
A Xiaomi lançou repentinamente um novo modelo: comparável ao DeepSeek-V3.2, trazendo inteligência artificial para a relação custo-benefício dos celulares.

O modelo de código aberto acaba de ganhar mais um concorrente de peso. A Xiaomi acaba de lançar oficialmente e disponibilizar como código aberto seu novo modelo, o MiMo-V2-Flash.
O MiMo-V2-Flash possui um total de 309 bilhões de parâmetros, com 15 bilhões de parâmetros ativos. Ele adota uma arquitetura híbrida especializada (MoE) e seu desempenho pode competir com os principais modelos de código aberto, como o DeepSeek-V3.2 e o Kimi-K2.

Além disso, o MiMo-V2-Flash adota a licença de código aberto MIT, e seus direitos autorais básicos também foram liberados no Hugging Face. Além de ser de código aberto, o grande diferencial do novo modelo reside em sua inovação radical no design arquitetônico, que aumentou a velocidade de inferência para 150 tokens/segundo e reduziu o custo para US$ 0,1 por milhão de tokens de entrada e US$ 0,3 por milhão de tokens de saída, resultando em uma excelente relação custo-benefício.
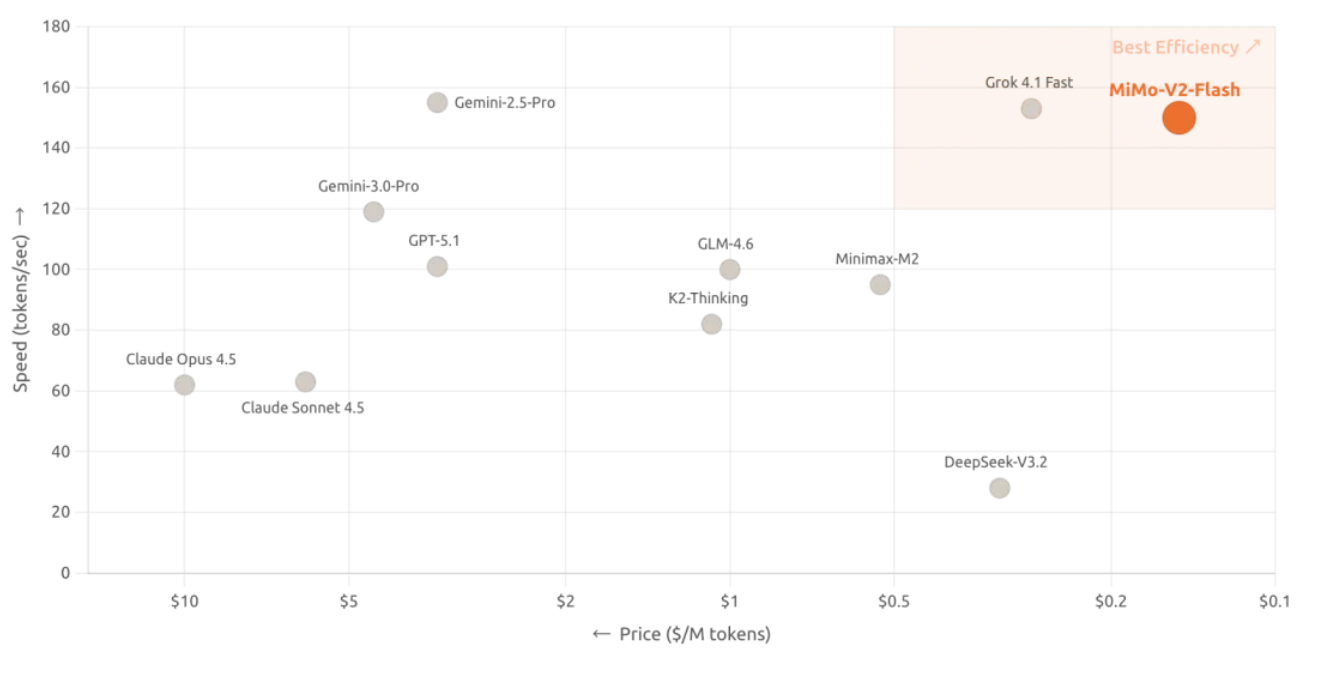
De acordo com a página oficial, o MiMo-V2-Flash suporta funções de raciocínio profundo e pesquisa online, o que significa que ele pode não apenas escrever código e resolver problemas matemáticos, mas também obter as informações mais recentes em tempo real.
