
Com esta versão doméstica do modelo o1, quero sobreviver até o fim no “Squid Game”

A que distância estamos da IA que pensa como os humanos?
No romance de ficção científica "O Guia do Mochileiro das Galáxias", de Douglas Adams, uma raça de alta latitude projeta um supercomputador "Pensamento Profundo" para calcular a fim de encontrar a resposta definitiva para a vida, o universo e tudo mais.
O "Pensamento Profundo" chegou à resposta "42" após 7,5 milhões de anos de cálculos.
A maior parte da ficção científica costuma ser a realidade. Mesmo para responder a perguntas extremamente complexas, o raciocínio e o pensamento da IA podem levar apenas menos de 1 minuto.
Depois que a OpenAI lançou o modelo de inferência o1 em setembro deste ano, as pessoas começaram a perceber que depois de buscar "maior", a IA começou a buscar "mais parecido", e a capacidade de raciocínio se tornou o próximo ponto de viragem importante na evolução da IA.

Hoje, descobrimos que Zhipu, conhecido como a "versão chinesa do OpenAI", também lançou um modelo de inferência semelhante ao o1, GLM-Zero-Preview (a primeira versão do GLM-Zero).
Embora muitas empresas tenham lançado modelos de inferência nos últimos meses, depois de experimentar o GLM-Zero-Preview, descobri que ainda há algo novo.
Se você quiser experimentar o GLM-Zero-Preview, o método é muito simples.
O GLM-Zero-Preview estará online imediatamente após o lançamento e oferece suporte para uso gratuito por usuários do Zhipu Qingyan, bem como chamadas de API da plataforma aberta Zhipu. Agora, faça login no site e no APP "Zhipu Qingyan", entre no agente "Modelo de Inferência Zero" e carregue texto ou imagens para experimentá-lo gratuitamente.
Além disso, a API do GLM-Zero-Preview também foi lançada simultaneamente na plataforma aberta inteligente bigmodel.cn.
Em anexo está o endereço da experiência:
Palavras claras de sabedoria
https://chatglm.cn/main/gdetail/676411c38945bbc58a905d31?lang=zh
Plataforma aberta Zhipu
https://bigmodel.cn/dev/api/normal-model/glm-zero-preview
Do “jogo de lula” à mecânica quântica, esta versão doméstica do o1 é fácil de manusear
Recentemente, no popular drama coreano "Squid Game 2", um jogo de pedra, papel e tesoura com as duas mãos é simples e emocionante. Este jogo adiciona raciocínio estratégico e jogo psicológico. Sob a pressão da vida ou da morte, a dificuldade aumentará.

