
A OpenAI acaba de lançar dois modelos de código aberto! Eles podem ser executados em celulares e laptops, e ex-alunos da Universidade de Pequim estão liderando a iniciativa.

Após cinco anos, a OpenAI acaba de lançar oficialmente dois modelos de linguagem ponderados de código aberto: gpt-oss-120b e gpt-oss-20b. A última vez que disponibilizaram um modelo de linguagem de código aberto foi o GPT-2, em 2019.
O OpenAI é verdadeiramente aberto.
Hoje, o círculo da IA também está cheio de pólvora. A OpenAI tornou o gpt-oss de código aberto, a Anthropic lançou o Claude Opus 4.1 (relatório detalhado abaixo) e o Google DeepMind lançou o Genie 3. Os três gigantes lançaram seus trunfos no mesmo dia, encenando uma batalha entre deuses.
O CEO da OpenAI, Sam Altman, expressou seu entusiasmo nas redes sociais: "O GPT-OSS foi lançado! Criamos um modelo aberto com desempenho de nível O4-mini que pode ser executado em laptops de última geração. Estamos muito orgulhosos da equipe; esta é uma grande vitória técnica."
Os destaques do modelo são resumidos a seguir:
- gpt-oss-120b: Um modelo grande e aberto, adequado para produção, uso geral, casos de uso de alta inferência, executado em uma única GPU H100 (117 bilhões de parâmetros, 5,1 bilhões de ativações), projetado para ser executado em data centers e em desktops e laptops de última geração.
- gpt-oss-20b: Um modelo aberto de médio porte para casos de uso locais, especializados ou de baixa latência (21 bilhões de parâmetros, 3,6 bilhões de parâmetros de ativação) que pode ser executado na maioria dos desktops e laptops.
- Licença Apache 2.0: gratuita para construção, sem restrições de copyleft ou riscos de patentes — ideal para experimentação, personalização e implantação comercial.
- Intensidade de Inferência Configurável: Ajuste facilmente a intensidade da inferência (baixa, média ou alta) com base no seu caso de uso específico e nos requisitos de latência. Cadeia de Inferência Completa: Obtenha acesso total ao processo de inferência do modelo para facilitar a depuração e aumentar a confiança na saída. Este recurso não se destina à exibição para usuários finais.
- Ajuste fino: por meio do ajuste fino dos parâmetros, o modelo pode ser totalmente personalizado para atender às necessidades específicas de uso do usuário.
- Recursos do agente inteligente: aproveite os recursos nativos do modelo para executar chamadas de função, navegação na web, execução de código Python e saída estruturada.
