
A Apple está trabalhando com a Nvidia para tornar a IA mais responsiva

Recentemente, a Apple e a NVIDIA anunciaram uma cooperação para acelerar e otimizar o desempenho de inferência de grandes modelos de linguagem (LLM).
A fim de melhorar a baixa eficiência e a pequena largura de banda de memória do raciocínio LLM autoregressivo tradicional, no início deste ano, os pesquisadores de aprendizado de máquina da Apple lançaram e abriram o código-fonte de uma tecnologia de decodificação especulativa chamada " ReDrafter " (Recurrent Drafter, modelo de rascunho cíclico).
▲Fonte: GitHub
Atualmente, o ReDrafter foi integrado à solução de inferência escalável da NVIDIA " TensorRT-LLM ". Esta última é uma biblioteca de código aberto baseada na estrutura de compilação de aprendizagem profunda "TensorRT" projetada para otimizar a inferência LLM e suporta decodificação especulativa, incluindo o método "Medusa".
No entanto, como os algoritmos incluídos no ReDrafter usam operadores que nunca foram usados antes, a NVIDIA adicionou novos operadores ou expôs os operadores existentes, o que melhora muito a adaptabilidade do TensorRT-LLM a modelos complexos e capacidade de decodificação.
▲Fonte: GitHub
É relatado que a decodificação especulativa do ReDrafter acelera o processo de raciocínio do LLM por meio de três tecnologias principais :
- Rascunho do modelo RNN
- Algoritmo de atenção de árvore dinâmica
- Treinamento de destilação de conhecimento
O modelo preliminar RNN é o componente "principal" do ReDrafter. Ele usa uma rede neural recorrente para prever a sequência de tokens que podem aparecer a seguir com base no "estado oculto" do LLM. Ele pode capturar a dependência do tempo local, melhorando assim a precisão da previsão.
O princípio de funcionamento deste modelo é: LLM primeiro gera um token inicial durante o processo de geração de texto e, em seguida, o modelo de rascunho RNN usa o token e o último estado oculto do LLM como entrada para realizar a pesquisa de feixe (Beam Search) e, em seguida, gera sequência de vários tokens candidatos.
Ao contrário do LLM autorregressivo tradicional, que gera apenas um token por vez, o ReDrafter pode gerar vários tokens em cada etapa de decodificação por meio da saída de previsão do modelo de rascunho RNN, o que reduz bastante o número de vezes que a verificação LLM precisa ser chamada, melhorando assim a velocidade geral de raciocínio.
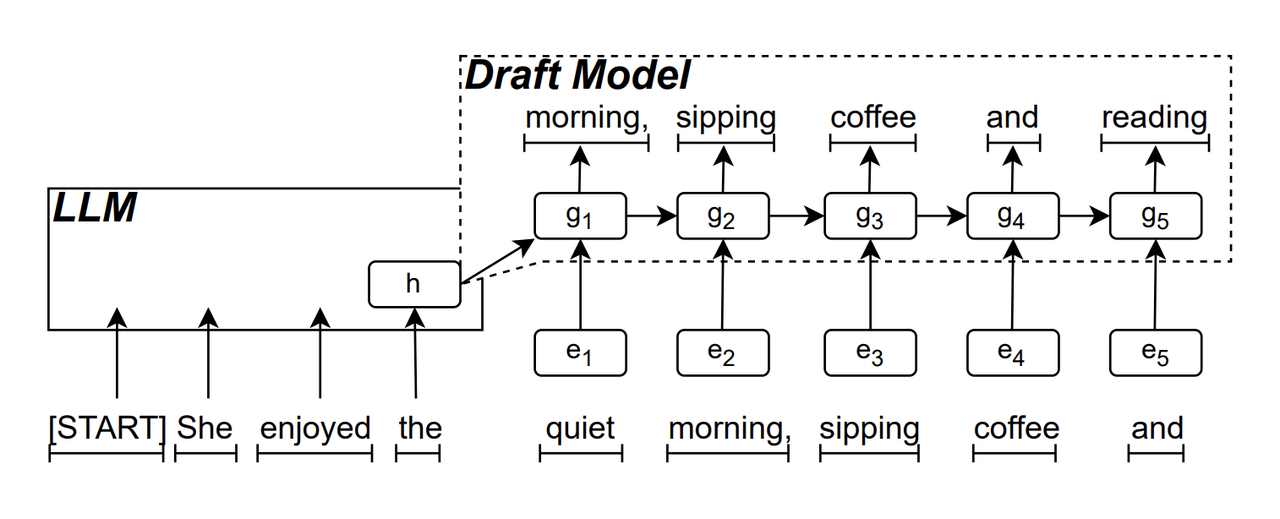
▲ Fonte da imagem: arXiv
Dynamic Tree Attention é um algoritmo que otimiza os resultados da pesquisa de feixe.
