
Alcançando o GPT-5 por US$ 4,6 milhões? A equipe de Kimi responde a tudo pela primeira vez, Yang Zhilin também comparece.

Na semana passada, foi lançado o Kimi K2 Thinking, e seu modelo de código aberto superou o OpenAI e o Anthropic, causando grande repercussão nas redes sociais. Os internautas estão dizendo que é incrível, e nós também o testamos. De fato, ele demonstra uma melhoria significativa em agentes inteligentes, código e habilidades de escrita.
A equipe da Kimi, incluindo o fundador Yang Zhilin, acaba de realizar um evento AMA (Ask Me Anything – Pergunte-me Qualquer Coisa) repleto de informações no Reddit.

▲ A equipe da Kimi, composta por três cofundadores — Yang Zhilin, Zhou Xinyu e Wu Yuxin —, participou da resposta.
Diante das perguntas incisivas da comunidade, Kimi não apenas revelou pistas sobre o modelo de próxima geração K3 e detalhes da tecnologia central KDA, mas também falou abertamente sobre o custo de 4,6 milhões e as enormes diferenças entre Kimi e OpenAI em termos de custos de treinamento e filosofia de produto.
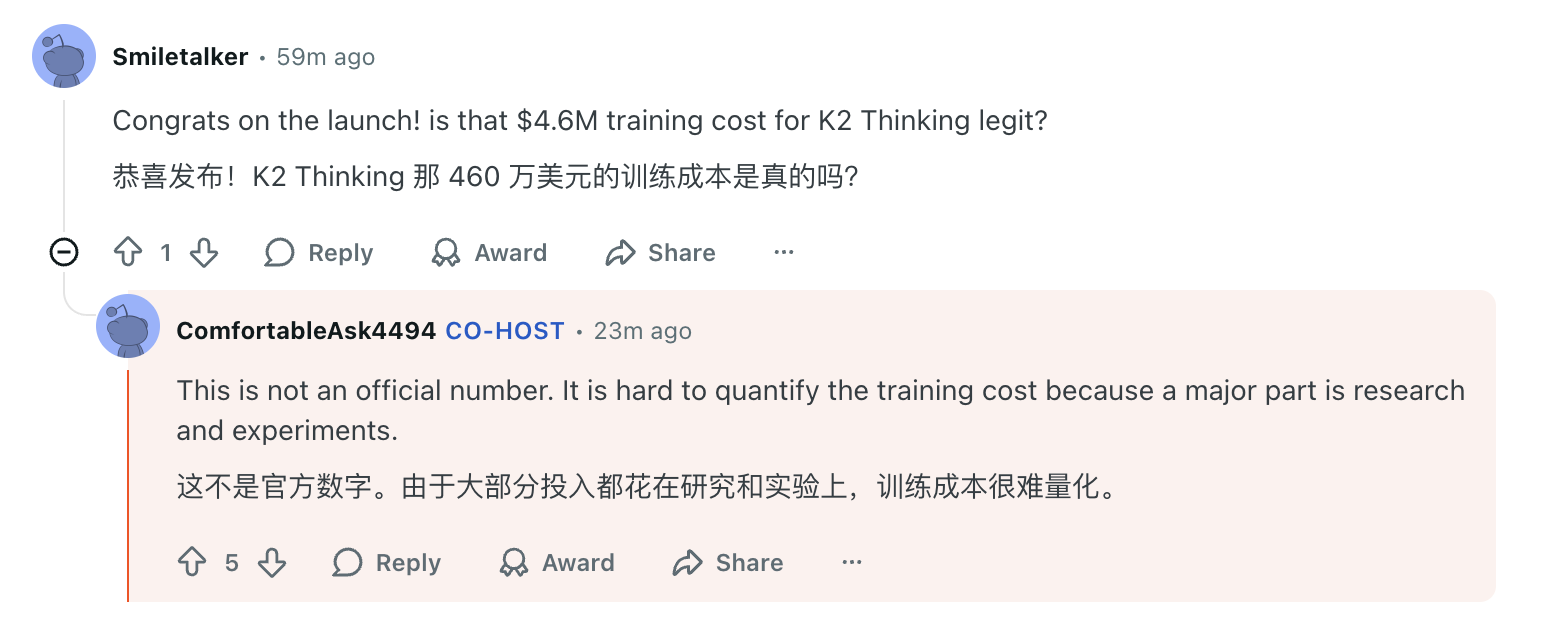
- O valor de 4,6 milhões de dólares não é oficial; o custo exato do treinamento é difícil de quantificar.
