
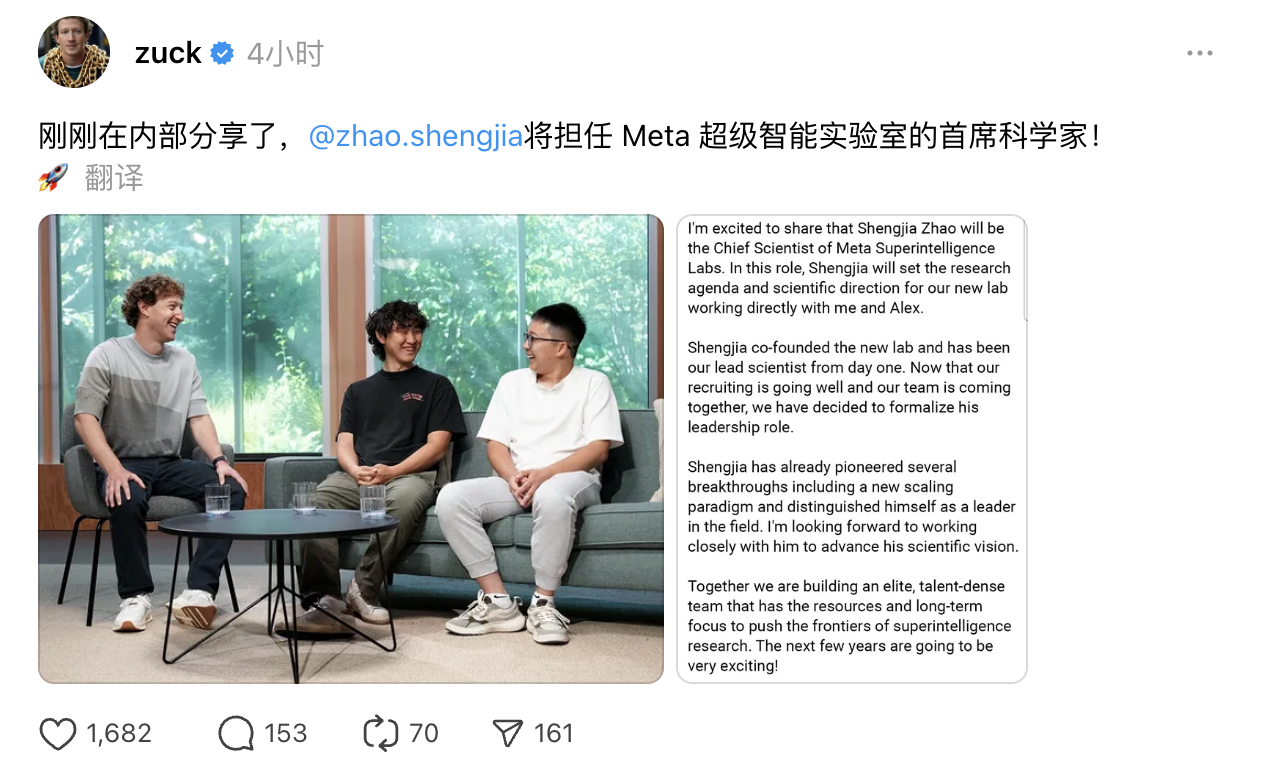
Zuckerberg nomeia ex-aluno da Tsinghua como cientista-chefe da Meta AI! O homem por trás do GPT-4 pode substituir o vencedor do Prêmio Turing, de 65 anos.

Agora mesmo, a Meta anunciou que o ex-aluno da Tsinghua, Shengjia Zhao, atuará oficialmente como cientista-chefe do seu Laboratório de Super Inteligência (MSL).
"Tenho o prazer de anunciar que Shengjia Zhao atuará como Cientista-Chefe do Laboratório de Meta Superinteligência", escreveu Zuckerberg em uma carta interna. "Shengjia Zhao é cofundador do novo laboratório e tem sido nosso Cientista-Chefe desde o início. Agora que nosso recrutamento está progredindo sem problemas e a equipe está gradualmente tomando forma, decidimos formalizar sua posição de liderança."
Zuckerberg também afirmou:
Shengjia Zhao alcançou avanços revolucionários em diversas áreas, incluindo a proposta de um novo paradigma de escalonamento, e demonstrou liderança excepcional nessa área. Estou ansioso para trabalhar em estreita colaboração com ele para avançar sua visão científica. Estamos reunindo uma equipe de alta densidade de talentos de ponta, equipada com amplos recursos e focada no desenvolvimento de longo prazo para avançar as fronteiras da pesquisa em superinteligência. Os próximos anos serão muito empolgantes!
