
A grande guerra de preços dos modelos da China: os grandes fabricantes estão enlouquecendo, Kaifu Lee e Wang Xiaochuan não seguem o exemplo, quem será morto primeiro?

Nunca esperei que o “618” deste ano começasse com um grande modelo de IA.
Em poucos dias, grandes modelos nacionais como Tencent, Alibaba, Baidu, iFlytek, etc. reduziram os seus preços, permitindo-nos sentir antecipadamente o ambiente simples de "festival de compras".
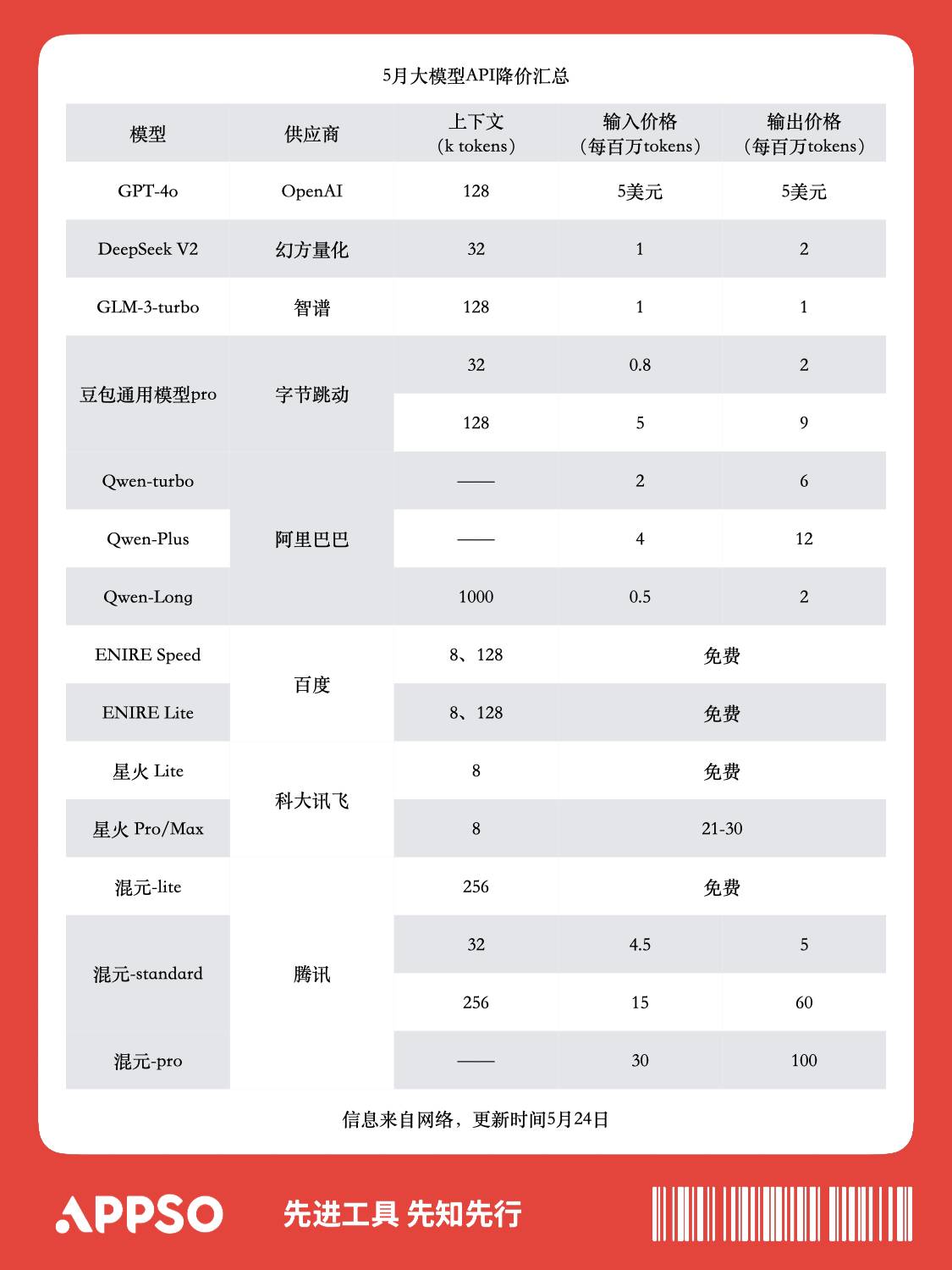
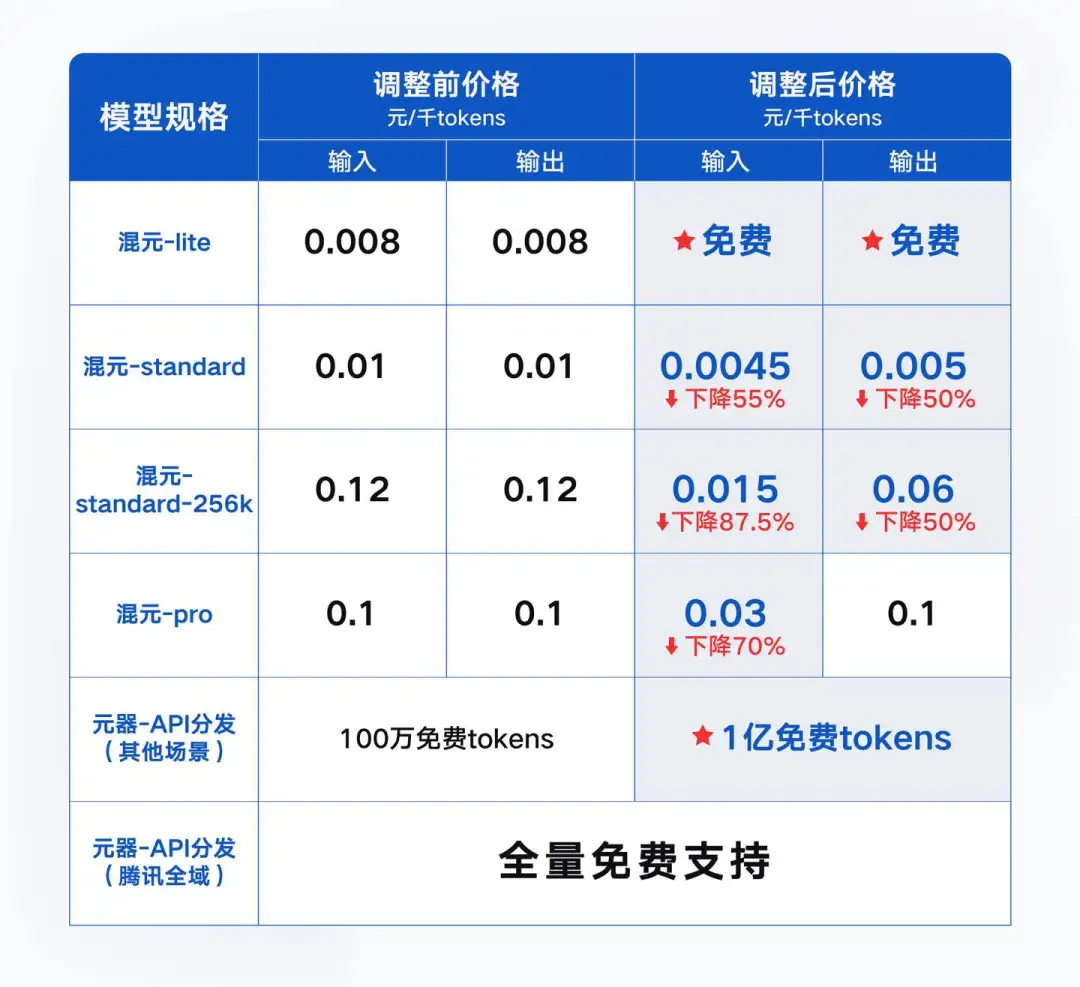
▲ Resumo das atuais reduções de preços de grandes modelos nacionais
Mas antes que a diversão comece, vamos primeiro descobrir o que esses fabricantes querem dizer com preço de modelos grandes.
Normalmente, depois que uma grande empresa de modelos de IA treina seu próprio grande modelo de código fechado, ela vende sua API (Interface de Programação de Aplicativos, Interface de Programação de Aplicativos) para desenvolvedores e cobra uma taxa.

▲ PI é como um garçom em um hotel, foto de hububbble.com
Com base na API de modelo grande, os desenvolvedores otimizam alimentando dados, ajustando, etc. Este é o modelo de monetização de muitos fabricantes de modelos grandes.
