
A antropologia “destilou” a maior base de conhecimento da humanidade.

No início de 2024, em um armazém em algum lugar dos Estados Unidos, trabalhadores faziam algo que parecia bastante estranho: alimentavam uma máquina com livros, um a um, cortavam suas lombadas, escaneavam-nos e, em seguida, enviavam o papel restante para reciclagem.
Esses livros foram comprados recentemente, alguns até novos. Ninguém vai lê-los; o único propósito deles é serem destruídos.
A empresa que encomendou isso foi uma empresa de IA chamada Anthropic.

Em seus documentos internos, o projeto tinha o codinome "Projeto Panamá". Um documento de planejamento afirmava categoricamente: "Este é o nosso plano para digitalizar de forma destrutiva todos os livros do mundo, e não queremos que o mundo exterior saiba que estamos fazendo isso."
Com o tempo, as pessoas descobriram isso.
No ano passado, um juiz federal tornou públicos um conjunto de documentos relacionados a um processo de direitos autorais, totalizando mais de 4.000 páginas. O que o mundo exterior viu não foram apenas os segredos de uma empresa, mas a verdadeira face de toda a indústria de IA em sua guerra de dados.
Livros físicos "devorados" por modelos grandes
Por que essas gigantes da tecnologia de ponta tratariam os livros impressos de uma maneira tão primitiva e até brutal? A resposta está na extrema sede da IA por dados de alta qualidade.
A Anthropic percebeu desde cedo que o conteúdo online por si só era insuficiente para treinar modelos de IA.
Segundo o The Washington Post, um dos cofundadores da Anthropic escreveu em um documento de janeiro de 2023 que treinar modelos com livros poderia ensinar a IA "a escrever melhor", em vez de apenas imitar a linguagem inconsistente da internet.
O livro passou por uma rigorosa edição e revisão, e sua estrutura de conteúdo é clara. Trata-se de um corpus de alta qualidade, difícil de substituir por textos online.
A lógica em si não é difícil de entender, mas o problema é: se o valor dos livros é reconhecido, por que não pagar por eles? A razão é que negociar o licenciamento com editoras e autores individualmente é demorado, trabalhoso e caro. Assim, a Anthropic lançou o "Projeto Panamá". A declaração "Não queremos que o mundo exterior saiba" indica que a empresa também sabe que esse argumento é insustentável.
Mesmo antes do lançamento do "Projeto Panamá", a Anthropic já havia tentado adquirir livros por outro método.

Documentos judiciais mostram que o cofundador da empresa, Ben Mann, baixou um grande número de romances e livros de não ficção de um site chamado LibGen ao longo de 11 dias em junho de 2021. O LibGen é uma "biblioteca paralela" onde a maioria dos recursos é suspeita de infringir direitos autorais. Capturas de tela do navegador anexadas aos documentos mostram que ele usou um software de compartilhamento de arquivos para concluir esses downloads.
Um ano depois, outro site, o Pirate Library Mirror, foi lançado em julho de 2022, declarando abertamente que "viola deliberadamente as leis de direitos autorais na maioria dos países". Mann enviou o link para este site a outros funcionários da Anthropic, comentando: "Momento perfeito!!!"
Por trás desse ponto de exclamação, esconde-se a verdadeira atitude de um executivo da empresa em relação a um site pirata que admite abertamente violar a lei.
A Anthropic afirmou posteriormente que a empresa nunca usou esses dados para treinar seu modelo comercial lançado oficialmente. No entanto, essa explicação é um tanto frágil. Eles baixaram e salvaram os dados, mas "não os usaram no modelo oficial". Onde exatamente essa linha divisória é traçada provavelmente não está claro nem mesmo para a própria Anthropic.
Para o "Projeto Panamá", a Anthropic contratou especificamente Tom Turvey para liderar o trabalho. Turvey já havia participado da criação do projeto Google Books, que também gerou anos de disputas de direitos autorais devido à digitalização massiva de livros. É difícil dizer que a escolha de Turvey pela Anthropic para liderar este projeto tenha sido uma coincidência.
Em última análise, a Anthropic dependia principalmente de duas livrarias para o fornecimento em grande quantidade:
A livraria americana de livros usados Better World Books e a britânica World of Books costumam comprar dezenas de milhares de livros de uma só vez. Documentos internos também mostram que funcionários discutiram a possibilidade de entrar em contato com a Biblioteca Pública de Nova York e até mencionaram a busca por ajuda de uma nova biblioteca que sofria com falta de verbas há muito tempo.
Após a conclusão do processo de aquisição, toda a digitalização assemelhava-se a uma linha de montagem industrial.

