
A Nvidia, de forma incomum, se absteve de lançar placas gráficas, e Jensen Huang acaba de causar alvoroço com uma nova “bomba nuclear” de 2,5 toneladas. O DeepSeek também foi novamente alvo de críticas.

Esta é a primeira vez em cinco anos que a Nvidia não lança uma placa gráfica para o consumidor final na CES.
O CEO Jensen Huang caminhou até o centro do palco do NVIDIA Live, ainda vestindo a mesma jaqueta de couro de crocodilo brilhante do ano passado.

Diferentemente de sua palestra solo no ano passado, Jensen Huang teve uma agenda lotada em 2026, participando de três eventos em 48 horas, desde o NVIDIA Live até o Siemens Industrial AI Dialogue e a conferência Lenovo TechWorld.
Na última vez, ele lançou as placas gráficas da série RTX 50 na CES, mas desta vez, a inteligência artificial para física e a robótica se tornaram as novas protagonistas.
A plataforma de computação Vera Rubin foi lançada e, quanto mais você compra, mais você economiza.
Durante a conferência de imprensa, Huang, conhecido pelas suas brincadeiras, trouxe para o palco um rack de servidores de IA de 2,5 toneladas, apresentando assim o ponto alto do evento: a plataforma de computação Vera Rubin, nomeada em homenagem aos astrônomos que descobriram a matéria escura, com um único objetivo:
Acelere o treinamento de IA para levar a próxima geração de modelos ao mercado mais rapidamente.
Normalmente, a Nvidia tem uma regra de que cada geração de produtos modifica no máximo 1 ou 2 chips. Mas desta vez, Vera Rubin quebrou a convenção, redesenhando 6 chips de uma só vez e colocando-os em produção em larga escala.
A razão para isso é que, com a desaceleração da Lei de Moore, os métodos tradicionais de aprimoramento de desempenho não conseguem mais acompanhar o crescimento anual de dez vezes da taxa de crescimento dos modelos de IA. Portanto, a NVIDIA optou pelo "design colaborativo extremo" — inovando simultaneamente em todos os níveis de todos os chips e em toda a plataforma.

Esses 6 chips são:
1. CPU Vera:
– 88 núcleos personalizados NVIDIA Olympus
– Utiliza a tecnologia NVIDIA Space Multithreading, com suporte para 176 threads.
– Largura de banda NVLink C2C de 1,8 TB/s
– Memória do sistema de 1,5 TB (3 vezes maior que a do Grace)
– Largura de banda LPDDR5X de 1,2 TB/s
– 227 bilhões de transistores

2. GPU Rubin:
– A capacidade de inferência do NVFP4 é de 50 PFLOPS, o que representa 5 vezes a do seu antecessor, o Blackwell.
– Possui 336 bilhões de transistores, 1,6 vezes mais que a Blackwell.
– Equipado com o motor Transformer de terceira geração, ele pode ajustar dinamicamente a precisão de acordo com as necessidades do modelo Transformer.

3. Adaptador de rede ConnectX-9:
– Ethernet de 800 Gb/s baseado em SerDes PAM4 de 200G
– Acelerador programável de RDMA e caminho de dados
– Certificado pela CNSA e FIPS
– 23 bilhões de transistores

4. DPU BlueField-4:
– Um mecanismo completo desenvolvido especificamente para plataformas de armazenamento de IA de última geração.
– DPU de 800G Gb/s para SmartNICs e processadores de armazenamento
– Processador Grace de 64 núcleos emparelhado com ConnectX-9
– 126 bilhões de transistores

5. Chip de comutação NVLink-6:
– Conecta 18 nós de computação, suportando até 72 GPUs Rubin para serem executadas colaborativamente como uma única entidade.
– Na arquitetura NVLink 6, cada GPU pode atingir 3,6 TB por segundo de largura de banda de comunicação total.
– Utiliza SerDes de 400G, suporta In-Network SHARP Collectives, permitindo operações de comunicação agregadas dentro da rede comutada.

