
Nessa lista de projetos de código aberto “do mais popular ao menos popular”, finalmente entendi por que a IA chinesa conseguiu ressurgir.
Nos últimos dias, uma lista de níveis para um modelo de código aberto tem circulado amplamente no X.

▲ Fonte da imagem: https://www.interconnects.ai/p/2025-open-models-year-in-review
Do topo à base, os modelos de código aberto desenvolvidos internamente estão entre os melhores, com DeepSeek, Qwen, Kimi, Zhipu e MiniMax sendo os cinco melhores modelos globais de código aberto. A OpenAI, por outro lado, ocupa o quarto lugar. O Meta, de Zuckerberg, e o Llama, que ele tentou construir recrutando metade dos talentos do Vale do Silício, receberam apenas uma indicação honorária.
Este ranking não é resultado de publicidade paga por modelos desenvolvidos internamente, nem se trata de autopromoção chinesa. Um artigo publicado na Interconnectai pelo renomado pesquisador de IA Nathan Lambert e por Florian Brand, doutorando no Centro Alemão de Pesquisa em IA, apresenta um ranking completo de modelos de código aberto em todo o mundo.

▲Nathan Lambert trabalhou na Meta, DeepMind e Hugging Face.
O artigo apresenta uma análise detalhada do desenvolvimento de modelos globais de código aberto ao longo do último ano, destacando como os modelos nacionais de código aberto, principalmente o DeepSeek e o Qwen, estão mudando as regras de funcionamento de toda a indústria de IA por meio do código aberto .
De fato, 2024 ainda pode ser o ano do Llama para o código aberto global. Este ano, no entanto, o código aberto desenvolvido internamente tem causado um impacto significativo, redefinindo continuamente as opções padrão nos modelos globais de código aberto.
Desempenho, preço, ecossistema, usabilidade… está se aproximando rapidamente dos gigantes de código fechado em todas as dimensões, e até já os superou em alguns aspectos.

▲Histórico de lançamentos do modelo de código aberto EUA-China, janeiro de 2024 – novembro de 2025. Fonte da imagem: https://www.atomproject.ai/
Enquanto ainda nos perguntamos quando os modelos domésticos conseguirão alcançar o ChatGPT e o Gemini, outra questão começou a ganhar força na corrida armamentista da IA: por que desenvolvedores do mundo todo estão usando modelos domésticos de código aberto?
Modelo de código aberto, com participação tanto de empresas consolidadas quanto de novos participantes.
Nos últimos meses, o ritmo de atualizações para modelos de código aberto desenvolvidos internamente tem sido quase ininterrupto. E não se trata apenas do avanço de uma única empresa de modelos; é todo o ecossistema nacional de código aberto, continuamente expandindo os limites como uma curva ascendente, constantemente superando gargalos.
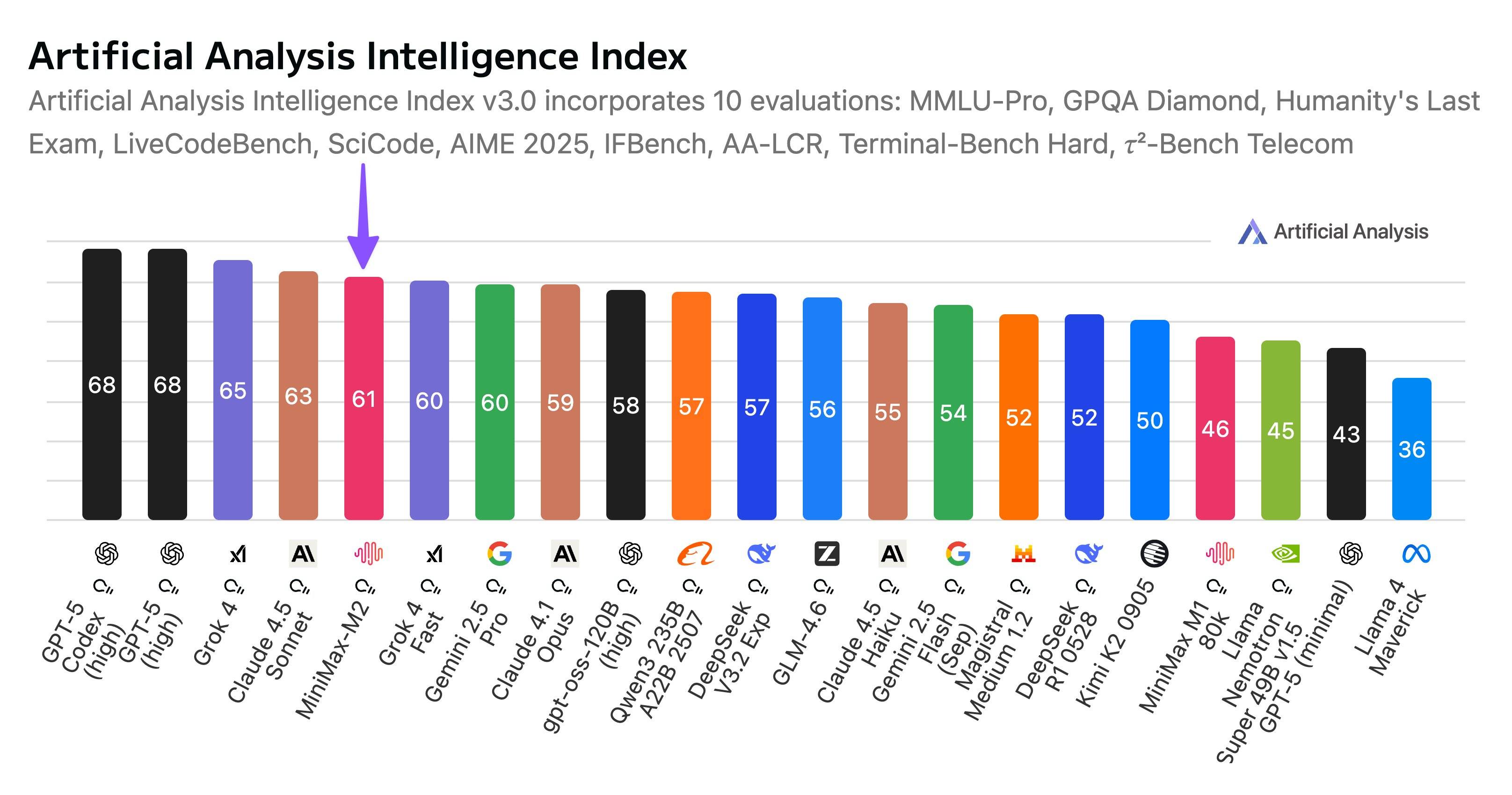
Em novembro, a Kimi lançou o Kimi K2 Thinking, um modelo híbrido especializado com trilhões de parâmetros, que imediatamente liderou diversos rankings, superando até mesmo o GPT-5 da OpenAI e o Claude 4.5 da Anthropic.
