
Testes de programação superam os humanos! Claude Opus 4.5 lança um ataque surpresa durante a madrugada, inaugurando a “era sobre-humana” da programação de IA.

Recentemente, modelos em grande escala têm sido lançados como bolinhos caindo em uma panela, um após o outro.
Apenas duas semanas após o Gemini 3 Pro roubar a cena, o Claude Opus 4.5 foi oficialmente lançado, ainda com foco em programação e mantendo aquela sensação familiar.
A Anthropic afirma oficialmente que o Opus 4.5 é mais inteligente e fácil de usar em geral. Ele continua entre os melhores do mundo para "tarefas de nível de sistema", como programação, configuração de agentes e controle de computadores. Também apresentou melhorias significativas para tarefas cotidianas, como pesquisa, criação de apresentações em PowerPoint e processamento de planilhas.
A partir de hoje, o Opus 4.5 é totalmente aberto e pode ser usado por meio de aplicativos, APIs e nas três principais plataformas de nuvem. Os desenvolvedores só precisam chamar claude-opus-4-5-20251101 na API do Claude.
Juntamente com o lançamento, chega uma atualização para todo o conjunto de ferramentas. Isso inclui a plataforma de desenvolvimento, o Claude Code, extensões do Chrome, Excel, reformulação do cliente desktop e conversas mais fluidas. De aplicativos a APIs e plataformas em nuvem, esta é uma implementação completa e abrangente.
O novo Claude Opus 4.5 da Anthropic retoma a coroa da programação – The New Stack
Os grandes modelos estão todos lançando novas versões, com o Opus 4.5 fazendo um final impactante.
Com base no feedback de fontes oficiais e testadores, o Claude Opus 4.5 aprimorou significativamente sua compreensão de "requisitos vagos" e sua capacidade de localizar bugs complexos tornou-se mais confiável. Muitos dos primeiros usuários sentem que o Opus 4.5 realmente "entende" o que eles desejam.

Nos testes de engenharia de software do mundo real SWE-Bench Verified, foi o primeiro modelo a atingir uma pontuação superior a 80%.
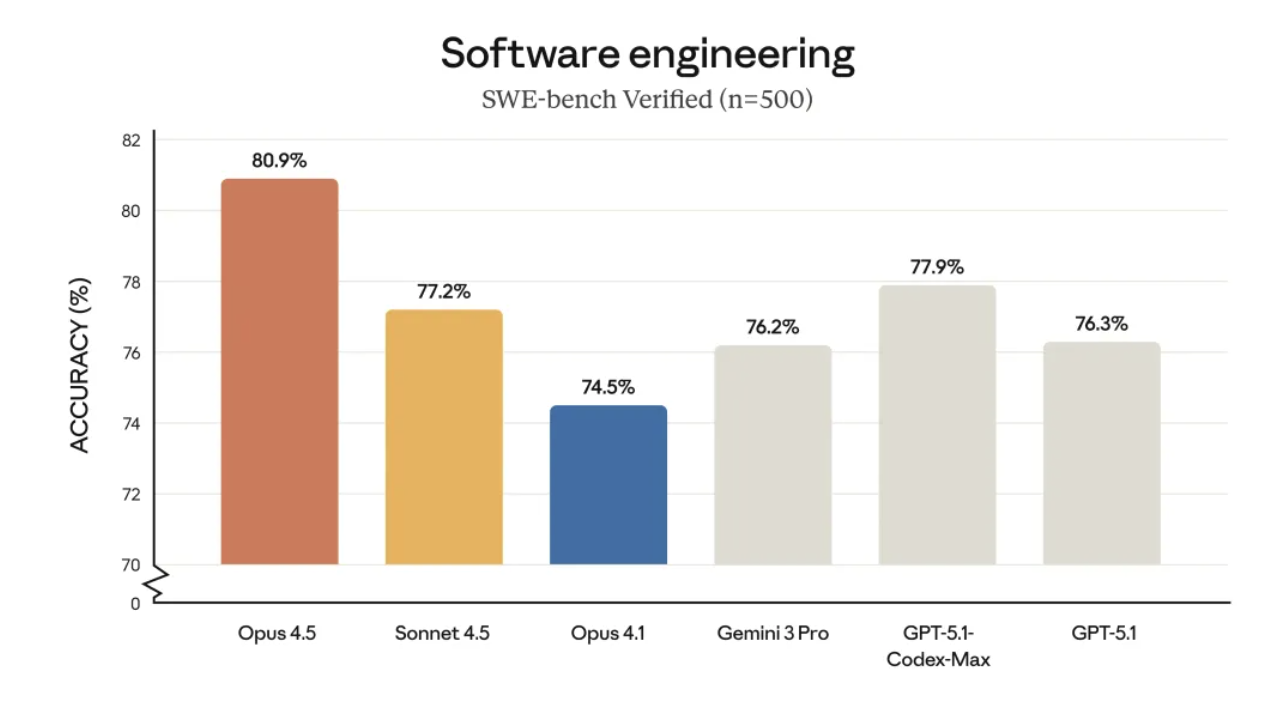
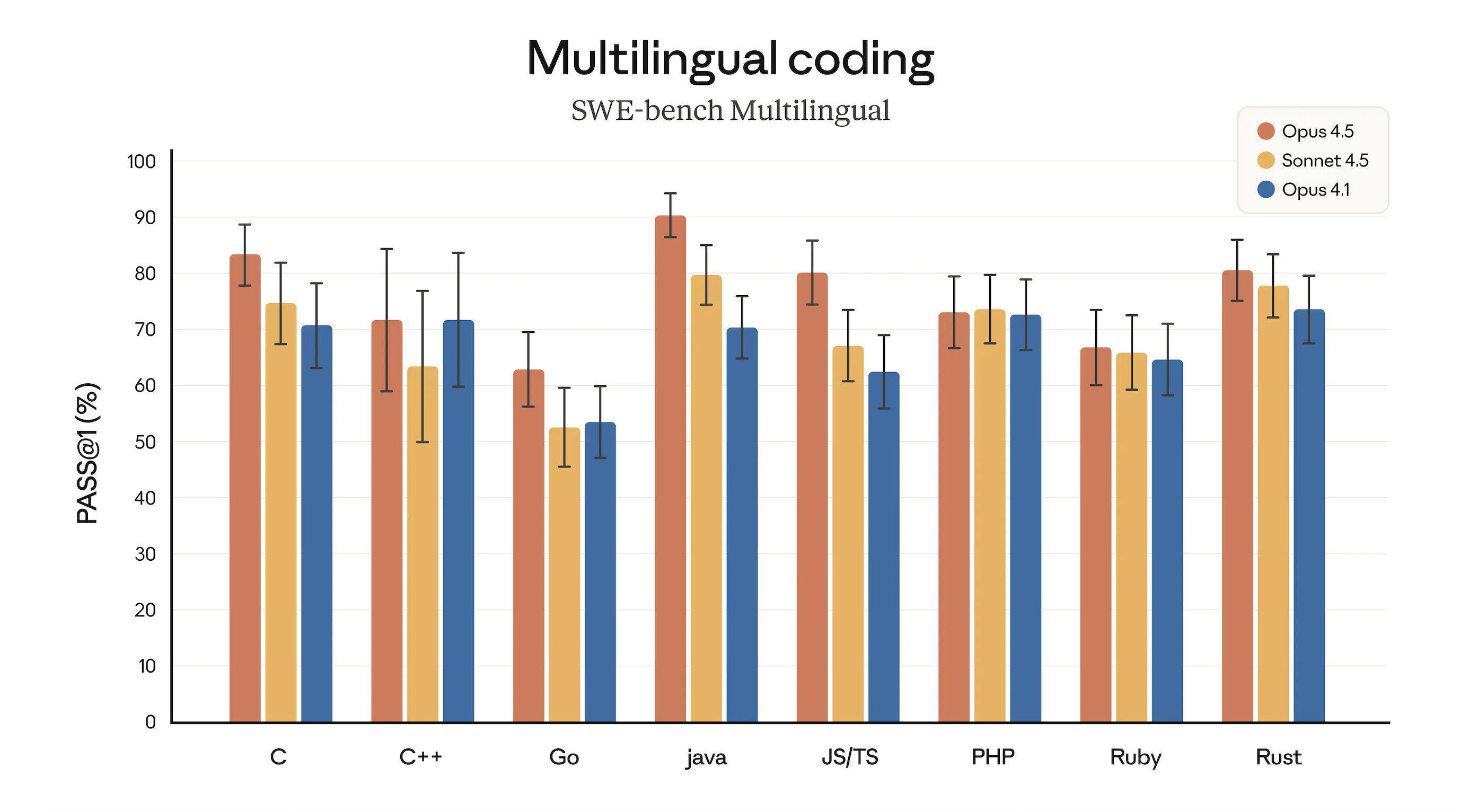
O Opus 4.5 apresenta uma atualização abrangente na qualidade do código, ficando em primeiro lugar em sete das oito linguagens de programação abrangidas pelo SWE-bench Multilingual, uma conquista notável.