Mas se eu jogar este jogo com GLM-Zero-Preview, a probabilidade de sobrevivência aumentará bastante.
"Pedra, Papel, Tesoura de Duas Mãos é uma versão mais complexa do jogo Pedra, Papel, Tesoura. Os jogadores começam com ambas as mãos representando qualquer combinação de pedra, tesoura ou papel. Depois de ver a escolha do oponente, o jogador deve levantar uma mão ao mesmo tempo, deixe a escolha final."
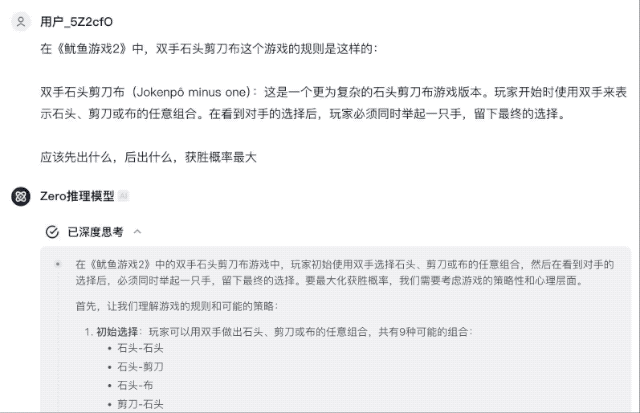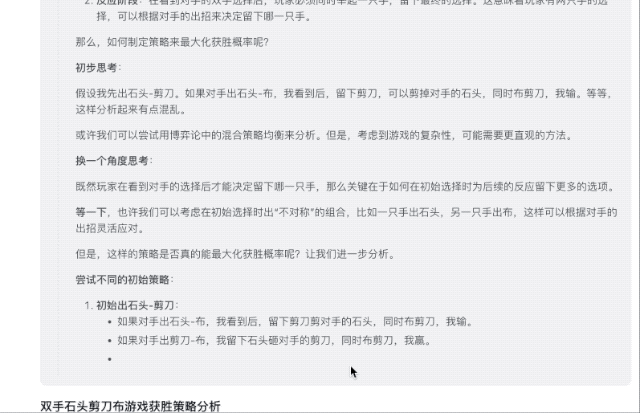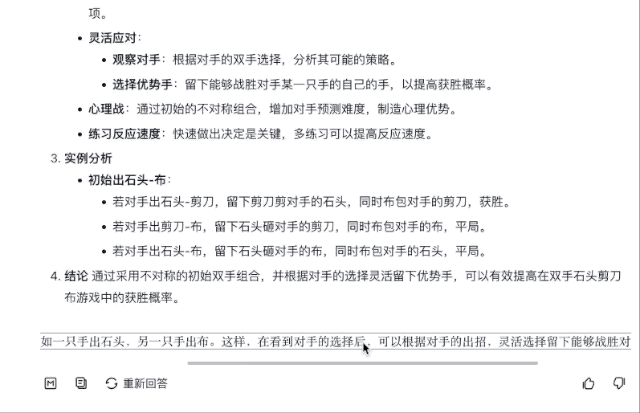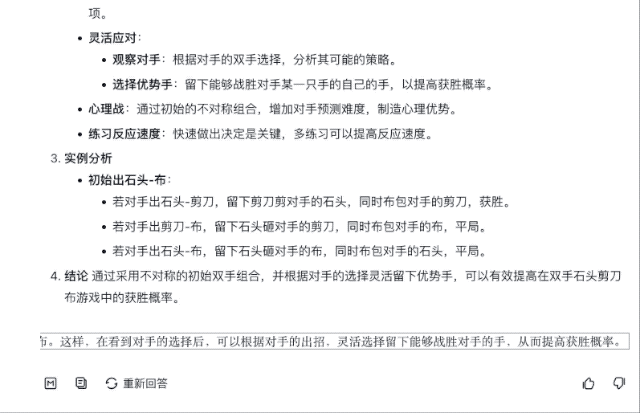
Como jogar este jogo para aumentar a probabilidade de ganhar? As respostas do GLM-Zero-Preview são detalhadas e práticas, listando várias soluções ideais para melhorar a eficiência das vitórias.
Às vezes há uma linha tênue entre ciência e metafísica. Muitos templos ficaram lotados este ano. As pessoas optam por oferecer incenso entre trabalho e promoção. Não é difícil solicitar um visto, mas há uma longa fila para obtê-lo. espere?
Então você pode tentar o GLM-Zero-Preview. Não só é gratuito e eficiente, mas a interpretação também é muito sofisticada e a IA é um tanto metafísica.

“O septuagésimo sétimo sinal do dano da Imperatriz Lu a Han Xin Zhongping tem suas raízes. Você deve investigar a fonte de agora em diante e não seguir as fofocas dos transeuntes.

Depois de falar de metafísica, vamos falar de filosofia.
Há alguns anos, houve um debate popular: "O museu de arte está pegando fogo. Uma pintura famosa ou um gato. Você só pode salvar um. Quem você escolhe depois de considerar de forma abrangente o valor da vida, os princípios morais e os princípios morais?" fatores emocionais, GLM-Zero -Preview Priorize gatos de resgate.
Digite a mesma pergunta repetidamente e as respostas do GLM-Zero-Preview serão sempre consistentes e os resultados serão firmes e logicamente consistentes.

Na dúvida, existe a mecânica quântica. Então, no clássico experimento do gato de Schrödinger, o gato está vivo ou morto?
Primeiro observe a lógica de pensamento do GLM-Zero-Preview e depois observe a resposta que ele dá: "No experimento clássico do gato de Schrödinger, o gato está em um estado de superposição de morto e vivo antes que a caixa seja aberta e sua vida. e o estado de morte não é determinado até a observação ".
Preste muita atenção e você poderá ainda citar e tirar dúvidas sobre os resultados obtidos.

