
A DeepSeek acaba de lançar um novo modelo, levando modelos pequenos e bonitos a novos patamares.
Recentemente, o DeepSeek tornou público um modelo 3B, o DeepSeek-OCR. Embora o 3B seja pequeno em tamanho, ele contém inovações significativas em sua modelagem.
Como todos sabemos, todos os LLMs atuais enfrentam um dilema inevitável ao processar textos longos: a complexidade computacional cresce quadraticamente. Quanto maior a sequência, maior o poder computacional consumido.
Então, a equipe do DeepSeek teve uma ideia inteligente. Já que uma única imagem pode conter uma grande quantidade de informações textuais usando relativamente poucos tokens, por que não converter o texto diretamente em uma imagem? Isso é conhecido como "compressão óptica" — o uso de modalidades visuais para reduzir o tamanho das informações textuais.
O OCR é naturalmente adequado para verificar essa ideia porque realiza a conversão "visual→texto", e o efeito pode ser avaliado quantitativamente.
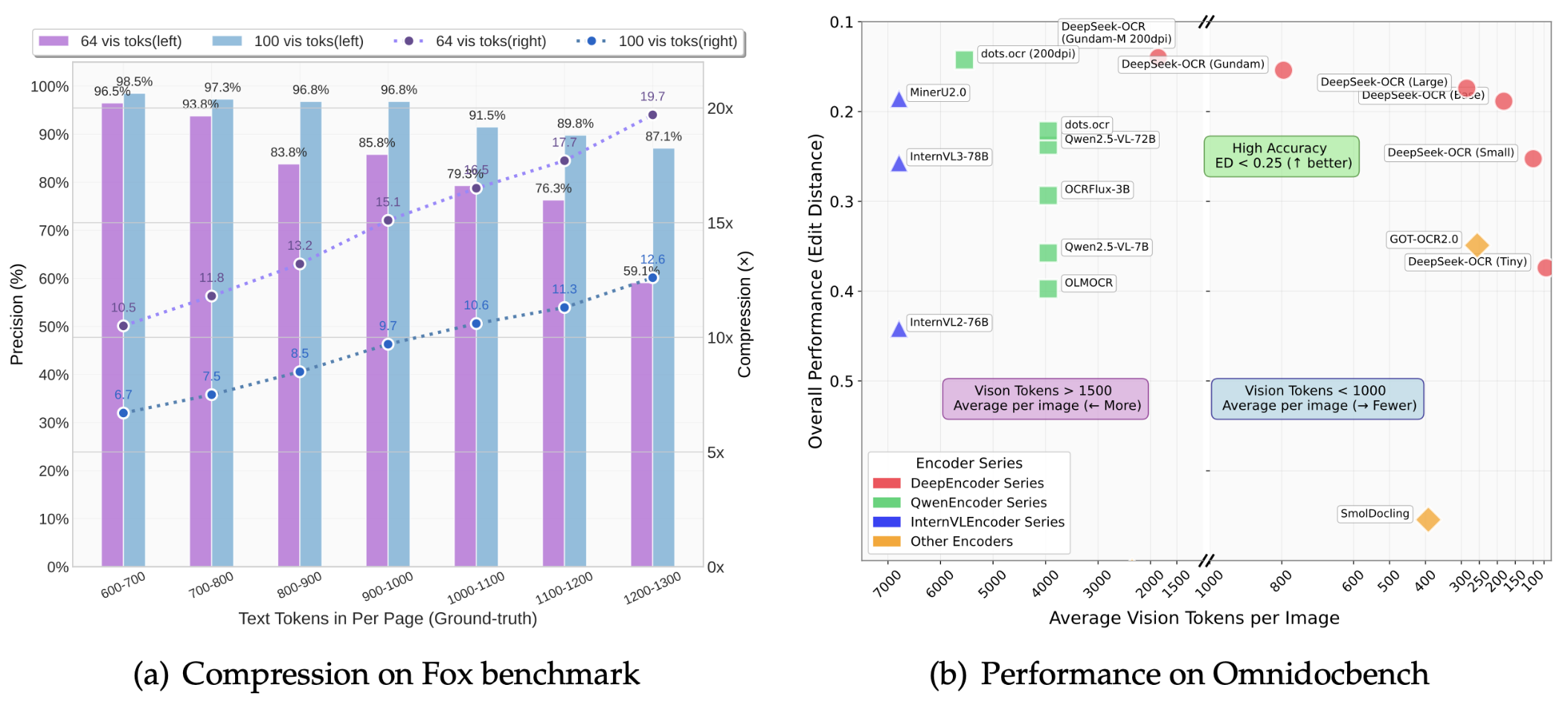
O artigo mostra que a taxa de compressão do DeepSeek-OCR pode chegar a 10 vezes, e a precisão do OCR pode ser mantida acima de 97%.