Alexandr Wang, chefe do Meta Super Intelligence Lab, e Jim Fan, chefe do departamento de robótica da Nvidia e cientista renomado, também postaram parabéns nas redes sociais.

Em resposta a isso, Zhao Shengjia postou uma mensagem na plataforma social:
Estou extremamente animado por assumir o cargo de Cientista-Chefe no Meta Superintelligence Labs. Mal posso esperar para trabalhar com a talentosa equipe aqui para desenvolver a ASI e alinhá-la às necessidades humanas para empoderar a todos. Vamos trabalhar juntos!

Vale ressaltar que, diferentemente do MSL, o FAIR se concentra em pesquisas de IA de longo prazo — tecnologias que podem ser utilizadas em cinco a dez anos. Embora a equipe do FAIR tenha sido marginalizada na estratégia geral da Meta, a posição de Yann LeCun, vencedor do Prêmio Turing, não mudou.

Zuckerberg enfatizou particularmente que Yann LeCun continuará atuando como cientista-chefe da FAIR.

Yann Lecun respondeu à nomeação de Zuckerberg: "Meu papel como cientista-chefe da FAIR tem se concentrado em pesquisas de IA de longo prazo e na construção da próxima geração de paradigmas de IA. Estou ansioso para trabalhar com Zhao Shengjia para acelerar a integração de novos resultados de pesquisa em nossos modelos mais avançados."
Então, quem é Zhao Shengjia?
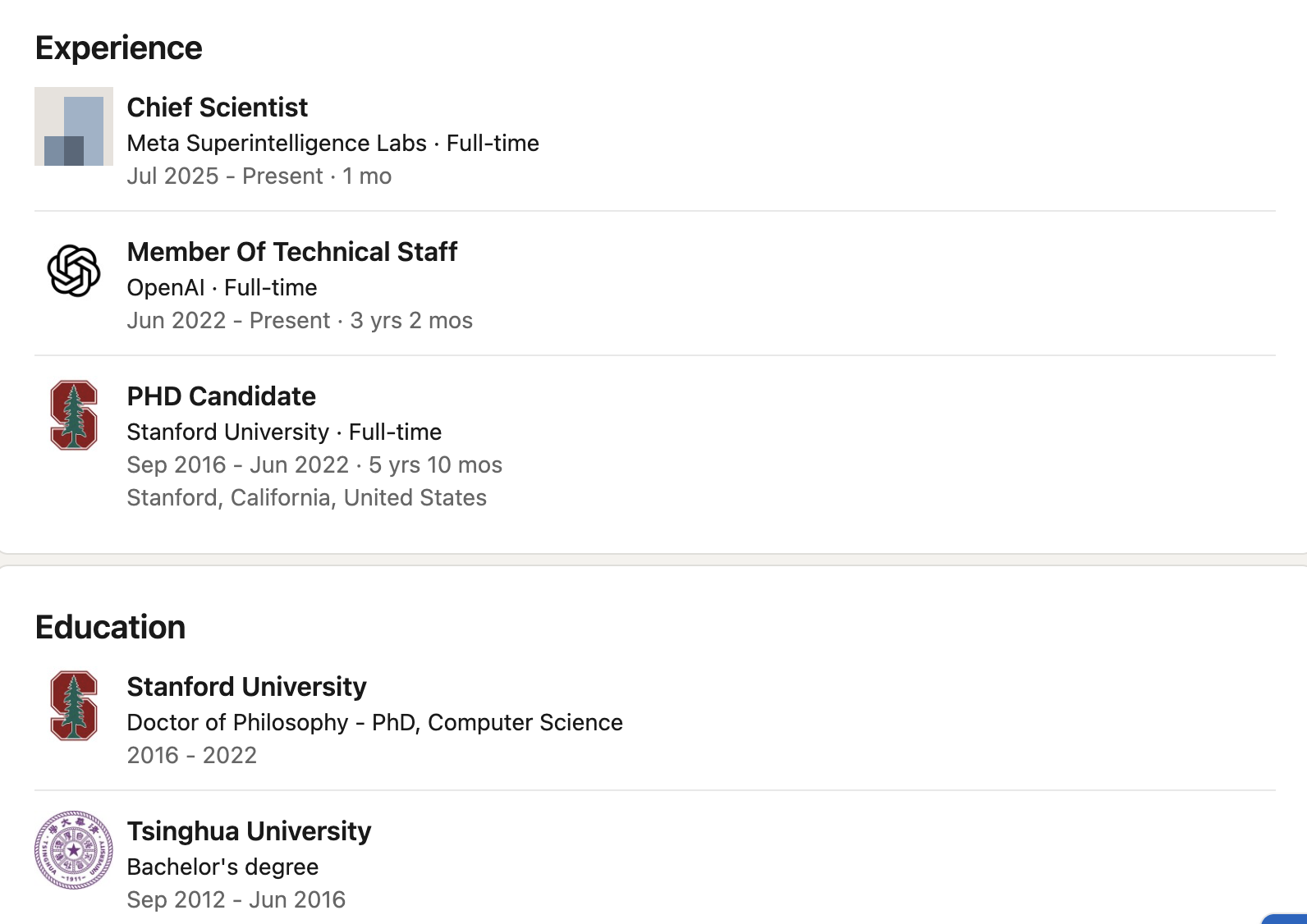
Zhao Shengjia se formou no Departamento de Ciência da Computação da Universidade Tsinghua em 2016. Ele foi aluno de intercâmbio na Universidade Rice, nos Estados Unidos, e posteriormente obteve um doutorado em Ciência da Computação pela Universidade Stanford. Sua pesquisa se concentrou em arquitetura de grandes modelos, raciocínio multimodal e alinhamento.
