
Agora mesmo, a OpenAI lançou o o3-pro, o modelo de código aberto foi adiado e a Ultraman publicou um longo artigo: Gentle Singularity

O ChatGPT ficou fora do ar por uma noite inteira, e internautas do mundo todo ficaram em caos.
A solução da OpenAI também era um tanto inusitada. Enquanto estava ocupada corrigindo bugs, lançou repentinamente o modelo o3-pro.
A partir de hoje, o o3-pro estará disponível primeiro para usuários Pro e Team, substituindo o o1-pro original no seletor de modelos, enquanto usuários Enterprise e Edu terão que esperar até a próxima semana.
Tudo o que posso dizer é que a vida dos usuários do Plus também é uma vida.
o3-pro chegou, mais potente, mas também mais lento
Como uma versão atualizada do modelo de raciocínio o3, o o3-pro tem melhor desempenho no tratamento de problemas complexos e fornece respostas mais precisas, especialmente em cenários como pesquisa científica, programação, educação e escrita, onde tem vantagens óbvias.
Além disso, ele também oferece suporte à chamada do conjunto completo de ferramentas do ChatGPT, como pesquisa na web, análise de arquivos, raciocínio de imagem, programação Python, personalização de memória, etc., com recursos gerais de execução e integração mais fortes.
Claro que, com mais funções, a velocidade de resposta também diminuiu um pouco.
Como o agendamento de tarefas e as chamadas de cadeia de ferramentas são mais complicados, a velocidade de resposta do o3-pro é geralmente maior que a do o1-pro, por isso ele é mais adequado para uso em cenários onde você precisa pensar com cuidado ou tem altos requisitos de precisão da resposta.
Na avaliação oficial de especialistas, os revisores geralmente acreditavam que o o3 Pro ia um passo além do modelo o3 em termos de clareza de expressão, integridade de respostas, capacidade de execução de instruções e precisão lógica, e era particularmente adequado para tarefas que exigem resultados aprofundados, como ciências, educação, programação, negócios e redação.
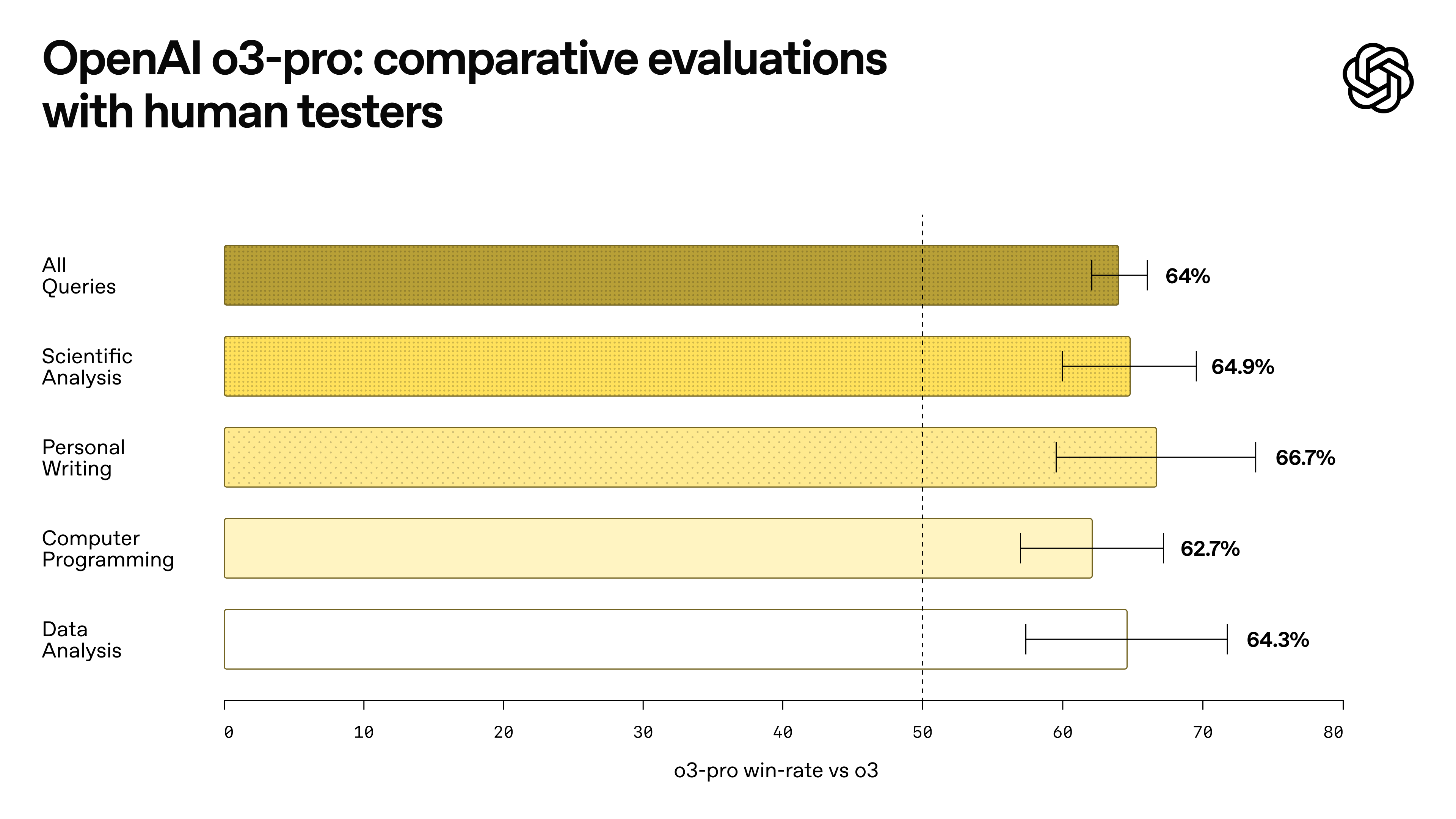
Avaliações acadêmicas também confirmaram isso, com o desempenho geral do o3-pro superando consistentemente o do o1-pro e do o3.