Aqui está o link para experimentar o AI Studio:
http://aistudio.xiaomimimo.com
O SWE-Bench estabelece um novo padrão para modelos de código aberto, liderando os rankings de código aberto.
Como de costume, vamos primeiro dar uma olhada nos resultados dos testes de benchmark do MiMo-V2-Flash.
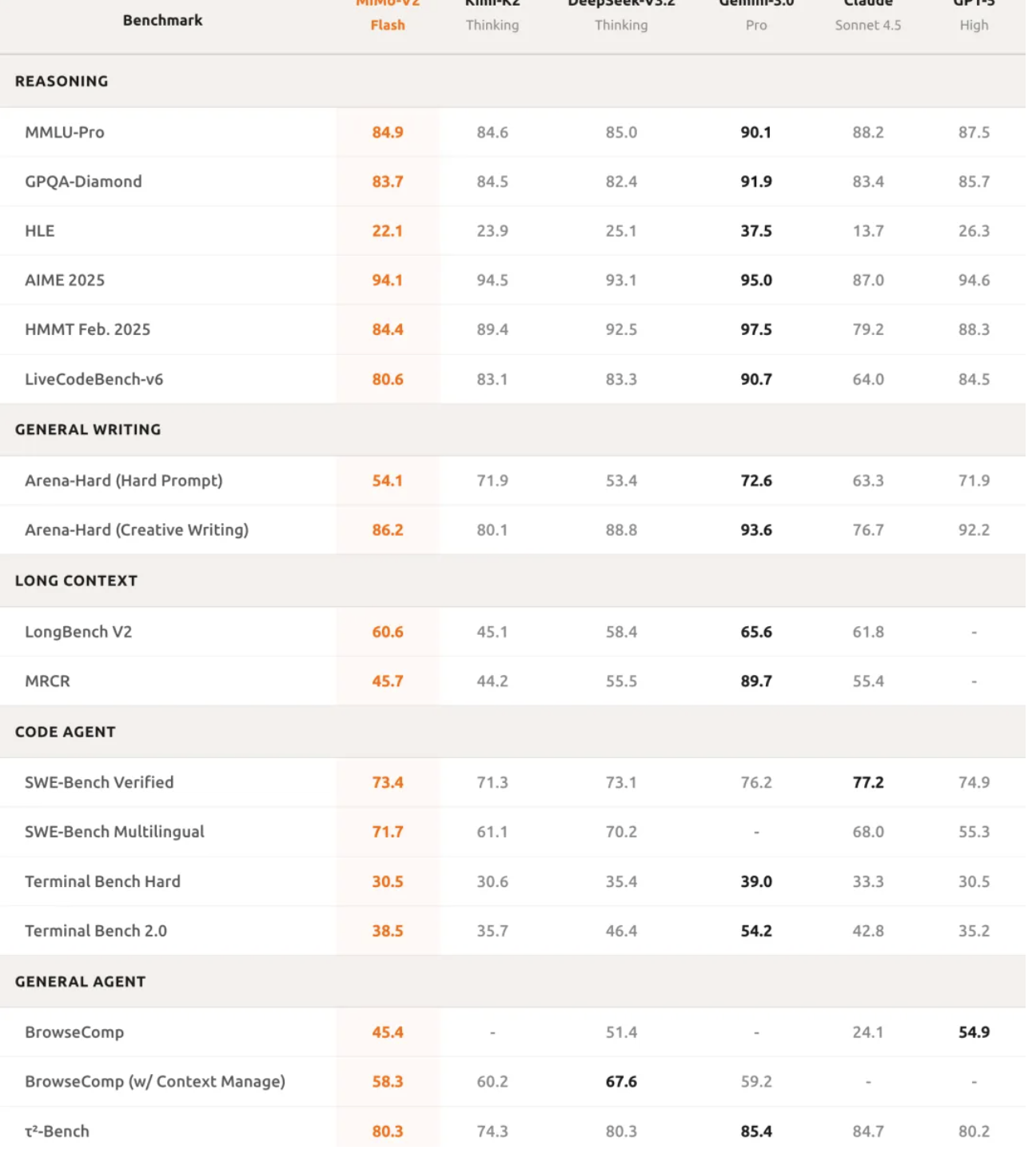
Em raciocínio matemático, o MiMo-V2-Flash ficou entre os dois melhores modelos de código aberto tanto na Competição de Matemática AIME 2025 quanto no Teste de Conhecimento Científico GPQA-Diamond.
