
Morning Post OpenAI lança Sora 2: vídeo de IA entra na era GPT-3.5 / Luo Yonghao chama as fontes pequenas da Xiaomi de uma prática ruim do setor / Bateria do anel da Samsung estoura e dedo do usuário preso nela busca atendimento médico


OpenAI lança Sora 2: vídeo de IA entra em seu "momento GPT-3.5"

Luo Yonghao discute a controvérsia da "fonte pequena" da Xiaomi: toda empresa faz isso

A bateria do Galaxy Ring estufa e não pode ser removida. Vítima: Nunca mais usarei um anel inteligente

Google atualiza seu logotipo "G" com um design gradiente mais brilhante

O relatório financeiro do primeiro semestre da OpenAI revela uma receita de aproximadamente US$ 4,3 bilhões

Deli Group pede desculpas pelo incidente em que um funcionário manco foi demitido no primeiro dia de trabalho

O prédio da subsede da Faraday Future pegou fogo; resposta oficial: não tem nada a ver com carros de produção

Yushu Technology responde a vulnerabilidades de segurança de robôs: a maioria das correções foi concluída

Ideal Auto lança plano de garantia fiscal para compra do i6 durante o Ano Novo

CEO da Ford alerta: desenvolvimento de IA nos EUA mascara 'crise dos trabalhadores'

Oli, um robô humanoide em tamanho real, se torna um "caddie cibernético": pegando bolas e agachando-se autonomamente

Sony lança sensor de obturador global de 100 megapixels e 100 fps

Nothing CMF lança novos fones de ouvido por 699,3 yuans

Lançamento do Doubao Modelo 1.6-vision: atualização abrangente de recursos multimodais e suporte para geração de imagens

Zhipu GLM-4.6 é lançado oficialmente: recursos de código alinhados com os principais modelos do mundo

A equipe de Bailing lançou um modelo de pensamento em escala de trilhões, melhorando significativamente as capacidades de raciocínio.

OpenAI lança Sora 2: vídeo de IA entra em seu "momento GPT-3.5"
A OpenAI lançou oficialmente hoje o modelo de geração de vídeo de IA de nova geração Sora 2 e, simultaneamente, lançou o aplicativo Sora para usuários C-end.
As autoridades chamaram isso de "momento GPT-3.5" para a geração de vídeos por IA, marcando a mudança da tecnologia do estágio de demonstração para a aplicação em larga escala.
Atualização do núcleo do Sora 2:
- Pela primeira vez, é alcançada a geração síncrona de áudio e vídeo, que pode gerar simultaneamente imagens e sons ambientes correspondentes, sons interativos e diálogos.
- Precisão física significativamente melhorada, com efeitos de movimento e fluidos mais alinhados com a dinâmica do mundo real
- Resolução de imagem aprimorada e realismo de detalhes, recursos de controle de estilo mais flexíveis
- Consistência de comando aprimorada e maior controlabilidade de cenas complexas em todas as lentes
Destaques do aplicativo Sora:
- Cameo: os usuários podem integrar perfeitamente sua imagem e voz em cenas geradas por IA
- 「Remix」: Suporta criação secundária ou remixagem de vídeos de outras pessoas para gerar conteúdo em conjunto
- Todos os vídeos no fluxo de informações são gerados por IA, e os usuários podem modificar diretamente as palavras do prompt ou adicionar sua própria imagem
O aplicativo Sora foi lançado nos EUA e Canadá, com suporte para versões iOS e web por meio de um mecanismo de código de convite. O Sora 2 será inicialmente gratuito, com usuários do ChatGPT Pro tendo acesso prioritário aos modelos Sora 2 Pro de maior qualidade. A OpenAI também planeja lançar uma API para desenvolvedores.
 Leitura relacionada: A OpenAI acaba de lançar o Sora 2! O momento do vídeo GPT-3.5 da IA chegou, e também há um aplicativo superdivertido | Link para download em anexo
Leitura relacionada: A OpenAI acaba de lançar o Sora 2! O momento do vídeo GPT-3.5 da IA chegou, e também há um aplicativo superdivertido | Link para download em anexo
Luo Yonghao discute a controvérsia da "fonte pequena" da Xiaomi: toda empresa faz isso

Recentemente, Luo Yonghao falou sobre as dúvidas online sobre as pequenas palavras no canto inferior direito do pôster "King of Backlight" da Xiaomi em uma transmissão ao vivo.
Ele afirmou que as práticas que vêm sendo acaloradamente discutidas no mundo exterior não são exclusivas da Xiaomi, mas sim um "mau hábito" em toda a indústria de telefonia móvel. Diversos fabricantes já utilizam métodos semelhantes há muito tempo.
Luo Yonghao destacou durante a transmissão ao vivo: "Muitas pessoas têm usado isso para desacreditar a Xiaomi ultimamente. Na verdade, essa é uma prática ruim do setor, que todas as empresas praticam. Não é exclusividade da Xiaomi. A indústria de telefonia móvel sempre fez isso. Se você não acredita em mim, vá conferir você mesmo."
Ele disse sem rodeios: "Não estou dizendo que isso é a coisa certa a fazer", mas é injusto que a opinião pública concentre o problema na Xiaomi.
Recentemente, Wan Zhiqiang, CMO do Meizu Group, também fez uma declaração no Weibo sobre esse assunto.
Ele disse que as empresas adicionam notas nas promoções de produtos principalmente para cumprir com requisitos regulatórios.
Na realidade, tudo isso é feito para cumprir as regulamentações, e cada empresa terá algumas notas e explicações. No entanto, a Meizu enfatizou internamente que, preservando a semântica contextual, devemos tornar os qualificadores suplementares o mais claros possível para evitar induzir as pessoas em erro, e que o conceito do produto deve incluir valores.
Naquela tarde, Luo Yonghao respondeu aos internautas no Weibo, expressando sua esperança de que, após esse incidente, a indústria seria capaz de eliminar "letras pequenas enganosas", mas que "letras grandes e pequenas não enganosas ainda são necessárias às vezes".