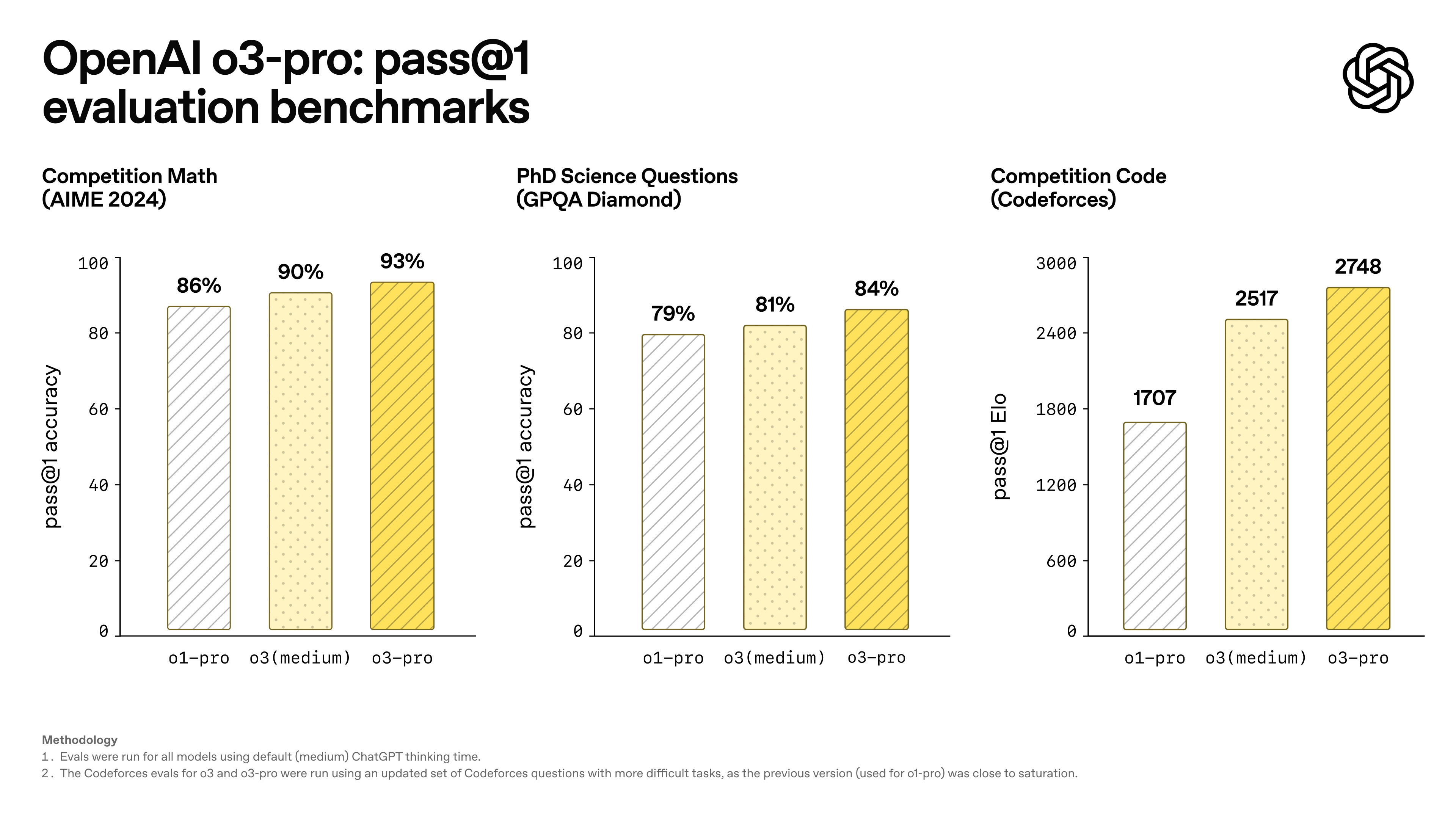
Para avaliar de forma mais científica a estabilidade do modelo, a OpenAI introduziu o padrão de avaliação "quatro respostas corretas": somente quando o modelo dá a resposta correta quatro vezes seguidas ele é considerado bem-sucedido.
