
Alcançando o GPT-4o, o modelo mais poderoso Llama 3.1 405B se tornou um deus da noite para o dia, Zuckerberg: código aberto lidera uma nova era
Agora mesmo, Meta lançou o modelo Llama 3.1 conforme programado.
Simplificando, o recém-lançado Llama 3.1 405B é o modelo mais poderoso da Meta até o momento. É também o modelo grande de código aberto mais poderoso do mundo e também o modelo grande mais poderoso do mundo.
A partir de hoje, não há necessidade de discutir sobre os méritos dos grandes modelos de código aberto e dos grandes modelos de código fechado, porque o Llama 3.1 405B prova com força irrefutável que a batalha pelas rotas não afeta a força técnica final.
Deixe-me primeiro resumir as características do modelo Llama 3.1:
- Contém três tamanhos de 8B, 70B e 405B, o contexto máximo foi aumentado para 128K, suporta vários idiomas, possui excelente desempenho de geração de código e possui capacidades de raciocínio complexas e habilidades de uso de ferramentas.
- A julgar pelos resultados dos testes de benchmark, o Llama 3.1 superou o GPT-4 0125, competindo com o GPT-4o e o Claude 3.5.
- Fornecendo códigos e pesos de modelo abertos/livres, a licença permite que os usuários ajustem, destilem o modelo em outras formas e ofereçam suporte à implantação em qualquer lugar
- Fornece API Llama Stack para facilitar o uso integrado e oferece suporte à coordenação de vários componentes, incluindo chamada de ferramentas externas
Em anexo está o endereço de download do modelo:
https://huggingface.co/meta-llama
https://llama.meta.com/

A xícara supergrande chega ao topo do modelo mais potente do mundo, enquanto as xícaras médias e grandes escondem surpresas
