
Agora mesmo, a OpenAI lançou três novos modelos de uma só vez! Também fiz um novo site para esse fim
Agora mesmo, a OpenAI anunciou o lançamento de uma nova geração de modelos de áudio em sua API, incluindo funções de fala para texto e texto para fala, permitindo que os desenvolvedores criem facilmente agentes de voz poderosos.
Os principais destaques do novo produto estão resumidos abaixo
- gpt-4o-transcribe (fala para texto): redução significativa na taxa de erro de palavras (WER), superando os modelos Whisper existentes em vários benchmarks
- gpt-4o-mini-transcribe (fala para texto): uma versão simplificada do gpt-4o-transcribe, mais rápida e eficiente
- gpt-4o-mini-tts (conversão de texto para fala): Suportando "orientabilidade" pela primeira vez, os desenvolvedores podem não apenas especificar "o que dizer", mas também controlar "como dizer"
De acordo com a OpenAI, o recém-lançado gpt-4o-transcribe foi treinado por um longo tempo usando conjuntos de dados de áudio diversos e de alta qualidade, que podem capturar melhor as nuances da fala, reduzir o reconhecimento incorreto e melhorar significativamente a confiabilidade da transcrição.
Portanto, gpt-4o-transcribe é mais adequado para lidar com cenários desafiadores, como sotaques diversos, ambientes barulhentos e mudanças na velocidade da fala, como centrais de atendimento de clientes, transcrições de reuniões e outros campos.
gpt-4o-mini-transcribe é baseado na arquitetura GPT-4o-mini e transfere recursos de modelos grandes por meio da tecnologia de destilação de conhecimento. Embora o WER (quanto menor, melhor) seja um pouco maior que o modelo da versão completa, ele ainda é melhor que o modelo Whisper original e é mais adequado para cenários de aplicação com recursos limitados, mas que ainda exigem reconhecimento de fala de alta qualidade.
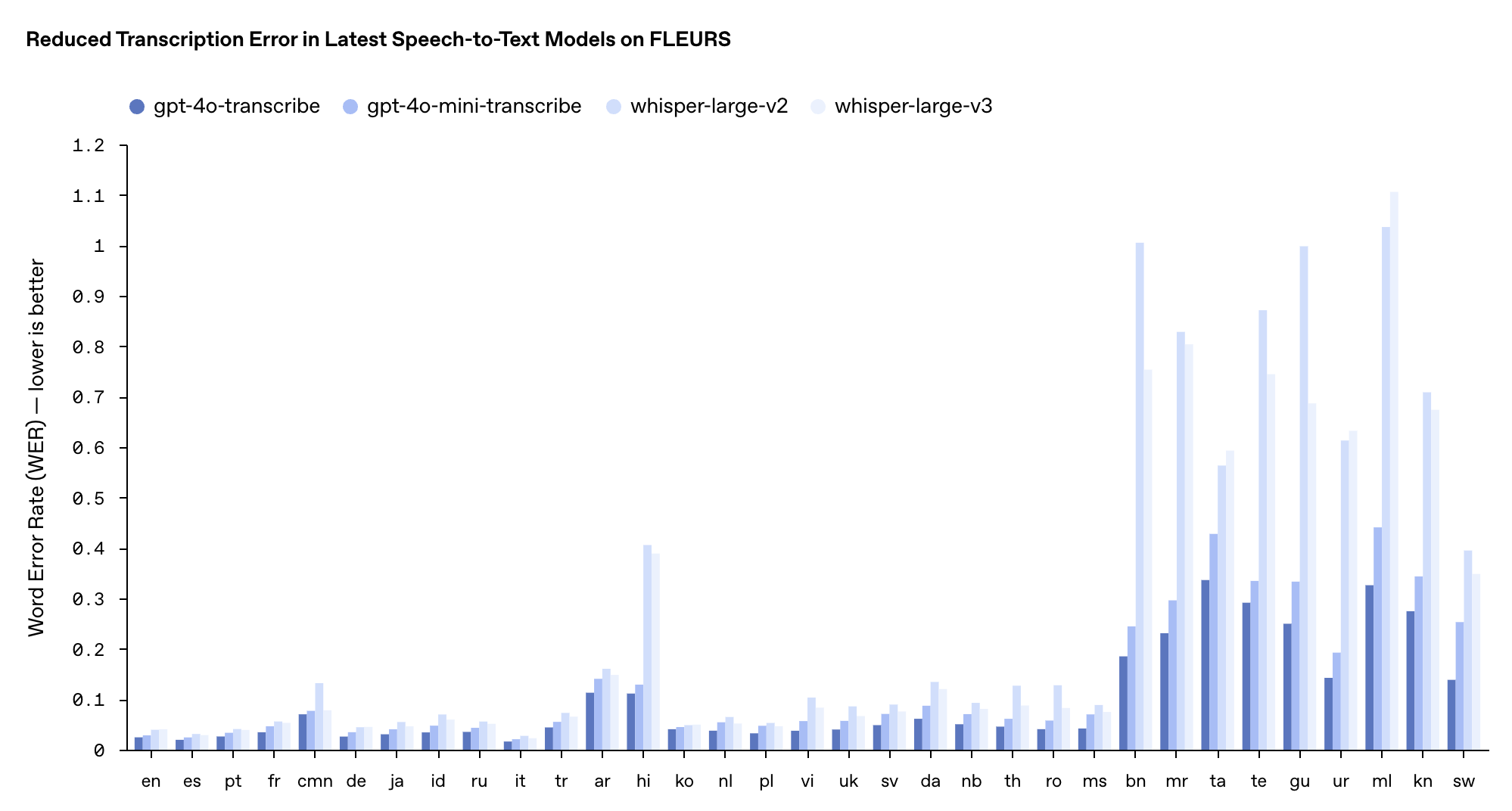
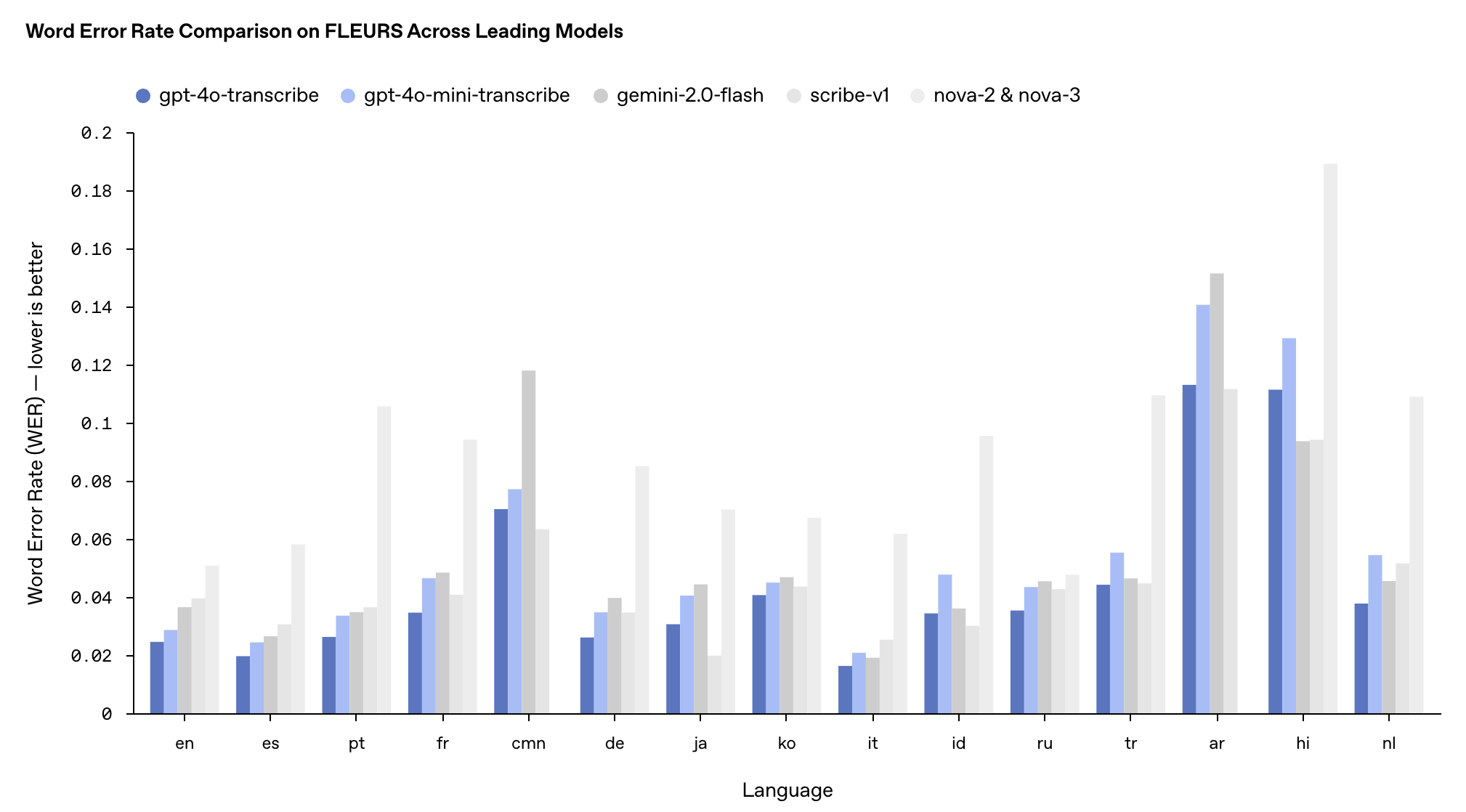