A bateria do Galaxy Ring estufa e não pode ser removida. Vítima: Nunca mais usarei um anel inteligente
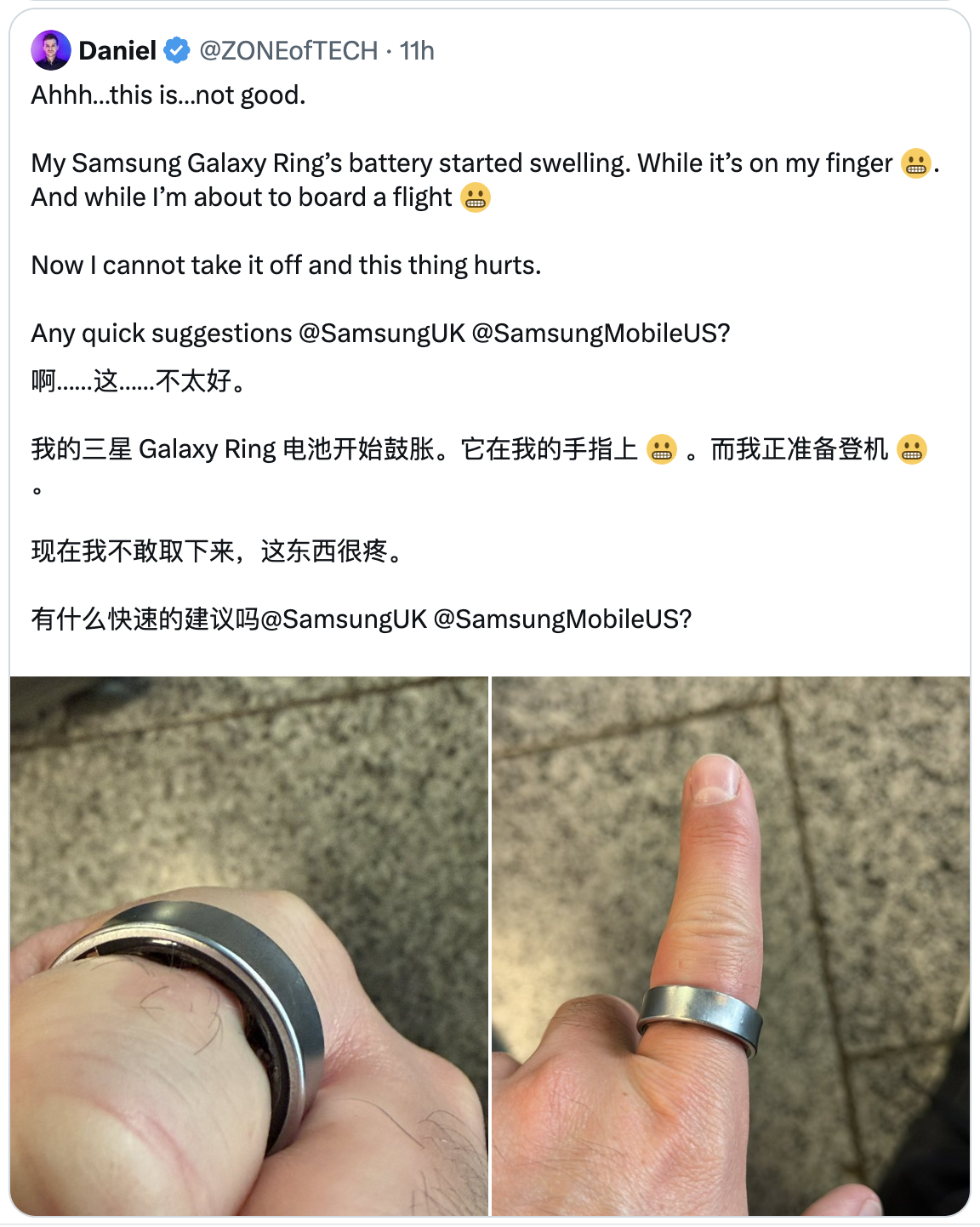
Ontem, o blogueiro de tecnologia estrangeiro Daniel (@ZONEofTECH) postou no X que a bateria do Samsung Galaxy Ring que ele estava usando inchou antes que ele embarcasse em um avião, fazendo com que o anel ficasse preso em seu dedo e não pudesse ser removido.
Devido à situação de emergência, ele foi levado ao hospital, onde o anel foi finalmente removido com a ajuda de gelo e lubrificante médico.
"A bateria do meu Galaxy Ring começou a inchar no meu dedo quando eu estava prestes a embarcar em um voo, não consegui remover o anel e foi extremamente doloroso", disse Daniel.
Ele acrescentou que o incidente resultou na recusa do embarque, no pagamento de uma diária extra em hotel e no atraso da viagem de volta. Daniel legendou a foto: "Dá para ver que a bateria está completamente inchada. Nunca mais usarei um anel inteligente."
Ele especula que as possíveis causas incluem "altas temperaturas no Havaí, contato com água salgada, voo contínuo" e "defeitos na própria bateria".
Ele também observou que a duração da bateria do dispositivo tem sido baixa nos últimos meses.
Até o momento, a Samsung não fez uma resposta pública sobre este incidente.
Daniel enfatizou: "Qualquer dispositivo que tenha uma bateria e precise ser usado próximo ao corpo deve ser projetado para ser muito fácil de remover para evitar que a bateria inche."
Google atualiza seu logotipo "G" com um design gradiente mais brilhante

Recentemente, o Google anunciou uma atualização para seu icônico ícone "G", permitindo um design de gradiente de quatro cores mais brilhante.
Autoridades disseram que o design foi aplicado inicialmente aos serviços de busca no início deste ano e agora será estendido a todos os produtos e plataformas da empresa.
O Google disse que o novo ícone, embora mantenha as quatro cores clássicas, simboliza a vitalidade inovadora e a energia criativa da era da IA por meio de um efeito gradiente mais distinto.
Anteriormente, esse design foi aplicado primeiro a produtos relacionados à Gemini e será gradualmente estendido a mais serviços nos próximos meses.
O relatório financeiro do primeiro semestre da OpenAI revela uma receita de aproximadamente US$ 4,3 bilhões