O Llama 3.1 lançado desta vez vem em três versões de tamanho: 8B, 70B e 405B.
A julgar pelos resultados dos testes de benchmark, o supergrande Llama 3.1 405B pode suportar todas as pressões do GPT-3.5 Turbo, e a maioria das pontuações dos testes de benchmark excedem o GPT-4 0125.
Diante do mais poderoso modelo grande de código fechado GPT-4o lançado anteriormente pela OpenAI e do Claude 3.5 Sonnet de primeira linha, a Supercopa ainda tem o poder de lutar. Pode-se até dizer apenas pelos parâmetros do papel que o Llama 3.1. 405B marca o código aberto Pela primeira vez, modelos grandes alcançaram modelos grandes de código fechado.
Analisando especificamente os resultados do benchmark, o Llama 3.1 405B obteve pontuação de 98,1 no benchmark NIH/Multi-needle. Embora não seja tão bom quanto o GPT-4o, também mostra que sua capacidade de processar informações complexas é perfeita.
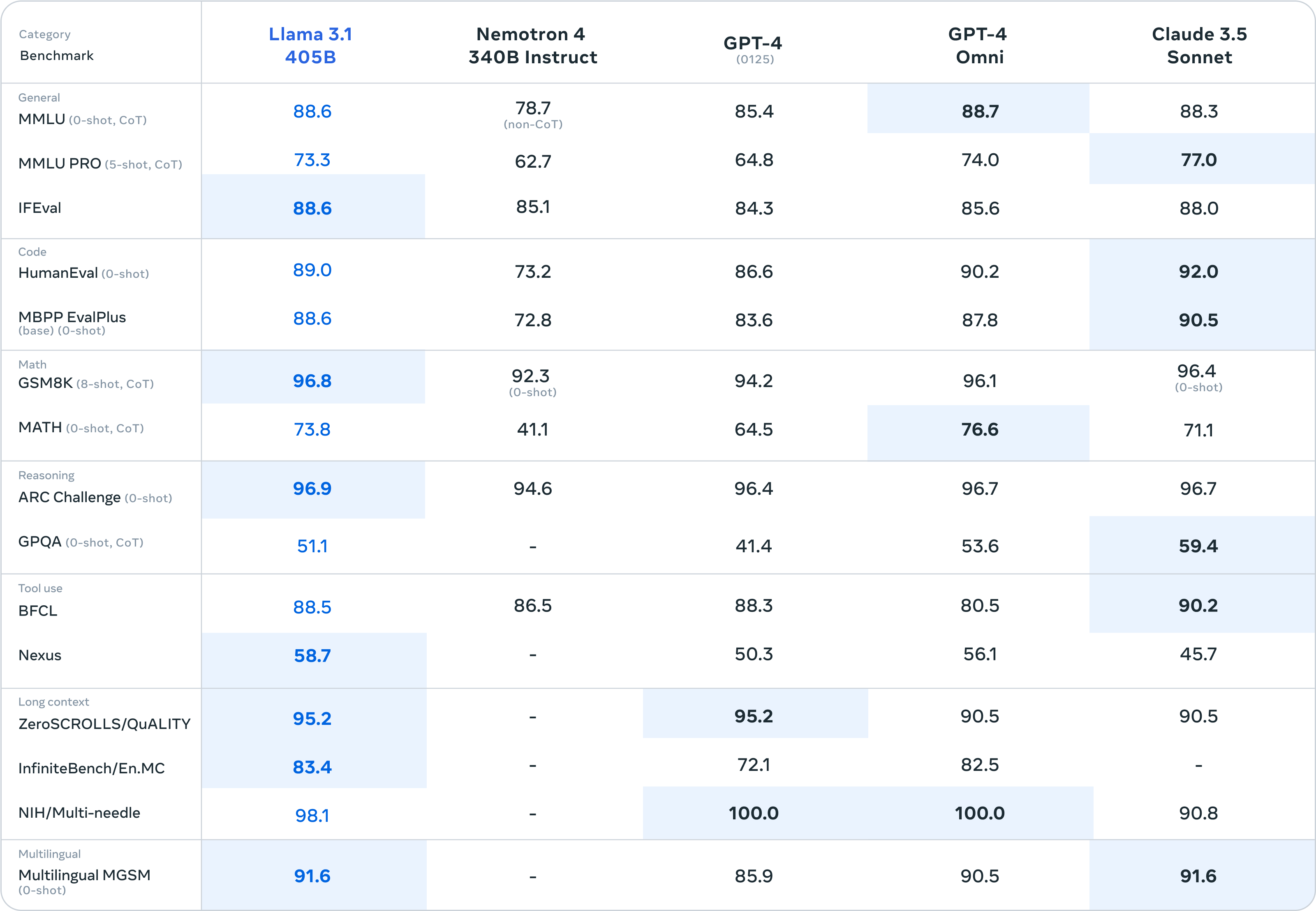
E o Llama 3.1 405B obteve pontuação de 95,2 no benchmark ZeroSCROLLS/QUALITY, o que também significa que ele tem uma forte capacidade de integrar grandes quantidades de informações de texto. Esses resultados mostram que o modelo LLaMA3.1 405B é excelente no processamento de textos longos e é adequado para. focando em LLM em RAG Para desenvolvedores de aplicativos de IA, o desempenho é bastante fácil de usar.
Particularmente preocupante é que o Human-Eval é o principal responsável por avaliar a capacidade do modelo de compreender e gerar código e resolver lógica abstrata, e o Llama 3.1 405B também tem uma ligeira vantagem na competição com outros modelos grandes.
Além do prato principal Llama 3.1 405B, os acompanhamentos Llama 3.1 8B e Llama 3.1 70B também dão um bom show de “pequenas vitórias sobre grandes”.