O desempenho destes dois modelos no teste de benchmark multilíngue FLEURS superou os modelos Whisper v2 e v3 existentes, especialmente em inglês, espanhol e outros idiomas.
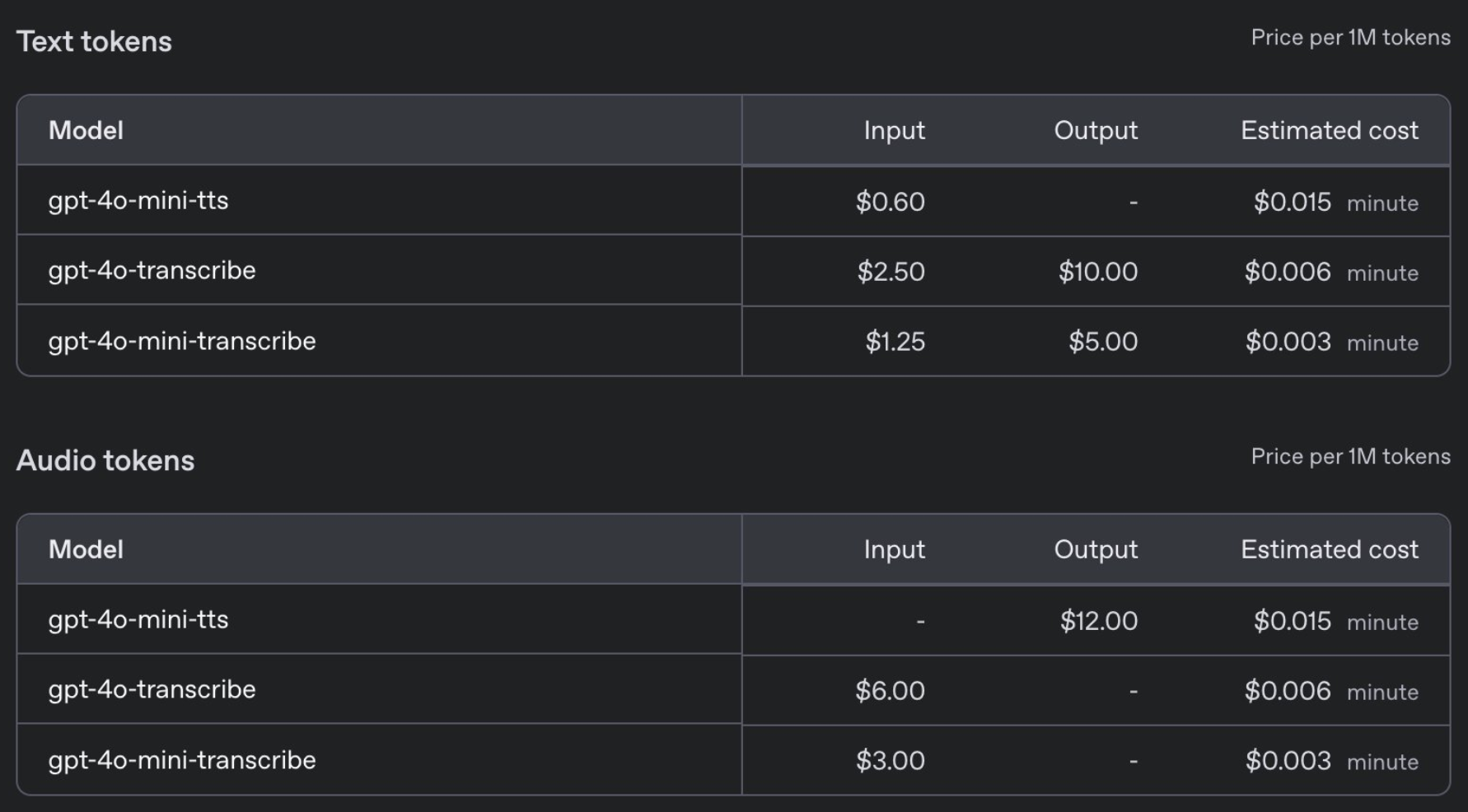
Em termos de preço, o GPT-4o-transcribe tem o mesmo preço do modelo Whisper anterior, US$ 0,006 por minuto, enquanto o GPT-4o-mini-transcribe custa metade do preço, US$ 0,003 por minuto.
Ao mesmo tempo, a OpenAI também lançou um novo modelo de conversão de texto em fala gpt-4o-mini-tts. Pela primeira vez, os desenvolvedores podem não apenas especificar o que dizer, mas também controlar como dizer.
Especificamente, os desenvolvedores podem predefinir uma variedade de estilos de voz, como "Calmo", "Surfista", "Profissional", "Cavaleiro Medieval" etc. Ele também pode ajustar o estilo de voz de acordo com instruções, como "Fale como um agente de atendimento ao cliente compassivo".
A segurança não pode ser menosprezada, e a OpenAI afirma que o gpt-4o-mini-tts será monitorado continuamente para garantir que sua saída seja consistente com o estilo de síntese predefinido.
Por trás desses avanços tecnológicos estão muitas inovações da OpenAI:
- O novo modelo de áudio é construído na arquitetura GPT-4o e GPT-4o-mini e é pré-treinado usando conjuntos de dados de áudio reais
- Aplique o método de destilação de conhecimento de conjuntos de dados destilados criados pelo método self-play para obter a transferência de conhecimento de modelos grandes para modelos pequenos.
- A integração da aprendizagem por reforço (RL) na tecnologia de fala para texto pode melhorar significativamente a precisão da transcrição e reduzir os fenômenos de "ilusão".
Na transmissão ao vivo da manhã, a OpenAI nos mostrou um caso de aplicação do agente consultor de moda de IA.
Quando o usuário perguntou “Qual é o meu último pedido?”, o sistema respondeu sem problemas: os shorts Patagonia encomendados pelo usuário em 9 de fevereiro foram enviados e o número do pedido “AD 507” foi fornecido com precisão na pergunta de acompanhamento.