O que isso significa? Significa que o conteúdo que antes exigia 1.000 tokens de texto agora pode ser expresso com apenas 100 tokens visuais. Mesmo com uma taxa de compressão de 20x, a precisão permanece em torno de 60%, o que é bastante impressionante no geral.
Os resultados do benchmark OmniDocBench mostram:
- Usando apenas 100 tokens visuais, ele supera o desempenho do GOT-OCR2.0 (256 tokens por página)
- Com menos de 800 tokens visuais, ele superou o MinerU2.0 (mais de 6.000 tokens por página em média)
Na produção real, uma única placa gráfica A100-40G pode gerar mais de 200.000 páginas de dados de treinamento LLM/VLM por dia. Com 20 nós (160 A100s), o número sobe para 33 milhões de páginas por dia.
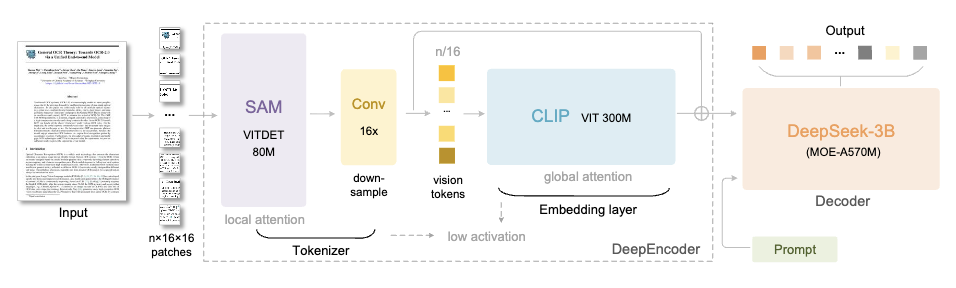
O DeepSeek-OCR consiste em dois componentes principais:
- DeepEncoder (codificador): responsável pela extração e compressão de recursos de imagem
- DeepSeek3B-MoE (decodificador): responsável por reconstruir texto a partir de tokens visuais compactados
Vamos nos concentrar no mecanismo DeepEncoder.
Sua arquitetura é muito inteligente. Ao conectar o SAM-base (80 milhões de parâmetros) e o CLIP-large (300 milhões de parâmetros), o primeiro é responsável pela "atenção da janela" para extrair recursos visuais, e o último é responsável pela "atenção global" para compreender as informações gerais.
Um compressor de convolução 16× é adicionado no meio para reduzir significativamente o número de tokens antes de entrar na camada de atenção global.
Por exemplo, uma imagem de 1024×1024 será cortada em 4096 tokens de patch. No entanto, após o processamento do compressor, o número de tokens que entram na camada de atenção global será bastante reduzido.
A vantagem disso é que garante a capacidade de processar entradas de alta resolução enquanto controla a sobrecarga da memória de ativação.
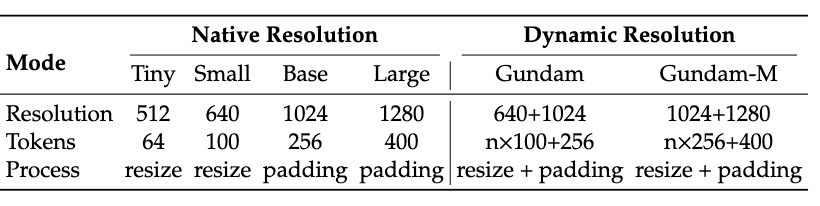
Além disso, o DeepEncoder também suporta entrada multirresolução, do modo Tiny 512×512 (64 Tokens) ao modo Large 1280×1280 (400 Tokens), tudo controlado por um modelo.
A versão de código aberto atualmente suporta quatro modos: Tiny, Small, Base e Large em resolução nativa, bem como o modo Gundam em resolução dinâmica, o que maximiza a flexibilidade.
O decodificador usa a arquitetura DeepSeek-3B-MoE.
Apesar de ter apenas 3 bilhões de parâmetros, o modelo utiliza um design de especialistas mistos (MoE), ativando 6 de 64 especialistas, além de 2 especialistas compartilhados, para um total real de aproximadamente 570 milhões de parâmetros ativados. Isso confere ao modelo o poder expressivo de um modelo de 3 bilhões de parâmetros, mantendo a eficiência de inferência de um modelo de 500 milhões de parâmetros.
A tarefa do decodificador é reconstruir o texto original a partir dos tokens visuais compactados, um processo que pode ser efetivamente aprendido pelo modelo de linguagem compacta por meio de treinamento no estilo OCR.
Em termos de dados, a equipe do DeepSeek também investiu bastante.