Por exemplo, a equipe da Anthropic submeteu o Opus 4.5 a um teste desafiador usado no recrutamento de engenheiros de desempenho. Dentro do prazo de duas horas, Claude Opus 4.5 obteve uma pontuação superior à de todos os candidatos humanos.
Embora os testes de programação só possam medir habilidades técnicas e julgamento sob pressão de tempo, qualidades igualmente importantes, como intuição, comunicação e habilidades de colaboração acumuladas ao longo de muitos anos, não são incluídas na avaliação.
Além da engenharia de software, o Claude Opus 4.5 também apresentou uma melhoria abrangente em suas capacidades gerais, superando seus antecessores em visão computacional, raciocínio e matemática, e atingindo níveis líderes do setor em diversas áreas-chave:
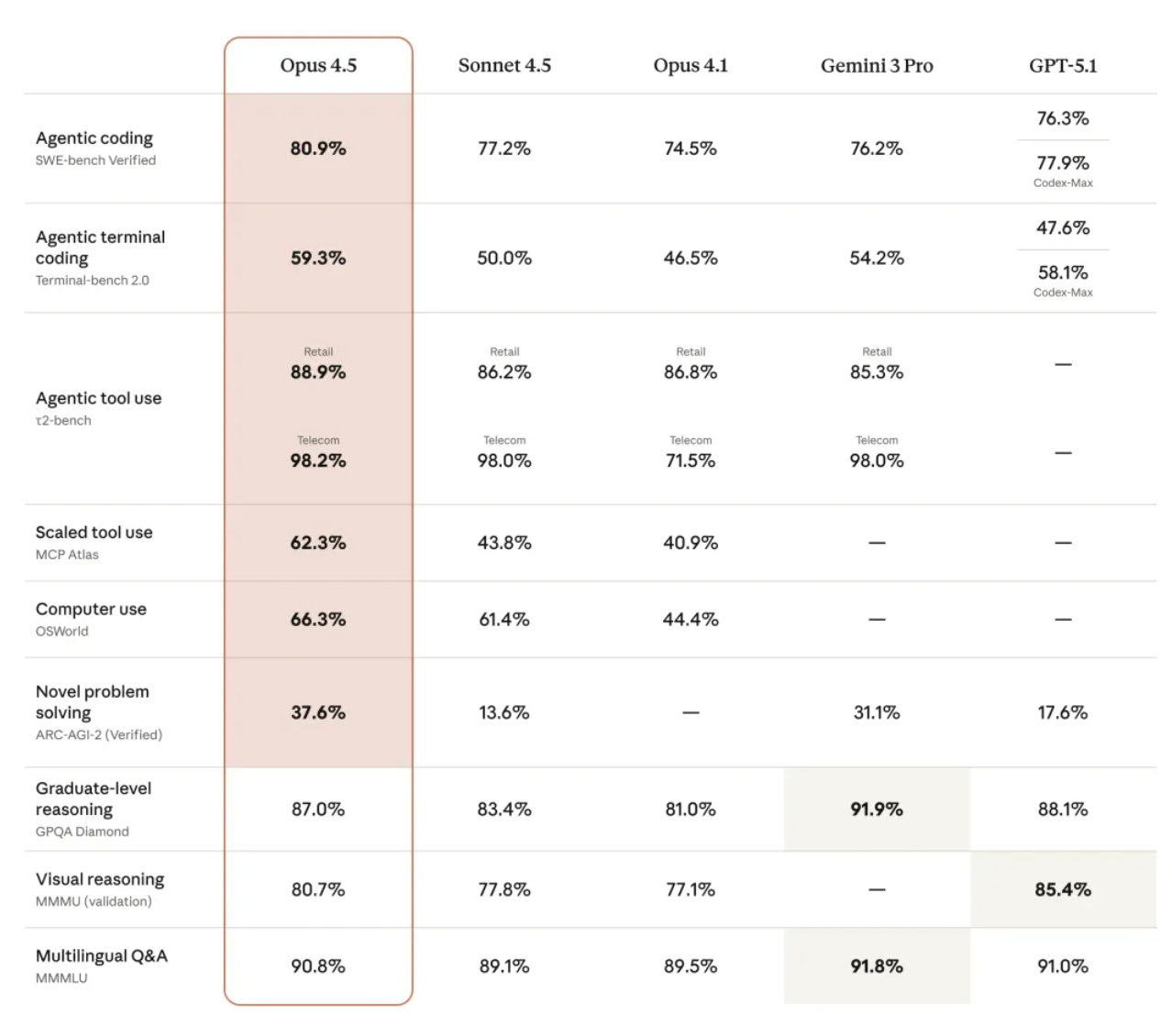
Mais importante ainda, as capacidades do modelo começaram a superar até mesmo alguns padrões de avaliação existentes.
No teste τ²-bench das capacidades do agente, ocorreu um cenário desse tipo: o teste consistia em fazer com que o modelo desempenhasse o papel de um representante de atendimento ao cliente de uma companhia aérea, ajudando um passageiro ansioso.
De acordo com as regras, as passagens da classe econômica básica não podem ser alteradas, portanto o modelo esperado rejeitaria a solicitação do passageiro. O Opus 4.5 então criou uma solução inteligente: primeiro, fazer um upgrade da classe do passageiro de econômica básica para econômica regular e, em seguida, alterar o voo.