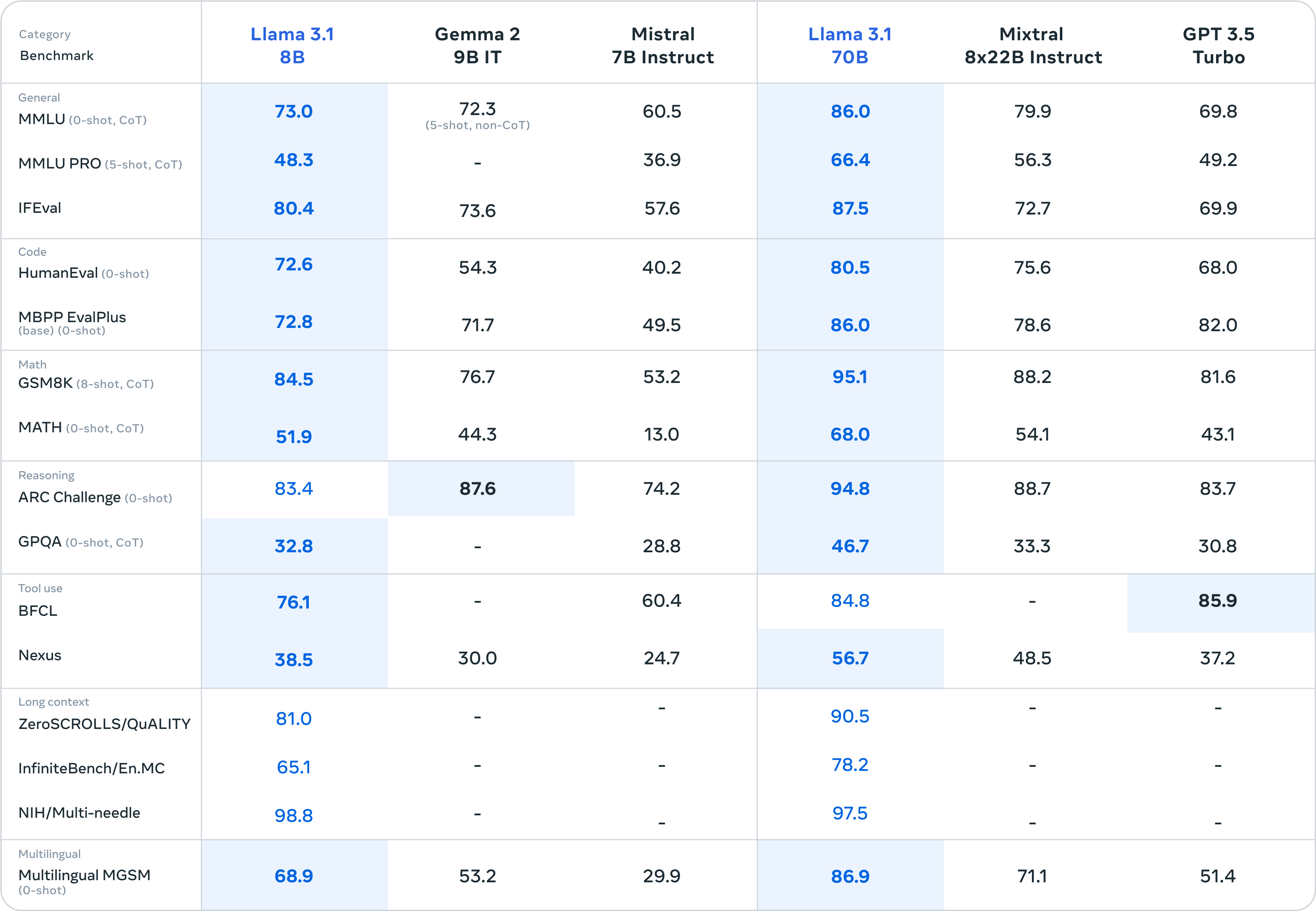
A julgar pelos resultados dos testes de benchmark, o Llama 3.1 8B quase esmagou o Gemma 2 9B 1T e o Mistral 7B Instruct. O desempenho geral foi significativamente melhorado do que o Llama 3 8B. O Llama 3.1 70B pode até superar o GPT-3.5 Turbo e o modelo Mixtral 8×7B com excelente desempenho.