- Quando o K3 chegará? Depende de quando o centro de dados de um trilhão de dólares do Ultraman for concluído.
- A tecnologia utilizada no K3 continuará a ser empregada, incluindo o mecanismo de atenção KDA, atualmente muito eficaz.
- Ainda precisamos coletar mais dados para os modelos visuais, mas já estamos fazendo isso…

Compilamos alguns dos pontos-chave mais relevantes desta sessão de perguntas e respostas, para que você possa ver como este laboratório de IA, agora considerado líder em soluções nacionais de código aberto, enxerga seu modelo e o desenvolvimento futuro da IA.
Desafiando a OpenAI: "Nós temos nosso próprio ritmo."
A parte mais acalorada desta sessão de perguntas e respostas foi provavelmente a resposta da equipe de Kimi à OpenAI.
Uma das maiores perguntas: Quando o K3 chegará? A resposta da equipe de Kimi foi bastante inteligente: " Antes que o centro de dados de um trilhão de dólares do Ultraman seja construído. "
É evidente que isso é em parte humorístico, já que ninguém sabe quando a OpenAI conseguirá de fato construir esse centro de dados, e em parte parece ser uma resposta à admiração do mundo exterior pelo fato de Kimi conseguir alcançar o GPT-5 com menos recursos.
Quando um internauta perguntou diretamente a Kimi o que ele achava do fato da OpenAI gastar tanto dinheiro em treinamento, Kimi respondeu francamente: "Nem nós sabemos, só o Ultraman sabe", e acrescentou firmemente: " Temos nossos próprios métodos e ritmo. "
Esse ritmo independente se reflete, antes de tudo, na filosofia de seus produtos. Quando perguntados se lançariam um navegador com IA como o OpenAI, a equipe respondeu categoricamente: "Não".
Não precisamos criar outro wrapper do Chromium (interface do navegador) para construir um modelo melhor.
Eles enfatizaram que seu trabalho atual se concentra no treinamento de modelos, e a demonstração das capacidades será realizada por meio de um assistente de modelos de grande porte.
Kimi também demonstrou uma abordagem econômica em relação aos custos de treinamento e hardware. Quando a comunidade questionou se o rumor de um custo de treinamento de US$ 4,6 milhões para o K2 era realmente preciso, Kimi esclareceu que o valor estava incorreto, mas afirmou que a maior parte do dinheiro foi gasta em pesquisa e experimentação, o que dificultava a quantificação exata.
Quanto ao hardware, Kimi admitiu que usaram GPUs H800 e Infiniband, que, embora "não tão boas quanto as melhores GPUs dos EUA, e não tão numerosas", aproveitaram ao máximo cada placa.
A individualidade do modelo e o cheiro de lixo da IA
Um bom modelo precisa não só de inteligência, mas também de individualidade.
Muitos usuários gostam do estilo do Kimi K2 Instruct, considerando-o "menos lisonjeiro, porém perspicaz e único, como uma redação".
Kimi explicou que isso é resultado de uma combinação de "pré-treinamento (fornecimento de conhecimento) + pós-treinamento (aprimoramento)". Diferentes fórmulas de aprendizado por reforço (ou seja, diferentes escolhas de modelos de recompensa) resultarão em estilos diferentes, e o modelo também será projetado intencionalmente para ser menos subserviente .