De acordo com o The Information, a OpenAI obteve uma receita de aproximadamente US$ 4,3 bilhões no primeiro semestre de 2025, um aumento anual de 16%, superando o nível de todo o ano passado.
O relatório destacou que o investimento operacional e em P&D da OpenAI no mesmo período chegou a US$ 6,7 bilhões, incluindo o custo de treinamento em larga escala e execução do ChatGPT, resultando em um consumo de caixa de aproximadamente US$ 2,5 bilhões.
A OpenAI detinha aproximadamente US$ 17,5 bilhões em caixa e títulos no final do primeiro semestre do ano. A empresa espera que a receita anual atinja US$ 13 bilhões e limite a queima de caixa a menos de US$ 8,5 bilhões.
Além disso, a Nvidia planeja investir até US$ 100 bilhões na OpenAI e fornecer suporte para chips de data center. Relatos anteriores sugeriram que a OpenAI está considerando vender ações de funcionários, o que pode avaliar a empresa em US$ 500 bilhões.
Deli Group pede desculpas pelo incidente em que um funcionário manco foi demitido no primeiro dia de trabalho

O Deli Group emitiu ontem uma declaração de desculpas em resposta ao incidente online muito debatido de "ser demitido no dia em que entrou na empresa por mancar".
A empresa afirmou que, após investigação e verificação por uma equipe especial, a situação relatada pelo funcionário era basicamente verdadeira.
O presidente executivo do grupo pediu desculpas imediatamente à pessoa envolvida e providenciou que o diretor do gabinete presidencial se comunicasse diretamente. Esta manhã, ele até enviou alguém até o local da pessoa na esperança de expressar seu pedido de desculpas pessoalmente.
O comunicado destacou que o incidente expôs as deficiências da empresa na implementação de valor e nos mecanismos de gestão interna. Para tanto, o Deli Group anunciou que tomaria três medidas corretivas:
- Responsabilizar os envolvidos de acordo com os regulamentos e disciplinas;
- Revisar de forma abrangente o processo de gestão de recursos humanos para eliminar quaisquer padrões discriminatórios ou ocultos que possam existir;
- Fortalecer o treinamento antidiscriminação para todos os funcionários, melhorar os sistemas de gestão e garantir a implementação de conceitos culturais.
O Deli Group enfatizou que implementará a retificação com os padrões mais rigorosos, otimizará continuamente o mecanismo de gestão de recursos humanos e implementará firmemente a filosofia de emprego "orientada para as pessoas".
O prédio da subsede da Faraday Future pegou fogo; resposta oficial: não tem nada a ver com carros de produção

Ontem, a Faraday Future publicou oficialmente um artigo no Weibo informando que um incêndio ocorreu em um prédio de escritórios na sede da Faraday Future nos EUA na manhã de 28 de setembro, horário do Pacífico.
A empresa enfatizou em seu comunicado que o incidente não causou vítimas e que as operações na sede estavam normais.
As divulgações oficiais incluem:
- O incêndio começou em um carro de exposição FF 91 dentro do prédio. A parede do prédio de escritórios ficou levemente danificada, mas o vidro estava intacto.
- Tendo inicialmente descartado a possibilidade de incêndio ou explosão da bateria, a causa mais provável é um curto-circuito no circuito do salão de exposições ou mau contato na linha de baixa tensão de 12 V;
- O veículo envolvido tem o codinome B40, um dos primeiros protótipos BETA do FF 91. Está em uso há quase 9 anos. Seu sistema de energia e bateria são versões iniciais, e os materiais do seu interior não atendem aos padrões de retardamento de chamas para veículos produzidos em massa.
A empresa enfatizou que o veículo acidentado é completamente diferente do veículo produzido em massa, portanto não acionará um recall do veículo produzido em massa FF 91.
As autoridades declararam: "A segurança é sempre nossa maior prioridade. Este incidente serve como um alerta para a prevenção de incêndios em nossos escritórios. A empresa concluirá sua investigação final o mais breve possível e implementará as medidas de melhoria necessárias."
Yushu Technology responde a vulnerabilidades de segurança de robôs: a maioria das correções foi concluída

Reportagens da mídia indicam que o IEEE Spectrum revelou recentemente que vários modelos de robôs da Yushu Technology têm vulnerabilidades críticas ao configurar interfaces Wi-Fi via BLE (Bluetooth Low Energy), o que pode permitir que invasores obtenham o mais alto nível de controle.
Em resposta, a Yushu Technology emitiu uma declaração na plataforma social dizendo que a empresa iniciou os reparos o mais rápido possível, a maioria dos problemas foi resolvida e atualizações subsequentes serão lançadas em breve.
A Yushu Technology enfatizou que seus produtos robóticos são projetados para uso offline por padrão e não se conectarão ativamente à Internet; o dispositivo só será conectado à rede quando configurado manualmente e autorizado pelo usuário.
Após a conexão, o robô pode enviar informações básicas, como número de série e status de saúde, para o servidor. Esse mecanismo é semelhante ao de dispositivos eletrônicos, como smartphones.
A empresa também declarou que continuará otimizando o mecanismo de gerenciamento de permissões para reduzir possíveis mal-entendidos e melhorar a experiência de segurança do usuário.
Ideal Auto lança plano de garantia fiscal para compra do i6 durante o Ano Novo
A Ideal Auto anunciou ontem que, em resposta às preocupações dos usuários sobre possíveis mudanças nas políticas de impostos de compra devido a entregas entre anos, lançou oficialmente o "Plano de subsídio de impostos de compra entre anos do Ideal i6" com o título "Há uma garantia, compre com confiança!"
De acordo com a introdução oficial, os usuários que concluírem o bloqueio do pedido antes de 31 de outubro de 2025, se o faturamento e a entrega precisarem ser concluídos em 2026 devido a motivos da Ideal Auto, poderão aproveitar o subsídio de imposto de compra entre anos.
O subsídio é na forma de uma redução em dinheiro no pagamento final, e o valor será deduzido da diferença de imposto de compra correspondente com base na configuração do veículo para garantir que os usuários não precisem arcar com despesas adicionais de imposto de compra.
Ao mesmo tempo, o Ideal i6 também oferece benefícios de primeira venda no valor de até 35.000 yuans, incluindo:
- Redução de caixa de 10.000 yuans;
- Uma suspensão a ar de câmara dupla tipo tapete mágico avaliada em 15.000 yuans é distribuída gratuitamente;
- Uma geladeira inteligente com função de resfriamento e aquecimento no valor de RMB 5.000 será distribuída gratuitamente;
- O veículo inteiro será entregue gratuitamente, com portas elétricas silenciosas de sucção, no valor de 5.000 yuans.
Vale ressaltar que os usuários podem modificar a configuração ou solicitar o reembolso em até 7 dias após o pagamento do depósito. Após esse prazo, o pedido não poderá ser modificado ou cancelado, e o depósito não será reembolsável.
A Ideal disse que o volume atual de pedidos do i6 superou as expectativas e que a empresa está trabalhando duro para aumentar a capacidade de produção, reduzir o tempo de espera de entrega e permitir que os usuários retirem seus carros o mais rápido possível.
CEO da Ford alerta: desenvolvimento de IA nos EUA mascara 'crise dos trabalhadores'

