
A luz doméstica do vídeo AI, esta nova função libera completamente as mãos de desenhar cartas

Não está satisfeito depois de assistir "Squid Game"? Basta fazer seu próprio final.


Não quer esperar pela terceira parte de “Duna”? Faça um você mesmo.


No passado, teria levado muito tempo apenas para evitar que estes atores perdessem a forma e quebrassem. Agora você só precisa enviar uma captura de tela para a IA e começar a fazer filmes.
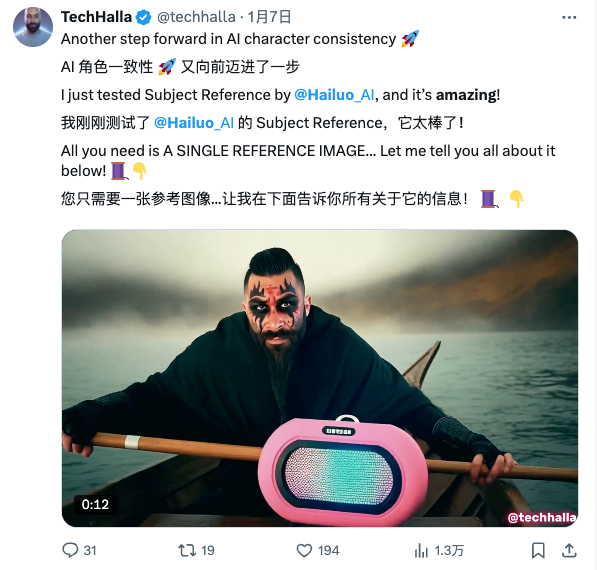
Esta é a função de “referência de assunto” lançada pela Conch AI. É suportada pelo novo modelo S2V-01 e pode identificar com precisão o assunto na imagem carregada e defini-lo como personagem no vídeo gerado. O resto pode ser usado como quiser com instruções simples e rápidas.

▲ Criação do usuário X @KarolineGeorges, as informações faciais são retidas com precisão

▲Criação do usuário X @Apple_Dog_Sol, apresentando múltiplos assuntos
Por que a "Referência do Assunto" é tão incrível?
Na verdade, muitos fabricantes estão executando a função de “referência de assunto”. Mas nem todos conseguem superar as dificuldades envolvidas nesta função: estabilidade, consistência e movimento consistente.
Outros podem não conseguir, mas a Conch AI pode. Com apenas uma imagem, você pode entender com precisão as características dos personagens, identificá-los como sujeitos e então fazer com que os personagens apareçam em diversas cenas e ambientes.
O Homem-Aranha, que num segundo estava salvando o mundo, no outro estava andando de moto.


A mãe dragão que deveria estar treinando o dragão em Game of Thrones agora estava provocando o lobinho.


O progresso revolucionário da "Referência Principal" é alcançar o equilíbrio perfeito entre liberdade criativa e redução. É como dar ao criador um “ator universal”. A aparência do ator não entrará em colapso, mas poderá mudar naturalmente com movimentos e posturas. Ele também poderá realizar qualquer ação em qualquer cena de acordo com as exigências do diretor.
Não apenas novos recursos, mas também soluções técnicas exclusivas
A sensação da medição real é: a referência principal é uma função completamente diferente, que é diferente dos efeitos alcançados por Vincent e Tusheng. As dificuldades técnicas envolvidas nela são diferentes, e os requisitos para ideias técnicas também são diferentes.
Os vídeos tradicionais do Tusheng animam apenas imagens estáticas e fazem principalmente alterações locais. Veja esta foto de Song Hye Kyo como exemplo. Apenas transformou a imagem estática original em uma imagem dinâmica, e o escopo é limitado e não haverá grandes movimentos.

▲ Fotos originais

▲ Filme baseado no vídeo Tusheng
Para a mesma foto, a “referência do assunto” pode formar um fragmento completo com base no texto do prompt. Embora os movimentos sejam livres, as características faciais ainda são realizadas de forma estável.

▲ prompt: Iluminação interna aconchegante, no auditório do teatro, o protagonista veste terno preto e está sentado na fila do meio à esquerda. Sua expressão é cheia de concentração, às vezes ela mostra um sorriso relaxado, batendo palmas, e seus movimentos são naturais e rítmicos. A câmera parte do lado da protagonista, capturando as silhuetas dos demais espectadores ao seu redor e a textura fosca das poltronas, enfatizando as camadas do ambiente. À medida que a câmera avança, o protagonista se levanta.
Atualmente existem duas rotas técnicas para gerar vídeos baseados em pessoas. Um é baseado na tecnologia LoRA para realizar ajustes específicos em modelos generativos de grande escala pré-treinados. LoRA requer muitos cálculos ao gerar novos vídeos. Isso faz com que os usuários tenham que fazer upload de materiais do mesmo assunto e ângulos diferentes, e até mesmo precisar quais elementos diferentes um único clipe precisa ter para garantir a qualidade da produção. Ao mesmo tempo, também requer um grande consumo de tokens e um longo tempo de espera.
Com base em uma grande quantidade de exploração técnica, a MiniMax escolheu uma rota técnica baseada na referência da imagem: as imagens contêm as informações visuais mais precisas, começando pelas imagens e em conformidade com a lógica criativa da fotografia física. Neste percurso técnico, o protagonista da imagem é a primeira prioridade para o modelo identificar entre todas as informações visuais – não importa qual imagem apareça a seguir ou qual seja o enredo, o assunto precisa permanecer consistente.
Outras informações visuais são mais abertas e controladas por prompts de texto. Desta forma, o objetivo de geração de “restauração precisa + alto grau de liberdade” pode ser alcançado.