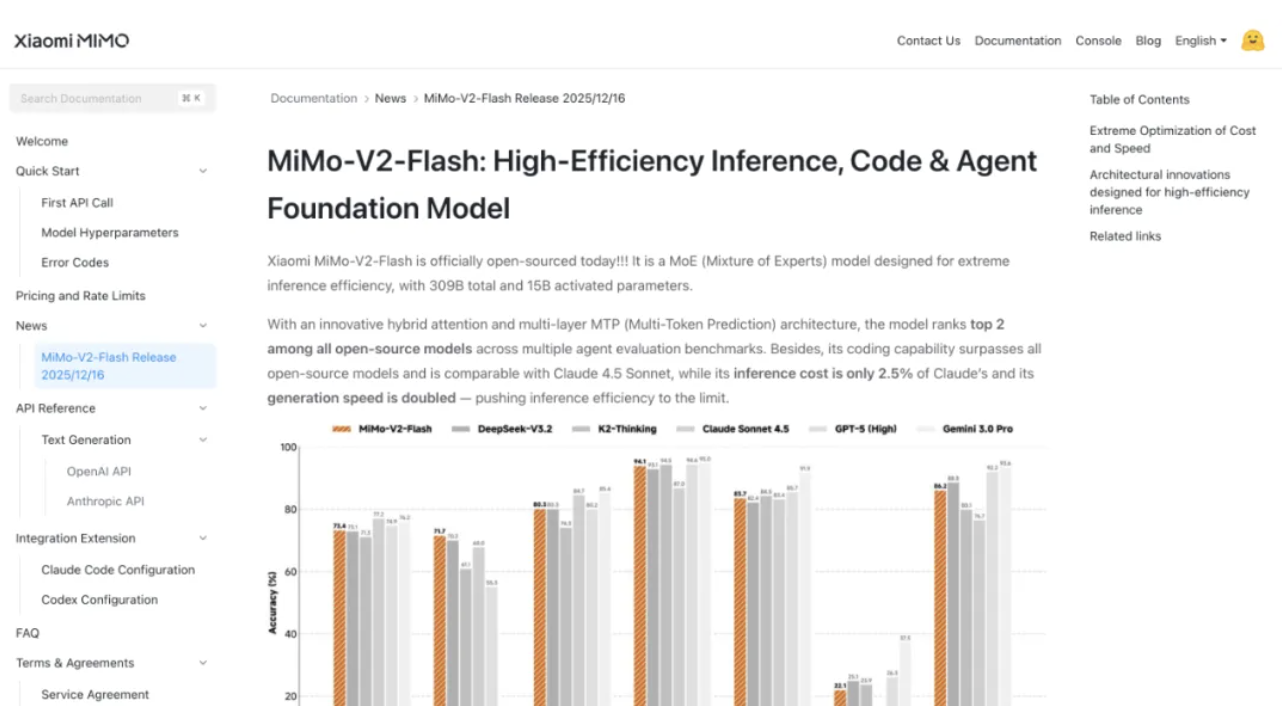
Suas capacidades de programação são ainda mais impressionantes, atingindo 73,4% no teste SWE-bench Verified, superando todos os modelos de código aberto e se aproximando do GPT-5-High. Simplificando, este teste coloca a IA diante de bugs de software do mundo real, e uma taxa de sucesso de 73,4% significa que ela pode lidar com a maioria dos problemas práticos de programação.
