
Atualização do modelo mundial de Fei-Fei Li: gere mundos 3D em tempo real, apenas com uma GPU

Enquanto Ultraman, da OpenAI, ainda comprava placas gráficas e poder de computação em todos os lugares para dar suporte ao seu modelo de geração de vídeo Sora 2.
O laboratório de Fei-Fei Li, The World Labs, consegue rodar um mundo inteiro em uma única placa de vídeo. Hoje, eles lançaram uma nova tecnologia chamada RTFM (Real-Time Frame Model), um modelo de geração de mundos em tempo real completamente novo.

Diferentemente do Marble, o mundo gerado por imagens lançado em meados de setembro, o RTFM não apenas usa uma única foto para gerar um mundo 3D que podemos explorar e percorrer livremente, mas, o mais importante, ele foi projetado para rodar eficientemente em uma única GPU H100 e gerá-lo em tempo real.
Atualmente, o RTFM foi lançado oficialmente como uma versão de pré-visualização de pesquisa, e uma demonstração é fornecida para você experimentar.
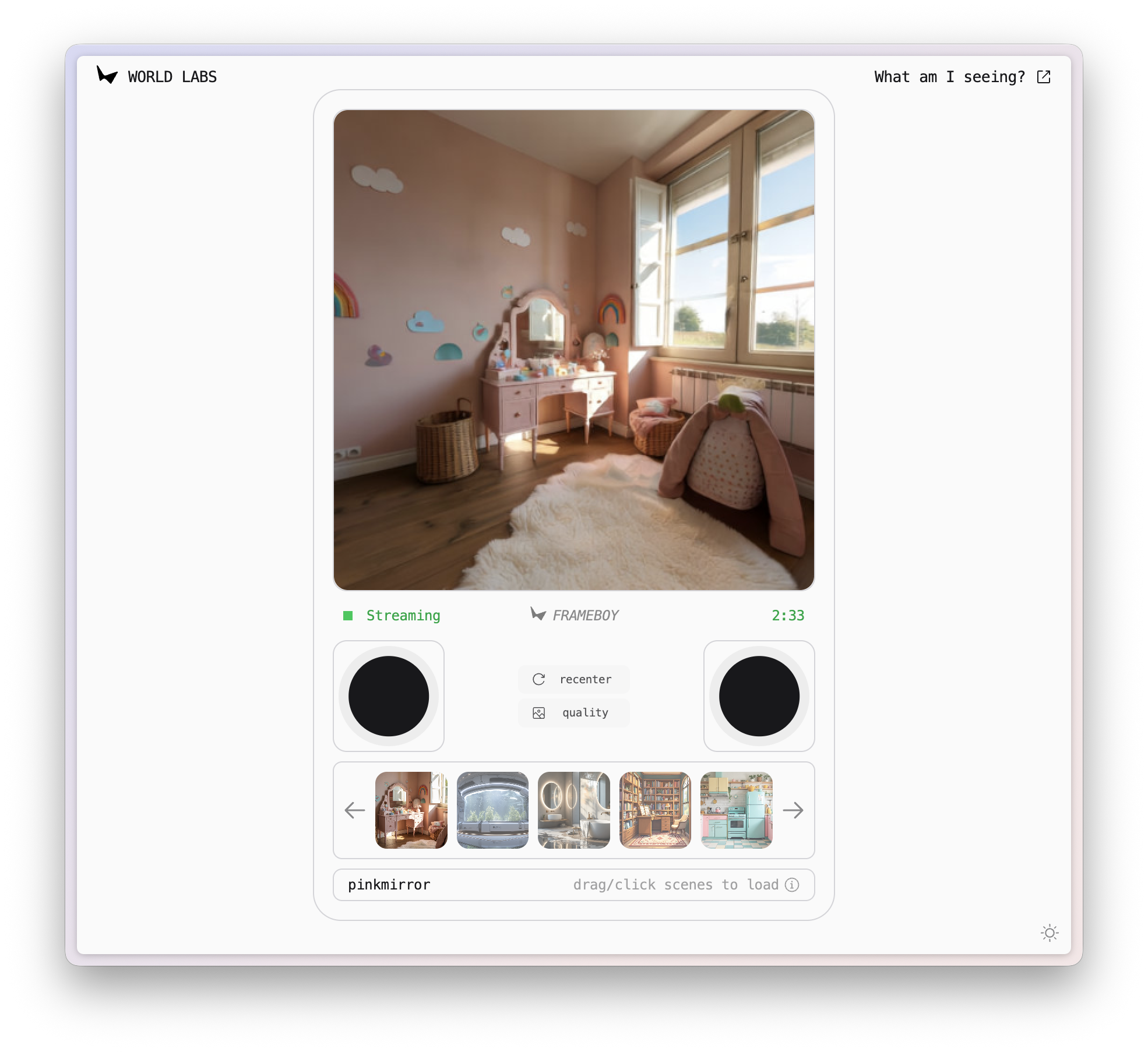
▲ Link de demonstração RTFM: https://rtfm.worldlabs.ai/
Descobri inesperadamente que o nome desta demo é FRAMEBOY. Combinado com o layout da página, rapidamente me lembrei do antigo console Game Boy.
Um mundo como esse, com iluminação, reflexos e sombras realistas, tudo acontecendo em tempo real diante dos nossos olhos, é, de certa forma, apenas outra maneira de jogar.
Mais do que geração, mais sobre interação em tempo real
A principal capacidade do RTFM é gerar vídeos interativos em tempo real. Ele pode começar com uma imagem estática e renderizar uma cena 3D livremente explorável.
Ao contrário de muitos modelos do mundo, o RTFM é capaz de aprender e renderizar efeitos visuais extremamente complexos e realistas. Sejam reflexos em pisos de mármore liso, sombras projetadas por objetos ao sol ou vistas através de vidro, o RTFM simula tudo com precisão.
O RTFM não depende da programação gráfica tradicional, mas permite que o modelo evolua continuamente por meio do aprendizado de ponta a ponta de dados de vídeo massivos.

