
A Wall-facing Intelligence concluiu uma nova rodada de financiamento de centenas de milhões de yuans e lançou a segunda versão do MiniCPM, um pequeno canhão de aço de alto desempenho

A história inspiradora de fazer uma grande diferença a partir de uma pequena coisa não acontece apenas na história do empreendedorismo, mas também em modelos ponta a ponta de grande escala.
Em fevereiro deste ano, a Wall-facing Intelligence lançou oficialmente o carro-chefe 2B modelo de grande escala do lado final MiniCPM voltado para a parede, que não apenas ultrapassou o benchmark de desempenho da "versão europeia do OpenAI", mas também ficou à frente do Google Gemma em geral Nível 2B, e até ultrapassou 7B e 13B em volume.modelos de nível, como Llama2-13B, etc.
Recentemente, a Wall-Facing Intelligence também concluiu uma nova rodada de financiamento de várias centenas de milhões de yuans, liderada pela Primavera Ventures e Huawei Hubble, e seguida pelo Fundo de Investimento da Indústria de Inteligência Artificial de Pequim e outros.Zhihu, como acionista estratégico, continua a investir e apoiar, e está comprometido em acelerar o investimento.Promover o treinamento eficiente de grandes modelos e a rápida implementação de aplicativos.

Hoje, o pequeno canhão de aço MiniCPM de modelo grande lado a lado está perseguindo a vitória e inaugurou a segunda série de quatro tiros. O tema principal é "pequeno, mas forte, pequeno, mas completo".
Entre eles, o modelo multimodal MiniCPM-V2.0 melhorou significativamente suas capacidades de OCR e atualizou o melhor desempenho de OCR dos modelos de código aberto.O texto da cena geral é comparável ao Gemini-Pro e supera toda a série de modelos 13B.
Na lista Object HalBench que avalia ilusões de modelos grandes, MiniCPM-V2.0 e GPT-4V têm desempenho quase igual.
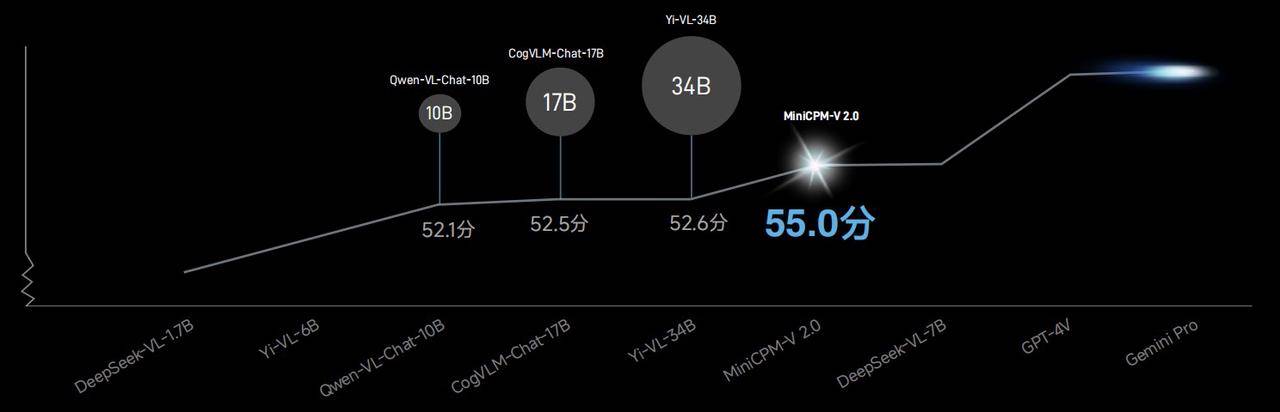
Na lista OpenCompass que combina 11 benchmarks de avaliação convencionais, a capacidade geral do modelo multimodal MiniCPM-V2.0 supera Qwen-VL-Chat-10B, CogVLM-Chat-17B, Yi-VL-34B, etc. Um modelo maior.
No caso de demonstração oficial, quando solicitado a descrever detalhadamente a cena da mesma imagem, o GPT-4V respondeu com 6 alucinações, enquanto o MiniCPM-V2.0 teve apenas 3 alucinações.