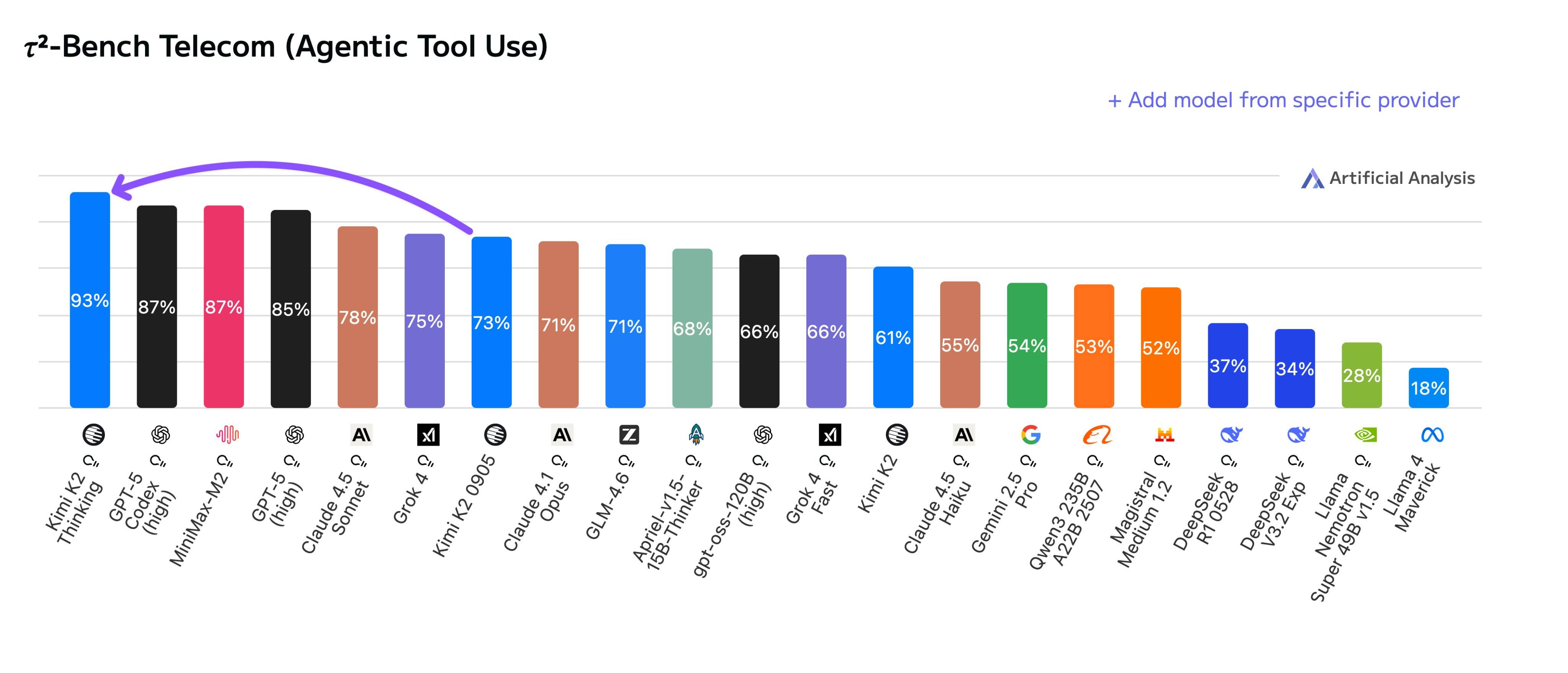
No final de outubro, a MiniMax lançou oficialmente o MiniMax M2, o modelo híbrido para especialistas (MoE). Assim como o Kimi, ele permanece de código aberto. Em termos de desempenho geral, o MiniMax M2 ficou em quinto lugar, superando o Gemini 2.5 Pro e o Claude Opus 4.1.
Em setembro, durante a Conferência Yunqi, a Alibaba lançou uma série de sete modelos, alcançando excelência em diversas áreas, como visão, fala, raciocínio e programação.
Nas redes sociais internacionais, o reconhecimento dos modelos chineses de código aberto tem sido constante desde o surgimento do DeepSeek. "Fácil de usar, barato, a primeira escolha para o desenvolvimento de pequenas empresas, meus projetos paralelos usam modelos chineses de código aberto…" Esses comentários estão por toda parte no X.
Por exemplo, internautas elogiaram o estilo de escrita de Kimi K2 Thinking e seu uso de tokens para representar a profundidade de seu pensamento.
Alguns internautas também compararam o Minimax M2 com o Claude Sonnet 4, afirmando que o M2 consegue gerar um site totalmente funcional em apenas uma utilização, enquanto o Sonnet 4 falha.

Existem ainda mais publicações sobre o Qwen. Da versão 2.5 à atual 3.0, de um modelo grande com 480 bilhões de parâmetros a um modelo pequeno com apenas 600 milhões de parâmetros, da linguagem visual Qwen 3 VL à ferramenta de escrita de código Qwen 3 Coder, o Qwen está presente em quase todo o mercado de código aberto.
Em uma entrevista, o CEO do Airbnb chegou a afirmar abertamente que, embora o OpenAI seja bom, não é adequado para eles; enquanto o modelo de código aberto Qwen, da China, é excelente, aplicável na prática ao seu trabalho, além de ser melhor e mais barato que o OpenAI.
No âmbito do código aberto, é impreciso dizer que o modelo de código aberto nacional ainda está se adaptando; ele já se tornou a opção de código aberto globalmente aceita.
MiniMax M2, um agente inteligente de código aberto que pode ser implementado em aplicações do mundo real.
Se quisermos usar exemplos específicos para ilustrar as vantagens do modelo nacional de código aberto, as experiências de testes práticos de diversas ferramentas de código aberto que compartilhamos no passado já fornecem a resposta.
O lançamento mais recente é o Kimi K2 Thinking, que apresenta uma cadeia de raciocínio ultralonga capaz de executar 300 chamadas de ferramentas em uma única execução; há também o Zhipu AutoGLM 2.0, um agente universal projetado para celulares; e a família de modelos Alibaba Tongyi para Android na era da IA.

▲Estatísticas de Análise Artificial sobre os principais fabricantes e startups de modelos de IA nacionais no primeiro trimestre de 2025
Embora todos esses modelos sejam de código aberto, cada um possui seus próprios destaques técnicos, buscando tornar o mapa de modelos nacionais de código aberto mais completo e abrangente.
O K2 Thinking se concentra em um modelo grande com trilhões de parâmetros e possui seu próprio mecanismo KDA (Kimi Delta Attention); o DeepSeek se concentra em atenção híbrida, o que reduz significativamente os custos; o Minimax M2, nesta atualização, mudou sua abordagem e passou a usar atenção completa, com apenas 230 bilhões de parâmetros no modelo.
Para verificar se o M2 é bom, fizemos um teste simples, seguindo o princípio de experimentá-lo sempre que possível.
Nossa primeira tarefa foi pedir que ele processasse dados de uma planilha do Excel. Enviamos a ele uma tabela com anúncios de vagas para o concurso público nacional deste ano e solicitamos que ele criasse uma ferramenta geral para triagem de candidatos a vagas no serviço público com base no conteúdo da tabela.
