
Como encontrar dados duplicados em um arquivo de texto Linux com uniq
Você já se deparou com arquivos de texto com linhas repetidas e palavras duplicadas? Talvez você trabalhe regularmente com saída de comando e queira filtrá-los para sequências distintas. Quando se trata de arquivos de texto e remoção de dados redundantes no Linux, o comando uniq é sua melhor aposta.
Neste artigo, discutiremos o comando uniq em detalhes, juntamente com um guia detalhado sobre como usar o comando para remover linhas duplicadas de um arquivo de texto.
O que é o comando uniq?
O comando uniq no Linux é usado para exibir linhas idênticas em um arquivo de texto. Este comando pode ser útil se você deseja remover palavras ou strings duplicadas de um arquivo de texto. Como o comando uniq corresponde a linhas adjacentes para localizar cópias redundantes, ele só funciona com arquivos de texto classificados.
Felizmente, você pode canalizar o comando sort com uniq para organizar o arquivo de texto de uma forma que seja compatível com o comando. Além de exibir linhas repetidas, o comando uniq também pode contar a ocorrência de linhas duplicadas em um arquivo de texto.
Como usar o comando uniq
Existem várias opções e sinalizadores que você pode usar com o uniq. Alguns deles são básicos e executam operações simples, como imprimir linhas repetidas, enquanto outros são para usuários avançados que frequentemente trabalham com arquivos de texto no Linux.
Sintaxe Básica
A sintaxe básica do comando uniq é:
uniq option input output… onde opção é o sinalizador usado para chamar métodos específicos do comando, entrada é o arquivo de texto para processamento e saída é o caminho do arquivo que armazenará a saída.
O argumento de saída é opcional e pode ser ignorado. Se um usuário não especificar o arquivo de entrada, o uniq obtém os dados da saída padrão como entrada. Isso permite que um usuário canalize o uniq com outros comandos do Linux .
Exemplo de arquivo de texto
Usaremos o arquivo de texto duplicate.txt como entrada para o comando.
127.0.0.1 TCP
127.0.0.1 UDP
Do catch this
DO CATCH THIS
Don't match this
Don't catch this
This is a text file.
This is a text file.
THIS IS A TEXT FILE.
Unique lines are really rare.
Observe que já classificamos este arquivo de texto usando o comando sort . Se você estiver trabalhando com algum outro arquivo de texto, poderá classificá-lo usando o seguinte comando:
sort filename.txt > sorted.txtRemover linhas duplicadas
O uso mais básico do uniq é remover strings repetidas da entrada e imprimir uma saída única.
uniq duplicate.txtResultado:
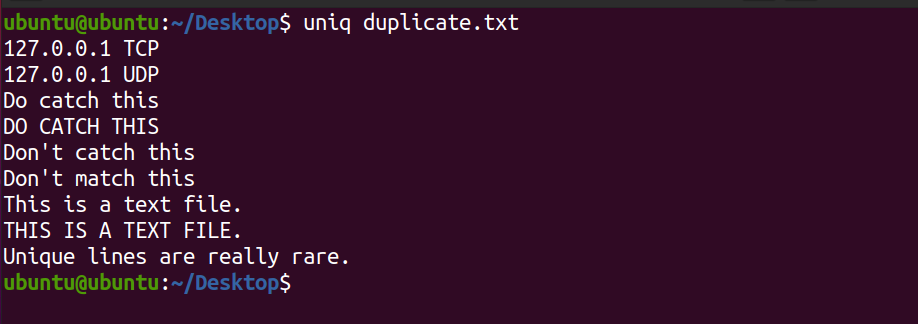
Observe que o sistema não exibe a segunda ocorrência da linha. Este é um arquivo de texto . Além disso, o comando mencionado apenas imprime as linhas exclusivas do arquivo e não afeta o conteúdo do arquivo de texto original.
Contar Linhas Repetidas
Para gerar o número de linhas repetidas em um arquivo de texto, use o sinalizador -c com o comando padrão.
uniq -c duplicate.txtResultado:
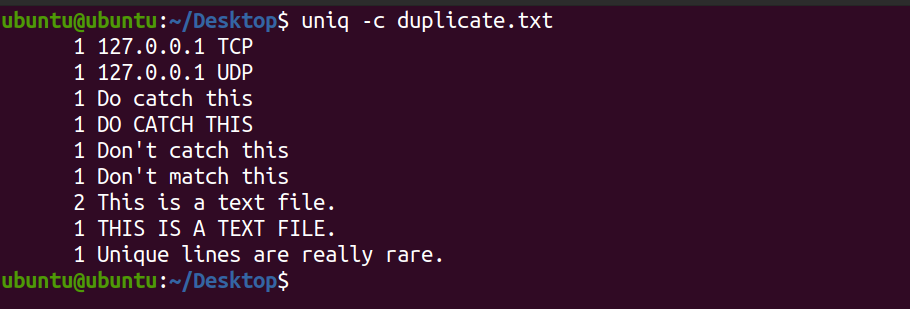
O sistema exibe a contagem de cada linha existente no arquivo de texto. Você pode ver que a linha Este é um arquivo de texto ocorre duas vezes no arquivo. Por padrão, o comando uniq diferencia maiúsculas de minúsculas.
Imprimir apenas linhas repetidas
Para imprimir apenas linhas duplicadas do arquivo de texto, use o sinalizador -D . O -D significa Duplicar .
uniq -D duplicate.txtO sistema exibirá a saída da seguinte forma.
This is a text file.
