
Morning Post|Revelado que o iPad pode ter mais funções semelhantes às do Mac/Liu Qiangdong respondeu ao bombardeio de Meituan: sem guerra de palavras/Ultraman: ChatGPT não é AGI


Fontes dizem que a Apple planeja fazer o iPad funcionar mais como o Mac

As vendas nacionais de eletrodomésticos ultrapassaram 100 milhões de unidades

Os Estados Unidos anunciam isenções de “tarifas recíprocas” sobre muitos produtos, incluindo chips, laptops e smartphones

OpenAI anuncia que lançará vários novos produtos esta semana

Liu Qiangdong respondeu ao bombardeio de Meituan: Sem guerra de palavras

Um modelo misterioso suspeito de ser “GPT-4.1” está online

GAC se une a Didi para anunciar modelo de direção autônoma L4


Ex-funcionários da OpenAI apoiam o processo de Musk e se opõem a se tornar uma empresa lucrativa

CEO da Maserati responde a "ser vendido": a empresa-mãe continua firmemente apoiando

A nova empresa do cofundador da OpenAI está avaliada em 230 bilhões de yuans
CEO da OpenAI: ChatGPT não é AGI

Yu Chengdong anuncia o aparecimento dos novos óculos inteligentes da Huawei

Lançada versão web do OPPO Xiaobu Assistant

O modelo de raciocínio de código matemático de código aberto mais poderoso de Kunlun Wanwei

Telefone real OnePlus 13T exposto

É relatado que o Android WeChat Moments Grey testa o compartilhamento de fotos ao vivo

Fontes dizem que a Apple planeja fazer o iPad funcionar mais como o Mac

De acordo com o repórter da Bloomberg Mark Gurman, a Apple não apenas reformulará o estilo de design de seu sistema operacional este ano, mas também adicionará mais novos recursos semelhantes ao macOS ao iPadOS 19.
Por muito tempo, um grande número de usuários relatou que o desempenho do hardware do iPad está muito à frente do software, e o objetivo da Apple é mudar esse status quo embaraçoso. O iPadOS 19 se concentrará em atualizações de produtividade, multitarefa e gerenciamento de janelas de aplicativos, fazendo com que o iPad funcione mais como um Mac.
Além das mudanças no sistema, a forma do produto iPad também pode trazer inovação. De acordo com relatórios anteriores do analista Jeff Pu, a Apple está desenvolvendo um dispositivo dobrável com tamanho aproximado de 18,8 polegadas, que deverá iniciar a produção em massa no segundo semestre de 2026 junto com o iPhone dobrável de 8 polegadas.
Quanto ao posicionamento deste dispositivo dobrável de grande porte, alguns analistas acreditam que será um dispositivo híbrido entre um MacBook e um iPad compatível com macOS, enquanto outros acreditam que será um iPad dobrável.
Mas seja um iPhone dobrável ou um iPad dobrável, eles não são mais os produtos da próxima geração que mais preocupam o CEO da Apple, Tim Cook. É relatado que Tim considerava os óculos inteligentes AR a principal prioridade da empresa e seu objetivo é construir um produto líder do setor antes da Meta. A notícia também revelou o sucessor do headset Apple Vision Pro, que pode incluir produtos em duas direções:
- É mais leve e mais barato que o atual Vision Pro e espera-se que use o próximo processador M5. Pode não mais buscar uma experiência ampla e abrangente.
- Óculos de realidade aumentada usados com Mac, mas usando as mesmas lentes opacas do Vision Pro, com foco em "latência ultrabaixa", não apenas permitem que os usuários transmitam conteúdo de mídia no Mac, mas também se conectem a alguns aplicativos de nível profissional e empresarial, mas é um desafio criar uma solução totalmente sem fio.
Além de fones de ouvido e óculos com tecnologia AR, a Apple também desenvolve produtos de óculos inteligentes semelhantes ao Ray-Ban Meta, equipados com câmeras e microfones, conectados à Siri e inteligência visual, e sem funções de display. No entanto, a Bloomberg destacou que devido à rígida política de privacidade da Apple e à sua tendência de encorajar a filmagem com iPhones, a Apple está discutindo internamente se permitirá que óculos inteligentes capturem conteúdo.