De acordo com o The Verge, em uma entrevista recente, o CEO da Ford, Jim Farley, mencionou que, embora a sociedade americana esteja discutindo acaloradamente como a IA pode melhorar a produtividade dos trabalhadores de colarinho branco, ela tem ignorado a grave escassez de empregos básicos e na indústria.
Ele ressaltou que atualmente há uma escassez de mais de 500.000 trabalhadores na indústria e 500.000 trabalhadores na construção civil nos Estados Unidos, e que empregos da "economia básica", como emergências, bombeiros, médicos e técnicos, também estão enfrentando uma crise.
Farley enfatizou que as ferramentas de IA estão mudando rapidamente a eficiência do trabalho de escritório, mas os cargos de colarinho azul não recebem o mesmo suporte técnico e recursos de treinamento. "Trabalhadores de colarinho branco têm IA, mas os de colarinho azul não."
Ele alertou que esse desequilíbrio representa uma ameaça maior ao desenvolvimento sustentável da sociedade do que a própria IA.
Para enfrentar esse desafio, a Ford investiu US$ 1 bilhão para melhorar as condições de fábrica e promover programas de treinamento e bolsas de estudo para trabalhadores qualificados.
Farley apelou à sociedade para que reconheça a importância da "economia básica" e restaure o respeito e o apoio às ocupações de colarinho azul. "Devemos investir recursos para melhorar a produtividade dos empregos de colarinho azul, assim como damos atenção à IA."

Oli, um robô humanoide em tamanho real, se torna um "caddie cibernético": pegando bolas e agachando-se autonomamente
Recentemente, o robô humanoide em escala real Oli demonstrou as novas capacidades de um "cybercaddy". O robô pode identificar, rastrear, pegar e posicionar bolas de tênis de forma autônoma, além de realizar posturas complexas como caminhar, se curvar e agachar.
A locomoção de corpo inteiro de Oli com percepção ativa não requer dados de captura de movimento e não depende de controle remoto; todo o processo é completamente autônomo.
Oli tem 1,65 metro de altura e um total de 43 graus de liberdade, incluindo 31 no corpo e 12 nas mãos hábeis. O alcance de rastreamento de suas mãos pode cobrir um máximo de 2 metros na vertical e 1,8 metro na horizontal.
Vale a pena notar que o movimento de agachamento de Oli é estável e natural, e o processo de operação é suave, o que é bastante semelhante ao clipe de Neo agachando para pegar roupas na recente transmissão ao vivo do Speed no 1X.
Ambos os robôs humanoides de tamanho real demonstraram coordenação ao agachar e se esticar para frente, movimentos extremamente desafiadores para robôs humanoides de pernas longas.
Sony lança sensor de obturador global de 100 megapixels e 100 fps

De acordo com a PetaPixel, a Sony Semiconductor lançou oficialmente a nova geração do sensor de imagem de alto desempenho IMX927.
Este é um sensor CMOS empilhado com iluminação traseira, design de obturador global, resolução de aproximadamente 105 milhões de pixels e suporte para saída de alta velocidade de até 100 quadros por segundo.
Segundo relatos, o tamanho diagonal do sensor IMX927 é de 39,7 mm, o que é próximo da especificação full-frame.
Seu núcleo é equipado com a tecnologia de obturador global Pregius S, desenvolvida pela Sony, que proporciona processamento de dados de alta velocidade e baixo consumo de energia, otimizando a leitura de pixels e o conversor A/D.
A Sony declarou: "Essa combinação de alta resolução e alta taxa de quadros ajudará a melhorar a produtividade no setor de equipamentos industriais e atenderá às necessidades cada vez mais diversas de reconhecimento e inspeção."
A série IMX927 usa um novo pacote de cerâmica com um conector padronizado integrado e suporta vários formatos de interface, facilitando para os fabricantes de câmeras integrá-los rapidamente em seus projetos.
Esta série oferece um total de 16 produtos, todos com design destacável, facilitando a substituição dos sensores de acordo com os cenários de aplicação.
Em termos de especificações, o IMX927 suporta modos de saída de 8/10/12 bits, correspondendo a velocidades de disparo de 112, 102 e 73 quadros por segundo, respectivamente.
O sensor gera imagens quadradas com um tamanho de quadro de 10.272 × 10.272 pixels e suporta vários modos de agrupamento de pixels para equilibrar sensibilidade e velocidade.
A Sony enfatizou que esse sensor não é adequado apenas para cenários de inspeção de alta precisão, como semicondutores e painéis, mas também pode fornecer imagens de alta resolução, sem distorção e com baixo ruído, na geração de imagens de objetos grandes, promovendo assim câmeras de visão de máquina para obter medições e inspeções de maior precisão em mais aplicações industriais.
Nothing CMF lança novos fones de ouvido por 699,3 yuans