Não é difícil ver que as mudanças no preço dos modelos grandes podem não afetar diretamente os consumidores, mas afetarão diretamente o custo dos desenvolvedores que fazem aplicações.
Embora existam atualmente algumas grandes empresas de modelos de IA que adotam sistemas de adesão, sistemas baseados em tempo e outros modelos, eles geralmente são cobrados com base no uso, semelhante aos pacotes de tráfego de telefonia móvel, exceto que a unidade de faturamento mudou de GB de tráfego para tokens .
No entanto, atualmente não existe um padrão unificado para a correspondência entre tokens, caracteres chineses e letras, e cada empresa também tem a sua própria definição. De acordo com notícias anteriores, 1 token de Tencent ≈ 1,8 caracteres chineses, 1 token de Tongyi Qianwen = 1 caractere chinês e, em alguns casos, 1 token ≈ 0,5 caracteres chineses.

▲ Fotos do Instituto de Pesquisa Tecnológica Bingjian
Portanto, os padrões de faturamento de cada empresa são diferentes, mas geralmente seguem a regra de que quanto maior a escala do modelo grande, mais caro é o preço. Afinal, aqui há custos de treinamento.
Nesta fase, os principais fabricantes ainda estão explorando o modelo de negócios de venda de chamadas de API. Muitos fabricantes tentam aumentar as chamadas de API de grandes modelos através de vários métodos, mas o crescimento não é óbvio.
Neste caso, a redução de preços de APIs de grandes modelos pode atrair alguns desenvolvedores para experimentar aplicações de IA a partir de "testes gratuitos", o que tem certo significado positivo para capturar e ativar o mercado. Esta é a premissa e o pano de fundo desta "guerra".
Prepare-se, renda-se!
Em 6 de maio, a Magic Square Quantitative assumiu a liderança no lançamento da primeira onda desta "guerra" de redução de preços. O preço de seu grande modelo DeepSeek-V2 caiu para apenas 1 yuan por milhão de tokens de entrada. Faça login e obtenha o slogan "tokens" de 500W.

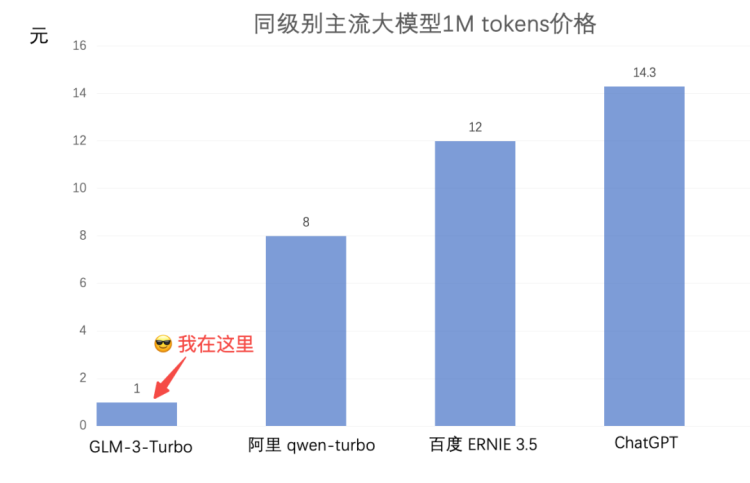
Em 11 de maio, Zhipu Big Model também "acompanhou o ritmo" e lançou novas medidas preferenciais. A cota para usuários recém-registrados foi aumentada de 5 milhões de tokens para 25 milhões de tokens.
O preço do produto básico GLM-3-turbo caiu de 5 yuans para 1 yuan por milhão de tokens, uma queda de 80%.
Ao anunciar o preço, ele também comparou “intimamente” seu GLM-3-turbo com Alibaba, Baidu e ChatGPT, que estava cheio de pólvora.
Posteriormente, a entrada de fornecedores de nuvem levou esta onda de “guerra” de redução de preços ao clímax.