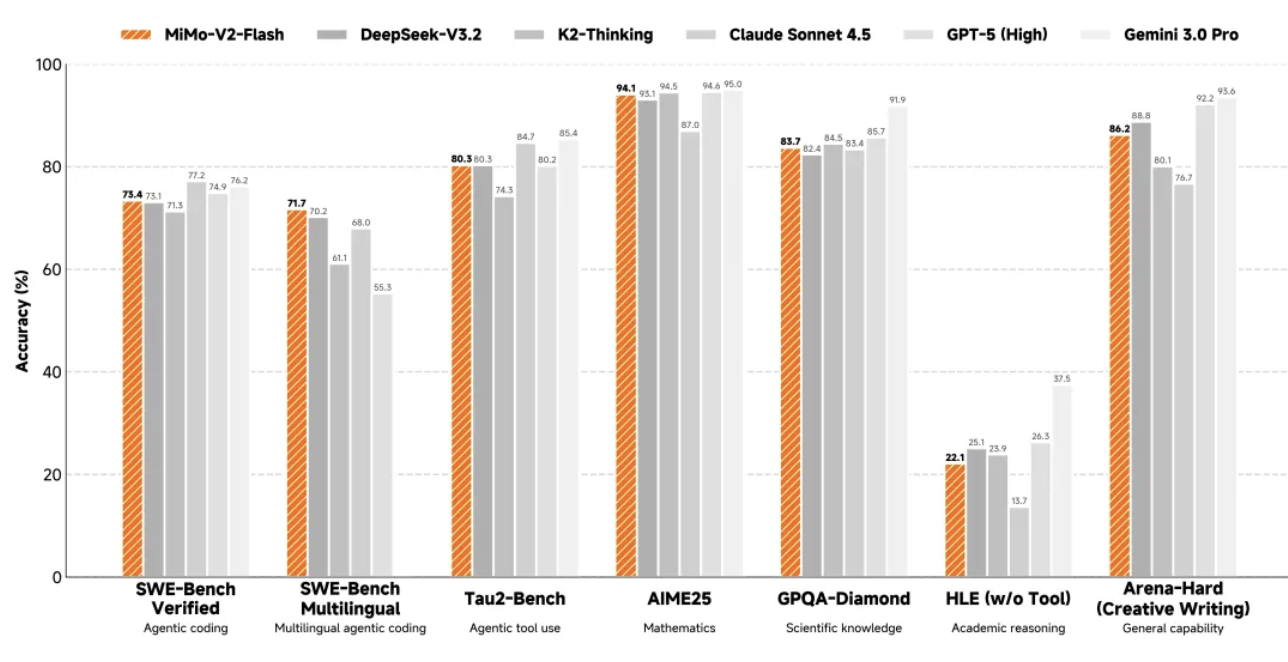
No teste de benchmark multilíngue SWE-Bench, a taxa de resolução foi de 71,7%. Na tarefa de agente inteligente, o MiMo-V2-Flash obteve 95,3 pontos na categoria de comunicação, 79,5 pontos na categoria de varejo e 66,0 pontos na categoria de aviação no teste de classificação τ²-Bench.
A pontuação do agente de busca do BrowseComp era de 45,4, mas saltou para 58,3 após a ativação do gerenciamento de contexto.
Esses dados demonstram que o MiMo-V2-Flash não apenas consegue escrever código, mas também compreender de fato a lógica complexa de tarefas e executar interações de agentes com múltiplas etapas. Suas capacidades de processamento de textos longos também são impressionantes; em testes práticos, seu desempenho supera até mesmo o do Kimi-K2 Thinking, de maior porte, comprovando as poderosas capacidades de modelagem de longo alcance da arquitetura híbrida de atenção por janela deslizante.
A qualidade de escrita também se aproxima da de modelos proprietários de ponta, o que significa que o MiMo-V2-Flash não é apenas uma ferramenta, mas também um assistente confiável para o dia a dia.
O segredo para manter o desempenho e reduzir os custos em até 6 vezes na saída de textos longos.
A principal inovação do MiMo-V2-Flash é seu mecanismo híbrido de atenção por janela deslizante.
Quando modelos tradicionais de grande escala processam textos longos, o mecanismo de atenção global causa uma explosão secundária na carga computacional, e o cache de chave-valor para armazenar resultados intermediários também aumenta exponencialmente. Desta vez, a Xiaomi adotou uma proporção agressiva de 5:1, alternando entre 5 camadas de atenção por janela deslizante e 1 camada de atenção global, com a janela deslizante considerando apenas 128 tokens.
(Para quem não está familiarizado com IA, aqui vai uma breve explicação: em modelagem em larga escala/processamento de linguagem natural, um "token" se refere à menor unidade de contagem usada pelo modelo ao ler e gerar texto. O modelo não conta de forma fixa, como "um caractere chinês = 1, uma palavra em inglês = 1", mas sim processa o texto dividindo-o em segmentos de tokens.)
Em termos simples, o modelo não precisa analisar todo o conteúdo a cada vez; ele analisa apenas os 128 tokens mais recentes e, ocasionalmente, verifica a lista global. Isso reduz significativamente os requisitos de computação e armazenamento. Esse design reduz o armazenamento do cache chave-valor em quase 6 vezes, sem comprometer a capacidade de lidar com textos longos, suportando uma janela de contexto máxima de 256k.