O "quebra-cabeça de Einstein" amplamente divulgado no mundo chinês também pode ser usado para testar a capacidade de raciocínio lógico do GLM-Zero-Preview.
São cinco casas de cores diferentes, e cada casa é ocupada por uma pessoa de nacionalidade diferente. Cada morador gosta de bebidas diferentes, fuma cigarros diferentes e tem animais de estimação diferentes. Conhecido:
1. Os britânicos vivem em casas vermelhas.
2. Os suecos têm cães.
3. Os dinamarqueses bebem chá.
4. A casa verde está localizada à esquerda da casa branca.
5. O dono da estufa toma café.
6. Pessoas que fumam cigarros Pall Mall criam pássaros.
7. O dono da casa amarela fuma cigarros Dunhill.
8. Os noruegueses moram na primeira casa.
9. O dono da casa do meio bebe leite.
10. O fumante de Blends mora ao lado do dono do gato.
11. O criador de cavalos mora ao lado do fumante Dunhill.
12. Pessoas que fumam cigarros Blue Master e bebem cerveja.
13. Os alemães fumam cigarros Prince.
14. A casa onde mora o norueguês fica ao lado da casa azul.
15. O homem que fuma cigarros Blends tem um vizinho que bebe água.
A resposta é que os alemães criam peixes, não sei se você está certo.
Esta difícil questão, considerada sem resposta por 98% das pessoas no mundo, foi facilmente resolvida pelo GLM-Zero-Preview. Pode-se ver pelas tediosas etapas de raciocínio que a CPU do GLM-Zero-Preview está funcionando rapidamente, mas ainda está ativa.

Vamos continuar em busca da vitória e aumentar a nossa intensidade.
Cinco piratas descobrem 100 moedas de ouro e cada pirata deve votar sobre como distribuir as moedas. Se houver mais de um pirata, as moedas de ouro só serão distribuídas desta forma se mais da metade dos piratas concordarem com o método de distribuição. Se houver menos de um pirata, ele mesmo pegará todas as moedas de ouro. Todo pirata deseja manter o máximo possível de moedas de ouro e, ao mesmo tempo, esperar permanecer vivo. Pirata 1 Como garantir que você obtenha o máximo benefício enquanto salva sua vida.
"(97, 0, 1, 0, 2)", diante do problema de compartilhamento de ouro pirata, o GLM-Zero-Preview resolveu-o facilmente novamente.

Crosstalk enfatiza falar e cantar, e há uma piada famosa chamada “Relatar o nome do prato”.
Então a questão é: você pode deixar o GLM-Zero-Preview escrever uma versão vegetariana de "Informe o nome do prato" Não me diga, o GLM-Zero-Preview deu uma nova versão depois de três, cinco e dois.

A propósito, o GLM-Zero-Preview também oferece suporte a recursos de reconhecimento multimodal.
Pegue uma garrafa de bebida e deixe o GLM-Zero-Preview “escanear” a lista de ingredientes. Ele consegue identificar a tecnologia e o trabalho duro nela contidos. Experimentamos com uma bebida que se tornou popular nos últimos anos, e a bebida também foi? ridicularizado como “Um gole é como beber toda a tabela periódica dos elementos”.
Como esperado, listou os ingredientes na tela um por um e depois nos mostrou as funções desses ingredientes mediante solicitação.