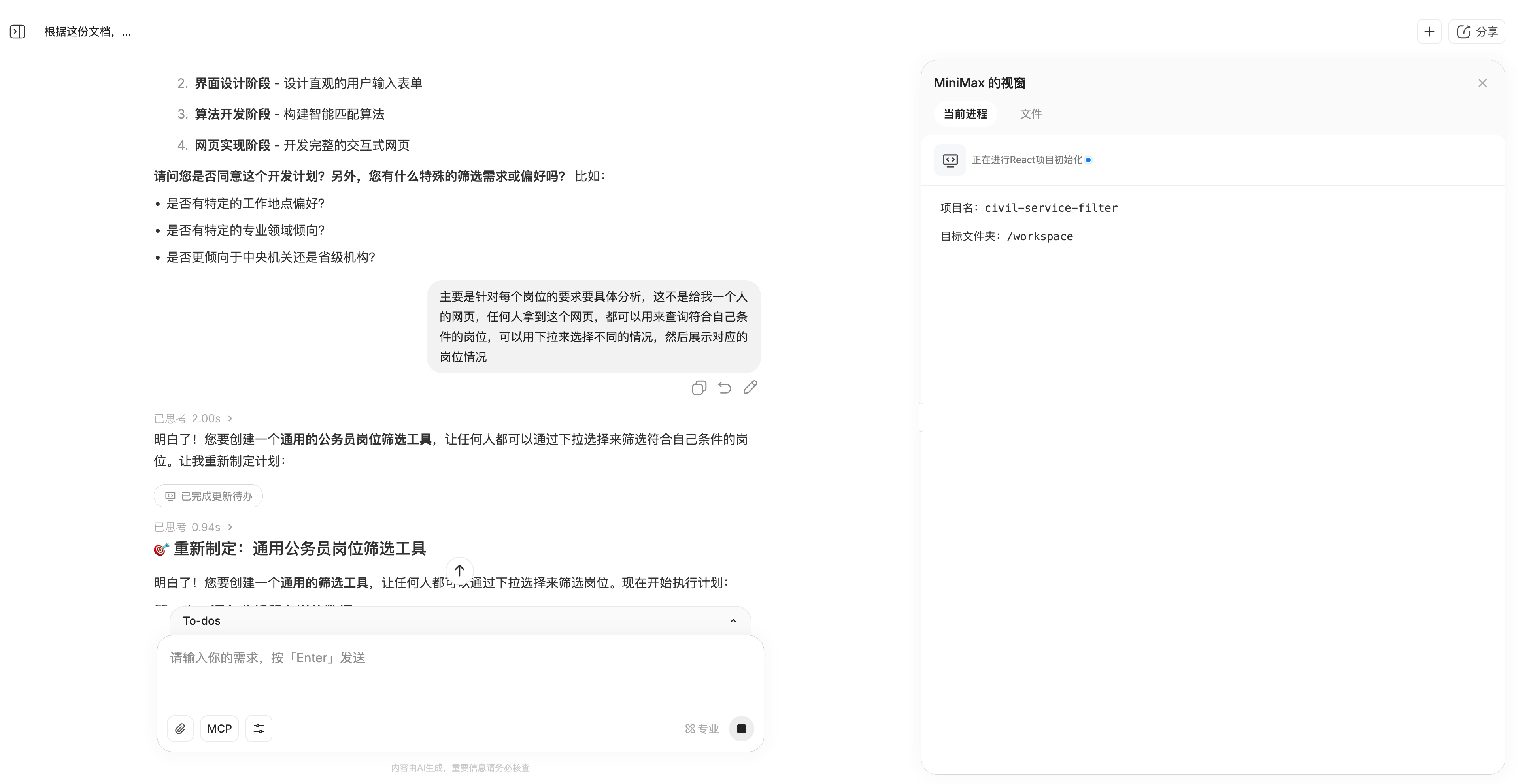
A tabela contém uma grande quantidade de dados, com 10 MB, e inclui mais de 20.000 anúncios de emprego. Um recurso particularmente bom do MiniMax M2 é que ele pergunta ao usuário se são necessários ajustes na tarefa antes da execução.
Em seu blog técnico, eles mencionaram que o M2 utiliza a técnica de "pensamento intercalado", que foi aplicada pela primeira vez no modelo Claude Sonnet 4, mas sua adoção ainda é muito limitada.
O MiniMax oferece uma dica que lembra os usuários de salvarem seus processos de pensamento usando as etiquetas "pensar" do modelo. O M2 depende do pensamento intercalado, e o contexto é essencial para a memória; preservar essas informações permite um pensamento intercalado mais eficaz.

▲O diretor de engenharia da MiniMax, FaX, explicou como o pensamento intercalado permite que os modelos executem melhor as tarefas dos agentes.
Em termos simples, o pensamento intercalado consiste em avançar numa tarefa fazendo com que um modelo amplo "execute ações (usando ferramentas/interfaces), pare para pensar, depois execute ações novamente e, em seguida, pense novamente", em vez de analisar uma série de ideias e executá-las todas de uma vez.
A versão atualizada do Kimi K2 Thinking também emprega a técnica de pensamento intercalado . Essa abordagem de pensar e recorrer a ideias simultaneamente permite que o modelo revise e ajuste seus planos imediatamente após cada resposta da ferramenta. Isso é particularmente adequado para tarefas de agentes com processos longos e resultados incertos.
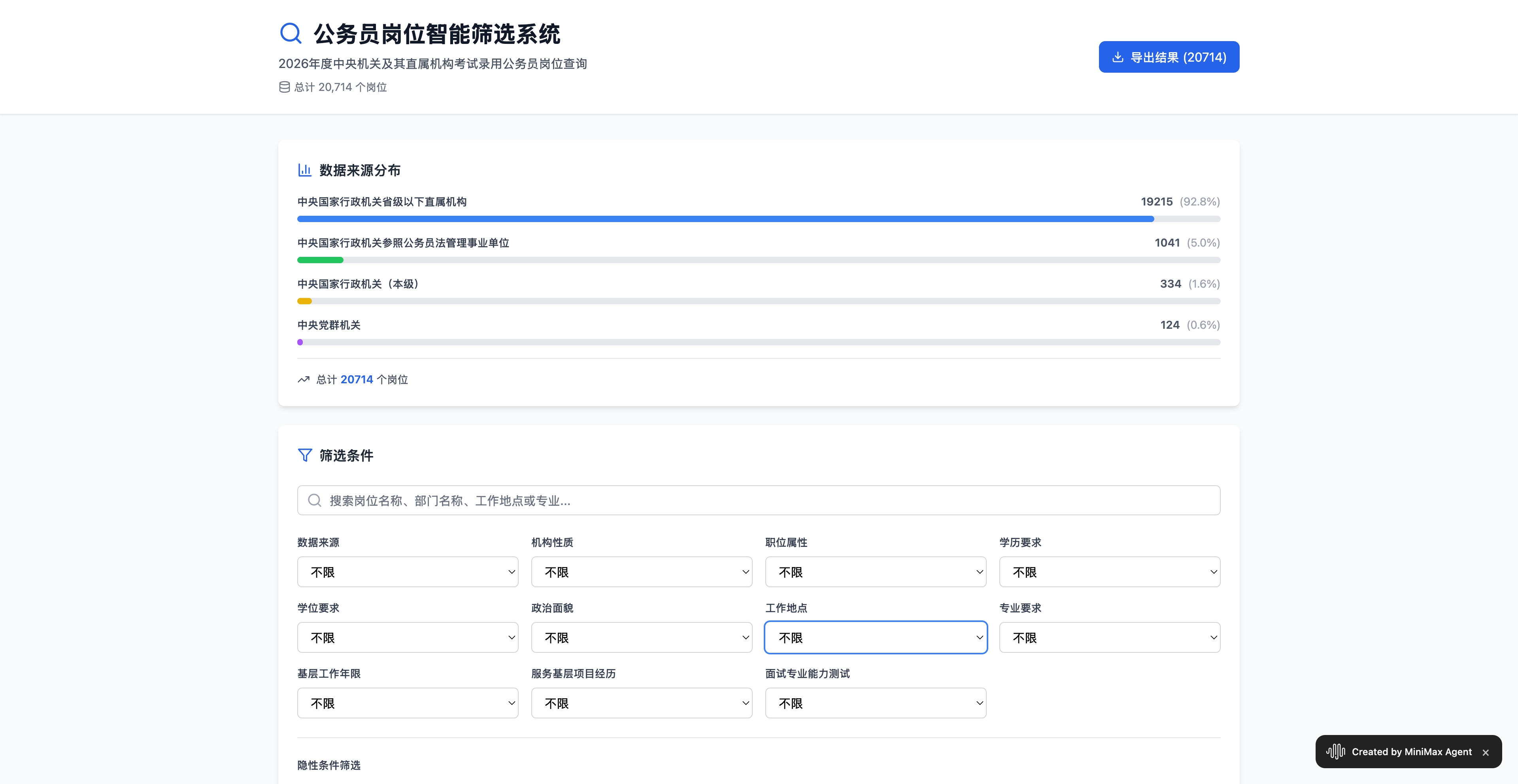
▲ Experimente aqui: https://2rfxtimus5nr.space.minimaxi.com/; Embora o exame tenha terminado, você ainda pode ver que a capacidade do MiniMax M2 de processar dados de planilhas do Excel não deve ser subestimada.