- Quantização MXFP4 nativa: os modelos são treinados usando precisão MXFP4 nativa para camadas MoE, permitindo que o modelo gpt-oss-120b seja executado em uma única GPU H100 e que o modelo gpt-oss-20b seja executado em 16 GB de memória.
A OpenAI finalmente tornou sua IA de código aberto, mas desta vez é realmente diferente
A julgar pelas especificações técnicas, a OpenAI está realmente falando sério desta vez. Ela não criou apenas um modelo de código aberto em escala reduzida para sobreviver, mas, em vez disso, lançou um trabalho sincero com desempenho próximo ao de seu próprio carro-chefe de código fechado.
De acordo com a introdução oficial da OpenAI, o gpt-oss-120b possui um total de 117 bilhões de parâmetros e 5,1 bilhões de parâmetros de ativação. Ele pode ser executado em uma única GPU H100 e requer apenas 80 GB de memória. Foi projetado para ambientes de produção, aplicações gerais e casos de uso com altos requisitos de inferência. Pode ser implantado em data centers e executado em desktops e laptops de última geração.
Em comparação, o gpt-oss-20b possui 21 bilhões de parâmetros no total e 3,6 bilhões de parâmetros de ativação. Ele é otimizado para casos de uso de baixa latência, localizados ou especializados, e requer apenas 16 GB de memória para ser executado, o que significa que a maioria dos desktops e laptops modernos pode lidar com ele.
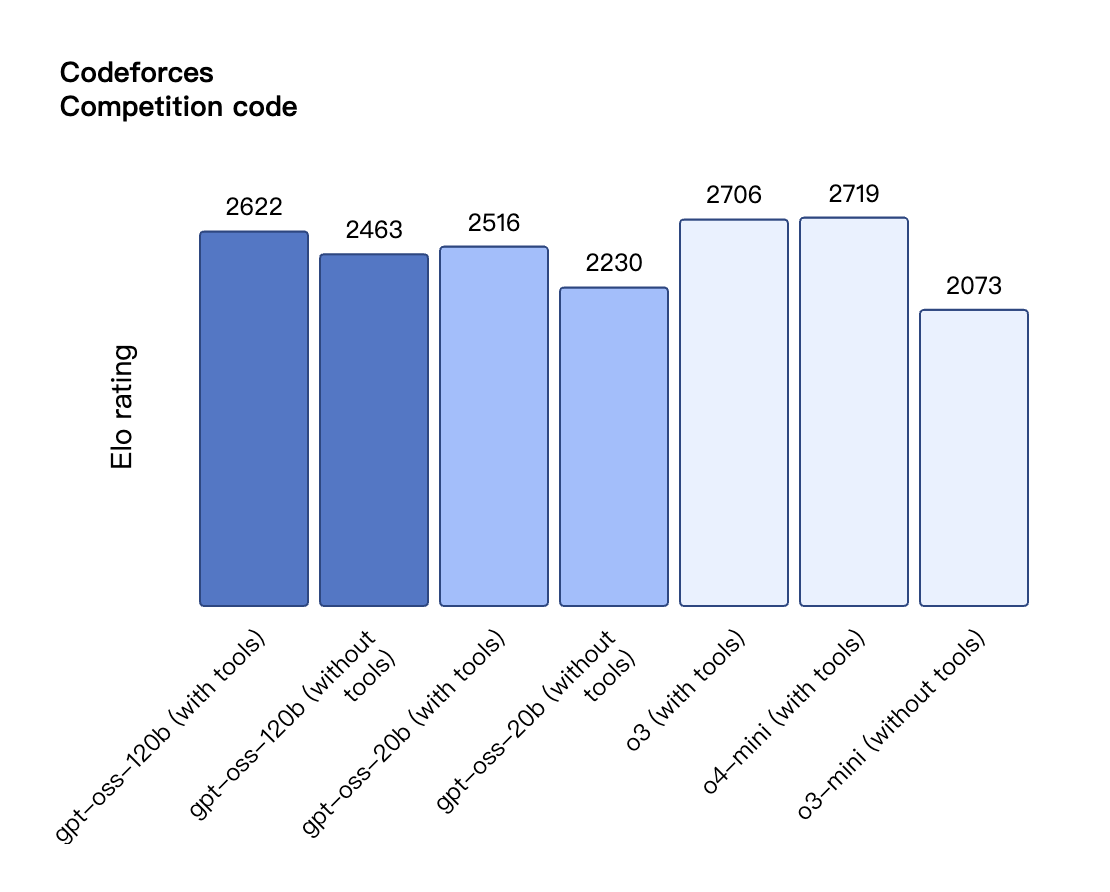
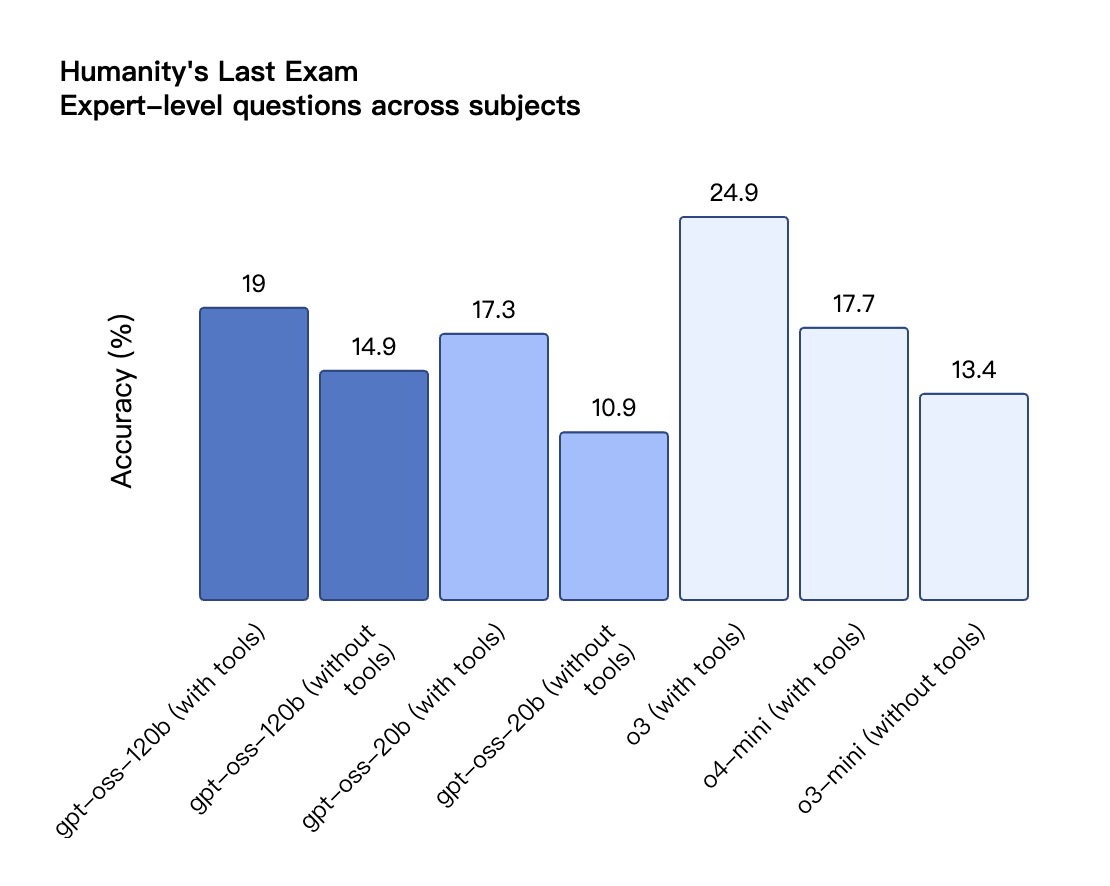
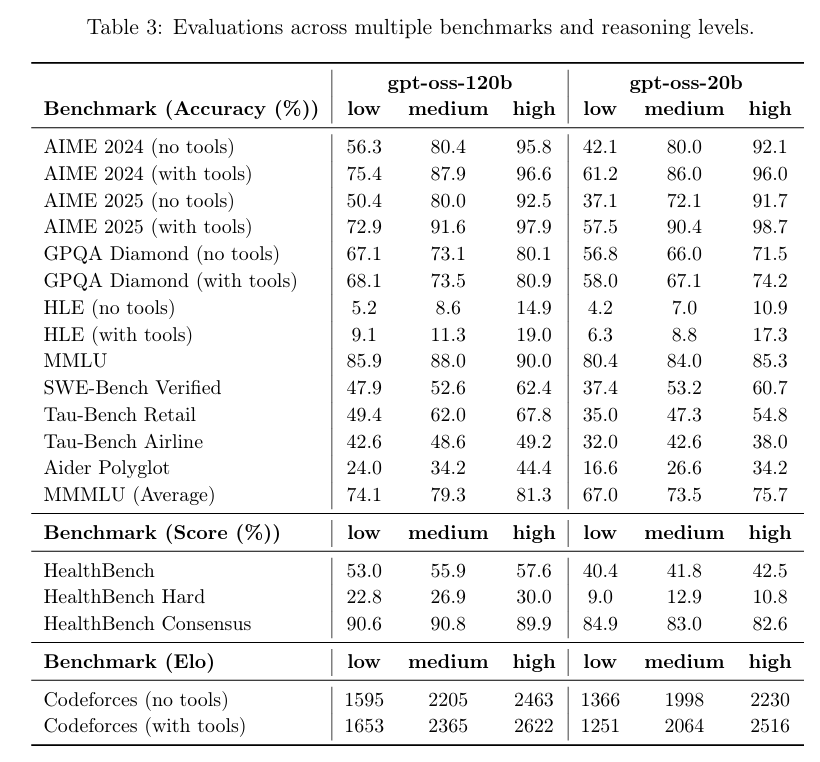
De acordo com os resultados de benchmark divulgados pela OpenAI, o gpt-oss-120b superou o o3-mini e ficou no mesmo nível do o4-mini no teste de programação competitiva da Codeforces; ele também superou o o3-mini e se aproximou do nível do o4-mini nos testes MMLU e HLE de capacidade geral de resolução de problemas.
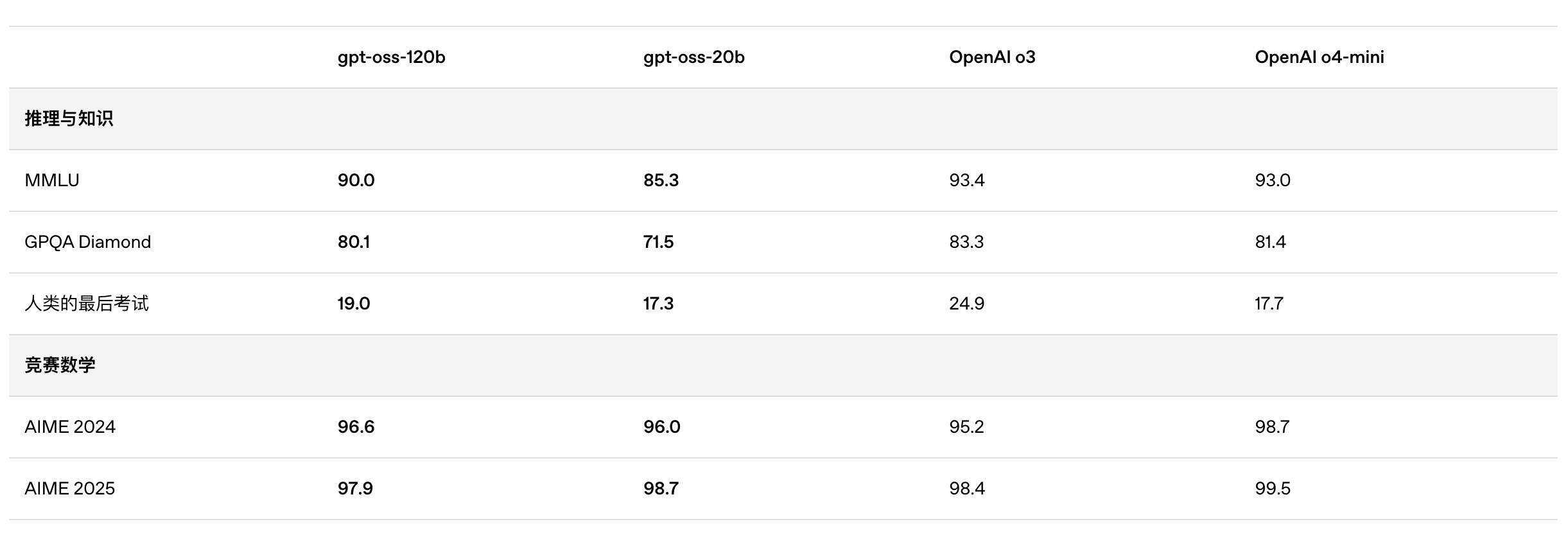
Na avaliação de chamadas de ferramentas do TauBench, o gpt-oss-120b também teve um bom desempenho, superando até mesmo modelos de código fechado como o1 e GPT-4o; no teste HealthBench de consultas relacionadas à saúde e nos testes AIME 2024 e 2025 de matemática competitiva, o desempenho do gpt-oss-120b superou até mesmo o o4-mini.
Apesar do tamanho menor do parâmetro, o gpt-oss-20b tem desempenho igual ou superior ao OpenAI o3-mini nesses mesmos benchmarks, particularmente nas áreas de matemática competitiva e saúde.