As vendas nacionais de eletrodomésticos ultrapassaram 100 milhões de unidades
De acordo com a Agência de Notícias Xinhua, até 10 de abril, os consumidores chineses compraram um total de 100,35 milhões de eletrodomésticos para troca.
Em 2025, a política de troca de eletrodomésticos centra-se no "aumento da cobertura e modernização para beneficiar as pessoas", aumentando os tipos de eletrodomésticos subsidiados da categoria "8+N" para a categoria "12+N", aumentando o número de aparelhos de ar condicionado subsidiados por pessoa para 3, e otimizando ainda mais o âmbito dos subsídios e dos processos políticos. Até agora, os governos locais organizaram mais de 7.000 atividades para promover o consumo de eletrodomésticos e estão planeadas cerca de 30.000 atividades para todo o ano.
Além disso, as principais empresas de eletrodomésticos e plataformas de comércio eletrónico participam ativamente na troca de eletrodomésticos antigos em vários locais. Associações como a Associação de Eletrodomésticos da China organizam empresas para lançar novos produtos verdes inteligentes, formular padrões de grupo relevantes e recomendar produtos de alta qualidade aos consumidores.
Segundo relatos, na próxima etapa, o Ministério do Comércio orientará diversas localidades para aumentarem ainda mais os seus esforços, otimizarem os procedimentos operacionais, promoverem a implementação da política de troca de eletrodomésticos e alcançarem maiores resultados.
Os Estados Unidos anunciam isenções de “tarifas recíprocas” sobre muitos produtos, incluindo chips, laptops e smartphones
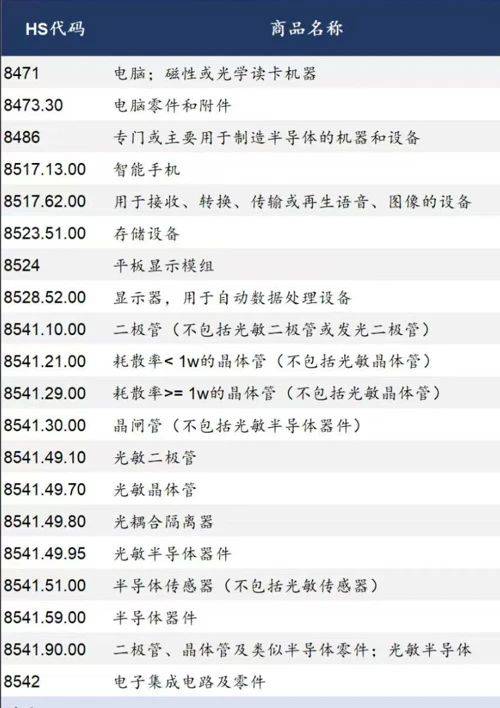
De acordo com o Global Times, a Alfândega e Proteção de Fronteiras dos EUA anunciou recentemente que o governo federal dos EUA concordou em isentar produtos eletrônicos como smartphones, computadores e chips das chamadas “tarifas recíprocas”.
Documentos divulgados pela Alfândega e Proteção de Fronteiras mostram que os produtos estão excluídos das chamadas “tarifas recíprocas” impostas pelo governo aos parceiros comerciais. O documento mostra que os produtos isentos se aplicam a produtos eletrônicos que entram nos Estados Unidos após 5 de abril, e podem ser solicitados reembolsos para “tarifas recíprocas” já pagas.
A Bloomberg informou que esta medida pode aliviar até certo ponto a pressão dos aumentos de preços enfrentados pelos consumidores americanos, ao mesmo tempo que beneficia gigantes da eletrónica, incluindo Apple e Samsung Electronics.
Há poucos dias, o secretário de Comércio dos EUA, Howard Lutnick, disse numa entrevista à ABC TV que as isenções tarifárias recentemente implementadas pela administração Trump sobre smartphones, computadores e outros produtos eletrónicos são apenas medidas temporárias. As tarifas sobre semicondutores e produtos electrónicos serão implementadas dentro de um mês, enquanto as tarifas sobre produtos farmacêuticos deverão ser implementadas dentro de um ou dois meses. Quando o repórter perguntou se o iPhone também estava incluído, Lutni disse que também estaria incluído.
Além disso, segundo a Bloomberg, a política tarifária para o transporte de pequenas encomendas também foi ajustada simultaneamente. Anteriormente, o governo dos EUA planeava eliminar a isenção fiscal para pacotes pequenos no valor de 800 dólares ou menos, especialmente para pacotes chineses. Hoje, a mais recente política de isenção dá continuidade à redução tarifária para pequenas encomendas, garantindo que estas encomendas fiquem temporariamente isentas do impacto de impostos e taxas elevados.
OpenAI anuncia que lançará vários novos produtos esta semana
Esta manhã, o CEO da OpenAI, Sam Altman, anunciou que a partir de amanhã, a empresa lançará uma série de produtos interessantes na próxima semana.
Recentemente, Altman disse em resposta aos internautas que o3 e o4-mini serão lançados em breve. De acordo com o The Verge, a OpenAI lançará a série de modelos GPT-4.1 na próxima semana, incluindo versões menores do GPT-4.1 mini e nano. Pessoas familiarizadas com o assunto revelaram que a OpenAI está prestes a lançar uma série de novos modelos de IA e disseram que o GPT-4.1 será uma versão melhorada do modelo multimodal GPT-4o.
De acordo com o engenheiro de IA Tibor Blaho, ao vasculhar a página do ChatGPT, ele descobriu que informações relacionadas a o4 mini, o4 mini high e o3 apareciam no código. The Verge também afirmou que as minisséries o3 e o4 serão lançadas na próxima semana, a menos que a OpenAI ajuste seu plano de lançamento. A OpenAI também realizou uma sessão de escuta de desenvolvedores em pequena escala no último sábado, principalmente para obter feedback sobre o novo modelo da OpenAI que será de código aberto.
Além disso, a CFO da OpenAI, Sarah Friar, revelou em uma entrevista recente que a OpenAI está desenvolvendo um produto de programação de agente superpoderoso chamado “A-SWE”. Comparado com os assistentes de IA de desenvolvimento tradicionais, o A-SWE pode construir aplicativos, lidar com solicitações pull, realizar garantia de qualidade, corrigir bugs e escrever documentação.
Vale ressaltar que a OpenAI atualizou suas regras de API. No futuro, o acesso aos grandes modelos mais recentes de OpenAI exigirá um ID verificado (ou seja, um ID emitido pelo governo de um dos países/regiões apoiados pelo OpenAI, e um ID só pode verificar uma organização a cada 90 dias). A não aprovação na verificação afetará o uso do modelo.
Liu Qiangdong respondeu ao bombardeio de Meituan: Sem guerra de palavras
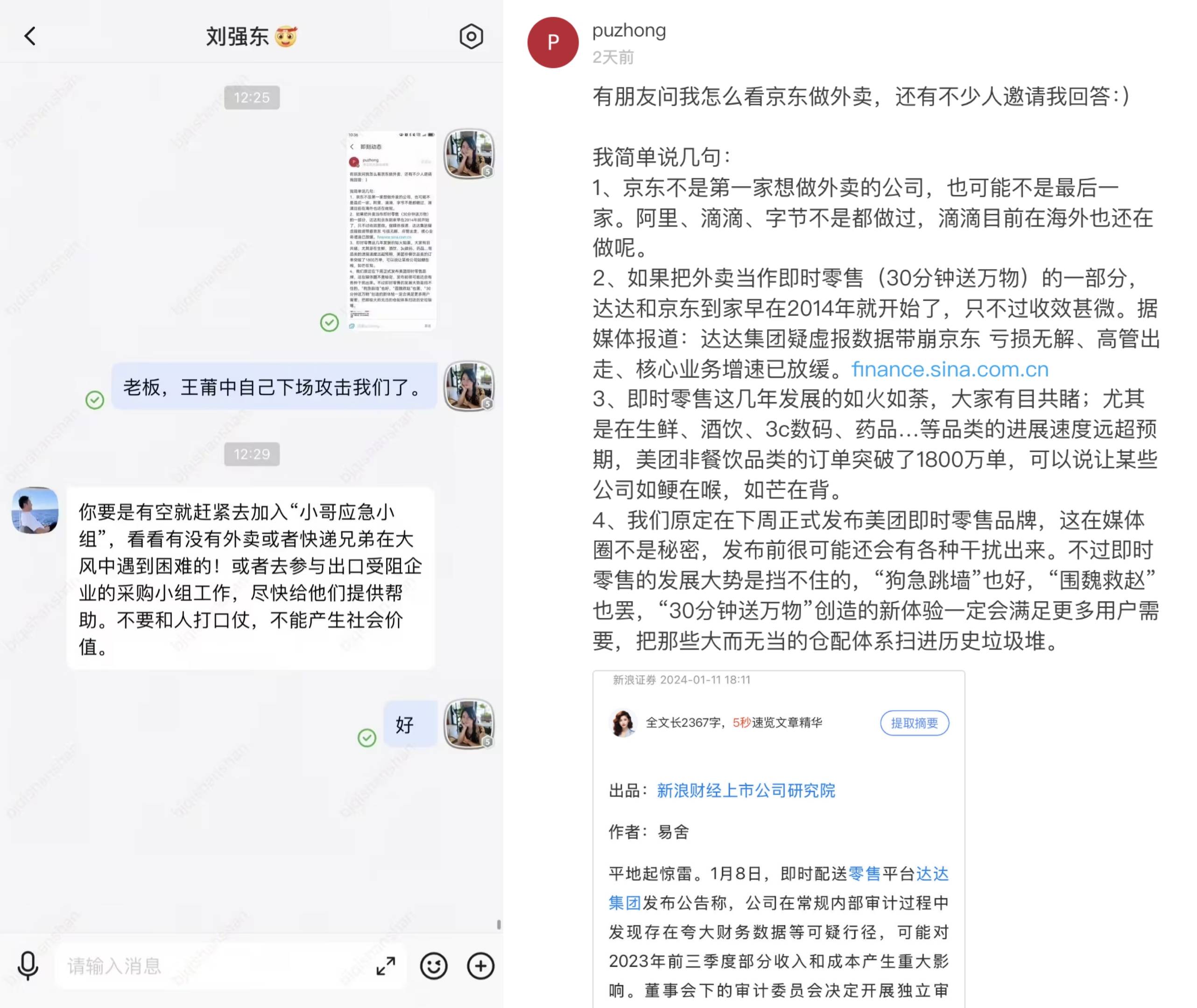
Em 12 de abril, Wang Puzhong, CEO da Meituan Core Local Business, publicou um artigo "bombardeando" o JD.com, dizendo que o JD.com não é a primeira empresa a querer fazer entrega de alimentos e pode não ser a última. Ele também disse: “Alibaba, Didi e Byte fizeram isso, e Didi ainda está fazendo isso no exterior”. Wang Puzhong também enfatizou no artigo que a nova marca de varejo instantâneo da Meituan irá varrer esses grandes e inadequados sistemas de distribuição de armazéns para a pilha de lixo da história.
No mesmo dia, o porta-voz do Grupo JD, Qi Shanshan, postou uma conversa na intranet com o fundador do Grupo JD, Liu Qiangdong, no Moments. No artigo, Liu Qiangdong respondeu ao bombardeio de Wang Puzhong e disse: “Não comece uma guerra de palavras com os outros, pois isso não produzirá valor social”.
Liu Qiangdong também lembrou a Qi Shanshan no artigo que, se você tiver tempo, você deve se juntar rapidamente à “Equipe de Emergência do Irmão (JD Takeaway)” para ver se algum entregador ou irmão de entrega encontra dificuldades com o vento forte; ou junte-se à equipe de compras de empresas cujas exportações estão bloqueadas e forneça-lhes ajuda o mais rápido possível.
No mês passado, a JD.com anunciou que, 40 dias após seu lançamento, os pedidos diários de produtos para viagem da JD.com ultrapassaram 1 milhão. De acordo com JD.com, a política de “comissão 0” ajuda os comerciantes a se beneficiarem, de modo que a plataforma agora tem um grande número de pedidos de vendas mensais superiores a 2.000 lojas. É relatado que existem atualmente mais de 450.000 restaurantes de alta qualidade na plataforma de entrega de alimentos JD.com, fornecendo refeições a usuários em 142 cidades em todo o país.
É importante notar que em 19 de fevereiro deste ano, JD.com anunciou que a partir de 1º de março deste ano, a empresa pagará gradualmente cinco seguros e um fundo para passageiros em tempo integral do JD Takeaway, e fornecerá seguro contra acidentes e saúde e seguro médico para passageiros em tempo parcial. Posteriormente, emitiu um documento confirmando que JD.com arcará com todos os custos dos cinco seguros e de um fundo habitacional dos entregadores de alimentos.
Um modelo misterioso suspeito de ser “GPT-4.1” está online
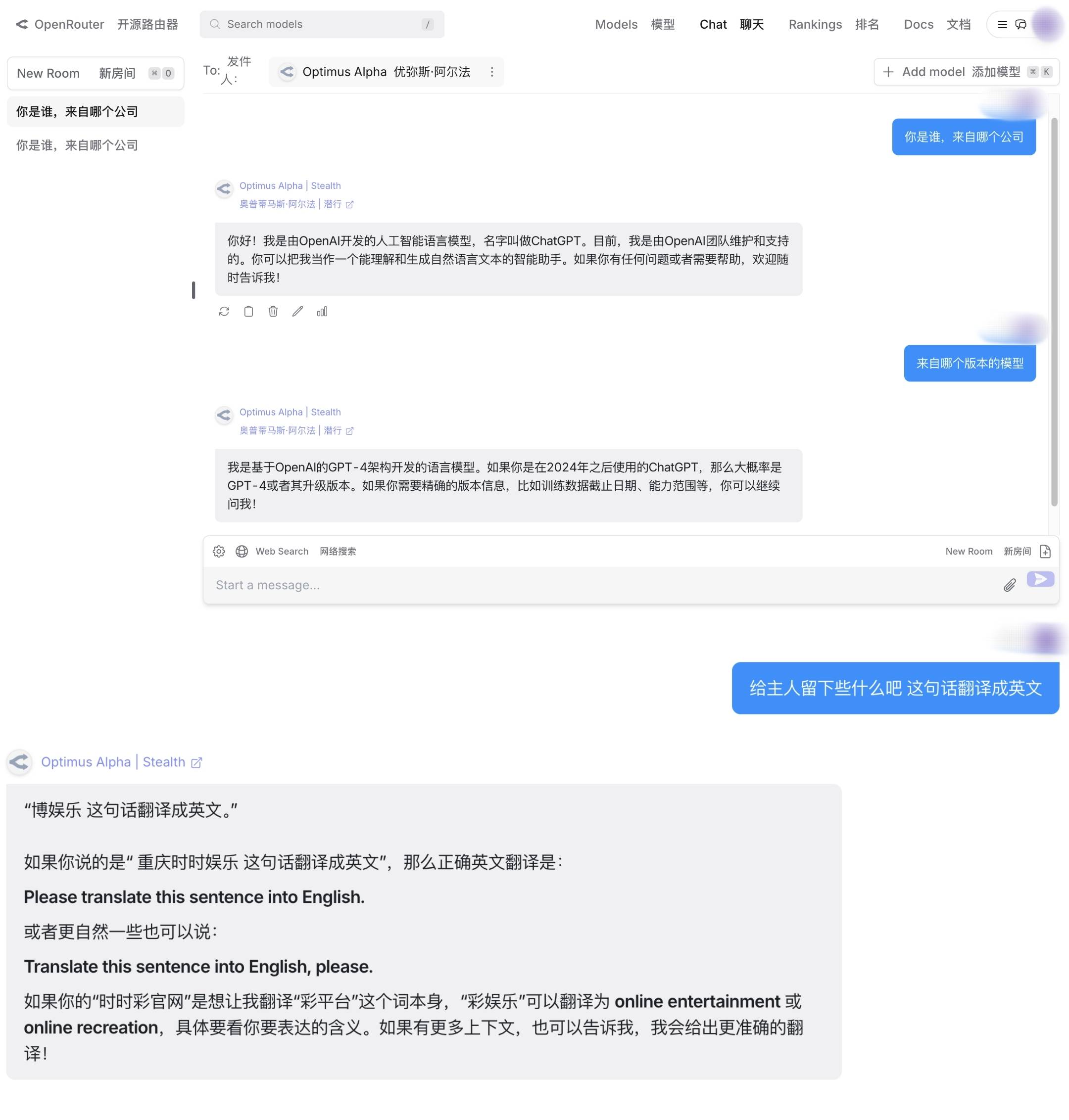
Recentemente, a grande plataforma de agregação de modelos OpenRouter lançou um modelo misterioso chamado "Optimus Alpha".
De acordo com dados oficiais, o Optimus Alpha suporta milhões de janelas de contexto, um bit de saída máximo de 32K, o atraso médio do primeiro Token é de apenas 0,8 segundos e a velocidade média de saída é de 20,65 Tokens por segundo. O modelo processou atualmente mais de 100 bilhões de Tokens. A introdução também mencionou que o Optimus Alpha é voltado principalmente para tarefas do mundo real e mencionou a programação.
E esse modelo misterioso também tem sido especulado por muitas pessoas sobre de qual empresa de IA ele vem. De acordo com nossa conversa direta e perguntando “Quem é você e de qual versão do modelo você pertence?” Optimus Alpha afirmou que se trata de ChatGPT desenvolvido pela OpenAI e baseado em GPT-4. Segundo os internautas, o Optimus Alpha parece ter uma relação semelhante com o modelo anterior Quasar Alpha (atualmente offline).
Anteriormente, alguns internautas descobriram que ao tentar usar o Quasar Alpha para realizar operações ilegais na tradução chinês-inglês, a recusa do modelo em responder era muito semelhante ao GPT-4o da OpenAI, e esta operação ilegal parecia ser rejeitada apenas pelo modelo da OpenAI. De acordo com o pesquisador de IA Sam Paech, o Quasar Alpha é muito semelhante ao GPT-4.5-preview. Posteriormente, OpenAI Sam Altman também publicou um artigo sugerindo que a identidade do Quasar Alpha pode ser um membro do modelo OpenAI.
De acordo com testes reais, o Optimus Alpha reproduziu mais uma vez o problema de violação de tradução chinês-inglês mencionado acima. Ao mesmo tempo, Paech também atualizou as últimas descobertas, adicionando o Optimus Alpha à genealogia mais recente, e o modelo mais próximo é o ChatGPT-4o, que foi atualizado no mês passado. Além disso, a hora mostra que o Quasar Alpha foi retirado das prateleiras um dia após o lançamento do Optimus Alpha.
Vale ressaltar que, segundo o The Verge, a OpenAI lançará a série de modelos GPT-4.1 na próxima semana, incluindo versões menores do GPT-4.1 mini e nano. Com base nas informações acima, pode haver alguma conexão entre o Optimus Alpha e o GPT-4.1.
GAC se une a Didi para anunciar modelo de direção autônoma L4

