
O modelo de próxima geração da OpenAI encontra grandes gargalos, e o ex-cientista-chefe revela uma nova rota tecnológica

O modelo de linguagem grande de próxima geração "Orion" da OpenAI pode ter encontrado um gargalo sem precedentes.
De acordo com The Information, funcionários internos da OpenAI disseram que a melhoria de desempenho do modelo Orion não atendeu às expectativas e que a melhoria de qualidade foi “muito menor” do que a atualização de GPT-3 para GPT-4.
Além disso, eles disseram que o Orion não é mais confiável que seu antecessor, o GPT-4, em determinadas tarefas. Embora Orion tenha habilidades linguísticas mais fortes, pode não ser capaz de superar o GPT-4 em termos de programação .

▲ Fonte da imagem: WeeTech
O relatório salientou que a oferta de textos e outros dados de alta qualidade para formação está a diminuir, o que torna mais difícil encontrar bons dados de formação, retardando assim o desenvolvimento de grandes modelos linguísticos (LLMs) em alguns aspectos.
Não só isso, a formação futura consumirá mais recursos informáticos, recursos financeiros e até eletricidade . Isso significa que o custo e o custo de desenvolvimento e operação do Orion e dos subsequentes grandes modelos de linguagem se tornarão mais caros.
Noam Brown, pesquisador da OpenAI, afirmou recentemente na conferência TED AI que modelos mais avançados podem não ser “ economicamente viáveis ”:
Será que realmente temos que gastar centenas de bilhões ou trilhões de dólares treinando modelos? Em algum momento, a lei da expansão entra em colapso.
Nesse sentido, a OpenAI estabeleceu uma equipe básica liderada por Nick Ryder, responsável pelo pré-treinamento, para estudar como lidar com a falta de dados de treinamento e quanto tempo durarão as leis de escala de grandes modelos.

▲Noam Brown
As leis de escala são uma suposição central no campo da inteligência artificial: enquanto houver mais dados para aprender e mais poder computacional para facilitar o processo de treinamento, grandes modelos de linguagem podem continuar a melhorar o desempenho na mesma proporção.
Simplificando, as leis de escala descrevem a relação entre entrada (volume de dados, poder computacional, tamanho do modelo) e saída, ou seja, até que ponto o desempenho melhora quando investimos mais recursos em um modelo de linguagem grande.
Por exemplo, treinar um grande modelo de linguagem é como construir um carro em uma oficina . Inicialmente a oficina era pequena, com apenas algumas máquinas e poucos trabalhadores. Neste momento, cada máquina ou trabalhador adicional pode aumentar significativamente a produção, porque estes novos recursos são directamente convertidos num aumento da capacidade de produção.
À medida que o tamanho da fábrica aumenta, o aumento na produção de cada máquina ou trabalhador adicional começa a diminuir. Pode acontecer que a gestão se tenha tornado mais complexa ou que a coordenação entre os trabalhadores se tenha tornado mais difícil.
Quando uma fábrica atinge uma determinada escala, adicionar mais máquinas e trabalhadores só pode aumentar a produção até certo ponto. Neste ponto, a fábrica pode estar a aproximar-se dos limites de terreno, fornecimento de energia, logística, etc., e o aumento dos factores de produção já não pode provocar um aumento proporcional na produção .