O fornecedor utilizou uma cortadora hidráulica para aparar cuidadosamente as lombadas dos livros, e as páginas soltas foram então inseridas em um scanner industrial de alta velocidade. Após a digitalização, o papel restante foi entregue a uma empresa de reciclagem. Um dos fornecedores de serviços de digitalização que apresentou uma proposta afirmou que a Anthropic esperava concluir a digitalização de 500.000 a 2 milhões de livros em seis meses.
A vice-conselheira geral da Anthropic, Aparna Sridhar, respondeu que o tribunal havia decidido que o treinamento de IA era "de natureza transformadora" e que a decisão da Anthropic de fazer um acordo era problemática "em termos de como parte do material foi obtido, não se poderíamos usar esse material".
Esse argumento pode ser válido legalmente, mas também revela uma coisa: a empresa nunca acreditou ter feito nada de errado, apenas que alguns de seus métodos não eram suficientemente transparentes.
Eles usarão seus livros para treinamento e depois roubarão seu emprego.
O mesmo está acontecendo com outras empresas, e alguns detalhes são ainda mais dramáticos.
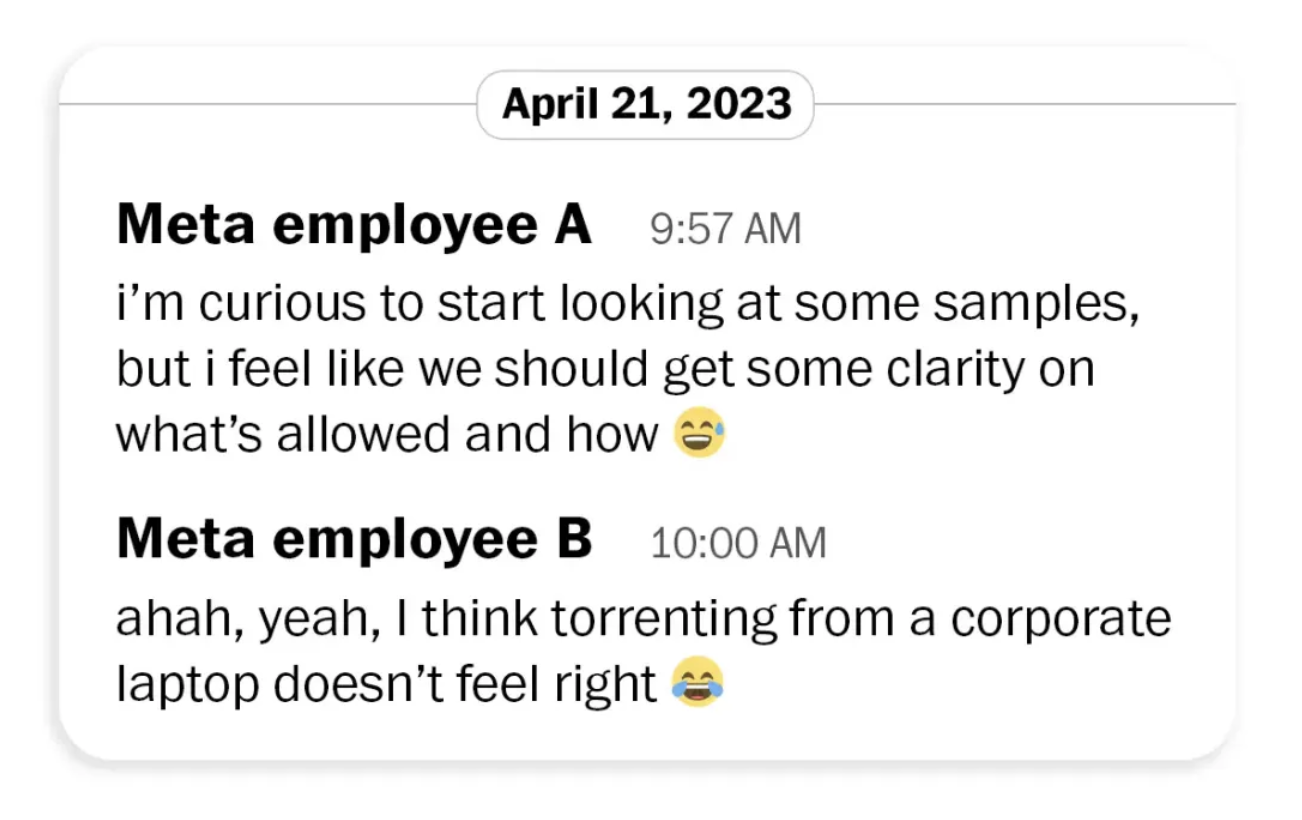
Documentos do processo contra a Meta mostram que um funcionário escreveu diretamente em 2023: "Não me parece certo usar o laptop da empresa para baixar torrents". Posteriormente, ele levantou essa questão especificamente com a equipe jurídica, afirmando que usar sites de torrents poderia significar distribuir obras pirateadas para outras pessoas, "o que pode não ser legalmente permitido".
Mas, no fim das contas, essas preocupações não mudaram nada.
Um e-mail interno de dezembro de 2023 revelou que o uso do LibGen havia sido aprovado após ser "relatado a MZ", referindo-se ao CEO Mark Zuckerberg. O e-mail também declarava abertamente os riscos dos quais estavam cientes: "Se reportagens da mídia sugerirem que usamos conjuntos de dados sabidamente pirateados, isso poderá enfraquecer nossa posição de negociação em questões regulatórias."
Em outras palavras, eles não desconheciam que o que estavam fazendo era errado; simplesmente estavam avaliando o custo de serem pegos. Para mitigar esse risco, os funcionários alugaram deliberadamente os servidores da Amazon para downloads de torrents em vez dos servidores da Meta, a fim de evitar serem rastreados até a Meta.
Tanto a OpenAI quanto a Microsoft enfrentam acusações de violação de direitos autorais por parte de autores de livros. A OpenAI chegou a admitir ter baixado o LibGen, mas alegou ter removido os arquivos antes do lançamento do ChatGPT.
O conflito de direitos autorais entre empresas de IA e criadores não começou com a Anthropic.
No início dos anos 2000, o Google realizou uma varredura em larga escala de acervos de bibliotecas, o que também desencadeou um processo judicial que durou uma década. Por fim, o tribunal decidiu que as ações do Google constituíam "uso justo", pois apenas forneciam trechos com o intuito de orientar os leitores na escolha dos livros, e não os substituindo.
Na época, esse veredicto pareceu razoável, mas vinte anos depois, ele serviu de escudo para toda a indústria de IA.
O Google Books é uma ferramenta de indexação, enquanto a IA generativa processa diretamente o conteúdo dos livros e gera textos, por vezes competindo diretamente com os autores. A natureza mudou, mas a lógica jurídica que invoca permanece a mesma, o que por si só já é digno de reflexão.