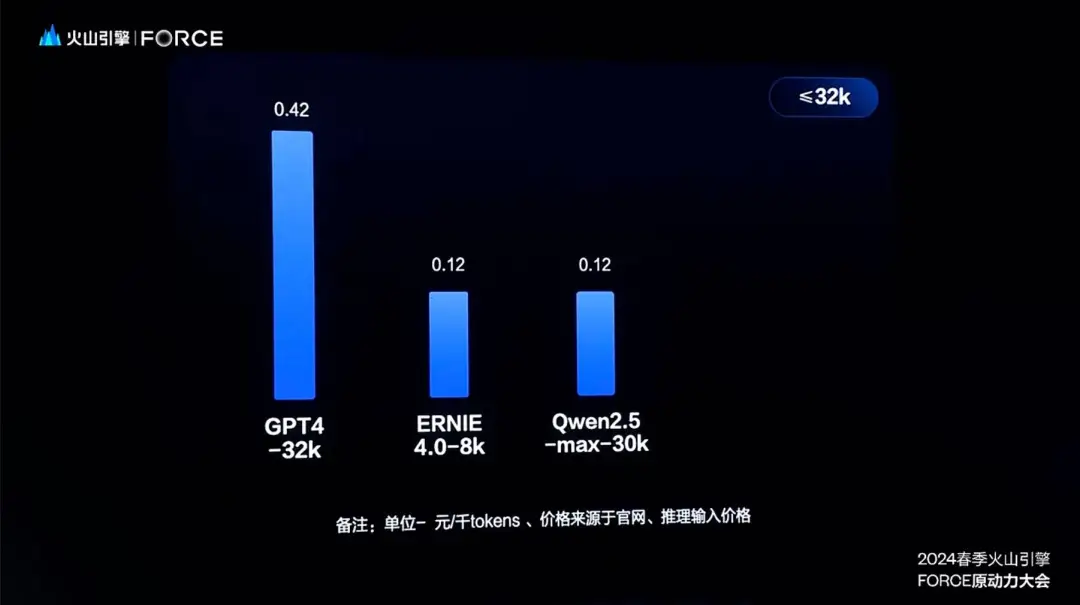
Em 15 de maio, ByteDouBao anunciou: “O preço dos modelos grandes foi reduzido!” Tan Dai, presidente da Volcano Engine, anunciou que o preço do principal modelo do DouBao no mercado corporativo é de 0,0008/mil tokens, comparando Baidu, Ali e modelos com as mesmas especificações do mercado. O preço é geralmente de 0,12/mil tokens, conseguindo uma involução de preços “de centavos em centavos”.
Ele também deu um exemplo: “Um yuan pode comprar 1,25 milhão de tokens do modelo principal de Doubao”, o que equivale a cerca de 2 milhões de caracteres chineses, o que equivale a gerar três “Romance dos Três Reinos”.
Em 21 de maio, diante da guerra de preços da ByteDance, o responsável pelo Alibaba Cloud disse em contra-ataque:
"Grandes empresas modelo amigáveis propuseram vários temas de redução de preços. O objetivo da redução de preços é beneficiar o mercado. Na China, qual empresa é realmente capaz e tem o capital para reduzir os preços depende se a capacidade do modelo básico do modelo está liderando, se existem recursos de raciocínio e se o modelo atual já existe. Muitos usuários o utilizam e modelos grandes não são o negócio principal.
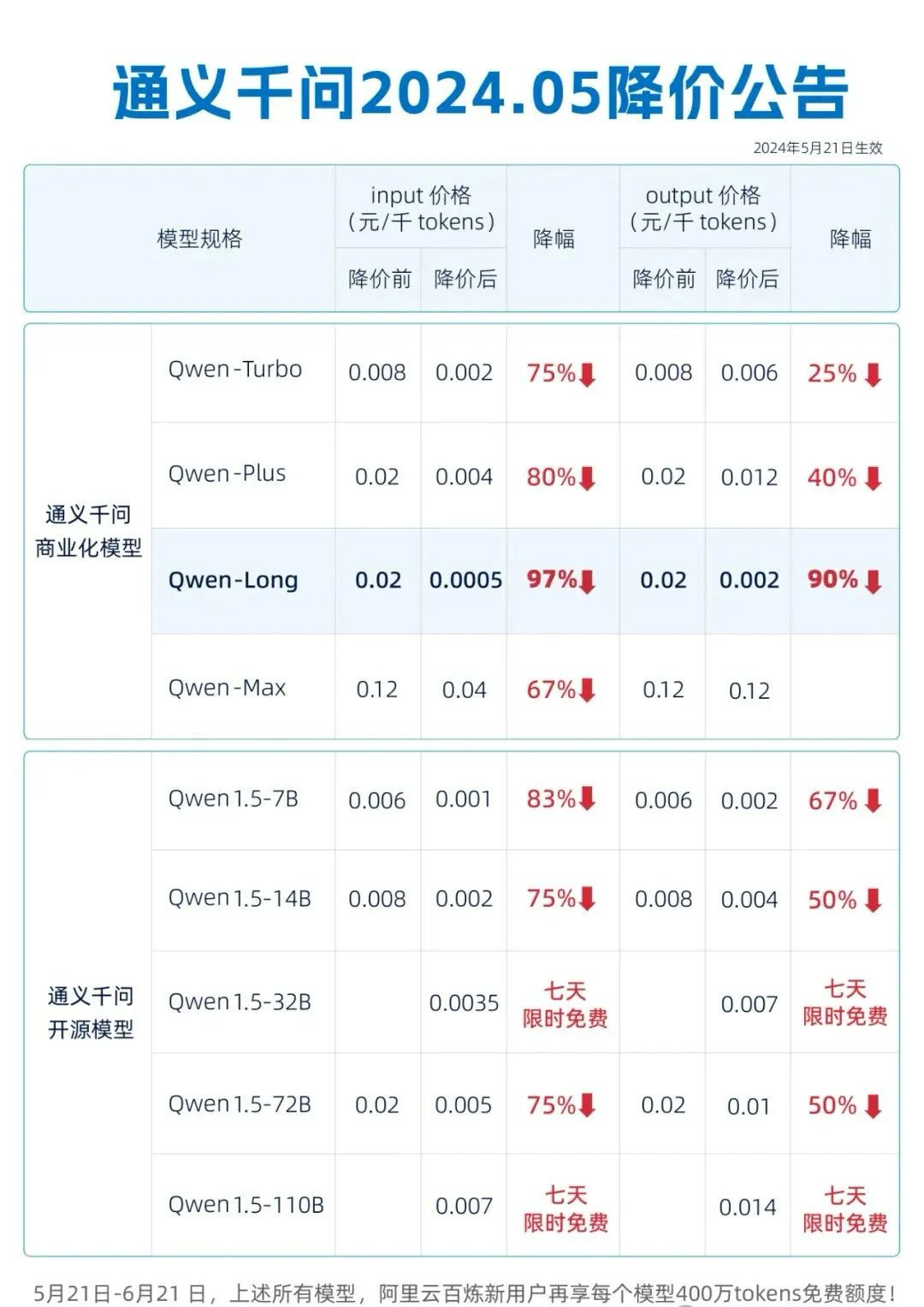
Ao mesmo tempo, o Alibaba Cloud também lançou o slogan "rompendo os preços mais baixos do mundo" e reduziu coletivamente os preços de seus 9 modelos grandes. O preço do modelo assistente de "nível GPT-4" Qwen-Long caiu para 0,5. yuans por milhão de tokens. Entrada e saída de 2 yuans.