A CMF, marca da Nothing, lançou hoje dois novos produtos simultaneamente no mercado chinês continental: o fone de ouvido Bluetooth Headphone Pro e o smartwatch Watch 3 Pro China Edition. Ambos os produtos já estão disponíveis para compra, apresentando alta relação custo-benefício e designs diferenciados.
Fone de ouvido CMF Pro: 699,3 yuans, 100 horas de duração da bateria
- Equipado com um driver de diafragma niquelado personalizado de 40 mm, uma bobina de voz de cobre de 16,5 mm, um duto de graves de precisão, um design de câmara dupla e uma bateria integrada de 720 mAh;
- Obteve certificação dupla Hi-Res para com fio/sem fio;
- Ele suporta redução de ruído ANC híbrido adaptável de 40 dB, tem um modo de transparência e é equipado com tecnologia ENC para recepção de som.
CMF Watch 3 Pro China Custom Edition: Preço inicial: 649 yuans
- Equipado com uma tela OLED circular de 1,43 polegadas, 466×466, 60Hz (brilho de 650 nits, brilho estimulado de 670 nits);
- 120 mostradores de relógio personalizáveis integrados e suporte à função exclusiva "mostrador de relógio de vídeo";
- Equipado com um motor linear de eixo Z e proteção IP68, ele é anunciado como "o único GPS de frequência dupla em um relógio de médio porte".
- Bateria integrada de 350mAh, o uso típico dura 13 dias e pode ser totalmente carregada em 99 minutos.
Lançamento do Doubao Modelo 1.6-vision: atualização abrangente de recursos multimodais e suporte para geração de imagens

