
Usei a nova função do ChatGPT para editar uma foto e enviar para o Moments, mas todas as mensagens privadas me perguntavam como fazer?
Quando a OpenAI lançou a nova geração da função gráfica Vincent esta manhã, todos não estavam muito claros sobre sua força. Eles pensaram que estava seguindo o Gemini e trazendo algumas atualizações tardias.
A GPT não disse nada, apenas chocou o público com seus casos de usuários.

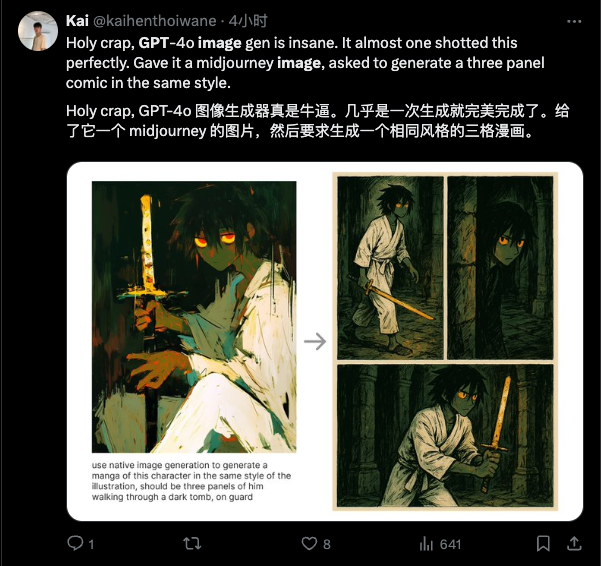
Em sua última iteração, OpenAI traz conformidade de instruções inovadora e desempenho consistente à funcionalidade gráfica vicentina. Com o prompt de texto mais simples, você pode obter um ajuste fino de alta precisão dos detalhes da imagem – todas as modificações só precisam ser feitas na sessão , sem quaisquer operações adicionais, como botões ou pincéis.
Magia não requer pincéis, apenas feitiços
Semelhante ao Gemini, o foco desta atualização do OpenAI não está no quão realistas e complexas as imagens podem ser, mas na conformidade e consistência das instruções, e isso ocorre sob a premissa de usar apenas instruções em linguagem natural.
Vejamos primeiro um conjunto de fotos de alimentos básicos. A dica também é muito simples: gere uma imagem de café e pão.

Mais tarde, com base na foto original, pedi para mudar para café gelado e espalhar geléia.

Exceto a alça do copo, acrescentei o que precisava ser adicionado e deixei o que precisava ser deixado de fora, e as instruções foram seguidas muito bem.
Fotos envolvendo retratos também apresentam desempenho estável.

Se você olhar com atenção, ainda há algumas pequenas mudanças, mas os movimentos mais críticos do corpo humano, as rugas nas roupas e as expressões são todos perfeitos.
Ao criar este conjunto de imagens, encontrei controle de risco de conteúdo e recebi um erro informando que ele não atendia aos requisitos da política. No entanto, compreendeu a intenção da directiva original e propôs alterações.

Este último é também o que tem o melhor e mais natural efeito.
Tarefas com conteúdo de tela simples são naturalmente fáceis de entender, mas e as mais complicadas?
No teste fotográfico anterior do Gemini, produzimos uma cena de rua de uma cidade e o efeito foi incrível. Dê uma olhada novamente:

O mesmo prompt foi executado no ChatGPT, mas o efeito da imagem ficou um pouco pior, principalmente à noite, onde os detalhes da multidão eram quase invisíveis.

Claro, esse problema tem mais a ver com diferenças estéticas. Não há problema em identificar os elementos-chave. Ele pode até capturar pequenos detalhes como “Livraria Tsutaya”, e a geração de fontes também é bastante estável.
Além de gerá-lo diretamente com texto, você também pode fazer upload de imagens para modificação – aí vem o episódio mais chocante.
Após fazer o upload do logotipo APPSO em formato png, o primeiro passo é simplesmente alterá-lo para 3D.

O efeito é bom, a direção da sombra é inconsistente, mas corresponde à própria luz. A seguir, faça alguns ajustes.

Chocante! As instruções para esses dois ajustes têm apenas cerca de vinte palavras.

(Mesmo os produtos digitais padrão são da Apple, e alguns atributos não mencionados estão realmente ocultos.)
O ajuste fino subsequente em pequenos ângulos também é muito preciso.

▲ Dica: Ajuste o ângulo para que o logotipo vermelho fique frontal, enquanto o resto permanece inalterado
O ajuste fino detalhado é um grande destaque desta atualização, que pode associar instruções com precisão aos detalhes correspondentes para completar modificações locais precisas.

▲ Aviso: ajuste o ângulo, a lente dispara pela frente direita, a luz geral diminui, um feixe de luz forte ilumina parte da máquina pela direita, com grãos de café próximos a ela
As instruções incluem conteúdos importantes, como efeitos de iluminação, ângulos de câmera e acréscimos de elementos. O modelo pode ser identificado com precisão e ajustado de forma holística. Estou cansado de falar sobre quais quatro palavras mudar.
A coisa mais surpreendente sobre esta atualização deve ser a capacidade de alternar rapidamente entre imagens brutas e texto bruto na mesma sessão.
Por exemplo, na imagem abaixo, a primeira instrução é gerar um guia de embrulho para presente.

