
A equipe de Stanford plagiou um grande modelo da Universidade Tsinghua. O autor pediu desculpas tarde da noite. O grande modelo da China não pode mais ser ignorado.
Há algum tempo, o Instituto de Inteligência Artificial da Universidade de Stanford (Stanford HAI) divulgou um relatório afirmando que os Estados Unidos estão muito à frente no campo de grandes modelos. O relatório apontou que 61 modelos de inteligência artificial bem conhecidos em 2023 vieram de instituições dos EUA, excedendo em muito os 21 na UE e os 15 na China.
Vinod Khosla, um dos primeiros investidores da OpenAI, também publicou um artigo no X no ano passado dizendo que os modelos americanos de código aberto serão copiados pela China.
No entanto, o grande modelo doméstico que sempre foi considerado "alcançando os Estados Unidos" tornou-se agora alvo de plágio, e a equipe de IA plagiada é da Universidade de Stanford, que divulgou o relatório acima.

O modelo de código aberto Llama3-V liderado pela equipe de IA de Stanford foi considerado suspeito de plagiar o modelo doméstico de código aberto "Little Steel Cannon" MiniCPM-Llama3-V 2.5 da Tsinghua University e Wall-Facing Intelligence, o que instantaneamente causou um rebuliço no círculo de IA.
Sob o martelo real, a equipe de Stanford também teve que pedir desculpas urgentemente.
Como Li Dahai, CEO da Wall-Facing Intelligence, respondeu brincando, este é um “método reconhecido pela equipe internacional”. Não importa o quão longe estejamos dos grandes modelos, os grandes modelos nacionais atingiram um estágio em que não podem mais ser ignorados.
Vamos resolver brevemente a linha do tempo:
- A equipe de IA de Stanford lança o Llama3-V, conhecido como modelo grande multimodal SOTA
- Internautas questionaram que o modelo copiou o MiniCPM-Llama3-V2.5 inteligente doméstico voltado para a parede
