
A OpenAI lançou repentinamente a cadeia de pensamento o3-mini! O primeiro show foi questionado. Comparado com o DeepSeek R1 na medição real, a lacuna é muito óbvia.

Vamos agradecer ao DeepSeek novamente.
Esta manhã, a OpenAI anunciou o lançamento da cadeia de pensamento do mais recente modelo da série o3-mini.
Simplificando, os usuários agora podem ver o processo de “pensamento” de o3-mini e o3-mini(alto) e ter uma compreensão mais clara de como o modelo raciocina e chega a conclusões.
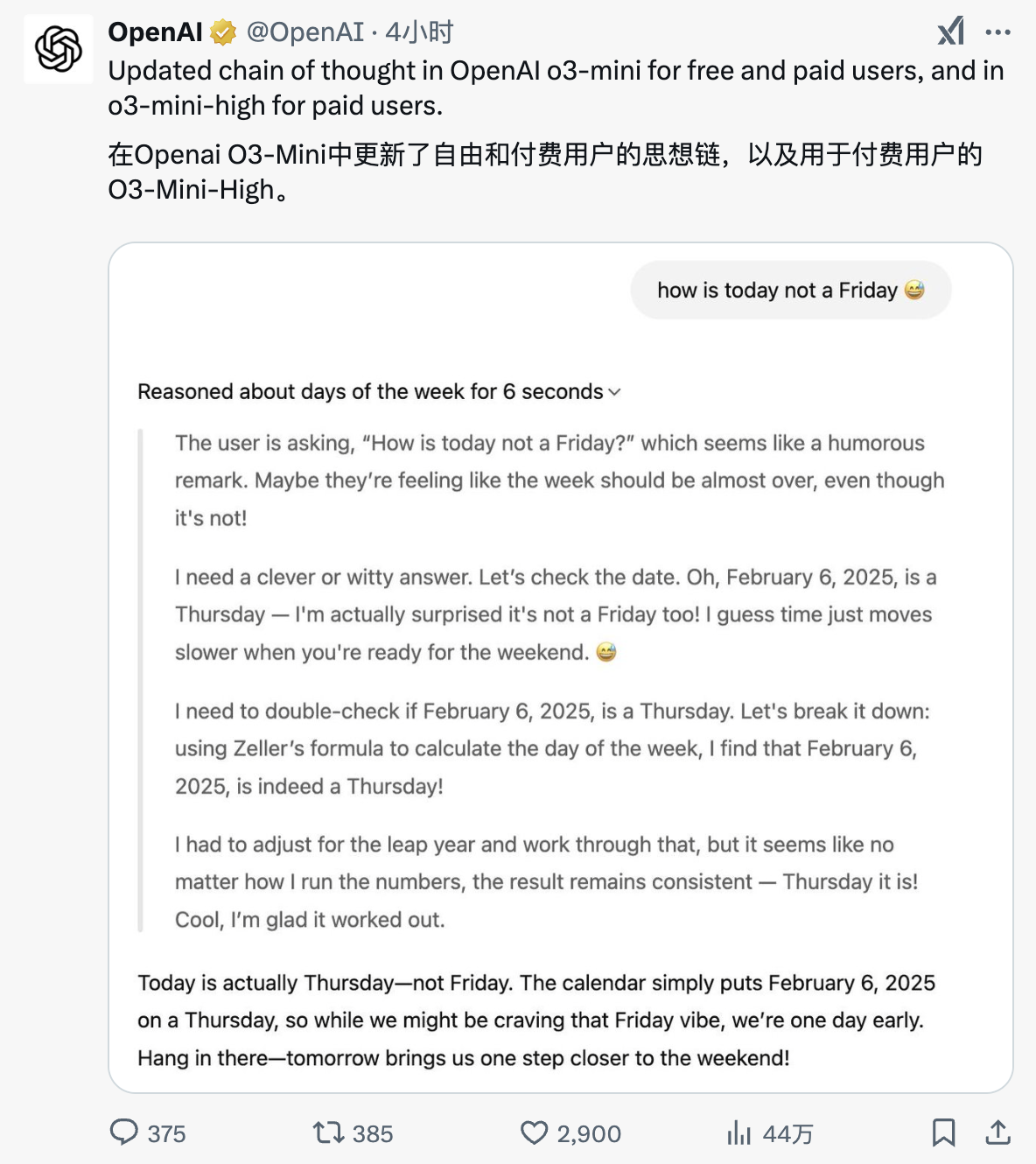
O cientista pesquisador da OpenAI, Noam Brown, postou na plataforma X:
"Antes do lançamento do o1-Preview, apresentamos a você  Ver a Cadeia de Pensamentos (CoT) funcionando em tempo real costuma ser o momento “aha”, fazendo-os perceber que isso será algo grande.