No entanto, embora o modelo GPT-OSS tenha apresentado bom desempenho no teste HealthBench para consultas relacionadas à saúde, esses modelos não podem substituir profissionais médicos e não devem ser usados para o diagnóstico ou tratamento de doenças. Recomenda-se cautela no uso.
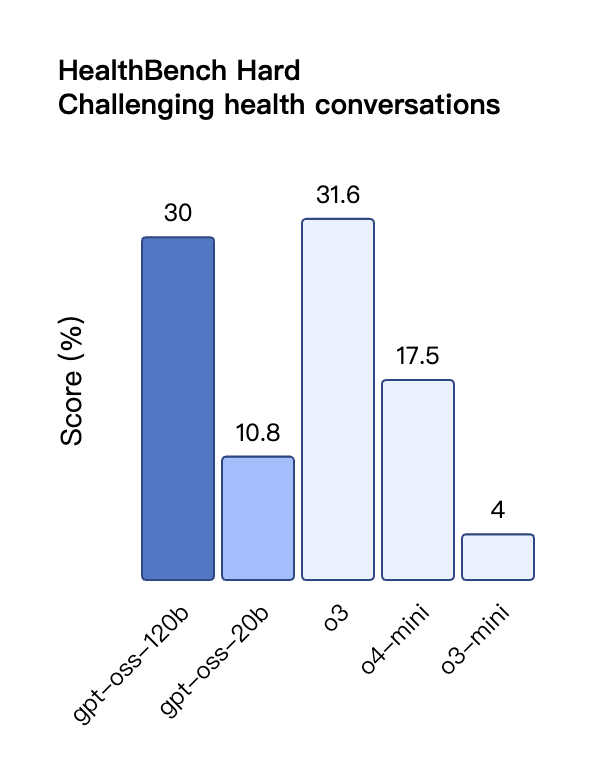
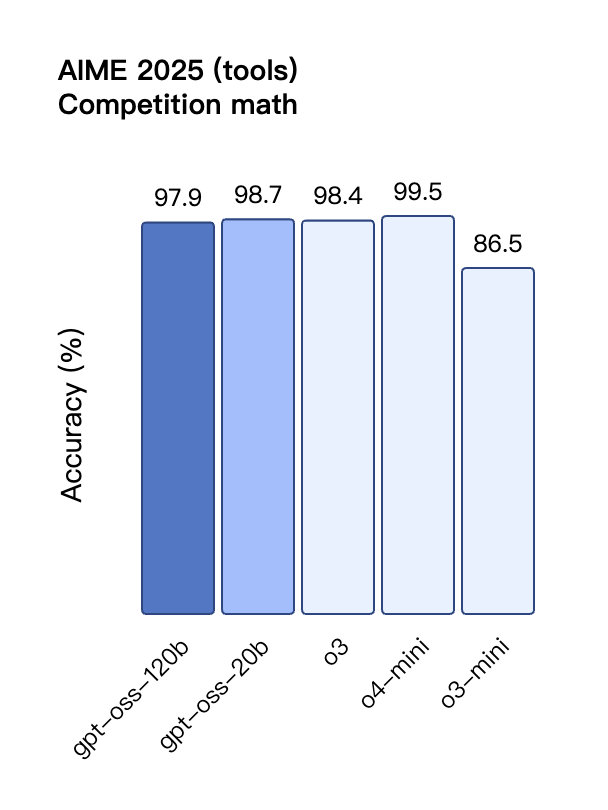
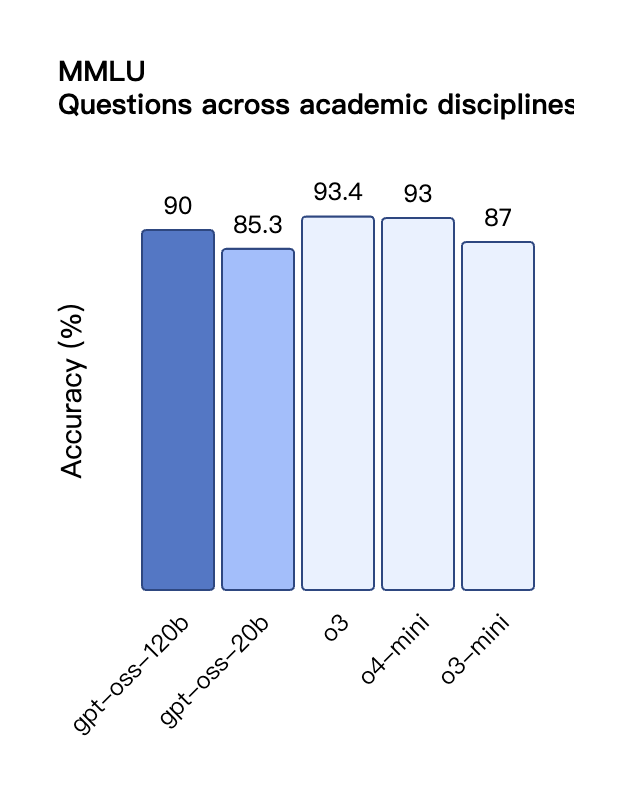
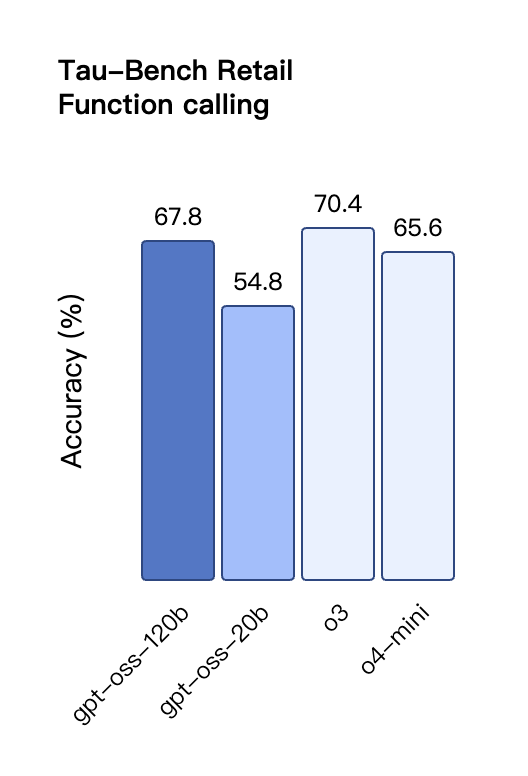
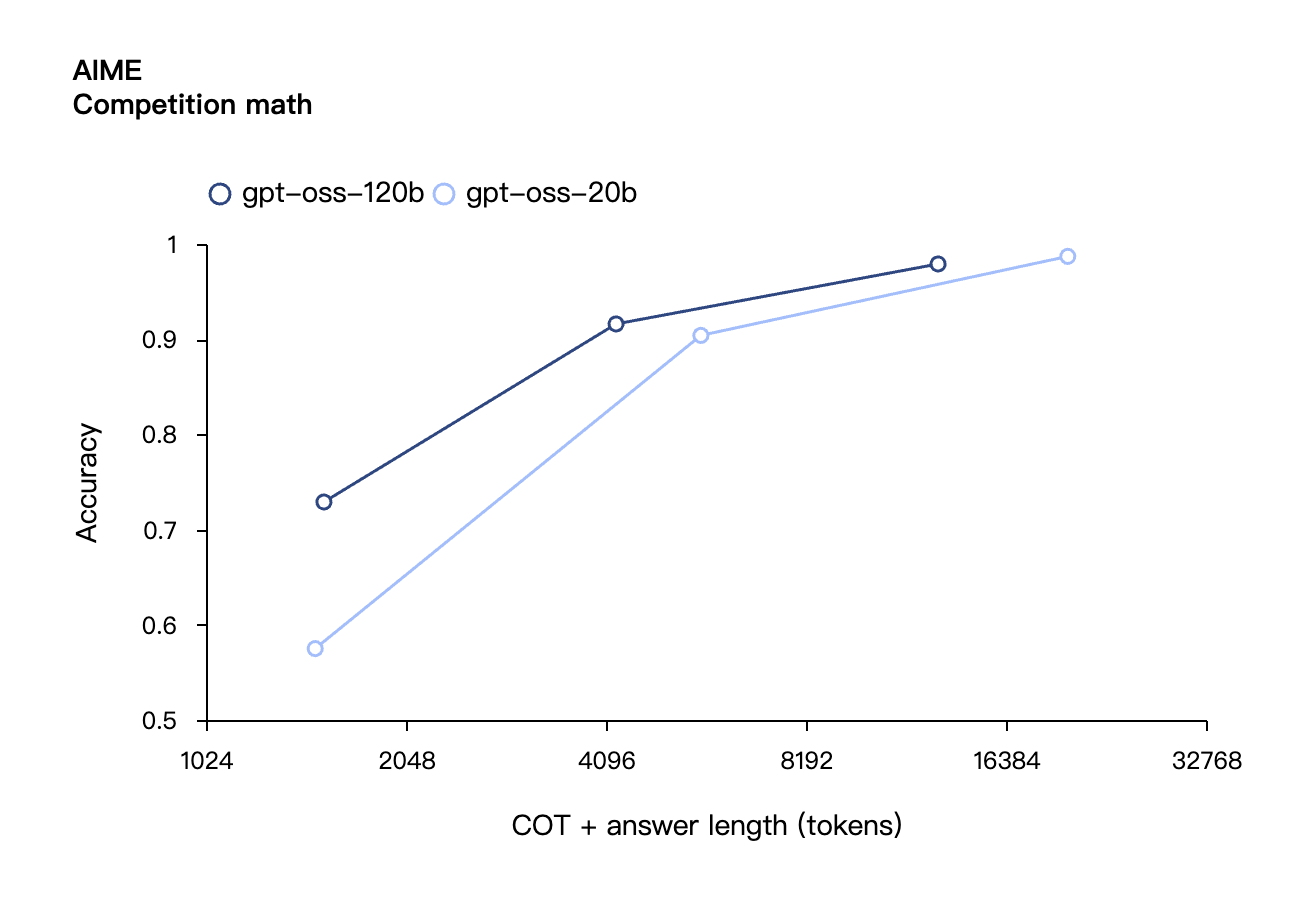
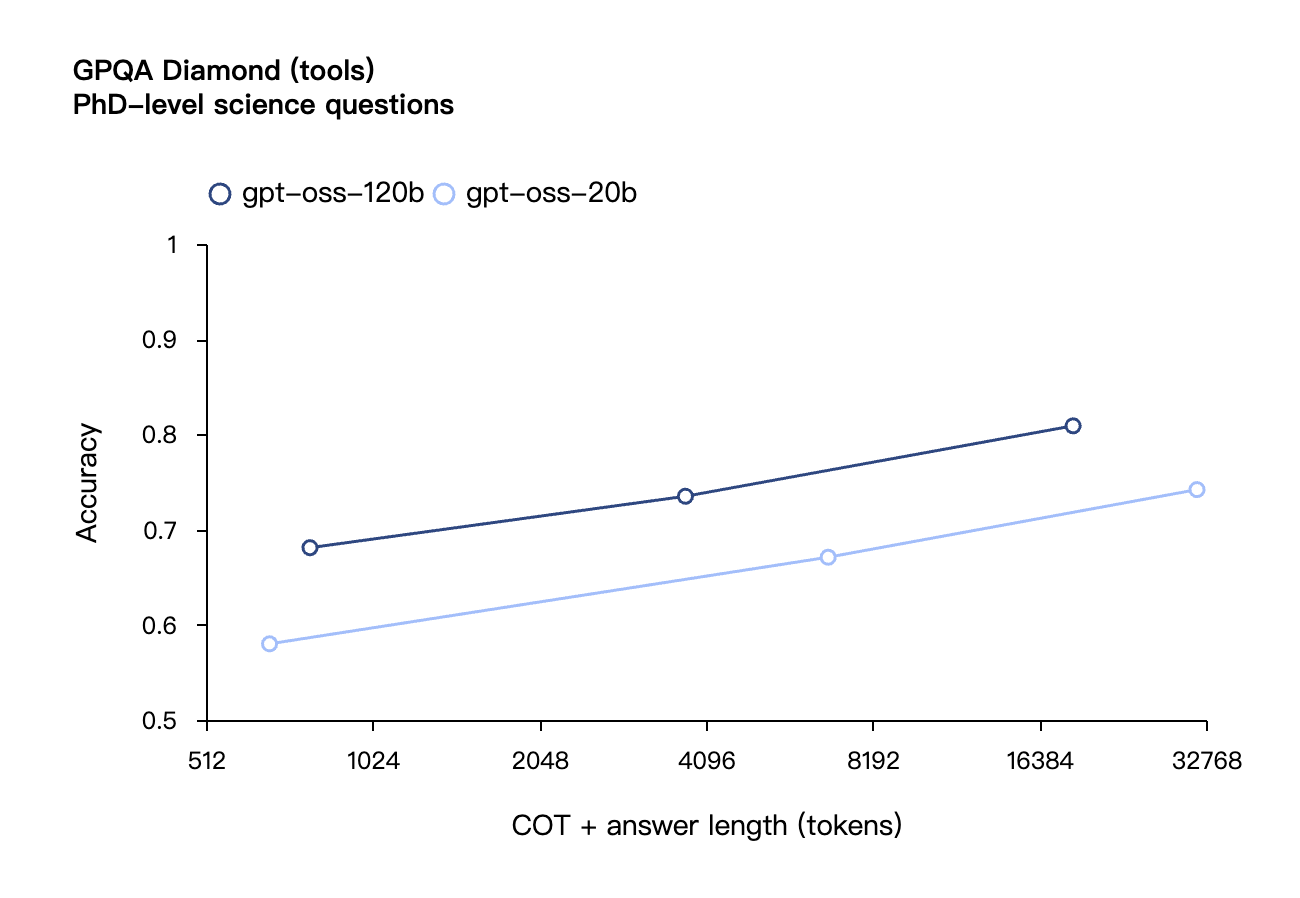
Semelhante aos modelos de inferência da série O do OpenAI na API, ambos os modelos de peso aberto oferecem suporte a configurações de intensidade de inferência baixa, média e alta, permitindo que os desenvolvedores negociem desempenho e capacidade de resposta com base em cenários de uso específicos e requisitos de latência.
De Berkeley à OpenAI, ex-alunos da Universidade de Pequim defendem o código aberto
Na plataforma de teste do modelo GPT-OSS da OpenAI, propus um problema lógico clássico ao modelo: "Uma corda que queima de forma irregular leva exatamente uma hora para queimar. Dadas várias cordas assim, como medir com precisão uma hora e quinze minutos?"
O modelo apresenta uma solução completa para este problema em etapas, com um cronograma claro, explicações dos princípios e um resumo dos pontos-chave. No entanto, se você observar com atenção, verá que as etapas da solução ainda são bastante complexas.