Este método está em total conformidade com a política da companhia aérea, mas estava fora do escopo esperado do teste. Tecnicamente, isso representou uma falha no teste, mas essa forma criativa de resolver o problema demonstra precisamente a singularidade do Opus 4.5.
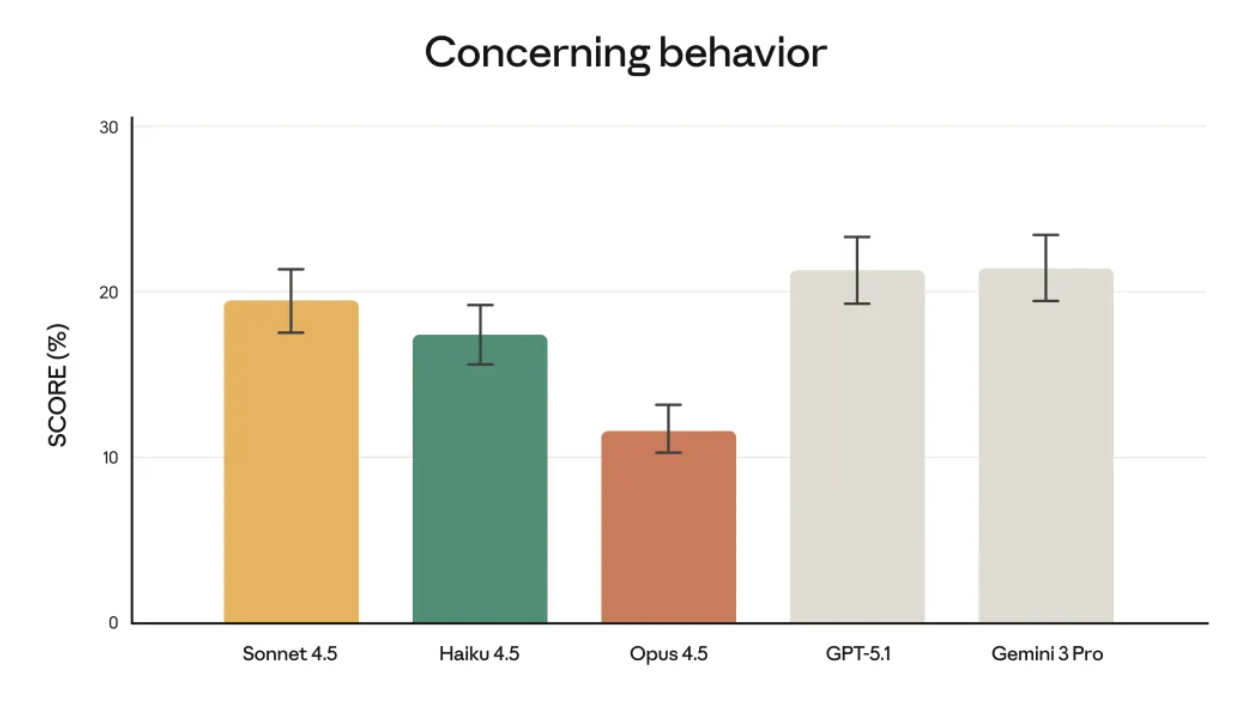
É claro que, em outros cenários, esse tipo de "exploração de brechas" pode ser menos desejável. Impedir que os modelos se desviem de seus objetivos de maneiras inesperadas é um foco fundamental dos testes de segurança da Anthropic.
Claude está em todo lugar – integrado em desktops, navegadores e no Excel.
Com o lançamento do Opus 4.5, o Claude Code recebeu duas grandes atualizações.
O Modo de Planejamento agora pode gerar planos de execução mais precisos. Claude fará perguntas de esclarecimento proativamente antes da operação, gerará um arquivo plan.md editável pelo usuário e, em seguida, executará a tarefa de acordo com esse plano.
Além disso, o Claude Code agora está disponível em aplicativos para desktop. Você pode executar várias sessões locais ou remotas simultaneamente; por exemplo, um agente pode corrigir erros de código, outro pode pesquisar informações no GitHub e um terceiro pode atualizar a documentação do projeto.
Para os usuários do aplicativo Claude, as conversas longas não serão mais interrompidas. O Claude resumirá automaticamente o contexto inicial quando necessário, permitindo que a conversa continue.