Ontem, a Volcano Engine lançou oficialmente o "Doubao Big Model 1.6-vision", que se concentra na compreensão multimodal e nas capacidades de geração. As inscrições para testes já estão abertas no site oficial.
Segundo relatos, o "1.6-vision" possui recursos de geração de imagens, resposta a perguntas sobre imagens, compreensão de imagens, etc. Ele suporta o upload de imagens para reconhecimento de conteúdo, análise de cenas, raciocínio misto imagem-texto e outras tarefas. É adequado para diversos cenários, como comércio eletrônico, educação e redes sociais.
A Volcano Engine disse que a nova versão introduziu o recurso "texto para imagem" na geração de imagens, suporta entrada de texto para gerar imagens, adapta-se a uma variedade de estilos e tamanhos e pode ser combinada com palavras de prompt para controle de conteúdo.
Além disso, o "1.6-vision" também atualizou seus recursos de resposta a perguntas de imagem, que podem reconhecer elementos complexos como objetos, texto, tabelas, mapas, etc. em imagens, oferecer suporte a diálogos multi-rodadas e compreensão de contexto, além de melhorar a precisão e a estabilidade do raciocínio multimodal.
Atualmente, o Doubao Big Model conta com acesso aberto à API e suporta entrada multimodal, como texto e imagens. Usuários corporativos podem solicitar um teste gratuito no site oficial do Volcano Engine.
Zhipu GLM-4.6 é lançado oficialmente: recursos de código alinhados com os principais modelos do mundo
Ontem, a Zhipu anunciou que seu principal modelo grande, o GLM-4.6, foi lançado oficialmente.
Segundo relatos, como a versão mais recente da série GLM, o modelo alcançou atualizações abrangentes em programação de código, processamento de contexto longo, raciocínio e pesquisa, e recursos de escrita.
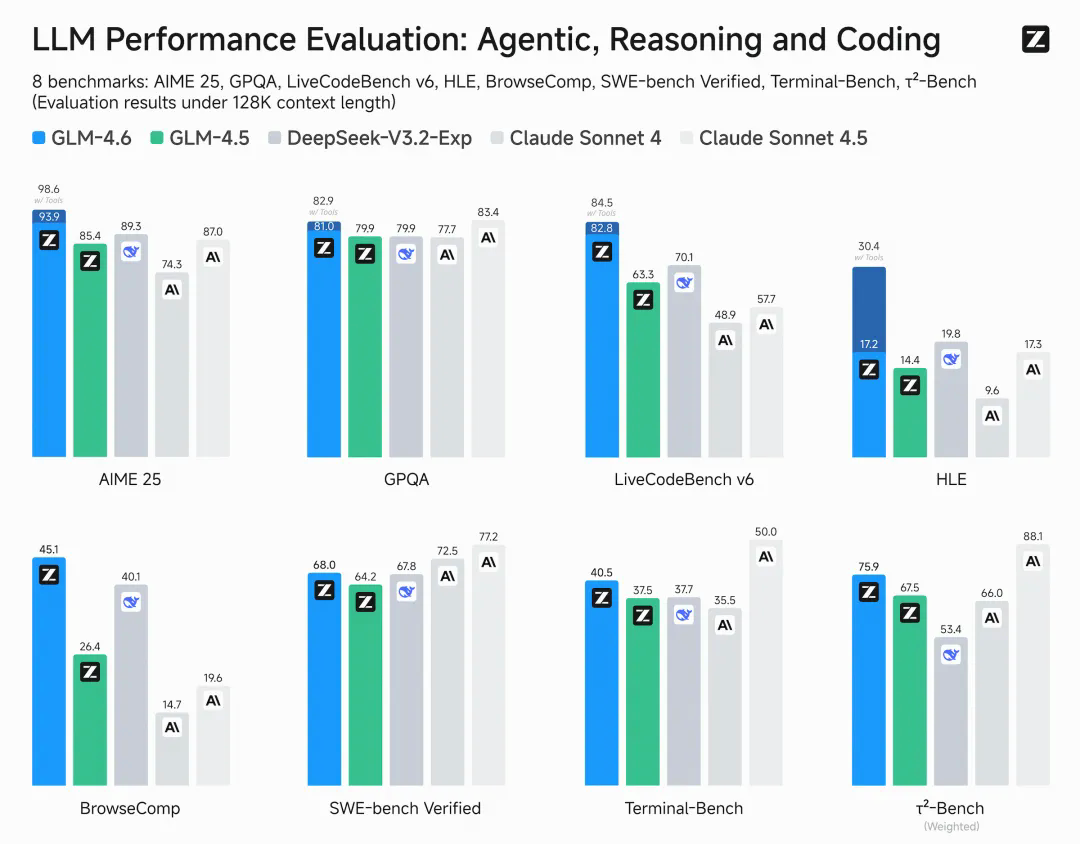
Dados oficiais mostram que a capacidade de codificação do GLM-4.6 é 27% superior à da geração anterior, o GLM-4.5. Em tarefas de programação do mundo real, ele foi alinhado ao "Claude Sonnet 4", tornando-se o modelo de codificação mais poderoso conhecido na China.
Em termos de processamento de contexto, o GLM-4.6 estende o comprimento da janela de 128K para 200K para melhor adaptação a códigos complexos e tarefas de agentes inteligentes.
Notavelmente, o GLM-4.6 implementou a quantização híbrida FP8+INT4 em chips Cambricon e roda de forma estável com precisão FP8 nativa em GPUs baseadas na Lei de Moore. Isso representa um avanço fundamental para chips produzidos internamente na inferência localizada para modelos de grande porte.
Em termos de avaliação, o GLM-4.6 teve um desempenho excepcional em oito benchmarks confiáveis, incluindo AIME 25 e SWE-Bench Verified. Alguns de seus resultados foram até comparáveis ao "Claude Sonnet 4/4.5", classificando-se firmemente em primeiro lugar entre os modelos nacionais.
Atualmente, o GLM-4.6 está totalmente disponível em bigmodel.cn, z.ai e Zhipu Qingyan. Usuários internacionais podem usar a API através do z.ai. O modelo também será de código aberto no Hugging Face e no ModelScope.
A equipe de Bailing lançou um modelo de pensamento em escala de trilhões, melhorando significativamente as capacidades de raciocínio.
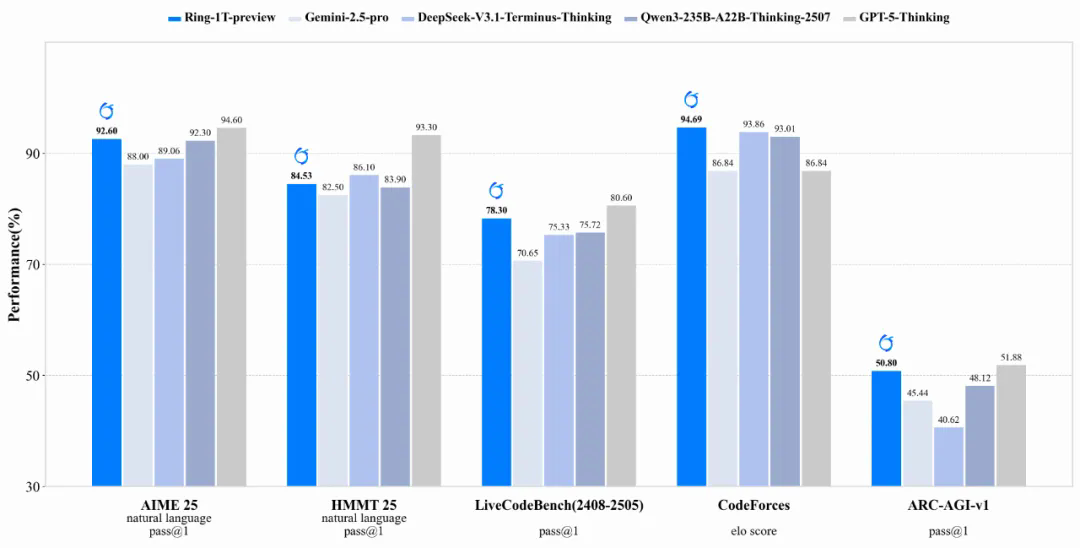
Ontem, a equipe do Bailing Big Model anunciou que o modelo de raciocínio "Ring-1T-preview", construído na base da linguagem 1T da família Ling 2.0, foi oficialmente disponibilizado como código aberto.
É relatado que o modelo demonstrou fortes capacidades de raciocínio em linguagem natural nos estágios iniciais do treinamento de aprendizagem por reforço em larga escala.
No AIME 2025 (American Invitational Mathematics Competition), "Ring-1T" alcançou uma pontuação de 92,6 com base apenas no raciocínio em linguagem natural, aproximando-se do nível 94,6 do GPT-5 com pensamento (sem ferramentas).
É relatado que o "Ring-1T-preview" continua a arquitetura MoE eficiente do Ling 2.0, conclui o pré-treinamento em um corpus de alta qualidade de 20T e combina o método "icepop" para executar o treinamento RLVR no sistema de aprendizado por reforço eficiente desenvolvido por nós mesmos, o ASystem.
A equipe disse que, embora a versão de pré-visualização tenha demonstrado fortes capacidades de raciocínio, ainda há problemas como mistura de idiomas, raciocínio repetido e erros de reconhecimento de identidade, e continuará a ser otimizada no futuro.
Atualmente, o "Ring-1T-preview" está disponível para download na plataforma Hugging Face. A equipe aguarda a exploração e o feedback da comunidade para, em conjunto, acelerar a iteração e o aprimoramento do modelo de base trilionária.