O resultado final é muito preciso, mostrando 20.714 vagas de emprego, e inclui estatísticas sobre fatores como se o candidato é recém-formado, possui anos de experiência em funções de base e tem local de residência. Comparado a algumas ferramentas pagas de seleção de emprego disponíveis no mercado, é muito mais conveniente gerar uma lista automaticamente usando o Agente.
Também pedimos que realizasse uma pesquisa aprofundada, fornecendo informações sobre o próprio M2 e criando uma bela apresentação em PowerPoint.
▲Link de pré-visualização: https://z4czsdfoakc7.space.minimaxi.com/
Além da experiência imersiva de programar e construir um produto do zero, o MiniMax também oferece tutoriais detalhados sobre como integrar ferramentas de linha de comando, como o Claude Code, ou plataformas de desenvolvimento, como o Cursor e o VS Code.
▲Código de Claude usando a API do modelo MiniMax M2
O pensamento intercalado torna os modelos mais inteligentes, sabendo quando acionar cada ferramenta. Mas o MiniMax M2 tem outro destaque técnico: ele usa um mecanismo de atenção completa, o que é uma exceção à regra .
Já discutimos anteriormente como o DeepSeek atinge custos tão baixos, sendo um dos principais motivos o uso de mecanismos de atenção esparsa e atenção híbrida . A atenção esparsa permite que o modelo se concentre seletivamente em informações importantes, ignorando informações secundárias ao processar tokens, assim como os humanos fazem.
Ao combiná-la com outras estratégias, podemos melhorar a velocidade de inferência do modelo e reduzir custos sem afetar a qualidade dos resultados.

▲ Postagem original no blog: https://huggingface.co/blog/MiniMax-AI/why-did-m2-end-up-as-a-full-attention-model
A equipe do MiniMax também escreveu uma postagem técnica no blog explicando por que voltaram à estaca zero e continuaram a escolher o mecanismo de atenção completa, um método que aumenta a pressão de treinamento e inferência.
Eles mencionaram que o principal motivo é o "desempenho específico". A maior parte do que hoje é chamado de atenção esparsa ou atenção eficiente não visa melhorar o desempenho do modelo, mas simplesmente economizar recursos computacionais e reduzir custos.
Os modelos de atenção completa ainda oferecem maior desempenho e confiabilidade. No entanto, à medida que os requisitos de comprimento de contexto continuam a aumentar e a taxa de crescimento da computação em GPUs diminui, o potencial da atenção linear e esparsa pode emergir gradualmente.
O que o MiniMax M2 está tentando fazer atualmente é alcançar um equilíbrio entre qualidade, velocidade e preço, tanto quanto possível, com recursos computacionais limitados, e desta vez, de fato, conseguiu.

Portanto, em certa medida, muitas pessoas sentem que o código aberto significa doar tecnologia gratuitamente para outros; mas, na história do desenvolvimento tecnológico, o código aberto tem a ver com permitir que diferentes tecnologias se encontrem e que diferentes pesquisadores colaborem, alcançando assim maior inovação tecnológica.
Quando a Artificial Analysis, uma plataforma de análise de modelos em larga escala, apresentou o desempenho geral do MiniMax M2 em sua plataforma, também mencionou a tecnologia de código aberto nacional, afirmou ele.
A China AI Labs continua a manter uma posição de liderança no campo do código aberto.
O lançamento do MiniMax consolida a posição de liderança da China no campo da IA de código aberto, posição iniciada pelo DeepSeek no final de 2024 e mantida por lançamentos subsequentes do DeepSeek, Alibaba, Zhipu e Kimi, entre outros.
É verdade. Esperamos um ano pelo DeepSeek R2, mas em vez disso vimos o Kimi K2, que se tornou um sucesso no exterior, a série Zhipu GLM e a série Qwen, na qual quase todos os desenvolvedores confiam.
Todos esses modelos de código aberto desenvolvidos internamente, com suas diversas abordagens técnicas e diferentes direções de aplicação, só possuem verdadeiras vantagens e força quando totalmente combinados, impedindo que o código fechado se torne o único representante de um "bom modelo".
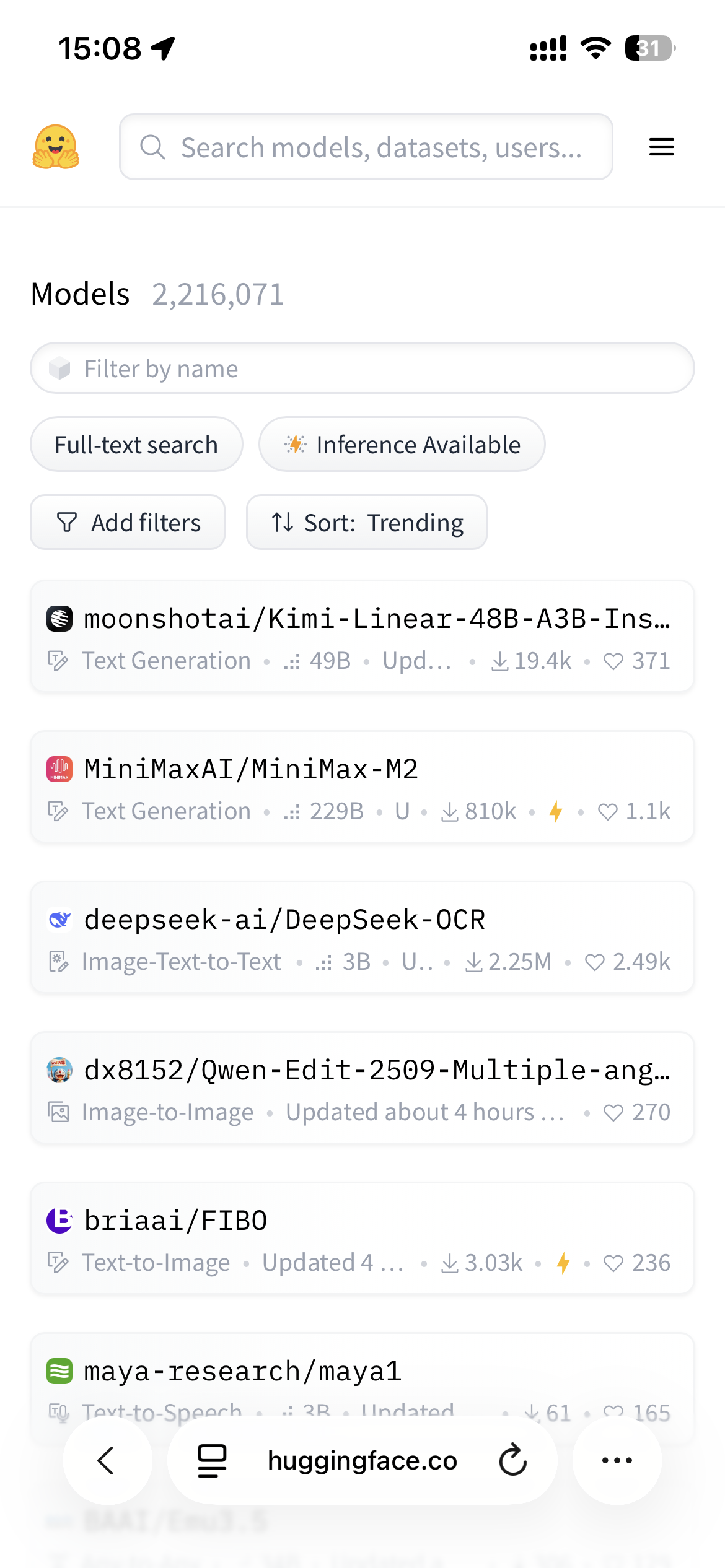
▲ No Hugging Face, os quatro modelos mais populares são todos modelos de código aberto desenvolvidos internamente; Fonte da imagem: https://huggingface.co/models?sort=trending
Código fechado não pode derrotar código fechado; somente código aberto pode romper essas barreiras.