Já sabemos que múltiplas sequências candidatas serão geradas durante o processo de busca de feixe, e essas sequências geralmente possuem prefixos compartilhados. O algoritmo de atenção de árvore dinâmica identifica esses prefixos compartilhados e os remove dos tokens que exigem verificação, reduzindo assim a quantidade de dados que o LLM precisa processar.
Em alguns casos, este algoritmo pode reduzir o número de tokens que precisam ser verificados em 30% a 60%. Isso significa que depois de usar o algoritmo de atenção de árvore dinâmica, o ReDrafter pode utilizar os recursos de computação de forma mais eficiente e melhorar ainda mais a velocidade de inferência.
▲ Fonte da imagem: NVIDIA
A destilação de conhecimento é uma tecnologia de compressão de modelo que pode “destilar” o conhecimento de um modelo grande e complexo (modelo de professor) em um modelo menor e mais simples (modelo de aluno). No ReDrafter, o modelo preliminar RNN serve como modelo de aluno e aprende com o LLM (modelo de professor) por meio da destilação de conhecimento.
Especificamente, durante o processo de treinamento de destilação, o LLM fornecerá uma série de "distribuições de probabilidade" das próximas palavras possíveis. Os desenvolvedores treinarão o modelo preliminar da RNN com base nesses dados de distribuição de probabilidade e, em seguida, calcularão a diferença entre as distribuições de probabilidade dos dois. modelos e minimizar essa diferença por meio de algoritmos de otimização.
Nesse processo, o modelo preliminar da RNN aprende continuamente o modo de previsão probabilística do LLM, para que possa gerar texto semelhante ao LLM em aplicações práticas.
Através do treinamento de destilação de conhecimento, o modelo preliminar RNN captura melhor as leis e padrões da linguagem, prevendo assim com mais precisão a saída do LLM e melhora significativamente o desempenho do ReDrafter em hardware limitado devido ao seu tamanho menor e menor custo geral de computação de inferência. sob condições.
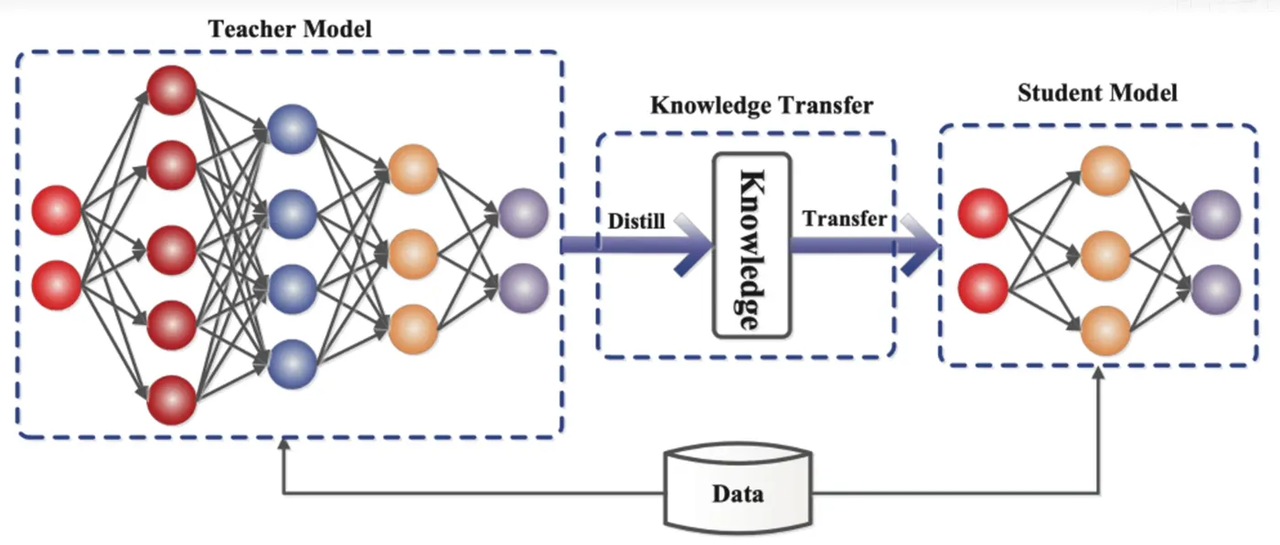
▲ Fonte da imagem: Comunidade de desenvolvedores do Alibaba Cloud
Os resultados do benchmark da Apple mostram que ao usar o TensorRT-LLM integrado ao ReDrafter em um modelo de produção com bilhões de parâmetros na GPU NVIDIA H100, o número de tokens gerados por segundo pelo Greedy Decoding aumentou 2,7 vezes.