Os trens-leito "verticais de compartimento único" provocaram um debate acalorado durante o feriado do Dia Nacional. 12306 respondeu: Eles só funcionarão à noite.
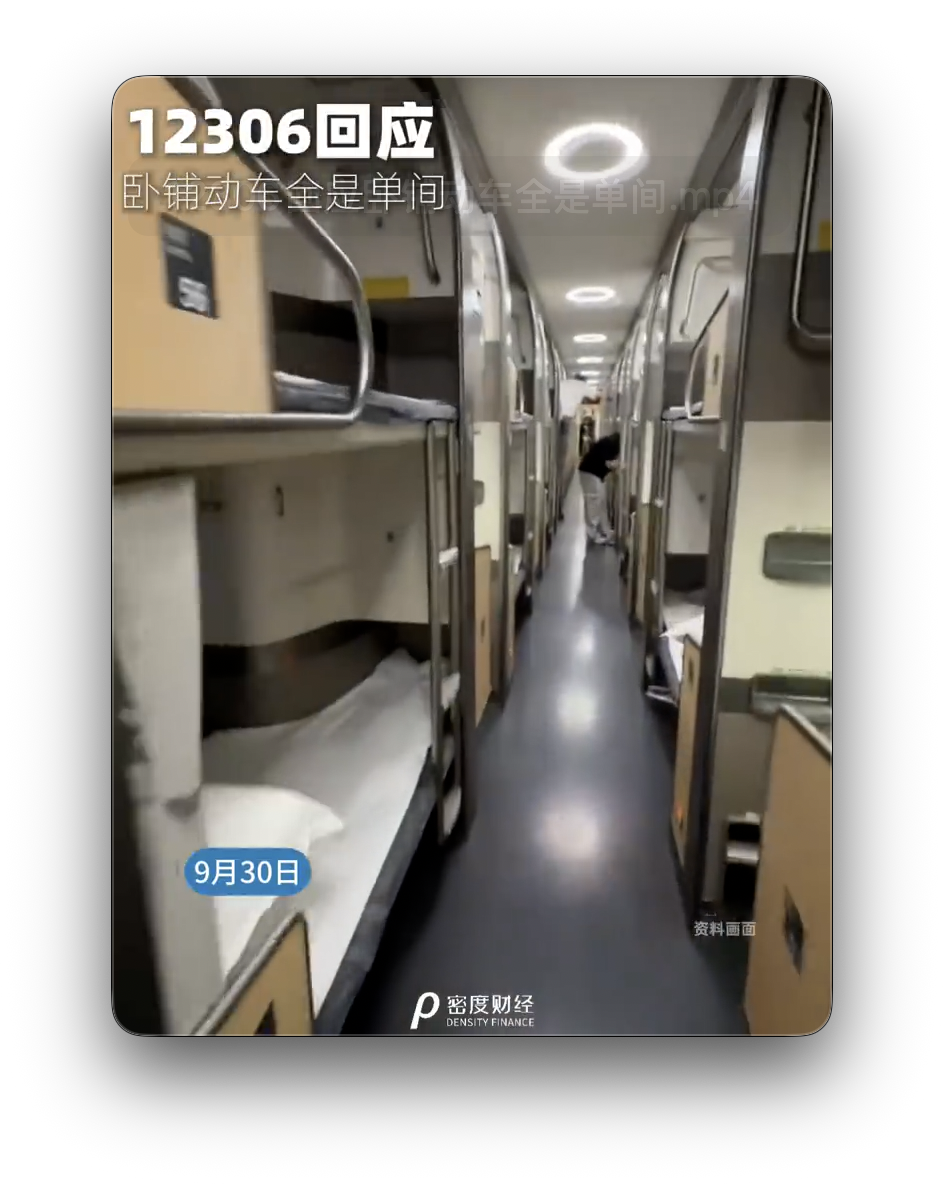
De acordo com a Dendi Finance, com a aproximação dos feriados do Dia Nacional e do Festival do Meio do Outono, muitos passageiros compartilharam suas experiências de viajar em trens-leito "verticais de quarto único" em plataformas sociais, chamando-os de "hotéis móveis", o que gerou uma ampla discussão.
De acordo com a equipe do 12306, este tipo de trem-leito longitudinal já está em operação há algum tempo e não haverá instruções especiais na página de compra de bilhetes. A situação específica será determinada no momento do embarque do passageiro. A equipe também afirmou que este tipo de trem é um modelo com "partida à noite e chegada pela manhã" e opera apenas à noite.
A China Railway divulgou anteriormente que o trem-leito opera entre Pequim Oeste e Shenzhen Norte, cobrindo uma distância total de 2.424 quilômetros. A linha terá serviço adicional durante os feriados, incluindo nos dias 30 de setembro, 1º de outubro, 2 de outubro, 7 de outubro e 8 de outubro.
Alguns internautas acreditam que o design de compartimento único evita efetivamente distrações entre estranhos, tornando-o mais adequado para viagens noturnas de longa distância. Outros reclamam que o layout longitudinal pode causar desconforto em altas velocidades. No geral, a experiência com este novo trem-leito continua gerando debate.
quebra-gelo Touch Lab abre em Chongqing MixC
A marca neozelandesa de lã merino para atividades ao ar livre, Icebreaker, inaugurou sua primeira loja em Chongqing. A nova loja está localizada no primeiro andar do Distrito Norte de Chongqing MixC.
No dia da inauguração, o amigo da marca, o jovem ator Chen Xinhai e muitos outros amigos da marca vieram apoiar.
A nova loja dá continuidade à linguagem visual consistente e ao temperamento natural da Icebreaker. Uma parede temática "100% Plastic-Free Journey" foi instalada no local, exibindo desde a seleção de ingredientes naturais e modelos de produção sustentáveis até a reprodução de logotipos de fazendas parceiras, destacando o conceito da marca de "coexistência harmoniosa entre o homem e a natureza".
A loja exibe uma gama completa de produtos de lã Merino, incluindo estilos básicos clássicos e roupas funcionais, abrangendo controle de temperatura, maciez, conforto para a pele, resistência a odores e antibacteriano, leveza e respirabilidade, além de recursos de lavagem à máquina, adequados para uso durante o ano todo e em vários cenários esportivos.
Na cerimônia de abertura, Chen Xinhai usou os novos produtos de outono e inverno desta temporada: jaqueta "Mao Ke" de lã merino e calças elásticas para atividades ao ar livre com mistura de lã merino.
A jaqueta "Maoke" é feita com 96,8% de matérias-primas naturais, combinando o processo de tecelagem compacta da lã merino com a membrana impermeável ecológica DWR. Possui propriedades à prova de vento, à prova d'água e ecologicamente corretas, proporcionando uma experiência de uso suave, macia e antiestática.
Dongpeng Special Drink e Xuanmai lançam em conjunto goma de mascar sem açúcar