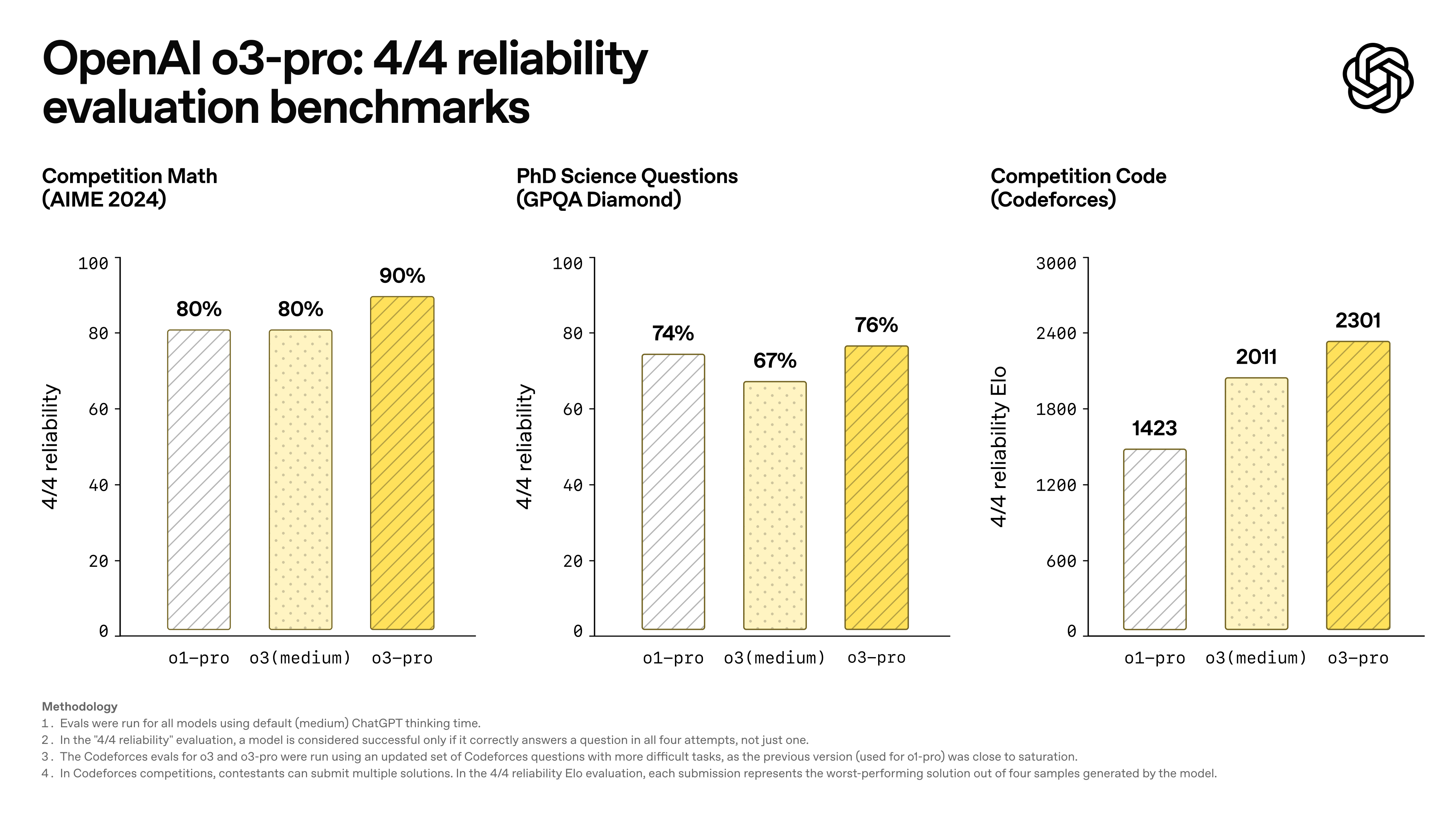
Pode-se dizer que esse mecanismo aumentou muito as exigências de consistência do raciocínio.
Vale ressaltar que o o3 Pro não lançou um cartão de sistema separado desta vez. A OpenAI afirmou que, como o o3-pro e o o3 usam o mesmo modelo subjacente, sua descrição completa de segurança pode ser encontrada no cartão de sistema do o3.
No entanto, o o3 Pro ainda apresenta algumas limitações funcionais, como a impossibilidade de suportar conversas temporárias, geração de imagens e funções do Canvas. Para gerar imagens, os usuários ainda precisam usar os modelos GPT-4o, o3 ou o4-mini.
Antes do lançamento oficial, alguns desenvolvedores receberam acesso antecipado ao o3 Pro.
Ben Hylak, ex-engenheiro de software da SpaceX e designer do Apple VisionOS, obteve acesso antecipado ao o3-pro na semana passada, e sua experiência também foi republicada pelo CEO da OpenAI, Sam Altman, nas redes sociais.

Mais especificamente, Ben e seu cofundador Alexis dedicaram um tempo para compilar todas as notas de reuniões de planejamento anteriores da Raindrop, metas e até memorandos de voz, e então pediram à o3-pro para tentar gerar um documento de planejamento estratégico.
Os resultados gerados pelo modelo final os surpreenderam: o conteúdo era claro e a estrutura, completa. Ele não apenas abrangia as metas e os cronogramas, como também classificava automaticamente as prioridades e até indicava claramente qual conteúdo deveria ser cortado.
Na opinião de Ben, não importa quão poderoso seja o modelo, se ele não puder ser integrado ao ambiente de trabalho real, será difícil se tornar um "membro" verdadeiramente útil.
O o3 Pro apresentou melhorias significativas na compreensão de ambientes complexos, na expressão das capacidades da ferramenta, na formulação de perguntas apropriadas e na alocação racional de recursos. Embora o modelo ocasionalmente apresente o problema de "pensar demais" quando há falta de contexto, o desempenho geral é significativamente melhor do que o da versão anterior.
▲o3 pro (esquerda) vs o3 (direita): o o3 pro entende claramente melhor suas próprias limitações e capacidades.
Em comparação com modelos similares, Ben elogiou que, embora o Claude Opus tenha um forte senso de tamanho, seu desempenho real é medíocre; enquanto o o3-pro é mais prático e pertence a "uma dimensão completamente diferente".
Na versão clássica atualizada do desafio da bola quicando hexagonal, o blogueiro @flavioAd acredita que o o3-pro é o primeiro modelo que consegue lidar quase perfeitamente com o efeito real de colisão entre a bola e a parede.