Em junho passado, o juiz federal William Alsup decidiu que o uso de livros pela Anthropic para treinar IA era legal, comparando o processo a um professor "treinando alunos para escrever boas redações". Embora essa analogia pareça branda, na realidade, os professores não treinam milhões de alunos simultaneamente, nem ganham bilhões de dólares com isso.
No fim das contas, a Anthropic optou por pagar um acordo recorde de US$ 1,5 bilhão, o maior da história em litígios de direitos autorais envolvendo inteligência artificial. Contudo, analisando mais a fundo, o resultado financeiro não foi um mau negócio. De acordo com a lei de direitos autorais dos EUA, o limite legal de indenização por obra é de US$ 150.000, enquanto este acordo equivale a aproximadamente US$ 3.000 por livro, apenas 2% do limite.
A compensação foi dividida igualmente entre o autor e a editora, mas esse acordo gerou controvérsia na comunidade de criadores.
Muitos autores acreditam que as editoras não fizeram o suficiente para proteger suas obras do uso indevido por IA, e mesmo assim receberam metade da indenização. Mais importante ainda, o acordo não exige que a Anthropic admita qualquer conduta ilegal, e a decisão judicial de que "o treinamento de IA constitui uso justo" permanece válida.

Em outras palavras, o que a Anthropic comprou por US$ 1,5 bilhão não foi apenas um acordo, mas também um endosso: podemos continuar fazendo isso. Alguns analistas apontam que, com esse precedente estabelecido, a violação de direitos autorais não é mais uma linha vermelha para as empresas de IA, mas sim um "pedágio" que pode ser incorporado aos custos antecipadamente.
Para muitos escritores, isso significa muito mais do que apenas um cheque. A renda anual mediana de um autor americano gira em torno de US$ 20.000, enquanto empresas de inteligência artificial, avaliadas em centenas de bilhões de dólares, utilizam amplamente seus trabalhos sem autorização, e a compensação que recebem posteriormente está muito abaixo do limite legal.
O que é ainda mais preocupante é que a IA está produzindo conteúdo textual em massa. Essa entrada maciça de textos de baixo custo no mercado está tornando ainda mais difícil ganhar a vida escrevendo. A IA é treinada usando livros escritos por humanos, mas o conteúdo produzido por ela está reduzindo o espaço disponível para que os humanos continuem escrevendo livros, criando um ciclo vicioso.
Os defensores dessa ideia têm sua própria lógica: a IA não armazena o conteúdo dos livros, mas sim extrai padrões linguísticos, o que se assemelha mais ao desenvolvimento da expressão pessoal após uma leitura extensa. Essa analogia não é totalmente desprovida de mérito, mas omite uma diferença crucial:
Uma pessoa lê um livro, mas não um milhão; enquanto a IA processa décadas de escrita humana em poucos meses e, em seguida, replica e reproduz esse conteúdo infinitamente a um custo marginal extremamente baixo. A escala altera a natureza, portanto, não é razoável equiparar as duas coisas.
Milhões de livros foram cortados, digitalizados e reciclados, resultando, por fim, em um acordo judicial. Esses livros já se foram há muito tempo. Enquanto isso, a IA continua escrevendo, e a uma velocidade cada vez maior. Este é talvez o aspecto mais perturbador de toda a história: ninguém pagou o preço pela destruição e pelo uso indiscriminado de livros para treinar IA.
Endereço de referência em anexo:
https://www.washingtonpost.com/technology/2026/01/27/anthropic-ai-scan-destroy-books/
#Siga a conta oficial do iFanr no WeChat: iFanr (ID do WeChat: ifanr), onde você encontrará conteúdo ainda mais interessante o mais breve possível.