E é aí que reside o dilema de Órion. À medida que o tamanho do modelo aumenta (semelhante à adição de máquinas e trabalhadores), a melhoria do desempenho do modelo pode ser muito óbvia no início e no médio prazo. Mas no estágio posterior, mesmo que o tamanho do modelo ou a quantidade de dados de treinamento continuem a aumentar, a melhoria do desempenho pode se tornar cada vez menor. Este é o chamado " bater na parede ".
Um artigo recente publicado no arXiv também afirmou que, com a crescente demanda por dados públicos de texto humano e a quantidade limitada de dados existentes, espera-se que o desenvolvimento de grandes modelos de linguagem fique sem recursos atuais entre 2026 e 2032. Existem recursos de dados textuais humanos.
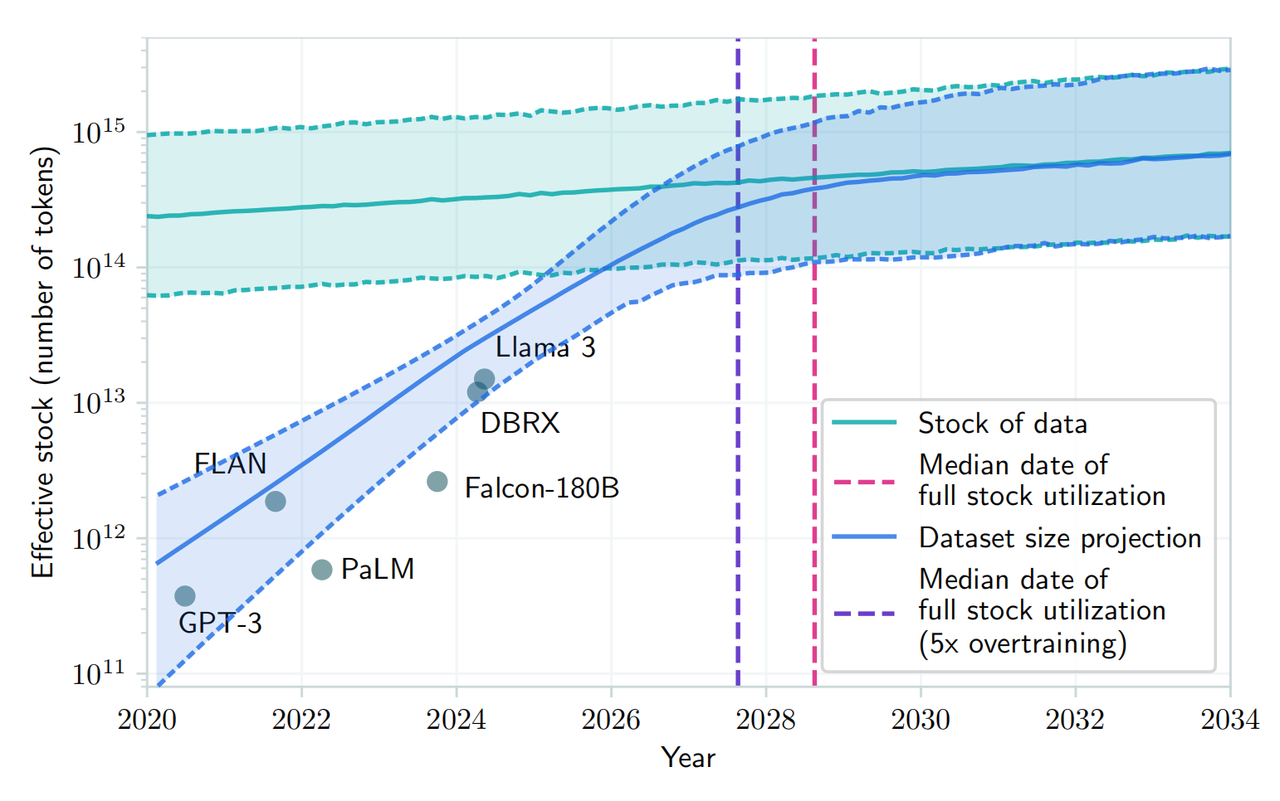
▲ Fonte da imagem: arXiv
Mesmo quando Norm Brown apontou as “questões económicas” da futura formação de modelos, ele ainda se opôs ao ponto de vista acima. Ele acredita que “ o desenvolvimento da inteligência artificial não irá desacelerar tão cedo ”.
Os pesquisadores da OpenAI concordam amplamente. Eles acreditam que, embora a lei de expansão do modelo possa desacelerar, o desenvolvimento geral da IA não será afetado pela otimização do tempo de inferência e pelas melhorias pós-treinamento.
Além disso, os CEOs de Mark Zuckerberg da Meta, Sam Altman da OpenAI e outros desenvolvedores de IA declararam publicamente que ainda não atingiram os limites das leis tradicionais de escalonamento e ainda estão desenvolvendo data centers caros para aumentar o desempenho de modelos pré-treinados.

▲Sam Altman (Fonte: Vanity Fair)
Peter Welinder, vice-presidente de produto da OpenAI, também disse nas redes sociais que “as pessoas subestimam o poder da computação durante os testes ”.
A computação em tempo de teste (TTC) é um conceito de aprendizado de máquina que se refere aos cálculos realizados ao inferir ou prever novos dados de entrada após a implantação do modelo. Isso é separado dos cálculos na fase de treinamento do modelo, onde o modelo aprende padrões nos dados e faz previsões.
Nos modelos tradicionais de aprendizado de máquina, depois que o modelo é treinado e implantado, normalmente não é necessário nenhum cálculo adicional para fazer previsões em novas instâncias de dados. No entanto, em alguns modelos mais complexos, como certos tipos de modelos de aprendizagem profunda, podem ser necessários cálculos adicionais no momento do teste (ou seja, no tempo de inferência).
Por exemplo, o modelo “o1” desenvolvido pela OpenAI utiliza este modelo de raciocínio. Na verdade, toda a indústria de IA está mudando seu foco para um modelo que melhore os modelos após o treinamento inicial .

▲Peter Welinder (Fonte: Dagens industri)
A este respeito, Ilya Sutskever, um dos cofundadores da OpenAI, admitiu numa entrevista recente à Reuters que, ao utilizar grandes quantidades de dados não rotulados para treinar modelos de inteligência artificial para compreender padrões e estruturas linguísticas na fase de pré-formação, o a melhoria do efeito se estabilizou .
“A década de 2010 foi uma era de expansão e agora estamos de volta a uma era de exploração e descoberta”, disse Ilya, observando que “ escalar para a escala certa é mais importante do que nunca”.
Espera-se que o Orion seja lançado em 2025. A OpenAI chamou-o de “Orion” em vez de “GPT-5”, o que pode sugerir uma nova revolução. Embora seja temporariamente “difícil dar à luz” devido a limitações teóricas, ainda esperamos por este “recém-nascido” com um novo nome que possa trazer novas oportunidades ao grande modelo de IA.
# Bem-vindo a seguir a conta pública oficial do WeChat de Aifaner: Aifaner (WeChat ID: ifanr). Mais conteúdo interessante será fornecido a você o mais rápido possível.