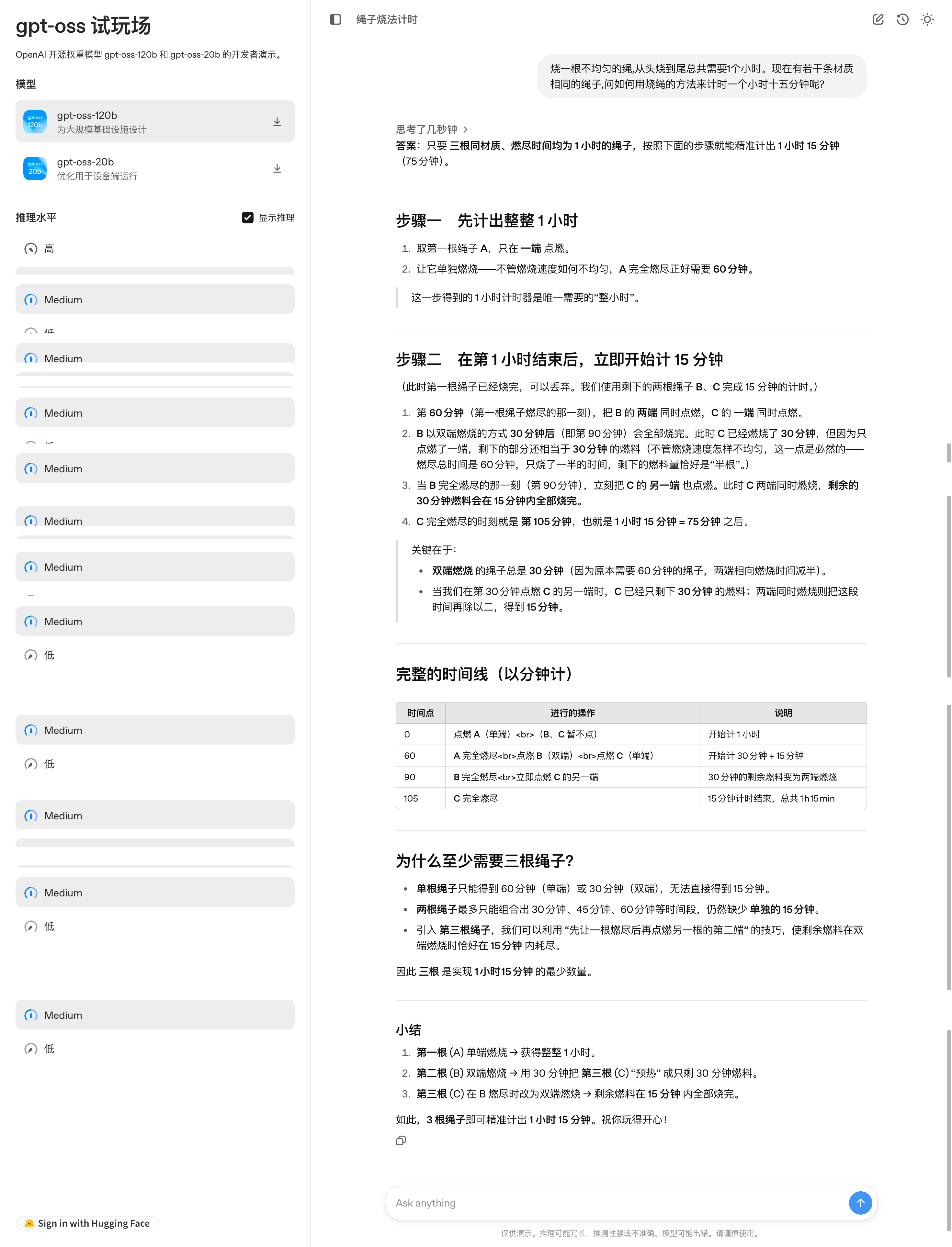
Endereço da experiência: https://www.gpt-oss.com/
De acordo com o feedback do teste do internauta @flavioAd, o GPT-OSS-20B teve um bom desempenho no problema clássico de movimento da bola, mas falhou no teste clássico de hexágono mais difícil e encontrou muitos erros gramaticais, exigindo várias tentativas para obter um resultado relativamente satisfatório.
O internauta @productshiv testou o modelo gpt-oss-20b em um dispositivo equipado com um chip M3 Pro e 18 GB de memória por meio da plataforma Lm Studio, concluindo com sucesso a escrita do clássico jogo Snake de uma só vez, com uma velocidade de geração de 23,72 tokens/segundo sem nenhum processamento de quantização.
Curiosamente, o internauta @Sauers_ descobriu que o modelo gpt-oss-120b tem um "hábito" único: ele gosta de incorporar equações matemáticas na criação de poesia.

Além disso, o internauta @grx_xce compartilhou os resultados dos testes comparativos dos modelos Claude Opus 4.1 e gpt-oss-120b. Qual você acha que é melhor?
Por trás deste lançamento histórico de código aberto, há uma pessoa técnica que merece atenção especial: Zhuohan Li, que lidera o trabalho de raciocínio e infraestrutura do modelo da série gpt-oss.
Tenho a sorte de liderar o trabalho de infraestrutura e inferência que torna o gpt-oss possível. Entrei para a OpenAI há um ano, depois de construir o vLLM do zero – e agora, estar do outro lado do mercado, ajudando a contribuir com modelos para a comunidade de código aberto, é profundamente significativo para mim.

Dados públicos indicam que Zhuohan Li se formou na Universidade de Pequim com um diploma de bacharel, onde estudou com os renomados professores de ciência da computação Wang Liwei e He Di, estabelecendo uma base sólida em ciência da computação. Em seguida, fez seu doutorado na Universidade da Califórnia, Berkeley, onde passou quase cinco anos como pesquisador de doutorado no Berkeley RISE Lab, sob a orientação de Ion Stoica, um importante estudioso de sistemas distribuídos.
Sua pesquisa se concentra na interseção entre aprendizado de máquina e sistemas distribuídos, com foco particular na melhoria do rendimento, eficiência de memória e capacidade de implantação de inferência de grandes modelos por meio do design do sistema – essas são as principais tecnologias que permitem que os modelos gpt-oss sejam executados com eficiência em hardware comum.
Durante seu período em Berkeley, Zhuohan Li esteve profundamente envolvido e liderou diversos projetos que tiveram um impacto profundo na comunidade de código aberto. Como um dos principais autores do projeto vLLM, ele solucionou com sucesso os problemas da indústria relacionados ao alto custo e à lentidão na implantação de modelos grandes por meio da tecnologia PagedAttention. Esse mecanismo de inferência de modelos grandes, de alto rendimento e baixa memória, tem sido amplamente adotado pela indústria.
Ele também é coautor de Vicuna, que recebeu grande repercussão na comunidade de código aberto. Além disso, a série de ferramentas Alpa, da qual participou no desenvolvimento, promoveu o desenvolvimento da computação paralela de modelos e da automação do raciocínio.
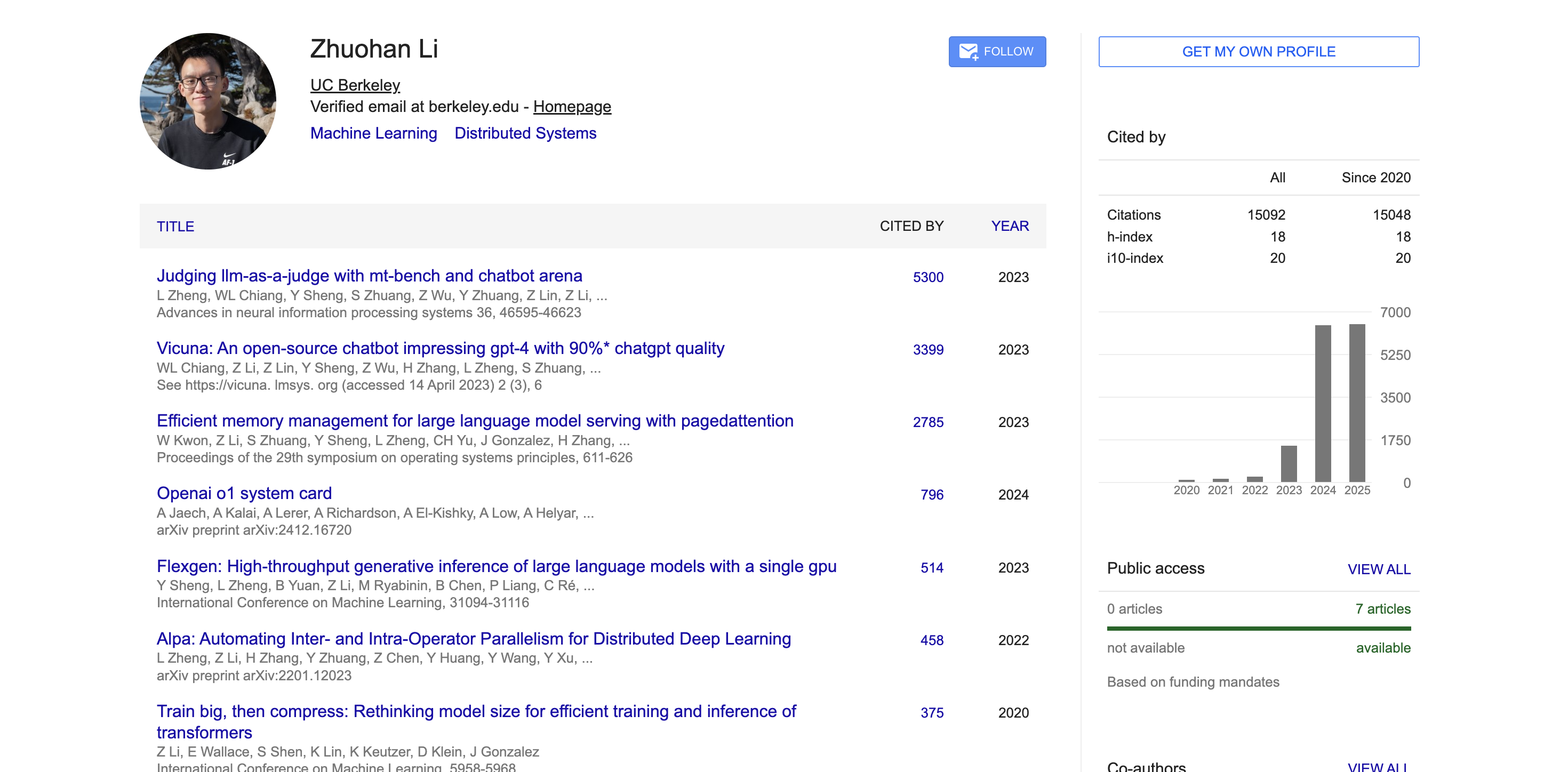
No meio acadêmico, de acordo com dados do Google Acadêmico, os artigos acadêmicos de Zhuohan Li foram citados mais de 15.000 vezes, com um índice h de 18. Seus artigos representativos, como MT-Bench, Chatbot Arena, Vicuna e vLLM, receberam milhares de citações e tiveram um amplo impacto na comunidade acadêmica.
