
AGI está chegando rapidamente! O modelo multimodal do Congresso Nacional Popular realiza atualização independente pela primeira vez, e a geração de vídeos fotográficos supera Sora

AGI (inteligência artificial geral) é o Santo Graal de toda a indústria de IA.
O ex-cientista-chefe da OpenAI, Ilya Sutskeve, expressou uma opinião no ano passado: “Desde que possamos prever muito bem o próximo token, podemos ajudar os humanos a alcançar AGI”.
O vencedor do Prêmio Turing, Geoffrey Hinton, conhecido como o pai do aprendizado profundo, e o CEO da OpenAI, Sam Altman, acreditam que a AGI chegará dentro de dez anos, ou até antes.
A AGI não é o fim, mas um novo ponto de partida na história do desenvolvimento humano. Há muitas coisas a considerar no caminho para a AGI, e a indústria chinesa de IA também é uma força que não pode ser ignorada.
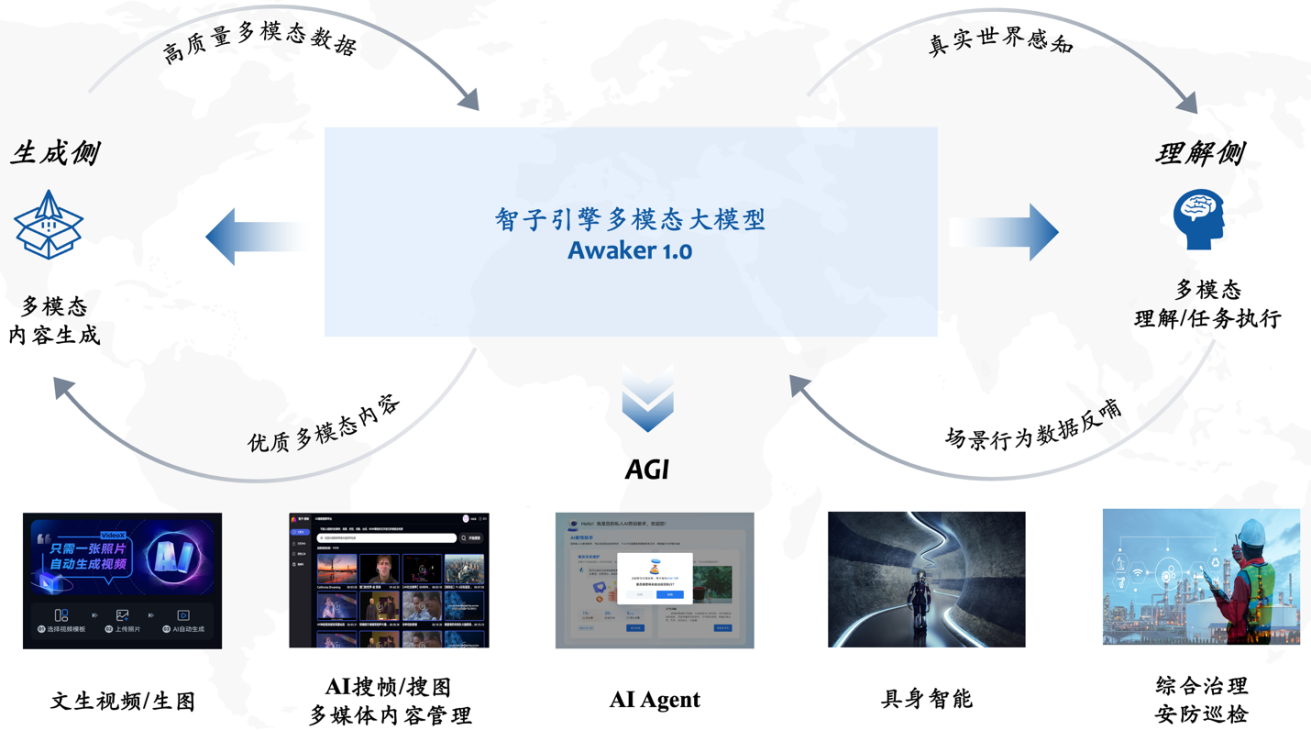
No Fórum Zhongguancun Fórum Paralelo Geral de Inteligência Artificial realizado em 27 de abril, Sophon Engine, uma empresa iniciante afiliada à Universidade Renmin da China, lançou grandiosamente um novo grande modelo multimodal Awaker 1.0, dando um passo crucial em direção à AGI.