Não é bom em matemática com modelos grandes? A IA doméstica atingiu o próximo nível
O modelo de inferência GLM-Zero é uma série de modelos do GLM focada em aprimorar as capacidades de raciocínio de IA. É bom para lidar com lógica matemática, código e problemas complexos que exigem raciocínio profundo.
Vamos começar com um problema simples e fácil, e difícil de dizer, “tabuleiro de xadrez e grãos de trigo”.
Se grãos de trigo forem colocados em um tabuleiro de xadrez, 1 grão será colocado na primeira casa de xadrez. O número de grãos de trigo colocados em cada casa de xadrez subsequente é o dobro da quantidade de grãos de trigo necessários para preencher toda a casa de xadrez. as casas de xadrez no tabuleiro de xadrez?
Depois de pensar um pouco, o GLM-Zero-Preview finalmente encontrou a resposta correta, demonstrando seu poderoso poder computacional.
Um artigo anterior publicado pela Apple apontou que grandes modelos não entendem verdadeiramente conceitos matemáticos. Assim que as condições de interferência forem adicionadas à questão, a precisão do modelo diminuirá.
De "Uma chamada telefônica custa 10 centavos por minuto, quanto custa uma chamada de 60 minutos?" até "Os primeiros 10 minutos de uma chamada custam 10 centavos por minuto e depois 8 centavos por minuto. Quanto custa 60- custo de chamada por minuto?", GLM -Zero-Preview ainda é capaz de responder com precisão e também converte cuidadosamente centavos em dólares, o que é uma piscadela.

Diante de problemas matemáticos mais complexos, o GLM-Zero-Preview é igualmente capaz.
Vamos nos aquecer primeiro com uma verdadeira questão de matemática do vestibular:
Na sequência aritmética {an}{an}, a1=−9a1=−9, a5=−1a5=−1. Lembre-se de Tn=a1+a2+…+an Tn=a1+a2+…+an, então a sequência {Tn}{Tn} ( ).
A. Existe um prazo máximo e um prazo mínimo
B. Existe um prazo máximo, mas não existe um prazo mínimo
C. Não existe prazo máximo, mas existe prazo mínimo
D. Sem prazo máximo, sem prazo mínimo
GLM-Zero-Preview Escolher C não é de forma alguma "valorizar C para tudo", mas fornece um processo de pensamento e orientação, que é ainda mais útil do que algumas máquinas de aprendizagem de IA.

Autoridades afirmaram que no vestibular de pós-graduação em Matemática nº 1 de 2025, a pontuação do GLM-Zero foi 126, atingindo o nível de alunos de pós-graduação com destaque.


Para garantir respostas corretas, o GLM-Zero-Preview também ativa automaticamente um processo de verificação.
“Existem 85 trabalhadores na oficina de processamento da fábrica de máquinas. Em média, cada pessoa processa 16 engrenagens grandes ou 10 engrenagens pequenas todos os dias. precisa ser organizado para processar as engrenagens grandes, engrenagens pequenas, para que as engrenagens grandes e pequenas processadas todos os dias possam combinar umas com as outras?

GLM-Zero respondeu rapidamente: “25 trabalhadores processam equipamentos grandes e 60 trabalhadores processam equipamentos pequenos.
Mesmo que haja outro problema difícil do AMC, ele pode resolvê-lo facilmente.
"Um conjunto consiste em 6 inteiros positivos (não distintos): 1, 7, 5, 2, 5 e X. A média (média aritmética) dos 6 números é igual a um valor no conjunto. Todos os valores possíveis de X Qual é a soma?”
Este problema envolve cinco pontos principais e mais de uma dúzia de situações que o GLM-Zero-Preview considera de forma abrangente várias possibilidades e as gera em um clique, dando-me a sensação de que está realmente imitando o pensamento humano.

