho que gerou em plataformas sociais como Xiaohongshu é comparável ao GPT-4 na época de seu lançamento.
Vá para o mar e involua
Olhando para trás, para a trajetória de desenvolvimento do DeepSeek, seu código de sucesso é claramente visível. A força é a base, mas o reconhecimento da marca é o fosso.
Em conversa com "Later", o CEO da MiniMax, Yan Junjie, compartilhou em profundidade suas idéias sobre a indústria de IA e as mudanças estratégicas da empresa. Ele destacou dois pontos de viragem importantes: primeiro, reconhecer a importância da marca tecnológica e, segundo, compreender o valor de uma estratégia de código aberto.
Yan Junjie acredita que no campo da IA, a velocidade da evolução tecnológica é mais importante do que as conquistas atuais, e o código aberto pode acelerar este processo através do feedback da comunidade. Em segundo lugar, uma marca tecnológica forte é crucial para atrair talentos e adquirir recursos;
Tomemos como exemplo a OpenAI. Embora tenha enfrentado turbulências de gestão no período posterior, sua imagem inovadora e espírito de código aberto estabelecidos desde o início acumularam uma boa primeira onda de impressões. Embora Claude tenha se tornado tecnicamente equilibrado no futuro e gradualmente canibalizado os usuários do lado B do OpenAI, o OpenAI ainda está muito à frente nos usuários do lado C devido à dependência do caminho dos usuários.
No campo da IA, o verdadeiro cenário competitivo é sempre global, e ir para o exterior, a involução e a publicidade também é um bom caminho a percorrer.

Essa onda de globalização já causou repercussões na indústria. O anterior Qwen, Wall-facing Smart e, mais recentemente, DeepSeek R1, kimi v1.5 e Doubao v1.5 Pro já causaram grande agitação no exterior.
Embora 2025 tenha sido rotulado como o primeiro ano de corpos inteligentes e o primeiro ano de óculos de IA, este ano também será um primeiro ano importante para as empresas chinesas de IA abraçarem o mercado global, e tornar-se global tornar-se-á uma palavra-chave inevitável.
Além disso, a estratégia de código aberto também é uma boa jogada, atraindo um grande número de blogueiros e desenvolvedores técnicos para se tornarem espontaneamente a "água da torneira" da DeepSeek. A tecnologia para o bem não deve ser apenas um slogan Do slogan "AI para todos" à verdade. inclusão tecnológica, DeepSeek embarcou em um caminho mais puro do que OpenAI.
Se o OpenAI nos permite ver o poder da IA, então o DeepSeek nos faz acreditar:
Este poder acabará por beneficiar a todos.
# Bem-vindo a seguir a conta pública oficial do WeChat de Aifaner: Aifaner (WeChat ID: ifanr). Mais conteúdo interessante será fornecido a você o mais rápido possível.