Comparado com o modelo de sequência ChatImg da geração anterior do mecanismo Sophon, o Awaker 1.0 adota uma nova arquitetura MOE e possui recursos de atualização independente. É o primeiro grande modelo multimodal da indústria a obter uma atualização independente "verdadeira" . Em termos de geração visual, o Awaker 1.0 usa um VDT de base de geração de vídeo totalmente desenvolvido, que alcança melhores resultados do que Sora na geração de vídeos fotográficos, quebrando a dificuldade da "última milha" de pousar modelos grandes.

Modelo básico MOE do Awaker
Do lado do entendimento, o modelo básico do Awaker 1.0 resolve principalmente o problema de conflitos graves no pré-treinamento multimodal e multitarefa. Beneficiando-se da arquitetura MOE multitarefa cuidadosamente projetada, o modelo básico do Awaker 1.0 pode não apenas herdar os recursos básicos do grande modelo multimodal ChatImg da geração anterior do Sophon Engine, mas também aprender os recursos exclusivos necessários para cada tarefa multimodal . Em comparação com o grande modelo multimodal ChatImg da geração anterior, os recursos do modelo básico do Awaker 1.0 foram bastante aprimorados em múltiplas tarefas.
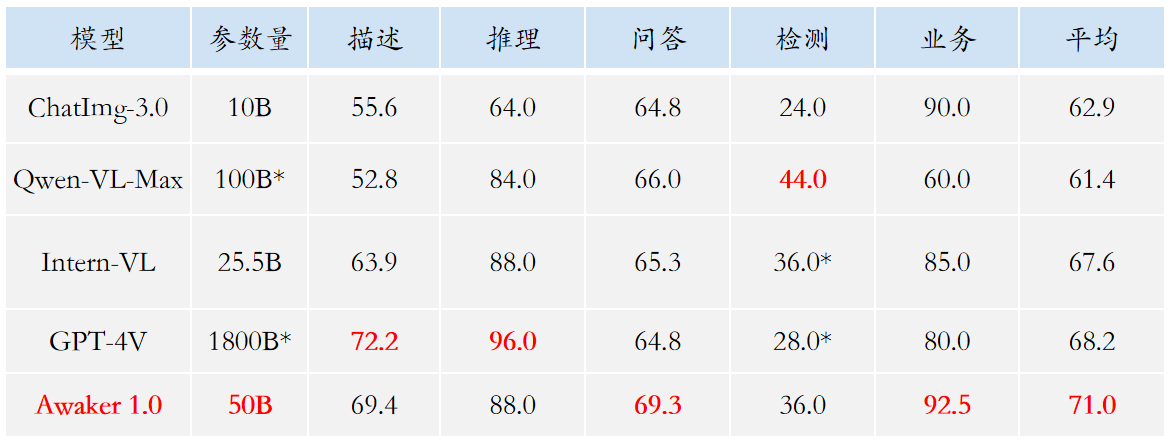
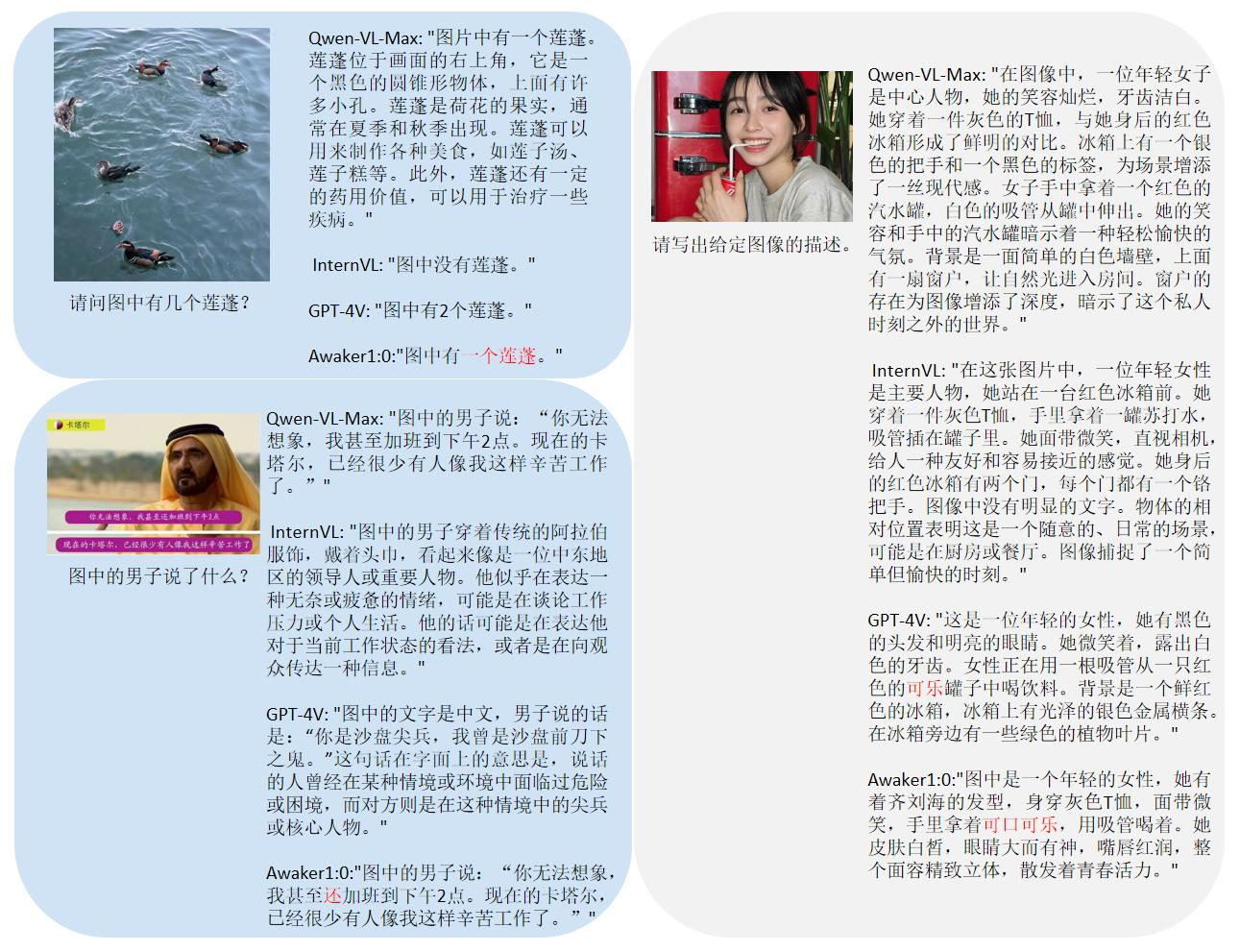
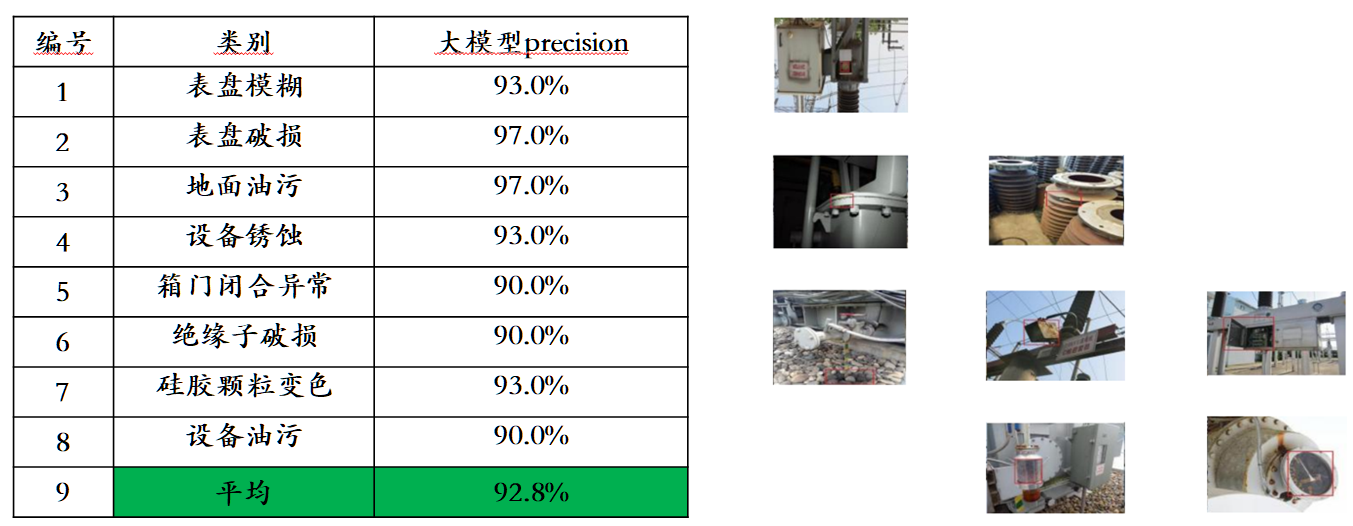
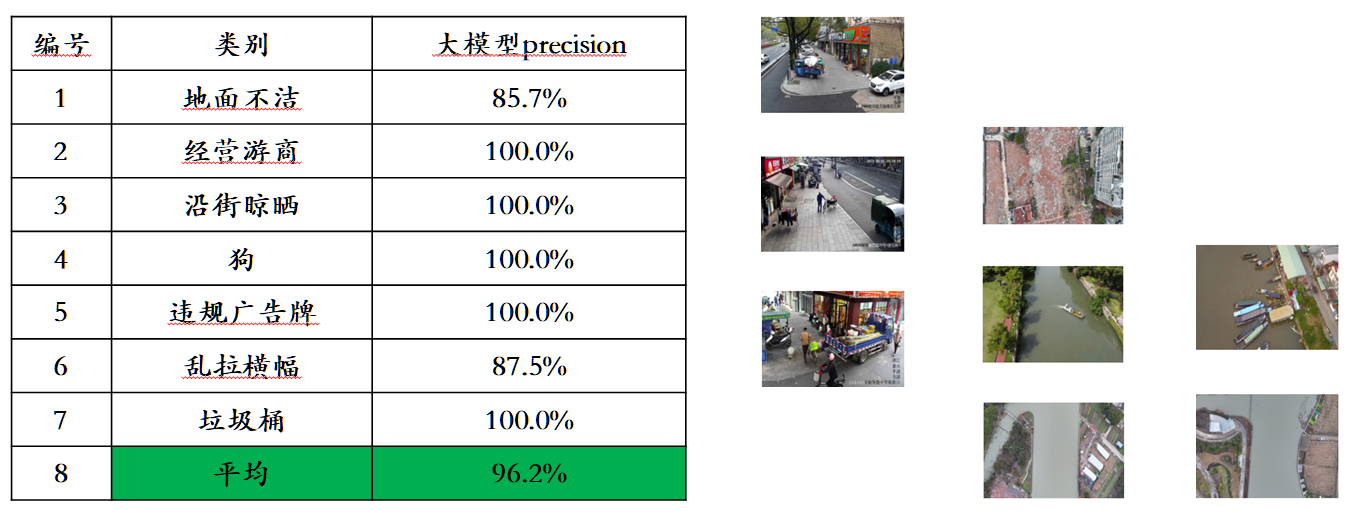
Tendo em conta o problema de fuga de dados de avaliação nas principais listas de avaliação multimodais, a Sophon Engine divulgou um padrão rigoroso para construir o seu próprio conjunto de avaliação, no qual a maioria das imagens de teste provém de álbuns pessoais de telemóveis. Neste conjunto de avaliação multimodal, ele realiza uma avaliação manual justa no Awaker 1.0 e nos três grandes modelos multimodais mais avançados no país e no exterior. Os resultados detalhados da avaliação são mostrados na tabela abaixo. Observe que GPT-4V e Intern-VL não suportam diretamente tarefas de detecção. Seus resultados de detecção são obtidos exigindo que o modelo use uma linguagem para descrever a orientação do objeto.
Inteligência Incorporada Awaker+: Rumo à AGI
A combinação de grandes modelos multimodais e inteligência incorporada é muito natural, porque as capacidades de compreensão visual dos grandes modelos multimodais podem ser naturalmente combinadas com câmeras inteligentes incorporadas. No campo da inteligência artificial, "grande modelo multimodal + inteligência incorporada" é até considerado um caminho viável para alcançar a inteligência artificial geral (AGI).