6. Chip de comutação Ethernet óptica Spectrum-6
– 512 canais, 200 Gbps por canal, permitindo transmissão de dados em alta velocidade.
– Tecnologia de fotônica de silício integrando o processo COOP da TSMC
– Equipado com ótica co-embalada
– 352 bilhões de transistores

Graças à profunda integração de seis chips, o sistema Vera Rubin NVL72 alcança uma melhoria de desempenho abrangente em relação à geração anterior da Blackwell.
Em tarefas de inferência NVFP4, o chip alcançou impressionantes 3,6 EFLOPS de poder computacional, uma melhoria de 5 vezes em relação à arquitetura Blackwell da geração anterior. No treinamento NVFP4, atingiu 2,5 EFLOPS, representando uma melhoria de desempenho de 3,5 vezes.
Em termos de capacidade de armazenamento, o NVL72 está equipado com 54 TB de memória LPDDR5X, três vezes mais que seu antecessor. A capacidade da HBM (Memória de Alta Largura de Banda) atinge 20,7 TB, um aumento de 1,5x. Quanto ao desempenho de largura de banda, a largura de banda da HBM4 atinge 1,6 PB/s, um aumento de 2,8x; a largura de banda Scale-Up atinge impressionantes 260 TB/s, representando um aumento de 2x.
Apesar dessa enorme melhoria de desempenho, o número de transistores aumentou apenas 1,7 vezes, chegando a 220 trilhões, o que demonstra a capacidade inovadora da tecnologia de fabricação de semicondutores.