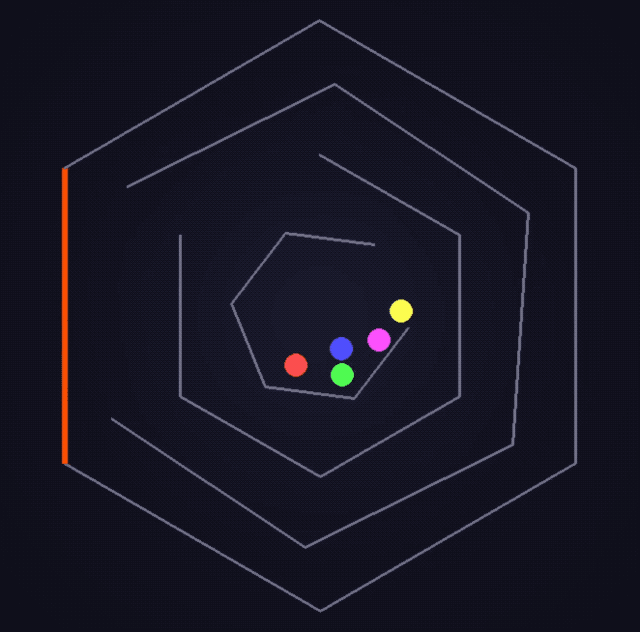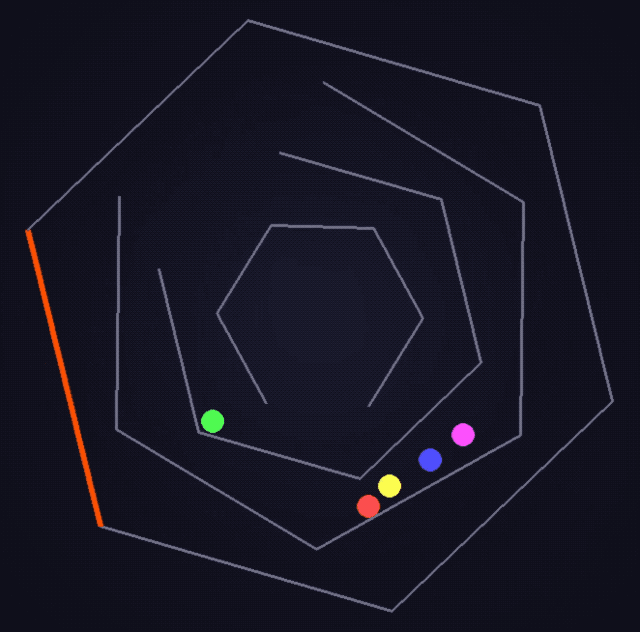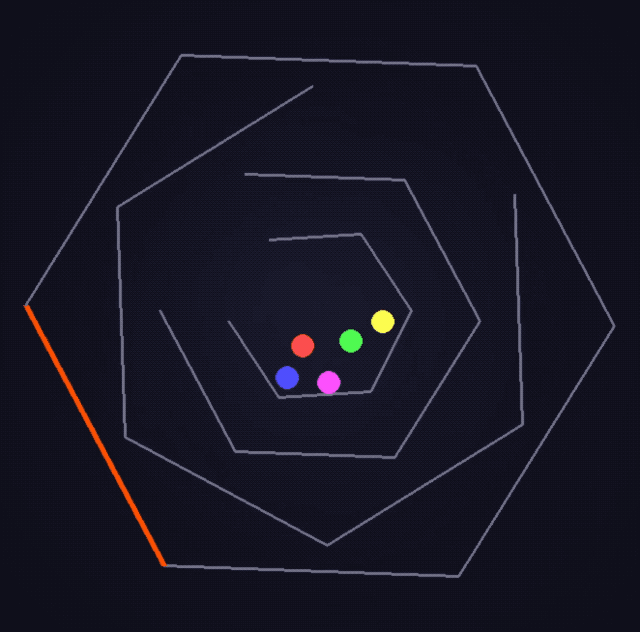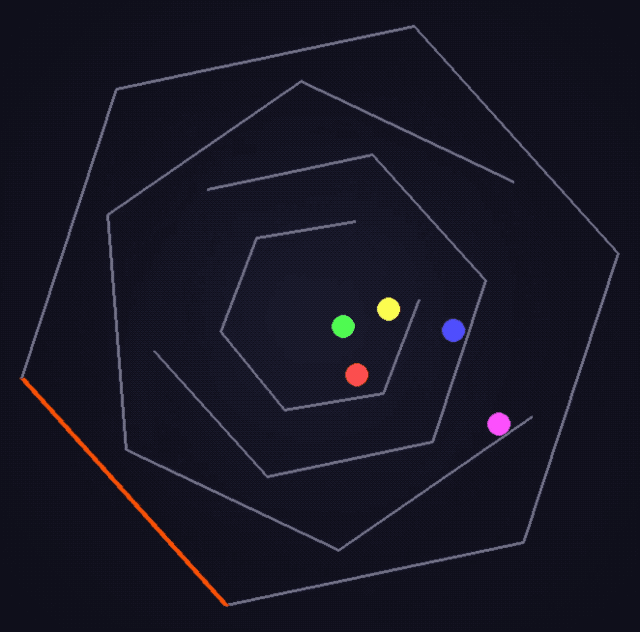
ARC-AGI é uma estrutura de referência usada para avaliar se modelos de linguagem têm capacidades de raciocínio semelhantes às da inteligência artificial geral (AGI).
Ele foi projetado para testar o raciocínio abstrato e as habilidades de resolução de problemas do sistema de IA quando confrontado com novos problemas, semelhante à capacidade dos humanos de se adaptarem rapidamente e encontrarem soluções quando confrontados com novas situações.