This is a text file.Pular campos ao verificar se há duplicatas
Se você quiser pular um certo número de campos enquanto combina as strings, você pode usar o sinalizador -f com o comando. O -f significa Campo .
Considere o seguinte arquivo de texto fields.txt .
192.168.0.1 TCP
127.0.0.1 TCP
354.231.1.1 TCP
Linux FS
Windows FS
macOS FSPara pular o primeiro campo:
uniq -f 1 fields.txtResultado:
192.168.0.1 TCP
Linux FSO comando mencionado pulou o primeiro campo (os endereços IP e nomes do sistema operacional) e correspondeu à segunda palavra (TCP e FS). Em seguida, ele exibiu a primeira ocorrência de cada correspondência como a saída.
Ignorar caracteres ao comparar
Assim como pular campos, você também pode pular caracteres. O sinalizador -s permite que você especifique o número de caracteres a serem ignorados durante a correspondência de linhas duplicadas. Este recurso ajuda quando os dados com os quais você está trabalhando estão na forma de uma lista da seguinte maneira:
1. First
2. Second
3. Second
4. Second
5. Third
6. Third
7. Fourth
8. FifthPara ignorar os dois primeiros caracteres (as numerações da lista) no arquivo list.txt :
uniq -s 2 list.txtResultado:
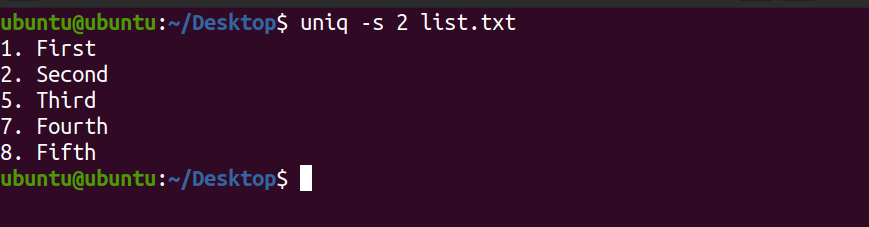
Na saída acima, os primeiros dois caracteres foram ignorados e o restante deles foi correspondido por linhas exclusivas.
Verifique o primeiro número N de caracteres para duplicar
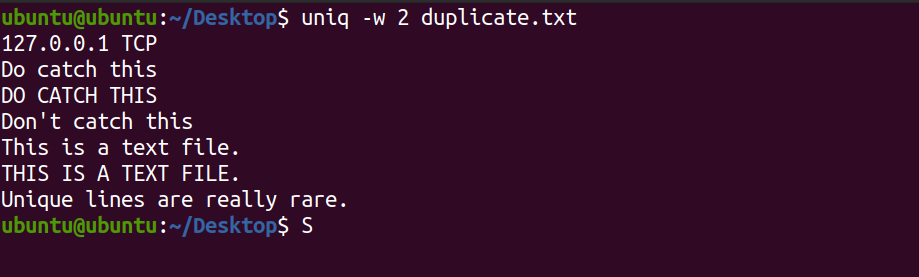
O sinalizador -w permite que você verifique apenas um número fixo de caracteres para duplicatas. Por exemplo:
uniq -w 2 duplicate.txtO comando mencionado apenas corresponderá aos dois primeiros caracteres e imprimirá linhas exclusivas, se houver.
Resultado:
Remover a sensibilidade a maiúsculas e minúsculas
Como mencionado acima, o uniq diferencia maiúsculas de minúsculas enquanto combina linhas em um arquivo. Para ignorar a capitalização do caractere, use a opção -i com o comando.
uniq -i duplicate.txtVocê verá a seguinte saída.
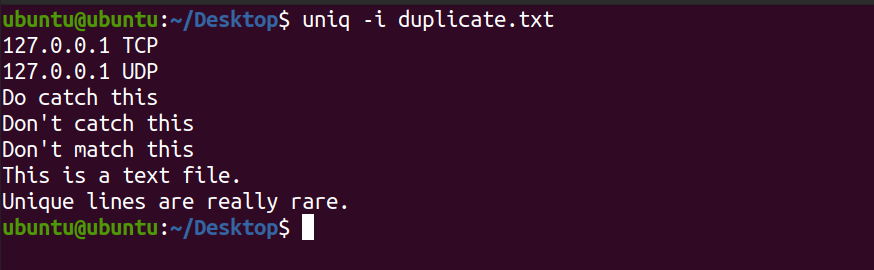
Observe na saída acima, o uniq não exibiu as linhas DO CATCH ISSO e ESTE É UM ARQUIVO DE TEXTO .
Enviar saída para um arquivo
Para enviar a saída do comando uniq para um arquivo, você pode usar o caractere de redirecionamento de saída ( > ) da seguinte maneira:
uniq -i duplicate.txt > otherfile.txtAo enviar uma saída para um arquivo de texto, o sistema não exibe a saída do comando. Você pode verificar o conteúdo do novo arquivo usando o comando cat .
cat otherfile.txtVocê também pode usar outras maneiras de enviar a saída da linha de comando para um arquivo no Linux .
Analisando dados duplicados com uniq
Na maioria das vezes, ao gerenciar servidores Linux, você estará trabalhando no terminal ou editando arquivos de texto. Portanto, saber como remover cópias redundantes de linhas em um arquivo de texto pode ser um grande trunfo para o seu conjunto de habilidades do Linux.
Trabalhar com arquivos de texto pode ser frustrante se você não souber como filtrar e classificar o texto em um arquivo. Para tornar seu trabalho mais fácil, o Linux possui vários comandos de edição de texto, como sed e awk, que permitem trabalhar de forma eficiente com arquivos de texto e saídas de linha de comando.