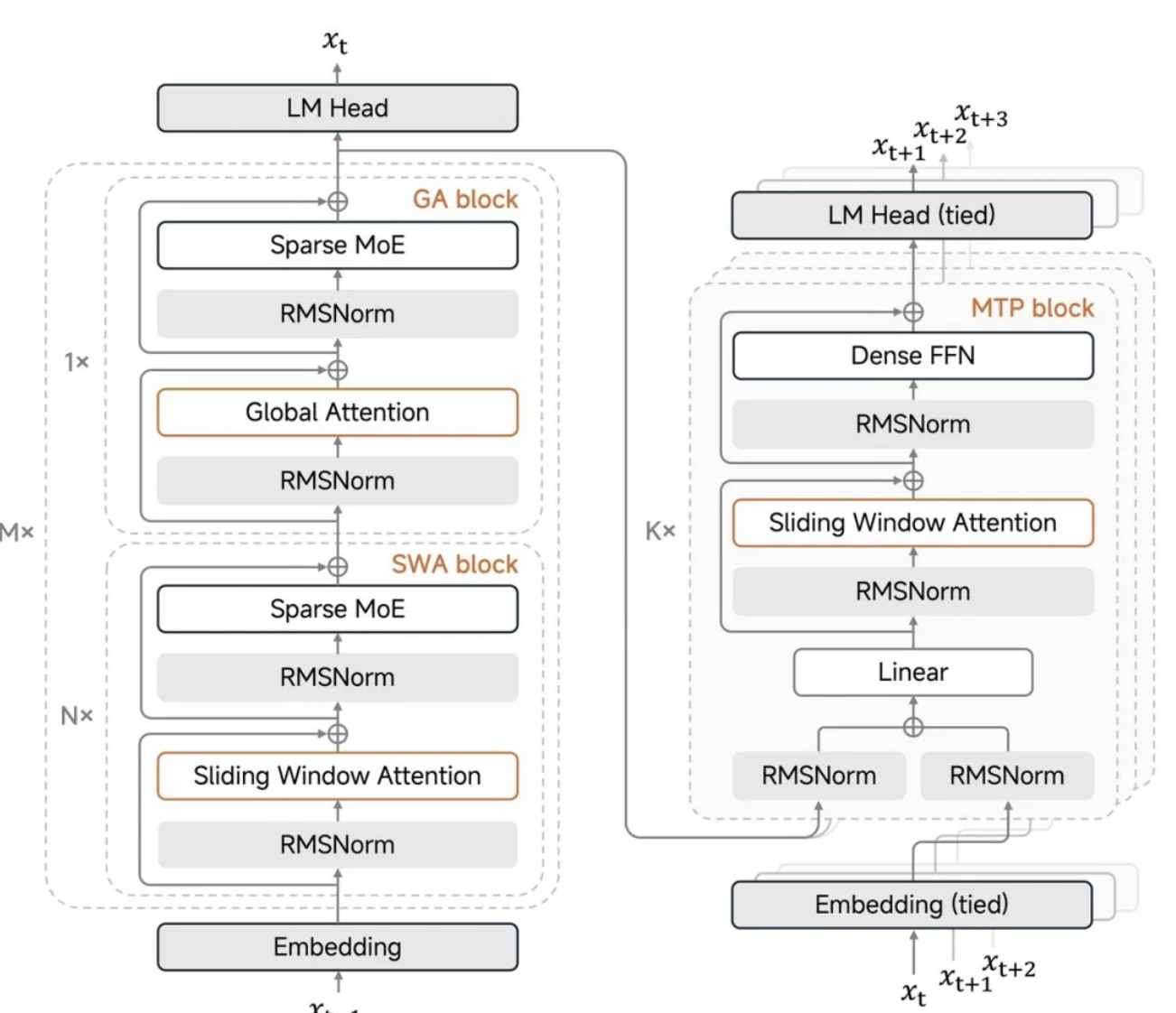
O ponto crucial é que a Xiaomi também desenvolveu um "viés de fluxo de atenção aprendível", que permite ao modelo manter um desempenho estável para textos longos, mesmo sob configurações de janela tão agressivas.
Luo Fuli enfatizou nas redes sociais que um tamanho de janela de 128 se mostrou o "valor ideal", enquanto 512, na verdade, leva à degradação do desempenho. Essa descoberta é bastante contraintuitiva; você pode pensar que quanto maior a janela, melhor, mas, em testes reais, 128 é o ponto ideal. Além disso, os valores de sink (valores de sink de atenção) são essenciais e nunca devem ser omitidos.