Além disso, o MiniCPM-V2.0 também lançou uma cooperação aprofundada com a Universidade de Tsinghua para explorar conjuntamente o tesouro do Museu da Universidade de Tsinghua – Tsinghua Slips.
Graças às suas poderosas capacidades de reconhecimento e raciocínio multimodal, o MiniCPM-V2.0 pode facilmente lidar com o reconhecimento da simples palavra "ke" ou da palavra complexa "I".
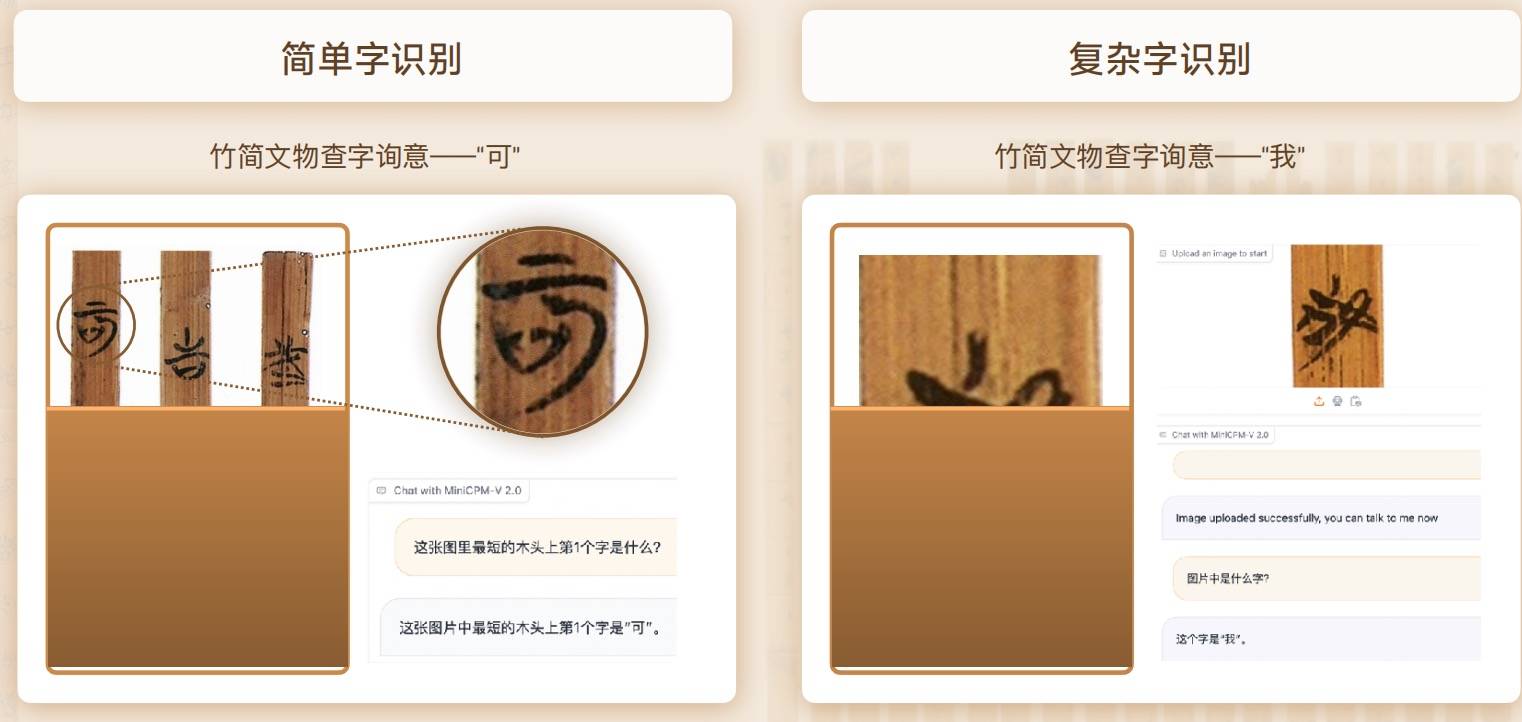
Na competição com modelos grandes multimodais de referência chineses semelhantes, a precisão do reconhecimento do MiniCPM-V2.0 está muito à frente.
O reconhecimento de detalhes precisos exige mais clareza das imagens, e os modelos grandes tradicionais geralmente só conseguem lidar com imagens pequenas de 448 × 448 pixels. Uma vez que a informação é compactada, o modelo se torna difícil de ler.
Mas isso não é um problema para o MiniCPM-V2.0. No caso de demonstração oficial, diante de uma imagem comum de cena de rua urbana, o MiniCPM-V2.0 pode capturar informações importantes rapidamente, mesmo sem detectá-las a olho nu. " Family Mart" também pode ser capturado facilmente.