▲ Na clareira do vale, o protagonista fica diante do dragão gigante, com seus longos cabelos esvoaçando ao vento. A câmera aumenta gradualmente o zoom para capturar a ação da protagonista se virando e olhando para longe. As asas do dragão se abrem, soprando o cabelo e a saia da protagonista. A cena finalmente termina com uma tomada aérea.
Neste vídeo, apenas uma foto da Mãe Dragão foi enviada para a modelo. No vídeo final, o modelo apresentou com precisão a linguagem da lente e os elementos da imagem envolvidos na solicitação, demonstrando sua forte capacidade de compreensão.
Em comparação com a solução LoRA, a rota técnica de referência de imagem pode reduzir visivelmente os materiais enviados pelos usuários, e dezenas de vídeos são transformados em uma imagem. Ao mesmo tempo, o tempo de espera é calculado em segundos, o que não difere muito do tempo necessário para gerar texto e imagens – tem a precisão do vídeo Tusheng e a liberdade do vídeo Vincent.
A luz doméstica pode satisfazer os seus "desejos e necessidades"
“Ter os dois” não é um pedido excessivo. Somente alcançando consistência precisa e movimento livre dos personagens ao mesmo tempo o modelo pode ir além do escopo de viver e fazer esboços, e ter um valor de uso mais amplo em cenários de aplicação industrial.
Por exemplo, na publicidade de produtos, uma imagem de modelo pode gerar vídeos diretamente para vários produtos, e isso pode ser conseguido simplesmente alterando o prompt.


Se for implementado usando Tusheng Video, a solução convencional atual é definir o primeiro e o último quadro, e os efeitos que podem ser alcançados também são limitados pelas imagens existentes. Ao mesmo tempo, você deve sacar cartas repetidamente, coletar diferentes ângulos e, finalmente, unir os materiais para completar um conjunto de planos gerais.
Combinando as características de diferentes tecnologias, fica mais alinhado com o fluxo de trabalho de criação de vídeo, o que é a vantagem da “Referência de Assunto”. No futuro, mais de 80% dos profissionais de marketing utilizarão ferramentas generativas em diferentes links. Eles só precisam se concentrar na concepção da história e do enredo, liberando as mãos para desenhar cartões.
Estatísticas do Statista mostram que o tamanho do mercado de produtos generativos de IA em marketing publicitário excederá US$ 15 bilhões em 2021. Em 2028, esse número atingirá US$ 107,5 bilhões. No fluxo de trabalho anterior, os vídeos puros do Vincent eram muito incontroláveis, por isso eram adequados para uso nos estágios iniciais de criação. A IA generativa tornou-se muito comum na indústria de publicidade e marketing na Europa e nos Estados Unidos, com 52% dos seus casos de utilização a serem utilizados na primeira elaboração e planeamento, e 48% a serem utilizados em brainstorming.
Atualmente, a Conch AI está abrindo primeiro a capacidade de referência para um único personagem. No futuro, ela se expandirá para capacidades de referência mais ricas para várias pessoas, objetos, cenas, etc., para liberar ainda mais a criatividade. “Todos A ideia é um filme de grande sucesso.”
Desde o lançamento do modelo de vídeo MiniMax em agosto do ano passado, ele continuou a atrair a atenção e a experiência de um grande número de usuários no exterior em termos de qualidade e fluência de imagem, consistência e estabilidade, incluindo muitos profissionais com experiência na criação de imagens. muito feedback positivo e reconhecimento profissional.
Na competição tecnológica ao longo do último ano, o cenário competitivo no campo da geração de vídeo de IA emergiu inicialmente. A implementação do Sora fez com que as pessoas vissem o potencial na área de geração de vídeo. Posteriormente, grandes empresas de tecnologia investiram recursos nesta área e investiram pesadamente em pesquisa e desenvolvimento.
Com o atraso no lançamento do produto Sora no final do ano e a reputação medíocre dos testes com usuários, ele não atendeu às expectativas do mercado. Isso também dá a outros players a oportunidade de conquistar o mercado.
Hoje, com o vídeo generativo prestes a entrar em seu segundo semestre, existem apenas três empresas que realmente demonstraram sua força técnica e potencial de desenvolvimento: Conch AI da MiniMax, Keling AI de Kuaishou e Jimeng AI da ByteDance.
Como uma empresa start-up que acaba de ser criada há 3 anos, a MiniMax traz produtos e tecnologias que são capazes de atingir o nível T0 com seu corpo start-up capaz. Do modelo de vídeo Tusheng I2V-01-Live em dezembro do ano passado ao novo modelo S2V-01 atual, todos eles estão resolvendo os problemas espinhosos da geração de vídeo do passado.
À medida que a tecnologia continua a amadurecer e os cenários de aplicação se expandem gradualmente, a IA de geração de vídeo desencadeará uma nova rodada de revolução na criação de conteúdo, produção de filmes e televisão, comunicações de marketing e outros campos. Estes fabricantes, que representam o mais alto nível no campo da IA de geração de vídeo da China, não só continuam a liderar o mercado interno, mas também deverão competir com gigantes internacionais em escala global. Ao mesmo tempo, como garantir a estabilidade e controlabilidade do produto, mantendo ao mesmo tempo a inovação tecnológica, será um desafio contínuo enfrentado por estas empresas.
# Bem-vindo a seguir a conta pública oficial do WeChat de Aifaner: Aifaner (WeChat ID: ifanr). Mais conteúdo interessante será fornecido a você o mais rápido possível.