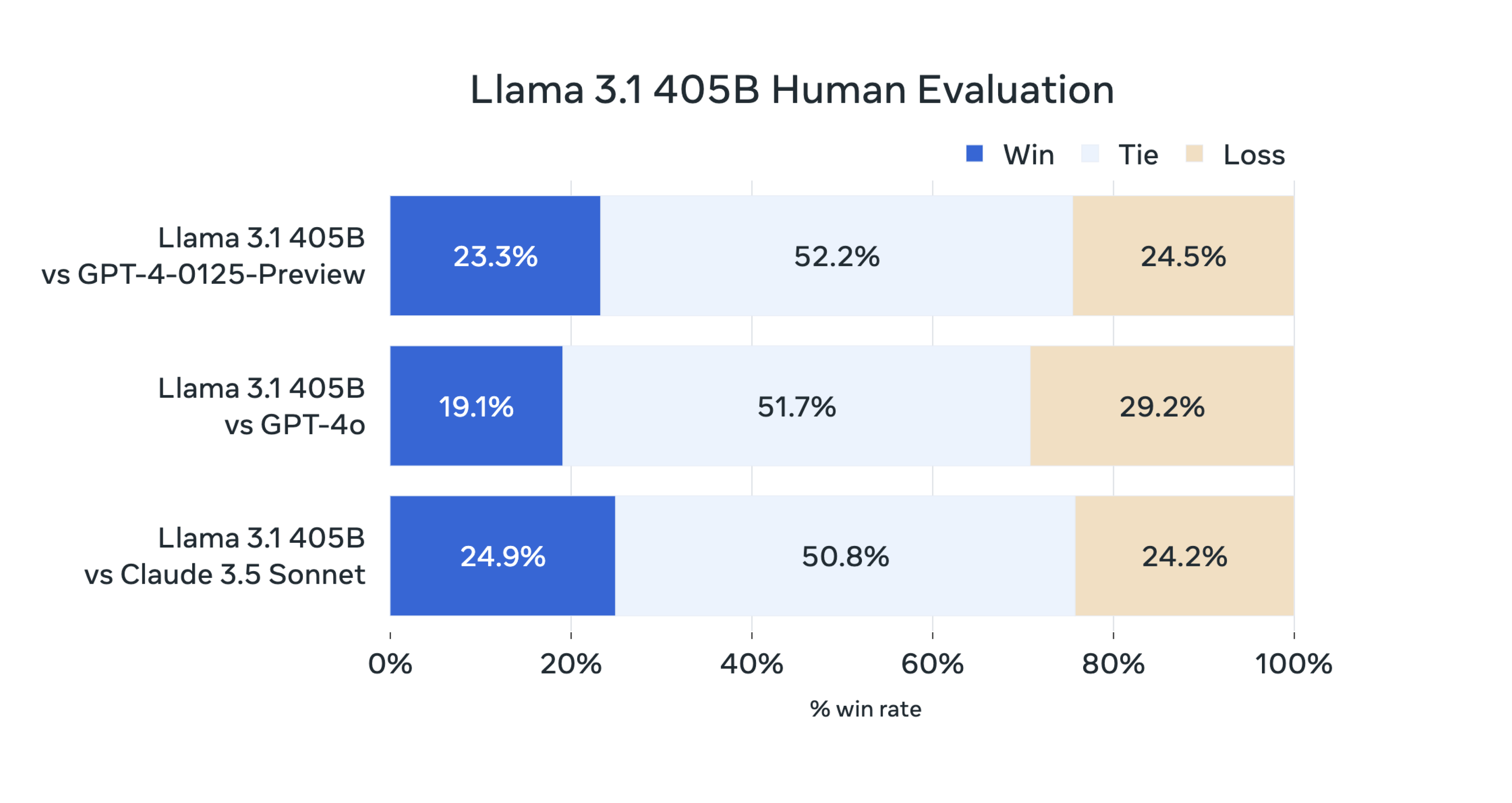
De acordo com a introdução oficial, neste lançamento, a equipe de pesquisa do Llama avaliou o desempenho do modelo em mais de 150 conjuntos de dados de benchmark abrangendo vários idiomas, e a equipe também realizou um grande número de avaliações manuais.
A conclusão final é:
Nosso modelo principal é competitivo com modelos básicos de ponta, como GPT-4, GPT-4o e Claude 3.5 Sonnet em múltiplas tarefas. Ao mesmo tempo, nosso modelo pequeno também apresenta competitividade quando comparado com modelos fechados e abertos com número semelhante de parâmetros.
Como é feita a Lhama 3.1 405B
Então, como o Llama 3.1 405B é treinado?
De acordo com o blog oficial, sendo o maior modelo do Meta até o momento, o Llama 3.1 405B usa mais de 15 trilhões de tokens para treinamento.
Para alcançar um treinamento nesta escala e alcançar os resultados esperados em um curto espaço de tempo, a equipe de pesquisa também otimizou toda a pilha de treinamento e treinou em mais de 16.000 GPUs H100. Este também é o primeiro modelo Llama treinado em tão grande escala. .
A equipe também fez algumas otimizações durante o processo de treinamento, com foco em manter o processo de desenvolvimento do modelo escalável e simples:
- Uma arquitetura de modelo Transformer de decodificador padrão com apenas pequenos ajustes foi escolhida em vez de um modelo especialista híbrido para maximizar a estabilidade do treinamento.
- Um procedimento iterativo de pós-treinamento é empregado, usando ajuste fino supervisionado e otimização de preferência direta em cada rodada. Isso permite que a equipe de pesquisa crie dados sintéticos da mais alta qualidade para cada rodada e melhore o desempenho de cada recurso.