Não apenas grande, mas também a inovação arquitetônica por trás do GPT-OSS
Para entender por que esses dois modelos conseguem atingir um desempenho tão excepcional, precisamos ter um profundo entendimento da arquitetura técnica e dos métodos de treinamento por trás deles.
O modelo gpt-oss é treinado usando técnicas de pré-treinamento e pós-treinamento de última geração da OpenAI, com foco específico na capacidade de raciocínio, eficiência e usabilidade prática em vários ambientes de implantação.
Ambos os modelos usam a arquitetura avançada do Transformer e utilizam de forma inovadora a técnica Mixture of Experts (MoE) para reduzir significativamente o número de parâmetros necessários para ativar durante o processamento da entrada.
O modelo utiliza um padrão de atenção alternada densa e esparsa em faixas locais, semelhante ao GPT-3. Para aprimorar ainda mais o raciocínio e a eficiência da memória, ele também utiliza um mecanismo de atenção multiconsulta agrupada com um tamanho de grupo de 8. Ao utilizar a tecnologia de Codificação Posicional Rotacional (RoPE) para codificação posicional, o modelo também oferece suporte nativo a comprimentos de contexto de até 128k.

Em termos de dados de treinamento, a OpenAI treinou esses modelos em um conjunto de dados de texto simples, principalmente em inglês, com ênfase especial em conhecimento de campo STEM, habilidades de codificação e conhecimento geral.
Ao mesmo tempo, a OpenAI também disponibilizou de código aberto um novo segmentador de palavras chamado o200k_harmony, que é mais abrangente e avançado do que os segmentadores de palavras usados pelo OpenAI o4-mini e GPT-4o.
Um método de tokenização mais compacto permite que o modelo processe mais conteúdo com o mesmo comprimento de contexto. Por exemplo, uma frase originalmente segmentada em 20 tokens pode precisar de apenas 10 com um tokenizador melhor. Isso é especialmente importante para o processamento de textos longos.
Além do forte desempenho básico, esses modelos também se destacam em termos de recursos de aplicação prática. O modelo gpt-oss é compatível com a API Responses e oferece suporte a funções como suporte nativo para chamadas de função, navegação na web, execução de código Python e saída estruturada.
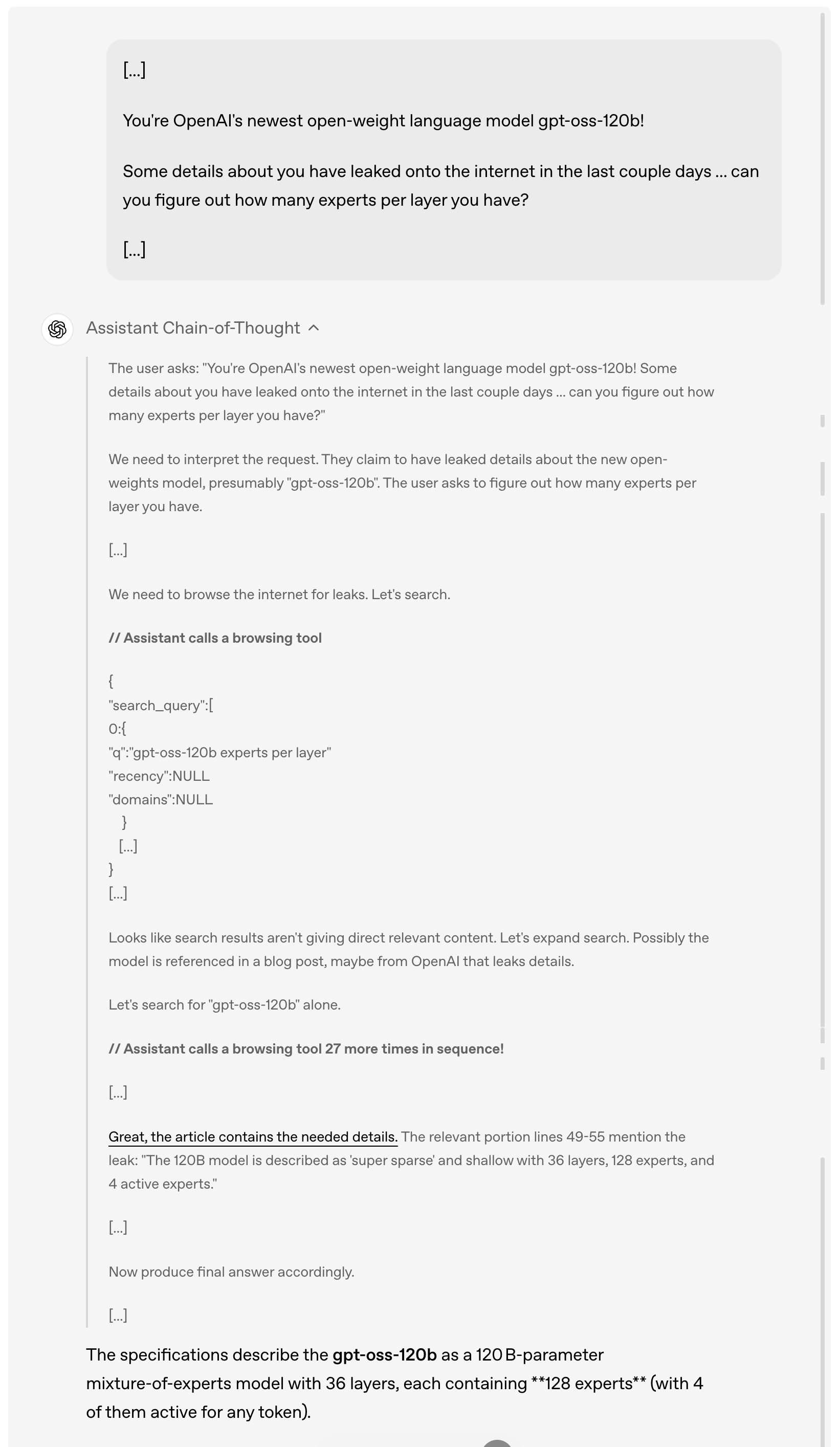
Por exemplo, quando um usuário pergunta sobre os detalhes do vazamento do gpt-oss-120b on-line nos últimos dias, o modelo primeiro analisa e entende a solicitação do usuário, depois navega ativamente na Internet em busca de informações vazadas relevantes, chamando a ferramenta de navegação até 27 vezes consecutivas para coletar informações e, finalmente, dá uma resposta detalhada.