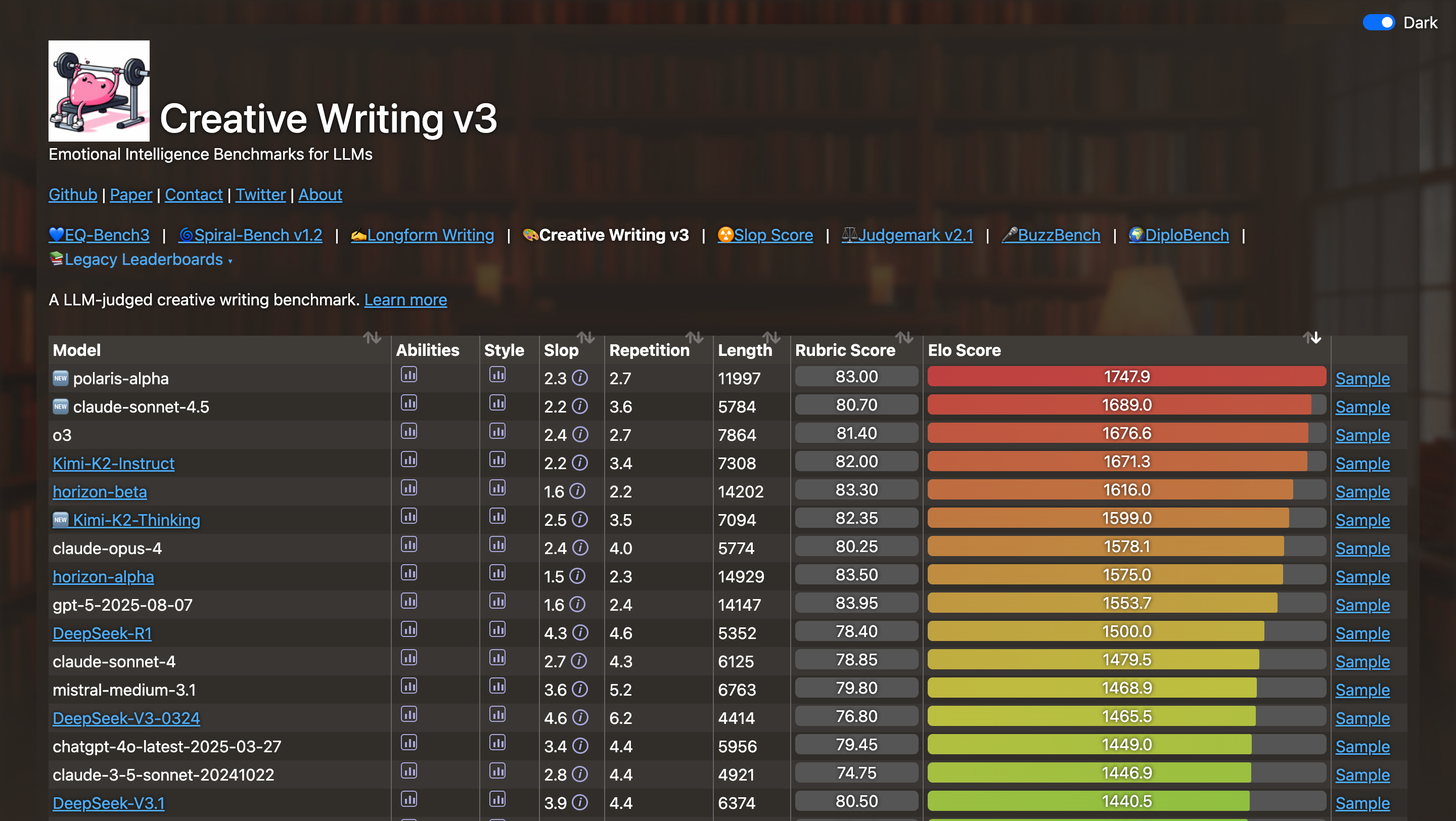
▲ Classificação da avaliação da inteligência emocional usando o modelo de linguagem amplo. Fonte da imagem: https://eqbench.com/creative_writing.html
No entanto, alguns usuários também afirmaram categoricamente que o estilo de escrita de Kimi K2 Thinking é "lixo de IA". Independentemente do tópico, o estilo é excessivamente positivo e otimista, resultando em uma forte impressão de inteligência artificial. Um usuário chegou a dar um exemplo: mesmo quando solicitado a escrever sobre conteúdo violento ou confrontador, Kimi ainda consegue manter um estilo geral positivo e otimista.
A resposta da equipe de Kimi foi muito franca. Eles reconheceram que esse é um problema comum em grandes modelos de linguagem e mencionaram que o aprendizado por reforço atual amplifica deliberadamente esse estilo.
Essa discrepância entre a experiência do usuário e os dados dos testes também se reflete no ceticismo em torno das pontuações dos benchmarks . Um internauta questionou, de forma incisiva, se o Kimi K2 Thinking foi especificamente treinado para benchmarks como o HLE a fim de alcançar uma pontuação tão alta, visto que tal pontuação parece inconsistente com sua inteligência real em uso no mundo real.