Em termos de projeto de engenharia, Vera Rubin também trouxe avanços tecnológicos.
Os nós de supercomputação anteriores exigiam 43 cabos, levavam 2 horas para serem montados e eram propensos a erros. Agora, o nó Vera Rubin usa 0 cabos, possui apenas 6 linhas de refrigeração líquida e pode ser montado em 5 minutos.
Mais impressionante ainda é o fato de a parte traseira do rack estar coberta por quase 3,2 quilômetros de cabos de cobre. Cinco mil cabos de cobre formam a rede backbone da NVLink, atingindo uma velocidade de transmissão de 400 Gbps. Nas palavras de Huang: "Pode pesar várias centenas de quilos. É preciso ser um CEO em ótima forma para fazer esse trabalho."
No mundo da IA, tempo é dinheiro. Uma estatística fundamental é que Rubin precisa de apenas 1/4 do número de parâmetros para treinar um modelo com 10 trilhões de parâmetros, e o custo de geração de um token é cerca de 1/10 do custo de Blackwell.
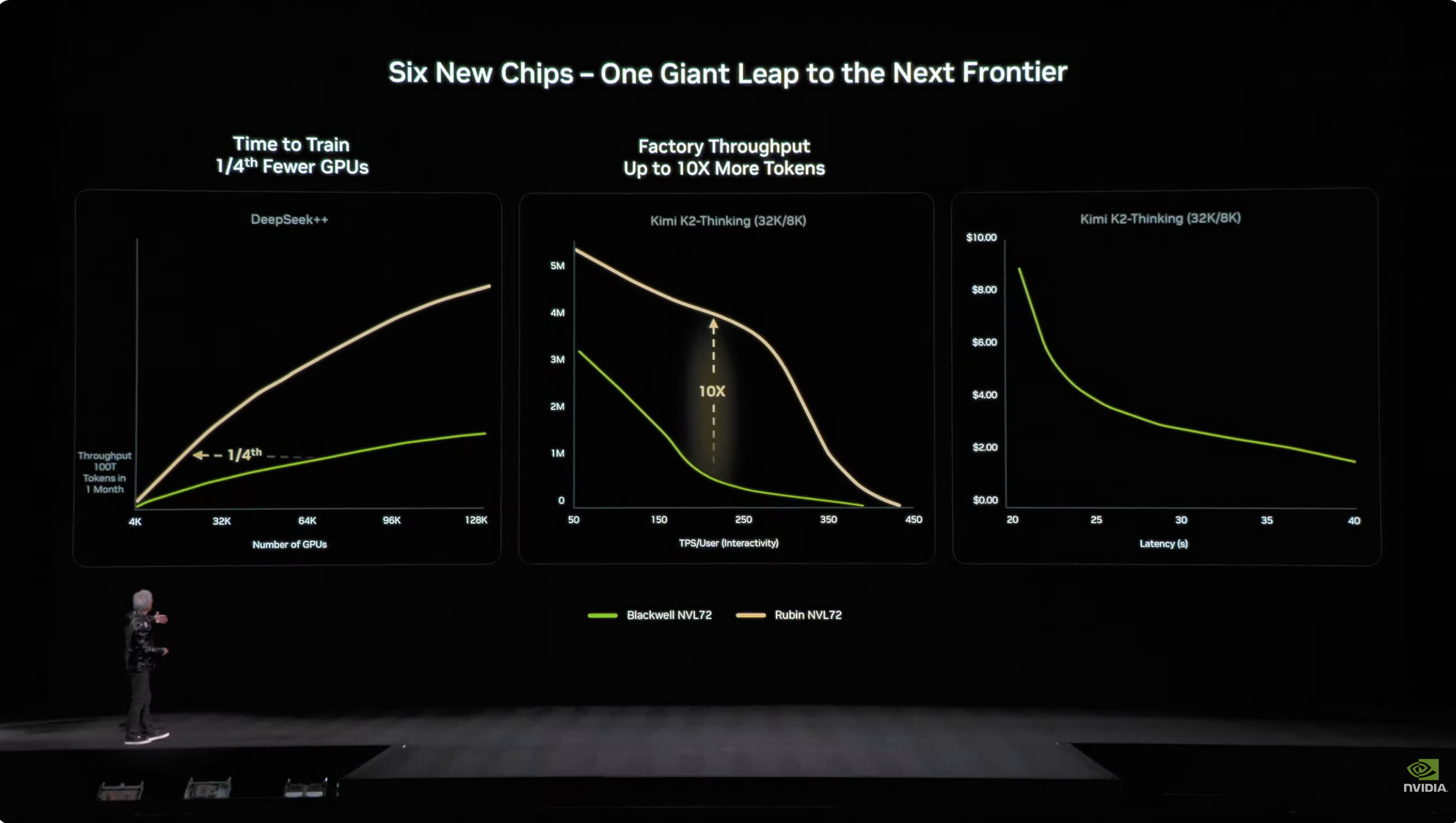
Além disso, embora Rubin consuma o dobro da energia de Grace Blackwell, sua melhoria de desempenho supera em muito o aumento no consumo de energia, com uma melhoria geral no desempenho de inferência de 5 vezes e uma melhoria no desempenho de treinamento de 3,5 vezes.
Mais importante ainda, a Rubin oferece um aumento de 10 vezes na capacidade de processamento (número de tokens de IA por watt – por dólar) em comparação com a Blackwell, o que se traduz em uma duplicação do potencial de receita para um data center de gigawatts de US$ 50 bilhões.
O maior problema enfrentado pela indústria de IA no passado tem sido a insuficiência de memória contextual. Especificamente, a IA gera um "cache KV" (cache de chave-valor) durante o funcionamento, que funciona como sua "memória de trabalho". O problema é que, à medida que os diálogos se tornam mais longos e os modelos mais complexos, a memória HBM (Head-Based Memory) se torna cada vez mais inadequada.