Os últimos resultados dos testes são os seguintes:
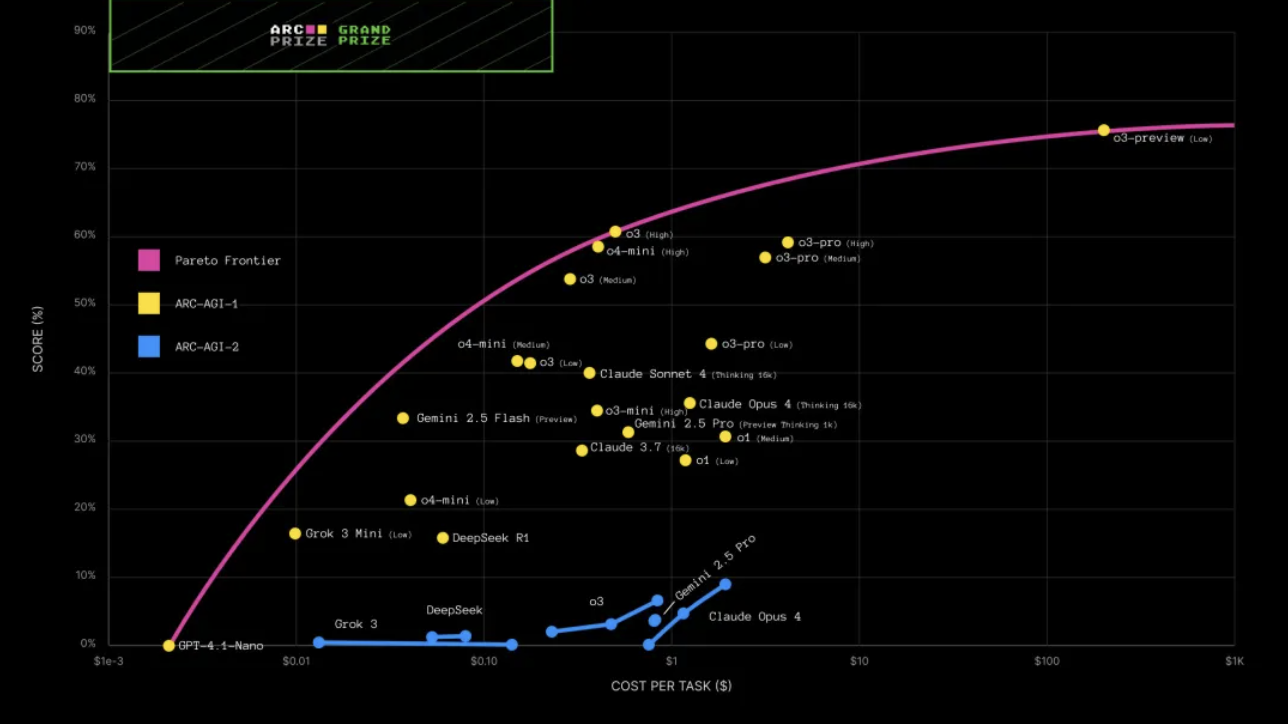
Como você pode ver, o o3-pro tem um desempenho um pouco melhor em tarefas difíceis, mas a melhoria não é significativa, e o custo aumenta com a dificuldade.
Enterprise é a segunda curva, o3-pro é um novo pilar
Quando o o3-pro foi lançado, o CEO da OpenAI, Sam Altman, também anunciou uma grande novidade na plataforma social: o preço do modelo o3 caiu 80%.
Atualmente, o modelo o3 cobra US$ 2 por milhão de tokens de entrada e US$ 8 por milhão de tokens de saída.
O diretor de produtos da OpenAI, Kevin Weil, escreveu que, devido ao forte feedback dos usuários, o limite de taxa de uso do modelo o3 para usuários Plus será dobrado, e o ajuste está sendo implementado gradualmente.
Em contraste, o o3-pro cobra US$ 20 por milhão de tokens de entrada e US$ 80 por milhão de tokens de saída, o que é 87% mais barato que o o1-pro.
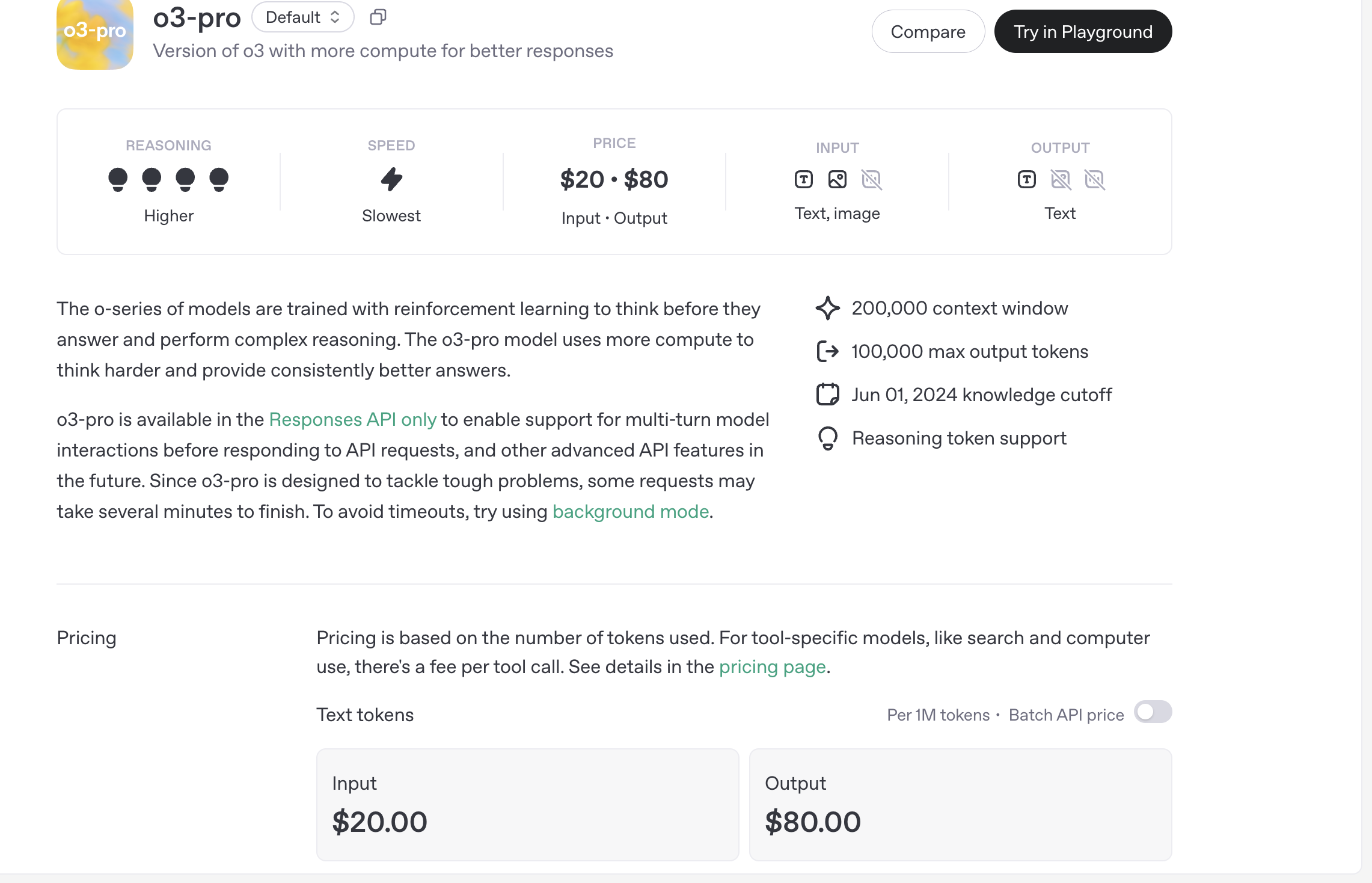
A OpenAI recomenda habilitar o "modo em segundo plano" ao usar o o3-pro: tarefas que demoram muito serão iniciadas de forma assíncrona para evitar problemas de tempo limite de solicitação.