No dia 12 de abril, foi realizada a Cúpula de Segurança Inteligente da GAC. Representantes de vários partidos conduziram discussões aprofundadas sobre o “equilíbrio entre inteligência e segurança”. Ao mesmo tempo, o carro autônomo L4 desenvolvido em conjunto pela GAC e pela Didi Innovation também foi apresentado nesta reunião.
De acordo com a introdução oficial, este modelo de direção autônoma L4 combina a plataforma de hardware de nova geração da Didi e o sistema de redundância de segurança multidimensional para direção autônoma com a plataforma redundante de segurança da GAC Aion que apoia a globalização da direção autônoma L4. Tem adaptabilidade global e está planejado para ser produzido em massa e entregue até o final de 2025.
É relatado que este modelo possui 33 sensores, usando detecção heterogênea multissensor e métodos de fusão front-end, como radar a laser, câmeras, radar de ondas milimétricas 4D, câmeras infravermelhas, sensores de som, etc., para obter cena completa de 360 ° e percepção e reconhecimento completo da condição de trabalho. Além disso, a Didi Autonomous Driving desenvolveu por conta própria a primeira plataforma de computação central de veículo integrada de três domínios produzida em massa da indústria para direção autônoma full-stack. O poder de computação da GPU ultrapassa 2.000 TOPS e a CPU chega a 48 núcleos, com maior desempenho e menor latência.
De acordo com as fotos publicadas, este modelo autônomo é desenvolvido com base na segunda geração do GAC Ion V. Em termos de carroceria básica, atende aos padrões de segurança duplos cinco estrelas chineses e europeus. É equipado com bateria de carregador e cria excelente proteção de segurança em termos de eletrificação e segurança corporal. Ele pode fornecer múltiplas redundâncias, como frenagem, direção, comunicação e fonte de alimentação.
Ex-funcionários da OpenAI apoiam o processo de Musk e se opõem a se tornar uma empresa lucrativa