No ano passado, a Nvidia lançou a arquitetura Grace-Blackwell para expandir a memória, mas ela ainda era insuficiente. A solução de Vera Rubin envolve a implantação de processadores BlueField-4 dentro do rack para gerenciar especificamente o cache KV.
Cada nó está equipado com 4 BlueField-4s, cada um com 150 TB de memória de contexto. Quando alocada às GPUs, cada GPU recebe 16 TB adicionais de memória — enquanto a memória integrada da GPU é de apenas cerca de 1 TB. Crucialmente, a largura de banda permanece em 200 Gbps, portanto a velocidade não é comprometida.
Mas a capacidade por si só não basta. Para que as "notas" distribuídas por dezenas de racks e dezenas de milhares de GPUs funcionem em conjunto como um único módulo de memória, a rede precisa ser "grande o suficiente, rápida o suficiente e estável o suficiente". É aí que entra o Spectrum-X.
Spectrum-X é a primeira plataforma de rede Ethernet de ponta a ponta do mundo da NVIDIA, "projetada especificamente para IA generativa". A última geração do Spectrum-X utiliza o processo COOP da TSMC e integra tecnologia de fotônica de silício, com 512 canais e velocidade de 200 Gbps.
Huang fez as contas: um centro de dados de um gigawatt custa US$ 50 bilhões, e o Spectrum-X pode proporcionar um aumento de 25% na capacidade de processamento, o que equivale a uma economia de US$ 5 bilhões. "Pode-se dizer que este sistema de rede é praticamente um 'presente'."
Em termos de segurança, a Vera Rubin também oferece suporte à Computação Confidencial. Todos os dados são criptografados durante todo o processo de transmissão, armazenamento e computação, incluindo todos os barramentos, como canais PCIe, NVLink e comunicação CPU-GPU.
As empresas podem implantar seus modelos em sistemas externos com confiança, sem se preocupar com vazamentos de dados.
DeepSeek chocou o mundo; código aberto e agentes inteligentes são a tendência dominante na IA.
Após o evento principal, voltemos ao início do discurso. Huang Renxun revelou imediatamente um número surpreendente ao subir ao palco: os aproximadamente 10 trilhões de dólares em recursos computacionais investidos na última década estão sendo completamente modernizados.
Mas não se trata apenas de uma atualização de hardware; é mais uma mudança nos paradigmas de software. Ele mencionou especificamente modelos inteligentes e agentes, citando o Cursor, que mudou completamente a forma como a Nvidia programa internamente.

O que realmente incendiou o ambiente foi o seu grande elogio à comunidade de código aberto. Huang Renxun afirmou francamente que o sucesso do DeepSeek V1 no ano passado surpreendeu o mundo; como o primeiro sistema de inferência de código aberto, ele desencadeou diretamente uma onda de desenvolvimento em toda a indústria. Na apresentação em PowerPoint, os conhecidos desenvolvedores chineses Kimi k2 e DeepSeek V3.2 foram listados como o primeiro e o segundo projetos de código aberto, respectivamente.
Huang acredita que, embora os modelos de código aberto possam estar atualmente cerca de seis meses atrasados em relação aos modelos mais avançados, um novo modelo surgirá a cada seis meses.
Esse ritmo acelerado de iteração é algo que startups, gigantes e pesquisadores, incluindo a Nvidia, estão ansiosos para acompanhar.
Dessa vez, eles não se limitaram a vender pás e promover placas de vídeo; a Nvidia construiu o supercomputador DGX Cloud, avaliado em bilhões de dólares, e desenvolveu modelos de ponta como La Proteina (síntese de proteínas) e OpenFold 3.