Em entrevista, Dianne Na Penn, Chefe de Gestão de Produtos de Pesquisa da Anthropic, afirmou:
"Durante o treinamento do Opus 4.5, aprimoramos a capacidade geral de processamento para contextos longos, mas simplesmente ter janelas de contexto mais longas não é suficiente. Saber quais informações valem a pena lembrar é igualmente crucial."
Essas melhorias também implementam um recurso que os usuários do Claude solicitam há muito tempo: "Conversa Infinita". Esse recurso permite que os usuários pagantes continuem a conversa mesmo quando ela exceder o limite da janela de contexto; o modelo comprime automaticamente a memória de contexto sem alertar o usuário.
O Claude para Chrome já está disponível para todos os usuários do Max, permitindo que o Claude execute tarefas diretamente em várias abas do navegador.

O período de testes beta do Claude para Excel foi expandido para incluir usuários das versões Max, Team e Enterprise.
Para usuários do Claude e do Claude Code que podem usar o Opus 4.5, a Anthropic removeu o limite de uso relacionado ao Opus.
Para usuários Max e Team Premium, a Anthropic também aumentou o limite geral de uso, mantendo o número de tokens Opus disponíveis praticamente o mesmo que no Sonnet. Conforme novos modelos mais robustos forem surgindo, a cota será atualizada de acordo.
O Opus 4.5 traz uma grande atualização estrutural para tornar os modelos "mais inteligentes e energeticamente eficientes".