A base dessa capacidade são três princípios fundamentais em torno dos quais o RTFM foi projetado.
Eficiência: Se quisermos aproximar o futuro do presente, os requisitos computacionais do modelo mundial são o maior obstáculo.
Seja um vídeo gerado por IA, como o Sora, ou o Genie 3 do Google, que ainda não foi lançado oficialmente, ambos representam enormes desafios computacionais. Pesquisas relacionadas observaram que, para gerar um fluxo de vídeo interativo 4K a 60 fps em tempo real, o modelo de IA precisa processar um número de tokens por segundo aproximadamente equivalente ao conteúdo de texto de um livro de Harry Potter.
Se quisermos manter a persistência desse conteúdo gerado durante uma interação com duração superior a uma hora, o contexto necessário para o processamento excederá 100 milhões de tokens. Isso não é prático nem acessível para a infraestrutura de computação atual.

O objetivo da equipe de Fei-Fei Li é “executar os modelos de amanhã no hardware de hoje e fornecer a visualização da mais alta fidelidade”.
Por meio da otimização extrema da arquitetura, da destilação do modelo e do processo de inferência, bem como de um redesenho de todo o sistema, eles alcançaram com sucesso o RTFM, usando apenas uma única GPU H100 para realizar inferência em taxas de quadros interativas e gerar resultados em tempo real.
Escalabilidade: de modelos de vídeo a modelos mundiais.
Os mecanismos 3D tradicionais utilizam estruturas explícitas, como malhas triangulares, nuvens de pontos gaussianas e renderização de voxels, baseando-se inteiramente em conhecimentos complexos de computação gráfica. Cada objeto precisa ser modelado, texturizado, iluminado e sombreado. Essa abordagem é semelhante ao mundo 3D Hunyuan que apresentamos anteriormente, com foco na geração de um pipeline 3D completo.

Método 3D tradicional (esquerda) e método RTFM (direita)
Ao contrário do Hunyuan, o World Lab adota uma abordagem diferente. O RTFM não cria modelos 3D explícitos. Em vez disso, utiliza um transformador de difusão autorregressivo semelhante ao Sora para aprender padrões do mundo diretamente a partir de sequências de quadros de vídeo.
Por exemplo, o modelo não precisa mais saber "isto é uma parede" ou "aquilo é uma luminária". Ele só aprende o que é "senso espacial" por meio de milhares de vídeos e aprende a prever a próxima nova perspectiva a partir da sequência de imagens 2D de entrada.
Diferentemente da rota de geração de ativos 3D, o RTFM pode utilizar melhor os dados e o poder de computação em constante crescimento, alcançando assim escalabilidade ilimitada.
Persistência , que mantém o modelo do mundo consistente como uma nano banana.
A maioria dos modelos de geração de vídeo tem uma falha inerente: falta memória. Embora o Sora consiga gerar 25 segundos de imagens impressionantes de uma só vez, o mundo acaba quando o vídeo é gerado, e ele não consegue proporcionar interação contínua.
Entretanto, se quisermos lembrar de todos os cenários, a carga computacional inevitavelmente se acumulará infinitamente à medida que a exploração se aprofunda.

O RTFM tenta garantir a persistência do mundo gerado. Ele introduz um mecanismo chamado "memória espacial", que atribui uma "pose" (posição e orientação) precisa no espaço 3D a cada quadro gerado.
Ao gerar novas imagens, o modelo usa uma técnica chamada "malabarismo de contexto", que usa apenas quadros próximos à nova imagem como referências, em vez do contexto global.

Isso habilita o RTFM, permitindo-nos entrar no mundo repetidamente, sair dele e retornar a ele sem aumentar a carga computacional.
Atualmente, a demonstração do RTFM dura apenas três minutos, após os quais perde a memória do mundo. Passei um bom tempo arrastando os joysticks esquerdo e direito na demonstração, e isso me lembrou da declaração de Fei-Fei Li de que a inteligência espacial deveria ser o próximo passo na IA.

Será que no futuro realmente haverá uma chance de criar uma conexão clara entre o mundo real e o virtual, como em Jogador Nº 1? Olhando apenas para o modelo de mundo atual, ainda há muito conteúdo para carregar.
Afinal, mesmo uma única GPU H100 custa mais de US$ 25.000. Mas, à medida que o preço do poder de computação cai e os algoritmos se tornam mais rápidos, podemos ver uma "atualização" verdadeiramente significativa no modelo mundial, um dia em que a realidade será totalmente gerada.
#Bem-vindo a seguir a conta pública oficial do WeChat do iFaner: iFaner (ID do WeChat: ifanr), onde mais conteúdo interessante será apresentado a você o mais breve possível.