▲ O ecossistema de modelos de código aberto da NVIDIA abrange biomedicina, IA física, modelos de agentes inteligentes, robótica e direção autônoma, entre outros.
Os múltiplos modelos de código aberto da família Nemotron da NVIDIA também foram um destaque da apresentação. Entre eles, estão modelos de código aberto que abrangem fala, multimodalidade, aprimoramento da geração de recuperação de informações e segurança, entre outros. Huang Renxun também mencionou que os modelos de código aberto Nemotron apresentam excelente desempenho em diversas listas de benchmarks e estão sendo adotados por um grande número de empresas.
O que é IA aplicada à física? Dezenas de modelos lançados de uma só vez.
Se os grandes modelos de linguagem resolveram os problemas do "mundo digital", a próxima ambição da Nvidia é claramente conquistar o "mundo físico". Jensen Huang mencionou que os dados são extremamente escassos para que a IA compreenda as leis da física e sobreviva na realidade.
Além do modelo de agente inteligente de código aberto Nemotron, ele propôs uma arquitetura central de "três computadores" para a construção de IA física.
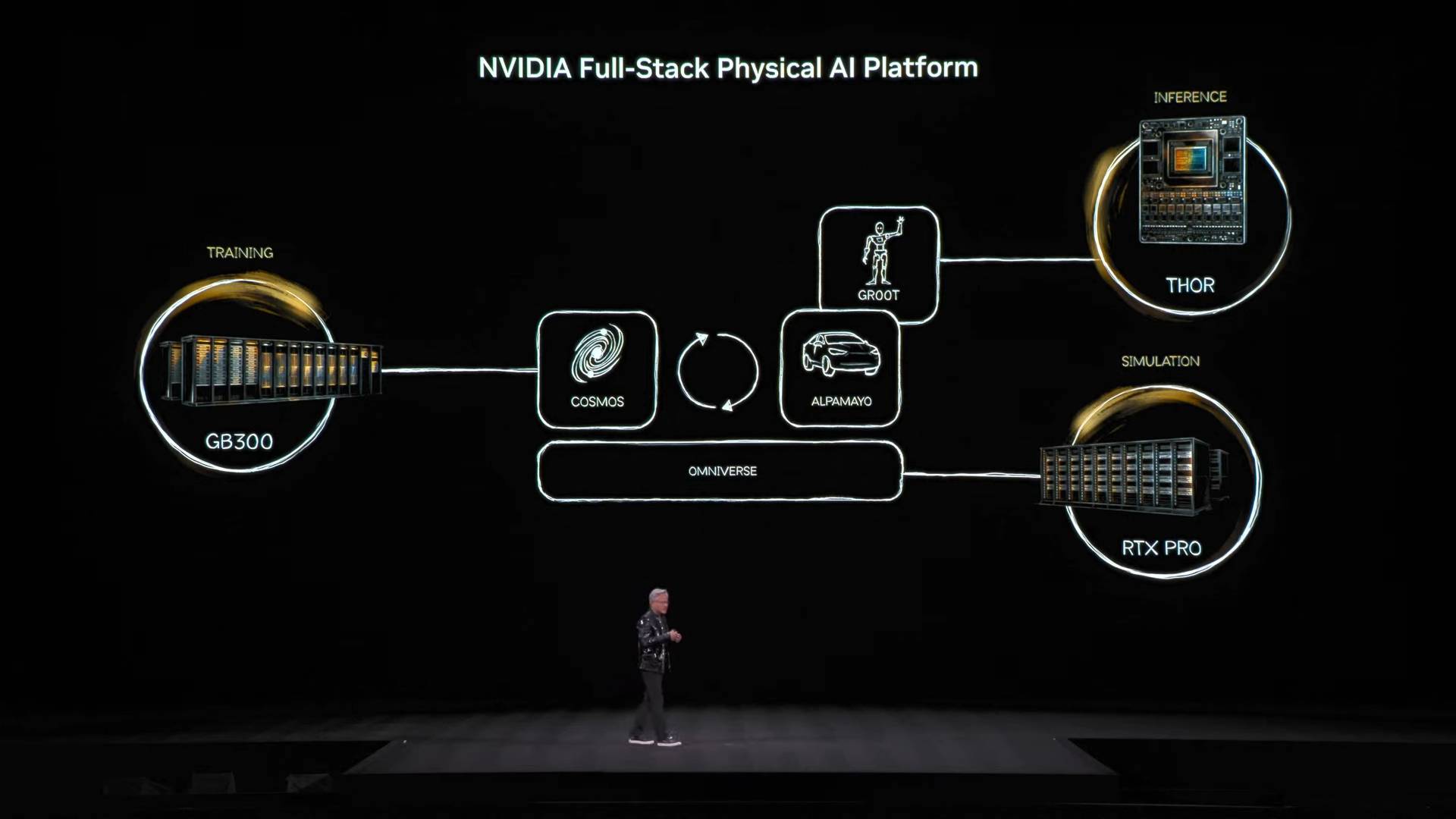
- Computadores de treinamento, que são o que conhecemos como computadores construídos com várias placas gráficas de nível educacional, como a arquitetura GB300 mencionada na imagem.
- Os computadores de inferência, o "cerebelo" que funciona na borda de um robô ou carro, são responsáveis pela execução em tempo real.
- Computadores de simulação, incluindo Omniverse e Cosmos, fornecem um ambiente de treinamento virtual para IA, permitindo que ela aprenda o feedback físico em uma simulação.