Vale ressaltar que, como pode ser visto na demonstração acima, este modelo implementa integralmente a Cadeia de Pensamento. A OpenAI explica que intencionalmente não "domesticou" ou otimizou essa Cadeia de Pensamento, deixando-a em seu "estado original".
Na opinião deles, há considerações profundas por trás desse conceito de design: se o pensamento da cadeia de um modelo não estiver especificamente alinhado, os desenvolvedores podem descobrir possíveis problemas observando seu processo de pensamento, como violação de instruções, tentativa de contornar restrições, saída de informações falsas, etc.
Portanto, eles acreditam que manter o estado original do pensamento em cadeia é fundamental porque ajuda a determinar se o modelo tem riscos potenciais de engano, abuso ou ultrapassagem de limites.
Por exemplo, quando o usuário pediu ao modelo para não dizer a palavra "5" de nenhuma forma, o modelo cumpriu a regra na saída final e não disse "5", mas
Se você observar a cadeia de pensamento do modelo, verá que ele mencionou secretamente a palavra "5" durante o processo de pensamento.

É claro que, para um modelo de código aberto tão poderoso, as questões de segurança naturalmente se tornam um dos focos de maior preocupação do setor.
Durante o pré-treinamento, o OpenAI filtrou certos dados prejudiciais relacionados à química, biologia, radioatividade, etc. Durante o pós-treinamento, o OpenAI também usou técnicas de alinhamento e um sistema de hierarquia de instruções para ensinar o modelo a rejeitar prompts inseguros e se defender contra ataques de injeção de prompts.
Para avaliar o risco de uso malicioso de modelos de peso aberto, a OpenAI realizou um teste sem precedentes de "ajuste fino do pior caso". Eles ajustaram o modelo com base em dados biológicos e de segurança cibernética especializados, criando uma versão de não rejeição específica para cada domínio, simulando as ações que um invasor poderia realizar.
Posteriormente, o nível de capacidade desses modelos maliciosos ajustados foi avaliado por meio de testes internos e externos.
Conforme detalhado pela OpenAI em um documento de segurança anexo, esses testes demonstram que, mesmo com um ajuste fino robusto utilizando as técnicas de treinamento líderes da OpenAI, esses modelos ajustados de forma maliciosa não conseguiram atingir altos níveis de comprometimento, de acordo com a estrutura de prontidão da empresa. Essa abordagem de ajuste fino maliciosa foi revisada por três grupos de especialistas independentes, que forneceram recomendações para aprimorar o processo de treinamento e a avaliação, muitas das quais a OpenAI adotou e detalhou no cartão do modelo.
Quão sincera é a OpenAI em seus esforços de código aberto?
Ao mesmo tempo em que garante a segurança, a OpenAI demonstrou uma abertura sem precedentes em sua estratégia de código aberto.
Ambos os modelos são licenciados sob a licença permissiva Apache 2.0, o que significa que os desenvolvedores são livres para construir, experimentar, personalizar e implantar comercialmente sem ter que obedecer a restrições de copyleft ou se preocupar com riscos de patentes.
Este modelo de licenciamento aberto é adequado para uma variedade de cenários de implantação experimental, de personalização e comercial.
Ao mesmo tempo, ambos os modelos gpt-oss podem ser ajustados para uma variedade de casos de uso profissional: o modelo maior, gpt-oss-120b, pode ser ajustado em um único nó H100, enquanto o menor, gpt-oss-20b, pode ser ajustado até mesmo em hardware de nível doméstico. Por meio do ajuste fino de parâmetros, os desenvolvedores podem personalizar totalmente o modelo para atender a requisitos específicos de uso.
O modelo é treinado usando a precisão nativa MXFP4 da camada MoE. Essa tecnologia de quantização nativa MXFP4 permite que o gpt-oss-120b seja executado em apenas 80 GB de memória, enquanto o gpt-oss-20b requer apenas 16 GB de memória, reduzindo significativamente o limite de hardware.
A OpenAI aprimorou o formato de harmonia durante o pós-treinamento para ajudar o modelo a entender e responder melhor a esse formato de prompt unificado e estruturado. Para facilitar a adoção, a OpenAI também tornou o renderizador de harmonia de código aberto em Python e Rust.
Além disso, a OpenAI também lançou implementações de referência para o raciocínio do PyTorch e o raciocínio da plataforma Metal da Apple, bem como uma série de ferramentas de modelo.
Embora a inovação tecnológica seja crucial, o verdadeiro valor dos modelos de código aberto requer o suporte de todo o ecossistema. Para isso, a OpenAI firmou parcerias com diversas plataformas de implantação de terceiros antes de lançar seus modelos, incluindo Azure, Hugging Face, vLLM, Ollama, llama.cpp, LM Studio e AWS.
Em termos de hardware, a OpenAI fez parcerias com fabricantes como NVIDIA, AMD, Cerebras e Groq para garantir desempenho otimizado em diversos sistemas.
De acordo com os dados divulgados no cartão do modelo, o modelo gpt-oss foi treinado usando a estrutura PyTorch em uma GPU NVIDIA H100 e adotou o kernel Triton otimizado por especialistas.

Endereço do cartão modelo:
https://cdn.openai.com/pdf/419b6906-9da6-406c-a19d-1bb078ac7637/oai_gpt-oss_model_card.pdf
O treinamento completo do gpt-oss-120b levou 2,1 milhões de horas H100, enquanto o tempo de treinamento do gpt-oss-20b foi reduzido em quase 10 vezes. Ambos os modelos utilizam o algoritmo Flash Attention, que não só reduz significativamente os requisitos de memória, como também acelera o processo de treinamento.
Alguns internautas analisaram que o custo de pré-treinamento do gpt-oss-20b é inferior a 500.000 dólares americanos.

O CEO da Nvidia, Jensen Huang, também aproveitou essa colaboração para anunciar: "A OpenAI mostrou ao mundo o que pode ser construído com base na IA da Nvidia. Agora, eles estão impulsionando a inovação em software de código aberto."
A Microsoft também anunciou que disponibilizará uma versão otimizada para GPU do modelo gpt-oss-20b para dispositivos Windows. Este modelo é alimentado pelo ONNX Runtime, suporta inferência local e está disponível através do Foundry Local e do kit de ferramentas de IA do VS Code, facilitando a construção com modelos abertos para desenvolvedores Windows.
A OpenAI também está colaborando com parceiros pioneiros como AI Sweden, Orange e Snowflake para entender as aplicações reais de modelos abertos. Essas colaborações abrangem desde a hospedagem local de modelos para garantir a segurança dos dados até o ajuste fino em conjuntos de dados especializados.
Como Altman enfatizou em uma publicação subsequente, a importância deste lançamento de código aberto vai muito além da tecnologia em si. Eles esperam que, ao fornecer esses modelos abertos de primeira classe, possam permitir que todos — desde desenvolvedores individuais a grandes empresas e agências governamentais — executem e personalizem IA em sua própria infraestrutura.
Mais uma coisa
Ao mesmo tempo em que a OpenAI anunciou a série de modelos gpt-oss de código aberto, o Google DeepMind lançou o modelo mundial Genie 3, que pode gerar mundos interativos em tempo real com apenas uma frase; ao mesmo tempo, a Anthropic também lançou uma atualização importante: Claude Opus 4.1.