Ver a Cadeia de Pensamentos (CoT) funcionando em tempo real costuma ser o momento “aha”, fazendo-os perceber que isso será algo grande.
Embora estas não sejam cadeias de pensamento originais, elas estão muito próximas. Estou muito animado por podermos compartilhar essa experiência com o mundo! "
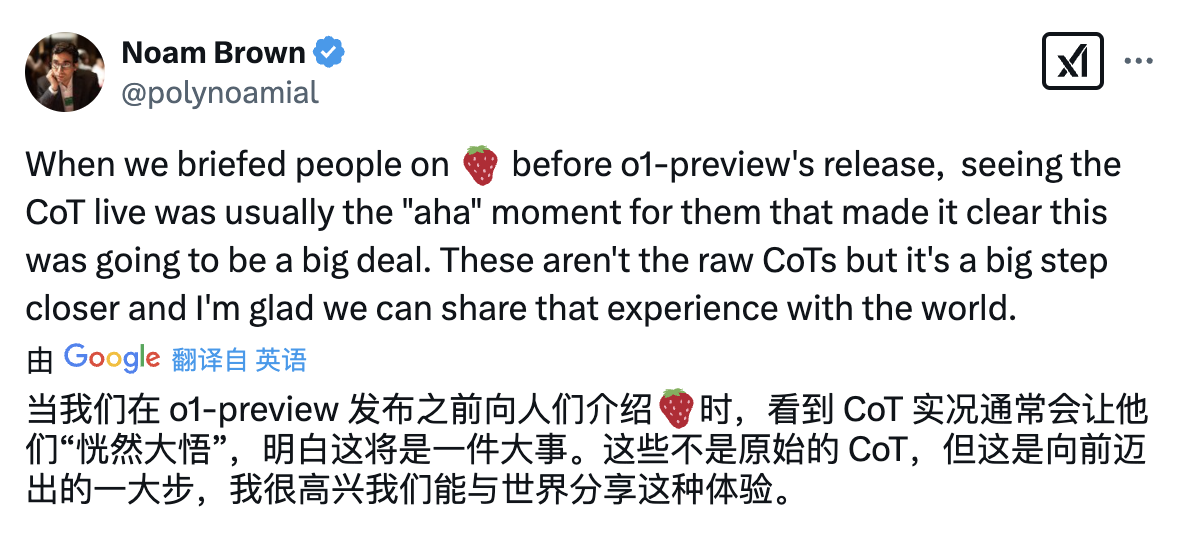
Ele então elaborou mais:
"o3-mini é o primeiro grande modelo de linguagem que pode responder de forma consistente e precisa aos problemas do jogo da velha. Embora a cadeia de pensamento resumida pareça um pouco confusa, você pode ver do lado direito que o modelo finalmente encontrou a resposta correta com sucesso."
foto
É público, mas não totalmente público.
De acordo com a mídia estrangeira TechCrunch, a OpenAI ainda não divulgará totalmente as etapas completas do raciocínio do o3-mini, mas disse que "encontrou um ponto de equilíbrio" e o o3-mini agora pode "pensar livremente" e então compilar um resumo de raciocínio mais detalhado.
Antes disso, devido a considerações competitivas, a OpenAI não divulgava completamente as etapas de inferência do o3-mini e seus antecessores (o1 e o1-mini), apenas fornecia resumos de inferência aos usuários, e mesmo esses resumos eram às vezes imprecisos.