Além disso, o ReDrafter também pode atingir um aumento de 2,3x na velocidade de inferência na GPU M2 Ultra Metal da Apple. Os pesquisadores da Apple afirmaram que “o LLM é cada vez mais usado para conduzir aplicativos de produção, e melhorar a eficiência da inferência pode afetar os custos de computação e reduzir a latência do lado do usuário”.
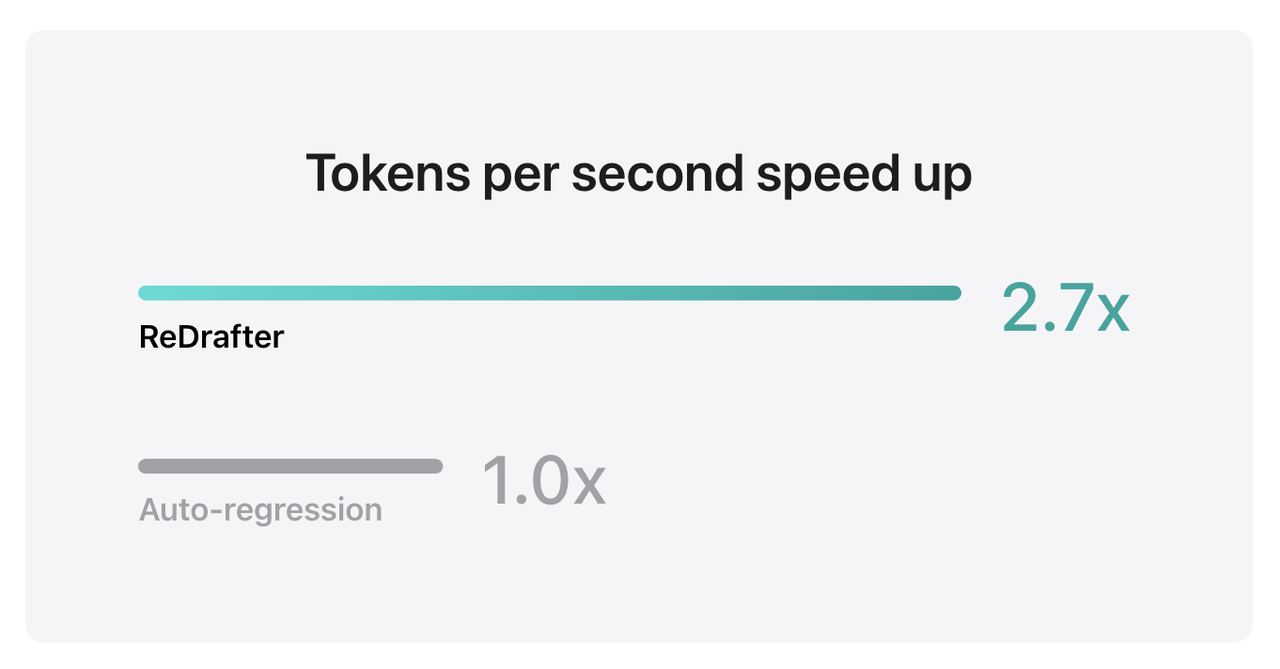
▲ Fonte: Apple
Vale ressaltar que, ao mesmo tempo que mantém a qualidade de saída, o ReDrafter reduz a demanda por recursos de GPU, o que permite que o LLM seja executado com eficiência em ambientes com recursos limitados e oferece oportunidades para que o LLM seja usado em diversas plataformas de hardware.
A Apple agora abriu o código-fonte dessa tecnologia no GitHub, e a Nvidia provavelmente será a única empresa que se beneficiará dela no futuro.
# Bem-vindo a seguir a conta pública oficial do WeChat do aifaner: aifaner (WeChat ID: ifanr). Mais conteúdo interessante será fornecido a você o mais rápido possível.