- Surgiram evidências questionáveis, o autor do Llama3-V encenou "excluir o banco de dados e fugir"
- Plágio oficial da Face Wall Intelligence, emitiu um comunicado tarde da noite
- O autor do Llama3-V pede desculpas oficialmente, os internautas têm opiniões diferentes
Plagiando o inteligente "Small Steel Cannon" voltado para a parede, a equipe de IA de Stanford encenou "Exclua o banco de dados e fuja"
Recentemente, uma equipe de IA de Stanford anunciou que custa apenas US$ 500 treinar um grande modelo SOTA multimodal que supere o GPT-4V.
Mas logo, um usuário X @yangzhizheng1 apontou que a estrutura do modelo e o código usado neste projeto são surpreendentemente semelhantes ao MiniCPM-Llama3-V2.5 lançado pela Wallface Intelligence há pouco tempo.
Para este fim, o usuário X @yangzhizheng1 também divulgou evidências de questionamento correspondentes.
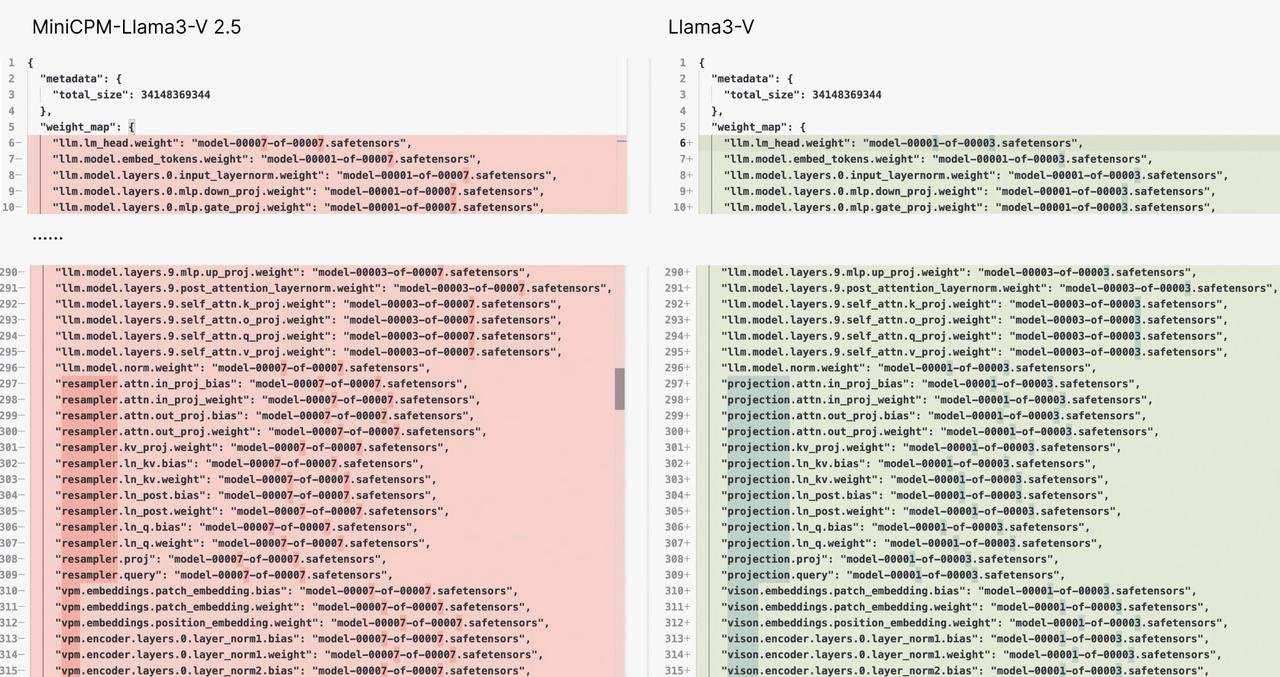
Evidência um:
A estrutura do modelo e o código do Llama3-V e do MiniCPM-Llama3-V 2.5 são quase semelhantes no nível de copiar e colar. A diferença é provavelmente que eles mudaram o colete – os nomes das variáveis foram alterados.
É como se fosse o mesmo vestido, mas com botões de cores diferentes. Você acha que é coincidência?
Evidência dois:
Quando os autores do Llama3-V foram questionados por que poderiam usar o tokenizer MinicPM-Llama3-V2.5 que ainda não havia sido lançado com antecedência, eles explicaram que estavam usando o projeto MinicPM-V-2 da geração anterior de Wall-Facing Inteligência.
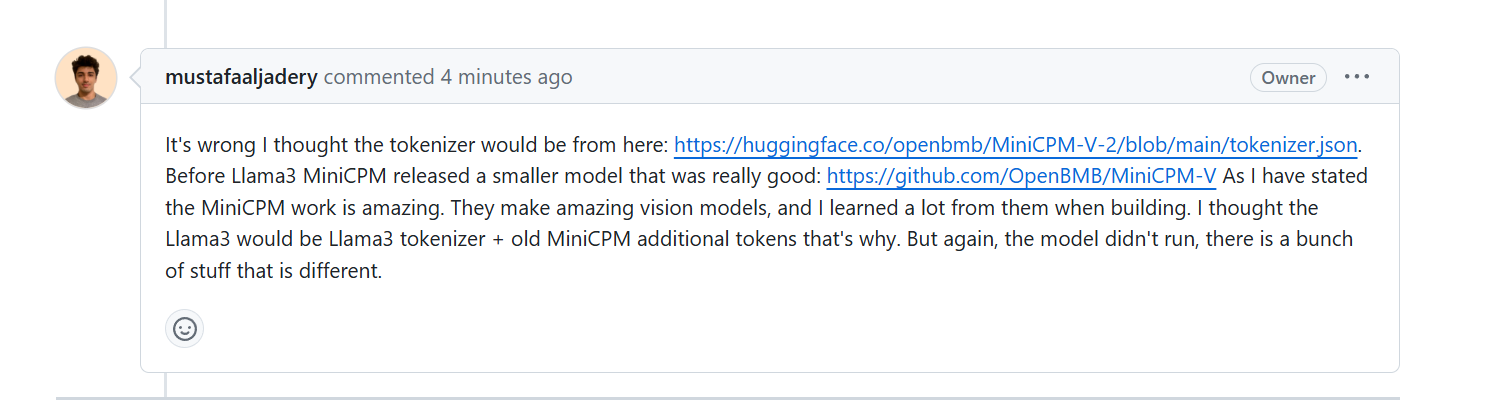
No entanto, alguns meios de comunicação buscaram a confirmação dos funcionários da Wallface Intelligence. No HuggingFace, os segmentadores de palavras MiniCPM-V2 e MiniCPM-Llama3-V 2.5 são dois arquivos, respectivamente, e os tamanhos dos arquivos são completamente diferentes.