Por um lado, as pessoas esperam que a inteligência incorporada seja adaptável, ou seja, o agente possa se adaptar às mudanças nos ambientes de aplicação por meio do aprendizado contínuo. Ele pode não apenas fazer cada vez melhor em tarefas multimodais conhecidas, mas também se adaptar rapidamente a tarefas multimodais desconhecidas. -tarefas modais. Por outro lado, as pessoas também esperam que a inteligência incorporada seja verdadeiramente criativa, esperando que possa descobrir novas estratégias e soluções e explorar os limites das capacidades da inteligência artificial através da exploração autónoma do ambiente. Ao utilizar grandes modelos multimodais como os “cérebros” da inteligência incorporada, é possível melhorar significativamente a adaptabilidade e a criatividade da inteligência incorporada, aproximando-se assim eventualmente do limiar da AGI (ou mesmo alcançando a AGI).
No entanto, existem dois problemas óbvios com os grandes modelos multimodais existentes: primeiro, o ciclo iterativo de atualização do modelo é longo, exigindo muito investimento humano e financeiro; segundo, os dados de formação do modelo são todos derivados de dados existentes; , e o modelo Incapaz de adquirir continuamente grandes quantidades de novos conhecimentos. Embora novos conhecimentos contínuos também possam ser injetados através do RAG e do contexto longo, o grande modelo multimodal em si não aprende esses novos conhecimentos, e estes dois métodos de remediação também trarão problemas adicionais. Em suma, os actuais grandes modelos multimodais não são muito adaptáveis em cenários de aplicação reais, muito menos criativos, resultando em diversas dificuldades quando implementados na indústria.
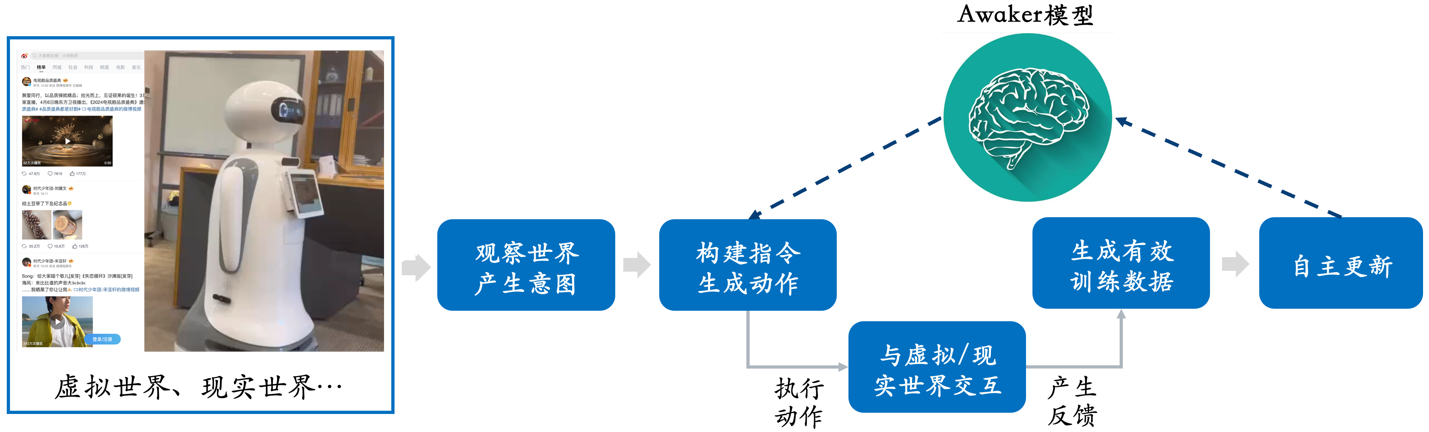
Desta vez, o Awaker 1.0 lançado pela Sophon Engine é o primeiro grande modelo multimodal do mundo com um mecanismo de atualização autônomo, que pode ser usado como o "cérebro" da inteligência incorporada. O mecanismo de atualização autônoma do Awaker 1.0 inclui três tecnologias principais: geração ativa de dados, reflexão e avaliação de modelo e atualização contínua de modelo .