Outra tecnologia de ponta é a previsão multi-token leve (MTP).
Os modelos tradicionais só conseguem gerar um token por vez ao produzir texto, assim como um digitador digita uma palavra por vez. O MiMo-V2-Flash, por meio de seu módulo MTP integrado nativamente, consegue prever vários tokens em paralelo, adivinhando diversos tokens simultaneamente.
Em testes práticos, ele consegue aceitar uma média de 2,8 a 3,6 tokens, aumentando diretamente a velocidade de inferência de 2 a 2,6 vezes. Isso não é útil apenas durante a inferência, mas também acelera a amostragem e reduz o tempo ocioso da GPU durante a fase de treinamento, o que representa um benefício duplo.
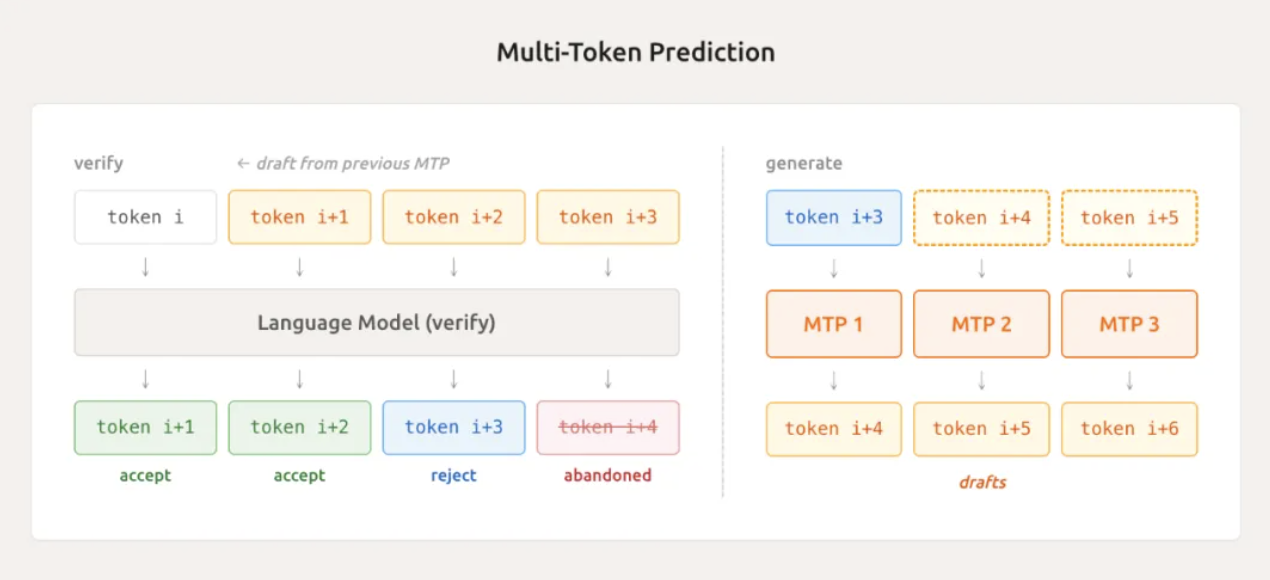
Luo Fuli mencionou que, com uma configuração MTP de três camadas, eles observaram um comprimento médio de aceitação superior a 3, resultando em uma aceleração de aproximadamente 2,5 vezes na tarefa de codificação. Isso resolve efetivamente o problema do tempo ocioso da GPU causado por "amostras de cauda longa" no aprendizado por reforço on-policy em mini-lotes.
O que são amostras de cauda longa? São aquelas tarefas particularmente difíceis e lentas que acabam por sobrecarregar outras tarefas, deixando a GPU congestionada. O MTP resolve esse problema, melhorando drasticamente a eficiência.
No entanto, Luo Fuli também admitiu que, devido a restrições de tempo, não conseguiram integrar totalmente o MTP ao ciclo de treinamento de RL desta vez, mas que ele é altamente compatível com o processo. A Xiaomi já disponibilizou o MTP de três camadas em código aberto, facilitando o uso e o desenvolvimento por qualquer pessoa em seus próprios projetos.
Como o desempenho não pode ser comprometido quando apenas 1/50 da capacidade computacional é utilizada?
Durante a fase de pré-treinamento, o novo modelo utiliza precisão mista FP8 e é treinado com 27 trilhões de tokens de dados, suportando nativamente sequências de até 32k.