Além disso, para melhorar a clareza e a segurança, a OpenAI também introduz uma etapa adicional de pós-processamento. O modelo irá primeiro revisar a “cadeia de pensamento” para eliminar conteúdo potencialmente inseguro e simplificar moderadamente conceitos complexos.

O relatório citou um porta-voz da OpenAI explicando: “Esta etapa de pós-processamento também oferece suporte a usuários que não falam inglês para garantir que possam visualizar a ‘Cadeia de Pensamentos’ em seu idioma nativo, tornando a experiência mais amigável e compreensível”.
Na verdade, a transparência do raciocínio está se tornando um importante ponto competitivo no campo da IA. Permitir que a IA exiba etapas de raciocínio completas pode não apenas melhorar a confiança do usuário, mas também tornar a IA mais fácil de ser pesquisada e melhorada.

No entanto, a cadeia de pensamento público pode ser explorada pelos concorrentes, como a extração da lógica de raciocínio do modelo por meio da tecnologia de destilação. No evento AMA (Ask Me Anything) no Reddit na semana passada, o diretor de produtos da OpenAI, Kevin Weil, disse:
"Estamos trabalhando para mostrar mais processos de raciocínio do que fazemos agora – [essa mudança] ocorrerá em breve. Ainda não foi decidido se devemos mostrar a" cadeia de pensamento "completa devido a questões de concorrência. Mas também sabemos que os usuários (especialmente os usuários avançados) desejam ver mais detalhes, por isso encontraremos o equilíbrio certo. "
Em contraste, a cadeia de pensamento do DeekSeek R1 é incondicionalmente aberta e transparente, e seu processo de pensamento aprofundado ganhou elogios de muitos internautas. O ajuste “forçado” da OpenAI desta vez é obviamente uma resposta à pressão da DeepSeek e de outras empresas de IA.