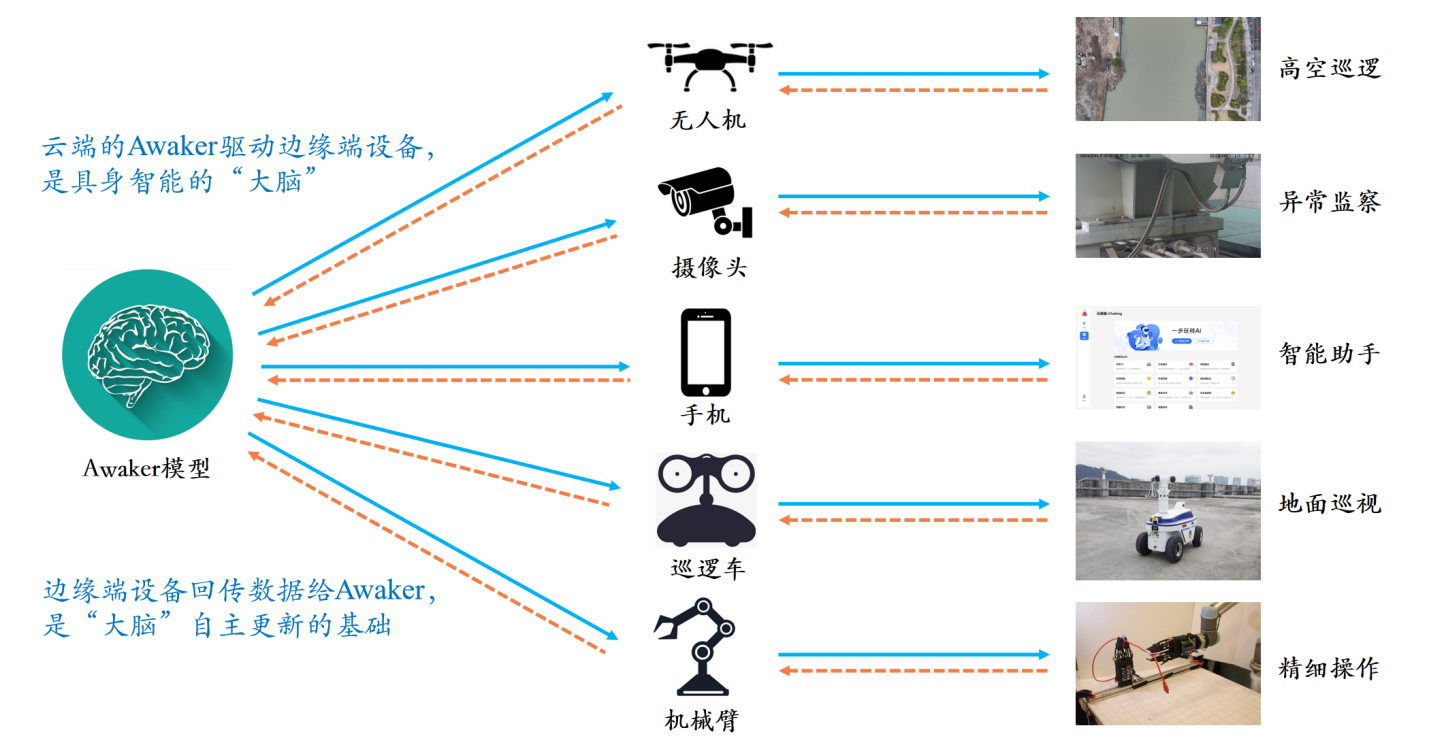
Diferente de todos os outros grandes modelos multimodais, o Awaker 1.0 é “ao vivo” e seus parâmetros podem ser continuamente atualizados em tempo real. Como pode ser visto no diagrama de quadro acima, o Awaker 1.0 pode ser combinado com vários dispositivos inteligentes, observar o mundo através de dispositivos inteligentes, gerar intenções de ação e construir automaticamente instruções para controlar dispositivos inteligentes para concluir várias ações. Os dispositivos inteligentes gerarão automaticamente vários feedbacks após a conclusão de várias ações, podendo obter dados de treinamento eficazes dessas ações e feedbacks para autoatualização contínua e fortalecer continuamente os vários recursos do modelo.