Durante seus estudos e trabalho, ele colaborou estreitamente com muitos acadêmicos renomados e publicou muitos artigos altamente citados, incluindo Stefano Ermon, professor associado de ciência da computação em Stanford, Jiaming Song, cientista-chefe da Luma AI, Aditya Grover, professor assistente da UCLA, bem como acadêmicos e especialistas como Noah Goodman, Silvio Savarese e Marco Pavone.
Em 2022, ingressou na OpenAI como membro principal de P&D e esteve profundamente envolvido no projeto dos sistemas GPT-4 e GPT-4o. Liderou o desenvolvimento do ChatGPT, GPT-4, todos os modelos mini, 4.1 e o3, e também liderou a equipe de dados sintéticos da OpenAI.
Zhao Shengjia está profundamente envolvido em importantes caminhos técnicos, como cartões de sistema de grandes modelos, mecanismos de segurança e otimização da capacidade de raciocínio.
Especificamente, Zhao Shengjia participou como um dos principais autores da redação do "Relatório Técnico GPT-4" (2023). Até o momento, este artigo recebeu mais de 17.000 citações e é um dos documentos técnicos mais citados na área de IA contemporânea.
Ele também participou ativamente de projetos de pesquisa como o cartão de sistema GPT-4o (2024) e o cartão de sistema OpenAI o1, abrangendo o design de módulos-chave, como raciocínio de modelos, chamada de ferramentas e alinhamento de sistemas. Ele é um dos principais contribuidores para a padronização e abertura dos modelos básicos do OpenAI.
Em seus primeiros anos, ele também fez contribuições notáveis na área de autocodificadores variacionais. Seu trabalho representativo "InfoVAE: Balancing Learning and Inference in Variational Autoencoders" foi publicado na AAAI em 2019 e se tornou um dos pilares importantes da pesquisa sobre modelos de geração de redes neurais.