▲ O sistema Cosmos pode gerar um grande número de ambientes físicos de treinamento de IA.
Com base nessa arquitetura, Jensen Huang lançou oficialmente o Alpamayo, que surpreendeu o público e se tornou o primeiro modelo de direção autônoma do mundo com capacidades de pensamento e raciocínio.

Ao contrário dos sistemas tradicionais de condução autônoma, o Alpamayo é um sistema totalmente treinado. Seu grande diferencial está em resolver o "problema da cauda longa" da condução autônoma. Diante de condições de estrada complexas e inéditas, o Alpamayo não apenas executa códigos rigidamente, mas consegue raciocinar como um motorista humano.
"Ele te diz o que fazer em seguida e por que tomou essa decisão." Na demonstração, o veículo dirigiu de forma notavelmente natural, simplificando cenários extremamente complexos em lógica básica.
Além da demonstração, tudo isso não é apenas teórico. Jensen Huang anunciou que o Mercedes-Benz CLA equipado com a tecnologia Alpamayo será lançado oficialmente nos Estados Unidos no primeiro trimestre deste ano, seguido pelo lançamento nos mercados europeu e asiático.

Este carro foi considerado o mais seguro do mundo pelo NCAP, graças ao design exclusivo de "dupla camada de segurança" da NVIDIA. Quando o modelo de IA de ponta a ponta não tem confiança nas condições da estrada, o sistema retorna imediatamente a um modo de proteção de segurança tradicional e mais confiável para garantir segurança absoluta.
Na conferência de imprensa, Huang também apresentou especificamente a estratégia de robótica da Nvidia.
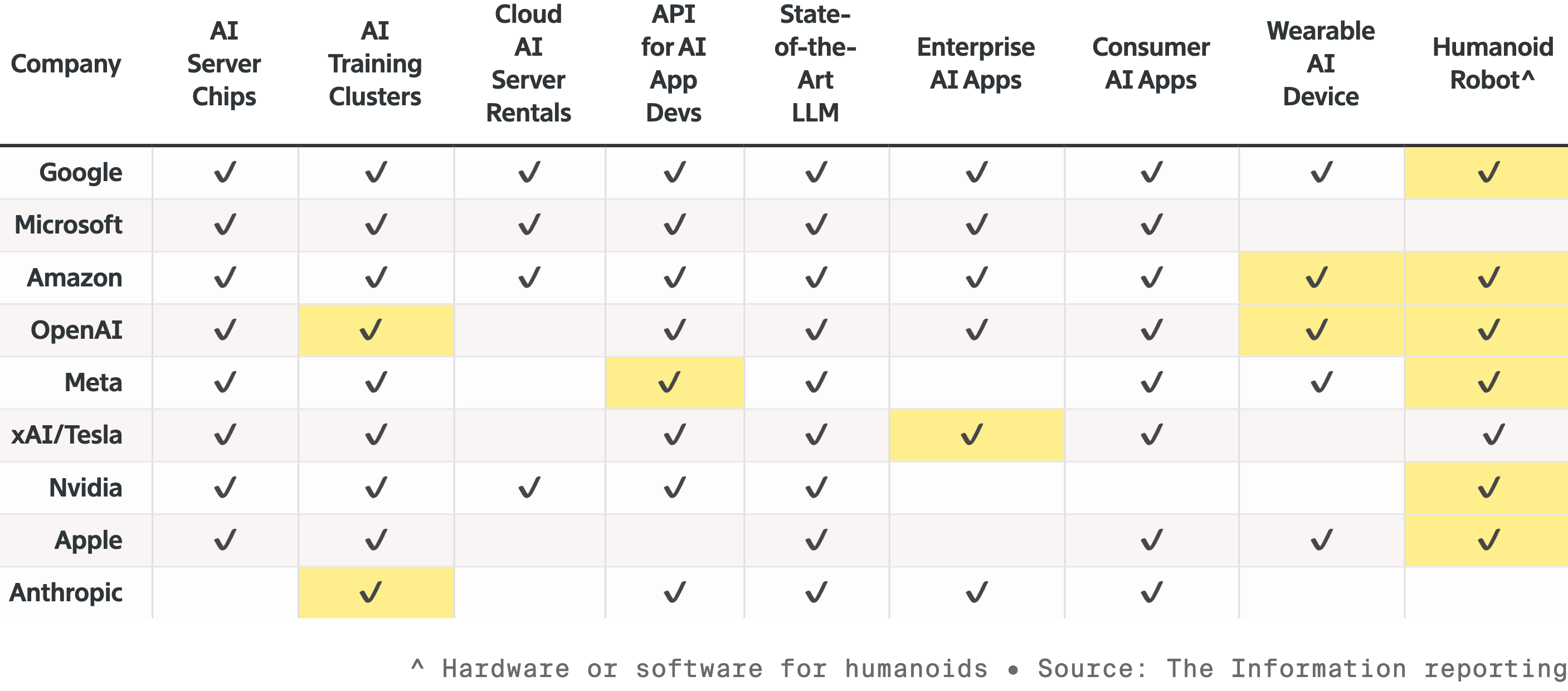
▲A competição entre nove dos principais fabricantes de IA e hardware relacionado, todos expandindo suas linhas de produtos, especialmente na disputa por uma fatia do mercado de robótica. As células destacadas representam novos produtos lançados desde o ano passado.
Todos os robôs serão equipados com minicomputadores Jetson e treinados no simulador Isaac, na plataforma Omniverse. A NVIDIA também está integrando essa tecnologia em sistemas industriais de empresas como Synopsys, Cadence e Siemens.