X Netizen @thegenioo testou imediatamente esta atualização da cadeia de pensamento. Ele disse: “A nova versão não apenas fornece uma interface de usuário mais suave, mas também torna o processo de pensamento do modelo mais transparente.
A seguir está uma comparação entre DeepSeek R1 e OpenAI o3-mini (high) pensando no mesmo problema.
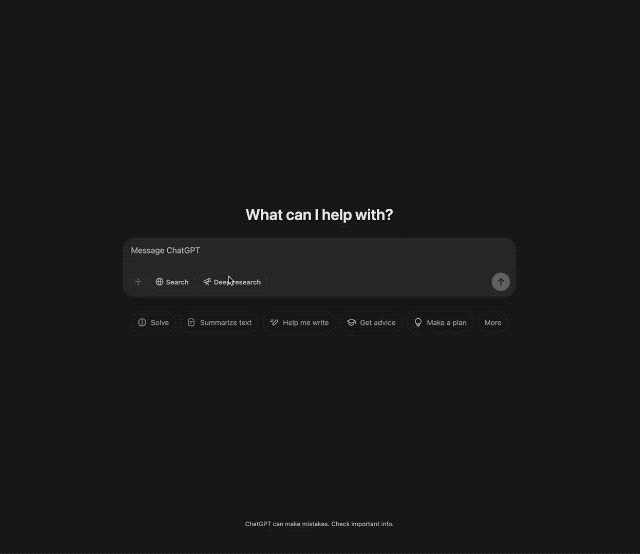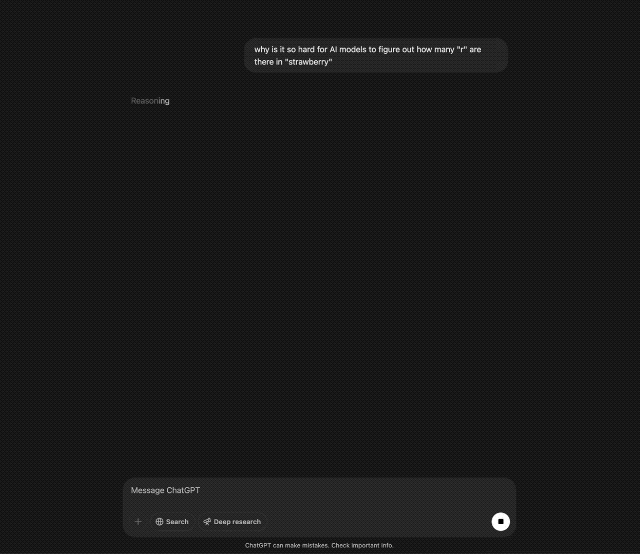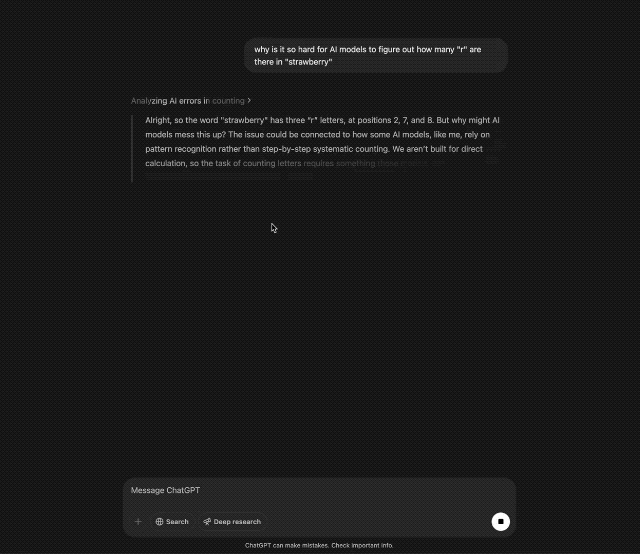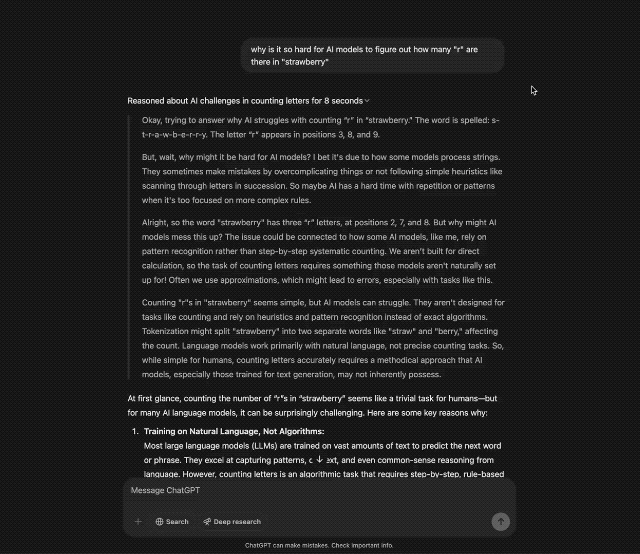
"Quantos e existem em deepseeeeeek"
DeepSeekR1
foto
OpenAI o3-mini (alto)
"Suponha que haja um lago com água infinita. Existem duas chaleiras vazias com capacidades de 5 litros e 6 litros respectivamente. O problema é como tirar 3 litros de água do lago usando apenas essas duas chaleiras."

▲DeepSeek R1

OpenAI o3-mini (alto)
“Um homem comprou um frango por 8 yuans e vendeu por 9 yuans. Então ele achou que não era um bom negócio, então comprou de volta por 10 yuans e vendeu para outra pessoa por 11 yuans.

▲DeepSeek R1

▲ OpenAI o3-mini (alto)
Depois de ler os casos acima, descobriremos que os dois modelos têm “estilos de pensamento” completamente diferentes.
DeepSeek R1 é mais parecido com um estudante de artes liberais. Seu processo de raciocínio é passo a passo e seu pensamento é completo e delicado. O3-mini(high) é mais parecido com um estudante de ciências. O processo de raciocínio é conciso e claro e vai direto ao cerne do problema.
Essa diferença se reflete ainda na velocidade de resposta do DeepSeek R1 que tem um tempo de pensamento relativamente longo, enquanto o o3-mini (alto) é mais rápido.
No que diz respeito às respostas, as respostas do DeepSeek R1 são frequentemente mais completas e detalhadas. Por exemplo, a primeira pergunta do teste também incluirá anotações cuidadosas. Em contraste, o3-mini(high) parece "profissional".