- Em comparação com a versão antiga do modelo Llama, a equipe de pesquisa melhorou a quantidade e a qualidade dos dados usados para pré-treinamento e pós-treinamento, incluindo o desenvolvimento de um pipeline de mais pré-processamento e gerenciamento para dados de pré-treinamento e o desenvolvimento de mais garantia de qualidade rigorosa e métodos de filtragem para dados pós-treinamento.
Os funcionários da Meta afirmaram que, sob a influência da Lei de Escala, o novo modelo principal superou os modelos menores treinados usando o mesmo método.
A equipe de pesquisa também utilizou o modelo de parâmetro 405B para melhorar a qualidade pós-treinamento de pequenos modelos.
Para apoiar a inferência de produção em massa de modelos em escala 405B, a equipe de pesquisa quantizou o modelo de precisão de 16 bits (BF16) para precisão de 8 bits (FP8). em um único nó de servidor executado.
Há também alguns detalhes que vale a pena explorar sobre o Llama 3.1 405B, como seu design que aposta na praticidade e segurança, permitindo compreender e executar melhor as instruções do usuário.
Através de métodos como ajuste fino supervisionado, amostragem de rejeição e otimização de preferência direta, várias rodadas de alinhamento são realizadas com base no modelo pré-treinado para construir um modelo de chat 3.1 405B também pode se adaptar com mais precisão a cenários de uso específicos. e necessidades do usuário, melhorando o desempenho dos aplicativos reais.
Vale ressaltar que a equipe de pesquisa do Llama utiliza a geração de dados sintéticos para produzir a grande maioria dos exemplos de SFT, o que significa que eles não dependem de dados do mundo real, mas de dados gerados por algoritmos para treinar o modelo.
Além disso, a equipe de pesquisa continua a melhorar a qualidade dos dados sintetizados através de múltiplos processos iterativos. Para garantir a alta qualidade dos dados sintéticos, a equipe de pesquisa utilizou uma variedade de técnicas de processamento de dados para filtragem e otimização de dados.
Através destas técnicas, a equipa é capaz de dimensionar a quantidade de dados de ajuste fino para que não sejam apenas aplicáveis a uma única função, mas possam ser utilizados em múltiplas funções, aumentando a aplicabilidade e flexibilidade do modelo.
Simplificando, a aplicação desta tecnologia de geração e processamento de dados sintéticos visa criar uma grande quantidade de dados de treinamento de alta qualidade, o que ajuda a melhorar a capacidade de generalização e a precisão do modelo.
Como defensor da rota do modelo de código aberto, Meta também demonstrou sinceridade nas "instalações de suporte" do modelo Llama.
- Como parte de um sistema de IA, o modelo Llama suporta a coordenação de vários componentes, incluindo a chamada de ferramentas externas.
- Publique sistemas de referência e exemplos de aplicativos de código aberto, incentive a participação e colaboração da comunidade e defina interfaces de componentes.
- Promova a interoperabilidade de componentes da cadeia de ferramentas e aplicativos de agentes por meio da interface padronizada "Llama Stack".
- Após o lançamento do modelo, todos os recursos avançados estarão abertos aos desenvolvedores, incluindo fluxos de trabalho avançados, como geração de dados sintéticos.
- O Llama 3.1 405B vem com um pacote de presente com ferramentas integradas, incluindo projetos importantes para simplificar o processo desde o desenvolvimento até a implantação.
Vale ressaltar que no novo acordo de código aberto, Meta não proíbe mais o uso do Llama 3 para melhorar outros modelos, incluindo o mais forte Llama 3.1 405B, um verdadeiro bom código aberto.