Tomando como exemplo a injeção de novos conhecimentos, o Awaker 1.0 pode aprender continuamente as últimas informações de notícias na Internet e responder a várias perguntas complexas com base nas informações de notícias recém-aprendidas. Diferente dos métodos tradicionais de RAG e de contexto longo, o Awaker 1.0 pode realmente aprender novos conhecimentos e “memorizá-los” nos parâmetros do modelo.

Como pode ser visto no exemplo acima, durante três dias consecutivos de autoatualização, o Awaker 1.0 foi capaz de aprender as notícias do dia todos os dias e falar com precisão as informações correspondentes ao responder às perguntas. Ao mesmo tempo, o Awaker 1.0 não esquecerá o conhecimento aprendido durante o processo de aprendizagem contínua. Por exemplo, o conhecimento do Zhijie S7 ainda é lembrado ou compreendido pelo Awaker 1.0 após 2 dias.
O Awaker 1.0 também pode ser combinado com vários dispositivos inteligentes para alcançar colaboração na nuvem. O Awaker 1.0 é implantado na nuvem como o “cérebro” para controlar vários dispositivos inteligentes de ponta para executar diversas tarefas. O feedback obtido quando o dispositivo inteligente de ponta executa várias tarefas será continuamente transmitido de volta ao Awaker 1.0, permitindo que ele obtenha continuamente dados de treinamento e se atualize continuamente.
Simulador do mundo real: VDT
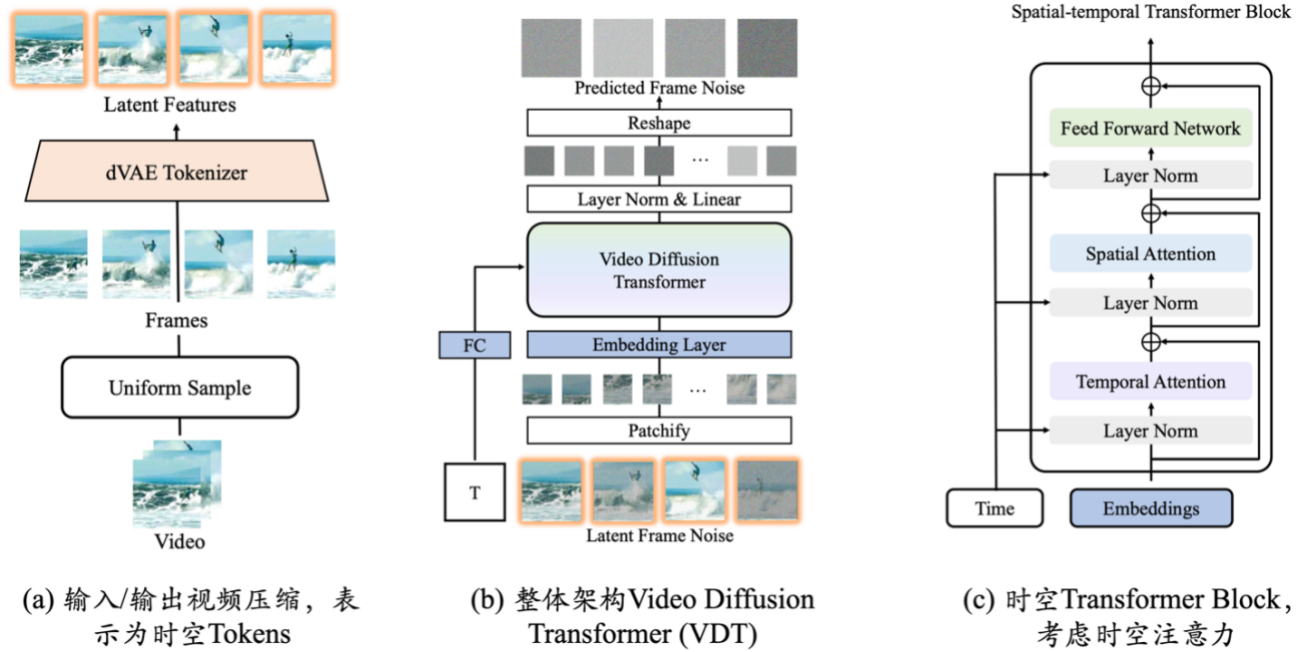
As inovações da base de geração de vídeo VDT incluem principalmente os seguintes aspectos:
- A aplicação da tecnologia Transformer à geração de vídeo baseada em difusão demonstra o grande potencial do Transformer no campo da geração de vídeo. A vantagem do VDT é a sua excelente capacidade de captura dependente do tempo, permitindo a geração de quadros de vídeo temporalmente coerentes, inclusive simulando a dinâmica física de objetos tridimensionais ao longo do tempo.