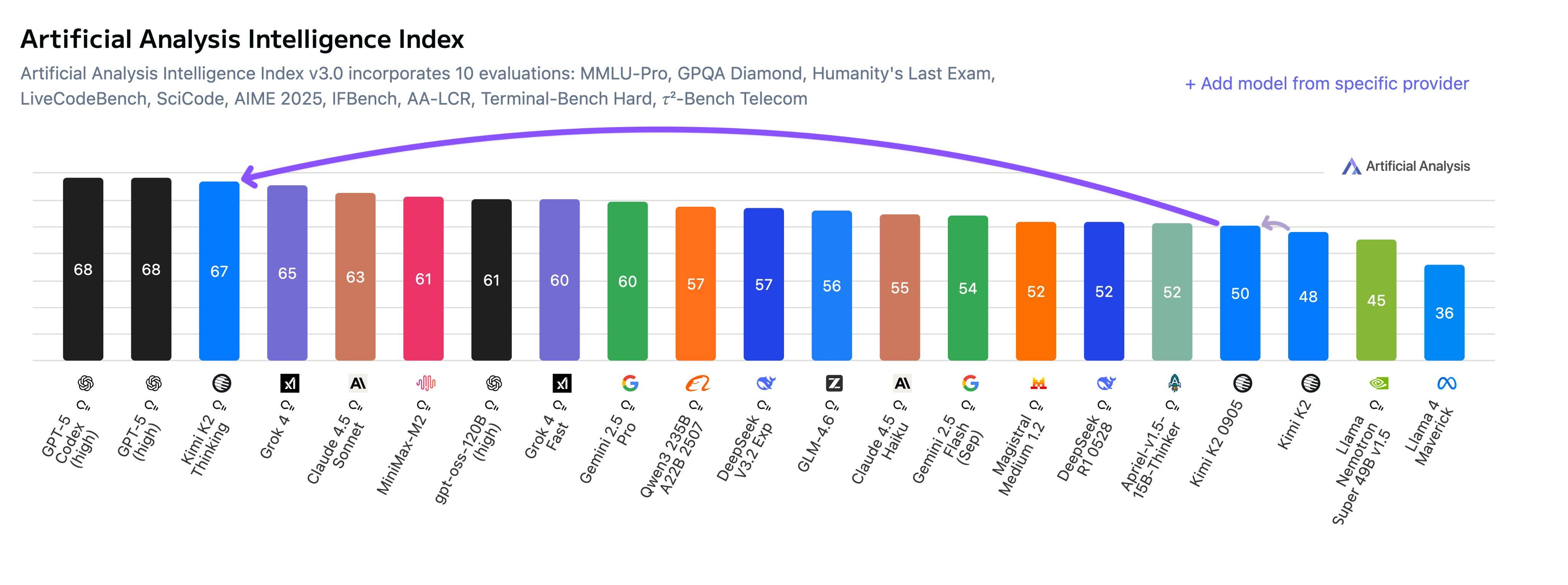
A equipe de Kimi explicou que havia feito alguns progressos modestos na melhoria do raciocínio autônomo, o que por acaso contribuiu para a alta pontuação do K2 Thinking no HLE. No entanto, eles também declararam abertamente sua direção: aprimorar ainda mais as capacidades gerais para que ele possa ser tão inteligente quanto suas pontuações de referência em aplicações do mundo real.
Internautas também comentaram que o Grok de Musk gera imagens e vídeos realizando muito trabalho NSFW (não recomendado para o ambiente de trabalho); Kimi poderia aproveitar suas habilidades de escrita para concluir algumas tarefas de escrita NSFW, o que certamente traria muitos usuários para Kimi.

Kimi apenas sorriu e permaneceu em silêncio, dizendo que era uma boa sugestão. A possibilidade de conteúdo NSFW ser suportado no futuro dependerá da descoberta de métodos de verificação de idade e do aprimoramento do alinhamento do modelo.
É evidente que Kimi não pode suportar conteúdo impróprio para menores neste momento.
Tecnologias Essenciais Reveladas: KDA, Inferência Longa e Multimodalidade
Sendo uma empresa conhecida como um "laboratório pioneiro de código aberto", e considerando que o Reddit em si é uma comunidade técnica muito grande e ativa, Kimi também compartilhou muitos detalhes técnicos nesta sessão de perguntas e respostas.
No final de outubro, Kimi detalhou uma nova arquitetura híbrida de atenção linear, a Kimi Linear, em seu artigo "Kimi Linear: Uma Arquitetura de Atenção Expressiva e Eficiente", cujo núcleo é a Atenção Delta de Kimi (KDA).

