
A Doubao acaba de lançar vários modelos grandes: tornando o DeepSeek mais útil, e a versão em áudio do Sora surpreendeu o público.

Tenho que dizer, estamos em 2025 e, quando faço uma pergunta à IA, a experiência geralmente é polarizada.
Ele responde a perguntas simples em segundos, mas é como se elas não tivessem sido respondidas.
Coisas complexas exigem que você pense profundamente, e levará mais de 30 segundos para ponderar.
E com cada resposta, a IA está constantemente "queimando" tokens.
Para as empresas, o consumo de tokens equivale diretamente ao custo. Embora os modelos que permitem aprendizado profundo possam melhorar significativamente o desempenho, a latência aumenta, o consumo de tokens aumenta e os custos disparam.
Este é um ponto problemático para todo o setor.
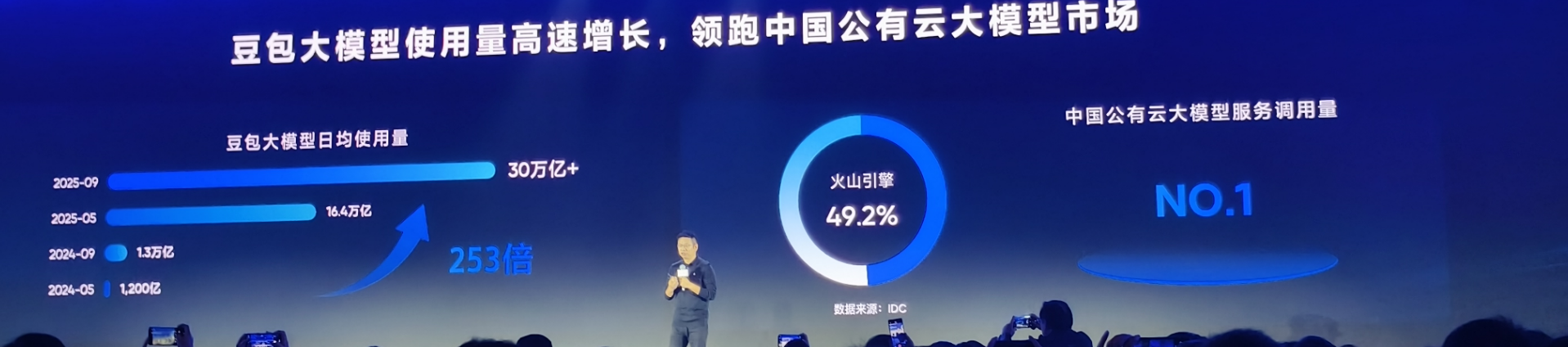
Com o aumento do número de aplicações de IA, o consumo de tokens também está disparando. Por exemplo, o modelo Doubao viu seu uso médio diário de tokens ultrapassar 30 trilhões no final de setembro, um aumento de mais de 80% em relação ao final de maio. E isso representa apenas uma parcela do mercado.
Com a demanda por IA crescendo nesse ritmo, a escolha é economizar dinheiro usando modelos leves com baixo desempenho ou investir para garantir o desempenho com modelos de ponta. A questão é: qual priorizar o desempenho ou o custo?
Em 16 de outubro, a Volcano Engine usou quatro novos produtos no FORCE LINK AI Innovation Tour em Wuhan para dizer a você: somente as crianças fazem escolhas.
O modelo grande Doubao 1.6 suporta nativamente ajuste de comprimento de pensamento de 4 níveis, o Doubao 1.6 lite corta o custo pela metade e melhora o efeito, e também há o modelo de síntese de fala Doubao 2.0 e o modelo de reprodução de som 2.0.
De acordo com um relatório da IDC, no primeiro semestre de 2025, a Volcano Engine conquistou uma participação de 49,2% no mercado de serviços de grande porte em nuvem pública da China, ficando firmemente em primeiro lugar.
Qual conceito?
Para cada duas empresas que usam grandes modelos na nuvem, uma usa o Volcano Engine.
Na coletiva de imprensa de hoje, foi mencionado que, embora o Modo de Pensamento Profundo possa melhorar o desempenho em 31%, o uso real é de apenas 18% devido à latência, ao aumento de custos e ao consumo exorbitante de tokens. Para ser franco, as empresas querem usá-lo, mas simplesmente não podem pagar.
Para resolver esse problema, o Doubao Big Model 1.6, recentemente atualizado, oferece quatro níveis de duração de pensamento: Mínimo, Baixo, Médio e Alto.
Este é o primeiro modelo na China que suporta nativamente "ajuste gradual do comprimento do pensamento".
Como entender isso?
É como instalar uma “caixa de engrenagens” para IA: para consultas simples, use o modo Mínimo para economizar tokens e, para raciocínios complexos, mude para o modo Alto para manter o efeito.
As empresas podem equilibrar de forma flexível os efeitos, a latência e os custos de acordo com o cenário, e pensar que a eficiência é ainda mais aprimorada.
Tomemos como exemplo o modo de pensamento de baixo nível.