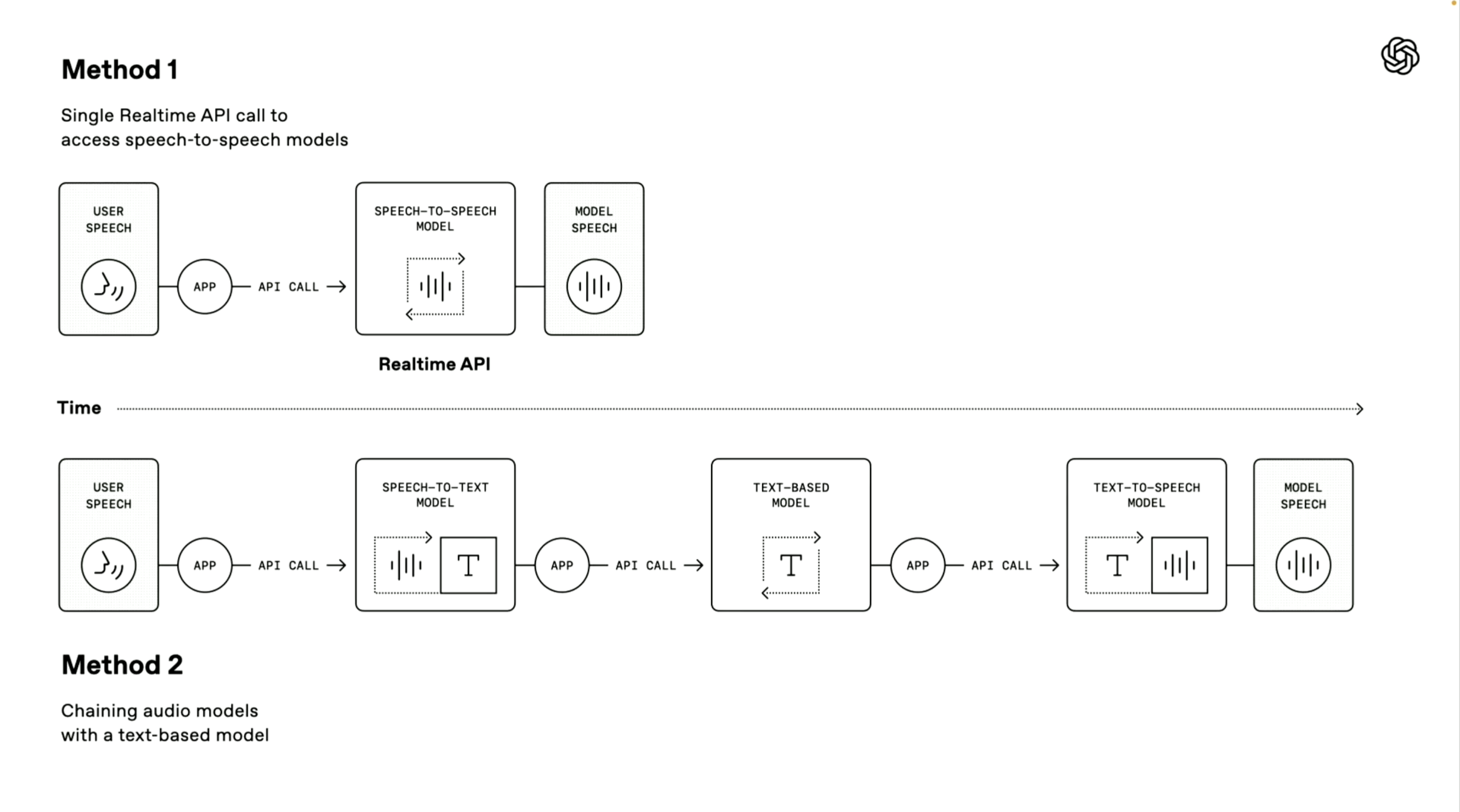
Vale ressaltar que o demonstrador OpenAI também introduziu dois caminhos técnicos para a construção de um agente de voz. O primeiro "modelo de fala para fala" utiliza um método de processamento direto de ponta a ponta.