Em outras palavras, 1 yuan pode comprar 2 milhões de tokens, o que equivale ao volume de texto de 5 “Dicionários Xinhua”, mas o preço é apenas cerca de 1/400 do GPT-4.
Poucas horas depois, a Baidu, outra empresa que está sempre sendo comparada, também agiu de forma direta e totalmente gratuita, os dois principais modelos da Wenxin Models, ERNIE Speed e ERNIE Lite.
Embora esses dois modelos não sejam os modelos carro-chefe entre seus modelos grandes, eles são atualmente os modelos que atendem ao maior número de usuários na grande série de modelos do Baidu Wenxin.

Em 22 de maio, a iFlytek também anunciou que se juntaria à “competição de redução de preços”. A API iFlytek Spark Lite será permanentemente aberta gratuitamente, e o iFlytek Spark Pro/Max custa apenas 0,21 yuan/10.000 tokens. “usar o iFlytek Spark 3.5 no máximo custa apenas 2,1 yuans e pode gerar o conteúdo de “Alive” de Yu Hua.

No mesmo dia, Tencent Cloud anunciou que se juntou ao grande campo de redução de preços de modelos. Seu preço de API do modelo Hunyuan-lite é totalmente gratuito a partir de 0,008 yuans/mil tokens. O recém-lançado padrão Hunyuan e o modelo de parâmetro de trilhão de configuração mais alta, Hunyuan. -pro API são ambos. Uma redução de preço ocorre e entra em vigor imediatamente.