Autoridades afirmaram que o motivo por trás desse grande corte de preço é a otimização abrangente da arquitetura do serviço de inferência da OpenAI. O modelo não mudou, mas a inferência é mais eficiente, então o preço foi ajustado para baixo de acordo.
Por outro lado, pode ser inseparável dos novos desenvolvimentos da OpenAI em recursos de computação.
Desde o lançamento do ChatGPT, a limitação de recursos computacionais sempre foi um "problema difícil" para a OpenAI. Devido às restrições do acordo vinculativo da Microsoft, o serviço de nuvem Azure era o único provedor de infraestrutura de data center para o ChatGPT.

De acordo com a Reuters nas primeiras horas da manhã, citando três pessoas familiarizadas com o assunto, para aliviar a pressão da computação, a OpenAI fechou um acordo de cooperação com a Alphabet (empresa controladora do Google) no mês passado para apresentar o Google Cloud como um provedor adicional de serviços de nuvem.
Essa cooperação é inesperada e razoável.
Por um lado, o ChatGPT é uma das maiores ameaças aos negócios de pesquisa do Google nos últimos anos, e o Google Cloud agora se tornou seu novo patrocinador.
Por outro lado, as vendas do Google Cloud em 2024 atingirão US$ 43 bilhões, representando 12% da receita da Alphabet. Portanto, para superar a Amazon e a Microsoft no mercado de computação em nuvem, o Google Cloud se comprometeu a desempenhar o papel de "provedor neutro de poder computacional".
A conclusão desta cooperação será um grande benefício para o Google Cloud. Até o momento, a OpenAI, o Google e a Microsoft não comentaram esta reportagem.

Ao mesmo tempo, a OpenAI está acelerando a implantação de redes de infraestrutura de IA em todo o mundo.
No início deste ano, a OpenAI também avançou com o Projeto Stargate de US$ 500 bilhões com a SoftBank e a Oracle, e assinou um acordo multibilionário de aquisição de poder de computação com a CoreWeave.
Altos investimentos são baseados em altos retornos. De acordo com reportagens da mídia estrangeira desta semana, no ano passado, o ARR da OpenAI era de aproximadamente US$ 5,5 bilhões e agora ultrapassou US$ 10 bilhões, um aumento de quase 80%.
Vale ressaltar que os US$ 10 bilhões incluem apenas seus produtos voltados para o consumidor, produtos pagos do ChatGPT e receita de API, e não incluem a receita de licenciamento da Microsoft e outras transações de grande porte. No âmbito empresarial, a ARR refere-se à receita recorrente anual que uma empresa recebe de serviços de assinatura ou contratos de longo prazo. Ela reflete um fluxo de receita previsível e contínuo e é frequentemente usada para medir a saúde e o potencial de crescimento de negócios com modelo de assinatura.
Simplificando, uma empresa que fornece software como serviço (SaaS) tem um contrato de assinatura com um cliente que paga 1.000 yuans por ano. Se houver 100 clientes, a ARR da empresa será 1.000 yuans × 100 = 100.000 yuans.

Na semana passada, Brad Lightcap, COO da OpenAI, também revelou que a OpenAI conta atualmente com 3 milhões de usuários comerciais pagantes, número superior aos 2 milhões registrados em fevereiro. Podemos afirmar que a OpenAI está em uma situação muito boa no momento.
Ao mesmo tempo em que reduz o custo de modelos básicos por meio do o3 e melhora a capacidade de resolver problemas complexos com o o3-pro, a OpenAI está mirando cenários de alto valor e tentando abrir um caminho entre as duas pontas para a próxima curva de crescimento: serviços empresariais.
Os modelos mais poderosos do mundo são lançados um após o outro, e o OpenAI também é um deles nessa onda de IA.
Com modelos mais fortes, poder de computação mais estável e chamadas de ferramentas mais abundantes, o ChatGPT não é mais apenas um chatbot, mas um parceiro de produtividade projetado para assumir o cenário de aplicação mais produtivo: o local de trabalho.
o3-pro é um novo marco nessa jornada.
Se ele poderá atender à ambição da OpenAI ainda será verificado com o tempo. Mas, pelo menos agora, ele fez as pessoas o reinventarem.