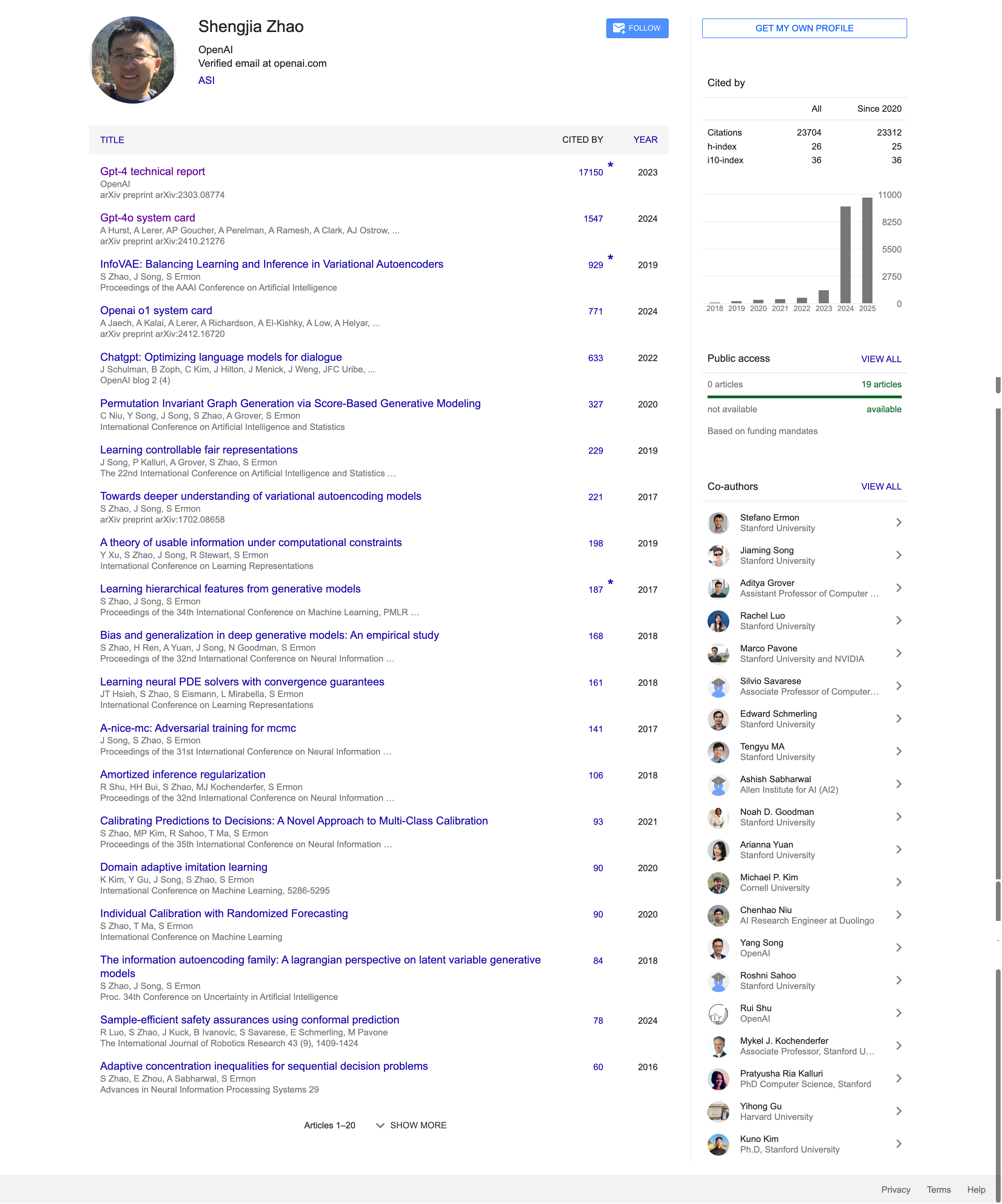
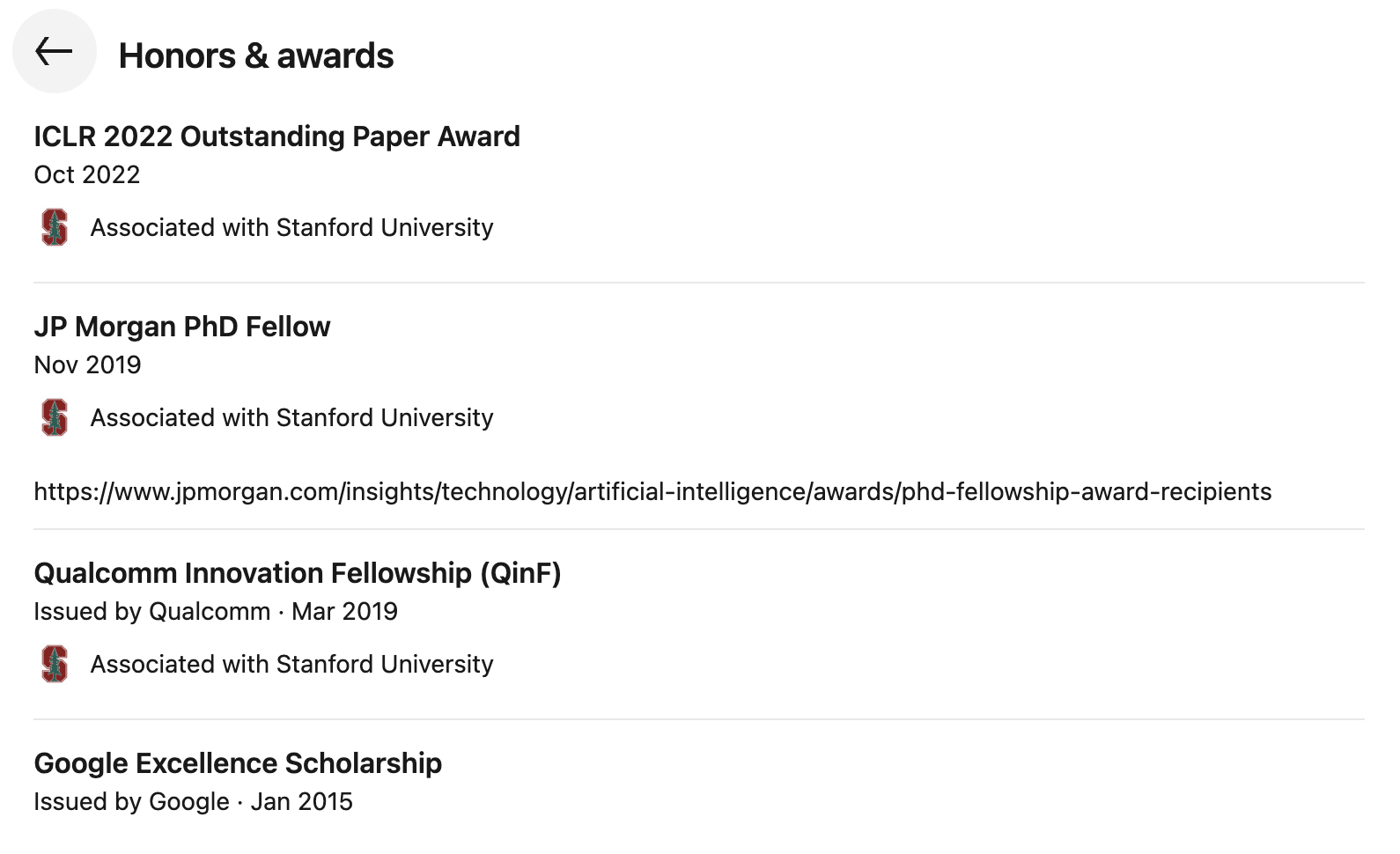
De acordo com dados do Google Acadêmico, até o momento desta publicação, os artigos de Zhao Shengjia receberam mais de 23.000 citações e um índice h de 26. Além disso, seu perfil no LinkedIn mostra que ele recebeu vários prêmios, incluindo o ICLR 2022 Outstanding Paper Award, JP Morgan PhD Fellow, Qualcomm Innovation Fellowship (QinF) e Google Excellence Scholarship.
A experiência de Zhao Shengjia não é um caso isolado.
De acordo com uma reportagem do The Information no mês passado, Zhao Shengjia se juntou ao Meta Superintelligence Lab ao lado de três pesquisadores da OpenAI: Jiahui Yu, Shuchao Bi e Hongyu Ren. Como relatado anteriormente, a equipe do Meta Superintelligence já conta com vários membros chineses, a maioria dos quais possui diplomas de graduação de importantes universidades chinesas, incluindo a Universidade de Tsinghua, a Universidade de Pequim, a Universidade Jiao Tong de Xangai e a Universidade de Ciência e Tecnologia da China.
Na semana passada, @deedydas, investidor da Menlo Ventures, também publicou detalhes sobre os 44 membros da equipe de superinteligência da Meta nas redes sociais. Cinquenta por cento dos membros da equipe são de origem chinesa, e Deedy especula que o salário anual de cada membro pode variar entre US$ 10 milhões e US$ 100 milhões.
Não é de se admirar que haja tantas piadas. Com uma proporção tão alta de chineses, a equipe de superinteligência do Meta poderia ser mais eficiente se falasse chinês diretamente durante as reuniões.
Pode-se dizer que em laboratórios de IA de alto nível, como OpenAI, DeepMind, Anthropic e Meta, cada vez mais rostos chineses estão na vanguarda, participando da definição do paradigma subjacente e da arquitetura de segurança da nova geração de inteligência artificial geral.
A nomeação de Zhao Shengjia é como um prego pregado no cronograma deste processo.
#Bem-vindo a seguir a conta pública oficial do WeChat do iFaner: iFaner (ID do WeChat: ifanr), onde mais conteúdo interessante será apresentado a você o mais breve possível.