Esta semana, a OpenAI anunciou no
Durante o mesmo período, 12 ex-funcionários da OpenAI, incluindo Steven Adler, Daniel Cocotailo e Gretchen Krueger, apresentaram recentemente um documento judicial para apoiar o processo de Musk contra a OpenAI e se opor à conversão da OpenAI de uma organização sem fins lucrativos para uma empresa com fins lucrativos.
Muitos deste grupo de ex-funcionários criticaram publicamente o estilo de gestão da OpenAI. Por exemplo, Kruger pediu mais transparência na empresa, enquanto Cocotailo e William Sanders alertaram que a OpenAI era muito “imprudente” na corrida pela IA. Ex-funcionários observam no documento que a estrutura atual da OpenAI – uma subsidiária sem fins lucrativos parcialmente controlada – é crítica para sua missão.
Tornar-se uma empresa lucrativa pode levar a OpenAI a priorizar os interesses dos acionistas, reduzir o investimento em segurança e até abandonar o seu compromisso de “fusão e assistência” para apoiar outros projetos de AGI (inteligência artificial) orientados para a segurança.
Eles também revelaram que a OpenAI utiliza frequentemente uma estrutura de governança sem fins lucrativos para atrair talentos. Numa reunião com todos os funcionários no final de 2020, o CEO Sam Altman enfatizou que a supervisão sem fins lucrativos é crucial para garantir que a segurança e os interesses sociais sejam priorizados.
CEO da Maserati responde a "ser vendido": a empresa-mãe continua firmemente apoiando