O modelo será de código aberto, mas não em junho
Agora mesmo, Sam Altman disse nas redes sociais que a OpenAI espera lançar um modelo de código aberto com pesos públicos no final deste verão, em vez de junho.

Além disso, Altman acaba de lançar seu novo blog pessoal, The Gentle Singularity, que explora o impacto do desenvolvimento da IA na sociedade humana, e ressalta que este pode ser o último artigo que ele escreve sem a ajuda da IA.
Em suas palavras, da perspectiva da relatividade, as singularidades ocorrem pouco a pouco, enquanto a fusão prossegue lentamente.
Em anexo está o endereço original do blog: https://blog.samaltman.com/the-gentle-singularity

Singularidade suave
Cruzamos o horizonte de eventos, a decolagem começou, a humanidade está perto de construir uma superinteligência digital e, pelo menos até agora, não é tão estranho quanto parece.
Robôs ainda não são onipresentes nas ruas, e a maioria das pessoas não interage com IA o dia todo. Pessoas ainda morrem de doenças, viajar para o espaço ainda é difícil e nossa compreensão do universo ainda é muito limitada.
No entanto, construímos recentemente sistemas que são mais inteligentes que os humanos em muitos aspectos e que podem ampliar significativamente a produção humana. As partes mais improváveis já foram alcançadas — os avanços científicos que possibilitaram sistemas como GPT-4 e O3 foram conquistados com muito esforço, mas nos levarão muito mais longe.
A IA contribuirá para o mundo de muitas maneiras, mas as melhorias na qualidade de vida que ela proporcionará, acelerando o progresso científico e aumentando a produtividade, serão enormes; o futuro promete ser muito melhor do que o presente. O progresso científico é o maior impulsionador do progresso geral; é emocionante pensar em quanto mais temos potencial para alcançar.
Em certo sentido, o ChatGPT já é mais poderoso do que qualquer outro na história. Centenas de milhões de pessoas dependem dele todos os dias, e as tarefas estão se tornando cada vez mais importantes; um pequeno recurso adicional pode ter um enorme impacto positivo, enquanto uma pequena incompatibilidade também pode causar um enorme impacto negativo quando usado por centenas de milhões de pessoas.
Em 2025, veremos agentes inteligentes capazes de realizar trabalho cognitivo real; a maneira como escrevemos códigos de computador será revolucionada. Em 2026, provavelmente veremos sistemas capazes de gerar insights originais. Em 2027, talvez robôs capazes de realizar tarefas no mundo real.
Mais pessoas poderão criar software e arte. Mas a demanda mundial por ambos também aumentará drasticamente. Especialistas que adotarem essas novas ferramentas provavelmente ainda serão muito melhores do que novatos. No geral, uma pessoa realizará muito mais em 2030 do que em 2020, e a mudança será drástica, e muitas pessoas aprenderão como se beneficiar dela.
Em aspectos mais importantes, a década de 2030 pode não representar uma mudança radical. As pessoas continuarão a amar suas famílias, a liberar sua criatividade, a brincar e a nadar em lagos.
Mas, em outros aspectos que ainda importam, a década de 2030 provavelmente será muito diferente de qualquer era anterior. Não conhecemos os limites máximos da inteligência humana, mas estamos prestes a descobri-los.
Até a década de 2030, inteligência e energia — ideias e a capacidade de concretizá-las — se tornarão extremamente abundantes. Esses dois fatores têm sido, há muito tempo, os limites fundamentais para o progresso humano; se inteligência e energia fossem abundantes (além de uma boa governança), poderíamos, teoricamente, alcançar qualquer coisa.
Vivemos agora com uma inteligência digital incrível e, após o choque inicial, a maioria das pessoas se acostumou a ela. Em breve, deixaremos de nos maravilhar com a capacidade da IA de escrever belos parágrafos para esperar que ela escreva romances inteiros; de ficarmos maravilhados com sua capacidade de diagnosticar doenças para esperar que ela desenvolva curas; de ficarmos maravilhados com sua capacidade de escrever pequenos programas para esperar que ela possa criar empresas inteiras. Este é o caminho da Singularidade: milagres se tornam rotina e, então, se tornam o ponto de partida.
Cientistas nos disseram que estão trabalhando de duas a três vezes mais eficientemente do que antes. Uma das razões mais importantes pela qual a IA avançada é tão significativa é que podemos usá-la para acelerar a própria pesquisa em IA. Podemos descobrir novos materiais computacionais, algoritmos melhores e possibilidades ainda mais desconhecidas. Se conseguirmos concluir dez anos de pesquisa em um ano ou mesmo em um mês, a velocidade do progresso obviamente será muito diferente.
A partir de agora, as ferramentas que temos nos ajudarão a descobrir mais insights científicos e a criar sistemas de IA mais avançados. É claro que isso ainda não significa que a IA atualize completamente seu próprio código de forma autônoma, mas é de fato a forma inicial de "autoaperfeiçoamento recursivo".
Existem outros ciclos de autorreforço em andamento. O valor econômico da IA impulsiona a construção de infraestrutura, e cada vez mais recursos estão sendo usados para operar esses poderosos sistemas de IA. E robôs capazes de construir outros robôs (e, de certa forma, data centers capazes de construir outros data centers) não estão longe.
Se tivéssemos que construir o primeiro milhão de robôs humanoides da maneira tradicional, mas eles pudessem então assumir toda a cadeia de suprimentos — mineração e refino de minerais, direção de caminhões, operação de fábricas e assim por diante — e construir mais robôs, fábricas de chips e data centers, o ritmo do progresso seria muito diferente.