O sistema pode receber diretamente a entrada de voz do usuário e gerar respostas de voz sem etapas intermediárias de conversão. Este método possui velocidade de processamento mais rápida e foi aplicado no modo de voz avançado e serviços API em tempo real do ChatGPT. É muito adequado para cenários que exigem velocidade de resposta extremamente alta.
O segundo “método em cadeia” é o foco desta conferência.
Ele decompõe todo o processo de processamento em três links independentes: primeiro, um modelo de fala para texto é usado para converter a fala do usuário em texto, depois um modelo de linguagem grande (LLM) processa o conteúdo do texto e gera o texto de resposta e, finalmente, um modelo de conversão de texto para fala é usado para converter a resposta em saída de fala natural.
As vantagens deste método são o design modular, cada componente pode ser otimizado de forma independente, os resultados do processamento são mais estáveis, porque a tecnologia de processamento de texto é geralmente mais madura do que o processamento de áudio direto e o limite de desenvolvimento é mais baixo, os desenvolvedores podem adicionar rapidamente funções de voz baseadas em sistemas de texto existentes;
OpenAI também oferece vários aprimoramentos para estes sistemas de interação por voz:
- Suporta streaming de voz para entrada e saída contínua de áudio
- A função de cancelamento de ruído integrada melhora a clareza da fala.
- Detecção semântica de atividade de fala, capaz de identificar quando um usuário termina de falar
- Fornece ferramentas de UI de rastreamento para facilitar aos desenvolvedores a depuração de agentes de voz