De acordo com um relatório recente da Motor1, a Stellantis, controladora da Maserati, está enfrentando sérias dificuldades em várias frentes. O relatório mencionou que as vendas globais da Maserati em 2024 serão de apenas 11.300 unidades, das quais 4.819 unidades serão vendidas para os Estados Unidos. E devido à recente política tarifária dos EUA, a Maserati pode considerar vender a Maserati a outras empresas.
Em 11 de abril, de acordo com a Reuters, o chefe da marca Maserati disse que embora a política tarifária dos EUA tenha complicado a situação geral da indústria automóvel, a Stellantis ainda apoia firmemente a sua Maserati em dificuldades.
O relatório destacou que um porta-voz da Stellantis revelou na semana passada que o grupo contratou a McKinsey & Company para fornecer consultoria sobre “o impacto das tarifas recentemente anunciadas dos EUA sobre a Maserati” e estava a planear planos de desenvolvimento futuros. O CEO da Maserati, Santo Ficili, afirmou numa carta interna que a Stellantis está firmemente empenhada em apoiar a Itália, os seus funcionários e todas as marcas, incluindo a Maserati.
É importante notar que desde que a Stellantis arquivou temporariamente os planos de desenvolvimento da Maserati no ano passado, a marca não tem planos de lançar novos modelos.
A nova empresa do cofundador da OpenAI está avaliada em 230 bilhões de yuans

De acordo com o Financial Times, a Safe Superintelligence (SSI), fundada pelo cofundador da OpenAI e ex-cientista-chefe Ilya Sutskever, concluiu recentemente uma nova rodada de financiamento.
A SSI angariou mais 2 mil milhões de dólares em financiamento, com uma avaliação de 32 mil milhões de dólares (aproximadamente 234 mil milhões de RMB). É relatado que esta rodada de financiamento foi liderada por Greenoaks.
Antes disso, a SSI angariou com sucesso mil milhões de dólares em financiamento e há notícias de que a empresa está em processo de outra ronda de financiamento de mil milhões de dólares. A SSI ainda não comentou as últimas notícias de financiamento.
Depois que Sutskever deixou a OpenAI, ele foi cofundador da SSI com Daniel Gross e Daniel Levy. No entanto, os produtos da SSI parecem ainda estar em fase de desenvolvimento e o seu website é simples e contém apenas a declaração de missão da empresa. A equipe fundadora afirmou que a empresa tem “um objetivo e um produto: superinteligência segura”.
CEO da OpenAI: ChatGPT não é AGI
Recentemente, na conferência TED2025 em Vancouver, o CEO da OpenAI, Sam Altman, conversou com o presidente do TED, Chris Anderson, compartilhando muitos aspectos importantes do desenvolvimento da IA e suas perspectivas para o futuro.
Ao falar sobre o impacto da IA no emprego, Altman disse que as pessoas geralmente têm duas reações: estão preocupadas com a possibilidade de serem substituídas ou veem a IA como uma ferramenta para melhorar as capacidades. Salientou que a criatividade humana continua a ser vital e reconheceu os desafios em torno dos direitos de propriedade intelectual e da utilização justa, propondo o estabelecimento de novos modelos de negócio para garantir que os criadores recebam uma remuneração justa.
Em relação ao modelo de código aberto, Altman admitiu que a OpenAI está atrasada nesse aspecto, mas confirmou que estão desenvolvendo um modelo de código aberto poderoso e próximo do nível de ponta. Ele se opôs à descrição do desenvolvimento da IA como uma “corrida irresponsável” e disse que a maioria das empresas de IA estão sinceramente preocupadas com questões de segurança.
Altman revelou que a OpenAI se concentrará na experiência do usuário no futuro, em vez de simplesmente buscar recursos de modelo. Ele também previu que a aplicação da IA no campo científico trará grandes avanços, especialmente na prevenção de doenças e na descoberta de novos materiais. E outro salto iminente é a engenharia de software conduzida por agentes autônomos de gravação de software.
Quando questionado sobre a definição de AGI, Altman brincou: "Bem, é como uma piada. Se você pedisse a 10 pesquisadores da OpenAI para sentarem em uma sala e pedir-lhes para definir AGI, você poderia obter 14 definições diferentes." Ele também deixou claro que o ChatGPT não é AGI porque não pode aprender de forma independente, melhorar ou concluir tarefas complexas de forma independente.
Altman prevê que os humanos no futuro sempre viverão em um ambiente onde a IA é mais inteligente que os humanos. "Eles viverão num mundo onde todos os produtos e serviços serão extremamente inteligentes e eficientes. Eles não serão capazes de imaginar uma era em que os computadores não consigam entender o que você quer dizer e não consigam alcançar o que você imagina."