Em anexo está o endereço do relatório de treinamento da tese de 92 páginas:
https://ai.meta.com/research/publications/the-llama-3-herd-of-models/
Uma nova era liderada pelo código aberto
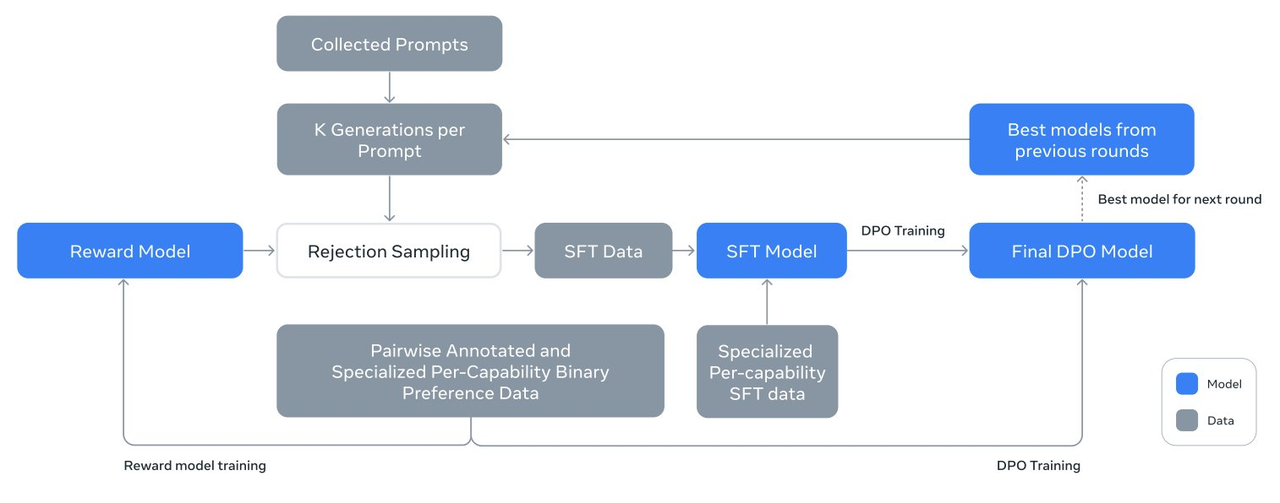
O internauta @ ZHOZHO672070 também testou rapidamente as respostas do Llama 3.1 405B Instruct FP8 a duas perguntas clássicas no Hugging Chat.
Infelizmente, o Llama 3.1 405B encontrou uma reviravolta ao resolver o problema de "quem é maior, 9,11 ou 9,9", mas depois de tentar novamente, deu a resposta correta. Em termos da anotação pinyin de “Eu peguei”, seu desempenho também é aceitável.
Os internautas usaram o modelo Llama 3.1 para construir e implantar rapidamente um chatbot em menos de 10 minutos.
Além disso, o cientista interno do Llama @astonzhangAZ também revelou no X que sua equipe de pesquisa está atualmente considerando a integração de funções de imagem, vídeo e voz no Llama 3.
O debate entre código aberto e código fechado continua na era dos grandes modelos, mas o lançamento de hoje do novo modelo Meta Llama 3.1 põe fim a este debate.
Meta declarou oficialmente: “Até agora, os modelos de linguagem de código aberto em grande escala ficaram atrás dos modelos fechados em termos de funcionalidade e desempenho. Agora, estamos inaugurando uma nova era liderada pelo código aberto”.
O nascimento do Meta Llama 3.1 405B prova uma coisa: a capacidade de um modelo não reside na abertura ou no fechamento, mas no investimento de recursos, nas pessoas e equipes por trás dele, etc. mas sempre haverá pessoas que carregam esta bandeira.
Como o primeiro gigante a tirar vantagem da situação, Meta também recebeu o título de primeiro SOTA a superar o modelo grande de código fechado mais forte.

O CEO da Meta, Zuckerberg, escreveu em um longo artigo "Open Source AI Is the Path Forward" lançado hoje:
"A partir do próximo ano, esperamos que o futuro Llama seja o mais avançado do setor. Mas antes disso, o Llama já estará liderando o caminho em código aberto, capacidade de modificação e eficiência de custos."
Os modelos de IA de código aberto podem não ter como objetivo superar o código fechado, ou por igualdade técnica, para que não se tornem um meio para algumas pessoas obterem lucros, ou pela esperança de que todos adicionem combustível à prosperidade da IA. ecossistema.
Como Zuckerberg descreveu sua visão no final de sua longa postagem:
Acredito que a versão Llama 3.1 será um ponto de viragem na indústria e a maioria dos desenvolvedores começará a usar principalmente tecnologias de código aberto. Espero que esta tendência continue a partir de agora… Juntos, estamos comprometidos em trazer os benefícios da IA. para todos ao redor do mundo.
# Bem-vindo a seguir a conta pública oficial do WeChat de Aifaner: Aifaner (WeChat ID: ifanr). Mais conteúdo interessante será fornecido a você o mais rápido possível.