Como mencionei no início, o que o o3-mini lançou desta vez não foi a versão completa da cadeia de pensamento, então depois de aberto ao público também despertou muitas dúvidas.
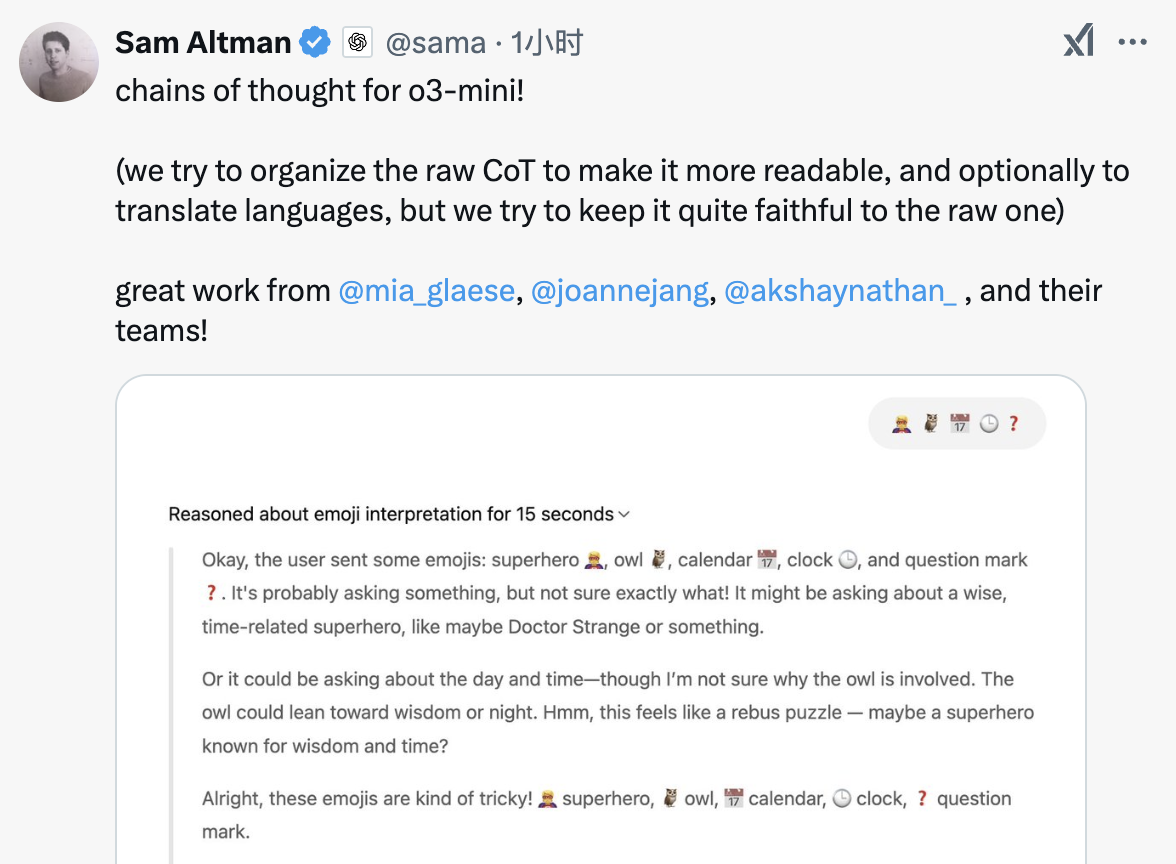
Diante da polêmica, o CEO da OpenAI, Sam Altman, também explicou rapidamente na plataforma X: “Tentamos organizar a cadeia de pensamento original para torná-la mais legível e traduzi-la quando necessário, mas tentamos manter seu estilo original”.
No entanto, como um internauta apontou: sem o DeepSeek, ainda seríamos capazes de ver até mesmo uma “versão castrada” da cadeia de pensamento do o3-mini? Receio que a resposta seja evidente.

# Bem-vindo a seguir a conta pública oficial do WeChat de Aifaner: Aifaner (WeChat ID: ifanr). Mais conteúdo interessante será fornecido a você o mais rápido possível.