Há algum tempo, no Dia do Programador 1024 da Xiaohongshu, o fundador da Hugging Face mencionou que a diferença entre software livre e software proprietário está diminuindo, e que a China está relativamente avançada nesse aspecto. O diretor técnico da Xiaohongshu também afirmou que o software livre reduz o custo do uso da IA na sociedade e mobiliza a força de todos para impulsionar o avanço da tecnologia.
Sem dúvida, o código aberto é algo bom, mas ninguém esperava que o que derrotaria o código fechado seria o próprio código aberto.

O surgimento do DeepSeek não apenas revelou ao mundo uma lógica de treinamento de modelos totalmente nova, alcançando resultados igualmente impressionantes a um custo menor, mas, mais importante ainda, forneceu uma direção clara para todo o modo de operação da IA doméstica.
Isso fez com que todos percebessem que, em um contexto em que os Estados Unidos monopolizavam o discurso global sobre IA na época, o código aberto era a única maneira de se tornar visível.
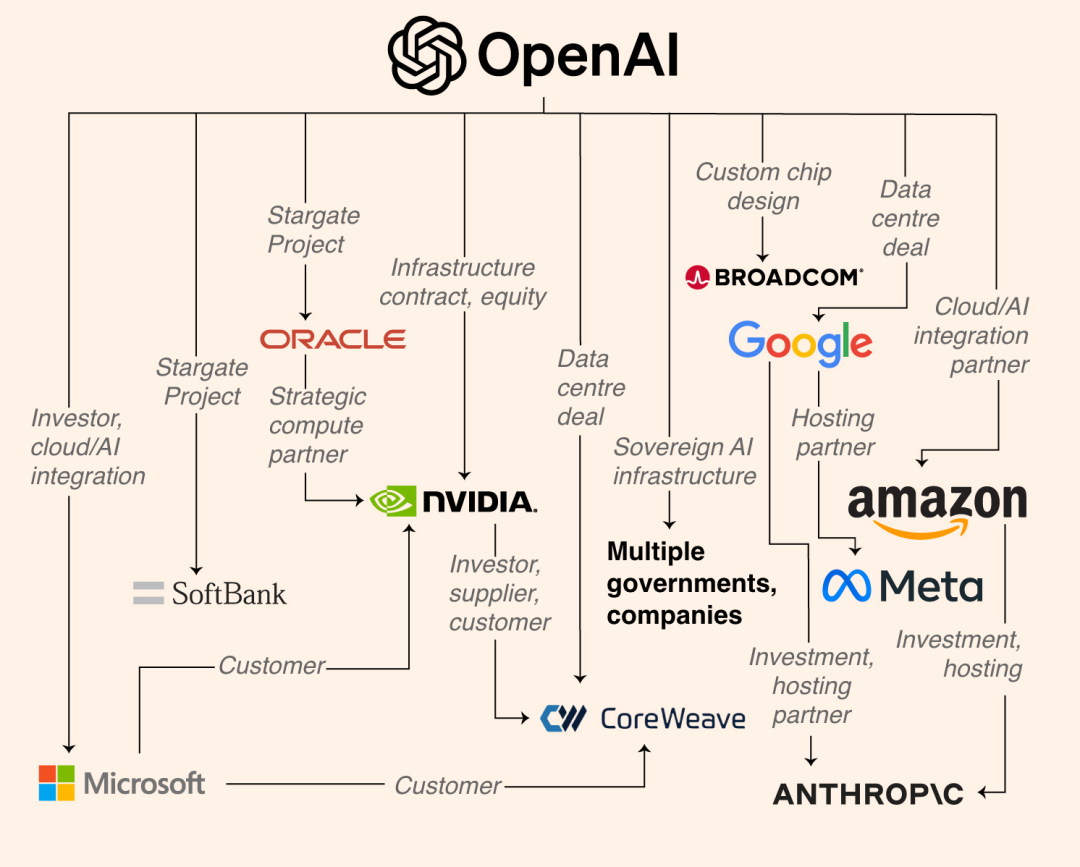
▲O império empresarial de poder computacional da OpenAI, avaliado em trilhões de dólares, inclui empresas como Google, Meta, Anthropic, etc.
É claro que existem muitas outras razões específicas para escolher o código aberto. A OpenAI, a Anthropic e a Gemini estão desenvolvendo seus próprios sistemas em ambientes fechados. Elas podem treinar modelos maiores com placas gráficas ilimitadas e arrecadar centenas de bilhões de dólares em financiamento.
No entanto, o dilema enfrentado pelos modelos desenvolvidos internamente é a escassez de poder computacional e a limitação de chips… Se os modelos não forem compartilhados, ninguém poderá reutilizar o poder computacional. Sem um modelo básico utilizável, significa que tudo precisa começar do zero. Inicialmente, a Baidu optou por manter os modelos em código fechado em função de seu modelo de negócios; em junho deste ano, eles também anunciaram a abertura oficial do código-fonte da série Wenxin Big Model 4.5.
Por outro lado, existem muitos fabricantes de modelos nacionais e a concorrência é muito acirrada. Se ele optar por não disponibilizar o código aberto, outros o farão; se optar por manter o código fechado, os usuários poderão escolher outros modelos.