30 milhões de páginas de dados PDF multilíngues foram coletadas da Internet, abrangendo cerca de 100 idiomas, dos quais chinês e inglês representaram 25 milhões de páginas.
Os dados são divididos em duas categorias: anotações grosseiras são extraídas diretamente do PDF usando o Fitz, principalmente para treinar os recursos de reconhecimento de alguns idiomas; anotações finas são geradas usando modelos como PP-DocLayout, MinerU e GOT-OCR2.0 e contêm dados de alta qualidade que interligam detecção e reconhecimento.
Para alguns idiomas, a equipe também desenvolveu um mecanismo de "roda de inércia de modelo" – primeiro usando um modelo de análise de layout com recursos de generalização entre idiomas para detecção, depois usando os dados gerados pelo Fitz para treinar o GOT-OCR2.0 e, então, usando o modelo treinado para anotar mais dados, repetindo esse ciclo para, eventualmente, gerar 600.000 amostras.
Além disso, há 3 milhões de dados de documentos do Word, o que melhora principalmente os recursos de reconhecimento de fórmulas e análise de tabelas HTML.
Para o OCR de cena, coletamos imagens dos conjuntos de dados LAION e Wukong e as anotamos usando o PaddleOCR, com 10 milhões de amostras em chinês e inglês.

O DeepSeek-OCR não apenas reconhece texto, mas também possui recursos de "análise profunda". Com apenas uma palavra-chave unificada, ele pode realizar extração estruturada em diversas imagens complexas:
- Gráficos: Os gráficos em relatórios de pesquisa financeira podem ser extraídos diretamente como dados estruturados
- Estruturas químicas: Identifique e converta para o formato SMILES
- Geometria: Cópia e análise estruturada da geometria plana
- Imagens naturais: gerando legendas densas
Isso tem grande potencial de aplicação em áreas STEM, especialmente em cenários como química, física e matemática, que exigem o processamento de um grande número de símbolos e gráficos.
Aqui temos que mencionar uma ideia criativa proposta pela equipe do DeepSeek: usar compressão óptica para simular o mecanismo de esquecimento humano.
A memória humana se degrada com o tempo, com as memórias de eventos mais antigos se tornando cada vez mais confusas. A equipe do DeepSeek se perguntou se a IA conseguiria fazer o mesmo. A solução:
- Renderize o conteúdo da conversa histórica além da rodada k em uma imagem
- Compressão inicial, atingindo cerca de 10 vezes a redução do token
- Para mais contexto, continue a reduzir o tamanho da imagem
- À medida que a imagem fica menor, o conteúdo fica cada vez mais desfocado, chegando ao efeito de "esquecimento do texto".
Isso é muito semelhante à curva de decaimento da memória humana, onde informações recentes mantêm alta fidelidade, enquanto memórias de longo prazo desaparecem naturalmente.
Embora esta ainda seja uma direção de pesquisa inicial, se puder ser realizada, será um grande avanço no processamento de contextos ultralongos – o contexto recente mantém alta resolução, o contexto histórico ocupa menos recursos de computação e, teoricamente, pode suportar "contexto infinito".
Em suma, o DeepSeek-OCR é um modelo de OCR superficialmente, mas na verdade ele explora uma proposta mais ampla: a modalidade visual pode ser usada como um meio de compressão eficiente para processamento de informações de texto LLM?
A resposta preliminar é sim, e a capacidade de compressão de tokens de 7 a 20 vezes foi demonstrada.
É claro que a equipe reconhece que isso é apenas o começo. O OCR por si só não é suficiente para validar completamente a Compressão Óptica Contextual. Eles planejam realizar subsequentes pré-treinamentos alternados de texto digital para óptico, testes de "agulha no palheiro" e outras avaliações sistemáticas.
Mas não importa o que aconteça, isso acrescenta um novo caminho à evolução do VLM e do LLM.
Nessa mesma época do ano passado, todos ainda estavam pensando em como fazer o modelo "lembrar mais".
Este ano, o DeepSeek adotou a abordagem oposta: e se o modelo aprendesse a "esquecer" algo? De fato, a evolução da IA às vezes envolve subtração, não adição. Pequenos e belos também podem realizar grandes feitos, e o pequeno modelo 3B DeepSeek-OCR é a prova perfeita disso.
Página inicial do GitHub:
http://github.com/deepseek-ai/DeepSeek-OCR
papel:
https://github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf
Download do modelo:
https://huggingface.co/deepseek-ai/DeepSeek-OCR
#Bem-vindo a seguir a conta pública oficial do WeChat do iFaner: iFaner (ID do WeChat: ifanr), onde mais conteúdo interessante será apresentado a você o mais breve possível.