Neste ponto, quase todos os grandes fabricantes de modelos entraram no jogo. Parece que da noite para o dia, os grandes modelos iniciaram coletivamente uma louca redução de preços.
A inovação tecnológica por trás da “guerra de preços”
Não só os fabricantes nacionais, mas também os grandes modelos estrangeiros representados pela OpenAI também estão constantemente a baixar os preços dos grandes modelos. Embora não sejam tão concentrados como os fabricantes nacionais, eles agem mais cedo do que os fabricantes nacionais.
O GPT-3.5 turbo, lançado em março de 2023, reduzirá o custo por mil tokens para US$ 0,002, o que é 90% menor que o GPT-3.5 turbo anterior.
O preço dos tokens de entrada do GPT-4 Turbo lançado em novembro é de apenas 1/3 do GPT-4, e o preço dos tokens de saída é 1/2 do GPT-4.
O GPT-4o lançado recentemente é 2 vezes mais rápido que o turbo GPT-4 anterior, mas o preço é metade mais barato. Seu preço foi reduzido quatro vezes consecutivas desde 2023.
Não é difícil ver que, para a OpenAI, a redução de preços se tornou a sua estratégia central para a atualização contínua e a expansão do mercado. Outros modelos grandes, como o Gemini, também não se esquecem de adicionar alterações de preços após o desempenho, e grandes reduções de preços se tornaram uma tendência geral.

Na verdade, não importa se se trata de um grande modelo nacional ou de um grande modelo estrangeiro, a razão fundamental para a redução de preços é a rápida redução dos custos de inferência.
Não muito tempo atrás, DeepSeek-V2 nos apresentou em um artigo que usa MLA (Atenção latente de múltiplas cabeças) combinado com MoE (modelo híbrido especializado de mistura de especialistas) para obter melhoria de nível cruzado no desempenho do modelo. de cálculo, raciocínio existente e casos de custos. Amigos interessados podem clicar para visualizar o texto original:
https://github.com/deepseek-ai/DeepSeek-V2/blob/main/deepseek-v2-tech-report.pdf
À medida que o poder de computação aumenta e os algoritmos continuam a avançar, esta tendência continuará. Em uma entrevista recente, o presidente e CEO da Sinovation Ventures, Kai-Fu Lee, falou sobre o recente frenesi de reduções de preços e acreditou que "espera-se que toda a indústria reduza os custos de inferência em 10 vezes a cada ano, e isso deve acontecer".
No entanto, ele também disse que o que está surgindo atualmente é uma abordagem insustentável "estilo ofo" de perder-perder, dizendo: "Se a tecnologia não for boa, dependeremos puramente de descontos e perdas para fazer negócios. Nunca seguiremos tal um preço. Faça benchmarking."
Isso decorre de sua confiança em seus modelos grandes: “Assim como a Tesla, ela não reduzirá os preços só porque outras marcas de carros são mais baratas que ele”.
No entanto, todos sabemos que a Tesla não reduz realmente os preços e, por vezes, até se torna pioneira na redução de preços. Perguntamo-nos se as suas observações se tornarão um "bumerangue" no futuro.

▲ Kai-fu Lee, presidente e CEO da Innovation Works, foto da Internet
A onda está próxima
Além de Kaifu Li, Wang Xiaochuan, fundador da Baichuan Intelligence, também tem uma compreensão diferente desta guerra de preços:
“Acho que, assim como o Didi Meituan original, isso estimulará todo o mercado B a prosperar mais rapidamente e todos estarão mais dispostos a experimentá-lo.”
Ele acredita que a guerra de preços vai na verdade lembrar aqueles fabricantes que entraram cegamente na indústria de grandes modelos porque tinham medo de ficar para trás para reconsiderar seu posicionamento e eliminar algumas empresas que “não pensaram com clareza”.
"Quando a maré subir e descer, no final haverá pérolas. Deve haver uma bolha dentro. As guerras de preços tornarão a bolha mais próspera. Isso não significa que não haja bolha na situação. Na bolha anterior, muitas empresas sentiram que precisavam treinar modelos. Isso não é saudável. Não há necessidade de tantos fornecedores de modelos no mercado e não há necessidade de uma guerra de milhares de modelos ou de uma guerra de dez mil modelos.