Comparado com o modo de pensamento único antes da atualização, os tokens de produção total foram cortados diretamente em 77,5% e o tempo de pensamento caiu em 84,6%.
O efeito? Permanecerá inalterado.
Quando o custo de cada token pode ser controlado com precisão, quanto mais você compra, mais você economiza; quanto mais detalhada for a otimização, mais você ganha.
A Volcano Engine também lançou o modelo grande Doubao 1.6 lite, que é mais leve e tem velocidade de inferência mais rápida que o modelo principal.
Em termos de desempenho, este modelo supera o Doubao 1.5 pro, com uma melhoria de 14% na avaliação de cenários de nível empresarial.
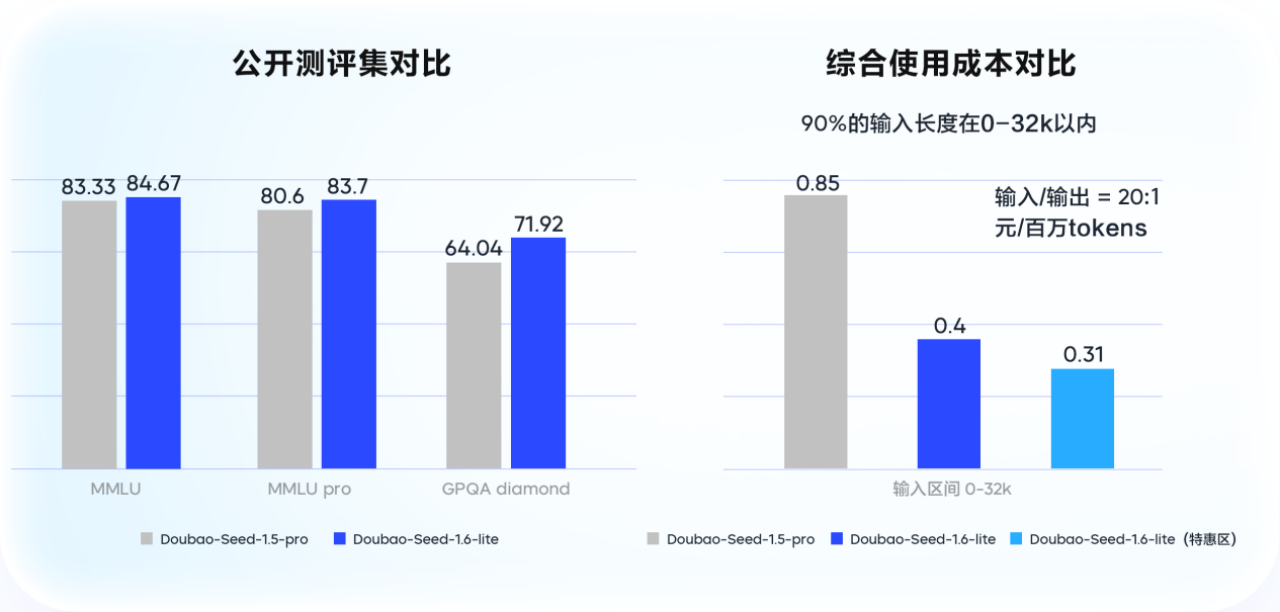
Em termos de custo, na faixa de entrada de 0-32k, o custo de uso abrangente é reduzido em 53,3% em comparação com o Doubao 1.5 pro.
O efeito é melhor e o custo é reduzido pela metade.
Esse aumento na "densidade de valor do token unitário" significa essencialmente que cada centavo é gasto com sabedoria.
Na conferência, a Volcano Engine também lançou o modelo de síntese de fala Doubao 2.0 e o modelo de reprodução de som 2.0.
A voz está se tornando o principal método de interação para aplicativos de IA.
Mas o que é mais notável do que sua expressão emocional mais forte ou seu seguimento mais preciso de instruções é que eles finalmente conseguem recitar fórmulas complexas com precisão.
Isso pode parecer insignificante, mas no ambiente educacional, ler em voz alta fórmulas e símbolos complexos sempre foi um problema difícil no setor.
Atualmente, a precisão de leitura de modelos similares no mercado é geralmente inferior a 50%.
Após a otimização direcionada dos dois modelos de voz recém-lançados, a taxa de precisão na recitação de fórmulas complexas em todas as disciplinas, do ensino fundamental ao ensino médio, subiu para 90%.

Por trás disso está uma nova arquitetura de síntese de fala desenvolvida com base no modelo de linguagem grande Doubao, que permite que sons sintetizados e reproduzidos tenham capacidades profundas de compreensão semântica e também expande as capacidades de raciocínio contextual.
A IA não converte mais texto em som sem pensar, mas primeiro "entende" o conteúdo e então "expressa emoções com precisão".
Os usuários podem usar linguagem natural para ajustar com precisão a velocidade da fala, a emoção, a voz, o tom e as mudanças de estilo, maximizando a controlabilidade da voz.
Quer algo mais suave? "Algo suave."