À medida que a produção em data centers se torna cada vez mais automatizada, o custo da inteligência deve eventualmente se aproximar do custo da eletricidade. (Muitas pessoas estão preocupadas com a quantidade de energia que o ChatGPT usa por consulta; uma consulta média consome cerca de 0,34 watts-hora, aproximadamente o mesmo que ligar um forno por pouco mais de um segundo ou usar uma lâmpada eficiente por alguns minutos. Além disso, cada consulta consome cerca de 0,000085 galões de água, o que equivale a cerca de um décimo quinto de uma colher de chá.)
O ritmo do progresso tecnológico continuará a acelerar, e os humanos são altamente adaptáveis. Embora haja desafios difíceis, como o desaparecimento de categorias inteiras de empregos, por outro lado, a riqueza mundial crescerá tão rapidamente que teremos a oportunidade de considerar seriamente novas políticas que antes não eram possíveis. Podemos não estabelecer um novo contrato social de uma só vez, mas olharemos para trás décadas depois e veremos que o acúmulo de mudanças graduais trouxe uma enorme transformação.
Se a história servir de guia, sempre encontraremos novas coisas para fazer, novos desejos para perseguir e nos adaptaremos rapidamente a novas ferramentas (as mudanças ocupacionais após a Revolução Industrial são um bom exemplo). As expectativas das pessoas aumentarão, mas suas habilidades também aumentarão rapidamente, e teremos vidas melhores. Criaremos cada vez mais coisas maravilhosas uns para os outros. Os humanos têm uma vantagem importante e de longo prazo sobre a IA: nos preocupamos naturalmente com as outras pessoas e com o modo como elas pensam e agem, enquanto não temos sentimentos pelas máquinas.
Se um agricultor de subsistência, há mil anos, visse a maneira como vivemos hoje, pensaria que estávamos fazendo "trabalhos falsos", como se estivéssemos apenas nos divertindo porque tínhamos fartura de comida e um luxo inimaginável. Espero que vejamos esses trabalhos da mesma forma daqui a mil anos – como "muito falsos", mas sem dúvida essas pessoas verão seu trabalho como extremamente importante e gratificante.
Haverá muitos novos milagres no futuro. É difícil imaginar que avanços alcançaremos até 2035. Podemos estar resolvendo problemas de física de alta energia este ano e colonizando o espaço no ano que vem. Ou podemos fazer um grande avanço na ciência dos materiais este ano e criar uma interface cérebro-computador de banda larga verdadeiramente alta no ano que vem. Muitas pessoas escolherão continuar vivendo como vivem agora, mas certamente haverá pessoas que escolherão "se conectar ao sistema".
Olhando para o futuro, essas coisas podem parecer inimagináveis agora. Mas quando você as vivencia de fato, elas podem ser incríveis, mas ainda assim estão sob controle. Da perspectiva da relatividade, a singularidade acontece aos poucos, e a convergência é gradual. Estamos escalando esse longo arco de crescimento exponencial em tecnologia; sempre parece uma vertical íngreme quando olhamos para frente, e parece uma linha reta quando olhamos para trás, mas na verdade é uma curva suave. (Olhando para 2020, se disséssemos naquela época que estaríamos próximos da IA em 2025, pareceria loucura, mas comparado com tudo o que aconteceu nos últimos cinco anos, talvez a previsão atual não seja tão absurda.)
É claro que ainda enfrentamos muitos desafios sérios. Precisamos resolver questões de segurança nos níveis técnico e social, mas, depois disso, o mais importante é garantir que a superinteligência seja amplamente acessível, pois está relacionada à estrutura econômica. O melhor caminho a seguir pode incluir as seguintes etapas:
Primeiro, precisamos resolver o “problema de alinhamento”, ou seja, podemos garantir que o sistema de IA possa aprender e realizar nossos verdadeiros desejos coletivos a longo prazo (a mídia social é um exemplo de falha de alinhamento: algoritmos de recomendação são muito bons em fazer você continuar rolando, mas eles fazem isso explorando as preferências de curto prazo do cérebro para suprimir seus objetivos de longo prazo).
Em seguida, concentre-se em tornar a superinteligência barata, onipresente e distante do controle centralizado de um único indivíduo, empresa ou país. A sociedade é resiliente, criativa e capaz de se adaptar rapidamente. Se conseguirmos liberar a vontade e a sabedoria coletivas, aprenderemos e nos ajustaremos rapidamente, apesar dos erros e interrupções, para maximizar os benefícios e minimizar os riscos. Dar aos usuários mais liberdade dentro das amplas estruturas estabelecidas pela sociedade será crucial. Quanto mais cedo o mundo começar a discutir essas estruturas e como definir "alinhamento coletivo", melhor.
Nós (toda a indústria, não apenas a OpenAI) estamos construindo um "cérebro" para o mundo. Esse cérebro será altamente personalizado e fácil de usar para todos; seus limites serão determinados por nossas boas ideias. Por muito tempo, a comunidade tecnológica sempre riu dessas "pessoas de ideias" — aquelas que têm uma ideia, mas não conseguem realizá-la. Agora, parece que a hora delas finalmente chegou.
A OpenAI é muita coisa hoje em dia, mas ainda é fundamentalmente uma empresa de pesquisa em superinteligência. Ainda temos muito trabalho a fazer, mas o caminho está iluminado e a escuridão está se dissipando rapidamente. Somos extremamente gratos por podermos fazer isso.
A frase "Smartphones são quase de graça" está quase aqui. Pode parecer loucura, mas se disséssemos em 2020 que chegaríamos lá em 2025, soaria ainda mais louco do que se estivéssemos prevendo 2030 agora.
Que possamos avançar de forma suave, exponencial e constante para a era da superinteligência.
#Bem-vindo a seguir a conta pública oficial do iFanr no WeChat: iFanr (ID do WeChat: ifanr), onde mais conteúdo interessante será apresentado a você o mais breve possível.