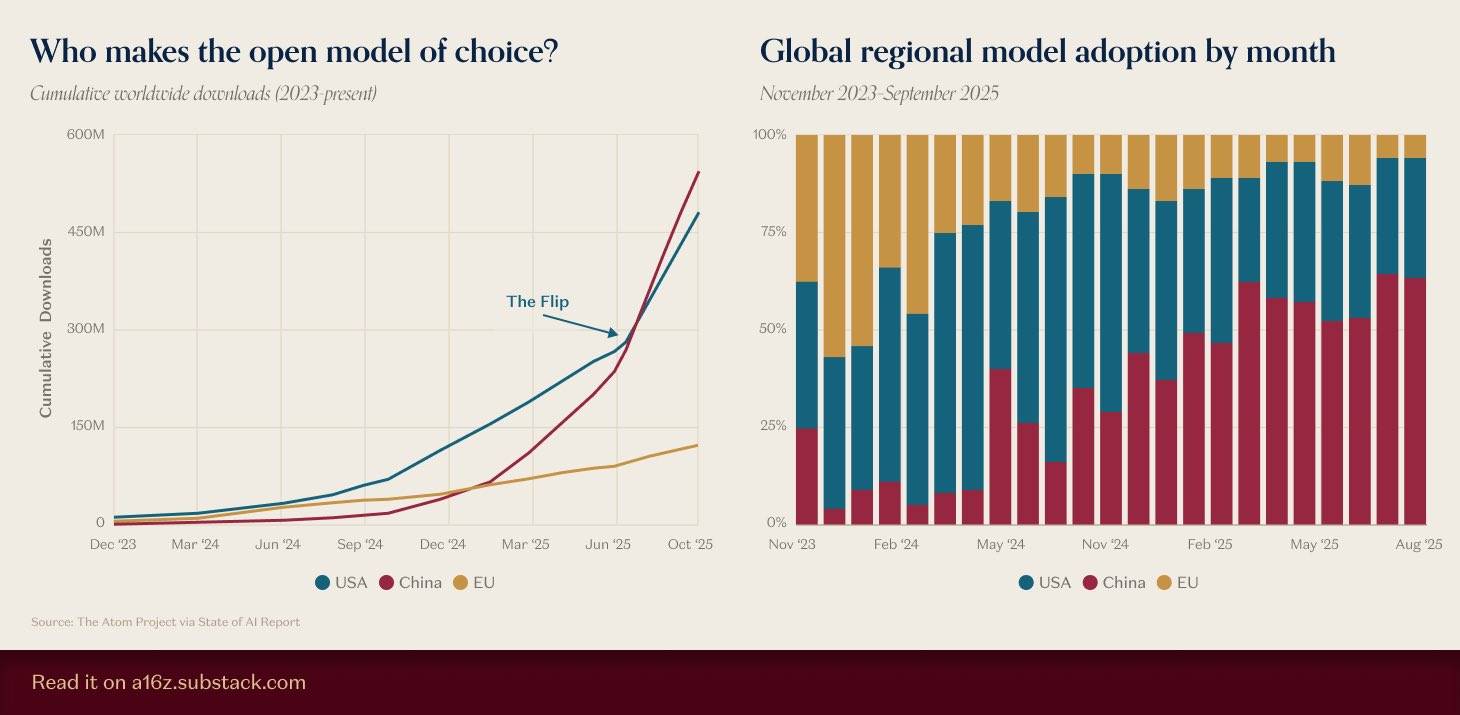
▲Fonte da imagem: https://a16z.substack.com/p/charts-of-the-week-open-model-of
Há algum tempo, a a16z compilou dados sobre modelos de código aberto, e os resultados mostraram que o número acumulado de downloads de modelos nacionais de código aberto não apenas ultrapassou o de modelos americanos, como essa vantagem continua a aumentar.
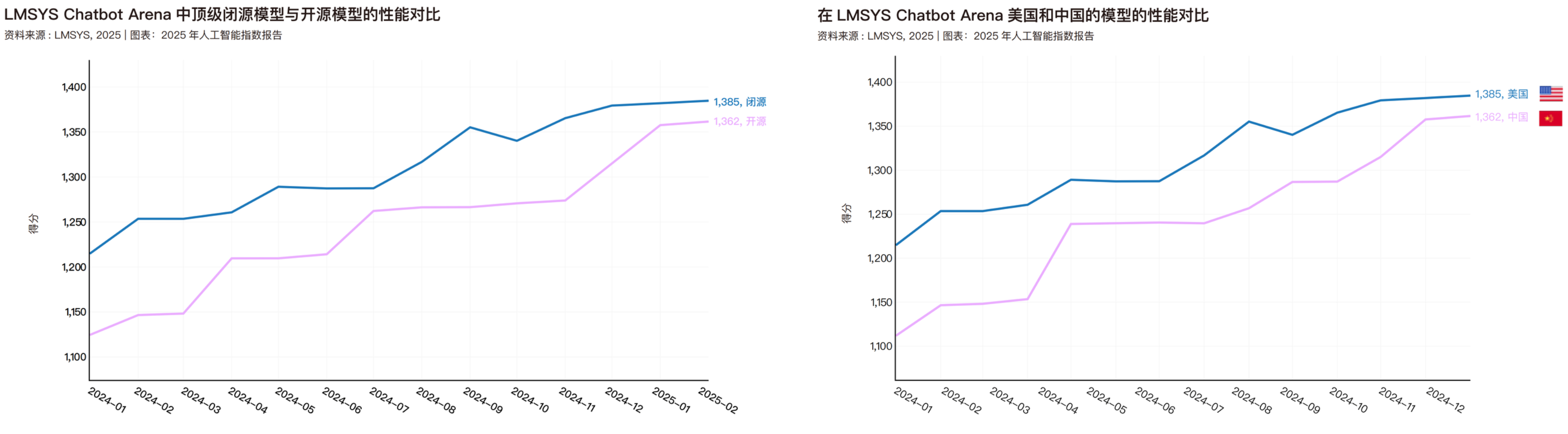
Em abril deste ano, a Universidade de Stanford também publicou um relatório do Índice de IA de 2025, que comparou o desempenho de modelos de código aberto e de código fechado, bem como o desempenho de modelos da China e dos Estados Unidos. Os dados deste relatório vão apenas até fevereiro deste ano; até o próximo ano, é provável que os modelos de código aberto desenvolvidos internamente já tenham superado tanto os modelos de código fechado quanto os americanos.
Se analisarmos as vantagens do código aberto nacional em seus mínimos detalhes, descobriremos que nossa liderança atual se deve a um sistema de código aberto completo e robusto. Cada elo desse sistema fortalece cada vez mais as capacidades do código aberto nacional.