▲ Wang Xiaochuan, CEO da Baichuan Intelligence
Fu Sheng, presidente e CEO da Cheetah Mobile, acredita que este é um movimento impotente depois que a homogeneização de grandes modelos torna difícil eliminar a lacuna de desempenho:
"Este grande corte de preços basicamente anunciou que as startups de grandes modelos devem encontrar novos modelos de negócios. No curto prazo, o desempenho dos grandes modelos encontrou um gargalo. Ninguém pode se livrar de ninguém e ninguém pode inventar um trunfo reduzir custos de inferência e reduzir custos O preço de venda tornou-se uma alta prioridade para todas as empresas agora.
Não há dúvida de que os grandes fabricantes baixaram os preços, o que significa maior pressão competitiva para muitas startups na indústria de grandes modelos.
Na verdade, quando uma indústria entra na fase de redução abrangente de preços, isso significa o início de uma competição eliminatória em grande escala e, no final, muitas vezes restam apenas algumas empresas.
Muitas vezes vemos que nas fases iniciais do desenvolvimento da indústria, devido à enorme tentação das "janelas", várias empresas boas e más competem frequentemente entre si no mercado. No entanto, após uma ou várias rondas de reduções de preços em grande escala, a indústria é remodelada e a eficiência é ineficiente. As empresas de alto desempenho são expulsas do mercado.
Atualmente, esse processo na área de IA parece estar se acelerando, principalmente para fabricantes cujos modelos grandes não apresentam vantagens no mercado.

Mas, por outro lado, a redução de preços dos grandes modelos é uma boa notícia para os utilizadores, porque significa que podem aceder e utilizar tecnologia avançada de IA a um custo mais baixo e é mais fácil produzir excelentes aplicações de IA no mercado.
Porém, atualmente, a comercialização de toda a indústria ainda está longe de formar um ecossistema. Além das grandes empresas modelo na China, ainda existe uma grande lacuna na equipe de desenvolvimento de aplicações de IA.
De acordo com os últimos dados divulgados pelo Baidu, o grande modelo de Wenxin processa 250 bilhões de tokens de texto por dia, e a ByteDance processa 120 bilhões de tokens de texto por dia. No entanto, grande parte disso é negócio interno de grandes empresas que usam aplicativos de IA e exploração de negócios. Percebe-se que atualmente, de fato, toda a indústria ainda não formou um ecossistema.
Os analistas da Bloomberg também apontaram anteriormente: “A China enfrentará um longo caminho para a lucratividade em IA, e a remodelação da indústria pode promover a lucratividade na indústria, mas parece improvável que isso aconteça em breve. desenvolvimento da indústria.
A IDC prevê que o mercado de grandes modelos de IA da China atingirá 21,1 mil milhões de dólares em 2026, e a inteligência artificial entrará num período crítico para implementação em grande escala.
Acredita-se que com o declínio do preço dos grandes modelos, bem como o desenvolvimento da multimodalidade, velocidade de inferência acelerada e custos reduzidos, a pesquisa, a IA para PC/telefones celulares ou outros produtos eletrônicos de consumo se tornarão um amplo espaço para o desenvolvimento de aplicações de IA.
Essa oportunidade pode lembrar a muitas pessoas a época em que a Internet estava em ascensão. Na verdade, as duas têm muitas semelhanças. Esta é também uma razão importante pela qual Huang Renxun disse que a era atual é a “próxima revolução industrial”.

O declínio dos custos marginais pode ser a causa direta da revolução da plataforma de IA
O parceiro da A16Z, Martin Casado, certa vez defendeu a opinião de que houve dois casos na história de mudanças de plataforma e revoluções na indústria causadas pelo declínio dos custos marginais, nomeadamente chips e Internet.
O nascimento dos chips reduziu o custo marginal da computação para perto de zero. Antes disso, os cálculos tinham que ser feitos manualmente. As pessoas eram obrigadas a fazer tabelas de logaritmos com as próprias mãos em uma sala grande.
Depois, o ENIAC e outras máquinas foram introduzidos, e a velocidade da computação aumentou rapidamente em quatro ordens de magnitude. A revolução informática subsequente trouxe um grande número de novas indústrias, revitalizou muitas empresas e gerou uma série de novas empresas.

Então, na era da Internet, o custo marginal de distribuição caiu para 0. No passado, não importa o que você enviasse (uma caixa ou uma carta), havia um certo custo depois que a Internet apareceu, o preço por bit caiu drasticamente.