Atualmente, esses novos modelos de áudio estão disponíveis para desenvolvedores em todo o mundo.
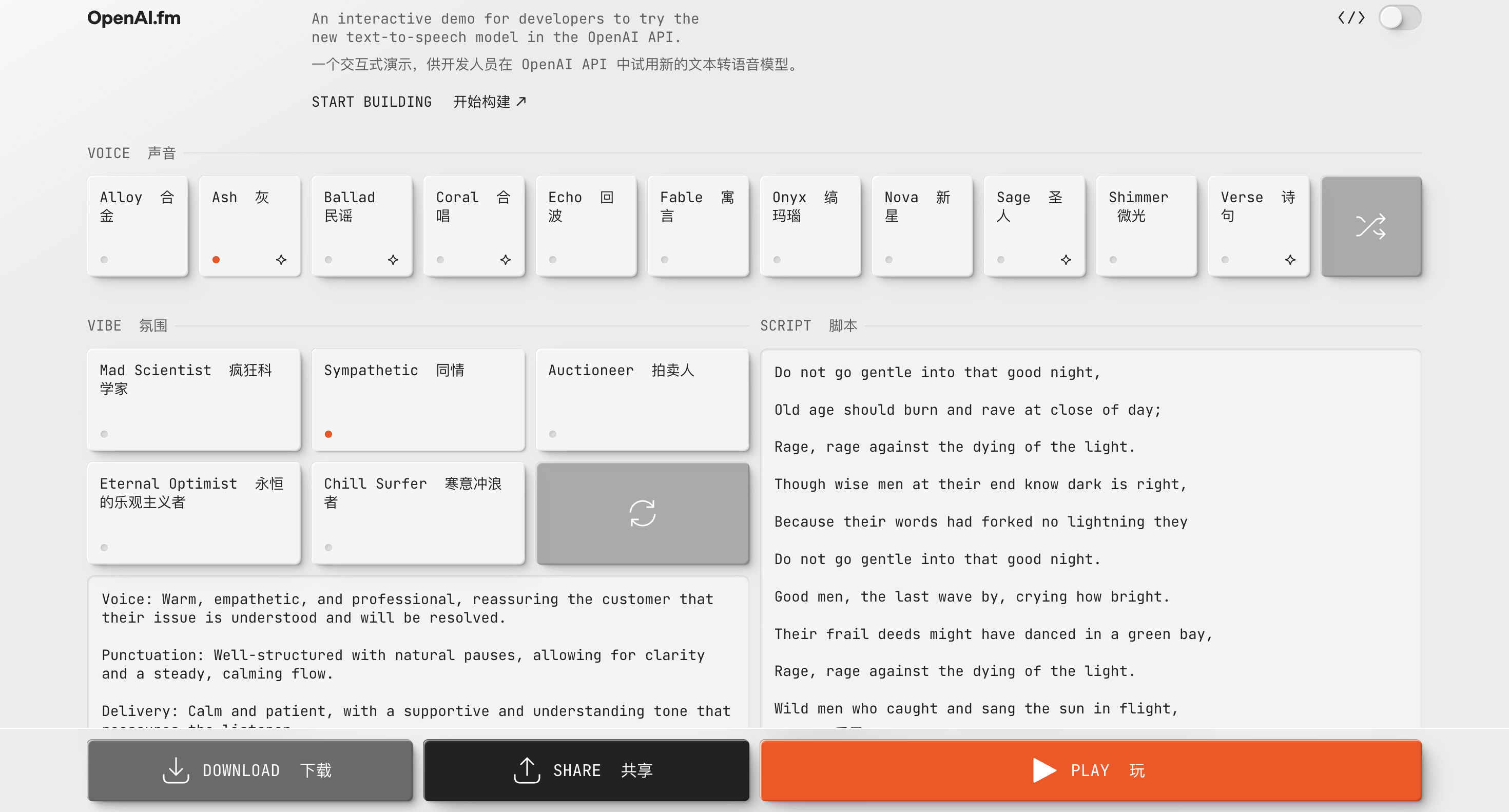
Você também pode experimentar e criar áudio relacionado ao gpt-4o-mini-tts em http://OpenAI.fm. Este site de demonstração é totalmente funcional. O canto inferior esquerdo é o modelo predefinido oficial, que inclui principalmente configurações como personalidade, tom, dialeto e pronúncia.
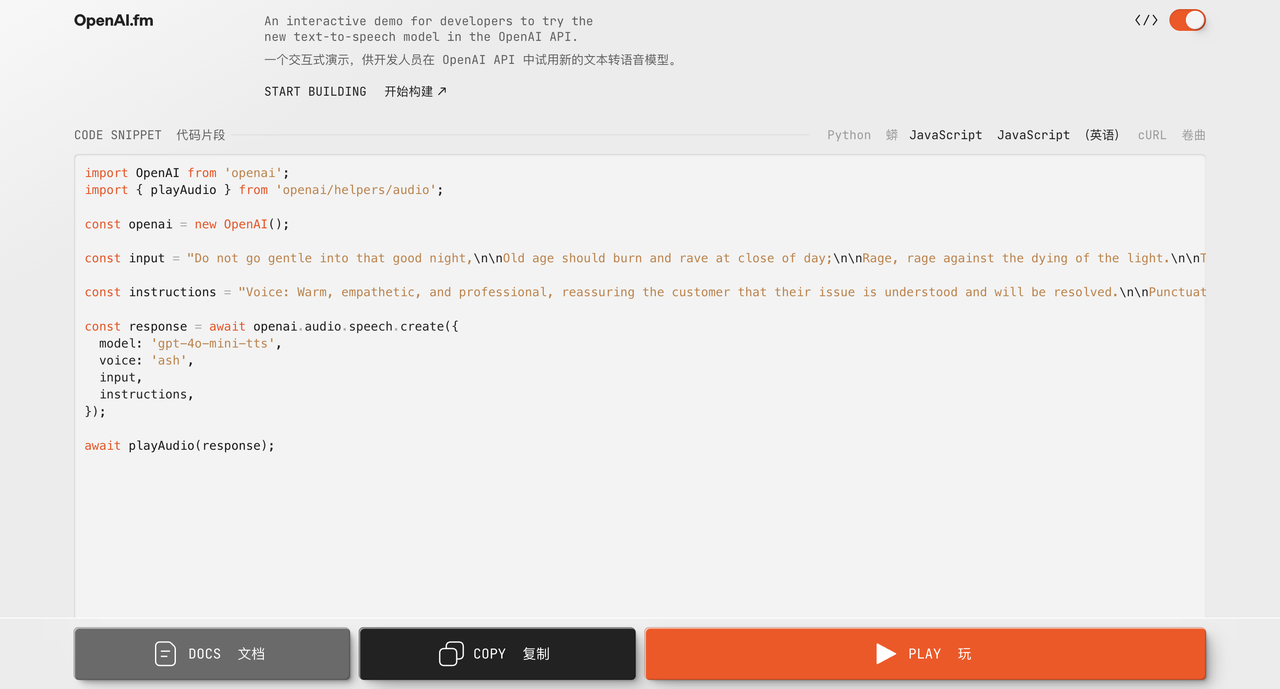
Também testamos um trava-língua com cerca de oitocentos marca-passos subindo a encosta norte de Emmm, a versão chinesa era mais ou menos. Quanto ao efeito inglês, ouvi-lo recitar poesia é como uma pessoa real, mas comparado com o anteriormente popular Hume AI ou Sesame, ainda não é tão bom quanto “audível ao ouvido humano”.
Além disso, a OpenAI lançou a integração com o Agents SDK para simplificar ainda mais o processo de desenvolvimento.
Vale ressaltar que a OpenAI também realizou uma competição de transmissão. Os usuários podem criar áudio em http://OpenAI.fm, usar o botão "Compartilhar" no OpenAI.fm para gerar um link e, em seguida, compartilhar o link na plataforma X.
Os três concorrentes mais criativos receberão, cada um, uma edição limitada do Teenage Engineering OB-4. É recomendado que a duração do áudio seja controlada em cerca de 30 segundos, podendo ser criativo na voz, expressão, pronúncia ou mudanças na entonação do roteiro.

Na verdade, a tendência da IA também está mudando silenciosamente este ano. Além de ainda enfatizar o QI, há também uma tendência adicional de enfatizar a emoção.