- Um mecanismo unificado de modelagem de máscara espaço-temporal é proposto para permitir que o VDT lide com uma variedade de tarefas de geração de vídeo, realizando a ampla aplicação desta tecnologia. Os métodos flexíveis de processamento de informações condicionais do VDT, como a emenda simples do espaço de token, unificam efetivamente informações de diferentes comprimentos e modalidades. Ao mesmo tempo, ao combinar com o mecanismo de modelagem de máscara espaço-temporal, o VDT tornou-se uma ferramenta universal de difusão de vídeo, que pode ser aplicada à geração incondicional, previsão de quadro subsequente de vídeo, interpolação de quadro, vídeos geradores de imagem e quadros de vídeo sem modificar o estrutura do modelo e outras tarefas de geração de vídeo.
A equipe do motor Sophon se concentrou em explorar a simulação de leis físicas simples do VDT e treinou o VDT no conjunto de dados Physion. No exemplo a seguir, descobrimos que o VDT simulou com sucesso processos físicos, como a bola se movendo ao longo de uma trajetória parabólica e a bola rolando em um plano e colidindo com outros objetos. Ao mesmo tempo, também pode ser visto no segundo exemplo da linha 2 que o VDT capturou a velocidade e o impulso da bola, porque a bola acabou não derrubando o pilar devido à força de impacto insuficiente. Isso prova que a arquitetura do Transformer pode aprender certas leis físicas.

Eles também conduziram uma exploração aprofundada da tarefa de geração de vídeos fotográficos. Esta tarefa exige muito da qualidade de geração de vídeo, pois somos naturalmente mais sensíveis a mudanças dinâmicas em rostos e personagens. Tendo em vista a particularidade desta tarefa, os pesquisadores precisam combinar VDT (ou Sora) e geração controlável para lidar com os desafios da geração de vídeo fotográfico. Atualmente, o mecanismo Sophon rompeu a maioria das principais tecnologias de geração de vídeos fotográficos e alcançou melhor qualidade de geração de vídeos fotográficos do que o Sora. O mecanismo Sophon continuará a otimizar o algoritmo de geração controlável de retratos e também está explorando ativamente a comercialização. Atualmente, foi encontrado um cenário de pouso comercial confirmado, e espera-se que num futuro próximo quebre a dificuldade de pouso de grandes modelos na "última milha".
No futuro, um VDT mais versátil se tornará uma ferramenta poderosa para resolver o problema de fontes de dados multimodais de grandes modelos. Usando a geração de vídeo, o VDT será capaz de simular o mundo real, melhorar ainda mais a eficiência da produção de dados visuais e fornecer assistência para a atualização independente do grande modelo multimodal Awaker.
Conclusão
Awaker 1.0 é um passo fundamental para a equipe do motor Sophon avançar em direção ao objetivo final de "realizar AGI". Sophon Engine disse à APPSO que a equipe acredita que a autoexploração, a autorreflexão e outras capacidades de aprendizagem autônoma da IA são critérios de avaliação importantes para o nível de inteligência e são tão importantes quanto o aumento contínuo na escala dos parâmetros (Lei de Escala).
Awaker 1.0 implementou estruturas técnicas importantes, como "geração ativa de dados, reflexão e avaliação de modelos e atualização contínua de modelos", alcançando avanços tanto no lado da compreensão quanto no lado da geração. Espera-se que acelere o desenvolvimento do grande multimodal. indústria modelo e, em última análise, permitir que os humanos realizem AGI.
# Bem-vindo a seguir a conta pública oficial do WeChat de Aifaner: Aifaner (ID do WeChat: ifanr). Mais conteúdo interessante será fornecido a você o mais rápido possível.