Imagens longas contêm informações de rich text e os modelos multimodais muitas vezes são incapazes de reconhecer imagens longas, mas o MiniCPM-V 2.0 pode capturar com firmeza as principais informações de imagens longas.

De 448 × 448 pixels a 1,8 milhão de imagens grandes de alta definição e até mesmo a proporção de aspecto final de 1:9 (448 * 4032), o MiniCPM-V 2.0 pode obter reconhecimento sem perdas.
Entende-se que a tecnologia exclusiva LLaVA-UHD é efetivamente utilizada por trás da codificação eficiente de imagens de alta definição MiniCPM-V 2.0.
- Codificação visual modular: A imagem de resolução original é dividida em fatias de tamanho variável, alcançando total adaptabilidade à resolução original sem preenchimento de pixels ou distorção de imagem.
- Módulo de compressão visual: usa uma camada de reamostragem perceptron compartilhada para compactar os tokens visuais das fatias de imagem. O número de tokens é acessível independentemente da resolução e a complexidade computacional é menor.
- Método de modificação espacial: Use padrões simples de símbolos de linguagem natural para informar com eficácia as posições relativas das fatias da imagem.

Em termos de capacidades de OCR chinês, o MiniCPM-V 2.0 também supera significativamente o GPT-4V. Comparado com o "desamparo" do GPT-4V, sua capacidade de identificar imagens com precisão é ainda mais valiosa.
Por trás desta capacidade está o apoio à tecnologia de generalização intermodal e multilíngue, que pode resolver o desafio da falta de dados multimodais de alta qualidade e em grande escala no campo chinês.
A capacidade de processar textos longos sempre foi um critério importante para medir modelos.
Embora a capacidade de texto longo de 128K não seja novidade, para o MiniCPM-2B-128K, que tem apenas 2B, isso é definitivamente algo digno de elogio.
O menor modelo de texto longo de 128K, modelo de texto longo MiniCPM-2B-128K, estende a janela de contexto original de 4K para 128K, superando vários modelos 7B, como Yarn-Mistral-7B-128K na lista InfiniteBench.

Ao introduzir a arquitetura MoE, o desempenho do recém-lançado MiniCPM-MoE-8x2B MoE melhorou em média 4,5%, superando toda a série de modelos 7B e modelos maiores, como LlaMA234B, enquanto o custo de inferência é de apenas 69,7% do Gemma- 7B.
MiniCPM-1.2B prova que “pequeno” e “poderoso” não são mutuamente exclusivos.
Embora os parâmetros diretos tenham sido reduzidos pela metade, o MiniCPM-1.2B ainda mantém 87% do desempenho abrangente do modelo 2.4B da geração anterior.Em várias listas de testes públicos autorizados, o modelo 1.2B é muito capaz e seu desempenho abrangente excede Qwen 1.8B e Qwen 1.8B. Excelentes resultados com Llama 2-7B e até Llama 2-13B.
Demonstração de gravação de tela do modelo MiniCPM-1.2B no celular iPhone 15, a velocidade de inferência foi aumentada em 38%. Atingiu 25 tokens/s por segundo, o que é 15 a 25 vezes mais rápido que a velocidade da fala humana. Ao mesmo tempo, a memória é reduzida em 51,9%, o custo é reduzido em 60% e o modelo de implementação é menor, mas os cenários de uso aumentaram bastante.
Na busca por modelos de grandes parâmetros, a Face Wall Intelligence escolheu um caminho técnico único – desenvolver modelos com tamanho menor e desempenho mais forte, tanto quanto possível.
O excelente desempenho do pequeno canhão de aço MiniCPM voltado para a parede prova plenamente que "pequeno" e "forte", "pequeno" e "cheio" não são atributos mutuamente exclusivos, mas podem coexistir harmoniosamente. Também esperamos que mais modelos desse tipo apareçam no futuro.
# Bem-vindo a seguir a conta pública oficial do WeChat de aifaner: aifaner (WeChat ID: ifanr).Mais conteúdo interessante será fornecido a você o mais rápido possível.