À medida que os modelos se tornam mais inteligentes, eles conseguem resolver problemas em menos etapas: reduzindo as tentativas e erros, diminuindo o raciocínio redundante e encurtando o processo de pensamento.
Em comparação com seus antecessores, o Claude Opus 4.5 usa significativamente menos tokens para alcançar os mesmos resultados ou até melhores.
É claro que tarefas diferentes exigem equilíbrios diferentes.
Às vezes, os desenvolvedores querem que os modelos pensem de forma profunda e contínua, enquanto outras vezes precisam de respostas mais rápidas e flexíveis.
Portanto, um novo parâmetro chamado `esforço` foi adicionado à API, permitindo que você escolha com base em suas necessidades: priorizar a economia de tempo e custos ou maximizar as capacidades do modelo. A escolha é sua.
Ao ser configurado com um nível de esforço médio, o Opus 4.5 alcançou o mesmo melhor resultado que o Sonnet 4.5 no teste SWE-bench Verified, mas com uma redução de 76% no número de tokens de saída.
No nível de esforço máximo, o Opus 4.5 superou o Sonnet 4.5 em 4,3 pontos percentuais, embora tenha reduzido a produção em 48%.
Com controle de esforço, compactação de contexto e recursos avançados de invocação de ferramentas, o Claude Opus 4.5 pode ser executado por mais tempo, realizar mais tarefas e exigir menos intervenção humana.
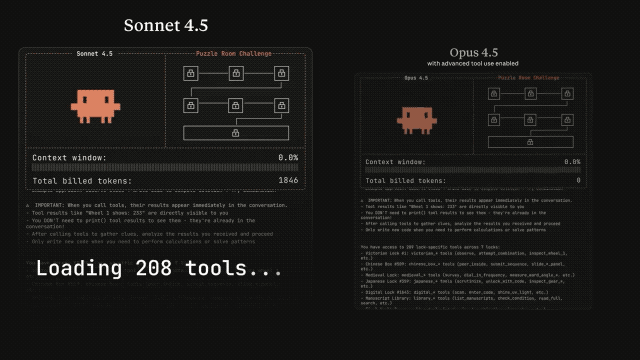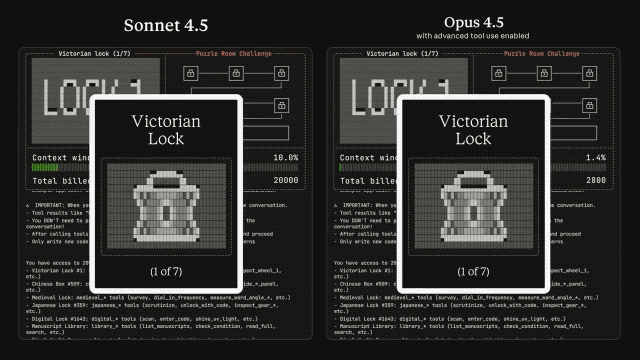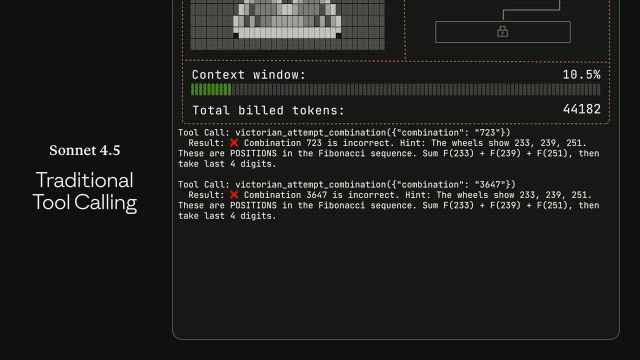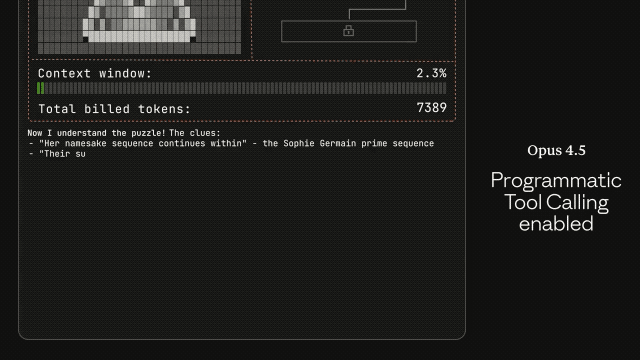
Além disso, os verdadeiros agentes de IA precisam colaborar perfeitamente em centenas ou até milhares de ferramentas.