A precisão mista FP8 é uma técnica para comprimir representações numéricas, o que pode reduzir o uso de memória e acelerar o treinamento, mantendo a precisão. Esse método de treinamento não é comum na indústria e requer uma otimização profunda da estrutura subjacente.
Na fase final de treinamento, a Xiaomi apresentou uma grande inovação ao propor a Destilação de Estratégia Online Multiprofessor (MOPD).
Os métodos tradicionais de aprendizado por reforço com ajuste fino supervisionado não são apenas instáveis durante o treinamento, mas também extremamente dispendiosos em termos computacionais. A abordagem MOPD consiste em fazer com que o modelo aluno realize amostragens em sua própria distribuição de políticas e, em seguida, que múltiplos professores especialistas forneçam sinais de recompensa densos em cada posição do token.
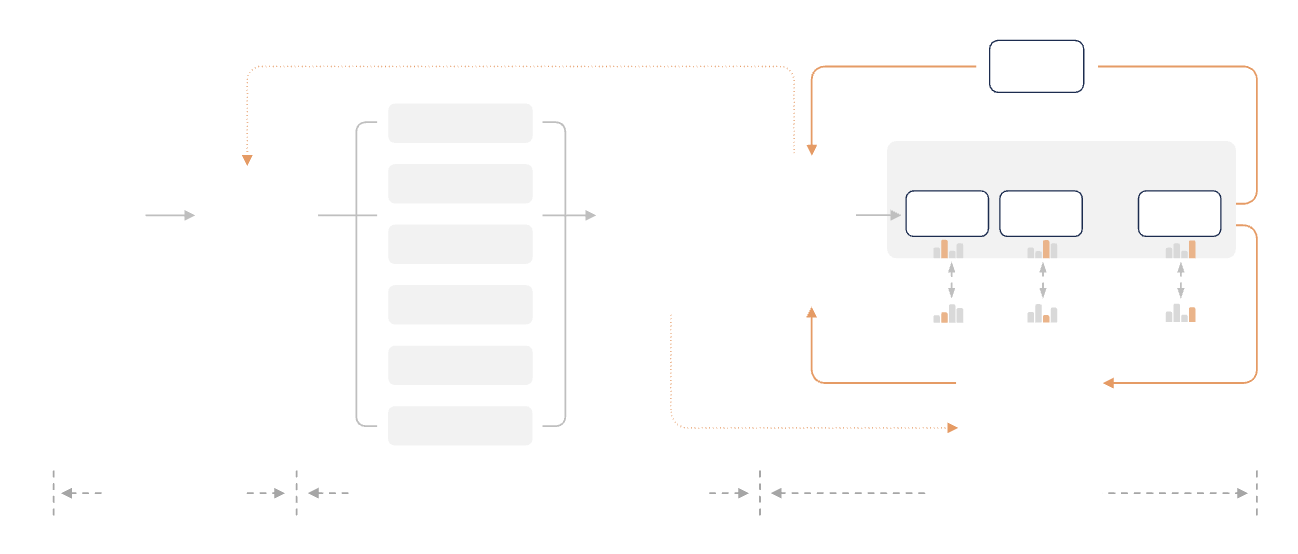
Em termos mais simples, o aluno realiza a tarefa de casa de forma independente, e o professor corrige cada palavra individualmente, sem esperar que o texto esteja completo. Isso permite que o aluno aprenda rapidamente os conceitos essenciais com o professor, e o processo de aprendizagem torna-se muito mais estável.
A melhoria mais notável reside na eficiência. O MOPD requer apenas 1/50 da capacidade computacional dos métodos tradicionais para permitir que os modelos dos alunos alcancem o desempenho máximo dos modelos dos professores. Isso significa que a Xiaomi pode iterar modelos mais rapidamente com menos recursos.
Além disso, o MOPD apoia a integração flexível de novos professores, e os alunos-modelo podem se tornar professores depois de crescerem, formando um ciclo fechado de autoevolução de "ensino e aprendizagem". Os alunos de hoje podem se tornar os professores de amanhã, e depois de amanhã podem formar alunos ainda mais capacitados. Essa abordagem, como uma boneca russa, é verdadeiramente genial.