▲ Jensen Huang convidou robôs humanoides e robôs quadrúpedes de empresas como Boston Dynamics e Agility para "subirem ao palco". Ele enfatizou que o maior robô é, na verdade, a própria fábrica.
A visão da NVIDIA é que, partindo da base, o design de chips, o design de sistemas e a simulação de fábrica do futuro serão acelerados pela IA Física da NVIDIA. No evento de lançamento, os robôs da Disney fizeram mais uma aparição deslumbrante, levando Jensen Huang a comentar, em tom de brincadeira, sobre esses adoráveis robôs:
"Você será projetado em computadores, fabricado em computadores e até mesmo testado e validado em computadores antes de realmente enfrentar a gravidade."

Se você não soubesse que se tratava de Huang Renxun, poderia confundir todo o discurso de abertura com o lançamento de um produto de uma fabricante de modelos.
No atual contexto de teorias da bolha da IA, além da desaceleração da Lei de Moore, Jensen Huang parece precisar demonstrar o que a IA realmente pode fazer para aumentar a confiança de todos nessa tecnologia.
Além de demonstrar o poderoso desempenho da nova plataforma de supercomputação de IA, Vera Rubin, para satisfazer a sede por poder computacional, ele também dedicou mais esforços do que nunca a aplicativos e softwares, buscando mostrar as mudanças intuitivas que a IA trará.
Além disso, como disse Huang Renxun, no passado eles criaram chips para o mundo virtual e agora também os estão demonstrando pessoalmente, concentrando sua atenção na IA física representada pela direção autônoma e robôs humanoides, e entrando no mundo físico real, onde a competição do setor é mais intensa.
Afinal, a venda de armas só pode continuar se houver uma guerra.
Por Mo Chongyu, Zhang Zihao e Yao Tong
#Siga a conta oficial do iFanr no WeChat: iFanr (ID do WeChat: ifanr), onde você encontrará conteúdo ainda mais interessante o mais breve possível.