Quer ficar mais animado? "Leia com entusiasmo."
Na coletiva de imprensa, a Volcano Engine mostrou uma demonstração muito interessante:
Um livro ilustrado infantil foi criado com o tema da proteção do pato-de-baer em Wuhan. O modelo de criação de imagens Doubao, Seedream 4.0, gerou as ilustrações, e o modelo de síntese de fala Doubao 2.0 forneceu a interpretação emocional.
Durante o processo, você também pode controlar o efeito de leitura em tempo real por meio de instruções.
Desde seu primeiro lançamento em maio do ano passado, a família de modelos de voz Doubao abrangeu sete áreas principais, incluindo síntese de fala, reconhecimento de fala, reprodução de som, fala em tempo real, interpretação simultânea, criação de música e criação de podcast, e foi conectada a mais de 460 milhões de terminais inteligentes.

Na coletiva de imprensa de hoje, Tan Dai destacou três grandes tendências de desenvolvimento em grandes modelos globais de IA:
Modelos de pensamento profundo estão sendo intensamente integrados a recursos de compreensão multimodal. Modelos de vídeo, imagem e voz estão gradualmente alcançando níveis de aplicação de nível de produção, e agentes complexos de nível empresarial estão amadurecendo.
Espere, vamos parar por um momento.
À medida que mais e mais modelos surgem, como escolhemos o modelo mais econômico ao enfrentar necessidades específicas?
Essa pode ser uma questão de autoanálise para muitas empresas.
A Volcano Engine lançou o Smart Model Router, a primeira solução na China para seleção inteligente de modelos.
A partir de hoje, os usuários podem selecionar a função "Smart Model Routing" no Volcano Ark.
Esta função suporta três modos: "Modo Balanceado", "Modo Prioridade de Efeito" e "Modo Prioridade de Custo", e pode selecionar automaticamente o modelo mais apropriado para solicitações de tarefas.

Por que isso é necessário?
Porque tarefas diferentes têm requisitos completamente diferentes para a "densidade de valor" dos tokens.
O sistema de atendimento ao cliente responde à pergunta "Como devolver um produto?" com um modelo leve.
Entretanto, quando se trata de diagnóstico médico e análise de casos, o modelo mais forte deve ser usado.
Embora o consumo de tokens seja o mesmo, a densidade de valor é muito diferente.
A essência do roteamento de modelo inteligente é deixar que a IA decida por si mesma "quantos tokens vale a pena queimar nesta tarefa".
Atualmente, o roteamento de modelo inteligente do Volcano Engine já oferece suporte a uma variedade de modelos tradicionais, incluindo Doubao, DeepSeek, Qwen e Kimi.
Tomemos como exemplo o DeepSeek, os dados medidos:
No modo de efeito primeiro, o efeito do modelo após o roteamento inteligente é melhorado em 14% em comparação ao uso direto do DeepSeek-V3.1.
No modo de custo em primeiro lugar, ao mesmo tempo em que obtém resultados semelhantes ao DeepSeek-V3.1, o custo geral do modelo pode ser reduzido em até 70%.
Quando a seleção do modelo é assumida pela IA, um ciclo de feedback positivo é formado em todo o setor:
Capacidades de modelo mais fortes desbloqueiam novos cenários de aplicação → A explosão de novas aplicações aumenta o consumo de tokens → O aumento no consumo força a otimização contínua do roteamento inteligente → A otimização do roteamento reduz ainda mais os custos unitários → Custos mais baixos liberam mais elasticidade da demanda → A liberação da demanda, por sua vez, aumenta o consumo geral.
Isso nos lembra de 1882, quando Edison construiu a primeira usina elétrica comercial do mundo. Ninguém poderia prever que a unidade "quilowatt-hora" daria origem a todo o sistema industrial moderno.
Hoje, os tokens estão se tornando os “quilowatts-hora” da era da IA.
A lista do "Trillion Token Club" anunciada recentemente pela OpenAI e os 130 trilhões de tokens queimados pelo Google todo mês confirmam o forte aumento da produtividade.
É claro que um bom modelo é apenas o ponto de partida, e uma boa experiência é o objetivo final.
Ao fazer uma pergunta à IA, você não precisa se preocupar se ela é rápida ou boa. O pensamento em camadas permite respostas instantâneas e precisas para perguntas simples, enquanto proporciona raciocínio profundo e eficiência para perguntas complexas.
Roteamento inteligente significa que você não precisa se preocupar com qual modelo escolher, a IA encontrará o mais adequado.
Usando linguagem natural, você pode controlar com precisão o modelo de fala, em vez de ficar sobrecarregado por uma infinidade de parâmetros. Cada iteração dessas tecnologias tem um único objetivo final: torná-la acessível e, mais importante, eficaz para os usuários.
Talvez seja assim que a IA deveria ser.
#Bem-vindo a seguir a conta pública oficial do WeChat do iFaner: iFaner (ID do WeChat: ifanr), onde mais conteúdo interessante será apresentado a você o mais breve possível.