▲Implementação do algoritmo KDA, link para o artigo: https://arxiv.org/pdf/2510.26692
Em termos simples, a atenção é o mecanismo pelo qual a IA decide em quais palavras do contexto focar durante o raciocínio. Ao contrário da atenção plena e da atenção linear comuns, o KDA (Kimi Delta Attention) é um mecanismo de atenção mais inteligente e eficiente .
Durante esta sessão de perguntas e respostas, Kimi também mencionou diversas vezes que o KDA demonstrou melhoria de desempenho em cenários de aprendizado por reforço de sequências longas e que ideias relacionadas ao KDA provavelmente serão aplicadas no K3.
No entanto, Kimi também admitiu que existem vantagens e desvantagens na tecnologia. Atualmente, o principal objetivo da atenção híbrida é economizar custos computacionais, não melhorar o raciocínio. Para tarefas com entradas e saídas extensas, a atenção completa ainda apresenta melhor desempenho.
Como é que o Kimi K2 Thinking consegue realizar uma cadeia de raciocínio tão longa, envolvendo a consideração e a invocação de até 300 ferramentas? Alguns internautas chegam a acreditar que é melhor que o GPT-5 Pro.
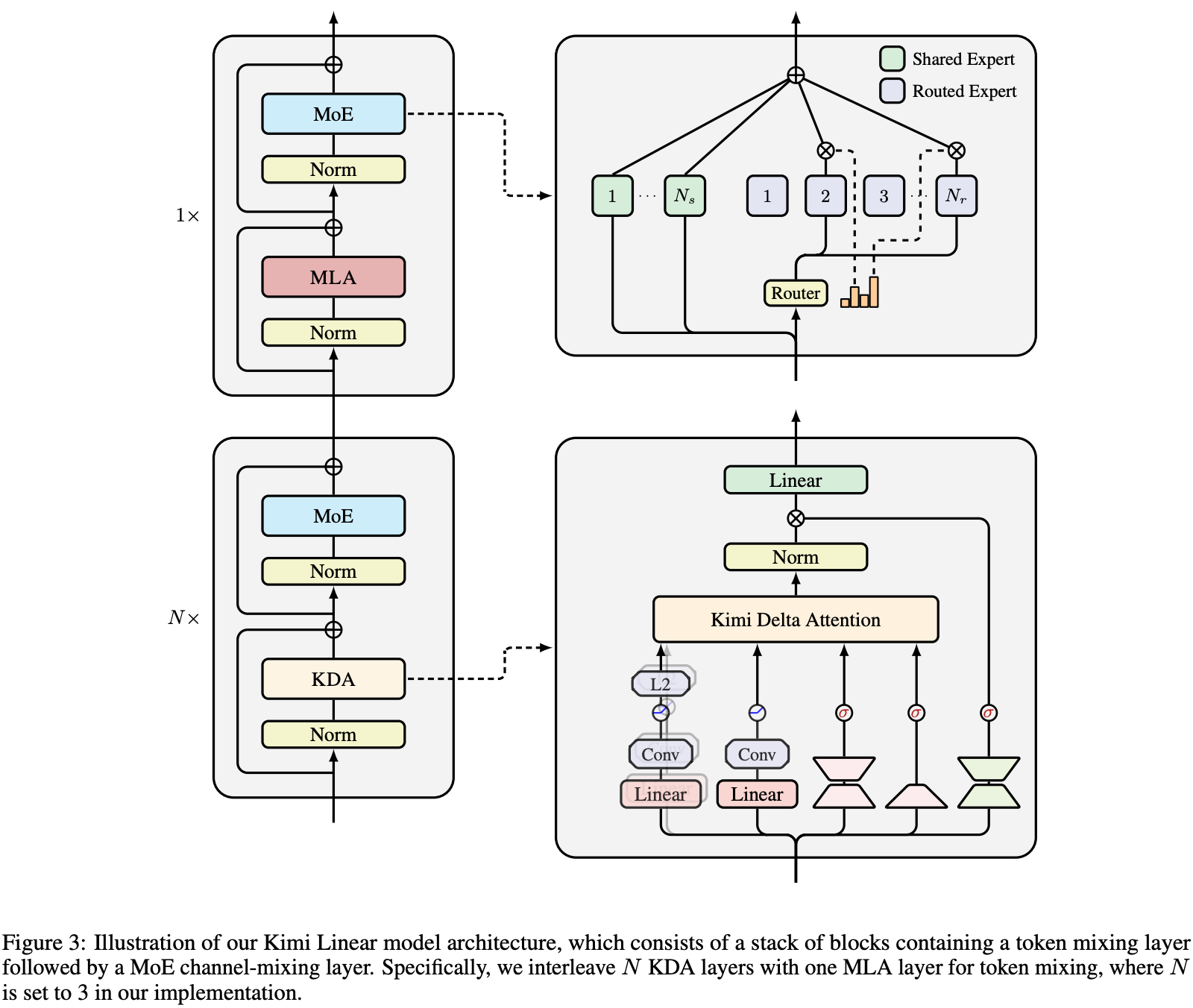
▲ Estrutura do Modelo Linear de Kimi
Kimi acredita que isso depende do método de treinamento; eles tendem a usar um número relativamente maior de tokens de pensamento para alcançar resultados ótimos . Além disso, o K2 Thinking oferece suporte nativo ao INT4, o que acelera ainda mais o processo de raciocínio.