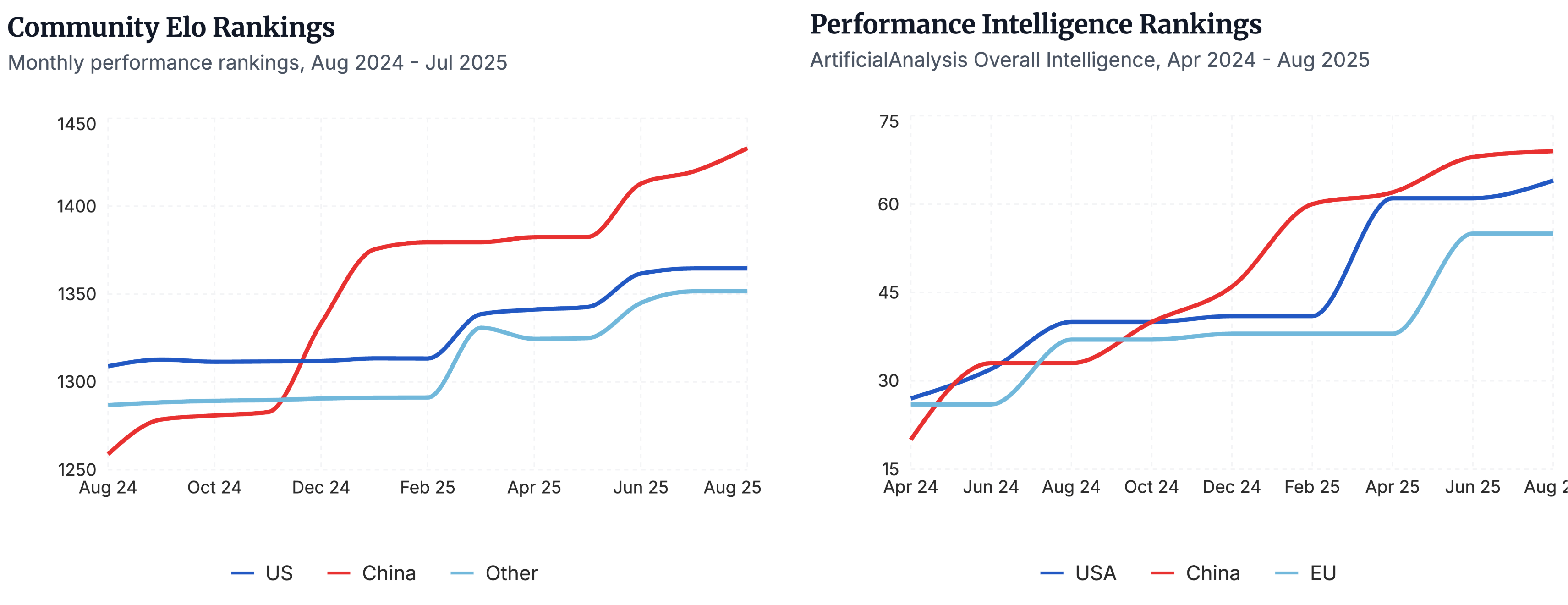
▲Seja na avaliação da comunidade sobre modelos nacionais de código aberto, como o ranking Elo, ou na comparação de desempenho por região no teste de benchmark de Análise Artificial, os modelos nacionais de código aberto ocupam uma posição de liderança. | Fonte da imagem: https://www.atomproject.ai/
DeepSeek abriu a primeira brecha com sua estrutura de custos e inferência eficiente; Qwen transformou essa brecha em uma lacuna com a escala de seu ecossistema; MiniMax, Zhipu e Kimi, por outro lado, usaram abordagens técnicas diferentes para ampliar ainda mais essa lacuna.
Quando pequenas equipes ao redor do mundo usam o Qwen para ajustes finos, o DeepSeek para fundamentos de inferência e o MiniMax para verificação de agentes, as soluções nacionais de código aberto deixaram de ser escolhidas e se tornaram o padrão. Como resultado, o centro do ecossistema global de código aberto começou a se deslocar para a China.
No mês passado, Jensen Huang afirmou em uma entrevista durante uma cúpula de IA que "a China vencerá a corrida da IA". No entanto, ele imediatamente retratou sua declaração por meio da conta oficial da Nvidia, X, esclarecendo que a China está, na verdade, "apenas nanossegundos atrás dos Estados Unidos na corrida da IA".

Esta não é a primeira vez que Huang menciona a posição da China na corrida da IA. Ele já afirmou em diversas ocasiões públicas que os modelos de código aberto são extremamente importantes, seja para desenvolvedores, startups ou mesmo para a chamada corrida da IA.
Na conferência NVIDIA GTC em outubro deste ano, Jensen Huang mencionou novamente em seu discurso que, no mercado global de modelos de código aberto, a Tongyi Qianwen, da China, ocupa o primeiro lugar e detém a maior parte da participação de mercado.
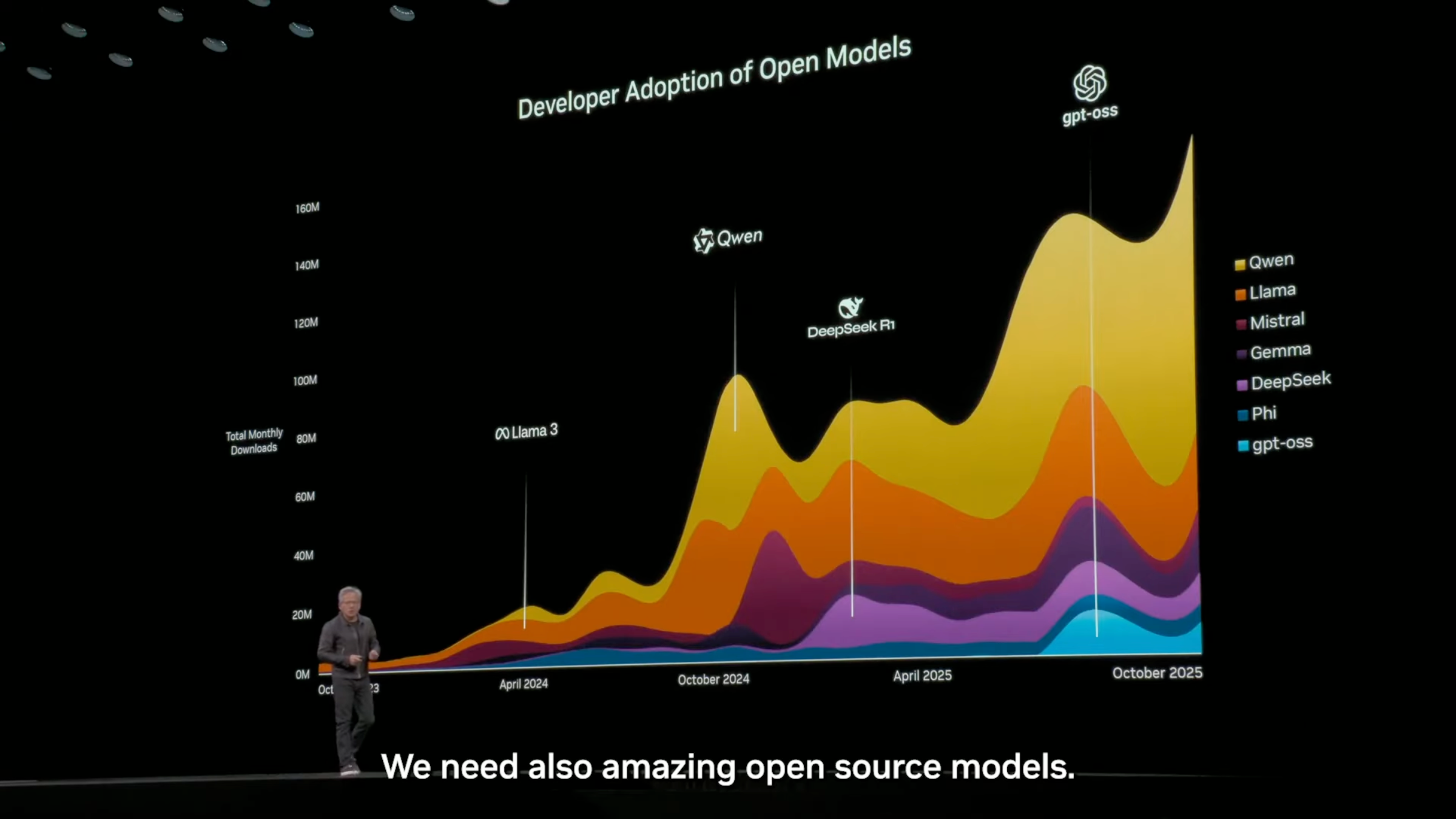
▲ Quase 60% são Qwen
Em abril deste ano, ele também afirmou em uma conferência de tecnologia em Washington: "Sem dúvida, a Huawei é uma das empresas de tecnologia mais poderosas do mundo… A China não está ficando para trás no campo da inteligência artificial. Estamos muito, muito perto… 50% dos pesquisadores de IA do mundo são chineses. Teremos que competir."