A primeira coisa que foi dada foi uma versão em imagem e texto – o que não é um erro. Não especifiquei se queria fazer uma versão em imagem e texto ou uma versão em texto. As instruções eram muito vagas.
Depois de gerar a versão em texto, o ChatGPT perguntou proativamente se queria criar uma versão gráfica. Após receber uma resposta de confirmação, forneceu uma versão gráfica.

Isso significa que a resposta precisa do modelo não se reflete apenas na compreensão de uma única instrução, mas também na compreensão das intenções potenciais do usuário e no "pensamento um passo a mais" do que o usuário .
Na verdade, esta é também a capacidade demonstrada pela Deep Research quando foi lançada antes. A pesquisa profunda do OpenAI é um dos poucos modelos que solicita ativamente aos usuários que esclareçam os detalhes da execução da tarefa.
Recursos semelhantes foram migrados para imagens brutas desta vez. Em termos de experiência do usuário, eles são mais intuitivos e perceptíveis do que os do Deep Research.
Por exemplo, pode ser utilizado para fazer avisos e instruções diárias, com fotos e textos, tudo em um só lugar.
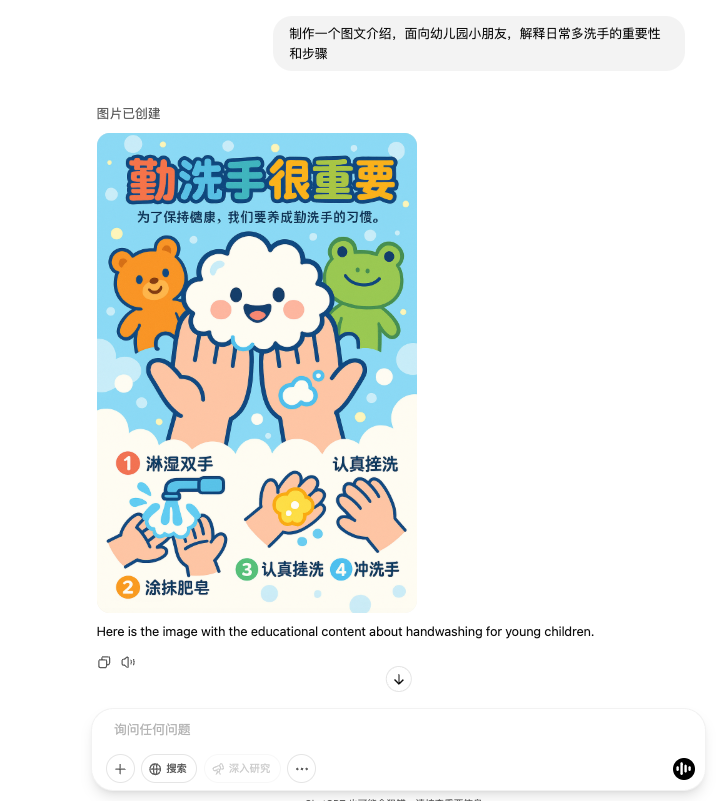
No geral, o mais surpreendente desta vez deve ser a sincronização da consistência e do seguimento das instruções.
Como sempre, toda revisão deveria ter alguns “guias de uso” – eu realmente não encontrei nenhuma precaução desta vez. Tudo o que você precisa fazer é seguir suas próprias ideias, tocar no teclado e inserir texto. Não existem “truques” ou “truques”.
A consistência da criação e modificação do desenho através do prompt é uma questão muito crítica no desenho Vincent. Está relacionado às capacidades do modelo e às capacidades de engenharia. Antes que a conformidade e a consistência das instruções fizessem tanto progresso, elas eram resolvidas principalmente por meio de avisos e a pressão estava do lado do usuário .
Portanto, haverá vários modelos e estratégias para ensiná-lo a “lidar com modelos”. Mas esse não é o estado em que a interação em linguagem natural deveria estar. Quando o modelo se depara com as pessoas, ele aceita apenas as instruções mais diretas do usuário – permitindo que as pessoas aprendam primeiro a escrever os prompts, o que é realmente desanimador.
As recentes atualizações do Gemini e do OpenAI fizeram com que a faixa de geração de fotos, que se tornou menos popular, voltasse a ser animada. Eles também mostram a mesma coisa em comum: já se foram os dias em que alguns produtos de modificação de imagem aumentavam a controlabilidade das imagens brutas adicionando botões e entradas para combater a ilusão dos modelos .
O problema de consistência resolve não apenas o problema de geração de imagem, mas também os pequenos problemas no processo de “uso da função de geração de imagem”. De certa forma, é também uma otimização de nível de engenharia.
A modificação e a geração podem ser alcançadas usando a compreensão precisa das instruções de texto do modelo – neste nível, “o modelo é o produto” ainda é válido.
# Bem-vindo a seguir a conta pública oficial do WeChat de Aifaner: Aifaner (WeChat ID: ifanr). Conteúdo mais interessante será fornecido a você o mais rápido possível.