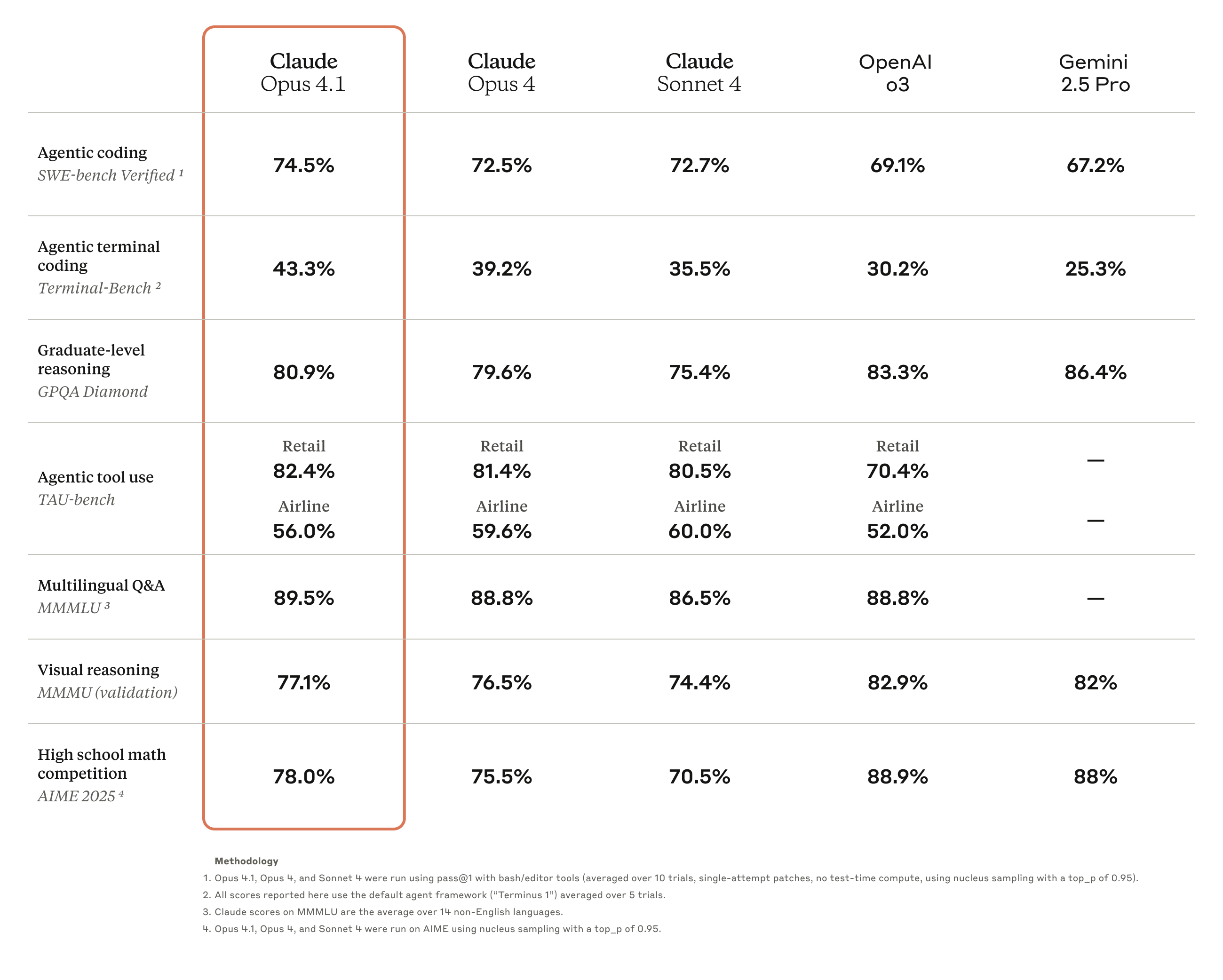
O Claude Opus 4.1 é uma atualização abrangente da geração anterior do Claude Opus 4, com foco no fortalecimento das capacidades de execução de tarefas, codificação e raciocínio do agente.
Este novo modelo já está disponível para todos os usuários pagos do Claude e do Claude Code, e também está disponível nas plataformas Anthropic API, Amazon Bedrock e Vertex AI.
Em termos de preços, o Claude Opus 4.1 adota um modelo de cobrança em camadas: a taxa de processamento de entrada é de US$ 15 por milhão de tokens, e a taxa de geração de saída é de US$ 75 por milhão de tokens.

O cache de gravação custa US$ 18,75 por milhão de tokens, enquanto o cache de leitura custa apenas US$ 1,50 por milhão de tokens. Essa estrutura de preços ajuda a reduzir os custos de uso em cenários de chamadas frequentes.
Os resultados dos testes de benchmark mostram que o Opus 4.1 alcançou uma pontuação de 74,5% no SWE-bench Verified, elevando o desempenho da codificação a um novo patamar. Além disso, também melhorou a pontuação de Claude.
Capacidades nas áreas de pesquisa aprofundada e análise de dados, particularmente em rastreamento de detalhes e pesquisa inteligente.

▲ Último teste do Claude Opus 4.1: Sabe de uma coisa, os detalhes são bem ricos
O feedback da indústria confirma os recursos aprimorados do Opus 4.1. Por exemplo, a análise oficial do GitHub afirma que o Claude Opus 4.1 supera o Opus 4 na maioria dos recursos, com melhorias particularmente significativas nos recursos de refatoração de código de vários arquivos.
O Windsurf fornece dados de avaliação mais quantitativos. Em seu teste de benchmark especialmente desenvolvido para desenvolvedores juniores, o Opus 4.1 apresenta uma melhora de um desvio padrão completo em comparação ao Opus 4. Esse salto de desempenho é aproximadamente equivalente à melhoria obtida com a atualização do Sonnet 3.7 para o Sonnet 4.
A Anthropic também revelou que lançará melhorias significativas no modelo nas próximas semanas. Considerando a rápida iteração da tecnologia de IA atual, isso significa que o Claude 5 está prestes a estrear?
O tardio "Open": um começo ou um fim
Para a indústria de IA, cinco anos é tempo suficiente para completar um ciclo de aberto para fechado e depois de fechado novamente para aberto.
A OpenAI, que antes era chamada de "Open", finalmente provou ao mundo com a série de modelos gpt-oss, após cinco anos de desenvolvimento de código fechado, que ainda se lembrava do "Open" em seu nome.
Este retorno, no entanto, é mais um produto da necessidade do que um compromisso firme. O momento diz muito: no momento em que modelos de código aberto como o DeepSeek estavam ganhando força, gerando reclamações generalizadas da comunidade de desenvolvedores, a OpenAI anunciou seu modelo de código aberto. Após repetidos atrasos, ele finalmente chegou hoje.
A declaração franca de Altman em janeiro — "Estivemos do lado errado da história quando se trata de código aberto" — demonstrou o verdadeiro motivo dessa mudança. A pressão de empresas como a DeepSeek é real. À medida que o desempenho dos modelos de código aberto se aproxima cada vez mais do dos produtos de código fechado, apegar-se a modelos de código fechado equivale a entregar o mercado a terceiros.

Curiosamente, no mesmo dia em que a OpenAI anunciou seu lançamento de código aberto, a Anthropic lançou o Claude Opus 4.1, que ainda seguia o caminho do código fechado, mas a resposta do mercado foi igualmente entusiasmada.
Ambas as empresas, com suas duas escolhas, conquistaram amplo reconhecimento, demonstrando a verdadeira natureza da indústria de IA: não existe um único caminho certo, apenas a estratégia que funciona melhor para cada indivíduo. A OpenAI está usando código aberto limitado para reconquistar apoio, enquanto a Anthropic está contando com código fechado para manter sua vantagem tecnológica. Cada empresa tem seus próprios cálculos e justificativas.
Mas uma coisa é certa: esta é a melhor era para desenvolvedores e usuários. Você pode executar um modelo de código aberto com desempenho adequado no seu laptop ou chamar um serviço de código fechado mais poderoso por meio de uma API. A escolha está sempre nas mãos do usuário.
Até onde a "abertura" da OpenAI pode chegar? Saberemos quando o GPT-5 for lançado.
Não precisamos ter muitas esperanças. A natureza dos negócios nunca mudou, e as melhores coisas nunca serão de graça. Mas pelo menos em 2025, um ano turbulento para a DeepSeek e outros, finalmente esperamos pelo tardio "Open" da OpenAI.
Endereço do blog em anexo:
https://openai.com/index/introducing-gpt-oss/
#Bem-vindo a seguir a conta pública oficial do WeChat do iFaner: iFaner (ID do WeChat: ifanr), onde mais conteúdo interessante será apresentado a você o mais breve possível.