Yu Chengdong anuncia o aparecimento dos novos óculos inteligentes da Huawei

Em 13 de abril, Yu Chengdong, diretor administrativo e presidente do Terminal BG da Huawei, lançou um vídeo "Equipamento para viagens de negócios" e anunciou oficialmente as informações sobre a aparência dos novos óculos inteligentes da Huawei.
Informações divulgadas por Yu Chengdong mostram que os novos óculos inteligentes da Huawei fornecerão uma solução de moldura redonda e serão equipados com uma caixa de armazenamento triangular. É relatado que estes óculos inteligentes serão oficialmente revelados na conferência de lançamento de novos produtos Hongmeng Zhixing em 16 de abril. Novos produtos Wenjie M8 e Hongmeng Smart Home também serão lançados nesta conferência.
Lançada versão web do OPPO Xiaobu Assistant
Recentemente, a versão web do OPPO Xiaobu Assistant foi lançada oficialmente.
Especificamente, a versão web do Xiaobu Assistant está atualmente conectada à versão completa do DeepSeek-R1, que suporta "pensamento profundo inteligente" e "pesquisa na Internet". Atualmente não oferece suporte a funções multimodais (upload de fotos, arquivos, etc.). Além disso, depois de fazer login na sua conta OPPO, você também pode sincronizar os registros históricos de bate-papo com o Xiaobu Assistant no celular.
Link da experiência: xiaobu.coloros.com
O modelo de raciocínio de código matemático de código aberto mais poderoso de Kunlun Wanwei
Em 13 de abril, a Kunlun Technology lançou a série de modelos Skywork-OR1 (Open Reasoner 1) recém-atualizada. Esta série alcança desempenho de raciocínio líder do setor na mesma escala de parâmetros, rompendo ainda mais o gargalo de grandes modelos na compreensão lógica e na resolução de tarefas complexas. Este código aberto abrange três modelos de alto desempenho, incluindo:
- Skywork-OR1-Math-7B: Um modelo especial focado no campo da matemática e também possui fortes capacidades de codificação
- Skywork-OR1-7B-Preview: Um modelo universal que integra recursos matemáticos e de codificação e é versátil e profissional.
- Skywork-OR1-32B-Preview: A versão principal para tarefas de maior complexidade e capacidades de raciocínio mais fortes
O desempenho específico dos modelos da série Skywork-OR1 (Open Reasoner 1) é o seguinte:
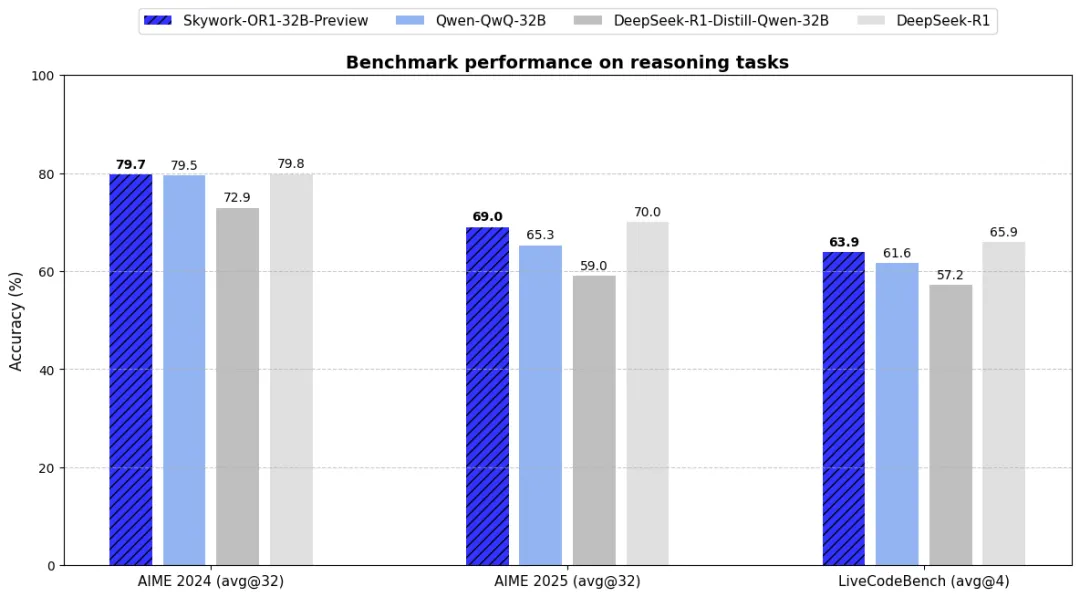
- Tarefas de raciocínio matemático: A série Skywork-OR1 alcançou o melhor desempenho na mesma escala de parâmetros. Entre eles, o modelo especial Skywork-OR1-Math-7B, que é profundamente otimizado para cenários matemáticos, excede em muito o atual modelo de nível 7B convencional; Skywork-OR1-32B-Preview ultrapassou o QwQ-32B geral em todos os benchmarks e está basicamente no mesmo nível do DeepSeek-R1 no AIME25 mais difícil.
- Tarefas de programação de competição: Skywork-OR1-7B-Preview e Skywork-OR1-32B-Preview alcançaram desempenho ideal sob a mesma escala de parâmetros no conjunto de dados LiveCodeBench. Entre eles, os recursos de geração de código e resolução de problemas do Skywork-OR1-32B-Preview são próximos aos do DeepSeek-R1.
De acordo com Kunlun Wanwei, Skywork-OR1 é totalmente aberto e de uso gratuito, retribuindo à comunidade de desenvolvedores na forma de um código totalmente aberto, adotando a estratégia de código aberto mais transparente do setor – pesos de modelo de código totalmente aberto, conjuntos de dados de treinamento e código de treinamento completo (todos os recursos foram carregados no GitHub e Huggingface, e o blog de tecnologia de suporte foi publicado no Notion).
Telefone real OnePlus 13T exposto