Foi também uma melhoria de quatro ordens de grandeza, que contribuiu para o rápido desenvolvimento das indústrias relacionadas e liderou a revolução da Internet. Nesse período, empresas como Amazon, Google e Meta surgiram como representantes.

Semelhante às duas tecnologias acima, a IA também é uma revolução de produtividade impulsionada pelos custos. Modelos grandes reduzem o custo marginal de criação a 0, como criação de imagens e compreensão de linguagem, etc. Ele também deu esse exemplo.
Se você quisesse criar um personagem animado no estilo Pixar sobre você mesmo, um modelo grande custaria cerca de 0,01 centavos e levaria apenas 1 segundo, mas contratar um designer gráfico por uma hora custaria cerca de US$ 100, talvez mais.
Em vez de ser um pouco melhor, a IA é mais barata e muito mais rápida.
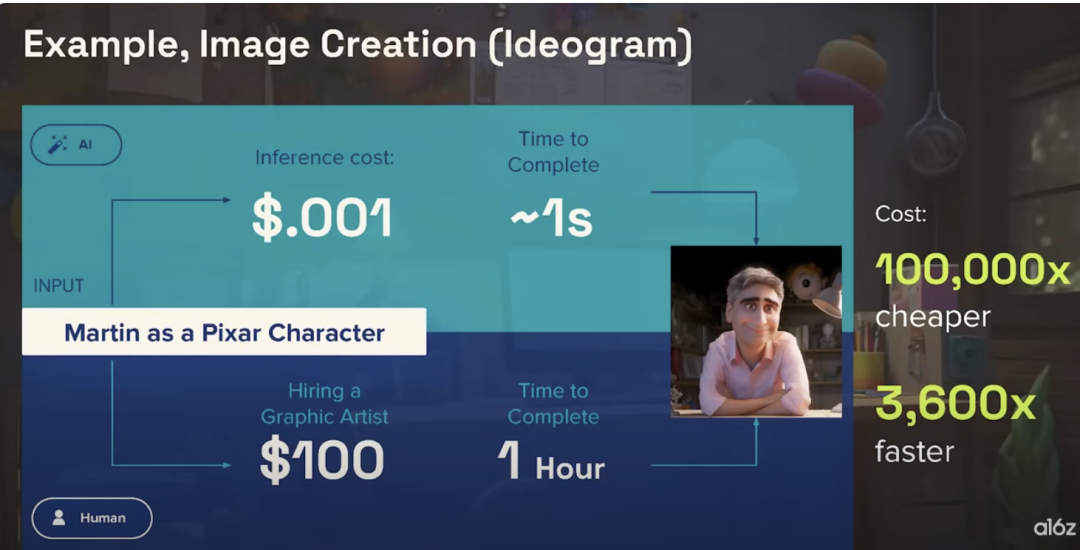
▲ Compare o custo e o tempo necessários para geração de imagens entre inteligência artificial e designers gráficos
Em 1865, o economista britânico William Stanley Jevons observou que as melhorias tecnológicas que tornavam a utilização do carvão mais eficiente levariam, em vez disso, ao aumento do consumo de carvão numa vasta gama de indústrias.
Ele acredita que, contrariamente à intuição de muitas pessoas, o aumento da eficiência leva a preços mais baixos, o que por sua vez estimula mais procura.
Por outras palavras, quando o progresso tecnológico melhora a eficiência da utilização de recursos, mas a redução de custos leva a um aumento da procura, a taxa de consumo de recursos aumenta em vez de diminuir. Este é o famoso “Paradoxo de Jevons”.

▲ William Stanley Jevons (1835.9.1—1882.8.13)
No passado, os chips e a Internet eram esses recursos. Devido à melhoria da eficiência da computação e da informação e à redução dos preços, estimulou mais procura, gerou mais valor e serviços e deu origem a novas transferências de plataformas e revoluções industriais, aumentando assim a produtividade. e o rendimento das pessoas, mudando em última análise a aparência do mundo inteiro e a vida de cada um de nós.
Esta é a história dos chips e da Internet há muitos anos, e é também a história da IA que está acontecendo hoje.
# Bem-vindo a seguir a conta pública oficial do WeChat do aifaner: aifaner (WeChat ID: ifanr). Mais conteúdo interessante será fornecido a você o mais rápido possível.