Nas palavras de Luo Fuli, eles adotaram o método de Destilação On-Policy das Máquinas Pensantes para fundir múltiplos modelos de aprendizado por reforço, resultando em uma melhoria notável na eficiência. Isso lançou as bases para a construção de um sistema de ciclo de auto-reforço, onde os modelos dos alunos podem evoluir gradualmente para modelos de professores mais robustos.
Em termos de extensões de aprendizado por reforço para agentes, a equipe de pesquisa Xiaomi MiMo-V2-Flash criou mais de 100.000 tarefas verificáveis com base em problemas reais do GitHub. O pipeline automatizado é executado em um cluster Kubernetes, capaz de executar mais de 10.000 Pods simultaneamente, com uma taxa de sucesso de implantação de ambiente de 70%.
Para tarefas de desenvolvimento web, também foi desenvolvido um validador multimodal. Ele verifica os resultados da execução do código gravando vídeos em vez de capturas de tela estáticas, reduzindo diretamente as ilusões visuais e garantindo que as funções estejam corretas.
Para desenvolvedores, o MiMo-V2-Flash pode ser integrado perfeitamente a ambientes de desenvolvimento convencionais, como Claude Code, Cursor e Cline, e sua janela de contexto ultralonga de 256k suporta centenas de rodadas de interação com agentes e chamadas de ferramentas.
O que significa 256k? É aproximadamente o equivalente a um romance de tamanho médio ou algumas dezenas de páginas de documentação técnica. Isso significa que os desenvolvedores podem integrar o MiMo-V2-Flash diretamente em seus fluxos de trabalho existentes sem qualquer adaptação adicional; eles podem usá-lo imediatamente, sem necessidade de adaptações.
A Xiaomi também contribuiu com todo o seu código de inferência para o SGLang e compartilhou sua experiência em otimização de inferência no blog da LMSYS.
O relatório técnico revela detalhes completos do modelo, e os pesos do modelo (incluindo MiMo-V2-Flash-Base) são disponibilizados pela Hugging Face sob a licença MIT. Essa abordagem abrangente de código aberto é verdadeiramente rara entre as principais empresas chinesas.
O MiMo-V2-Flash está disponível gratuitamente na plataforma API por tempo limitado, permitindo que os desenvolvedores comecem a usá-lo imediatamente.
As ambições da Xiaomi em IA vão muito além de um simples assistente para dispositivos móveis.
O lançamento do MiMo-V2-Flash marca o esforço total da Xiaomi no campo da IA (Inteligência Artificial).
Luo Fuli revelou mais informações nas redes sociais: "O MiMo-V2-Flash foi oficialmente lançado. Este é apenas o segundo passo em nosso roteiro de Inteligência Artificial Geral (AGI)." O segundo passo já é impressionante, então que outras grandes surpresas nos aguardam? É algo para se aguardar com expectativa.
É claro que a Xiaomi também admitiu francamente em seu relatório técnico que o MiMo-V2-Flash ainda está atrás dos modelos proprietários mais robustos. No entanto, seu plano é claro: reduzir essa diferença aumentando o tamanho do modelo e o poder computacional de treinamento, enquanto continua a explorar arquiteturas de agentes mais robustas e eficientes.
A coevolução iterativa dos modelos de professor e aluno no âmbito da estrutura MOPD também oferece amplo espaço para o aprimoramento futuro das capacidades.
Em uma perspectiva mais ampla, isso representa uma aposta estratégica da Xiaomi em todo o ecossistema de IA. De smartphones e IoT a automóveis, o ecossistema de hardware da Xiaomi precisa de uma base sólida de IA, e o MiMo-V2-Flash é claramente a pedra angular que a Xiaomi está preparando para todo o seu ecossistema de hardware.
Assim como a Xiaomi redefiniu o padrão de preço para celulares topo de linha há uma década com seu aparelho de 1999 yuans, o MiMo-V2-Flash agora está redefinindo o padrão de desempenho para grandes modelos de código aberto, com um custo de US$ 0,1 por milhão de tokens e uma pontuação de 73,4% no SWE-Bench.
Desta vez, o "momento Xiaomi" pertencente ao modelo de código aberto realmente chegou.
Endereço do modelo HuggingFace:
http://hf.co/XiaomiMiMo/MiMo-V2-Flash
Endereço do relatório técnico:
http://github.com/XiaomiMiMo/MiMo-V2-Flash/blob/main/paper.pdf
#Siga a conta oficial do iFanr no WeChat: iFanr (ID do WeChat: ifanr), onde você encontrará conteúdo ainda mais interessante o mais breve possível.