No entanto, na competição por software livre, observe o líder americano, o Llama, da Meta. Em abril passado, foi lançado o Llama 3, seguido pelo Llama 3.1 em julho, o Llama 3.2 em setembro e, surpreendentemente, o Llama 4 em abril deste ano. Existe ainda uma versão mais avançada, o Behemoth, que ainda não foi lançada.

▲O jogo Llama 4, lançado em abril, mencionava três versões: Behemoth, Maverick e Scout. Parece que a versão Behemoth foi abandonada.
Depois disso, a única notícia sobre a Meta foi Zuckerberg oferecendo salários exorbitantes para atrair talentos e, mais recentemente, demitindo 600 pessoas. Até mesmo o ganhador do Prêmio Turing, Yann LeCun, pediu demissão para abrir seu próprio negócio.
Zuckerberg provavelmente jamais imaginou que sua escolha por um software de código aberto no Vale do Silício, que o tornou uma figura singular, seria superada pelo DeepSeek, que explodiu em popularidade em janeiro deste ano. Como resultado, a Meta agora se encontra em um dilema: o código aberto não é uma opção, e o código fechado não é uma alternativa viável.
É difícil discordar que o Llama deve metade do seu sucesso à tecnologia nacional de código aberto.
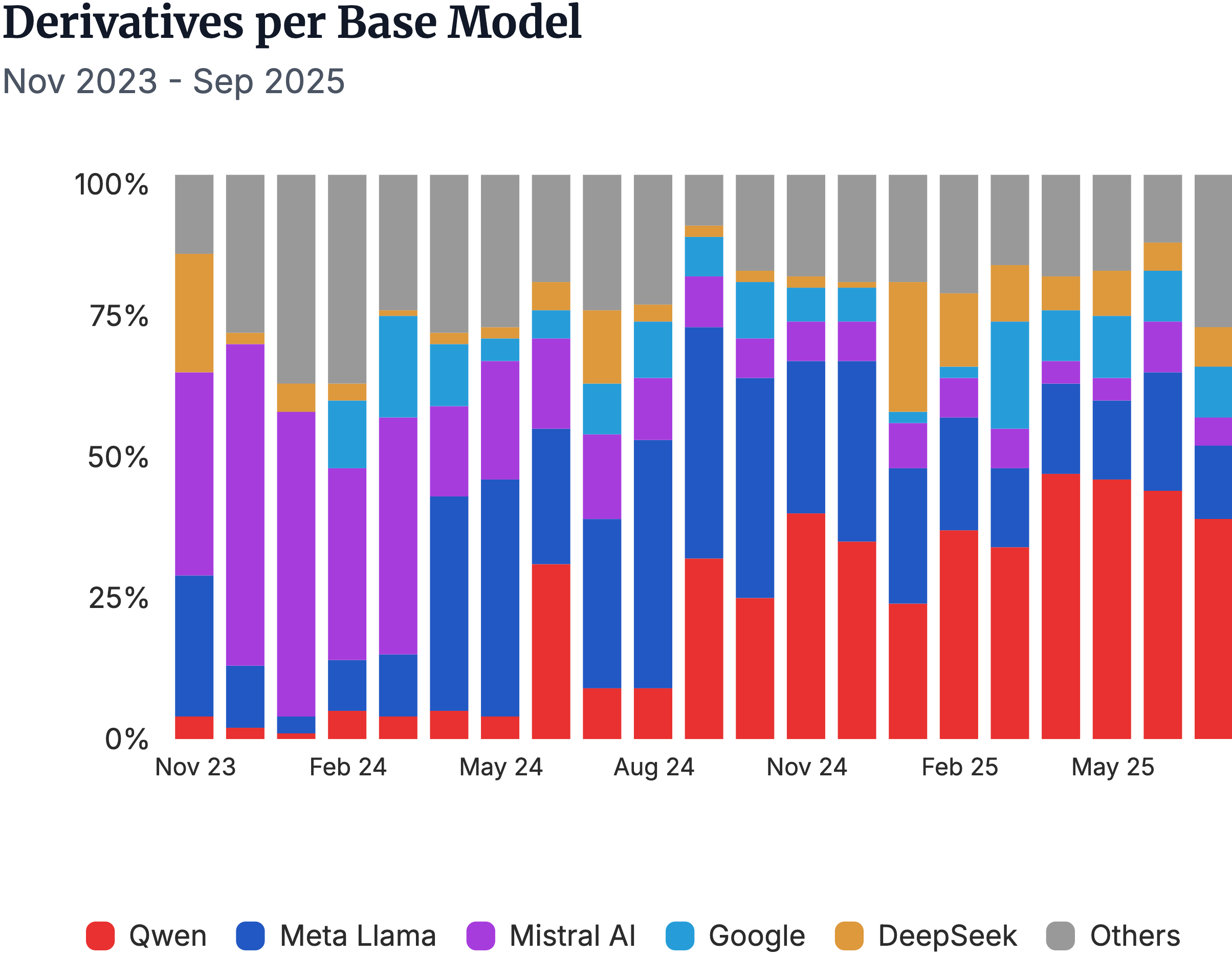
▲Os modelos derivados relacionados a metadados e a vantagem inicial da Mistral AI foram completamente superados pelo modelo Qwen da Alibaba.
Há alguns dias, enquanto navegava nas redes sociais, vi um comentário que dizia: "O código aberto é como transformar seu oponente em seu filho; nenhum filho bateria em seu pai." As palavras podem parecer grosseiras, mas a verdade é sólida. No ciclo de código aberto da IA, o modelo representativo da China tornou-se claramente a base do ecossistema de IA.
Essa onda de modelos de IA, impulsionada por tecnologias de código aberto desenvolvidas internamente, está mudando a questão de quem pode definir o futuro da IA. Ela permitirá que cada um de nós utilize a IA mais avançada e fácil de usar do mundo a um custo menor e com maior velocidade.
Os detalhes da última imagem são os seguintes.
▲De cima para baixo:
Modelos de ponta: DeepSeek, Qwen, Moonshot AI (Kimi)
Principais concorrentes: Z.Ai, MiniMax
Empresas para ficar de olho: StepFun, InclusionAI/Ant Financial, Meituan, Tencent, IBM, Nvidia, Google, Mistral
Áreas de especialização: OpenAI, Ai2, Moondream, Arcee, RedNote, HuggingFace, LiquidAI, Microsoft, Xiaomi, Universidade Mohammed bin Zayed para Inteligência Artificial. Empresas emergentes: ByteDance Seed, Apertus, OpenBMB, Motif, Baidu, Marin Community, InternLM, OpenGVLab, ServiceNow, Skywork.
Menções Honrosas: TNG Group, Meta, Cohere, Instituto de Inteligência Artificial de Pequim, Projeção de Arte Multimodal, Huawei
#Siga a conta oficial do iFanr no WeChat: iFanr (ID do WeChat: ifanr), onde você encontrará conteúdo ainda mais interessante o mais breve possível.