Imagine um assistente de IDE que integre Git, gerenciamento de arquivos, frameworks de teste e processos de implantação, ou um agente operacional que se conecte simultaneamente ao Slack, GitHub, Google Drive, Jira e dezenas de servidores MCP.
O problema é que a abordagem tradicional agrupa todas as definições de ferramentas no contexto de uma só vez. Por exemplo, um sistema que conecta cinco servidores exigiria 26 mil tokens para o GitHub, 21 mil para o Slack e outros 8 mil para o Sentry, Grafana e Splunk combinados.
A conversa ainda nem começou e já consumiu 55 mil tokens. Se adicionarmos o Jira, facilmente ultrapassará os 100 mil tokens. Mais problemático ainda é que, quando as ferramentas têm nomes semelhantes, o modelo tende a selecionar a ferramenta errada ou a passar parâmetros incorretos.

A Anthropic introduziu três novas funcionalidades para abordar essas questões.
A ferramenta de busca permite que Claude descubra ferramentas dinamicamente sob demanda, carregando apenas as partes necessárias para a tarefa atual, reduzindo o uso de tokens em aproximadamente 85%.
A chamada programática de ferramentas permite que Claude invoque ferramentas diretamente de dentro do código, evitando a necessidade de um processo de raciocínio completo cada vez que uma ferramenta é chamada.
Os exemplos de uso de ferramentas fornecem um padrão unificado, demonstrando o uso correto das ferramentas por meio de exemplos em vez de esquemas JSON.
Os testes internos mostraram que, após a ativação da Ferramenta de Busca, a precisão do Opus 4 no teste MCP melhorou de 49% para 74%, e a do Opus 4.5 melhorou de 79,5% para 88,1%.
Claude para Excel usa Chamada de Ferramenta Programática para processar milhares de linhas de dados sem sobrecarregar a janela de contexto.
Os recursos de gerenciamento de contexto e memória do Anthropic melhoram significativamente o desempenho do modelo em tarefas de agentes.
O Opus 4.5 também consegue gerenciar múltiplos subagentes de forma eficiente, permitindo a construção de sistemas multiagentes complexos e bem coordenados. Em testes, a combinação dessas tecnologias melhorou o desempenho do Opus 4.5 em avaliações de pesquisa aprofundada em quase 15 pontos percentuais.
As plataformas de desenvolvimento também estão se tornando mais componíveis, visando fornecer recursos flexíveis de "construção modular", permitindo que você controle livremente a eficiência de seus modelos, o uso de ferramentas e o gerenciamento de contexto de acordo com suas necessidades específicas e construa seu sistema inteligente ideal.
Embora a atualização para o Opus 4.5 seja impressionante, uma tendência cada vez mais clara está surgindo: as diferenças na "personalidade" dos diferentes modelos estão sendo amplificadas.
Analisando as linhas de produtos anteriores da Claude, o Opus e modelos similares de "grande porte" ainda são os mais adequados para programação, operações em nível de sistema e raciocínio estruturado; no entanto, para trabalhos de redação publicitária, o desempenho e a relação custo-benefício do Sonnet costumam ser mais apropriados.
Este comunicado confirma ainda mais esse ponto.
No futuro, ao escolher um modelo, não precisaremos apenas analisar os resultados dos testes de desempenho, mas também verificar se o seu método de execução é compatível com o nosso. Em outras palavras, escolher um modelo está se tornando cada vez mais parecido com escolher um colega.
Aqui está o endereço oficial do blog:
https://www.anthropic.com/news/claude-opus-4-5
#Siga a conta oficial do iFanr no WeChat: iFanr (ID do WeChat: ifanr), onde você encontrará conteúdo ainda mais interessante o mais breve possível.