Além do mais, o tokenizer do MiniCPM-Llama3-V 2.5 é composto pelo tokenizer Llama3 mais o token especial do modelo da série MiniCPM-V.
Considerando que o MiniCPM-V2 foi lançado antes do Llama3, é teoricamente impossível incluir a tecnologia tokenizer Llama3 que ainda não foi divulgada.
Evidência três:
O que é ainda mais escandaloso é que quando o autor do projeto llama3-V enfrentou as dúvidas dos usuários e viu que algo não estava indo bem, ele simplesmente fez um bom show de “deletar a biblioteca e fugir”.
Até a página do projeto no GitHub foi removida, o que pode ser chamado de enganosa versão 2.0.
O endereço do Hugging Face é o seguinte. Atualmente, quando abrimos a página, só podemos ver “404”.
https://huggingface.co/mustafaaljadery/llama3v/commit/3bee89259ecac051d5c3e58ab619e3fafef20ea6
Isto ainda não acabou, mais evidências estão surgindo:
O usuário X @ yangzhizheng1 disse que se o ruído gaussiano (parametrizado por um único escalar) for adicionado ao ponto de verificação do MiniCPM-Llama3-V 2.5, o modelo resultante será esculpido no mesmo molde do Llama3-V.
Além disso, este modelo também pode reconhecer os profundos escritos antigos do Período dos Reinos Combatentes, como os "Deslizamentos de Tsinghua", e os erros são exatamente os mesmos. Nas palavras oficiais da Wall-Facing Intelligence:
Eles não apenas estão certos, mas também errados.

Você deve saber que esses dados de escrita antiga foram obtidos digitalizando e anotando manualmente as tiras de bambu de Tsinghua coletadas pela Universidade de Tsinghua durante vários meses.
Então, como a equipe de IA de Stanford tirou isso do nada?
Pode-se dizer que a declaração da Wallface Intelligence na madrugada de 2 de junho pode ser considerada um plágio completo da equipe de pesquisa de IA de Stanford.
Até esta manhã, Siddharth Sharma e Aksh Garg, dois autores da equipe Stanford Llama3-V, pediram desculpas formalmente à equipe MiniCPM por esta má conduta acadêmica na plataforma social X, dizendo que todos os modelos Llama3-V seriam removidos.
Os melhores alunos de escolas famosas também plagiam? Os grandes modelos de código aberto da China estão se aproximando
Uma razão importante pela qual esse assunto causou polêmica na Internet é que a formação do plagiador é tão glamorosa.
Informações públicas mostram que Siddharth Sharma e Aksh Garg são estudantes de graduação do Departamento de Ciência da Computação da Universidade de Stanford e publicaram muitos artigos na área de aprendizado de máquina. Entre eles, Siddharth Sharma estagiou na Amazon por um período de tempo e atualmente está principalmente envolvido em IA e trabalhos relacionados a dados.
O currículo de estágio de Aksh Garg é rico, abrangendo organizações conhecidas como SpaceX, Universidade de Stanford e Instituto de Tecnologia da Califórnia.
Quanto a Mustafa Aljadery, chamado de "portador do código" pelos dois autores acima mencionados, ele se formou na Universidade do Sul da Califórnia. Após a fermentação da opinião pública, a conta X foi definida como privada.

Internautas atentos não aceitaram o pedido de desculpas da equipe Stanford Llama3-V.
Por exemplo, o
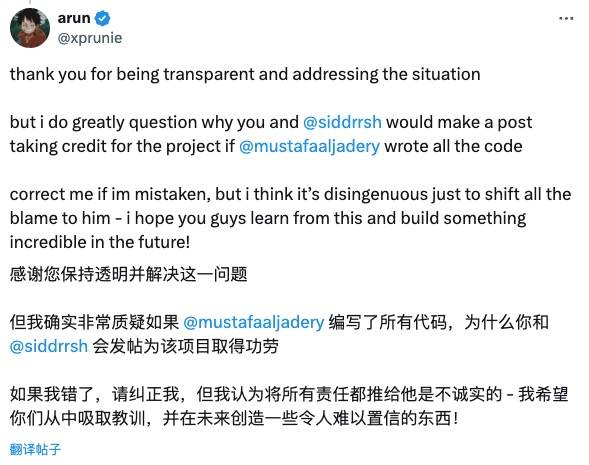
Christopher David Manning, diretor do Stanford AI Laboratory, também se levantou para condenar esse plágio e elogiou o MiniCPM, um excelente modelo chinês de código aberto.