Em nosso artigo anterior sobre o Kimi K2 Thinking, também compartilhamos a técnica de treinamento de quantização INT4, que é uma técnica de quantização eficiente (INT4 QAT). O Kimi não comprimiu os dados após o treinamento, mas manteve o modelo de computação de baixa precisão durante o processo de treinamento.
Isso traz duas grandes vantagens: maior velocidade de raciocínio e a capacidade de lidar com raciocínios de cadeia longa sem colapso lógico causado pela compressão e quantização após o treinamento.
Por fim, em relação à tão aguardada capacidade de linguagem visual, Kimi afirmou claramente: "Estamos trabalhando nisso."
O motivo para lançar primeiro o modelo de texto simples é que a aquisição de dados e o treinamento do modelo de linguagem visual exigem muito tempo, e os recursos da equipe são limitados, então só podemos priorizar uma direção.
Ecologia, Custo e Abertura: Um Futuro
A equipe de Kimi também respondeu, uma a uma, às perguntas que preocupavam desenvolvedores e usuários comuns.
Por que o modelo que suportava 1 milhão de contextos desapareceu? A resposta de Kimi foi sucinta: "O custo era muito alto". Quanto ao problema de 256 mil contextos ainda serem insuficientes para lidar com bases de código grandes, a equipe afirmou que planeja aumentar o tamanho do contexto no futuro.
Em relação ao preço da API, alguns desenvolvedores questionaram por que a cobrança é feita com base no número de chamadas à API em vez de tokens. Para usuários que programam com outras ferramentas de agentes inteligentes, como o Claude Code, a cobrança com base no número de solicitações à API é o método menos controlável e mais opaco.
Antes do envio da solicitação, o usuário não tem ideia de quantas chamadas de API a ferramenta fará ou quanto tempo a tarefa levará.

▲Programa de Membros Kimi
Kimi explicou que usaram chamadas de API para deixar mais claro aos usuários como os custos foram incorridos, além de alinhar isso ao planejamento de custos da equipe. No entanto, também indicaram que explorariam métodos de cálculo melhores.
Quando um internauta mencionou que sua empresa não permitia o uso de outros assistentes de bate-papo, Kimi aproveitou a oportunidade para expressar sua filosofia central:
Apoiamos o código aberto porque acreditamos que a inteligência artificial geral deve ser uma busca que traga união, e não divisão.
Quanto à pergunta crucial — quando a Inteligência Artificial Geral (IAG) chegará? Kimi acredita que a IAG é difícil de definir, mas as pessoas já começaram a sentir a atmosfera da IAG, e modelos mais poderosos estão a caminho.
Ao contrário da agressiva campanha de publicidade e marketing da Kimi no ano passado, as respostas de Yang Zhilin e sua equipe nesta sessão de perguntas e respostas demonstraram que, em um contexto de crescente domínio das tecnologias de código aberto nacionais no mercado global de modelos de linguagem de código aberto, a Kimi está mais confiante e tem uma compreensão mais clara do seu próprio ritmo.
O princípio fundamental é claro: nesta corrida da IA, onde se gasta muito dinheiro e até mesmo se disputa espaço, continuar no caminho do código aberto é a única maneira de impulsionar a tecnologia.
#Siga a conta oficial do iFanr no WeChat: iFanr (ID do WeChat: ifanr), onde você encontrará conteúdo ainda mais interessante o mais breve possível.