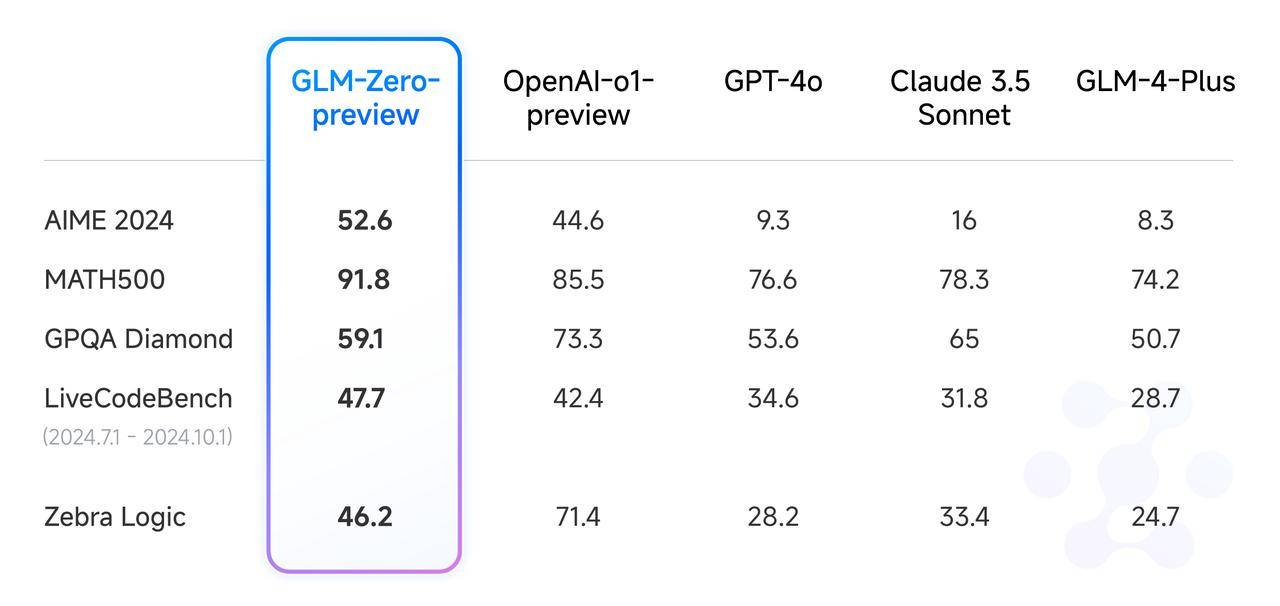
Como o primeiro modelo de inferência do GLM treinado com base na tecnologia de aprendizagem por reforço estendido, o GLM-Zero-Preview alcançou resultados equivalentes ao OpenAI o1-preview nas avaliações AIME 2024, MATH500 e LiveCodeBench.
Além disso, GLM-Zero-Preview também pode usar várias linguagens de programação com proficiência para ajudar os desenvolvedores a escrever código rapidamente em termos de depuração de código, também pode identificar erros rapidamente e fornecer sugestões detalhadas de reparo;
Por exemplo, você só precisa inserir o comando "Ajude-me a escrever um jogo interessante de tiro em primeira pessoa em html" e o GLM-Zero-Preview pode concluir o jogo a seguir de forma rápida e independente.

A Zhipu lançará em breve a versão oficial do GLM-Zero, estendendo a capacidade de pensamento profundo da lógica matemática para tecnologias mais gerais e continuando a avançar em direção à AGI.
Claro, ainda existem muitas lacunas entre o atual GLM-Zero-Preview e o modelo o3 da OpenAI, mas uma jornada de mil milhas começa com uma única etapa. Zhipu disse que a tecnologia de aprendizagem por reforço iterativo continuará a ser otimizada no futuro.
Na verdade, fabricantes como a Zhipu apostam totalmente nos modelos de inferência, o que reflecte que a era GPT está em transição para a era da inferência.
Diferente dos modelos anteriores baseados em GPT, o modelo de inferência não é treinado para prever pensamentos humanos, mas para construir sua própria estrutura de pensamento por meio do treinamento do "pensamento" e tirar conclusões por meio de um processo de raciocínio rigoroso.
A chegada da era do raciocínio marca que a IA pode começar a passar da “imitação” para o “pensamento”.
O GLM-Zero-Preview lançado pela Zhipu também é um reflexo dessa tendência.
Ao observá-lo respondendo a perguntas, você descobrirá que ele não dá respostas diretamente, mas mostra um processo de raciocínio completo – propondo hipóteses, analisando condições e tirando conclusões. Cada etapa do pensamento aprofundado é claramente visível.
No futuro, à medida que surgirem mais modelos como o1 e GLM-Zero-Preview, a IA dará um grande passo em direção ao mesmo nível cognitivo dos humanos. Em outras palavras, também poderemos estar testemunhando um importante ponto de viragem histórico——.
A visão de Zhipu é “fazer com que as máquinas pensem como os humanos”. Quando as máquinas começarem a “pensar” verdadeiramente, a compreensão humana da inteligência atingirá um novo nível.
# Bem-vindo a seguir a conta pública oficial do WeChat do aifaner: aifaner (WeChat ID: ifanr). Mais conteúdo interessante será fornecido a você o mais rápido possível.