De acordo com informações da Xiaoshidai, a Dongpeng Special Drink e a Xuanmai, uma subsidiária da Mondelez, anunciaram recentemente uma cooperação transfronteiriça e lançaram oficialmente a goma de mascar sem açúcar com sabor Dongpeng Special Drink.
Esta é a primeira vez que as duas partes quebram as barreiras de categoria e combinam bebidas energéticas e gomas de mascar, com o objetivo de proporcionar aos consumidores uma nova experiência de sabor e estímulo mental.
É relatado que este produto de marca compartilhada combina o sabor clássico do Dongpeng Special Drink com o fator menta do Xuanmai, formando um "BUFF" duplo.
Um lado se concentra em "beber refrescantemente", enquanto o outro enfatiza "mastigar com satisfação". Ambas as partes esperam criar uma "combinação de alta energia" no cotidiano dos jovens por meio dessa combinação.
A Dongpeng Special Drink disse que as equipes de ambos os lados passaram vários meses analisando todos os níveis de análise, desde pesquisa e desenvolvimento de sabores, polimento do sabor até design de embalagem e planejamento de marketing, e finalmente concluíram este produto inovador.
A goma de mascar de marca compartilhada será vendida em todo o país e promovida por meio de vários canais online e offline.
Dados da Nielsen mostram que a Dongpeng Special Drink foi responsável por 47,9% das vendas em 2024, ficando em primeiro lugar no mercado de bebidas energéticas da China por quatro anos consecutivos.
Com a ajuda dessa colaboração, a Dongpeng Special Drink espera se integrar ao grupo de consumidores jovens de uma forma mais leve, enquanto a Xuanmai deve romper o círculo da população com a ajuda dos canais e da base de usuários da Dongpeng Special Drink.
Sony e Reebok lançam tênis colaborativos para o 30º aniversário do PlayStation

Para comemorar o 30º aniversário do PlayStation, a Sony e a Reebok se uniram para lançar uma nova série conjunta de calçados.
Esta colaboração é inspirada nos consoles de jogos clássicos dos anos 90. Os três estilos de calçados serão lançados em quantidades limitadas nos Estados Unidos, Reino Unido e Japão, com cada região equipada com elementos de design exclusivos.
- O Reebok Workout Plus estará disponível no mercado do Reino Unido exclusivamente na END em 15 de outubro, oferecendo uma solução de cadarço duplo e acessórios removíveis;
- O Reebok Pump Omni Zone II estará disponível nos EUA a partir de 17 de outubro na CNCPTS em Nova York, com bolas de bomba personalizadas nas cores do PlayStation e detalhes retrô.
- O mercado japonês lançará o Reebok Instapump Fury 94 pela Beams em 24 de outubro. O design da lingueta incorpora o elemento "Press Play", uma homenagem ao console clássico de 1994.
Os três tênis apresentam cabedal cinza, ecoando a icônica paleta de cores do PlayStation original, com símbolos clássicos de botões adornados na língua e no calcanhar. Esta colaboração é vista como uma fusão entre a cultura gamer e a esportiva.

Sequência de 'Os Simpsons' com estreia prevista para o verão de 2027

A Disney e a 20th Century Fox anunciaram oficialmente que a sequência de "Os Simpsons" será lançada nos cinemas do mundo todo em 23 de julho de 2027. Este é o retorno da série 20 anos após o lançamento do primeiro filme em 2007.
Há relatos de que a sequência será supervisionada pelo próprio criador Matt Groening, dando continuidade ao estilo satírico e humorístico consistente da série.
O enredo do filme ainda não foi divulgado, mas a empresa divulgou nas redes sociais o icônico pôster do donut rosa, com o slogan "Homer quer fazer de novo", o que gerou discussões acaloradas entre os fãs.
Deafening lança novo trailer

O filme "Deafening" lançou hoje o trailer "Am I Wrong?". O filme aborda a experiência de crescimento do "Advogado da Escala de Cinza" Li Qi como tema principal e revela profundamente o trauma original e o verdadeiro dilema trazido pela identidade CODA.
O filme acompanha Li Qi, envolvido em um caso antifraude para surdos, à medida que ele gradualmente se encontra na encruzilhada entre o desejo e a moralidade. Apesar de resistir veementemente à conexão com sua identidade surda, ele revela, bêbado: "Desde o dia em que nasci, falo todos os dias, e ninguém consegue me ouvir". Essa frase toca profundamente, refletindo a situação complexa da comunidade CODA.
De acordo com a introdução oficial, o filme é parcialmente baseado nas experiências reais do advogado da CODA, Zhang Qi. O diretor Wan Li expressou sua esperança de que, por meio da história de Li Qi, ele transmitisse o valor de "ser seu próprio herói", permitindo que o público se identificasse e encontrasse coragem nas lutas e na redenção do personagem.
"Deafening" é dirigido por Tan Jianci, Lan Xiya e Wang Ge, com Wang Yanhui e Chi Peng como convidados especiais. O filme será exibido em todo o país de 2 a 3 de outubro e será lançado oficialmente em 4 de outubro.
"The Wandering Life" estreia hoje

O filme "Uma Vida Errante" estreou oficialmente nos cinemas de todo o país ontem.
O filme é produzido por Han Han e dirigido por Ma Lin, estrelado por Huang Bo, Fan Chengcheng, Yin Tao, Chang Yuan, Li Jiaqi, Liu Xuehua, Fu Hang e outros. Conta a história de uma família que "enlouquece" e luta pela sobrevivência para proteger seu lar em meio à adversidade.
O filme é uma adaptação do livro best-seller de Cai Chongda, "Skin", que é baseado em histórias reais e combina elementos de comédia, família e drama.
A reputação do filme continuou a crescer durante a pré-estreia, com uma pontuação Maoyan de 9,5 e uma taxa de recomendação de 98% por parte de influenciadores. Muitos espectadores comentaram: "É hilário e comovente, e o significado da família é vividamente capturado."
Atualmente, "A Vagrant Life" está sendo exibido em todo o país, coincidindo com o Dia Nacional e o período do Festival de Meio do Outono, e é considerado uma opção popular para assistir em família.
#Bem-vindo a seguir a conta pública oficial do WeChat do iFaner: iFaner (ID do WeChat: ifanr), onde mais conteúdo interessante será apresentado a você o mais breve possível.