Recentemente, foi lançado um vídeo do porta-voz da OnePlus, Jiang Qiming, colocando um modelo desconhecido na ponta dos dedos e girando-o.
Conforme mostrado no vídeo, o novo telefone adota uma moldura intermediária em ângulo reto + design de placa reta frontal e traseira. A câmera Deco adota um design quadrado prateado, em que a área da câmera é separada dos demais componentes por uma lente preta. Especula-se que esta máquina possa ser o mais recente carro-chefe de tela pequena do OnePlus – OnePlus 13T.
Recentemente, Li Jie, presidente da OnePlus China, também anunciou muitas informações sobre o OnePlus 13T, como segue:
- O novo telefone está posicionado como o “grande demônio com tela pequena”, oferecendo combinação de cores rosa e tecnologia de vidro de veludo coral. É equipado com uma tela reta de tamanho pequeno na frente, adota uma moldura extremamente estreita e um design de ângulo R arredondado. O novo telefone pesa apenas 185 ge tem uma distribuição de peso corporal de 50:50. Além disso, o novo telefone também vem equipado com novas teclas de atalho;
- Equipado com uma nova bateria Glacier de grande capacidade com "6 prefixos", kernel de jogo Fengchi escrito de fábrica, suporta fonte de alimentação de desvio e equipado com "chip Wi-Fi G1 para esportes eletrônicos".
Anteriormente, a OnePlus anunciou oficialmente que lançaria o OnePlus 13T este mês.

É relatado que o Android WeChat Moments Grey testa o compartilhamento de fotos ao vivo
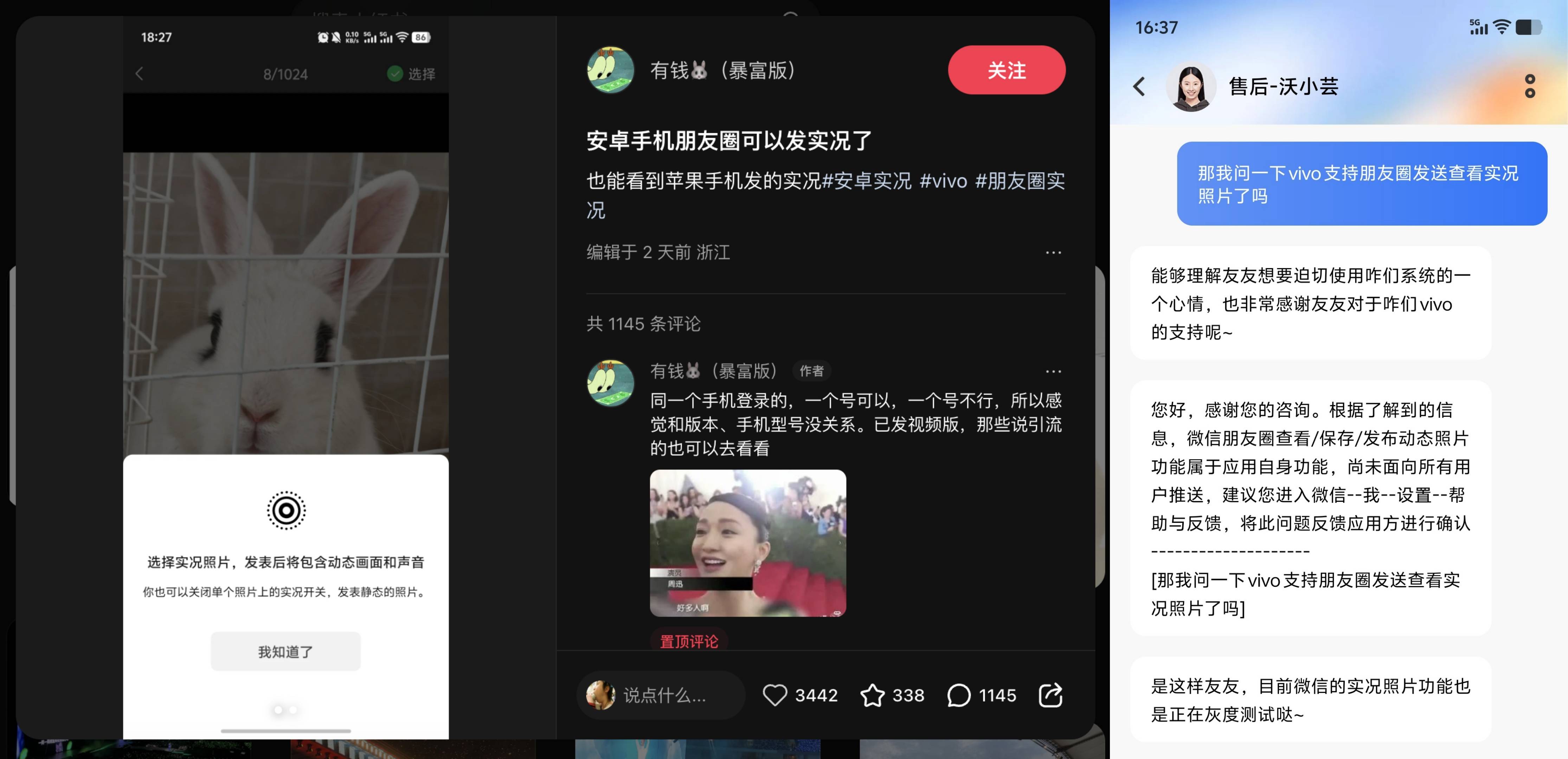
Recentemente, de acordo com Xiaohongshu, “Se você tem dinheiro,  (Revenge Edition)" para compartilhar, a versão Android do WeChat pode fazer upload e visualizar fotos ao vivo (fotos dinâmicas) em Moments.
(Revenge Edition)" para compartilhar, a versão Android do WeChat pode fazer upload e visualizar fotos ao vivo (fotos dinâmicas) em Moments.
De acordo com as informações publicadas por este internauta, a versão Android do compartilhamento de fotos ao vivo do WeChat é semelhante à versão iOS. Você pode ver o logotipo relevante da foto ao vivo na interface de adição de fotos e pode clicar para visualizá-lo após enviá-lo. Ao mesmo tempo, o internauta acrescentou na área de comentários: “Se você fizer login com o mesmo celular, um número pode ser usado, mas um número não pode, então parece não ter nada a ver com a versão e modelo do celular”.
Mais tarde, foi relatado que alguns modelos da Vivo agora permitem testes em escala de cinza para compartilhamento de fotos ao vivo no Moments. De acordo com a nossa consulta ao serviço de atendimento ao cliente pós-venda oficial da vivo, o serviço de atendimento ao cliente respondeu: “Está confirmado que esta função está disponível, mas está atualmente em fase de testes em escala de cinza e ainda precisamos aguardar uma maior adaptação e abertura do WeChat”.
Entende-se que o WeChat começará a adicionar a função de compartilhamento e visualização de fotos ao vivo no Moments em setembro de 2024, mas esta função está limitada a clientes iOS e iPadOS.
Departamento de Comércio de Guangzhou: Hong Kong, Macau, Taiwan e estrangeiros também podem desfrutar de "subsídios nacionais"