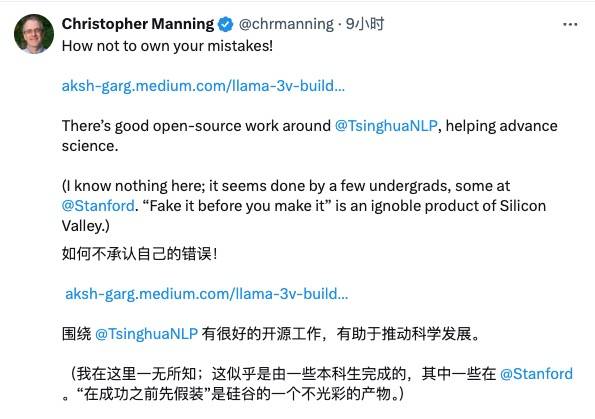
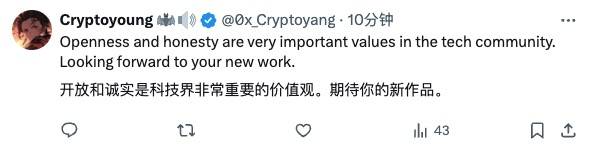
No entanto, também existem internautas que mantêm a atitude de “perdoar os outros quando você tem que lhes dar misericórdia” e os encorajam sem pressa:
Abertura e honestidade são valores muito importantes no mundo da tecnologia e estou ansioso pelo seu novo trabalho.
O pesquisador do Google DeepMind, Lucas Beyer, disse que os grandes modelos de código aberto da China têm bons modelos como o MiniCPM, mas a comunidade internacional não lhes deu atenção suficiente…

A equipe Wall-Facing Intelligence também respondeu a este assunto ontem.
Li Dahai, CEO da Face-Wall Intelligence, disse: "A inovação tecnológica não é fácil. Cada trabalho é o resultado dos esforços dia e noite da equipe. É também uma contribuição sincera para o progresso tecnológico e o desenvolvimento inovador em todo o mundo com poder de computação limitado.
Esperamos que o bom trabalho da equipe seja notado e reconhecido por mais pessoas, mas não desta forma. "

Liu Zhiyuan, cientista-chefe da Wall-Facing Intelligence, também postou no Zhihu, dizendo que este incidente provou a influência internacional das conquistas inovadoras da China de outra perspectiva, enfatizando a importância do compartilhamento de código aberto e do respeito pelo espírito de originalidade.
É preciso dizer que esse drama do plágio no círculo da IA é uma explicação clássica de que "a inovação não é fácil, deve ser feita e valorizada, a integridade acadêmica é responsabilidade de todos".
Você sabe, se você imitar a forma do código, não poderá copiar a graça original.
Na verdade, desde o ano passado, os grandes modelos da China têm sido de código aberto como cogumelos depois de uma chuva de primavera. Eles passaram de beneficiários a contribuintes e não são mesquinhos em fornecer resultados de código aberto mais notáveis ao mundo.
De gigantes como Alibaba e Tencent à inteligência voltada para a parede, startups de IA como Zhipu AI e Kunlun Tiangong também são membros ativos da comunidade de código aberto, contribuindo para o desenvolvimento de modelos de grande escala da China.
Esperamos também que esta brisa primaveril de abertura e partilha sopre mais forte.
Tal como Li Dahai, CEO da Face Wall Intelligence, apela a que todos trabalhem em conjunto para construir um ambiente comunitário aberto, cooperativo e de confiança. Vamos, trabalhem juntos para tornar o mundo um lugar melhor com a chegada da AGI!
# Bem-vindo a seguir a conta pública oficial do WeChat do aifaner: aifaner (WeChat ID: ifanr). Mais conteúdo interessante será fornecido a você o mais rápido possível.