Os pontos de venda do GPT-4.5 e Grok 3 são inteligência emocional, escrita mais criativa e respostas mais personalizadas, enquanto o robô frio (Zhiyuan Robot) também enfatiza ser mais antropomórfico e foca em um valor emocional.
Por tocar diretamente a forma mais instintiva de comunicação do ser humano, o campo da voz tem realizado esforços ainda mais significativos nesta área.
A Sesame AI, que recentemente se tornou popular no Vale do Silício, pode sentir as emoções dos usuários em tempo real e gerar respostas emocionalmente ressonantes, capturando rapidamente os corações de um grande número de usuários. O vencedor do Prêmio Turing, Yann Lecun, também enfatizou recentemente que a IA do futuro precisa ter emoções.
Seja o novo modelo de voz lançado hoje pela OpenAI ou o Meta Llama 4, que será lançado em breve, ambos estão se aproximando intencionalmente do diálogo de voz nativo, tentando se aproximar dos usuários por meio de interações emocionais mais naturais e contando com o “toque humano” para atrair fãs.
A IA precisa ser humana? Por muito tempo. Os chatbots são frequentemente definidos como ferramentas sem emoção e também irão lembrá-lo durante a conversa de que se trata de um modelo sem alma. No entanto, muitas vezes podemos interpretar o valor emocional dele e até mesmo estabelecer conexões emocionais com ele inconscientemente.
Talvez o ser humano tenha um desejo inato de ser compreendido e acompanhado, mesmo que essa compreensão venha de uma máquina.
# Bem-vindo a seguir a conta pública oficial do WeChat de Aifaner: Aifaner (WeChat ID: ifanr). Mais conteúdo interessante será fornecido a você o mais rápido possível.