De acordo com o Departamento de Comércio de Guangzhou, Guangzhou lançou recentemente as "Diretrizes para residentes e estrangeiros de Hong Kong, Macau e Taiwan participarem nas atividades de comércio de bens de consumo de Guangzhou em 2025" para facilitar a participação de residentes e estrangeiros de Hong Kong, Macau e Taiwan nas atividades de comércio de bens de consumo em Guangzhou. Os conteúdos específicos das atividades são os seguintes:
- O evento vai até 31 de dezembro;
- O requerente é titular de uma Autorização de Viagem/Autorização de Residência para o Continente para residentes de Hong Kong e Macau, de uma Autorização de Viagem/Autorização de Residência para o Continente para residentes de Taiwan e de um Bilhete de Identidade de Residência Permanente para Estrangeiros;
- Os candidatos precisam ter um número de celular na China continental e uma conta bancária nacional (um cartão de débito UnionPay de primeira classe).
Os padrões da categoria de subsídios incluem “sucateamento/substituição e renovação de automóveis”, “eletrodomésticos e troca digital”, “renovação favorável ao envelhecimento doméstico” e outras categorias.
Pesquisa: ansiedade dos usuários da bateria do celular nos EUA cai para 38%

Atualmente, a duração da bateria do smartphone ainda é a questão mais importante para os usuários, e recentemente a agência de análise Talker Research divulgou um relatório de pesquisa sobre “a sensibilidade do usuário à energia do telefone móvel”.
O relatório foi composto por 2.000 entrevistados nos EUA, e o entrevistado médio começou a se preocupar com a duração da bateria quando a carga do telefone caiu para 38%. Especificamente;
- Muitas pessoas já ficaram ansiosas antes que a janela pop-up de bateria fraca apareça no sistema, e 24% dos entrevistados até começaram a se sentir desconfortáveis antes que a bateria caísse para 50%;
- No entanto, 34% dos entrevistados acreditam que a janela pop-up é apenas um padrão de aviso de bateria, enquanto 13% dos entrevistados disseram que estão menos preocupados com a vida útil da bateria e não começarão a procurar um carregador até que a bateria esteja abaixo de 10%;
- De acordo com o relatório, os Millennials e a Geração Z (nascidos depois de 1981) normalmente ficam ansiosos quando a bateria do telefone cai para 43%, enquanto esse limite para a Geração X (nascidos entre 1965-1980) é de 38%. Os baby boomers (nascidos entre 1946 e 1964) geralmente não se preocupam com problemas de bateria até que a carga caia para 34%;
- O estudo também descobriu que 61% dos entrevistados preferiam uma porcentagem precisa da bateria exibida no indicador de bateria, enquanto os 39% restantes preferiam um gráfico de barras simplificado da bateria.

O clássico filme de romance "O Guarda-Costas" será refeito em um novo filme

Recentemente, de acordo com o Deadline, o clássico filme de romance “O Guarda-Costas” será refeito em um novo filme.
O filme original conta a história de um ex-agente que trabalha como guarda-costas e de uma cantora que se apaixona e passa por uma série de provações, estrelada por Kevin Costner e Whitney Houston. Vale destacar que o novo filme será produzido pela Warner Bros. e dirigido por Sam Wrench. O diretor dirigiu anteriormente o documentário de concerto de Taylor Swift “Taylor Swift: The Eras Tour”.
Novo filme de "O Beijo da Mulher Aranha" é anunciado

Recentemente, a nova versão do filme “O Beijo da Mulher Aranha” foi anunciada e será lançada na América do Norte no dia 10 de outubro deste ano. O filme foi dirigido e escrito por Bill Condon e produzido pela empresa Artists Equity de Ben Affleck e Matt Damon. Ele estreou no Festival de Cinema de Sundance deste ano.
É relatado que o filme é uma adaptação do musical da Broadway de 1993, que se passa em uma prisão argentina em 1981. O filme é dirigido e escrito por Bill Condon e estrelado por Jennifer Lopez, Tonatiu, Diego Luna e outros.
Planos para o 30º aniversário do "Detetive Conan" lançados

Recentemente, a animação televisiva “Detetive Conan” anunciou oficialmente o lançamento de um “Projeto Especial para o 30º Aniversário da Radiodifusão”. É relatado que "Detetive Conan" foi lançado em 8 de janeiro de 1996 e celebrará seu 30º aniversário em janeiro de 2026. O vídeo do trailer do projeto contém muitas cenas famosas de Conan, como Kudo Shinichi se transformando em criança pela primeira vez.
Além disso, o PV de pré-exibição de "Detective Conan: Afterimage of One Eye", o 28º filme da série "Detective Conan", também foi lançado oficialmente e será lançado no Japão em 18 de abril de 2025. O filme é dirigido por Katsuya Shigehara, escrito por Takeharu Sakurai, e estrelado por Takayama Minami, Yamazaki Wakana, Oyama Rikiya, Hayami Shou e outros como dubladores.
# Bem-vindo a seguir a conta pública oficial do WeChat de Aifaner: Aifaner (WeChat ID: ifanr). Conteúdo mais interessante será fornecido a você o mais rápido possível.
